
1. Avant de commencer
Au cours de la dernière décennie, des dizaines de milliers de personnes ont pu accéder à des applications Web de plus en plus sociales et interactives, incluant des commentaires et bien plus encore, sur un site Web à moyennement populaire.
Cela a également permis aux spammeurs d'utiliser ces systèmes de manière abusive et d'y associer des contenus moins salés dans les articles, les vidéos et les posts d'autres utilisateurs, dans le but d'accroître leur visibilité.
Les anciennes méthodes de détection de spam, telles que la liste des mots bloqués, peuvent être facilement ignorées et ne sont tout simplement pas adaptées aux bots de spam avancés, qui évoluent constamment en termes de complexité. Aujourd'hui, vous pouvez utiliser des modèles de machine learning entraînés à détecter de tels spams.
Traditionnellement, l'exécution d'un modèle de machine learning pour préfiltrer les commentaires aurait été effectuée côté serveur. Mais avec TensorFlow.js, vous pouvez désormais exécuter des modèles de machine learning côté client, dans le navigateur via JavaScript. Vous pouvez arrêter le spam avant qu'il n'entre en contact avec le backend, ce qui permet d'économiser des ressources côté serveur coûteuses.
Comme vous le savez peut-être, le machine learning est aujourd'hui un concept à la mode. Alors, comment exploiter ces fonctionnalités en tant que développeur Web ?
Cet atelier de programmation vous explique comment créer une application Web à partir d'un canevas vierge, qui résout le problème du spam réel dans les commentaires à l'aide du traitement du langage naturel (l'art de comprendre le langage humain avec un ordinateur). De nombreux développeurs Web rencontreront ce problème alors qu'ils travaillent sur l'une des applications Web les plus populaires au monde. Cet atelier de programmation vous permettra de résoudre efficacement ces problèmes.
Conditions préalables
Cet atelier de programmation a été rédigé pour les développeurs Web qui découvrent le machine learning et souhaitent commencer à utiliser des modèles pré-entraînés avec TensorFlow.js.
Dans cet atelier, nous partons du principe que vous connaissez les langages HTML5, CSS et JavaScript.
Points abordés
Vous découvrirez comment :
- Apprenez-en plus sur TensorFlow.js et sur les modèles de traitement du langage naturel.
- Créer une page Web HTML / CSS / JS simple pour un blog de vidéos fictive avec une section de commentaires en temps réel.
- Utiliser TensorFlow.js pour charger un modèle de machine learning pré-entraîné capable de prédire si une phrase saisie est susceptible d'être du spam ou non. Si c'est le cas, avertissez l'utilisateur que son commentaire a été soumis à modération.
- Encodez les phrases des commentaires de sorte qu'elles puissent être classées par le modèle de machine learning.
- Interprétez le résultat du modèle de machine learning pour déterminer si vous souhaitez signaler automatiquement le commentaire. Cette expérience utilisateur fictive peut être réutilisée sur n'importe quel site Web sur lequel vous travaillez, et adaptée à tous les cas d'utilisation de clients, par exemple un blog standard, un forum ou une autre forme de CMS comme Drupal.
Joli. Est-il difficile de le faire ? Non. C'est parti !
Prérequis
- un compte Glitch.com est préférable, ou vous pouvez utiliser un environnement de diffusion Web que vous êtes capable de modifier et d'utiliser vous-même.
2. Qu'est-ce que TensorFlow.js ?

TensorFlow.js est une bibliothèque de machine learning Open Source qui peut s'exécuter partout où JavaScript est disponible. Il est basé sur la bibliothèque TensorFlow d'origine écrite en Python et vise à recréer cette expérience de développement et cet ensemble d'API pour l'écosystème JavaScript.
Où puis-je l'utiliser ?
Compte tenu de la portabilité de JavaScript, vous pouvez désormais écrire dans un langage et effectuer des opérations de machine learning sur toutes les plates-formes suivantes en toute simplicité:
- Côté client dans le navigateur Web à l'aide de vanilla JavaScript
- Côté serveur, et même les appareils IoT comme Raspberry Pi à l'aide de Node.js
- les applications de bureau qui utilisent Electron ;
- Les applications mobiles natives utilisant React Native
TensorFlow.js est également compatible avec plusieurs backends dans chacun de ces environnements (les environnements matériels réels qu'il peut exécuter, comme le processeur ou WebGL). Dans ce contexte, un "backend" ne signifie pas un environnement côté serveur. Le backend pour l'exécution peut, par exemple, du côté client dans WebGL, pour assurer la compatibilité et s'exécuter rapidement. Actuellement, TensorFlow.js est compatible avec les points suivants:
- Exécution WebGL sur la carte graphique de l'appareil : il s'agit du moyen le plus rapide d'exécuter des modèles plus volumineux (plus de 3 Mo) avec accélération GPU.
- l'exécution WASM (Web Assembly) sur le processeur pour améliorer les performances du processeur sur tous les appareils, y compris les téléphones mobiles d'ancienne génération. Cette version est mieux adaptée aux modèles plus petits (moins de 3 Mo), qui peuvent s'exécuter plus rapidement sur le processeur avec WASM, et non avec WebGL, en raison de la surcharge d'importation de contenu dans un processeur graphique.
- CPU utilization (Exécution du processeur) : les autres environnements ne doivent pas être disponibles. C'est le plus lent des trois, mais vous pouvez toujours y accéder.
Remarque:Vous pouvez choisir de forcer l'un de ces backends si vous savez sur quel appareil vous allez vous lancer, ou laisser le système TensorFlow.js décider à votre place si vous le faites. ne la spécifiez pas.
Super-utilisateurs côté client
L'exécution de TensorFlow.js dans le navigateur Web de la machine cliente peut entraîner plusieurs avantages à prendre en compte.
Confidentialité
Vous pouvez entraîner et classer des données sur la machine cliente sans jamais envoyer de données à un serveur Web tiers. Dans certains cas, vous pouvez être tenu de respecter les lois locales en vigueur, comme le RGPD, par exemple, ou de traiter les données que l'utilisateur souhaite conserver sur son ordinateur et ne pas envoyer à un tiers.
Vitesse
Comme vous n'avez pas besoin d'envoyer de données à un serveur distant, l'inférence (la classification des données) peut être plus rapide. En outre, vous bénéficiez d'un accès direct aux capteurs de l'appareil, tels que la caméra, le micro, le GPS, l'accéléromètre, etc., si l'utilisateur vous y donne accès.
Couverture et scaling
En un clic, les internautes du monde entier peuvent cliquer sur un lien que vous leur avez envoyé, ouvrir la page Web dans leur navigateur et utiliser votre création. Inutile de configurer Linux côté serveur avec des pilotes CUDA et bien plus encore pour utiliser le système de machine learning.
Coût
Aucun serveur ne signifie que la seule chose à payer est un CDN pour héberger vos fichiers HTML, CSS, JS et de modèle. Le coût d'un CDN est bien moins cher que de laisser un serveur (éventuellement associé à une carte graphique) fonctionner 24h/24, 7j/7.
Fonctionnalités côté serveur
L'implémentation de Node.js de TensorFlow.js active les fonctionnalités suivantes.
Prise en charge complète du CUDA
Du côté du serveur, pour l'accélération de la carte graphique, vous devez installer les pilotes NVIDIA CUDA pour que TensorFlow fonctionne avec la carte graphique (contrairement au navigateur qui utilise WebGL, sans installation). Toutefois, la compatibilité complète de CUDA vous permet d'exploiter pleinement les capacités de niveau inférieur de la carte graphique, ce qui accélère les entraînements et les inférences. Les performances sont semblables à celles de l'implémentation Python pour Python, car elles partagent le même backend C++.
Taille du modèle
Pour les modèles de pointe de la recherche, vous travaillez peut-être avec des modèles très volumineux, de la taille d'un gigaoctet par exemple. Pour le moment, ces modèles ne peuvent pas être exécutés dans le navigateur Web en raison des limitations de l'utilisation de la mémoire par onglet du navigateur. Pour exécuter ces modèles plus volumineux, vous pouvez utiliser Node.js sur votre propre serveur, avec les caractéristiques matérielles dont vous avez besoin pour exécuter ces modèles efficacement.
OI
Node.js est compatible avec les ordinateurs à carte unique populaires comme Raspberry Pi, ce qui signifie que vous pouvez également exécuter des modèles TensorFlow.js sur ces appareils.
Vitesse
Node.js est écrit en JavaScript, ce qui signifie qu'il ne présente qu'un temps de compilation. Cela signifie que vous pouvez souvent constater des gains de performances lorsque vous utilisez Node.js, car il sera optimisé au moment de l'exécution, en particulier pour tout prétraitement que vous effectuez. Prenons l'exemple de cette étude de cas. Elle montre comment Hugging Face a utilisé Node.js pour multiplier par deux les performances de son modèle de traitement du langage naturel.
