
1. Antes de começar
Na última década, os aplicativos da Web se tornaram cada vez mais sociais e interativos, com suporte para multimídia, comentários e muito mais, tudo em tempo real por meio de dezenas de milhares de pessoas em um site moderadamente popular.
Isso também possibilitou o abuso de tais sistemas pelos criadores de spam e associando conteúdos menos sagrados aos artigos, vídeos e postagens escritos por outras pessoas, para tentar obter mais visibilidade.
Métodos mais antigos de detecção de spam, como uma lista de palavras bloqueadas, podem ser facilmente ignorados e simplesmente não serão correspondências com bots de spam avançados, que estão em constante evolução na complexidade. A partir de hoje, você pode usar modelos de aprendizado de máquina que foram treinados para detectar esse tipo de spam.
Tradicionalmente, a execução de um modelo de machine learning para pré-filtrar comentários seria feita no lado do servidor. Agora, com o TensorFlow.js, é possível executar modelos de machine learning no lado do cliente com o navegador via JavaScript. Você pode parar o spam antes mesmo que ele toque no back-end, economizando recursos caros do servidor.
Como você já deve saber, o machine learning é a tendência atual, abordando quase todos os setores, mas como você pode dar o primeiro passo para usar esses recursos como desenvolvedor da Web?
Este codelab mostrará como criar um app da Web, em uma tela em branco, que lida com o verdadeiro problema do spam de comentários usando o processamento de linguagem natural (a arte de entender a linguagem humana com um computador). Muitos desenvolvedores da Web encontrarão esse problema ao trabalhar em um dos aplicativos da Web cada vez mais usados, e este codelab permitirá que você resolva esses problemas de forma eficiente.
Pré-requisitos
Este codelab foi escrito para desenvolvedores da Web que ainda não conhecem o machine learning e que querem começar a usar modelos pré-treinados com o TensorFlow.js.
Para este laboratório, é preciso ter familiaridade com HTML5, CSS e JavaScript.
O que você aprenderá
Você vai:
- Saiba mais sobre o TensorFlow.js e quais são os modelos disponíveis para processamento de linguagem natural.
- Crie uma página da Web simples em HTML / CSS / JS para um blog de vídeo fictício com uma seção de comentários em tempo real.
- Use o TensorFlow.js para carregar um modelo de machine learning pré-treinado capaz de prever se uma frase inserida provavelmente é spam ou não e, se for o caso, avisar o usuário que o comentário dela está retido para moderação.
- Codifique as frases de comentários de maneira que possam ser usadas pelo modelo de aprendizado de máquina para classificar.
- Interprete o resultado do modelo de machine learning para decidir se quer sinalizar automaticamente o comentário. Essa UX hipotética pode ser reutilizada em qualquer site em que você esteja trabalhando e ser adaptada para qualquer caso de uso do cliente, talvez seja um blog, fórum ou alguma forma de CMS, como o Drupal.
Muito legal. É difícil de fazer? Não. Então, vamos hackear...
Pré-requisitos
- ter uma conta do Glitch.com é preferível para acompanhar, ou você pode usar um ambiente de veiculação na Web com o qual se sinta confortável para editar e executar por conta própria.
2. O que é o TensorFlow.js?

O TensorFlow.js é uma biblioteca de machine learning de código aberto que pode ser executada em qualquer lugar com JavaScript. Ele é baseado na biblioteca original do TensorFlow escrita em Python e tem como objetivo recriar essa experiência do desenvolvedor e um conjunto de APIs para o ecossistema JavaScript.
Onde ele pode ser usado?
Pela portabilidade do JavaScript, agora é possível escrever em uma linguagem e realizar machine learning em todas as plataformas a seguir com facilidade:
- lado do cliente no navegador da Web usando JavaScript simples
- Servidor e até dispositivos de IoT como o Raspberry Pi usando o Node.js
- Apps para computador com o Electron
- Apps nativos para dispositivos móveis usando o React Native
O TensorFlow.js também oferece suporte a vários back-ends em cada um desses ambientes (os ambientes reais de hardware com que ele pode ser executado, por exemplo, a CPU ou a WebGL). Um "back-end" nesse contexto não significa um ambiente do lado do servidor. O back-end para execução pode ser do lado do cliente em WebGL, por exemplo, para garantir a compatibilidade e também manter as coisas funcionando rapidamente. Atualmente, o TensorFlow.js é compatível com o seguinte:
- Execução do WebGL na placa de vídeo do dispositivo (GPU): esta é a maneira mais rápida de executar modelos maiores (com mais de 3 MB) com aceleração de GPU.
- Execução do Web ssembly (WASM) na CPU: para melhorar o desempenho da CPU em dispositivos como os smartphones mais antigos, por exemplo. Isso é mais adequado para modelos menores (menos de 3 MB) que podem ser executados mais rapidamente na CPU com WASM do que com WebGL devido à sobrecarga de fazer upload de conteúdo para um processador gráfico.
- Execução da CPU: o substituto não deve estar disponível em nenhum dos outros ambientes. Esse é o caminho mais lento, mas está sempre disponível para você.
Observação:você poderá forçar um desses back-ends se souber em qual dispositivo será executado ou simplesmente deixar o TensorFlow.js decidir se. não especifique isso.
Superpoderes do lado do cliente
Executar o TensorFlow.js no navegador da Web na máquina cliente pode gerar muitos benefícios que vale a pena considerar.
Privacidade
É possível treinar e classificar dados na máquina cliente sem nunca enviá-los a um servidor da Web de terceiros. Às vezes, pode ser necessário obedecer à legislação local, como o GDPR, ou ao processar dados que o usuário queira manter na máquina e não enviar a terceiros.
Velocidade
Como você não precisa enviar dados para um servidor remoto, a inferência (o ato de classificar os dados) pode ser mais rápida. Melhor ainda, você tem acesso direto aos sensores do dispositivo, como a câmera, o microfone, o GPS, o acelerômetro e muito mais, caso o usuário conceda acesso.
Alcance e escala
Com um clique, qualquer pessoa pode clicar em um link que você envia, abrir a página da Web no navegador e usar o que você criou. Você não precisa de uma configuração complexa para Linux no lado do servidor com drivers CUDA e muito mais, só para usar o sistema de machine learning.
Custo
Nenhum servidor significa que você só precisa pagar por uma CDN para hospedar seus arquivos HTML, CSS, JS e de modelo. O custo de uma CDN é muito mais barato do que manter um servidor (possivelmente com uma placa de vídeo anexada) funcionando 24 horas.
Recursos do lado do servidor
Ao usar a implementação do TensorFlow.js em Node.js, são permitidos os seguintes recursos.
Suporte completo ao CUDA
No lado do servidor, para aceleração da placa gráfica, você precisa instalar os drivers CUDA do NVIDIA para permitir que o TensorFlow funcione com a placa de vídeo, diferentemente do navegador que usa a WebGL. Não é necessário instalar. No entanto, com a compatibilidade total com a CUDA, é possível aproveitar ao máximo os recursos de nível inferior da placa de vídeo, o que resulta em tempos de treinamento e inferência mais rápidos. O desempenho é igual ao da implementação do TensorFlow em Python, porque ambos compartilham o mesmo back-end C++.
Tamanho do modelo
Para modelos de pesquisa modernos, talvez você esteja trabalhando com modelos muito grandes, talvez gigabytes. No momento, não é possível executar esses modelos no navegador da Web devido às limitações do uso de memória por guia. Para executar esses modelos maiores, use o Node.js no seu próprio servidor com as especificações de hardware necessárias para executar esse modelo com eficiência.
IOL
O Node.js é compatível com computadores de placa única conhecidos, como o Raspberry Pi. Isso significa que você também pode executar modelos do TensorFlow.js nesses dispositivos.
Velocidade
O Node.js é escrito em JavaScript, o que significa que ele só funciona na compilação no tempo. Isso significa que você poderá ver ganhos de desempenho ao usar o Node.js, já que ele será otimizado no momento da execução, especialmente para qualquer pré-processamento realizado. Um ótimo exemplo disso pode ser visto neste estudo de caso, que mostra como a Hugging Face usou o Node.js para conseguir o dobro de desempenho no modelo de processamento de linguagem natural.
Agora que você já conhece os conceitos básicos do TensorFlow.js, onde ele pode ser executado e alguns dos benefícios, vamos começar a usar esse recurso.
3. Modelos pré-treinados
Por que usar um modelo pré-treinado?
Há várias vantagens em começar com um modelo pré-treinado conhecido se ele atender ao seu caso de uso, como:
- Não é preciso coletar dados de treinamento. Preparar os dados no formato correto e rotulá-los para que um sistema de machine learning possa usá-los para aprender pode ser muito demorado e caro.
- A capacidade de prototipar rapidamente uma ideia com redução de tempo e custo.
Não há motivo para "reinventar a roda" quando um modelo pré-treinado é suficiente para fazer o que precisa, permitindo que você se concentre em usar o conhecimento fornecido pelo modelo para implementar as ideias do criativo. de dados. - Uso de pesquisa de última geração. Os modelos pré-treinados geralmente são baseados em pesquisas em alta, dando a você exposição a esses modelos e, ao mesmo tempo, entendendo o desempenho deles no mundo real.
- Facilidade de uso e documentação abrangente. Devido à popularidade desses modelos.
- Recursos de aprendizado por transferência Alguns modelos pré-treinados oferecem recursos de transferência de aprendizado, que são a prática de transferência de informações aprendidas de uma tarefa de machine learning para outro exemplo semelhante. Por exemplo, um modelo treinado originalmente para reconhecer gatos pode ser treinado novamente para reconhecer cães, caso você tenha fornecido dados de treinamento novos. Isso será mais rápido porque você não começará com uma tela em branco. O modelo já pode usar o que aprendeu para reconhecer gatos e depois reconhecer a nova novidade: cachorros têm olhos e orelhas também, então, se já sabe como encontrar esses recursos, estamos na metade do caminho. Treinar novamente o modelo com seus próprios dados de uma maneira muito mais rápida.
Modelo de detecção de spam de comentários pré-treinado
Você usará a arquitetura do modelo de Incorporação de palavras média para as necessidades de detecção de spam de comentários. No entanto, se você usar um modelo não treinado, isso não será melhor do que adivinhar aleatoriamente se as frases são spam ou não.
Para tornar o modelo útil, ele precisa ser treinado em dados personalizados, nesse caso, para permitir que ele aprenda como funcionam os comentários de spam e não spam. A partir desse aprendizado, eles terão mais chances de classificar as coisas corretamente no futuro.
