
1. Prima di iniziare
Negli ultimi dieci anni le app web sono diventate sempre più social e interattive, con il supporto di contenuti multimediali, commenti e altro ancora in tempo reale, potenzialmente decine di migliaia di persone, anche su un sito web moderatamente popolare.
Ciò ha anche offerto l'opportunità agli spammer di abusare di tali sistemi e associare i contenuti meno salati agli articoli, ai video e ai post scritti da altri nel tentativo di ottenere maggiore visibilità.
I metodi di rilevamento dello spam meno recenti, come l'elenco di parole bloccate, possono essere facilmente ignorati e non corrispondono esattamente ai bot di spam avanzati, in continua evoluzione nella loro complessità. Ora puoi iniziare a utilizzare i modelli di machine learning che sono stati addestrati per rilevare questo tipo di spam.
Tradizionalmente, l'esecuzione di un modello di machine learning per prefiltrare i commenti veniva eseguita sul lato server, ma con TensorFlow.js ora è possibile eseguire i modelli di machine learning sul lato client, nel browser tramite JavaScript. Puoi fermare lo spam prima che entri in contatto con il back-end, risparmiando potenzialmente risorse costose dal lato server.
Come forse saprai già, il machine learning è ormai una parola d'attesa che interessa quasi tutti i settori del mondo, ma come puoi iniziare a utilizzare queste funzionalità come sviluppatore web?
Questo codelab ti mostrerà come creare un'app web partendo da una tela vuota che affronta il vero problema dei commenti spam utilizzando l'elaborazione del linguaggio naturale (l'arte della comprensione del linguaggio umano con un computer). Molti sviluppatori web troveranno questo problema perché lavorano su una delle sempre più numerose applicazioni web esistenti. Questo codelab ti consentirà di risolvere tali problemi in modo efficiente.
Prerequisiti
Questo codelab è stato scritto per gli sviluppatori web che non hanno mai utilizzato il machine learning e vogliono iniziare a utilizzare i modelli preaddestrati con TensorFlow.js.
Per questo lab si presume una certa familiarità con HTML5, CSS e JavaScript.
Cosa imparerai a fare:
Imparerai a:
- Scopri di più su cos'è TensorFlow.js e su quali modelli esistono per l'elaborazione del linguaggio naturale.
- Crea una semplice pagina web HTML / CSS / JS per un blog di video fittizi con una sezione di commenti in tempo reale.
- Utilizza TensorFlow.js per caricare un modello di machine learning preaddestrato in grado di prevedere se una frase inserita può essere spam o meno e, in tal caso, avvertire l'utente che il suo commento è stato trattenuto per la moderazione.
- Codifica le frasi di commento in modo che il modello di machine learning possa essere utilizzate e quindi classificate.
- Interpreta l'output del modello di machine learning per decidere se vuoi contrassegnare automaticamente il commento o meno. Questa ipotetica UX può essere riutilizzata su qualunque sito web su cui stai lavorando e adattarla a qualsiasi caso d'uso dei clienti, ad esempio un normale blog, un forum o qualsiasi forma di CMS come Drupal.
Niente male. È difficile da fare? Non è originale. Iniziamo la pirateria informatica...
Che cosa ti serve
- è preferibile seguire un account Glitch.com oppure utilizzare un ambiente di pubblicazione web adatto alle tue esigenze.
2. Che cos'è TensorFlow.js?

TensorFlow.js è una libreria di machine learning open source che può essere eseguita in qualsiasi ambiente JavaScript. È basato sulla libreria TensorFlow originale scritta in Python e mira a ricreare questa esperienza sviluppatore e un insieme di API per l'ecosistema JavaScript.
Dove può essere utilizzato?
Data la portabilità di JavaScript, ora puoi scrivere in una sola lingua ed eseguire facilmente il machine learning su tutte le seguenti piattaforme:
- Lato client nel browser web utilizzando JavaScript vanilla
- Dispositivi lato server e perfino IoT, come Raspberry Pi, che utilizza Node.js
- App desktop che utilizzano Electron
- App native per dispositivi mobili che utilizzano React Native
TensorFlow.js supporta anche più backend all'interno di ciascuno di questi ambienti (gli ambienti effettivi basati su hardware che può eseguire all'interno, ad esempio la CPU o WebGL). Un "backend" in questo contesto non significa un ambiente lato server, ad esempio il backend per l'esecuzione in WebGL, per garantire la compatibilità e mantenere un funzionamento rapido. Attualmente TensorFlow.js supporta:
- Esecuzione di WebGL sulla scheda grafica del dispositivo: questo è il modo più rapido per eseguire modelli più grandi (oltre 3 MB) con accelerazione GPU.
- Esecuzione di Web Assembly (WASM) sulla CPU: per migliorare le prestazioni della CPU su tutti i dispositivi, ad esempio i telefoni cellulari di generazione precedente. È più adatto a modelli più piccoli (di dimensioni inferiori a 3 MB) che possono effettivamente essere eseguiti più velocemente sulla CPU con WASM rispetto a WebGL, poiché l'overhead del caricamento dei contenuti avviene su un processore grafico.
- Esecuzione CPU: il video di riserva non dovrebbe essere disponibile in nessuno degli altri ambienti. Questa è la più lenta delle tre, ma è sempre disponibile per te.
Nota: puoi scegliere di forzare uno di questi backend se sai su quale dispositivo eseguirai oppure puoi lasciare che sia TensorFlow.js a decidere per te se non lo specifichi.
Superpoteri lato client
L'esecuzione di TensorFlow.js nel browser web sul computer client può portare a diversi vantaggi che vale la pena prendere in considerazione.
Privacy
Puoi sia addestrare sia classificare i dati sul computer client senza inviare mai dati a un server web di terze parti. In alcuni casi potrebbe essere necessario rispettare le leggi locali, ad esempio il GDPR, o quando devi elaborare i dati che l'utente vuole conservare sul computer e non vengono inviati a una terza parte.
Velocità
Poiché non devi inviare dati a un server remoto, l'inferenza (l'atto di classificarli) può essere più veloce. Per di più, puoi accedere direttamente ai sensori del dispositivo, come la fotocamera, il microfono, il GPS, l'accelerometro e altri, qualora l'utente ti concedesse l'accesso.
Copertura e scalabilità
Con un solo clic, chiunque può fare clic su un link inviato da te, aprire la pagina web nel browser e utilizzare le tue creazioni. Non è necessaria una configurazione Linux lato server complessa con driver CUDA e molto altro solo per utilizzare il sistema di machine learning.
Costo
Senza server, l'unica cosa da pagare è una CDN per ospitare i tuoi file HTML, CSS, JS e modello. Il costo di una CDN è molto più basso rispetto al mantenimento di un server (potenzialmente collegato a una scheda grafica) in esecuzione 24 ore su 24, 7 giorni su 7.
Funzionalità lato server
Utilizzando l'implementazione di Node.js, TensorFlow.js abilita le seguenti funzionalità.
Supporto completo di CUDA
Sul lato server, per l'accelerazione della scheda grafica, devi installare i driver CUDA NVIDIA per consentire a TensorFlow di funzionare con la scheda grafica (a differenza del browser che utilizza WebGL, non è necessaria l'installazione). Tuttavia, con il supporto completo di CUDA, puoi sfruttare appieno le capacità di livello inferiore della scheda grafica, offrendo tempi di addestramento e inferenza più rapidi. Le prestazioni sono in linea con l'implementazione di TensorFlow Python perché entrambe condividono lo stesso backend C++.
Dimensioni del modello
Per i modelli all'avanguardia della ricerca, potresti utilizzare modelli molto grandi, magari di gigabyte. Questi modelli attualmente non possono essere eseguiti nel browser web a causa delle limitazioni di utilizzo della memoria per ciascuna scheda del browser. Per eseguire questi modelli di dimensioni maggiori, puoi utilizzare Node.js sul tuo server con le specifiche hardware necessarie per eseguire questo modello in modo efficiente.
IOT
Node.js è supportato su computer a scheda singola molto diffusi come Raspberry Pi, il che significa a sua volta che puoi eseguire i modelli TensorFlow.js su tali dispositivi.
Velocità
Node.js è scritto in JavaScript, per cui trae vantaggio dalla compilazione temporale. Ciò significa che spesso potresti notare un aumento delle prestazioni quando utilizzi Node.js poiché sarà ottimizzato al momento dell'esecuzione, in particolare per ogni pre-elaborazione che potresti eseguire. Ne è un ottimo esempio questo case study che mostra in che modo Hugging Face ha utilizzato Node.js per raddoppiare le prestazioni del modello di elaborazione del linguaggio naturale.
Ora conosci le nozioni di base di TensorFlow.js, dove può essere eseguito, e alcuni dei vantaggi, iniziamo a fare cose utili con questo.
3. Modelli preaddestrati
Perché dovrei utilizzare un modello preaddestrato?
Esistono diversi vantaggi nel iniziare da un modello preaddestrato molto adatto al caso d'uso desiderato, ad esempio:
- Non hai bisogno di raccogliere i dati di formazione. Preparare i dati nel formato corretto e etichettarli in modo che un sistema di machine learning possa utilizzarli per apprendere può richiedere molto tempo e denaro.