Maintenant que vous connaissez les principes de base de TensorFlow.js, où il peut s'exécuter et certains des avantages qu'il offre, nous allons commencer à l'utiliser.
3. Modèles pré-entraînés
Pourquoi utiliser un modèle pré-entraîné ?
Commencer un modèle populaire pré-entraîné convient particulièrement bien à votre cas d'utilisation souhaité, notamment:
- Nul besoin de rassembler des données d'entraînement vous-même. Préparer les données au bon format et les attribuer à un système de machine learning (apprentissage automatique) peut être très long et coûteux.
- Possibilité de prototyper rapidement une idée en réduisant les coûts et le temps.
Il n'est pas nécessaire de "réinventer la roue" lorsqu'un modèle pré-entraîné peut suffire à faire ce dont vous avez besoin, ce qui vous permet de vous concentrer sur les connaissances fournies par le modèle pour implémenter vos idées de créations. dans le menu déroulant ; - Utilisation de recherches de pointe Les modèles pré-entraînés s'appuient souvent sur des recherches populaires, ce qui vous permet de découvrir de tels modèles tout en analysant leurs performances réelles.
- Simplicité d'utilisation et documentation complète en raison de la popularité de ces modèles.
- Fonctionnalités d'apprentissage par transfert. Certains modèles pré-entraînés proposent des fonctionnalités d'apprentissage par transfert, c'est-à-dire principalement la pratique qui consiste à transférer les informations apprises d'une tâche de machine learning à un autre. Par exemple, un modèle entraîné à reconnaître des chats peut être entraîné à reconnaître de nouveau des chiens, si vous lui avez fourni de nouvelles données d'entraînement. Cela sera plus rapide, car vous ne pourrez pas utiliser une toile vierge. Le modèle peut exploiter ce qu'il a déjà appris pour reconnaître les chats et reconnaître la nouvelle chose. Les chiens ont également les yeux et les oreilles, et ils savent déjà comment trouver ces caractéristiques. Réentraînez le modèle sur vos propres données de façon beaucoup plus rapide.
Modèle pré-entraîné de détection du spam pour les commentaires
Vous utiliserez l'architecture de modèle de représentation vectorielle continue de mots pour vos besoins de détection de spam dans les commentaires. Toutefois, si vous utilisez un modèle non entraîné, il ne sera pas plus difficile d'estimer de façon aléatoire si les phrases sont du spam ou non.
Pour rendre le modèle utile, il doit être entraîné avec des données personnalisées. Dans ce cas, il lui permettra de déterminer à quoi ressemble le spam par rapport aux autres. Ces informations leur permettront alors de mieux classer les produits.
Heureusement, quelqu'un a déjà entraîné cette architecture de modèle exacte pour cette tâche de classification du spam dans les commentaires. Vous pouvez donc l'utiliser comme point de départ. Vous trouverez peut-être d'autres modèles pré-entraînés dans une même architecture pour effectuer différentes actions, comme détecter la langue dans laquelle un commentaire a été rédigé ou déterminer si les données du formulaire de contact du site Web doivent être redirigées automatiquement vers une équipe spécifique en fonction du texte écrit. Par exemple : ventes (demande de produits) ou ingénierie (bugs ou commentaires techniques). Avec suffisamment de données d'entraînement, un modèle comme celui-ci peut apprendre à classifier ce texte dans chaque cas afin d'exploiter les superpouvoirs de votre application Web et d'améliorer l'efficacité de votre organisation.
Dans un atelier de programmation à venir, vous apprendrez à utiliser Model Maker pour réentraîner ce modèle de spam pré-entraîné afin d'améliorer encore les performances de vos données. Pour le moment, vous devez d'abord utiliser le modèle existant de détection des spams pour les commentaires afin de faire fonctionner l'application Web initiale en tant que premier prototype.
Ce modèle pré-entraîné de détection du spam dans les commentaires a été publié sur un site Web appelé TF Hub, un dépôt de modèles de machine learning géré par Google dans lequel les ingénieurs en ML peuvent publier des modèles préconçus pour de nombreux cas d'utilisation courants. (texte, vision, son, etc. pour des cas d'utilisation spécifiques de chacune de ces catégories). Pour le moment, téléchargez les fichiers de modèle pour les utiliser dans l'application Web.
Cliquez sur le bouton de téléchargement du modèle JavaScript, comme indiqué ci-dessous:

4. Configurer le code
Prérequis
- Un navigateur Web moderne
- Connaissances de base en HTML, CSS, JavaScript et dans les Outils pour les développeurs Chrome (affichage des résultats de la console)
Passons au codage.
Pour commencer, vous pouvez créer un modèle Glitch.com Express.js standard à partir duquel vous pouvez simplement cloner l'état de base de cet atelier de programmation en un seul clic.
Dans Glitch, cliquez simplement sur le bouton remixer pour le dupliquer et créer un ensemble de fichiers modifiables.
Ce squelette très simple nous fournit les fichiers suivants dans le dossier www:
- Page HTML (index.html)
- Feuille de style (style.css)
- Fichier d'écriture de notre code JavaScript (script.js)
Pour plus de commodité, nous avons également ajouté dans le fichier HTML une importation pour la bibliothèque TensorFlow.js, qui se présente comme suit:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
Nous diffusons ensuite ce dossier www via un serveur Node Express simple via package.json et server.js.
5. Plaquette HTML pour application
Point de départ
Tous les prototypes nécessitent un échafaudage HTML de base sur lequel vous pouvez effectuer votre rendu. Configurez-le maintenant. Vous allez ajouter les éléments suivants:
- Titre de la page
- Texte descriptif
- Vidéo d'espace réservé représentant l'entrée du blog vidéo
- Zone d'affichage et de saisie des commentaires
Ouvrez index.html et collez le code existant avec les éléments suivants pour configurer les fonctionnalités ci-dessus:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Elles sont réparties
Examinons une partie du code HTML ci-dessus afin de mettre en évidence les éléments clés que vous avez ajoutés.
- Vous avez ajouté une balise
<h1>pour le titre de la page, ainsi qu'une balise<a>pour le bouton de connexion dans la<header>. Vous avez ensuite ajouté un<h2>pour le titre de l'article et une balise<p>pour la description de la vidéo. Rien de spécial ici. - Vous avez ajouté une balise
iframequi intègre une vidéo YouTube arbitraire. Pour le moment, vous utilisez le puissant rap TensorFlow.js comme espace réservé, mais vous pouvez ajouter n'importe quelle vidéo ici en modifiant l'URL du composant iFrame. Sur un site Web de production, toutes ces valeurs s'affichent de façon dynamique par le backend, en fonction de la page consultée. - Enfin, vous avez ajouté
sectionavec un ID et une classe "comments" contenant undivpour rédiger de nouveaux commentaires avec unbuttonpour envoyer le nouveau commentaire à ajouter, ainsi qu'une liste de commentaires non classés. Vous disposez du nom d'utilisateur et de l'heure de publication dans une balisespanau sein de chaque élément de liste, puis pour le commentaire lui-même dans une balisep. Pour le moment, deux exemples de commentaires sont codés en dur comme espaces réservés.