Felizmente, alguém já treinou esta arquitetura de modelo exata para essa tarefa de classificação de spam de comentários. Você pode usá-la como ponto de partida. É possível que outros modelos pré-treinados usem a mesma arquitetura para fazer outras coisas, como detectar o idioma em que um comentário foi escrito ou prever se os dados do formulário de contato do site precisam ser roteados para uma equipe específica da empresa automaticamente com base no texto escrito. Por exemplo, venda (consulta de produto) ou engenharia (bug técnico ou feedback). Com dados de treinamento suficientes, um modelo como este pode aprender a classificar o texto em cada caso para dar superpoderes ao app da Web e melhorar a eficiência da organização.
Em um futuro codelab de códigos, você aprenderá a usar o Model Maker para treinar novamente esse modelo de spam de comentários pré-treinado e melhorar ainda mais o desempenho dele nos seus próprios dados de comentários. Por enquanto, você usará o modelo existente de detecção de spam de comentários como ponto de partida para que o app da Web inicial funcione como o primeiro protótipo.
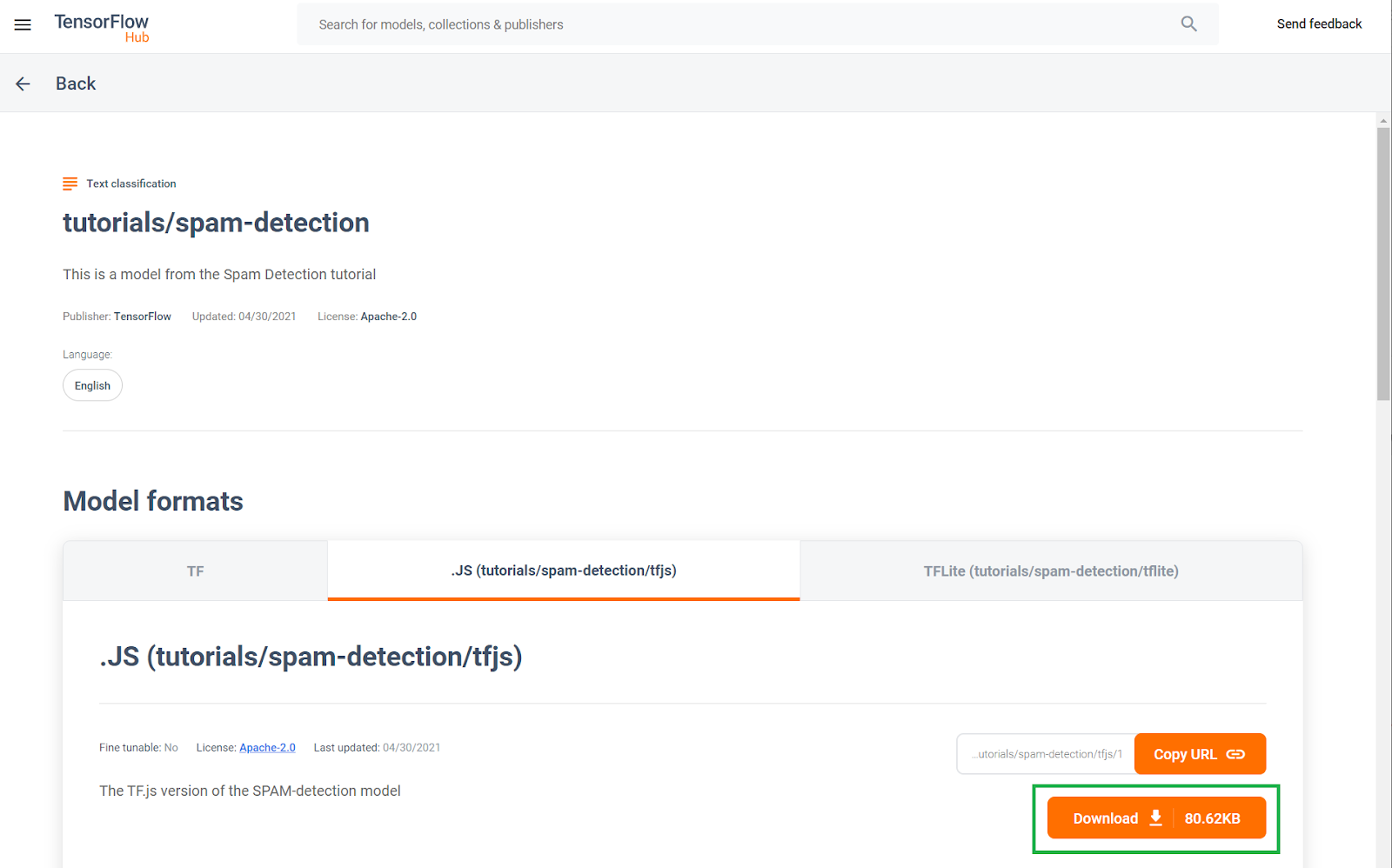
Este modelo de detecção de spam de comentários pré-treinado foi publicado em um site conhecido como TF Hub, um repositório de modelos de machine learning mantido pelo Google. Nele, os engenheiros de ML podem publicar os modelos predefinidos para muitos casos de uso comuns. (como texto, visão, som e outros para casos de uso específicos em cada uma dessas categorias). Faça o download dos arquivos de modelo para usar no app da Web posteriormente neste codelab.
Clique no botão de download do modelo JS, conforme mostrado abaixo:
4. Começar a configurar o código
Pré-requisitos
- Um navegador da Web moderno.
- Conhecimento básico de HTML, CSS, JavaScript e Chrome DevTools (visualizando a saída do console)
Vamos começar a programar.
Criamos um modelo boilerplate do Glitch.com Express.Node Express que pode ser clonado como estado base para este codelab com apenas um clique.
No Glitch, clique no botão "remix this" para bifurcá-lo e crie um novo conjunto de arquivos que você possa editar.
Este esqueleto muito simples oferece os seguintes arquivos na pasta www:
- Página HTML (index.html)
- Folha de estilo (style.css)
- Arquivo para escrever nosso código JavaScript (script.js)
Para facilitar, também adicionamos ao arquivo HTML uma importação para a biblioteca TensorFlow.js semelhante a esta:
index.html
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
Em seguida, exibimos essa pasta www por meio de um servidor Node Express simples por meio de package.json e server.js.
5. Código HTML do aplicativo
Qual é seu ponto de partida?
Todos os protótipos exigem alguns suportes HTML básicos em que você pode renderizar suas descobertas. Configure agora. Você adicionará:
- Um título para a página
- Texto descritivo
- Um vídeo de marcador que representa a entrada do blog de vídeo
- Área para visualizar e digitar comentários
Abra index.html e cole o código existente com o seguinte para configurar os recursos acima:
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<title>My Pretend Video Blog</title>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- Import the webpage's stylesheet -->
<link rel="stylesheet" href="/style.css">
</head>
<body>
<header>
<h1>MooTube</h1>
<a id="login" href="#">Login</a>
</header>
<h2>Check out the TensorFlow.js rap for the show and tell!</h2>
<p>Lorem ipsum dolor sit amet, consectetur adipiscing elit. Curabitur ipsum quam, tincidunt et tempor in, pulvinar vel urna. Nunc eget erat pulvinar, lacinia nisl in, rhoncus est. Morbi molestie vestibulum nunc. Integer non ipsum dolor. Curabitur condimentum sem eget odio dapibus, nec bibendum augue ultricies. Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia curae; Sed iaculis ut ligula sed tempor. Phasellus ac dictum felis. Integer arcu dui, facilisis sit amet placerat sagittis, blandit sit amet risus.</p>
<iframe width="100%" height="500" src="https://www.youtube.com/embed/RhVs7ijB17c" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
<section id="comments" class="comments">
<div id="comment" class="comment" contenteditable></div>
<button id="post" type="button">Comment</button>
<ul id="commentsList">
<li>
<span class="username">NotASpammer</span>
<span class="timestamp">3/18/2021, 6:52:16 PM</span>
<p>I am not a spammer, I am a good boy.</p>
</li>
<li>
<span class="username">SomeUser</span>
<span class="timestamp">2/11/2021, 3:10:00 PM</span>
<p>Wow, I love this video, so many amazing demos!</p>
</li>
</ul>
</section>
<!-- Import TensorFlow.js library -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@2.0.0/dist/tf.min.js" type="text/javascript"></script>
<!-- Import the page's JavaScript to do some stuff -->
<script type="module" src="/script.js"></script>
</body>
</html>
Detalhamento
Vamos detalhar parte do código HTML acima para destacar alguns dos principais itens que você adicionou.
- Você adicionou uma tag
<h1>para o título da página e uma tag<a>para o botão de login, tudo dentro do<header>. Depois, você adicionou uma<h2>para o título do artigo e uma tag<p>para a descrição do vídeo. Nada de especial aqui. - Você adicionou uma tag
iframeque incorpora um vídeo arbitrário do YouTube. Por enquanto, você está usando o poderoso rap do TensorFlow.js como um marcador, mas pode colocar qualquer vídeo aqui simplesmente mudando o URL do iframe. Na verdade, em um site de produção, todos esses valores são renderizados pelo back-end dinamicamente, dependendo da página que está sendo visualizada. - Por fim, você adicionou um
sectioncom um ID e uma classe de "comentários", que contém umdiveditável para escrever novos comentários, além de umbuttonpara enviar o novo comentário que você quer adicionar junto com um elemento não ordenado. lista de comentários. Veja o nome de usuário e a hora de postagem em uma tagspandentro de cada item da lista e, finalmente, o comentário em uma tagp. Por enquanto, dois comentários de exemplo estão codificados como marcador.