- La capacità di creare rapidamente un prototipo in un'idea con costi e tempi ridotti.
Non c'è motivo di reinventare la ruota, quando un modello preaddestrato può essere abbastanza efficace da farti fare ciò che ti serve, così puoi concentrarti sull'utilizzo delle conoscenze fornite dal modello per sviluppare le tue idee creative. - Utilizzo di ricerche all'avanguardia. I modelli preaddestrati sono spesso basati su ricerche popolari che ti danno esposizione a tali modelli, comprendendo anche il loro rendimento nel mondo reale.
- Facilità d'uso e ampia documentazione. A causa della popolarità di questi modelli.
- Trasferisci le funzionalità. Alcuni modelli preaddestrati offrono funzionalità di transfer learning, ovvero la pratica di trasferire le informazioni apprese da un'attività di machine learning a un altro esempio simile. Ad esempio, un modello addestrato originariamente per il riconoscimento dei gatti potrebbe essere addestrato a riconoscere i cani se gli hai fornito nuovi dati. Questo metodo sarà più rapido perché non inizierai con un canvas vuoto. Il modello può utilizzare ciò che ha già imparato per riconoscere i gatti e riconoscere la nuova cosa: anche i cani hanno occhi e orecchie, dopo tutto, quindi se sa già come trovare queste funzionalità, siamo a metà strada. Addestra il modello sui tuoi dati in modo molto più rapido.
Un modello di rilevamento dei commenti preaddestrato
Utilizzerai l'architettura del modello L'incorporamento medio delle parole per le tue esigenze di rilevamento di spam nei commenti, tuttavia, se tenti di utilizzare un modello non addestrato, la modalità che consente di indovinare se le frasi sono spam sarà più che casuale.
Per rendere utile il modello, deve essere addestrato su dati personalizzati, in questo caso per permettergli di comprendere l'aspetto dei commenti spam e non spam. In questo modo, avrai maggiori possibilità di classificare correttamente gli elementi in futuro.
Per fortuna, qualcuno ha già addestrato questa architettura del modello esatta per questa attività di classificazione dei commenti spam, quindi puoi utilizzarla come punto di partenza. Potresti trovare altri modelli preaddestrati che utilizzano la stessa architettura del modello per eseguire operazioni diverse, ad esempio per rilevare la lingua in cui è stato scritto un commento o per prevedere se i dati del modulo di contatto del sito web devono essere indirizzati automaticamente a un determinato team aziendale in base al testo scritto, ad esempio per le vendite (richiesta di prodotto) o per l'ingegneria (bug tecnico o feedback). Con un volume sufficiente di dati di addestramento, un modello come questo può imparare a classificare il testo in ogni caso, per dotare la tua app web dei superpoteri e migliorare l'efficienza della tua organizzazione.
In un futuro lab del codice imparerai a utilizzare Model Maker per addestrare nuovamente questo modello di spam preaddestrato e a migliorare ulteriormente le sue prestazioni sui tuoi dati di commento. Per il momento, potrai utilizzare il modello di rilevamento di commenti spam esistente come punto di partenza per far funzionare l'app web iniziale come primo prototipo.
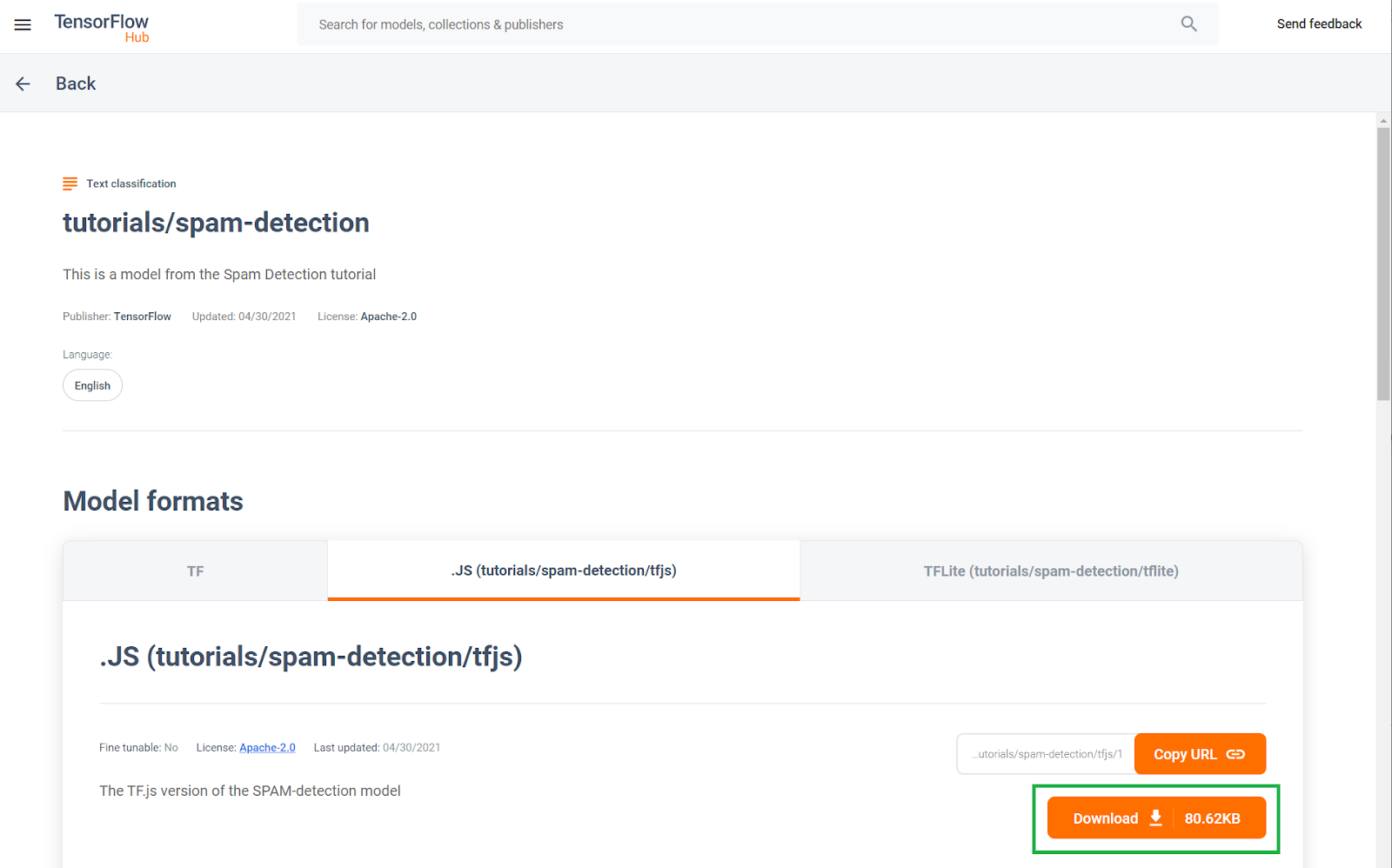
Questo modello di rilevamento di spam preaddestrato è stato pubblicato su un sito web noto come TF Hub, un repository di modelli di machine learning gestito da Google, in cui gli ingegneri di ML possono pubblicare i modelli predefiniti per molti casi d'uso comuni (ad esempio testo, visione, suoni e altro ancora per casi d'uso specifici all'interno di ciascuna di queste categorie). Procedi e scarica i file del modello per il momento da utilizzare nell'app web in questo codelab.
Fai clic sul pulsante di download per il modello JS, come mostrato di seguito:
4. Configura per codice
Che cosa ti serve
- Un browser web moderno.
- Conoscenza di base di HTML, CSS, JavaScript e Chrome DevTools (visualizzazione dell'output della console).
Iniziamo a programmare.
Abbiamo creato un modello boilerplate Node.js Express per iniziare, da cui puoi semplicemente clonarlo come stato di base per questo codice lab con un solo clic.
In Glitch, fai clic sul pulsante "fai questo remix" per creare un fork e creare un nuovo set di file che puoi modificare.
Questo scheletro molto semplice fornisce i seguenti file all'interno della cartella www:
- Pagina HTML (index.html)
- Foglio di stile (style.css)
- File per scrivere il nostro codice JavaScript (script.js)
Per comodità, abbiamo anche aggiunto nel file HTML un'importazione per la libreria TensorFlow.js simile a questa:
indice.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
Dopodiché pubblichiamo questa cartella www tramite un semplice server Node Express tramite package.json e server.js
5. Boilerplate HTML dell'app
Qual è il tuo punto di partenza?
Tutti i prototipi richiedono alcune struttura di base del codice HTML su cui puoi visualizzare i risultati. Configurala subito. Stai per aggiungere:
- Un titolo per la pagina
- Alcuni testi descrittivi
- Un video segnaposto che rappresenta la voce del blog video
- Un'area per visualizzare e digitare i commenti
Apri index.html e incolla il codice esistente con quanto segue per configurare le funzionalità sopra indicate:
indice.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Analisi dettagliata
Analizziamo parte del codice HTML riportato sopra per evidenziare alcuni elementi chiave che hai aggiunto.
