
1. ก่อนเริ่มต้น
ใน Codelab นี้ คุณจะได้เรียนรู้เกี่ยวกับ Convolution และเหตุผลที่ Convolution มีประสิทธิภาพมากในสถานการณ์ด้านคอมพิวเตอร์วิทัศน์
ใน Codelab ก่อนหน้า คุณได้สร้าง Deep Neural Network (DNN) อย่างง่ายสำหรับคอมพิวเตอร์วิทัศน์ของไอเทมแฟชั่น ข้อจำกัดนี้มีขึ้นเนื่องจากกำหนดให้ไอเทมเสื้อผ้าต้องเป็นสิ่งเดียวในรูปภาพและต้องอยู่ตรงกลาง
แน่นอนว่านี่ไม่ใช่สถานการณ์ที่สมจริง คุณจะต้องทำให้ DNN ระบุเสื้อผ้าในรูปภาพที่มีวัตถุอื่นๆ หรือในรูปภาพที่ไม่ได้วางเสื้อผ้าไว้ตรงกลางได้ หากต้องการทำเช่นนี้ คุณจะต้องใช้การสังวัตนาการ
ข้อกำหนดเบื้องต้น
โค้ดแล็บนี้สร้างขึ้นจากงานที่ทำเสร็จแล้วใน 2 ตอนก่อนหน้า ได้แก่ มาทำความรู้จักกับ "Hello, World" ของแมชชีนเลิร์นนิง และสร้างโมเดลคอมพิวเตอร์วิทัศน์ โปรดทำ Codelab เหล่านั้นให้เสร็จก่อนดำเนินการต่อ
สิ่งที่คุณจะได้เรียนรู้
- การสังวัตนาคืออะไร
- วิธีสร้างแผนที่ฟีเจอร์
- การรวมกลุ่มคืออะไร
สิ่งที่คุณจะสร้าง
- แผนที่ฟีเจอร์ของรูปภาพ
สิ่งที่คุณต้องมี
คุณดูโค้ดสำหรับ Codelab ที่เหลือได้โดยเรียกใช้ใน Colab
นอกจากนี้ คุณจะต้องติดตั้ง TensorFlow และไลบรารีที่คุณติดตั้งใน Codelab ก่อนหน้าด้วย
2. การสังวัตคืออะไร
การสังวัตนาการคือฟิลเตอร์ที่ผ่านรูปภาพ ประมวลผล และดึงฟีเจอร์ที่สำคัญออกมา
สมมติว่าคุณมีรูปภาพคนใส่รองเท้าผ้าใบ คุณจะตรวจจับได้อย่างไรว่ามีรองเท้าผ้าใบอยู่ในรูปภาพ หากต้องการให้โปรแกรม "เห็น" รูปภาพเป็นรองเท้าผ้าใบ คุณจะต้องดึงฟีเจอร์ที่สำคัญและเบลอฟีเจอร์ที่ไม่จำเป็น ซึ่งเรียกว่าการแมปฟีเจอร์
กระบวนการแมปฟีเจอร์นั้นในทางทฤษฎีแล้วทำได้ง่ายๆ คุณจะสแกนทุกพิกเซลในรูปภาพ แล้วดูพิกเซลที่อยู่ข้างเคียง คุณคูณค่าของพิกเซลเหล่านั้นด้วยค่าถ่วงน้ำหนักที่เทียบเท่าในตัวกรอง
เช่น