Se você visualizar a saída agora, ela terá esta aparência:
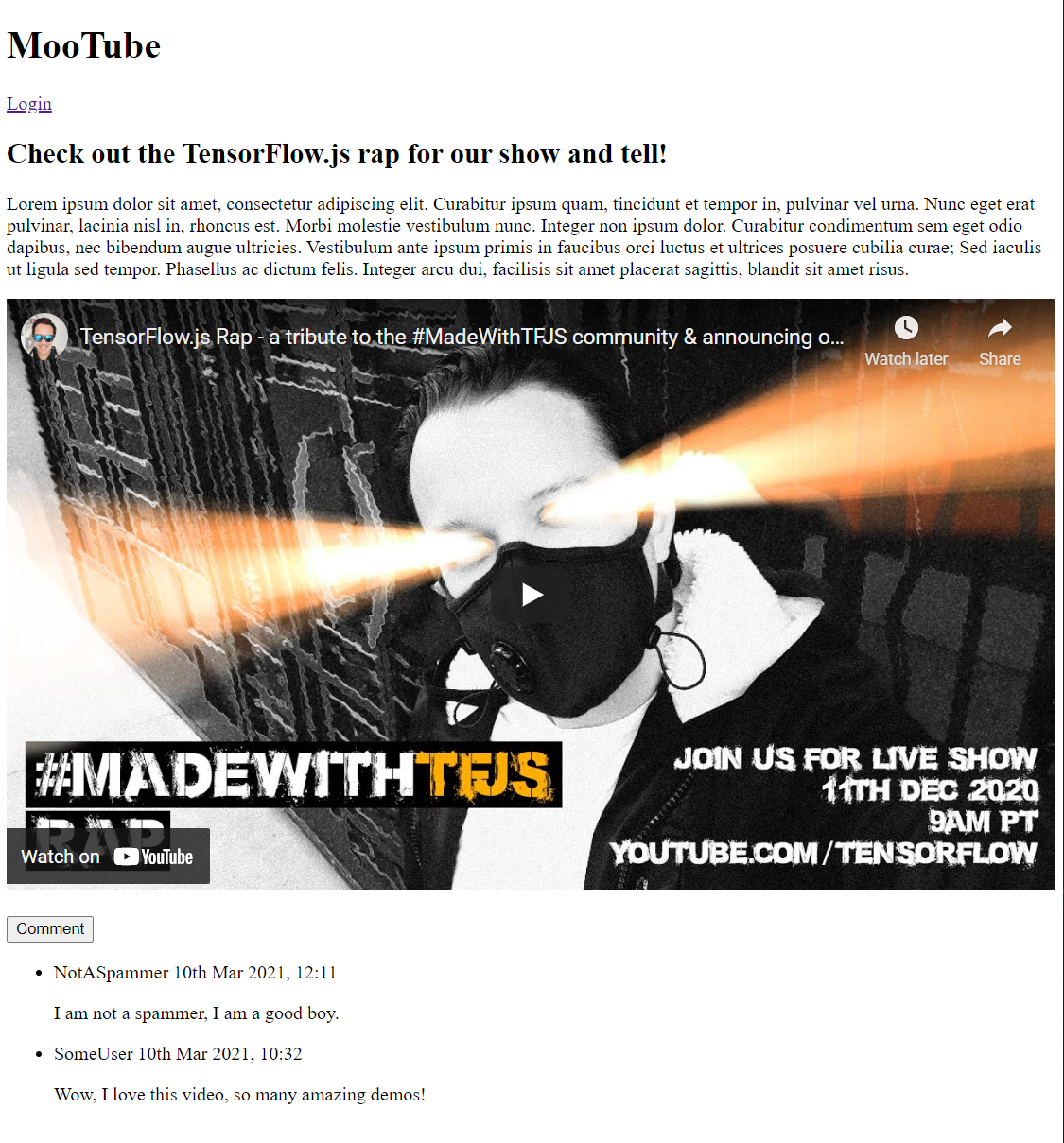
Isso é muito ruim, então é hora de adicionar um pouco de estilo...
6. Adic. estilo
Elementos padrão
Primeiro, adicione estilos para os elementos HTML que você acabou de adicionar para garantir que eles sejam renderizados corretamente.
Comece aplicando uma redefinição de CSS para ter um ponto de partida de comentários em todos os navegadores e no SO. Substitua o conteúdo de style.css pelo seguinte:
style.css (em inglês)
/* http://meyerweb.com/eric/tools/css/reset/
v2.0 | 20110126
License: none (public domain)
*/
a,abbr,acronym,address,applet,article,aside,audio,b,big,blockquote,body,canvas,caption,center,cite,code,dd,del,details,dfn,div,dl,dt,em,embed,fieldset,figcaption,figure,footer,form,h1,h2,h3,h4,h5,h6,header,hgroup,html,i,iframe,img,ins,kbd,label,legend,li,mark,menu,nav,object,ol,output,p,pre,q,ruby,s,samp,section,small,span,strike,strong,sub,summary,sup,table,tbody,td,tfoot,th,thead,time,tr,tt,u,ul,var,video{margin:0;padding:0;border:0;font-size:100%;font:inherit;vertical-align:baseline}article,aside,details,figcaption,figure,footer,header,hgroup,menu,nav,section{display:block}body{line-height:1}ol,ul{list-style:none}blockquote,q{quotes:none}blockquote:after,blockquote:before,q:after,q:before{content:'';content:none}table{border-collapse:collapse;border-spacing:0}
Depois, acrescente um CSS útil para dar vida à interface do usuário.
Adicione o seguinte código no fim de style.css, abaixo do código CSS redefinido que você adicionou acima:
style.css (em inglês)
/* CSS files add styling rules to your content */
body {
background: #212121;
color: #fff;
font-family: helvetica, arial, sans-serif;
}
header {
background: linear-gradient(0deg, rgba(7,7,7,1) 0%, rgba(7,7,7,1) 85%, rgba(55,52,54,1) 100%);
min-height: 30px;
overflow: hidden;
}
h1 {
color: #f0821b;
font-size: 24pt;
padding: 15px 25px;
display: inline-block;
float: left;
}
h2, p, section, iframe {
background: #212121;
padding: 10px 25px;
}
h2 {
font-size: 16pt;
padding-top: 25px;
}
p {
color: #cdcdcd;
}
iframe {
display: block;
padding: 15px 0;
}
header a, button {
color: #222;
padding: 7px;
min-width: 100px;
background: rgb(240, 130, 30);
border-radius: 3px;
border: 1px solid #3d3d3d;
text-transform: uppercase;
font-weight: bold;
cursor: pointer;
transition: background 300ms ease-in-out;
}
header a {
background: #efefef;
float: right;
margin: 15px 25px;
text-decoration: none;
text-align: center;
}
button:focus, button:hover, header a:hover {
background: rgb(260, 150, 50);
}
.comment {
background: #212121;
border: none;
border-bottom: 1px solid #888;
color: #fff;
min-height: 25px;
display: block;
padding: 5px;
}
.comments button {
float: right;
margin: 5px 0;
}
.comments button, .comment {
transition: opacity 500ms ease-in-out;
}
.comments ul {
clear: both;
margin-top: 60px;
}
.comments ul li {
margin-top: 5px;
padding: 10px;
transition: background 500ms ease-in-out;
}
.comments ul li * {
background: transparent;
}
.comments ul li:nth-child(1) {
background: #313131;
}
.comments ul li:hover {
background: rgb(70, 60, 10);
}
.username, .timestamp {
font-size: 80%;
margin-right: 5px;
}
.username {
font-weight: bold;
}
.processing {
opacity: 0.3;
filter: grayscale(1);
}
.comments ul li.spam {
background-color: #d32f2f;
}
.comments ul li.spam::after {
content: "⚠";
margin: -17px 2px;
zoom: 3;
float: right;
}
Ótimo. Isso é tudo o que você precisa. Se você tiver substituído seus estilos com os dois códigos acima, sua visualização dinâmica ficará assim:
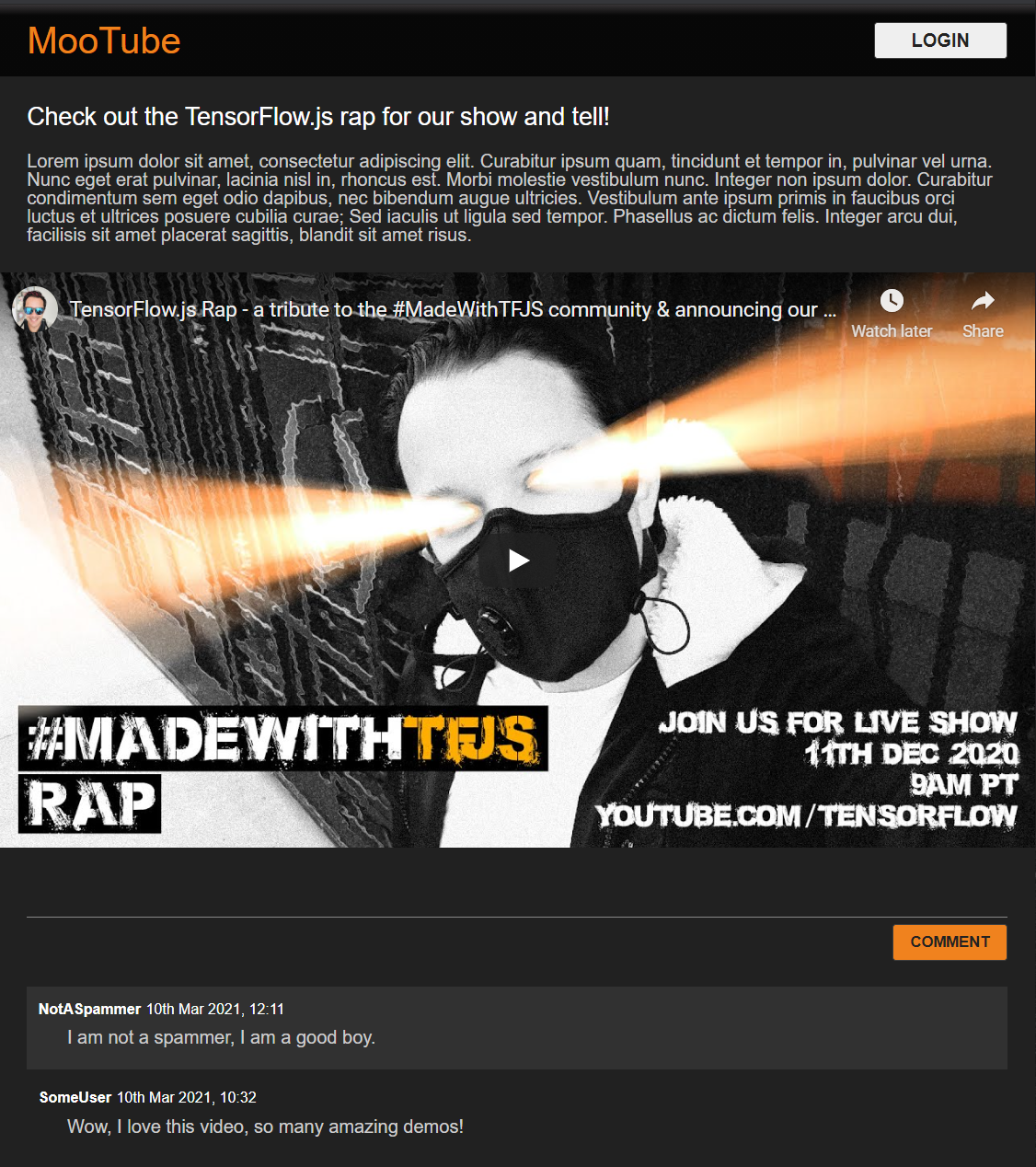
O Modo noturno é perfeito para os efeitos de passar o cursor sobre elementos importantes. Parece bom. Integre a lógica comportamental usando JavaScript.
7. JavaScript: manipulação de DOM e manipuladores de eventos
Como fazer referência a elementos DOM importantes
Primeiro, verifique se é possível acessar as principais partes da página que você precisará manipular ou acessar mais tarde no código, além de definir algumas constantes de classe CSS para estilo.