- Hai aggiunto un tag
<h1>per il titolo della pagina insieme a un tag<a>per il pulsante di accesso, tutti contenuti in<header>. Hai aggiunto un<h2>per il titolo dell'articolo e un tag<p>per la descrizione del video. Non c'è niente di speciale. - Hai aggiunto un tag
iframeche incorpora un video di YouTube arbitrario. Per ora utilizzi il potente rap TensorFlow.js come segnaposto, ma puoi inserire qui il video che preferisci semplicemente modificando l'URL dell'iframe. Infatti, su un sito web di produzione, tutti questi valori vengono visualizzati in modo dinamico dal backend, a seconda della pagina visualizzata. - Infine, hai aggiunto un
sectioncon un id e una classe di "comments" che contiene undivmodificabile per scrivere nuovi commenti insieme a unbuttonper inviare il nuovo commento che vuoi aggiungere insieme a un elenco non ordinato di commenti. In ogni elemento dell'elenco hai il nome utente e l'ora della pubblicazione all'interno di un tagspan, quindi infine il commento in un tagp. Due commenti di esempio sono hardcoded per il momento come segnaposto.
Se visualizzi l'anteprima in questo momento, l'output dovrebbe essere simile al seguente:
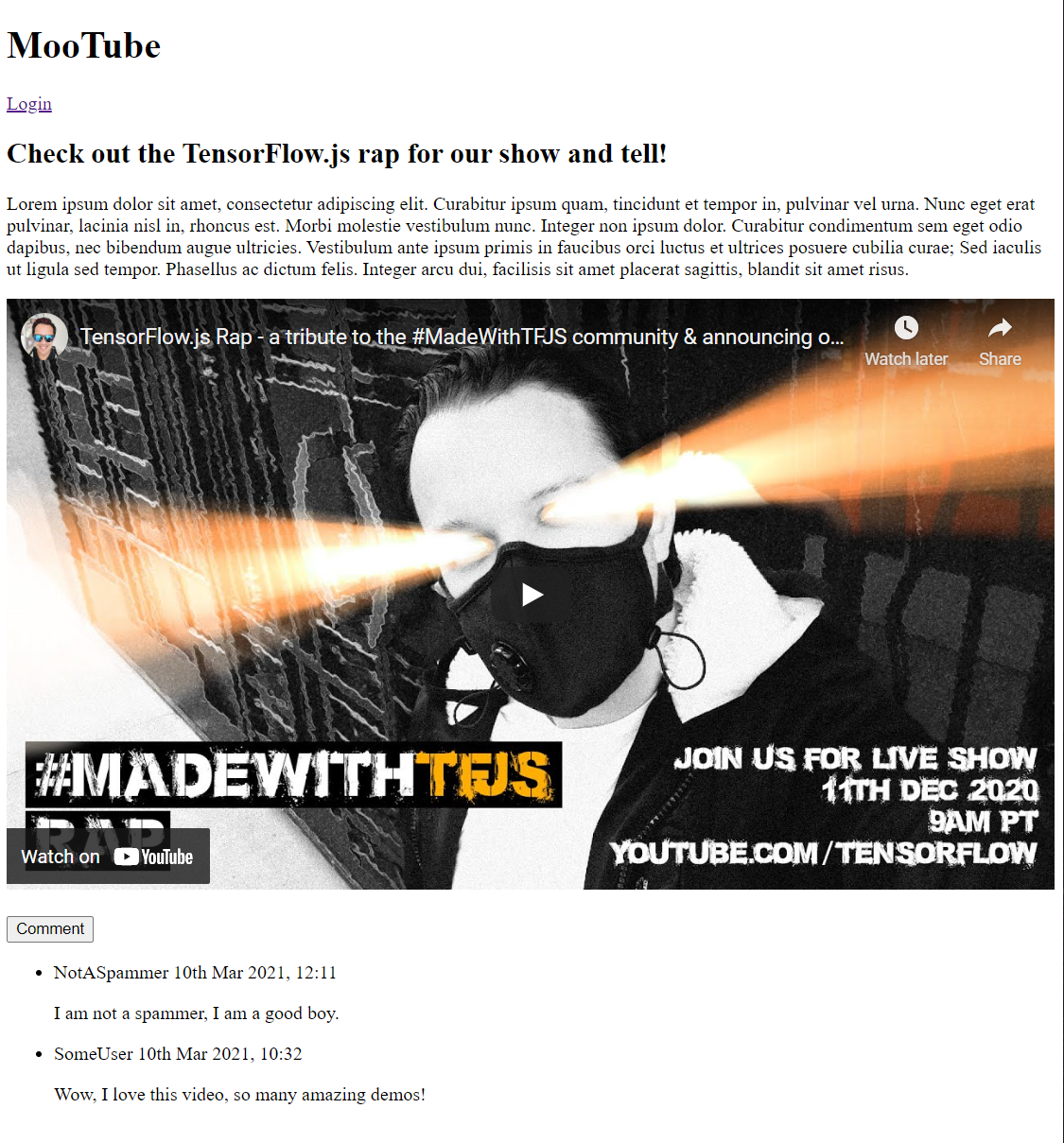
Beh, è pessimo, quindi è il momento di aggiungere un po' di stile...
6. Aggiungi stile
Valori predefiniti elemento
Innanzitutto, aggiungi stili per gli elementi HTML appena aggiunti per assicurarti che vengano visualizzati correttamente.
Inizia applicando un ripristino CSS per avere un punto di partenza per i commenti su tutti i browser e il sistema operativo. Sovrascrivi style.css contenuti con i seguenti valori:
style.css
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
A questo punto, aggiungi un utile codice CSS per dare vita all'interfaccia utente.
Aggiungi quanto segue alla fine del giorno style.css sotto il codice CSS di reimpostazione che hai aggiunto sopra:
style.css
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
Bene. È tutto ciò che ti serve. Se hai sovrascritto correttamente i tuoi stili con il seguente codice, l'anteprima in tempo reale dovrebbe avere il seguente aspetto:

Dolci modalità notturna, per impostazione predefinita, e suggestive transizioni CSS per effetti a volontà su elementi chiave. Niente male. Ora integra alcune logiche di comportamento utilizzando JavaScript.
7. JavaScript: manipolazione DOM e gestione eventi
Riferimenti a elementi DOM chiave
Innanzitutto, assicurati di poter accedere alle parti principali della pagina che dovrai modificare o a cui accedere in un secondo momento nel codice, oltre a definire alcune costanti della classe CSS per lo stile.
Inizia sostituendo i contenuti di script.js con le seguenti costanti:
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
Gestire la pubblicazione di commenti
Dopodiché, aggiungi un listener di eventi e una funzione di gestione a POST_COMMENT_BTN, in modo che possa recuperare il testo del commento scritto e impostare una classe CSS per indicare che l'elaborazione è iniziata. Verifica di non aver già fatto clic sul pulsante nel caso in cui l'elaborazione sia già in corso.
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
Bene. Se aggiorni la pagina web e provi a pubblicare un commento, dovresti vedere il pulsante del commento e il testo in scala di grigi, mentre nella console dovresti vedere il commento stampato in questo modo:
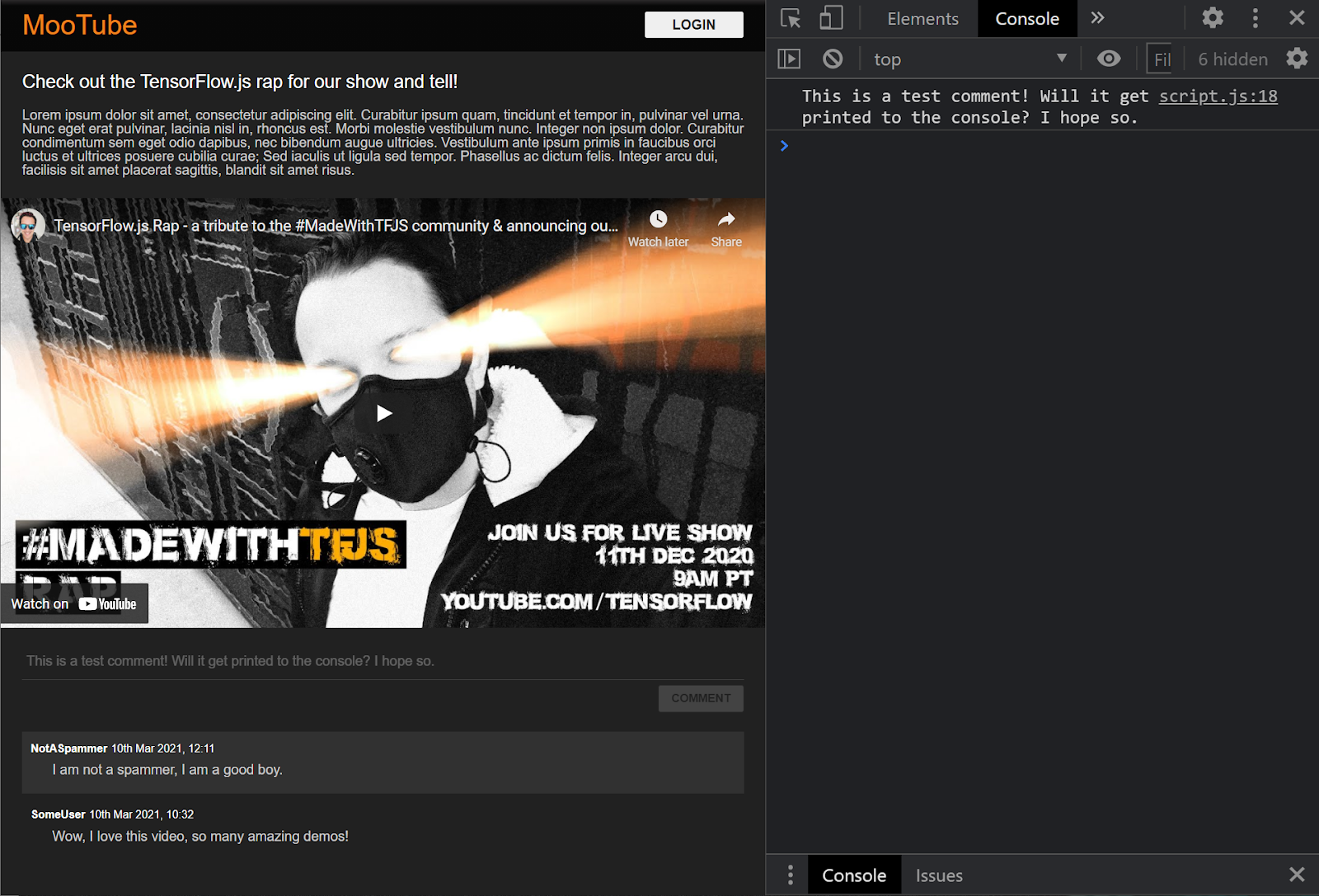
Ora che disponi di uno scheletro di tipo HTML / CSS / JS di base, è il momento di tornare alla tua attenzione con il modello di machine learning in modo da poterlo integrare con la bellissima pagina web.