Si vous prévisualisez le résultat maintenant, il devrait ressembler à ceci:
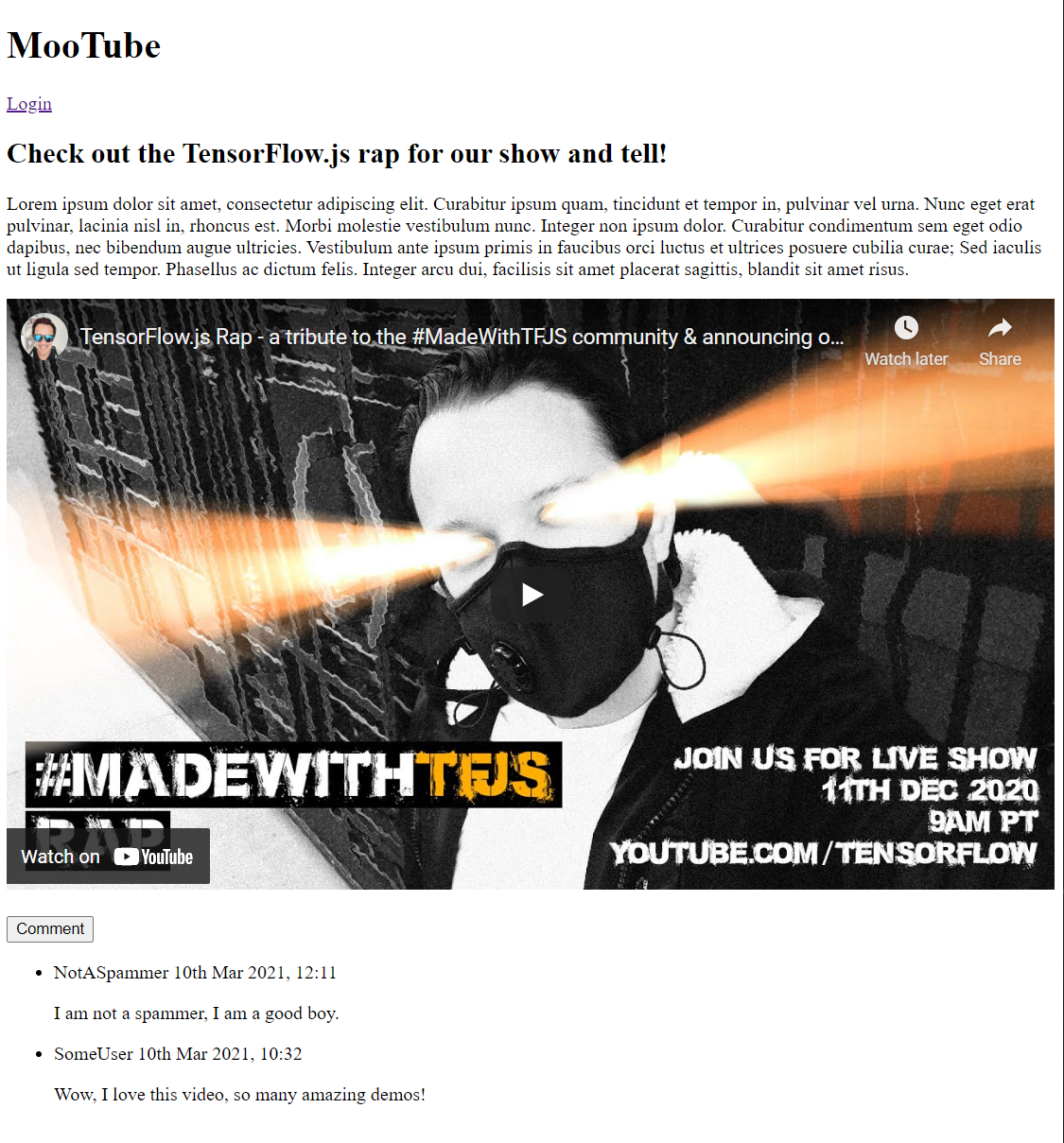
Très bien, il est temps d'ajouter quelques styles...
6. Ajouter style
Paramètres par défaut de l'élément
Tout d'abord, ajoutez des styles pour les éléments HTML que vous venez d'ajouter afin de vous assurer qu'ils s'affichent correctement.
Commencez par appliquer une réinitialisation CSS pour créer un point de départ pour tous les navigateurs et OS. Remplacez le contenu style.css par ce qui suit:
style.css.
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
Ensuite, ajoutez le code CSS utile pour donner vie à l'interface utilisateur.
Ajoutez ce qui suit à la fin de style.css sous le code CSS de réinitialisation que vous avez ajouté ci-dessus:
style.css.
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
Parfait. C'est tout ce dont vous avez besoin. Si vos styles ont été remplacés à l'aide des deux extraits de code ci-dessus, votre aperçu en direct devrait maintenant se présenter comme suit:
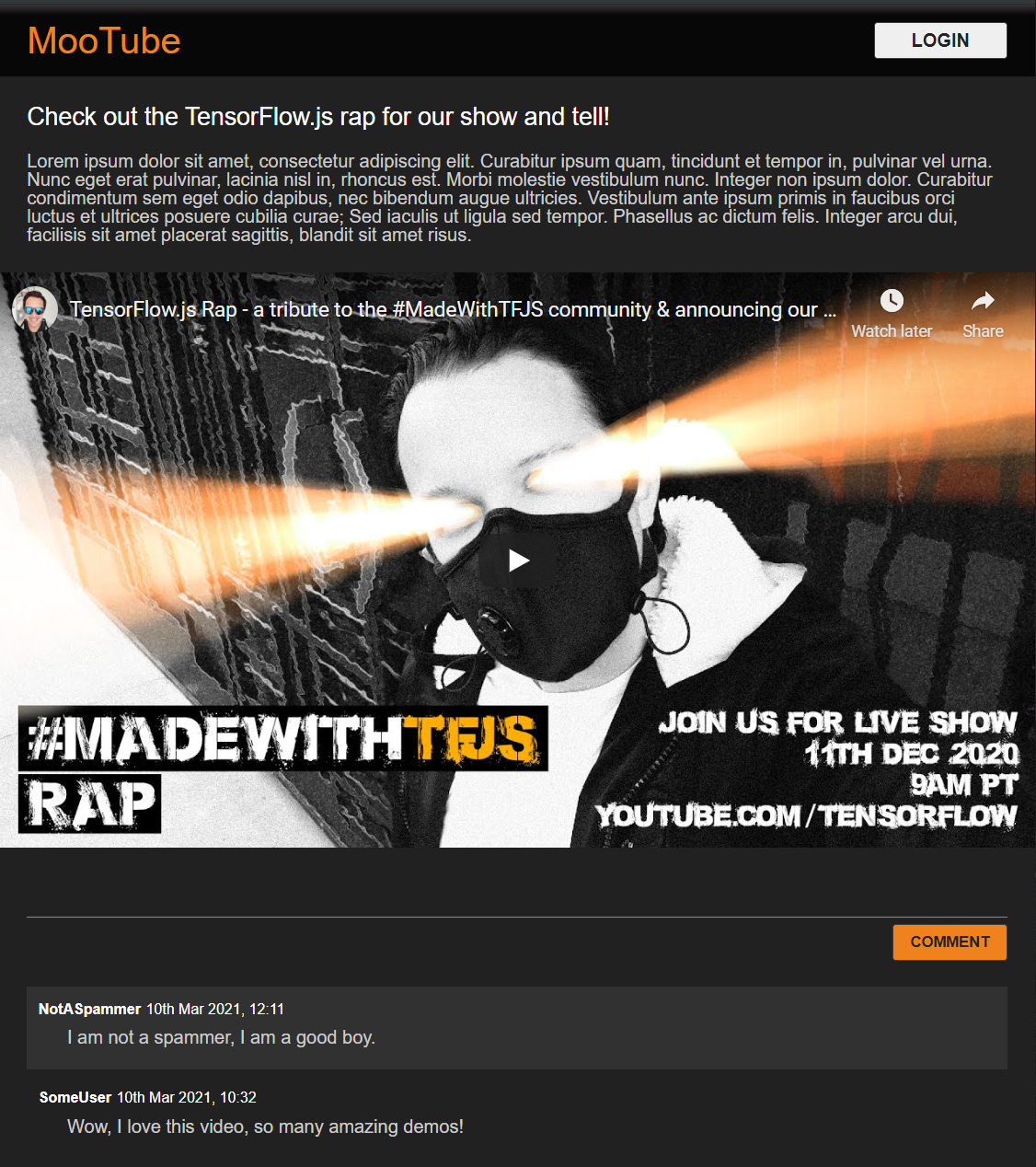
Découvrez le mode Nuit par défaut et les transitions CSS pittoresques pour les effets de survol sur les éléments clés. Ça se présente bien. Intégrer une logique comportementale à l'aide de JavaScript
7. JavaScript: manipulation du DOM et gestionnaires d'événements
Référencer des éléments DOM principaux
Tout d'abord, assurez-vous d'avoir accès aux sections clés de la page, que vous devrez manipuler ou accéder plus tard dans le code, et en définissant des constantes de classe CSS pour la mise en forme.
Commencez par remplacer le contenu du fichier script.js par les constantes suivantes:
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
Gérer la publication de commentaires
Ajoutez ensuite un écouteur d'événements et une fonction de traitement à la POST_COMMENT_BTN pour qu'il puisse récupérer le texte du commentaire écrit et définir une classe CSS pour indiquer que le traitement a commencé. Notez que vous n'avez pas encore cliqué sur le bouton dans le cas où le traitement est déjà en cours.