Comece substituindo o conteúdo de script.js pelas seguintes constantes:
script.js
const POST_COMMENT_BTN = document.getElementById('post');
const COMMENT_TEXT = document.getElementById('comment');
const COMMENTS_LIST = document.getElementById('commentsList');
// CSS styling class to indicate comment is being processed when
// posting to provide visual feedback to users.
const PROCESSING_CLASS = 'processing';
// Store username of logged in user. Right now you have no auth
// so default to Anonymous until known.
var currentUserName = 'Anonymous';
Gerenciar a postagem de comentários
Em seguida, adicione um listener de eventos e uma função de gerenciamento ao POST_COMMENT_BTN para que ele possa capturar o texto do comentário escrito e definir uma classe CSS para indicar que o processamento foi iniciado. Se o processamento já estiver em andamento, verifique se você ainda não clicou no botão.
script.js (em inglês)
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
let currentComment = COMMENT_TEXT.innerText;
console.log(currentComment);
// TODO: Fill out the rest of this function later.
}
}
POST_COMMENT_BTN.addEventListener('click', handleCommentPost);
Ótimo. Se você atualizar a página da Web e tentar postar um comentário, o botão de comentário e a escala de texto ficarão cinza e, no console, você vai ver o comentário impresso da seguinte forma:
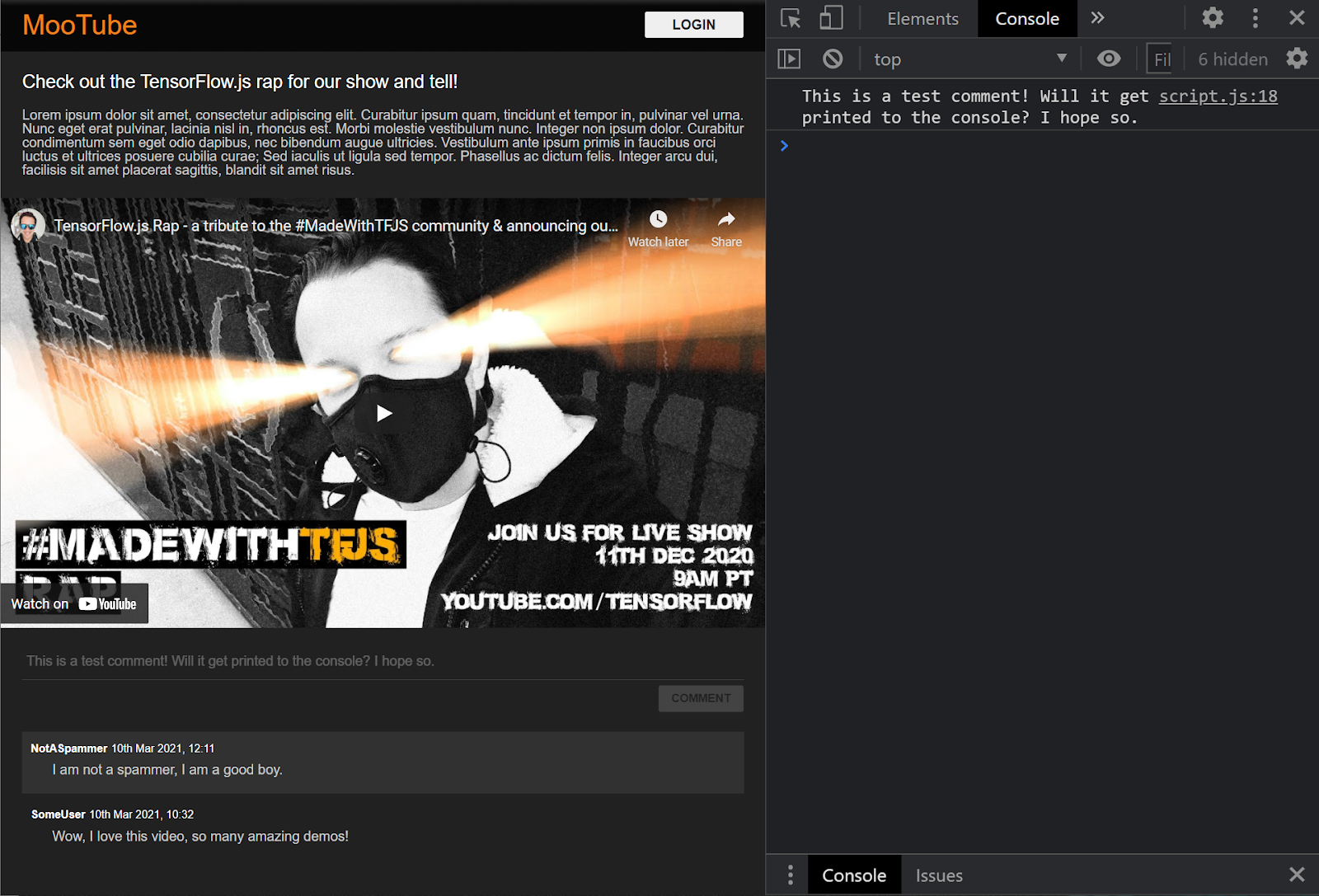
Agora que você tem um esqueleto de HTML / CSS / JS básico, é hora de voltar seu foco ao modelo de machine learning para integrá-lo à linda página da Web.
8. Exibir o modelo de machine learning
Está quase tudo pronto para carregar o modelo. Antes de fazer isso, é necessário fazer upload dos arquivos de modelo transferidos anteriormente no codelab para seu site. Assim, ele fica hospedado e pode ser usado no código.
Primeiro, se você ainda não tiver feito isso, descompacte os arquivos do modelo no início deste codelab. Você verá um diretório com os seguintes arquivos:
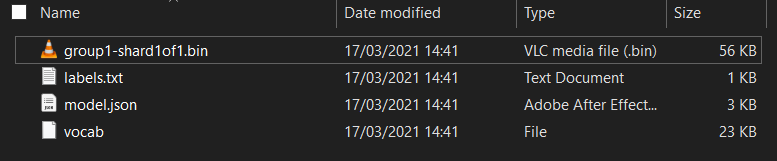
O que você tem aqui?
model.json: é um dos arquivos que compõem o modelo treinado do TensorFlow.js. Você usará realmente esse arquivo para referência posterior no seu código do TensorFlow.js.group1-shard1of1.bin: é um arquivo binário que contém os pesos treinados do modelo TensorFlow.js. Ele precisa ser hospedado em algum lugar do servidor para download.vocab: esse arquivo estranho sem extensão é algo do Model Maker que nos mostra como codificar palavras nas frases para que o modelo entenda como usá-las. Você vai ver mais detalhes na próxima seção.labels.txt: contém simplesmente os nomes de classes resultantes que o modelo prevê. Para esse modelo, se você abrir esse arquivo no seu editor de texto, ele terá "false" e "true" listados, indicando "não é spam" ou "spam" como a saída da previsão.
Hospedar os arquivos de modelo do TensorFlow.js
Primeiro coloque model.json e os arquivos *.bin gerados em um servidor da Web para que você possa acessá-los por meio da página da Web.
Fazer upload de arquivos no Glitch
- Clique na pasta assets no painel esquerdo do projeto Glitch.
- Clique em Fazer upload de um recurso e selecione
group1-shard1of1.binpara fazer o upload na pasta. Ele ficará assim após o upload:
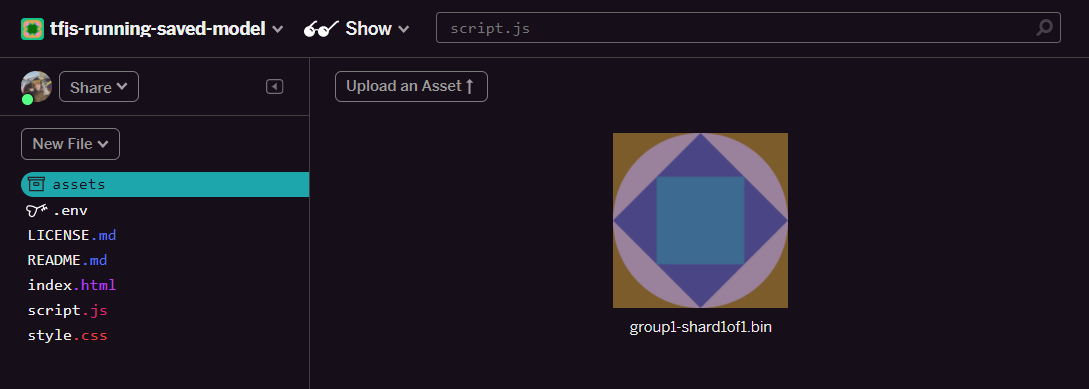
- Ótimo. Agora, faça o mesmo para o arquivo
model.json. Dois arquivos precisam estar na sua pasta assets, desta forma:
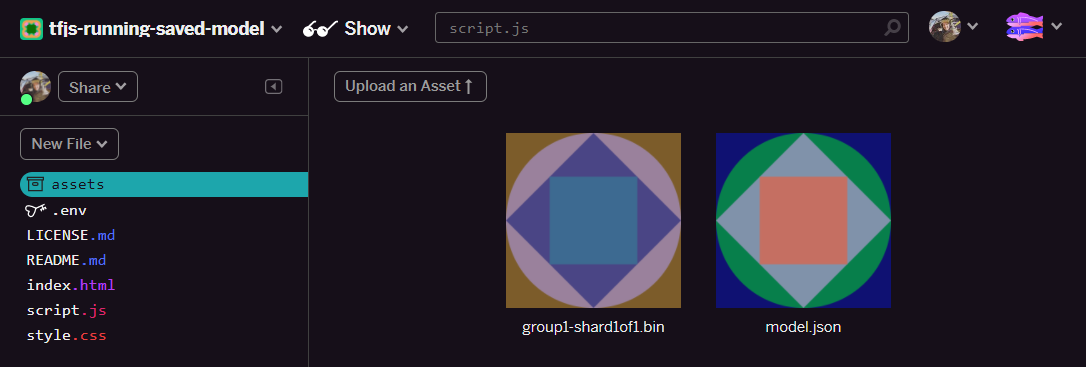
- Clique no arquivo
group1-shard1of1.binque você acabou de enviar. Você poderá copiar o URL para o local dele. Copie este caminho agora como mostrado:
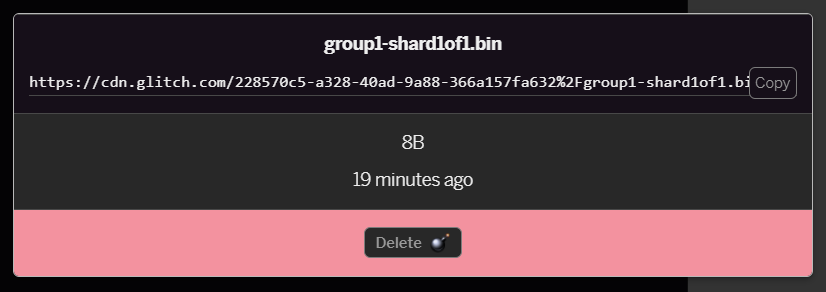
- Agora, no canto inferior esquerdo da tela, clique em Ferramentas > Terminal. Aguarde a janela de terminal ser carregada. Depois de carregar, digite o seguinte e pressione Enter para mudar o diretório para a pasta
www:
terminal:
cd www
- Em seguida, use o
wgetpara fazer o download dos dois arquivos que você acabou de enviar substituindo os URLs abaixo pelos que você gerou para os arquivos na pasta assets do Glitch (verifique a pasta de recursos do URL personalizado de cada arquivo). . O espaço entre os dois URLs e os URLs que você precisa usar são diferentes dos listados abaixo, mas têm uma aparência semelhante a esta:
terminal
wget https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fmodel.json?v=1616111344958 https://cdn.glitch.com/1cb82939-a5dd-42a2-9db9-0c42cab7e407%2Fgroup1-shard1of1.bin?v=1616017964562
Você fez uma cópia dos arquivos enviados para a pasta www, mas eles serão salvos com nomes estranhos no momento.