8. Pubblica il modello di machine learning
È quasi tutto pronto per caricare il modello. Prima di poterlo fare, devi caricare sul tuo sito web i file del modello scaricati in precedenza in modo che siano ospitati e utilizzabili all'interno del codice.
Prima di tutto, se non l'hai già fatto, decomprimi i file che hai scaricato per il modello all'inizio di questo codelab. Dovresti vedere una directory con i seguenti file contenuti all'interno:
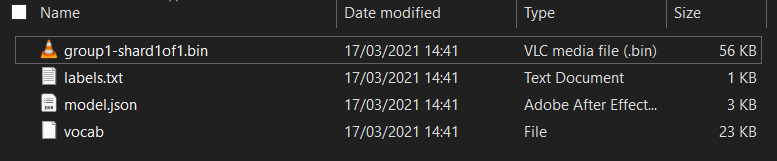
Che cosa hai qui?
model.json: si tratta di uno dei file che costituiscono il modello TensorFlow.js addestrato. In seguito farai riferimento a questo file specifico nel codice TensorFlow.js.group1-shard1of1.bin: si tratta di un file binario contenente le ponderazioni addestrate (essenzialmente un gruppo di numeri che ha imparato a svolgere bene l'attività di classificazione) del modello TensorFlow.js e dovrà essere ospitato sul tuo server per essere scaricato.vocab: questo file strano senza estensione è un elemento di Model Maker che mostra come codificare le parole nelle frasi in modo che il modello capisca come utilizzarle. Approfondirai questo argomento nella sezione successiva.labels.txt: contiene semplicemente i nomi delle classi risultanti che verranno previsti dal modello. Per questo modello, se apri questo file nell'editor di testo, vengono aggiunti ""false" e "vero", come output di previsione.
Ospitare i file del modello TensorFlow.js
Per prima cosa, model.json e i file *.bin generati su un server web per potervi accedere tramite la pagina web.
Caricare file su Glitch
- Fai clic sulla cartella assets nel riquadro a sinistra del progetto Glitch.
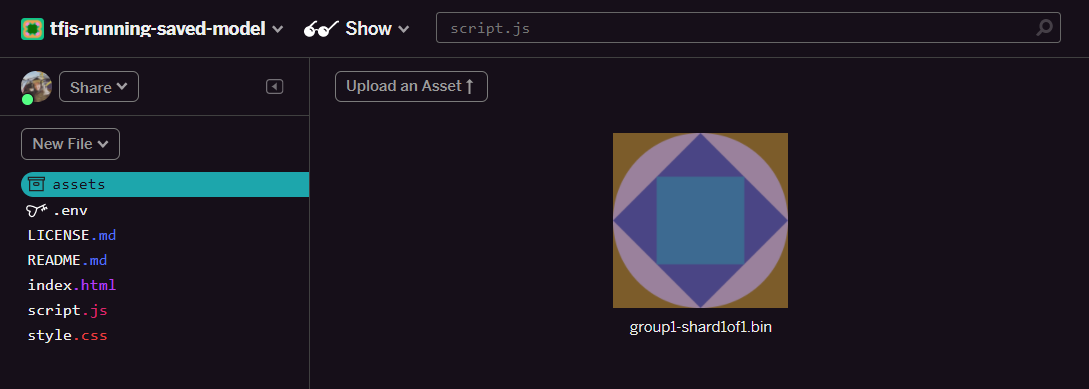
- Fai clic su carica un asset e seleziona
group1-shard1of1.binda caricare in questa cartella. Ora dovrebbe essere simile a questa dopo il caricamento:
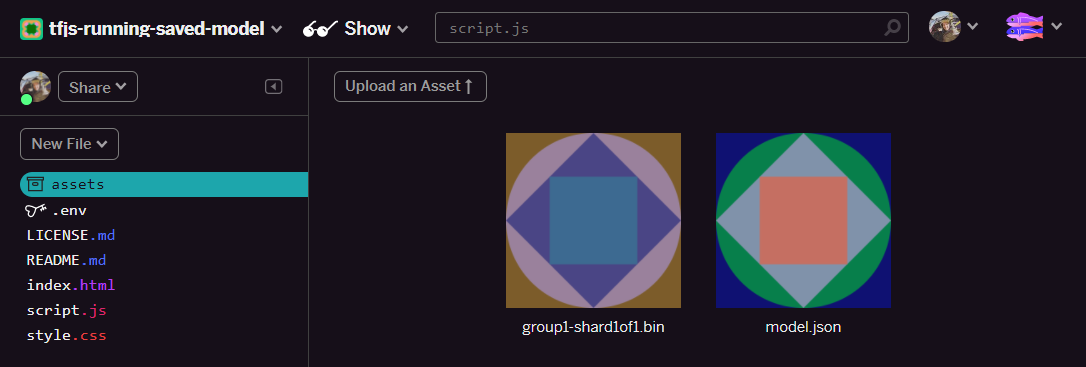
- Bene. Esegui ora la stessa operazione per il file
model.json. Devono essere presenti due file nella cartella assets in questo modo:
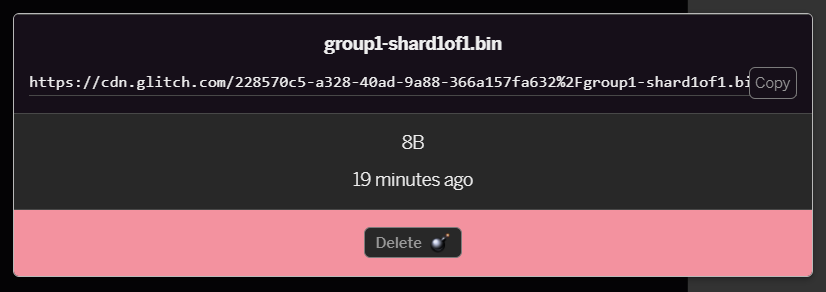
- Fai clic sul file
group1-shard1of1.binappena caricato. Potrai copiare l'URL nella relativa posizione. Copia questo percorso come mostrato:
- Ora, nell'angolo in basso a sinistra dello schermo, fai clic su Strumenti > Terminale. Attendi il caricamento della finestra del terminale. Al termine del caricamento, digita quanto segue, quindi premi Invio per cambiare la directory nella cartella
www:
terminale:
cd www
- Successivamente, utilizza
wgetper scaricare i 2 file appena caricati sostituendo gli URL di seguito con gli URL che hai generato per i file nella cartella assets in Glitch (controlla la cartella degli asset per ogni URL personalizzato di ogni file). Lo spazio tra i due URL e l'URL da utilizzare sarà diverso da quelli riportati di seguito, ma saranno simili:
terminale
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Super, ora hai creato una copia dei file caricati nella cartella www, ma da questo momento verranno scaricati con nomi inusuali.
- Digita
lsnel terminale e premi Invio. Verrà visualizzata un'intestazione simile alla seguente:

- Usa il comando
mvper rinominare i file. Digita quanto segue nella console e premi <kbd>Invio</kbd> o <kbd>return</kbd>, dopo ogni riga.
terminale:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Infine, aggiorna il progetto Glitch digitando
refreshnel terminale e premendo <kbd>Invio</kbd>:
terminale:
refresh
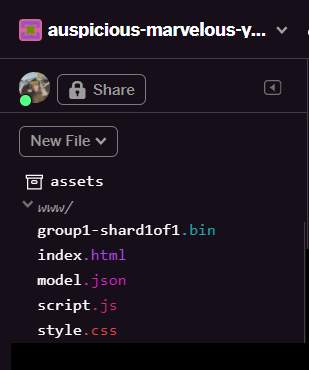
- Dopo l'aggiornamento, dovresti vedere
model.jsonegroup1-shard1of1.binnella cartellawwwdell'interfaccia utente:
Bene. Ora puoi utilizzare i file del modello caricati con un codice effettivo nel browser.