script
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
Parfait. Si vous actualisez la page Web et essayez de publier un commentaire, le bouton de commentaire et le texte doivent s'afficher en nuances de gris. Dans la console, le commentaire doit ressembler à ceci:
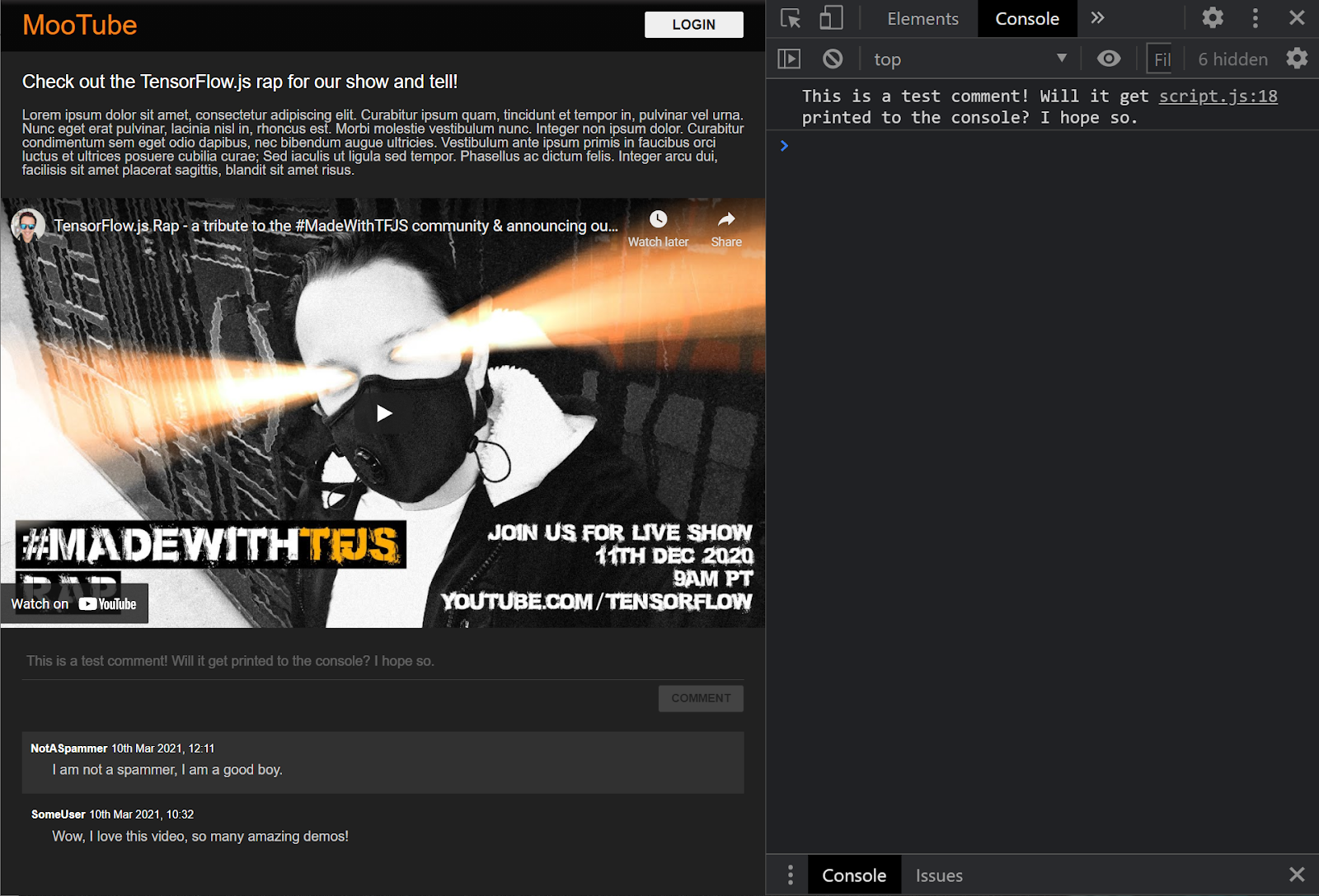
Vous disposez maintenant d'un squelette HTML / CSS / JS de base. Il est temps de revenir au modèle de machine learning afin de l'intégrer à la superbe page Web.
8. Diffuser le modèle de machine learning
Vous êtes presque prêt à charger le modèle. Avant cela, vous devez importer les fichiers modèles téléchargés précédemment dans l'atelier de programmation sur votre site Web. Ils sont ensuite hébergés et utilisables dans le code.
Commencez par décompresser les fichiers que vous avez téléchargés pour le modèle au début de cet atelier de programmation, si vous ne l'avez pas déjà fait. Un répertoire contenant les fichiers suivants doit s'afficher:
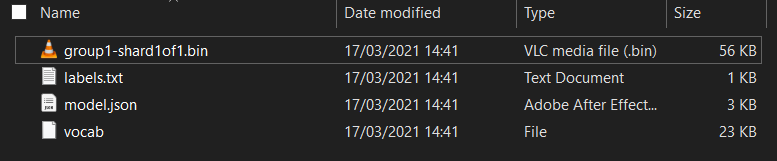
Qu'est-ce que vous avez ici ?
model.json: il s'agit de l'un des fichiers qui composent le modèle TensorFlow.js entraîné. Vous aurez besoin de consulter ce fichier plus tard dans votre code TensorFlow.js.group1-shard1of1.bin: il s'agit d'un fichier binaire contenant les pondérations entraînées (en d'autres termes, un groupe de nombres apprenant à faire correctement la tâche de classification) du modèle TensorFlow.js. Il devra être hébergé sur votre serveur pour le téléchargement.vocab: ce fichier étrange sans extension, provenant de Model Maker, nous montre comment encoder des mots dans les phrases pour que le modèle comprenne comment les utiliser. Vous aborderez ces points plus en détail dans la section suivante.labels.txt: contient uniquement les noms de classes prédits par le modèle. Pour ce modèle, si vous ouvrez ce fichier dans votre éditeur de texte, il indique simplement "false" et "true", indiquant "not spam" ou "spam" comme résultat de prédiction.
Héberger les fichiers de modèle TensorFlow.js
D'abord, placez model.json et les fichiers *.bin générés sur un serveur Web pour pouvoir y accéder via la page Web.
Importer des fichiers dans Glitch
- Cliquez sur le dossier assets dans le panneau de gauche de votre projet Glitch.
- Cliquez sur Importer un élément et sélectionnez
group1-shard1of1.binà importer dans ce dossier. Elle doit se présenter comme suit une fois l'importation effectuée:
- Parfait. Procédez de la même manière pour le fichier
model.json. Vous devez placer deux fichiers dans le dossier assets de la manière suivante:
- Cliquez sur le fichier
group1-shard1of1.binque vous venez d'importer. Vous pourrez copier l'URL à son emplacement. Copiez ce chemin d'accès comme indiqué ci-dessous:

- En bas à gauche de l'écran, cliquez sur Tools > Terminal (Outils > Terminal). Attendez que la fenêtre de terminal se charge. Une fois le fichier chargé, saisissez la commande suivante, puis appuyez sur Entrée pour passer au répertoire
www:
terminal:
cd www
- Ensuite, utilisez
wgetpour télécharger les deux fichiers que vous venez d'importer en remplaçant les URL ci-dessous par les URL des fichiers figurant dans le dossier assets sur Glitch (vérifiez le dossier des éléments pour l'URL personnalisée de chaque fichier). ). Notez que l'espace entre les deux URL et que les URL que vous devrez utiliser sera différent de celles ci-dessous, mais qu'elles ressembleront à ceci:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Super. Vous avez maintenant créé une copie des fichiers importés dans le dossier www. Cependant, ils sont actuellement téléchargés et portent des noms étranges.
- Saisissez
lsdans le terminal, puis appuyez sur Entrée. Le résultat qui s'affiche doit ressembler à ceci :

- La commande
mvvous permet de renommer les fichiers. Saisissez ce qui suit dans la console et appuyez sur <kbd>Entrée</kbd> ou <kbd>Retour</kbd>, après chaque ligne:
terminal :
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Enfin, actualisez le projet Glitch en saisissant
refreshdans le terminal, puis en appuyant sur <kbd>Entrée</kbd>:
terminal :
refresh
- Après l'actualisation, vous devriez voir
model.jsonetgroup1-shard1of1.bindans le dossierwwwde l'interface utilisateur:
Parfait. Vous êtes maintenant prêt à utiliser les fichiers de modèle importés avec du code dans le navigateur.
9. Charger et utiliser le modèle TensorFlow.js hébergé
Vous pouvez à présent tester le chargement du modèle TensorFlow.js importé avec des données pour vérifier s'il fonctionne.
À l'heure actuelle, l'exemple de données d'entrée que vous verrez ci-dessous vous semblera plutôt mystérieux (un tableau de nombres) et nous vous expliquerons comment il a été généré dans la section suivante. Pour l'instant, il s'agit simplement d'un tableau de nombres. À ce stade, il est important de tester simplement que le modèle nous fournit une réponse sans erreur.
Ajoutez le code suivant à la fin de votre fichier script.js, en veillant à remplacer la valeur de chaîne MODEL_JSON_URL par le chemin d'accès au fichier model.json généré lorsque vous avez importé le fichier dans le dossier des éléments Glitch : à l'étape précédente. N'oubliez pas que vous pouvez simplement cliquer sur le fichier situé dans le dossier assets de Glitch pour trouver son URL.