- Digite
lsno terminal e pressione Enter. Você verá algo como:

- É possível renomear os arquivos usando o comando
mv. Digite o código a seguir no console e pressione <kbd>Enter</kbd> ou <kbd>retornar</kbd> após cada linha:
terminal:
mv *group1-shard1of1.bin* group1-shard1of1.bin
mv *model.json* model.json
- Por fim, atualize o projeto Glitch digitando
refreshno terminal e pressionando <kbd>Enter</kbd>:
terminal:
refresh
- Depois de atualizar, você verá
model.jsonegroup1-shard1of1.binna pastawwwda interface do usuário:

Ótimo. Agora você está pronto para usar os arquivos de modelo enviados com um código real no navegador.
9. Carregar e usar o modelo hospedado do TensorFlow.js
Agora você pode testar o carregamento do modelo do TensorFlow.js enviado com alguns dados para conferir se ele está funcionando.
Agora, os dados de entrada de exemplo abaixo serão um pouco misteriosos (uma matriz de números), e a próxima etapa explica como eles foram gerados. Agora, basta visualizá-lo como uma matriz de números por enquanto. Nesse estágio, é importante testar se o modelo oferece uma resposta sem erros.
Adicione o seguinte código no fim do arquivo script.js e substitua o valor da string MODEL_JSON_URL pelo caminho do arquivo model.json que você gerou ao fazer upload do arquivo para a pasta de recursos do Glitch em a etapa anterior. Lembre-se, basta clicar no arquivo na pasta assets do Glitch para encontrar o URL.
Leia os comentários do novo código abaixo para entender o que cada linha está fazendo:
script.js (em inglês)
// Set the URL below to the path of the model.json file you uploaded.
const MODEL_JSON_URL = 'model.json';
// Set the minimum confidence for spam comments to be flagged.
// Remember this is a number from 0 to 1, representing a percentage
// So here 0.75 == 75% sure it is spam.
const SPAM_THRESHOLD = 0.75;
// Create a variable to store the loaded model once it is ready so
// you can use it elsewhere in the program later.
var model = undefined;
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
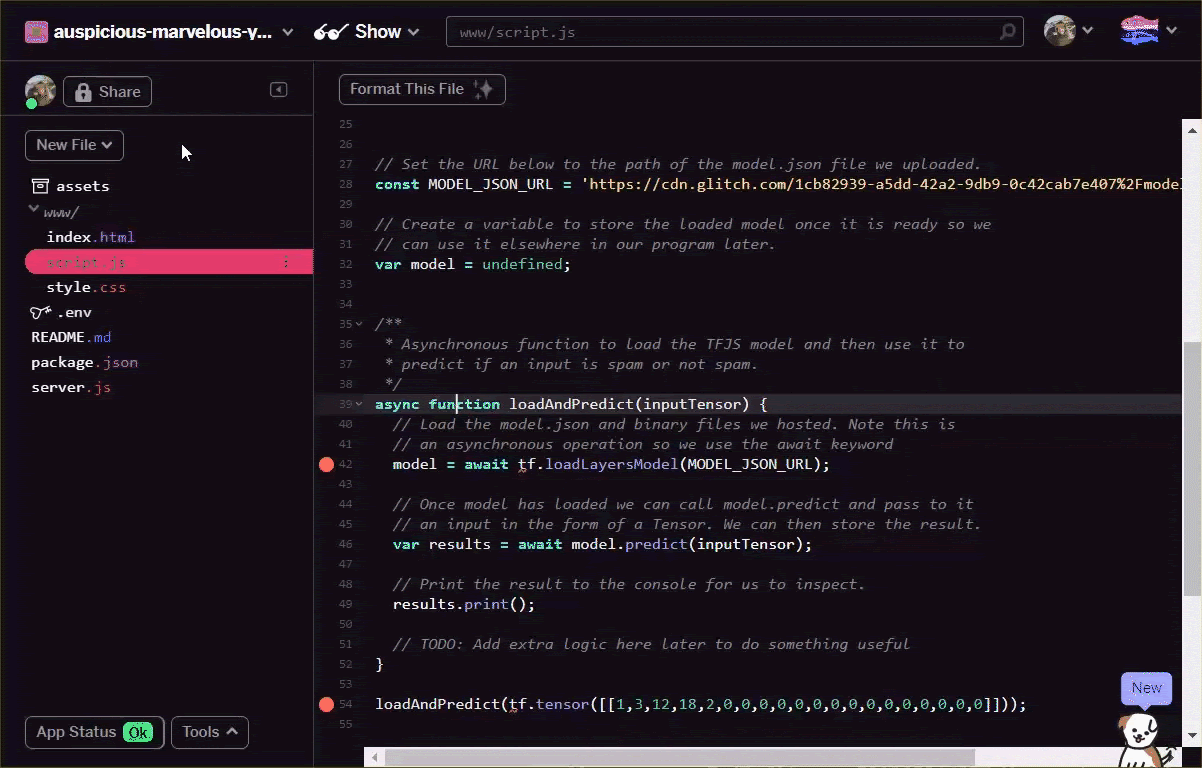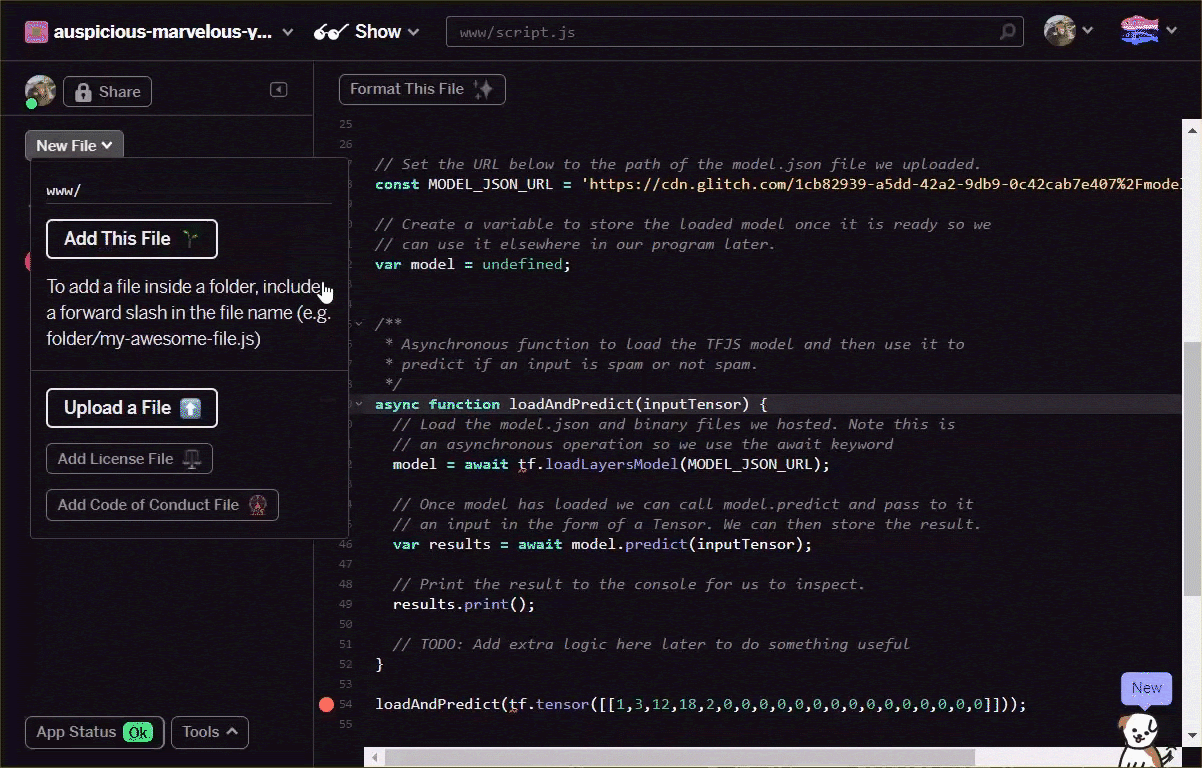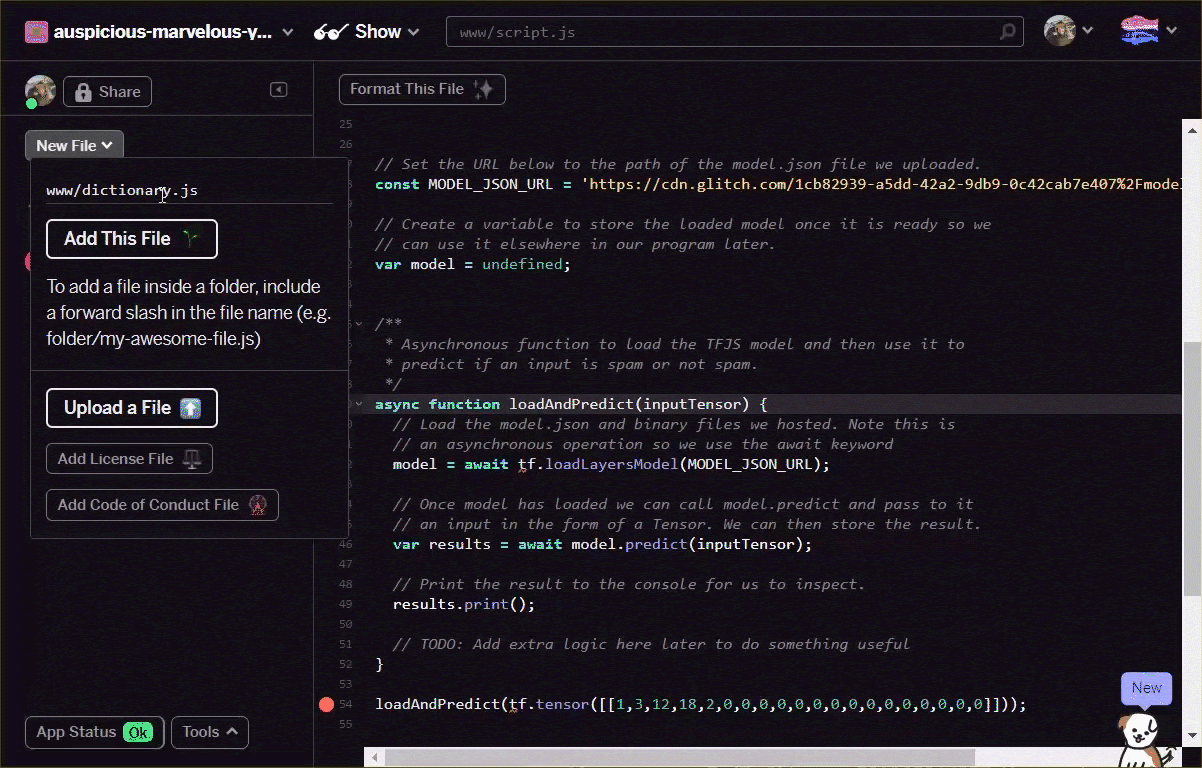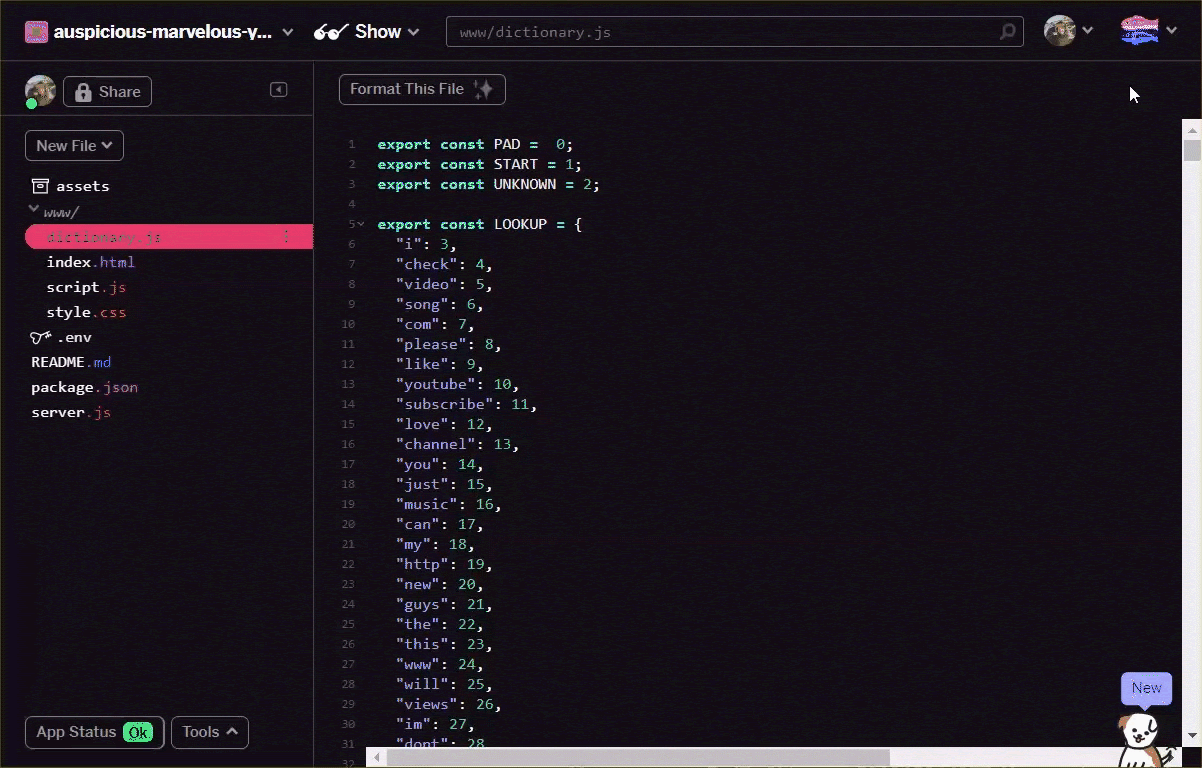
async function loadAndPredict(inputTensor) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
// TODO: Add extra logic here later to do something useful
}
loadAndPredict(tf.tensor([[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]]));
Se o projeto estiver configurado corretamente, você verá algo parecido com o seguinte impresso na janela do console, quando usar o modelo carregado para prever um resultado da entrada transmitida a ele:
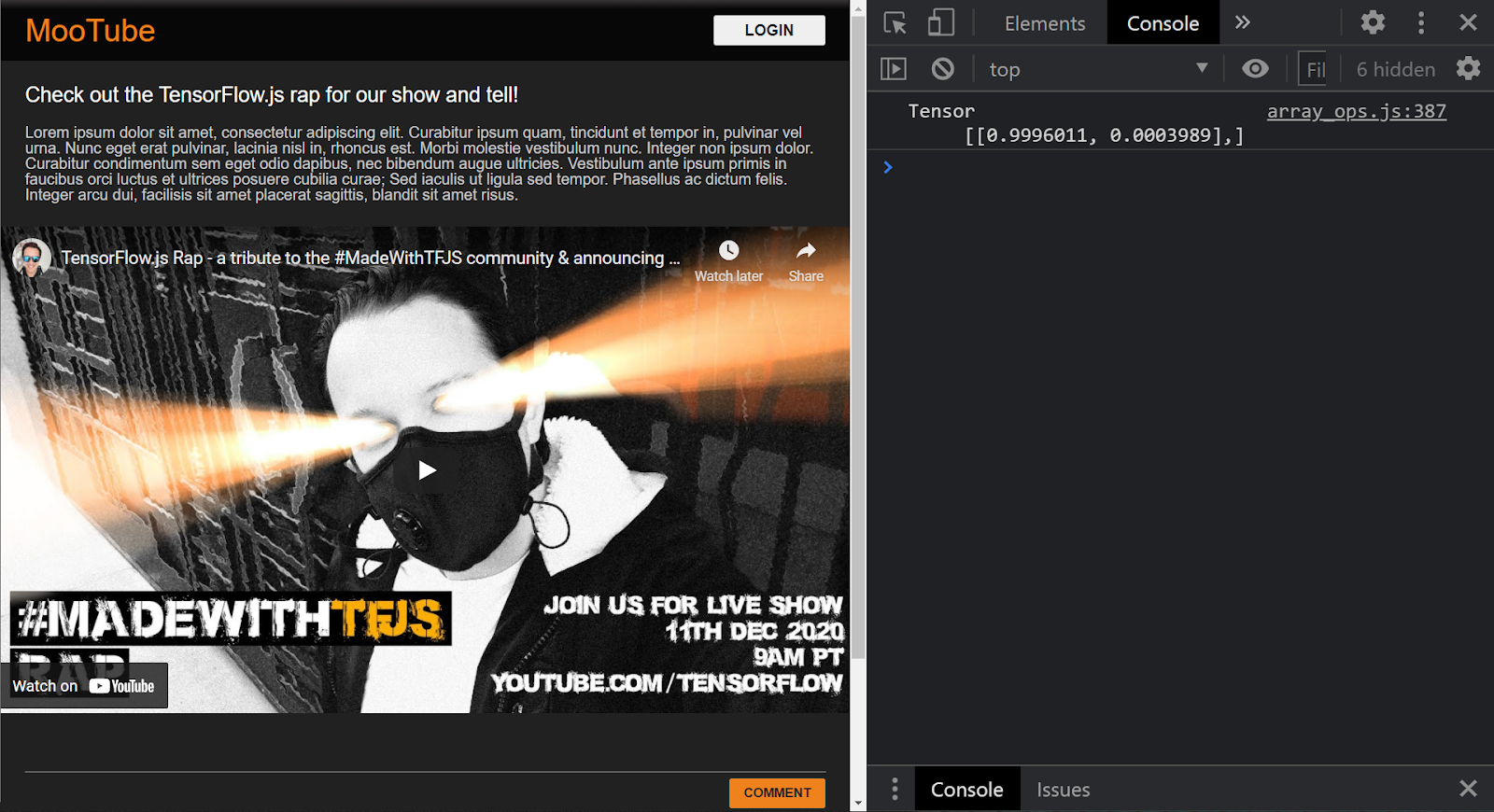
No console, você vê dois números impressos:
- 0,9996011
- 0,0003989