9. Carica e usa il modello TensorFlow.js ospitato
Ora sei in un punto in cui puoi testare il caricamento del modello TensorFlow.js caricato con alcuni dati per verificare se funziona.
Al momento, i dati di esempio riportati di seguito appariranno piuttosto misteriosi (un array di numeri) e il modo in cui sono stati generati verrà spiegato nella sezione successiva. Puoi solo visualizzarlo come una serie di numeri per ora. In questa fase è importante verificare semplicemente che il modello ci fornisca una risposta senza errori.
Aggiungi il seguente codice alla fine del file script.js e assicurati di sostituire il valore della stringa MODEL_JSON_URL con il percorso del file model.json che hai generato quando hai caricato il file nella cartella degli asset del passaggio precedente. Ricorda che puoi semplicemente fare clic sul file nella cartella assets su Glitch per trovare il relativo URL.
Leggi i commenti del nuovo codice di seguito per capire il rendimento di ogni riga:
script.js
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
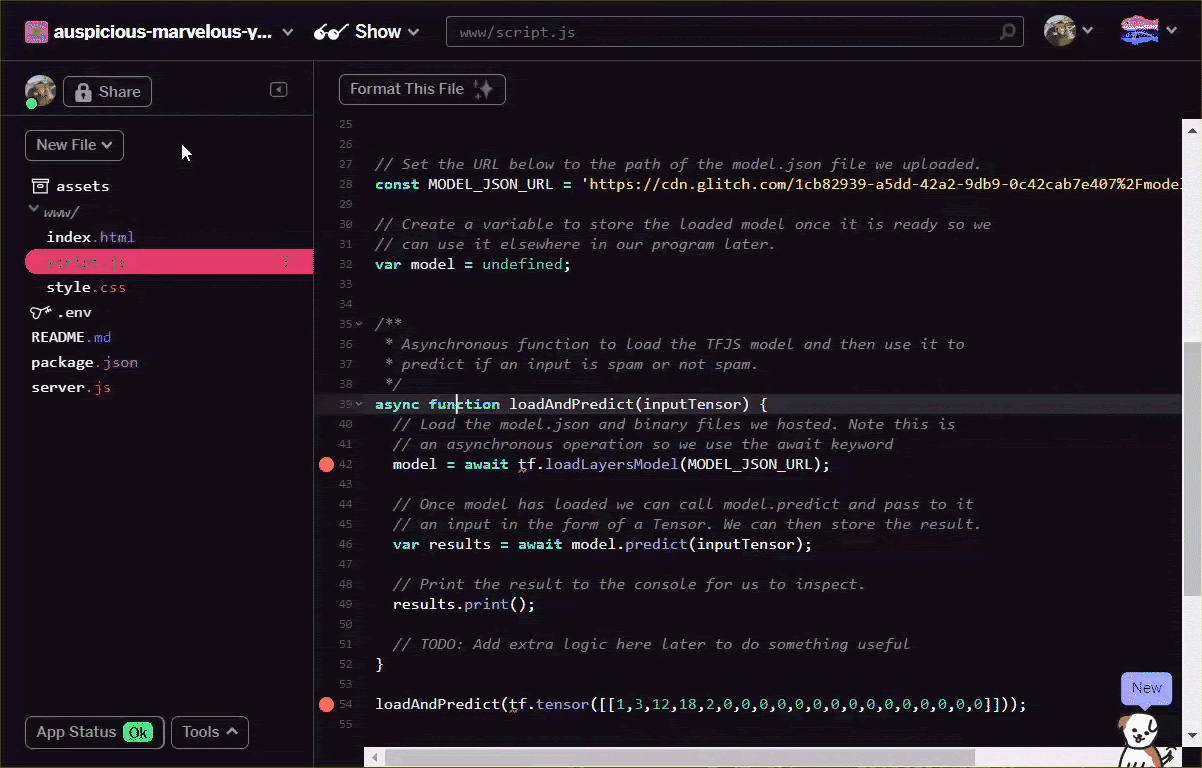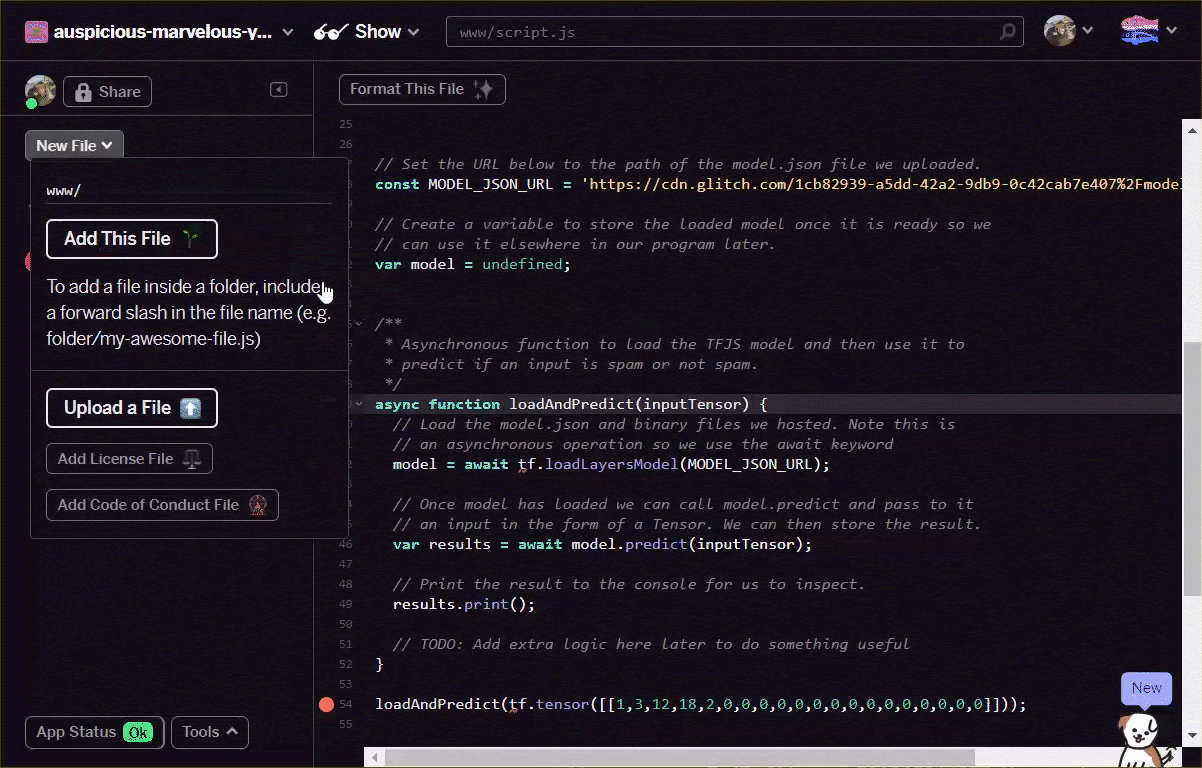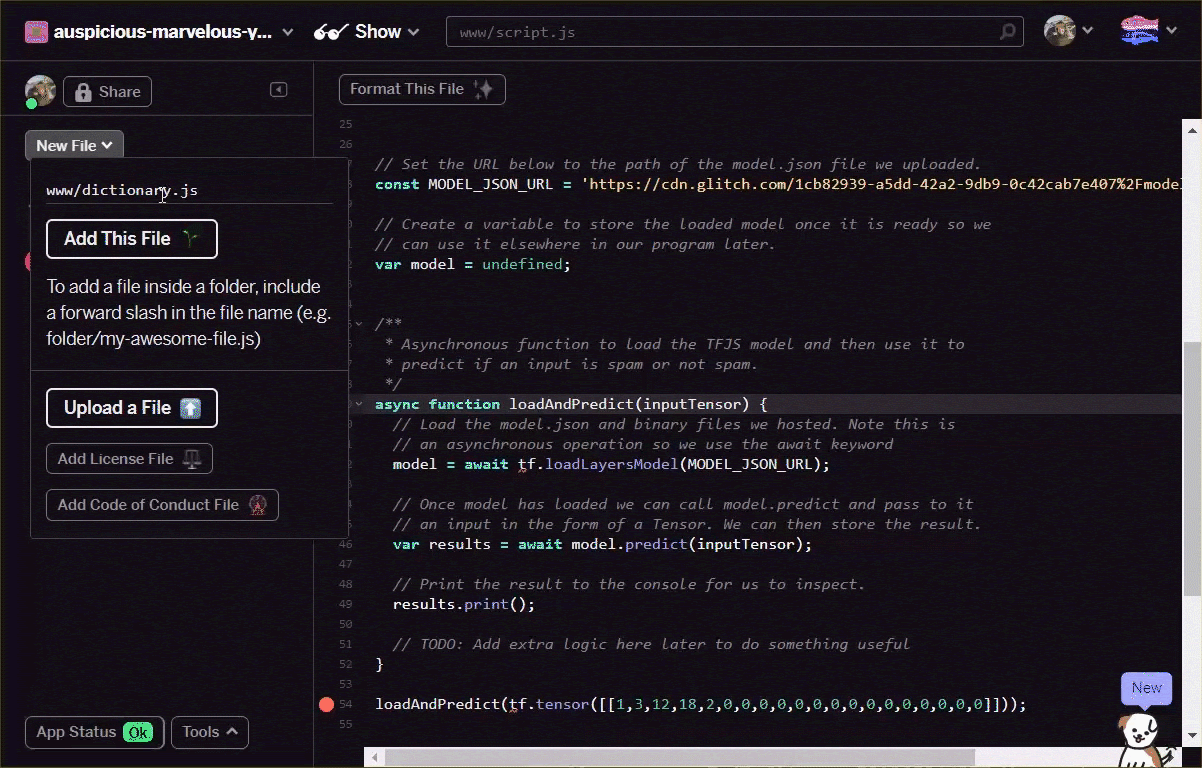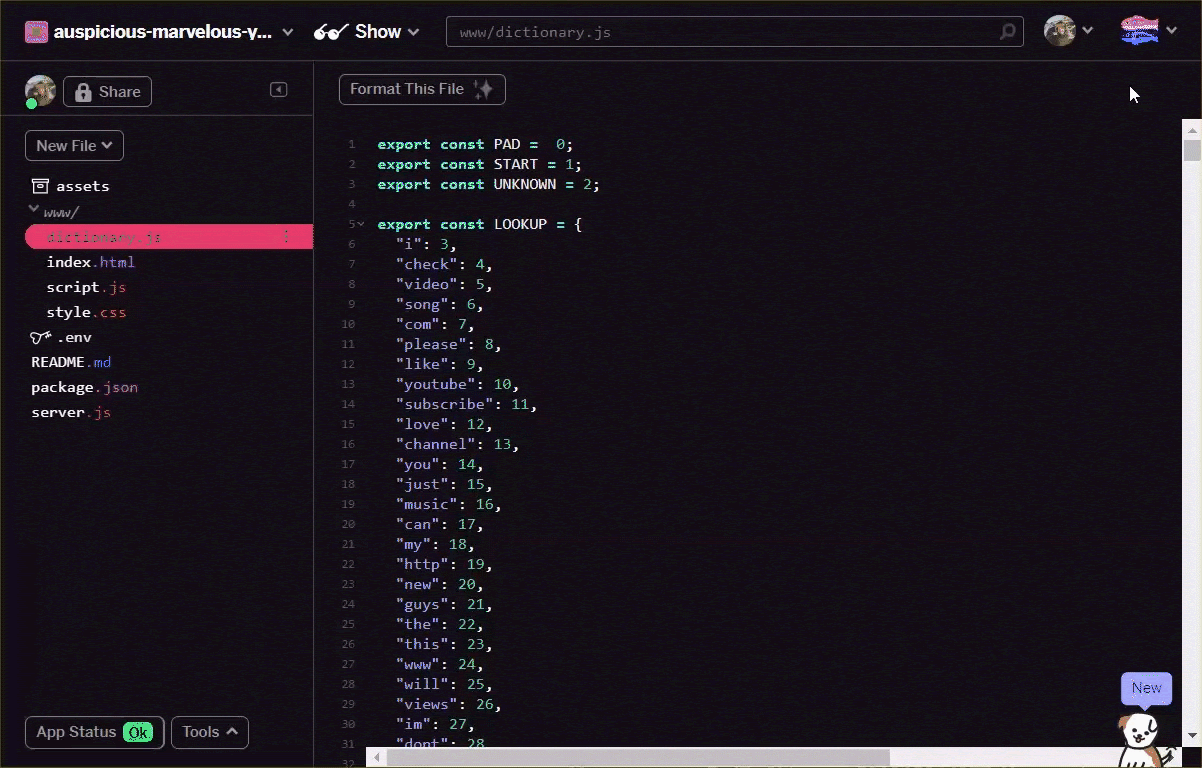
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