Lisez les commentaires du nouveau code ci-dessous pour comprendre l'action de chaque ligne:
script
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
Si le projet est correctement configuré, vous devriez maintenant voir ce qui suit affiché dans la fenêtre de la console. Lorsque vous utilisez le modèle que vous avez chargé pour prédire un résultat à partir de l'entrée qui lui a été envoyée:
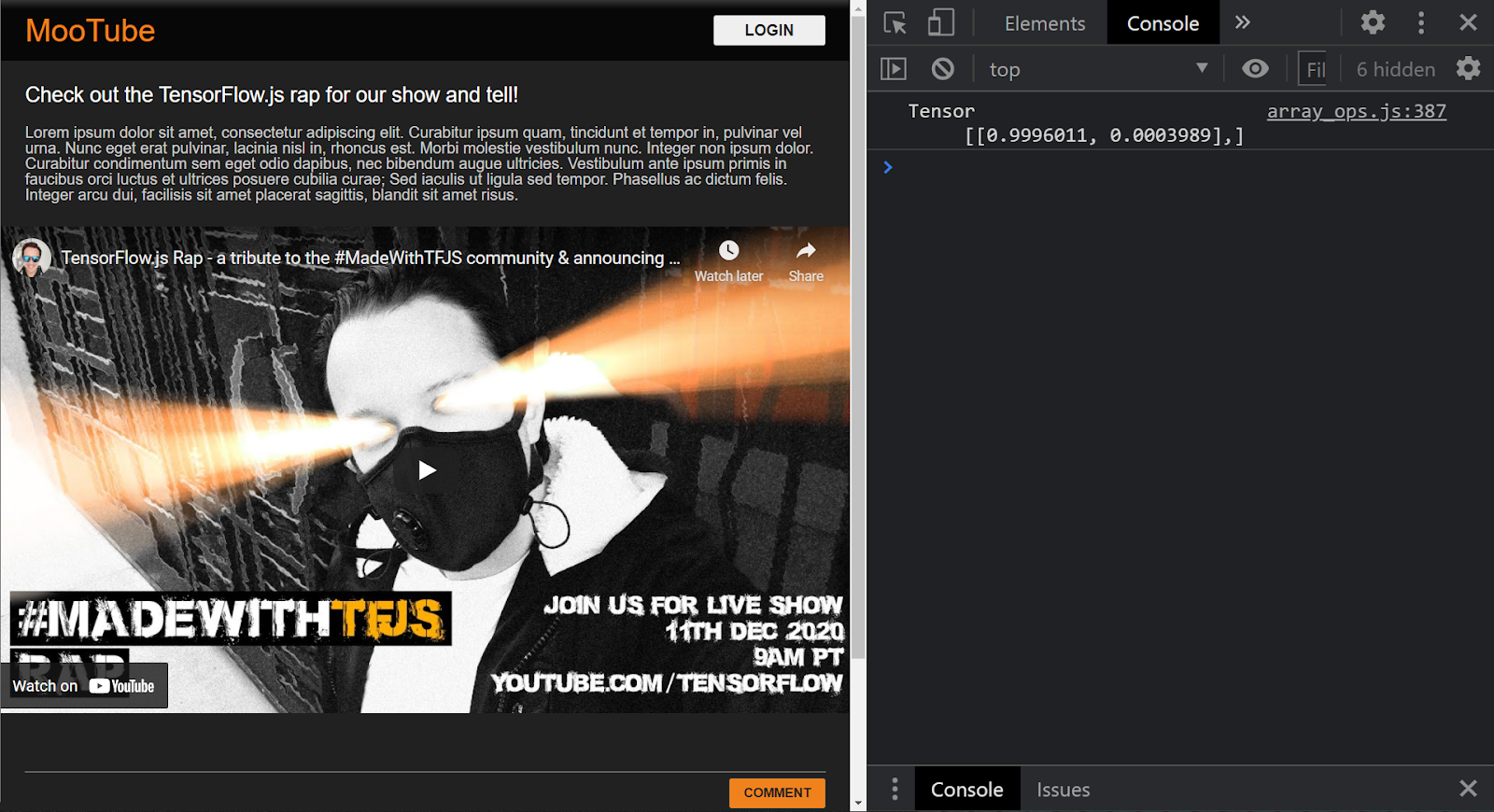
Dans la console, deux numéros sont affichés:
- 0,9996011
- 0,0003989
Même si ces données peuvent sembler complexes, ces chiffres représentent en fait les probabilités que le modèle pense que la classification correspond à l'entrée que vous avez fournie. Mais que représentent-elles ?
Si vous ouvrez votre fichier labels.txt à partir des fichiers de modèle téléchargés sur votre ordinateur local, il comprend également deux champs:
- Faux
- Vrai
Dans ce cas, le modèle indique99,96011% Assurez-vous que l'objet de résultat que vous avez saisi (affiché dans l'objet 0,9996011) (ce qui correspond à[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] étaitPAS de spam (par exemple, "Faux").
Remarque : La valeur false est la première étiquette de labels.txt et est représentée par la première sortie dans l'impression de la console. Cela vous permet de savoir à quoi correspond la prédiction de sortie.
Vous savez maintenant comment interpréter le résultat, mais quel est exactement l'ensemble de chiffres indiqués en entrée ? Comment convertir les phrases dans ce format pour que le modèle les utilise ? Pour cela, vous devez en savoir plus sur la segmentation et les Tensors. Lisez la suite.
10. Tensors et Tensors
Tokenisation
Il s'avère donc que les modèles de machine learning n'acceptent que de nombreux nombres en tant qu'entrées. Pourquoi ? En fait, c'est parce qu'un modèle de machine learning est un ensemble d'opérations mathématiques enchaînées. Si vous lui transmettez un nombre qui n'est pas un nombre, vous aurez du mal à le traiter. Maintenant, la question est de savoir comment convertir les phrases en chiffres à utiliser avec le modèle que vous avez chargé.
Le processus exact varie d'un modèle à l'autre, mais pour celui-ci, un autre fichier (vocab,) est disponible dans les fichiers modèles. C'est la clé de la façon dont vous encodez les données.
Ouvrez vocab dans un éditeur de texte local sur votre ordinateur. Vous devriez obtenir le résultat suivant:
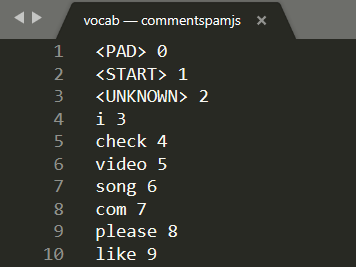
Il s'agit essentiellement d'un tableau de conversion expliquant comment convertir les mots importants que le modèle a appris en chiffres qu'il peut interpréter. Vous trouverez également des cas particuliers en haut du fichier <PAD>, <START> et <UNKNOWN>:
<PAD>: l'acronyme de "padding" est utilisé. Les modèles de machine learning ont un nombre fixe d'entrées, quelle que soit la durée de votre phrase. Le modèle utilisé attend toujours 20 nombres pour l'entrée (défini par le créateur du modèle et peut être modifié si vous le réentraînez). Par exemple, si vous disposez d'une expression comme "J'aime la vidéo", vous devez remplacer les espaces restants du tableau par des zéros qui représentent le jeton<PAD>. Si la phrase contient plus de 20 mots, vous devez la scinder, pour répondre à cette exigence. Utilisez plutôt plusieurs classifications sur de nombreuses phrases plus petites.<START>: il s'agit simplement du premier jeton pour indiquer le début de la phrase. Vous remarquerez que, dans l'exemple d'entrée aux étapes précédentes, le tableau de nombres a commencé par un "1", ce qui représentait le jeton<START>.<UNKNOWN>: Comme vous pouvez l'imaginer, si le mot n'existe pas dans cette recherche de mots, vous utilisez simplement le jeton<UNKNOWN>(représenté par un "2") comme nombre.
Pour tous les autres mots, elle existe soit dans la recherche, soit elle est associée à un numéro spécial. Vous pouvez donc l'utiliser, ou elle n'existe pas. Dans ce cas, vous devez utiliser le numéro de jeton <UNKNOWN>.
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
Vous pouvez voir qu'il s'agit d'une phrase contenant quatre mots, car les autres sont des jetons <START> ou <PAD> et que le tableau contient 20 chiffres. OK, nous commençons à faire un peu plus de sens.
La phrase que j'ai écrit à ce sujet était "J'aime mon chien". La capture d'écran ci-dessus montre que "I" est converti en nombre "3", ce qui est correct. Si vous recherchez les autres mots, vous trouverez les numéros correspondants.
Tensors
Il y a un obstacle final avant que le modèle de ML n'accepte votre entrée numérique. Vous devez convertir le tableau de nombres en un Tensor, et oui, vous l'aurez deviné, TensorFlow porte le nom de ces éléments : le flux de Tensors à travers un modèle.
Qu'est-ce qu'un Tensor ?
Voici la définition officielle de TensorFlow.org:
"Les Tensors sont des tableaux multidimensionnels de type uniforme. Tous les Tensors sont immuables: vous ne pouvez jamais mettre à jour le contenu d'un Tensor, mais seulement en créer un."
En anglais, il s'agit simplement d'un nom mathématique sophistiqué pour un tableau de toute dimension comportant d'autres fonctions intégrées à l'objet Tensor utiles pour les développeurs en machine learning. Notez que les Tensors stockent uniquement des données de type 1, par exemple tous les nombres entiers ou nombres à virgule flottante, et une fois créé, vous ne pouvez plus modifier le contenu d'un Tensor.Vous pouvez donc le considérer comme une zone de stockage permanente pour les nombres.