Mesmo que isso pareça criptográfico, esses números representam as probabilidades do modelo de classificação da entrada que você deu a ele. Mas o que elas representam?
Ao abrir o arquivo labels.txt dos arquivos de modelo salvos na máquina local, você verá que ele também tem dois campos:
- Falso
- Verdadeiro
Neste caso, o modelo diz que é99,96011% certifique-se (mostrado no objeto de resultado como 0.9996011) que a entrada fornecida (que era[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] eraNÃO é spam Por exemplo, "False".
Observe que false foi o primeiro rótulo em labels.txt e é representado pela primeira saída na impressão do console, que é como você sabe a que a previsão se refere.
Certo, agora você já sabe como interpretar os resultados. Mas qual exatamente aquele número enorme de números recebeu como entrada e como converter as frases nesse formato para o modelo usar? Para isso, você precisa aprender sobre tokenização e tensores. Boa leitura!
10. Tokenização e tensores
Tokenização
Acontece que os modelos de machine learning só podem aceitar vários números como entradas. Por quê? Basicamente, é porque um modelo de machine learning é basicamente uma série de operações matemáticas em cadeia. Portanto, se você passar para ele algo que não seja um número, será difícil lidar com ele. A pergunta agora é como converter as frases em números para uso com o modelo que você carregou.
O processo exato varia de acordo com o modelo. No entanto, para este, há mais um arquivo nos arquivos de download chamado vocab,, e essa é a chave de como você codifica dados.
Abra vocab em um editor de texto local na sua máquina para ver o seguinte:
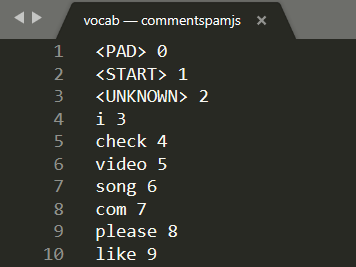
Basicamente, esta é uma tabela de consulta sobre como converter palavras significativas que o modelo aprendeu em números. Há também alguns casos especiais na parte superior do arquivo <PAD>, <START> e <UNKNOWN>:
<PAD>: é a abreviação de "padding". Acontece que os modelos de machine learning gostam de ter um número fixo de entradas, não importa qual seja a duração da frase. O modelo usado espera que sempre haja 20 números para a entrada (definido pelo criador do modelo e pode ser alterado se você treiná-lo novamente). Portanto, se você tivesse uma frase como "Gosto de vídeo", preencheria os espaços restantes na matriz com 0s que representam o token<PAD>. Se a frase tiver mais de 20 palavras, você vai precisar dividi-la para que ela atenda a esse requisito. Assim, faça várias classificações em várias frases menores.<START>: é sempre o primeiro token para indicar o início da frase. Na entrada de exemplo das etapas anteriores, observe que a matriz de números começou com "1". Isso representa o token<START>.<UNKNOWN>: como você deve ter imaginado, se a palavra não existir na pesquisa de palavras, basta usar o token<UNKNOWN>(representado por um "2") como o número.