Se il progetto è configurato correttamente, ora dovresti utilizzare il modello che hai caricato per prevedere un risultato dall'input trasmesso nella console:
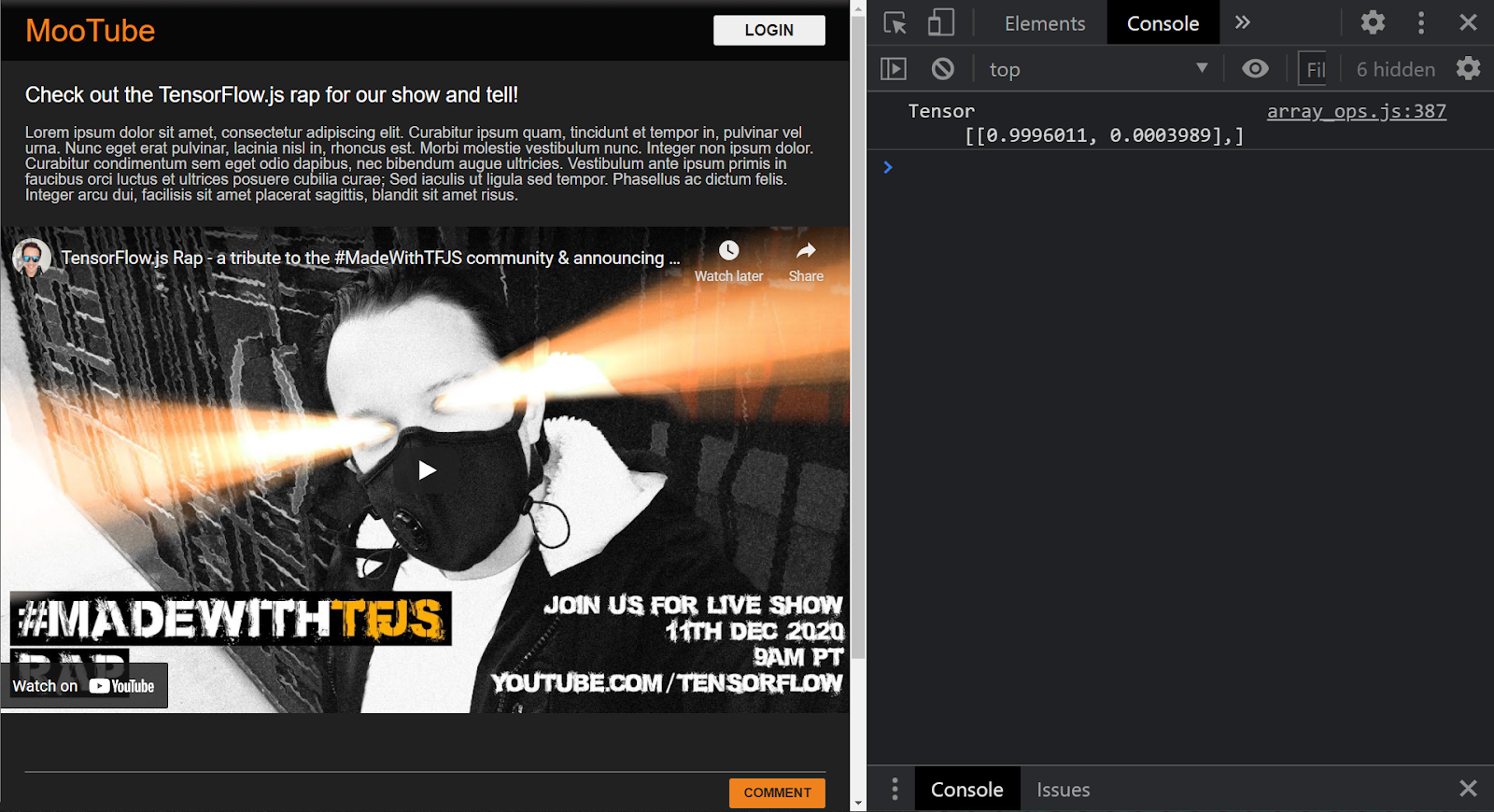
Nella console vedi due numeri stampati:
- 0,9996011
- 0,0003989
Potrebbe sembrare criptico, ma questi numeri rappresentano effettivamente le probabilità di ciò che il modello ritiene che la classificazione sia per l'input che hai fornito. Ma cosa rappresentano?
Se apri il file labels.txt dai file di modello scaricati sulla tua macchina locale, vedrai che contiene anche 2 campi:
- falso.
- vero
Pertanto, il modello in questo caso afferma che è il 99,96011% sicuro (mostrato nell'oggetto del risultato come 0,9996011) che l'input fornito (che era [1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] NON era spam (ad es. Falso).
Tieni presente che false è stata la prima etichetta di labels.txt ed è rappresentata dal primo output della stampa della console, che è il modo in cui conosci la previsione di output.
Ok, adesso sai come interpretare l'output, ma qual era esattamente l'enorme quantità di numeri fornita come input e come puoi convertire le frasi in questo formato affinché il modello possa utilizzarlo? Per questo motivo, devi saperne di più sulla tokenizzazione e sui tensori. Continua a leggere.