Ne vous inquiétez pas trop pour l'instant. Considérez tout au moins qu'il s'agit d'un mécanisme de stockage multidimensionnel avec lequel les modèles de machine learning fonctionnent, jusqu'à ce que vous compreniez un bon livre comme celui-ci. Nous vous le conseillons vivement pour en savoir plus sur les Tensors. et leur utilisation.
Regrouper tous les Tensors et la jetonisation
Comment utiliser ce fichier vocab dans le code ? Bonne question.
Ce fichier à lui tout seul n'a aucun intérêt pour les développeurs JS. Il serait beaucoup plus efficace s'il s'agissait d'un objet JavaScript que vous pourriez simplement importer et utiliser. Comme vous pouvez le constater, il peut être très simple de convertir les données de ce fichier vers un format plus semblable à celui-ci:
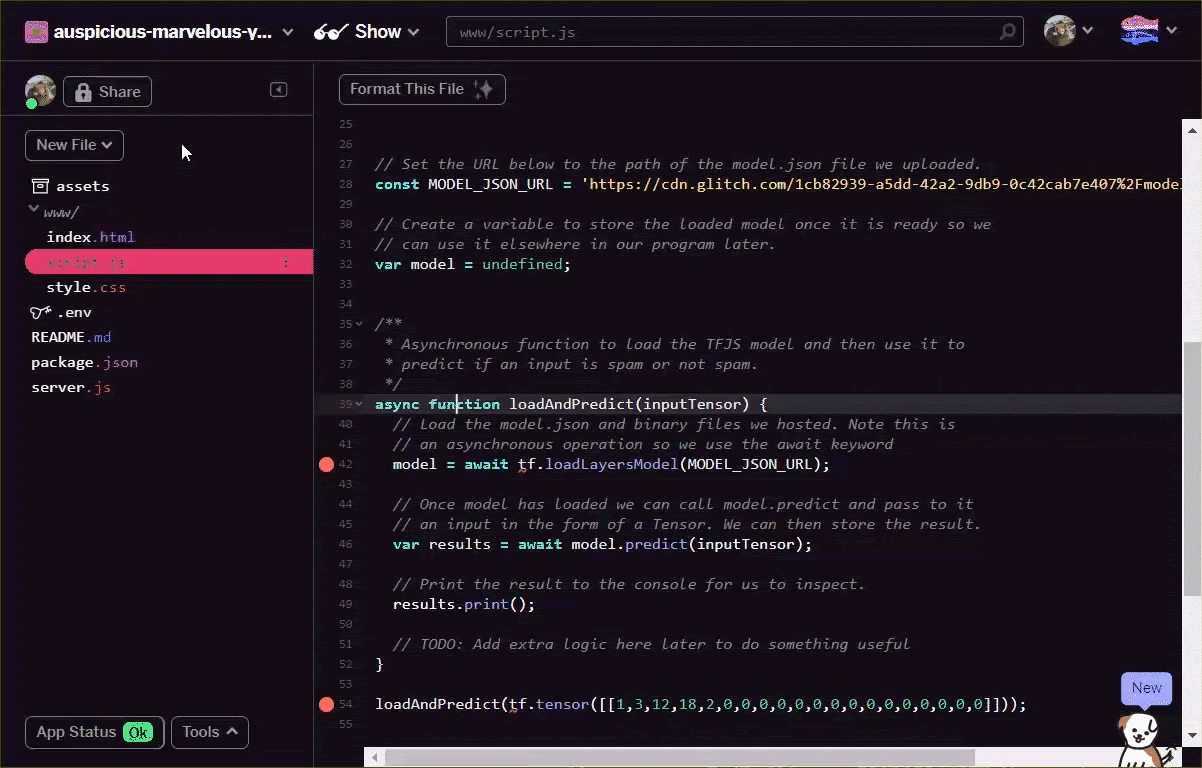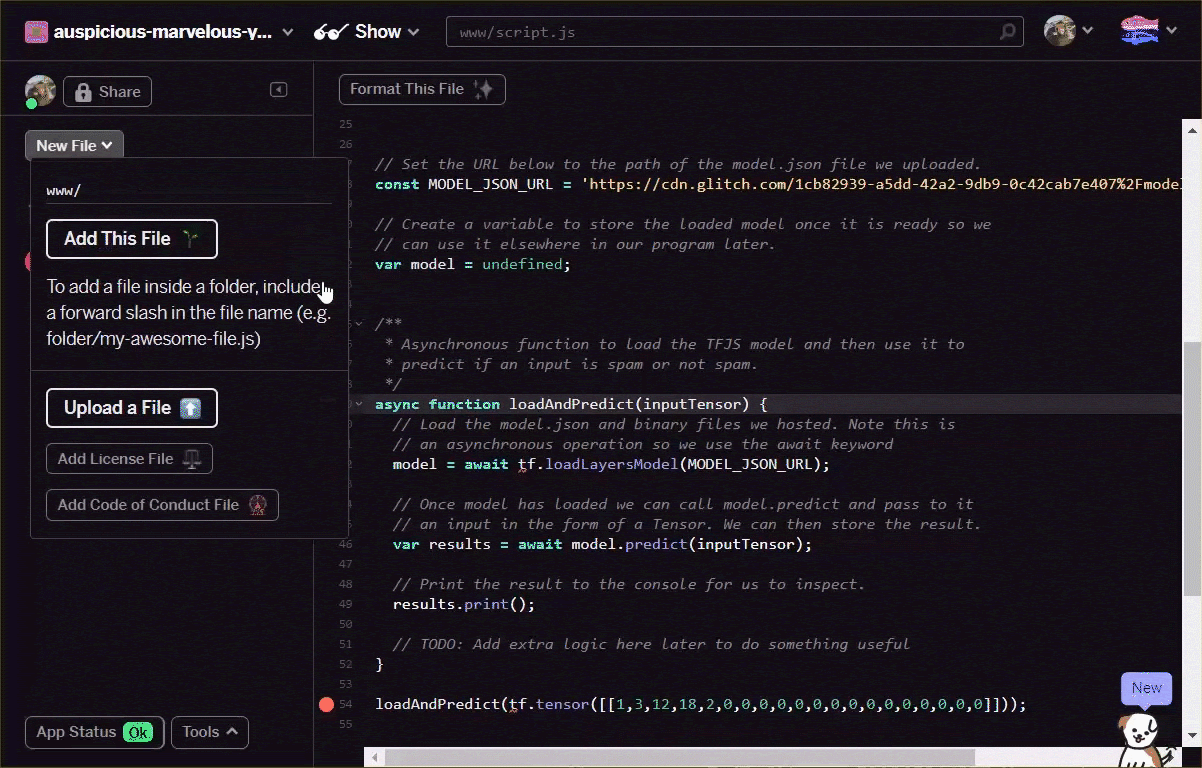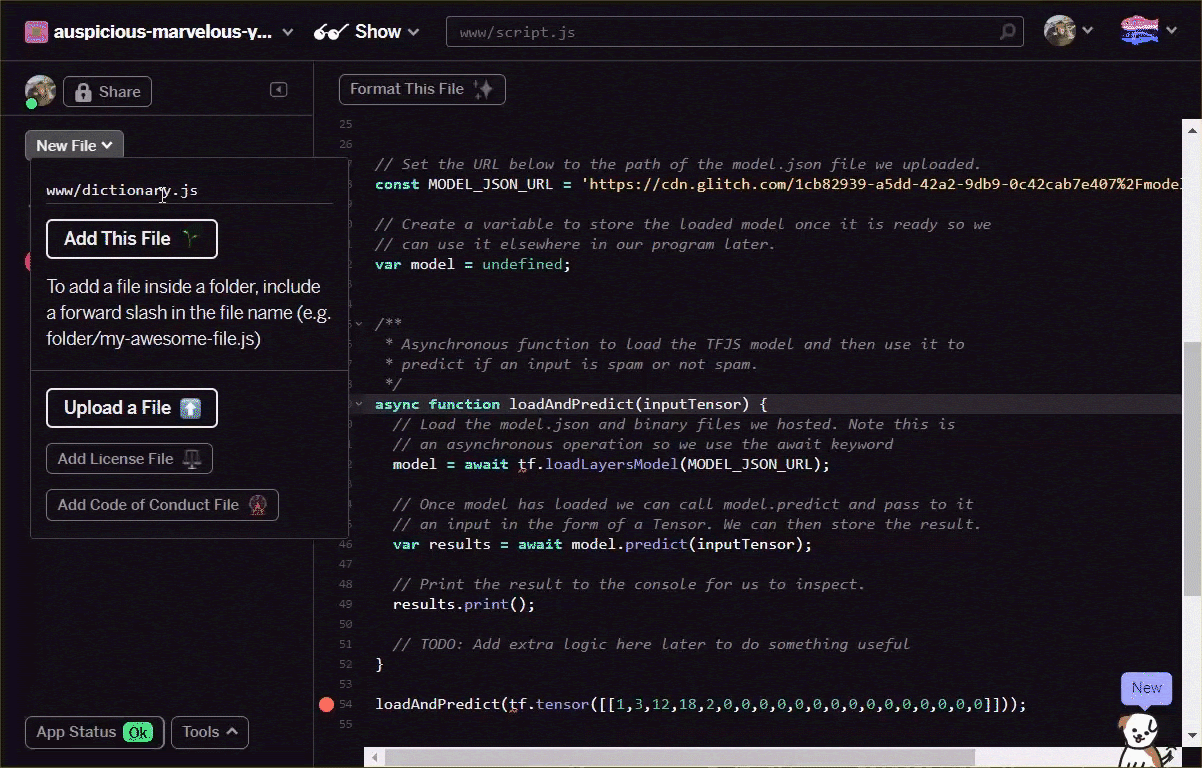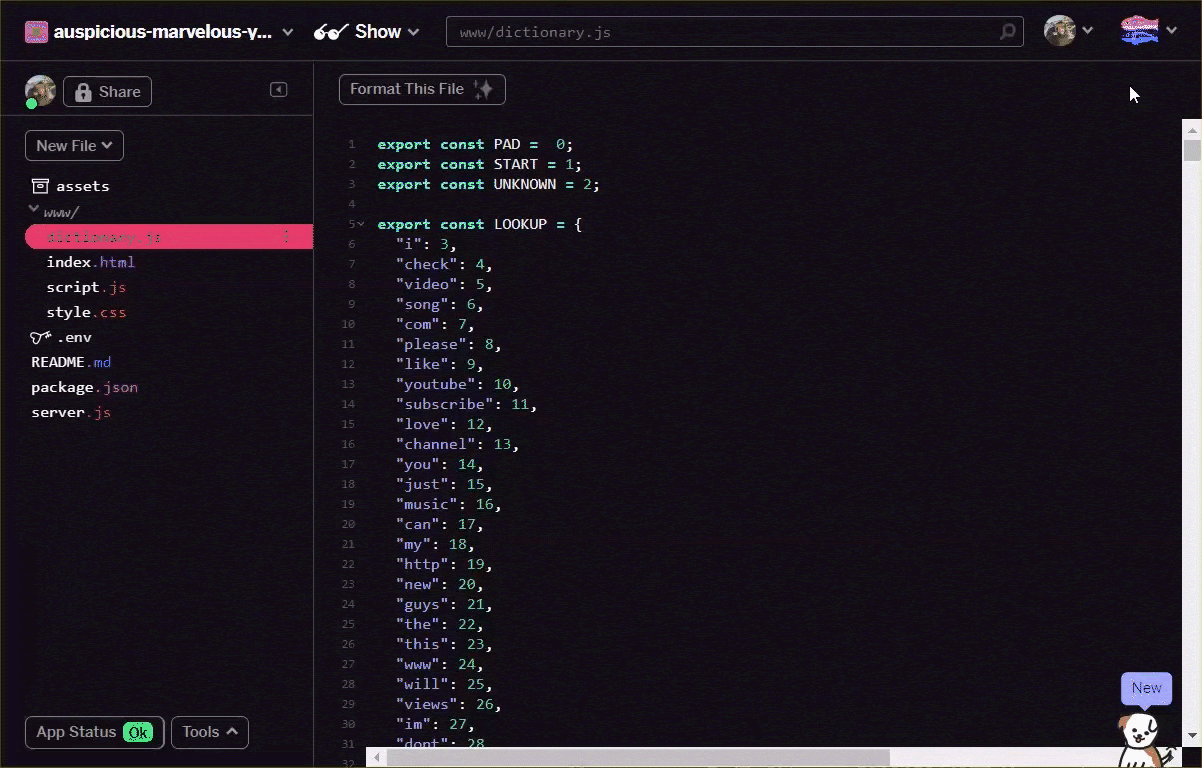
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
En utilisant votre éditeur de texte préféré, vous pouvez facilement transformer le fichier vocab dans un format tel que la recherche et le remplacement. Vous pouvez également utiliser cet outil prédéfini pour simplifier cette procédure.
En effectuant cette opération à l'avance et en enregistrant le format de fichier vocab au bon format, vous ne pouvez pas effectuer cette conversion ni l'analyser à chaque chargement de page, ce qui représente un gaspillage des ressources du processeur. Mieux encore, les objets JavaScript ont les propriétés suivantes:
"Un nom de propriété d'objet peut être n'importe quelle chaîne JavaScript valide ou tout élément pouvant être converti en chaîne, y compris la chaîne vide. Toutefois, tous les noms de propriété qui ne sont pas des identifiants JavaScript valides (par exemple, un nom de propriété comportant un espace ou un trait d'union ou commençant par un nombre) ne sont accessibles qu'à l'aide de la notation entre crochets.
Ainsi, tant que vous utilisez la notation entre crochets, vous pouvez créer un tableau de conversion plutôt efficace grâce à cette transformation simple.
Convertir un fichier dans un format plus utile
Convertissez votre fichier vocabulaire au format ci-dessus, soit manuellement via votre éditeur de texte, soit en utilisant cet outil. Enregistrez la sortie obtenue dans le dossier www sous la forme dictionary.js.
Dans Glitch, vous pouvez simplement créer un fichier à cet emplacement, puis coller le résultat de votre conversion pour l'enregistrer comme indiqué:
Une fois que vous avez enregistré un fichier dictionary.js au format décrit ci-dessus, vous pouvez ajouter le code suivant tout en haut de script.js pour importer le module dictionary.js que vous venez d'écrire. Vous allez également définir une constante ENCODING_LENGTH supplémentaire pour savoir combien de texte utiliser dans la suite, ainsi qu'une fonction tokenize vous permettant de convertir un tableau de mots en Tensor compatible qui peut être utilisé comme une entrée au modèle.
Consultez les commentaires dans le code ci-dessous pour en savoir plus sur les opérations de chaque ligne:
script
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