Para todas as outras palavras, ele existe na pesquisa e tem um número especial associado a ele. Assim, você usaria ou não existe. Nesse caso, use o número do token <UNKNOWN>.
Take another look at the input used in the prior code you ran:
[1,3,12,18,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]
Você verá que essa é uma frase com quatro palavras. O restante é um token <START> ou <PAD> e há 20 números na matriz. Ok, começando a fazer mais sentido.
A frase que eu realmente escrevi era: "Eu amo meu cachorro". A captura de tela acima mostra que "I" está convertido no número "3", e isso está correto. Se você procurar as outras palavras, também encontrará os números correspondentes.
Tensores
Há um obstáculo final antes que o modelo de ML aceite sua entrada numérica. Você precisa converter a matriz de números em algo conhecido como Tensor. Sim, ela vem de um nome específico: o TensorFlow, chamado "Fluxo de Tensors".
O que é um Tensor?
A definição oficial do TensorFlow.org diz:
"Os tensores são matrizes multidimensionais com um tipo uniforme. Todos os tensores são imutáveis: não é possível atualizar o conteúdo de um tensor, basta criar um novo."
Em inglês simples, é apenas um nome matemático sofisticado para uma matriz de qualquer dimensão que tenha algumas outras funções integradas ao objeto Tensor. Elas são úteis para nós, desenvolvedores de machine learning. É importante observar que os Tensors armazenam dados de apenas um tipo, por exemplo, números inteiros ou números de pontos flutuantes. Depois de criados, não é possível alterar o conteúdo dos Tensors. Pense neles como uma caixa de armazenamento permanente para números.
Não se preocupe muito com isso por enquanto. No mínimo, pense nele como um mecanismo de armazenamento multidimensional para os modelos de machine learning, até que você se aprofunde em um bom livro como este, altamente recomendado se quiser saber mais sobre Tensors e como usá-los.
Combinar tudo: tensores de codificação e tokenização
Então, como você usa esse arquivo vocab no código? Boa pergunta.
Esse arquivo é praticamente inútil para você, como desenvolvedor JS. Seria muito melhor se fosse um objeto JavaScript que você pudesse apenas importar e usar. É possível ver como seria simples converter os dados nesse arquivo para um formato mais parecido com este:
// Special cases. Export as constants.
export const PAD = 0;
export const START = 1;
export const UNKNOWN = 2;
// Export a lookup object.
export const LOOKUP = {
"i": 3,
"check": 4,
"video": 5,
"song": 6,
"com": 7,
"please": 8,
"like": 9
// and all the other words...
}
Com seu editor de texto favorito, é fácil transformar o arquivo vocab para esse formato, basta encontrar e substituir. No entanto, também é possível usar essa ferramenta predefinida para facilitar o processo.
Ao fazer esse trabalho com antecedência e salvar o arquivo vocab no formato correto, você não precisa fazer essa conversão e análise em cada carregamento de página, o que é um desperdício de recursos da CPU. Melhor ainda, os objetos JavaScript têm as seguintes propriedades:
"Um nome de propriedade de objeto pode ser qualquer string JavaScript válida ou qualquer item que possa ser convertido em uma string, incluindo a string vazia. No entanto, qualquer nome de propriedade que não seja um identificador JavaScript válido (por exemplo, um nome de propriedade com espaço ou hífen ou que comece com um número) só pode ser acessado usando a notação de colchetes.
Portanto, se você usar a notação de colchetes, poderá criar uma tabela de consulta bastante eficiente por meio dessa transformação simples.
Como converter para um formato mais útil
Converta o arquivo vocabulário no formato acima manualmente, por meio do seu editor de texto, ou use esta ferramenta aqui. Salve a saída resultante como dictionary.js na pasta www.
No Glitch, basta criar um novo arquivo nesse local e colar o resultado da conversão para salvar como mostrado:
Depois de salvar um arquivo dictionary.js no formato descrito acima, adicione o seguinte código à parte superior da script.js para importar o módulo dictionary.js que você acabou de gravar. Aqui, você também define uma ENCODING_LENGTH extra constante para saber quanto precisa ser preenchido posteriormente no código, junto com uma função tokenize que será usada para converter uma matriz de palavras em um tensor adequado que pode ser usado como uma entrada para o modelo.
Verifique os comentários no código abaixo para ver mais detalhes sobre o que cada linha faz:
script.js (em inglês)
import * as DICTIONARY from '/dictionary.js';
// The number of input elements the ML Model is expecting.
const ENCODING_LENGTH = 20;
/**
* Function that takes an array of words, converts words to tokens,
* and then returns a Tensor representation of the tokenization that
* can be used as input to the machine learning model.
*/
function tokenize(wordArray) {
// Always start with the START token.
let returnArray = [DICTIONARY.START];
// Loop through the words in the sentence you want to encode.
// If word is found in dictionary, add that number else
// you add the UNKNOWN token.
for (var i = 0; i < wordArray.length; i++) {
let encoding = DICTIONARY.LOOKUP[wordArray[i]];
returnArray.push(encoding === undefined ? DICTIONARY.UNKNOWN : encoding);
}
// Finally if the number of words was < the minimum encoding length
// minus 1 (due to the start token), fill the rest with PAD tokens.
while (i < ENCODING_LENGTH - 1) {
returnArray.push(DICTIONARY.PAD);
i++;
}
// Log the result to see what you made.
console.log([returnArray]);
// Convert to a TensorFlow Tensor and return that.
return tf.tensor([returnArray]);
}
Ótimo, agora volte à função handleCommentPost() e substitua-a por essa nova versão.
Veja o código dos comentários sobre o que você adicionou:
script.js (em inglês)
/**
* Function to handle the processing of submitted comments.
**/
function handleCommentPost() {
// Only continue if you are not already processing the comment.
if (! POST_COMMENT_BTN.classList.contains(PROCESSING_CLASS)) {
// Set styles to show processing in case it takes a long time.
POST_COMMENT_BTN.classList.add(PROCESSING_CLASS);
COMMENT_TEXT.classList.add(PROCESSING_CLASS);
// Grab the comment text from DOM.
let currentComment = COMMENT_TEXT.innerText;
// Convert sentence to lower case which ML Model expects
// Strip all characters that are not alphanumeric or spaces
// Then split on spaces to create a word array.
let lowercaseSentenceArray = currentComment.toLowerCase().replace(/[^\w\s]/g, ' ').split(' ');
// Create a list item DOM element in memory.
let li = document.createElement('li');
// Remember loadAndPredict is asynchronous so you use the then
// keyword to await a result before continuing.
loadAndPredict(tokenize(lowercaseSentenceArray), li).then(function() {
// Reset class styles ready for the next comment.
POST_COMMENT_BTN.classList.remove(PROCESSING_CLASS);
COMMENT_TEXT.classList.remove(PROCESSING_CLASS);
let p = document.createElement('p');
p.innerText = COMMENT_TEXT.innerText;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = currentUserName;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
let curDate = new Date();
spanDate.innerText = curDate.toLocaleString();
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
// Reset comment text.
COMMENT_TEXT.innerText = '';
});
}
}
Por fim, atualize a função loadAndPredict() para definir um estilo se um comentário for detectado como spam.
Por enquanto, basta mudar o estilo, mas você pode escolher reter o comentário em uma fila de moderação ou parar de enviar.
script.js (em inglês)
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam.
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
}
})
}
11. Atualizações em tempo real: Node.js + Websockets
Agora que você tem um front-end funcional com a detecção de spam, a peça final do quebra-cabeça é usar o Node.js com alguns soquetes da Web para comunicação em tempo real e atualizar comentários que não sejam spam em tempo real.
Soquete.io
Socket.io é uma das formas mais conhecidas (no momento da escrita) de usar websockets com Node.js. Diga ao Glitch que você quer incluir a biblioteca Socket.io no build editando package.json no diretório de nível superior (na pasta pai da pasta www) para incluir socket.io como uma das dependências. :
pacote. JSON
{
"name": "tfjs-with-backend",
"version": "0.0.1",
"description": "A TFJS front end with thin Node.js backend",
"main": "server.js",
"scripts": {
"start": "node server.js"
},
"dependencies": {
"express": "^4.17.1",
"socket.io": "^4.0.1"
},
"engines": {
"node": "12.x"
}
}
Ótimo. Depois de atualizá-lo, atualize index.html na pasta www para incluir a biblioteca socket.io.
Basta inserir esta linha de código acima da importação da tag de script HTML para script.js perto do fim do arquivo index.html:
index.html
<script src="/socket.io/socket.io.js"></script>
Agora, você tem três tags de script no seu arquivo index.html:
- o primeiro a importar a biblioteca TensorFlow.js
- a segunda importação do socket.io que você acabou de adicionar
- e a última precisa importar o código do script.js.
Em seguida, edite server.js para configurar o socket.io dentro do nó e criar um back-end simples para redirecionar as mensagens recebidas para todos os clientes conectados.
Veja os comentários do código abaixo para saber o que o código Node.js está fazendo:
server.js (em inglês)
const http = require('http');
const express = require("express");
const app = express();
const server = http.createServer(app);
// Require socket.io and then make it use the http server above.
// This allows us to expose correct socket.io library JS for use
// in the client side JS.
var io = require('socket.io')(server);
// Serve all the files in 'www'.
app.use(express.static("www"));
// If no file specified in a request, default to index.html
app.get("/", (request, response) => {
response.sendFile(__dirname + "/www/index.html");
});
// Handle socket.io client connect event.
io.on('connect', socket => {
console.log('Client connected');
// If you wanted you could emit existing comments from some DB
// to client to render upon connect.
// socket.emit('storedComments', commentObjectArray);
// Listen for "comment" event from a connected client.
socket.on('comment', (data) => {
// Relay this comment data to all other connected clients
// upon receiving.
socket.broadcast.emit('remoteComment', data);
});
});
// Start the web server.
const listener = server.listen(process.env.PORT, () => {
console.log("Your app is listening on port " + listener.address().port);
});
Ótimo. Agora você tem um servidor da Web que está ouvindo eventos socket.io. Ou seja, você tem um evento comment quando um novo comentário é enviado de um cliente e o servidor emite eventos remoteComment, que o código do lado do cliente detectará para renderizar um comentário remoto. A última coisa a fazer é adicionar a lógica socket.io ao código do lado do cliente para emitir e lidar com esses eventos.