10. Tensorizzazione e tokenizzazione
Tokenizzazione
Di conseguenza, i modelli di machine learning possono accettare solo un numero di input. Perché? Ebbene, in sostanza, perché un modello di machine learning è essenzialmente un insieme di operazioni matematiche concatenate, quindi se gli trasmetti qualcosa che non è un numero, avrà difficoltà a affrontarlo. La domanda diventa quindi come si fa a convertire le frasi in numeri da utilizzare con il modello caricato.
Il processo esatto varia da un modello all'altro, ma in questo caso c'è un altro file nei file del modello che hai scaricato, denominato vocab,, e questa è la chiave della codifica dei dati.
Apri vocab in un editor di testo locale sul computer e visualizzerai quanto segue:
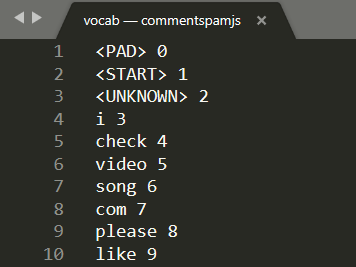
Essenzialmente si tratta di una tabella di ricerca su come convertire le parole significative che il modello ha appreso in numeri che è in grado di comprendere. Esistono anche alcuni casi speciali nella parte superiore del file <PAD>, <START> e <UNKNOWN>:
<PAD>: abbreviazione di "padding". In questo caso, i modelli di machine learning apprezzano avere un numero fisso di input, indipendentemente dalla durata della frase. Il modello utilizzato prevede che siano sempre presenti 20 numeri per l'input (questo valore è stato definito dall'autore del modello e può essere modificato se si reimposta il modello). Quindi, se hai una frase come "Mi piace video", riempirai gli spazi rimanenti nell'array con 0& che rappresenta il token<PAD>. Se la frase è più lunga di 20, è necessario suddividerla in modo che soddisfi questo requisito ed effettuare più classificazioni su molte frasi di dimensioni inferiori.<START>: questo è semplicemente il primo token che indica l'inizio della frase. Noterai che nei passaggi precedenti l'array di numeri iniziato con l'esempio "" - rappresentava il token<START>.<UNKNOWN>- Come potrai intuire, se la parola non esiste nella ricerca di una parola, è sufficiente utilizzare il token<UNKNOWN>(rappresentato da un "2") come numero.
Ogni altra parola è presente nella ricerca e ha un numero speciale associato, quindi useresti questa parola o non esiste, nel qual caso utilizzerai il numero di token <UNKNOWN>.
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
Da questo momento puoi vedere che questa era una frase con 4 parole, mentre le altre sono <START> o <PAD> e ci sono 20 numeri nell'array. Ok, inizio a dare un senso alla questione.
In realtà ho scritto qualcosa come "Adoro il mio cane". dallo screenshot riportato sopra puoi vedere "I" viene convertito nel numero "3", che è corretto. Se cercassi le altre parole, dovresti trovare anche i numeri corrispondenti.
Tensor
Prima che il modello di ML accetti l'input numerico, esiste un ostacolo finale. Devi convertire l'array di numeri in qualcosa di noto come Tensor. Sì, hai indovinato, TensorFlow ha il nome da questi elementi, il flusso di Tensor, attraverso un modello.
Cos'è un Tensor?
La definizione ufficiale di TensorFlow.org dice:
"I Tensor sono array multidimensionali con un tipo uniforme. Tutti i tensori sono immutabili: non puoi mai aggiornare il contenuto di un tensore, ma solo crearne uno nuovo.
In parole semplici, si tratta di un nome matematico sofisticato per un array di qualsiasi dimensione che abbia alcune funzioni integrate nell'oggetto Tensor che sono utili per gli sviluppatori del machine learning. Tieni presente, tuttavia, che Tensor memorizza i dati di un solo tipo, ad esempio tutti i numeri interi o tutti i numeri in virgola mobile e, una volta creato, non puoi mai modificare i contenuti di un Tensor, quindi puoi pensare a questo come una casella di archiviazione permanente per i numeri.
Per il momento, non preoccuparti. Per lo più, si tratta di un meccanismo di archiviazione multidimensionale su cui lavorare i modelli di machine learning, fino a quando non approfondisci un buon libro come questo, consigliato vivamente se vuoi scoprire di più su Tensor e sulle modalità di utilizzo.
Per riassumere: Codifica Tensor e tokenizzazione
Come puoi quindi utilizzare quel file vocab nel codice? Ottima domanda.
Questo file è molto utile a te in quanto sviluppatore JS. Sarebbe molto meglio se si trattasse di un oggetto JavaScript che si poteva semplicemente importare e utilizzare. Scoprirai come sarebbe semplice convertire i dati in questo file in un formato più simile a questo:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
Utilizzando il tuo editor di testo preferito, puoi trasformare facilmente il file vocab in un formato di questo tipo con una ricerca e sostituzione. Tuttavia, puoi anche utilizzare questo strumento predefinito per semplificare l'operazione.
Se esegui questa operazione in anticipo e salvi il file vocab nel formato corretto, non potrai eseguire questa conversione e analizzare ogni caricamento pagina, che è uno spreco di risorse della CPU. Inoltre, gli oggetti JavaScript hanno le seguenti proprietà:
"Il nome di una proprietà dell'oggetto può essere qualsiasi stringa JavaScript valida oppure qualsiasi elemento che possa essere convertito in una stringa, inclusa la stringa vuota. Tuttavia, è possibile accedere a qualsiasi nome di proprietà diverso da un identificatore JavaScript valido (ad esempio, il nome di una proprietà che contiene uno spazio o un trattino o inizia con un numero) utilizzando la notazione della parentesi quadre".
Pertanto, se utilizzi la notazione della parentesi quadra, puoi creare una tabella di ricerca piuttosto efficace attraverso questa semplice trasformazione.
Convertire in un formato più utile
Converti il file vocab nel formato sopra riportato, manualmente utilizzando il tuo editor di testo o utilizzando questo strumento qui. Salva l'output risultante come dictionary.js nella cartella www.
In Glitch, puoi semplicemente creare un nuovo file in questa posizione e incollare il risultato della conversione da salvare come mostrato:
Dopo aver salvato un file dictionary.js nel formato descritto sopra, puoi anteporre il seguente codice alla parte superiore di script.js per importare il modulo dictionary.js che hai appena scritto. Qui puoi anche definire un'ulteriore ENCODING_LENGTH costante, in modo da sapere di quanto eseguire il pad in seguito nel codice, insieme a una funzione tokenize che utilizzerai per convertire un array di parole in un tensore adatto che può essere utilizzato come input per il modello.
Leggi i commenti nel codice qui sotto per maggiori dettagli sulle operazioni eseguite da ciascuna riga:
script.js
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
Ottimo. Ora torna alla funzione handleCommentPost() e sostituiscila con questa nuova versione.
Visualizza il codice per vedere cosa hai aggiunto:
script.js
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
Infine, aggiorna la funzione loadAndPredict() per impostare uno stile se viene rilevato un commento come spam.
Per ora puoi semplicemente modificare lo stile, ma in seguito puoi scegliere di trattenere il commento in un certo tipo di coda di moderazione o di interromperne l'invio.
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. Aggiornamenti in tempo reale: Node.js + WebSocket
Ora che hai un frontend funzionante con rilevamento dello spam, l'ultima parte del rompicapo è l'utilizzo di Node.js con alcuni socket web per la comunicazione in tempo reale e l'aggiornamento in tempo reale di tutti i commenti aggiunti che non sono spam.
Bussola.io
Socket.io è uno dei modi più utilizzati (al momento della scrittura) per utilizzare websocket con Node.js. Procedi per indicare a Glitch che vuoi includere la libreria Socket.io nella build modificando package.json nella directory di primo livello (nella cartella principale della cartella www) in modo da includere socket.io come una delle dipendenze:
package. json
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
Bene. Una volta aggiornato, esegui l'aggiornamento index.html all'interno della cartella www in modo da includere la libreria socket.io.
Posiziona semplicemente questa riga di codice sopra l'importazione del tag dello script HTML per script.js verso la fine del file index.html:
indice.html
<script src="/socket.io/socket.io.js"></script>
Ora dovresti avere tre tag script nel file index.html:
- la prima importa la libreria TensorFlow.js
- Il secondo importazione di socket.io appena aggiunto
- e l'ultimo deve importare il codice script.js.
Successivamente, modifica server.js per configurare socket.io all'interno del nodo e creare un semplice backend per inoltrare i messaggi ricevuti a tutti i client connessi.
Consulta i commenti al codice riportati di seguito per una spiegazione del funzionamento del codice Node.js:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
Bene. Ora hai un server web che rimane in ascolto degli eventi socket.io. Vale a dire che hai un evento comment quando un nuovo commento proviene da un client e il server emette eventi remoteComment che il codice lato client ascolterà per sapere come visualizzare un commento remoto. L'ultima cosa da fare è aggiungere la logica socket.io al codice lato client per emettere e gestire questi eventi.