Maintenant, revenez à la fonction handleCommentPost() et remplacez-la par cette nouvelle version.
Consultez le code pour connaître le commentaire que vous avez ajouté:
script
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
Enfin, mettez à jour la fonction loadAndPredict() pour définir un style si un commentaire est détecté comme spam.
Pour le moment, vous pouvez simplement modifier le style. Cependant, vous pourrez choisir plus tard de mettre le commentaire en attente dans une file d'attente de modération ou de ne plus l'envoyer.
script
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. Mises à jour en temps réel: Node.js + Websockets
Vous disposez à présent d'une interface qui fonctionne avec la détection de spam. La dernière étape consiste à utiliser Node.js avec des Websockets pour communiquer en temps réel et mettre à jour en temps réel les commentaires ajoutés qui ne sont pas des spams.
Socket.io
Socket.io est l'un des moyens les plus utilisés (au moment de la rédaction) pour utiliser Websockets avec Node.js. Indiquez à Glitch que vous souhaitez inclure la bibliothèque Socket.io dans le build en modifiant le répertoire package.json dans le répertoire racine (dans le dossier parent du dossier www) pour inclure socket.io en tant que dépendance. :
. JSON
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
Parfait. Après la mise à jour, mettez à jour index.html dans le dossier www pour inclure la bibliothèque socket.io.
Placez simplement cette ligne de code au-dessus de l'importation de la balise de script HTML pour script.js à la fin du fichier index.html:
index.html
<script src="/socket.io/socket.io.js"></script>
Votre fichier index.html doit contenir trois balises de script:
- la première importation de la bibliothèque TensorFlow.js
- La deuxième importation de socket.io que vous venez d'ajouter
- Le dernier doit importer le code script.js.
Modifiez ensuite server.js pour configurer socket.io dans le nœud et créez un backend simple pour transmettre les messages reçus à tous les clients connectés.
Consultez les commentaires ci-dessous pour en savoir plus sur les opérations du code Node.js:
server.js
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
Parfait. Vous disposez maintenant d'un serveur Web qui écoute les événements socket.io. Par exemple, vous avez un événement comment lorsqu'un nouveau commentaire provient d'un client et que le serveur émet des événements remoteComment que le code côté client écoute pour afficher un commentaire à distance. La dernière étape consiste à ajouter la logique socket.io au code côté client pour émettre et gérer ces événements.
Tout d'abord, ajoutez le code suivant à la fin de script.js pour vous connecter au serveur socket.io et écouter / gérer les événements RemoteComment:
script
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
Enfin, ajoutez du code à la fonction loadAndPredict pour émettre un événement socket.io si un commentaire n'est pas du spam. Cela vous permet de mettre à jour les autres clients connectés avec ce nouveau commentaire, car le contenu de ce message leur sera transmis via le code server.js que vous avez écrit ci-dessus.