Primeiro, adicione o seguinte código no fim de script.js para se conectar ao servidor socket.io e detectar / processar os eventos RemoteComment recebidos:
script.js (em inglês)
// Connect to Socket.io on the Node.js backend.
var socket = io.connect();
function handleRemoteComments(data) {
// Render a new comment to DOM from a remote client.
let li = document.createElement('li');
let p = document.createElement('p');
p.innerText = data.comment;
let spanName = document.createElement('span');
spanName.setAttribute('class', 'username');
spanName.innerText = data.username;
let spanDate = document.createElement('span');
spanDate.setAttribute('class', 'timestamp');
spanDate.innerText = data.timestamp;
li.appendChild(spanName);
li.appendChild(spanDate);
li.appendChild(p);
COMMENTS_LIST.prepend(li);
}
// Add event listener to receive remote comments that passed
// spam check.
socket.on('remoteComment', handleRemoteComments);
Por fim, adicione um código à função loadAndPredict para emitir um evento socket.io se um comentário não for spam. Assim, você poderá atualizar os outros clientes conectados com esse novo comentário porque o conteúdo da mensagem será redirecionado para eles pelo código server.js escrito acima.
Basta substituir a função loadAndPredict existente pelo seguinte código que adiciona uma instrução else à última verificação de spam. Se o comentário não for spam, chame socket.emit() para enviar todos os dados do comentário:
script.js (em inglês)
/**
* Asynchronous function to load the TFJS model and then use it to
* predict if an input is spam or not spam. The 2nd parameter
* allows us to specify the DOM element list item you are currently
* classifying so you can change it+s style if it is spam!
*/
async function loadAndPredict(inputTensor, domComment) {
// Load the model.json and binary files you hosted. Note this is
// an asynchronous operation so you use the await keyword
if (model === undefined) {
model = await tf.loadLayersModel(MODEL_JSON_URL);
}
// Once model has loaded you can call model.predict and pass to it
// an input in the form of a Tensor. You can then store the result.
var results = await model.predict(inputTensor);
// Print the result to the console for us to inspect.
results.print();
results.data().then((dataArray)=>{
if (dataArray[1] > SPAM_THRESHOLD) {
domComment.classList.add('spam');
} else {
// Emit socket.io comment event for server to handle containing
// all the comment data you would need to render the comment on
// a remote client's front end.
socket.emit('comment', {
username: currentUserName,
timestamp: domComment.querySelectorAll('span')[1].innerText,
comment: domComment.querySelectorAll('p')[0].innerText
});
}
})
}
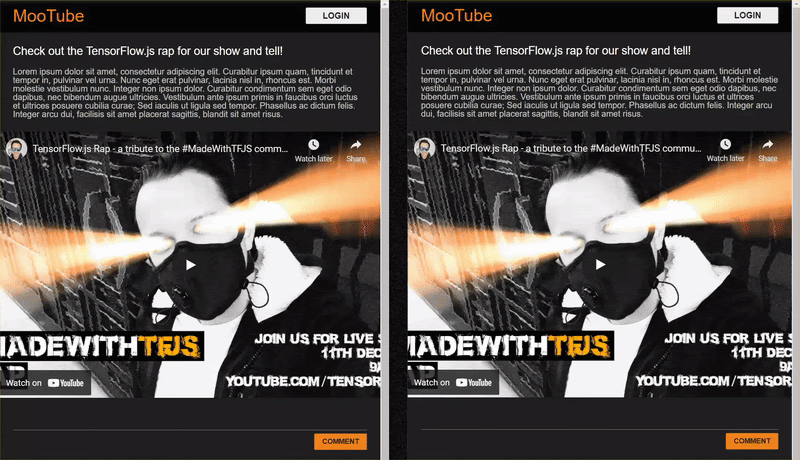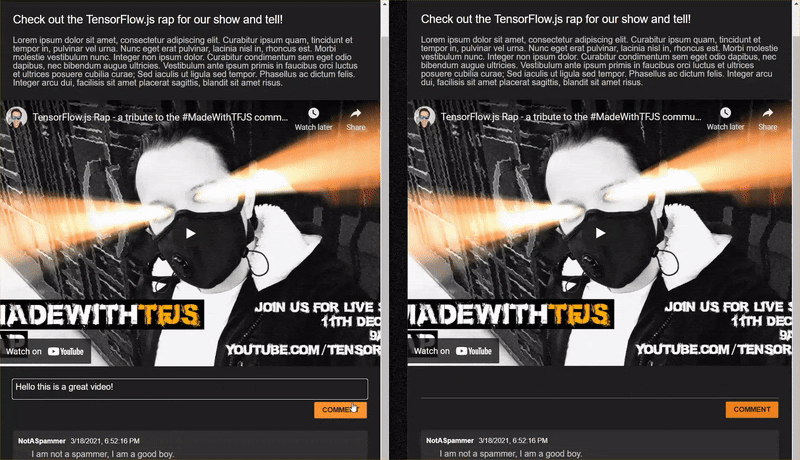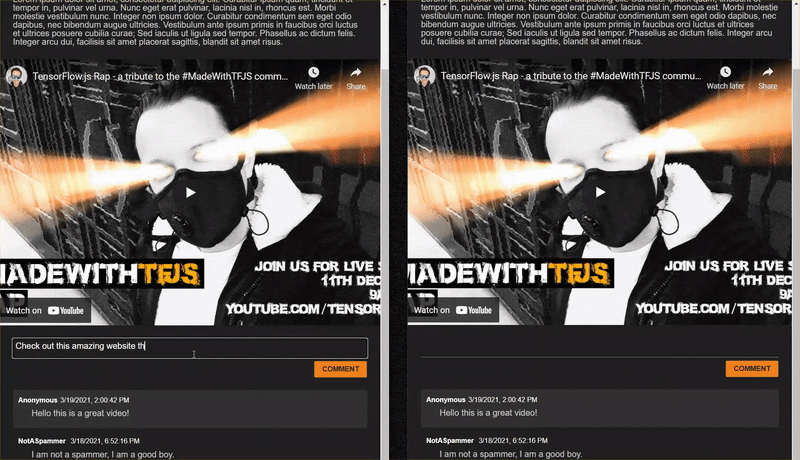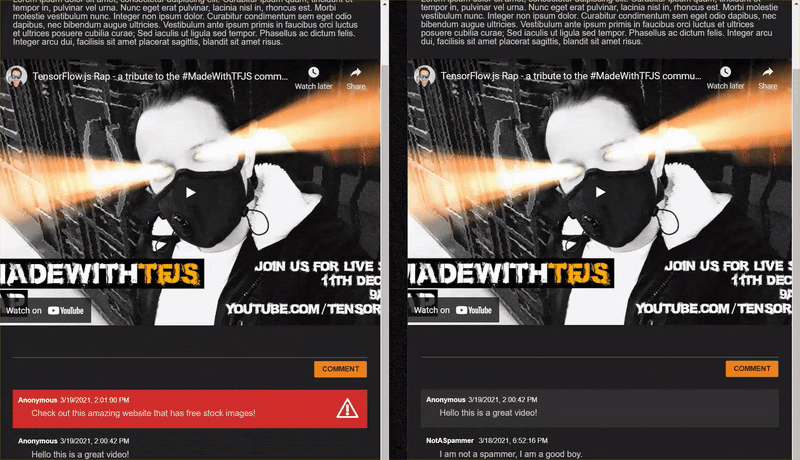
Muito bem! Se você seguiu corretamente, poderá abrir duas instâncias da página index.html.
Ao postar comentários que não são spam, você os verá renderizados no outro cliente quase instantaneamente. Se o comentário for spam, ele nunca será enviado e, em vez disso, será marcado como spam no front-end que o gerou somente assim:
12. Parabéns
Parabéns! Você deu os primeiros passos para usar machine learning com o TensorFlow.js no navegador da Web em um aplicativo real para detectar spam de comentários.
Faça um teste, teste-o usando vários comentários. Talvez você perceba que algo ainda vai funcionar. Você também perceberá que, se inserir uma frase com mais de 20 palavras, ela falhará porque o modelo espera 20 palavras como entrada.
Nesse caso, talvez seja necessário dividir frases longas em grupos de 20 palavras e, então, considerar a probabilidade de spam de cada subseção para decidir se serão exibidas ou não. Deixaremos isso como uma tarefa extra opcional para você experimentar, já que há muitas abordagens possíveis.
No próximo codelab, mostraremos como treinar novamente esse modelo com seus dados de comentários personalizados para casos extremos que ele não detecta ou até mesmo para mudar a expectativa de entrada do modelo para que ele possa lidar com frases que tenham mais de 20 palavras. Em seguida, exporte e use esse modelo com o TensorFlow.js.
Se, por algum motivo, você tiver problemas, compare seu código com esta versão completa disponível aqui e confira se você perdeu alguma informação.
Resumo
Neste codelab, você:
- Saber o que é o TensorFlow.js e quais modelos existem para o processamento de linguagem natural
- Criou um site fictício que permite comentários em tempo real para um site de exemplo.
- Carregou um modelo de machine learning pré-treinado adequado para detecção de spam de comentários pelo TensorFlow.js na página da Web.
- aprendeu a codificar frases para uso com o modelo de machine learning carregado e encapsular essa codificação dentro de um Tensor.
- Interpretou a resposta do modelo de machine learning para decidir se quer manter o comentário para análise e, caso contrário, encaminhá-lo ao servidor para redirecionamento para outros clientes conectados em tempo real.
A seguir
Agora que você já tem uma base de trabalho para começar, quais ideias criativas você pode adotar para ampliar esse modelo de machine learning para um caso de uso real?
Compartilhe o que você sabe conosco
É fácil estender o que você fez hoje para outros casos de uso de criativo. Além disso, recomendamos que você pense fora da caixa e continue a invadir.
Lembre-se de nos marcar nas mídias sociais usando a hashtag #MadeWithTFJS para que seu projeto tenha a chance de ser destacado no nosso blog do TensorFlow ou até mesmo em eventos futuros. Adoraríamos ver o que você fará.
Mais codelabs do TensorFlow.js para continuar seu aprendizado
- Confira a parte 2 desta série para saber como treinar novamente o modelo de spam de comentários e considerar os casos extremos que ele não detecta como spam no momento.
- Usar o Firebase Hosting para implantar e hospedar um modelo do TensorFlow.js em escala.
- Faça uma webcam inteligente usando um modelo predefinido de detecção de objetos com o TensorFlow.js
Sites para conferir
- Site oficial do TensorFlow.js
- Modelos prontos do TensorFlow.js
- API do TensorFlow.js
- TensorFlow.js Show & Tell: inspire-se e veja o que outras pessoas fizeram.