Per prima cosa, aggiungi il seguente codice alla fine di script.js per connetterti al server socket.io e ascolta / gestisci gli eventi remoteComment ricevuti:
script.js
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
Infine, aggiungi un codice alla funzione loadAndPredict per emettere un evento socket.io se un commento non è spam. Ciò ti consente di aggiornare gli altri client connessi con questo nuovo commento poiché il contenuto di questo messaggio verrà inoltrato loro tramite il codice server.js che hai scritto sopra.
Puoi sostituire la tua funzione loadAndPredict esistente con il seguente codice che aggiunge un'istruzione else al controllo antispam finale, qualora la nota non sia spam, dovrai chiamare socket.emit() per inviare tutti i dati del commento:
script.js
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
Benissimo! Se hai seguito correttamente la procedura, ora dovresti riuscire ad aprire due istanze della pagina index.html.
Quando pubblichi commenti non spam, dovresti visualizzarli quasi istantaneamente sull'altro client. Se il commento è spam, semplicemente non verrà mai inviato e verrà contrassegnato come spam nel frontend che lo ha generato solo nel seguente modo:
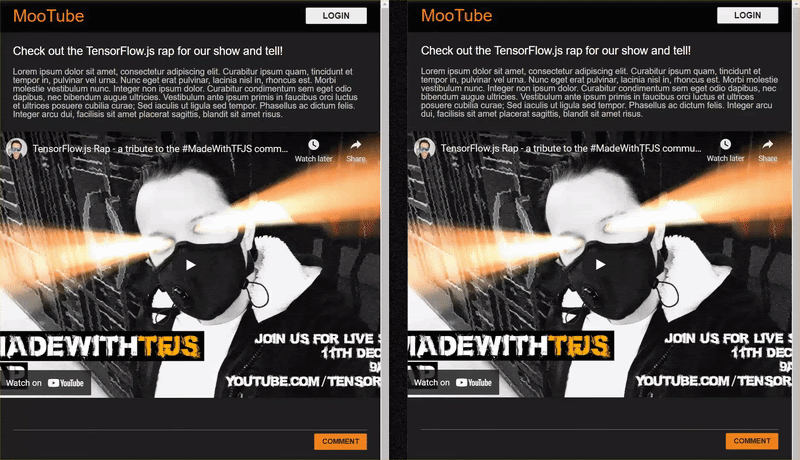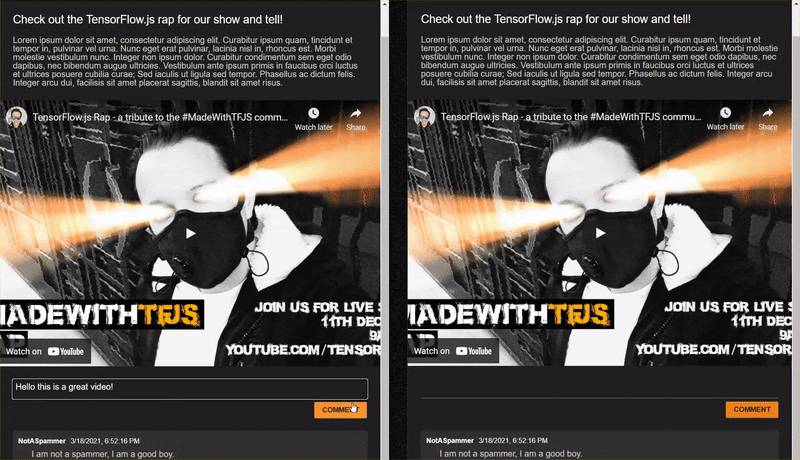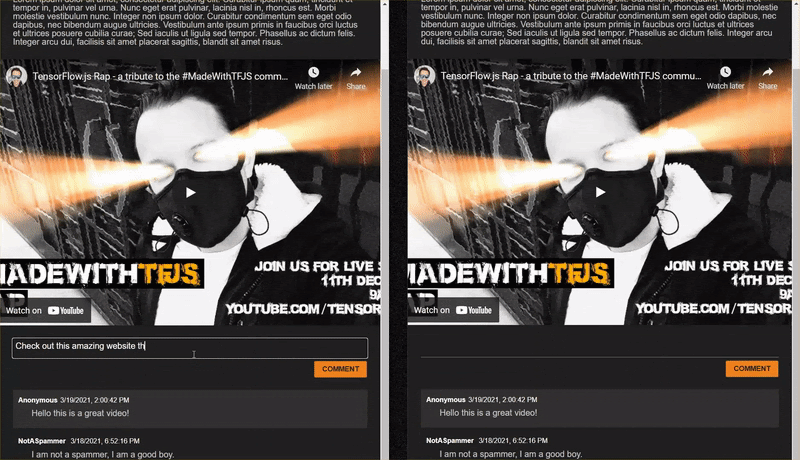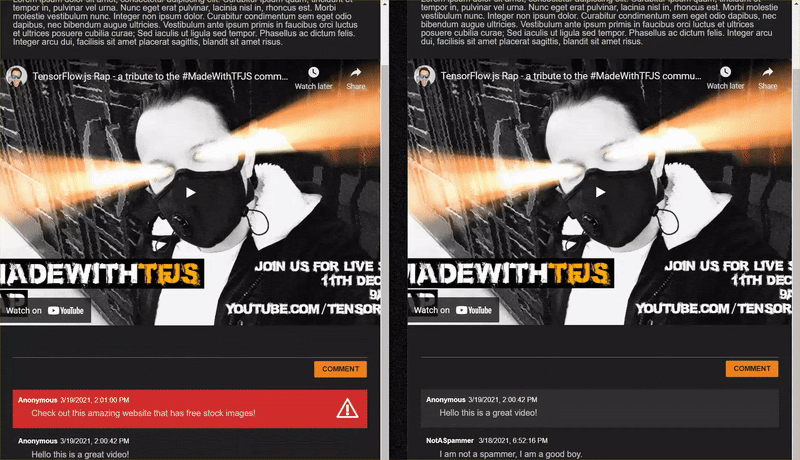
12. Complimenti
Congratulazioni. Hai fatto i primi passi nell'utilizzo del machine learning con TensorFlow.js nel browser web di un'applicazione reale: rileva i commenti spam.
Prova la funzionalità, provala in base a una serie di commenti: potresti notare che alcuni elementi sono ancora in fase di elaborazione. Noterai inoltre che, se inserisci una frase di lunghezza superiore a 20 parole, attualmente l'errore non verrà completato poiché il modello prevede 20 parole come input.
In tal caso, potresti dover suddividere le frasi lunghe in gruppi di 20 parole, quindi prendere in considerazione la probabilità di spam di ogni frase secondaria per stabilire se mostrare o meno. Lasciamo questa opzione come un'attività aggiuntiva facoltativa per sperimentare i diversi approcci disponibili.
Nel codelab successivo, ti mostreremo come addestrare questo modello con i tuoi dati personalizzati dei commenti per i casi limite che attualmente non rileva o persino per modificare le aspettative in termini di input del modello in modo che possa gestire frasi di lunghezza superiore a 20 parole e quindi esportare e utilizzare il modello con TensorFlow.js.
Se per qualche motivo si verificano dei problemi, confronta il tuo codice con questa versione completa disponibile qui e verifica se hai perso qualcosa.
Riepilogo
In questo codelab:
- Che cos'è TensorFlow.js e quali modelli esistono per l'elaborazione del linguaggio naturale
- È stato creato un sito web fittizio che consente commenti in tempo reale per un sito web di esempio.
- È stato caricato un modello di machine learning preaddestrato adatto al rilevamento di commenti spam tramite TensorFlow.js sulla pagina web.
- Hai imparato a codificare le frasi da usare con il modello di machine learning caricato e ad incapsulare la codifica in un oggetto Tensor.
- Ha interpretato l'output del modello di machine learning per decidere se vuoi trattenere il commento per la revisione e, in caso contrario, inviarlo al server per inoltrare in tempo reale altri client connessi.
Passaggi successivi
Ora che disponi di una base operativa da cui iniziare, quali idee creative puoi trovare per estendere questa caldaia a un modello d'uso reale per il mondo reale?
Condividi con noi le tue creazioni
Puoi anche estendere facilmente le tue entrate correnti per altri casi d'uso creativi e ti invitiamo a pensare fuori dagli schemi e a continuare a compromettere il tuo sito.
Ricordati di taggarci sui social media utilizzando l'hashtag #MadeWithTFJS per avere la possibilità di presentare il tuo progetto sul nostro blog TensorFlow o perfino eventi futuri. Ci piacerebbe vedere cosa ne fai.
Altri codelab di TensorFlow.js per approfondire
- Dai un'occhiata alla parte 2 di questa serie per scoprire come reimpostare il modello di commenti spam per tenere conto dei casi limite che al momento non vengono rilevati come spam.
- Utilizza l'hosting di Firebase per eseguire il deployment e ospitare un modello TensorFlow.js su larga scala.
- Crea una webcam intelligente con un modello di rilevamento di oggetti predefinito con TensorFlow.js
Siti web da visitare
- Sito web ufficiale TensorFlow.js
- Modelli predefiniti di TensorFlow.js
- API TensorFlow.js
- TensorFlow.js Show & Tell: lasciati ispirare e scopri cosa hanno fatto gli altri.