Remplacez simplement votre fonction loadAndPredict existante par le code suivant, qui ajoute une instruction else à la vérification antispam finale. Si le commentaire n'est pas du spam, vous appelez socket.emit() pour envoyer toutes les données de commentaire:
script
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
Bravo ! Si vous avez correctement suivi les deux étapes, vous devriez maintenant pouvoir ouvrir deux instances de votre page index.html.
Lorsque vous publiez des commentaires qui ne sont pas des spams, ils doivent s'afficher presque instantanément. S'il s'agit d'un spam, il ne sera jamais envoyé et sera marqué comme spam à la place de l'interface qui l'a généré uniquement comme suit:
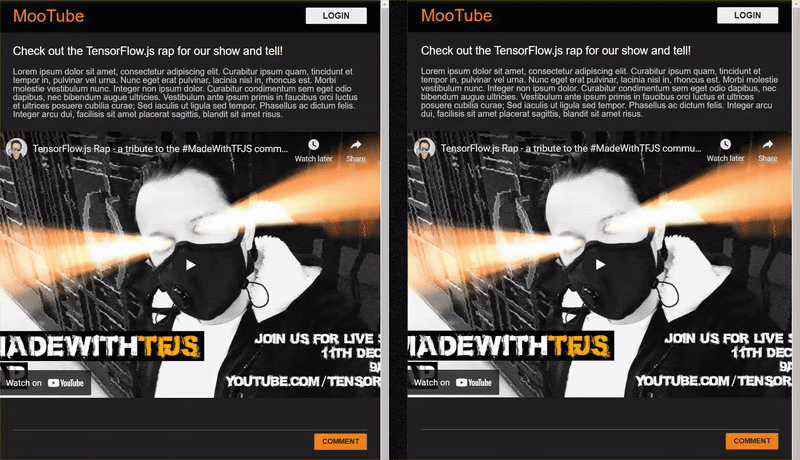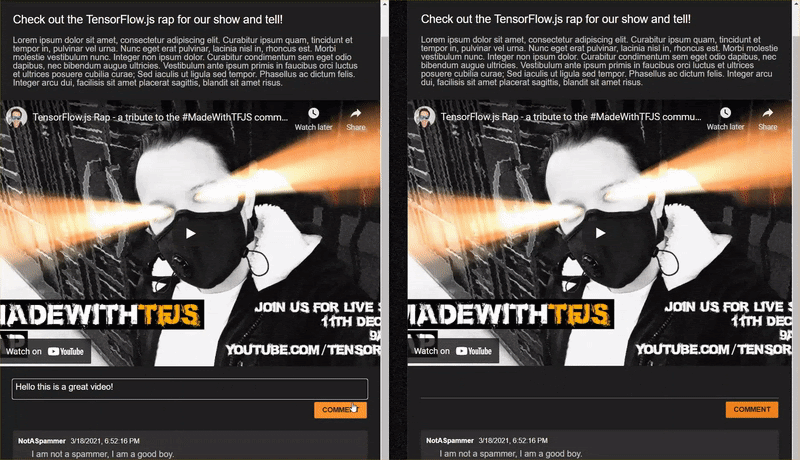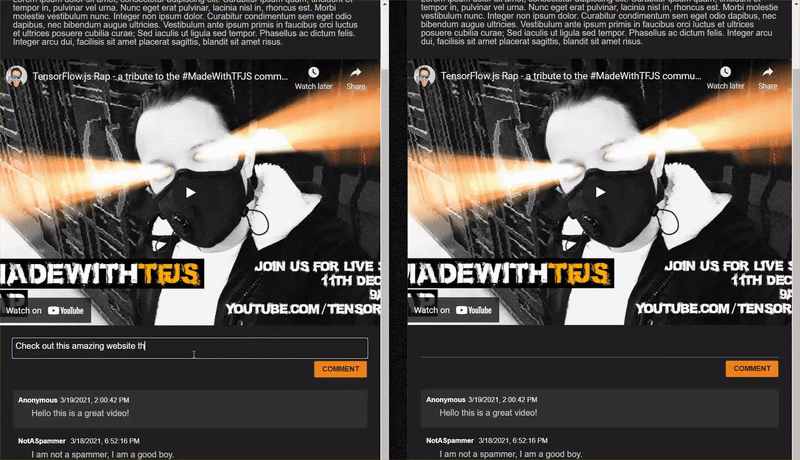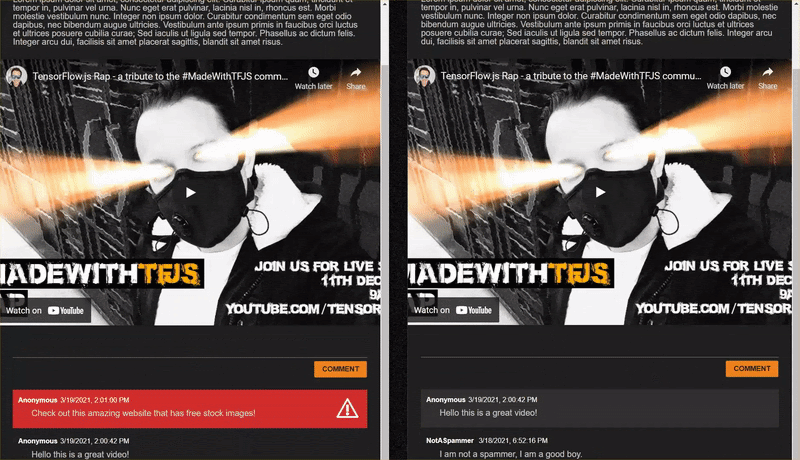
12. Félicitations
Félicitations ! Vous venez de faire vos premiers pas dans l'utilisation du machine learning avec TensorFlow.js dans le navigateur Web d'une application réelle. Vous allez ainsi détecter la présence de spam dans les commentaires.
Essayez-le en testant différents commentaires. Vous remarquerez peut-être que certains problèmes persistent. Vous pouvez également noter que si vous saisissez une phrase de plus de 20 mots, le message échouera pour le moment, car le modèle s'attend à 20 mots en entrée.
Dans ce cas, vous devrez peut-être diviser les longues phrases par groupes de 20 mots, puis tenir compte de la probabilité de spam de chaque sous-phrase pour déterminer si elle doit être affichée ou non. Nous allons laisser cette tâche supplémentaire facultative à tester, car vous pouvez choisir de nombreuses approches à ce sujet.
Dans l'atelier de programmation suivant, nous vous montrerons comment réentraîner ce modèle avec vos données de commentaires personnalisées pour les cas spéciaux qu'il ne détecte pas actuellement, et même pour modifier l'attente d'entrée du modèle afin qu'il puisse gérer les phrases qui comportent plus de 20 mots, puis les exporter et les utiliser avec TensorFlow.js.
Si vous rencontrez des difficultés, comparez votre code à cette version terminée disponible, et vérifiez si vous avez oublié quelque chose.
Résumé
Dans cet atelier de programmation, vous allez:
- Présentation de TensorFlow.js et des modèles de traitement du langage naturel
- Vous avez créé un site Web fictif qui permet de commenter en temps réel un exemple de site Web.
- Chargement d'un modèle de machine learning pré-entraîné pour la détection des spams dans les commentaires via TensorFlow.js sur la page Web.
- Vous avez appris à encoder des phrases à utiliser avec le modèle de machine learning chargé et à encapsuler cet encodage dans un Tensor.
- Interprétation du résultat du modèle de machine learning pour déterminer si vous souhaitez vérifier le commentaire avant son examen et, si ce n'est pas le cas, envoyer au serveur pour le transmettre à d'autres clients connectés en temps réel.
Étape suivante
Maintenant que vous disposez d'une base de travail, quelles idées créatives pouvez-vous mettre en place pour étendre ce modèle de machine learning à un cas d'utilisation concret ?
Partagez vos créations
Vous pouvez facilement étendre vos créations pour d'autres cas d'utilisation créatifs, et nous vous encourageons à sortir du lot et à pirater votre chaîne.
N'oubliez pas de nous taguer sur les réseaux sociaux à l'aide du hashtag #MadeWithTFJS, et votre projet sera peut-être mis en avant sur notre blog TensorFlow ou même événements futurs. Nous serions ravis de découvrir vos créations.
Plus d'ateliers de programmation TensorFlow.js pour aller plus loin
- Découvrez la deuxième partie de cette série pour savoir comment réentraîner le modèle de spam dans les commentaires afin de prendre en compte les cas spéciaux qu'il ne détecte pas comme étant du spam.
- Utilisez l'hébergement Firebase pour déployer et héberger un modèle TensorFlow.js à grande échelle.
- Créer une webcam intelligente à l'aide d'un modèle de détection d'objets prédéfini avec TensorFlow.js
Sites Web à consulter
- Site Web officiel de TensorFlow.js
- Modèles prédéfinis TensorFlow.js
- API TensorFlow.js
- TensorFlow, TensorFlow.js : inspirez-vous et découvrez les créations des autres.