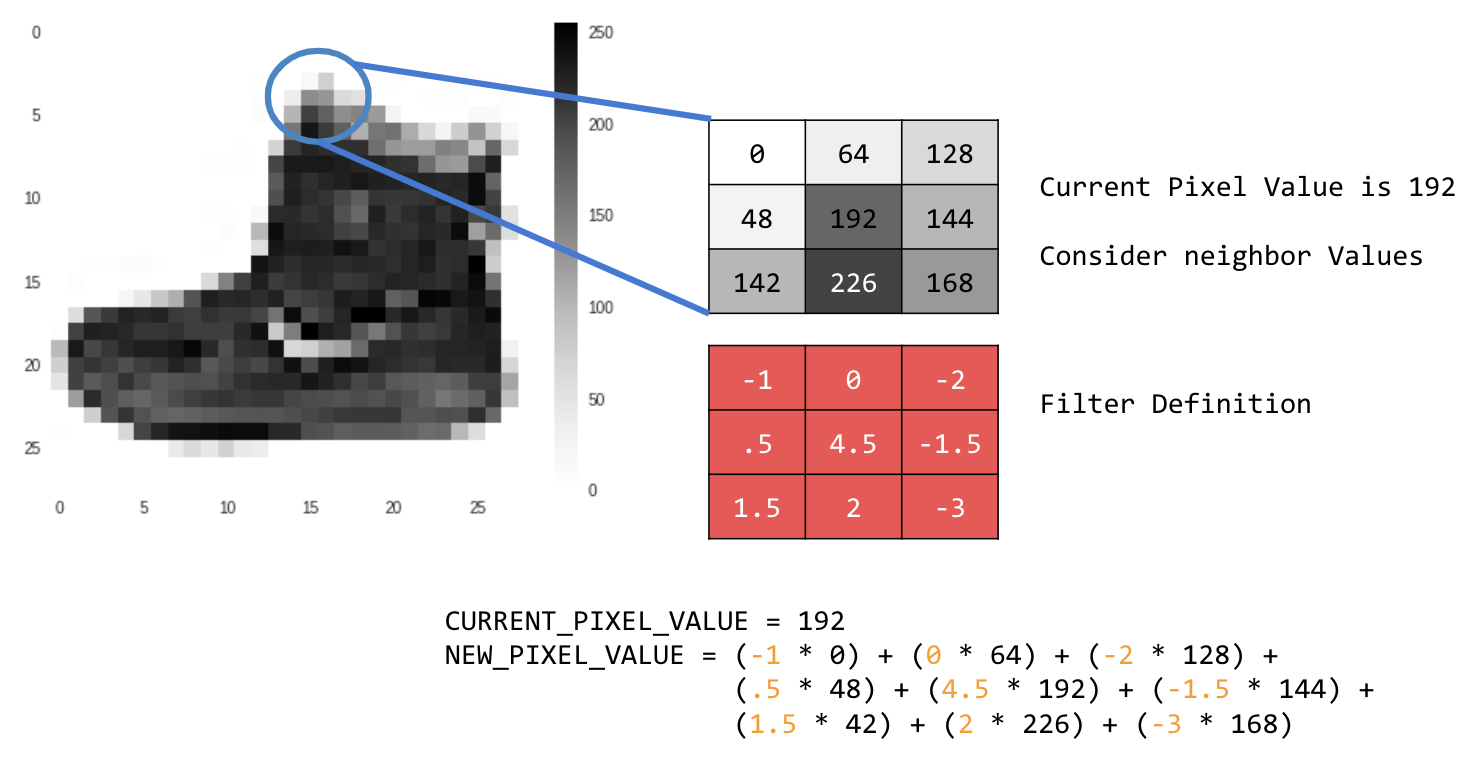
ในกรณีนี้ จะมีการระบุเมทริกซ์การแปลงแบบ 3x3 หรือเคอร์เนลของรูปภาพ
ค่าพิกเซลปัจจุบันคือ 192 คุณสามารถคำนวณค่าของพิกเซลใหม่ได้โดยดูค่าที่อยู่ข้างเคียง คูณค่าเหล่านั้นด้วยค่าที่ระบุในตัวกรอง และกำหนดค่าพิกเซลใหม่เป็นจำนวนสุดท้าย
ตอนนี้ก็ถึงเวลาสำรวจว่าการทำงานของ Convolution เป็นอย่างไรด้วยการสร้าง Convolution พื้นฐานบนรูปภาพระดับสีเทาแบบ 2 มิติ
คุณจะสาธิตโดยใช้รูปภาพการขึ้นจาก SciPy เป็นภาพในตัวที่สวยงามซึ่งมีหลายมุมและเส้น
3. เริ่มเขียนโค้ด
เริ่มต้นด้วยการนำเข้าไลบรารี Python และรูปภาพการขึ้นไป
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
จากนั้นใช้ไลบรารี Pyplot matplotlib เพื่อวาดรูปภาพเพื่อให้คุณทราบว่ารูปภาพมีลักษณะอย่างไร
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

คุณจะเห็นว่ารูปภาพนี้เป็นภาพบันได คุณลองใช้และแยกฟีเจอร์ต่างๆ ได้มากมาย เช่น มีเส้นแนวตั้งที่ชัดเจน
ระบบจะจัดเก็บรูปภาพเป็นอาร์เรย์ NumPy ดังนั้นเราจึงสร้างรูปภาพที่แปลงแล้วได้โดยเพียงแค่คัดลอกอาร์เรย์นั้น ตัวแปร size_x และ size_y จะเก็บขนาดของรูปภาพเพื่อให้คุณวนซ้ำได้ในภายหลัง
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. สร้างเมทริกซ์การบิด
ก่อนอื่น ให้สร้างเมทริกซ์การแปลง (หรือเคอร์เนล) เป็นอาร์เรย์ 3x3 ดังนี้
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
ตอนนี้ให้คำนวณพิกเซลเอาต์พุต วนซ้ำในรูปภาพโดยเว้นขอบ 1 พิกเซล และคูณค่าของพิกเซลข้างเคียงแต่ละพิกเซลของพิกเซลปัจจุบันด้วยค่าที่กำหนดไว้ในตัวกรอง
ซึ่งหมายความว่าเพื่อนบ้านของพิกเซลปัจจุบันที่อยู่เหนือและทางซ้ายของพิกเซลจะถูกคูณด้วยรายการด้านซ้ายบนในตัวกรอง จากนั้นคูณผลลัพธ์ด้วยค่าถ่วงน้ำหนัก และตรวจสอบว่าผลลัพธ์อยู่ในช่วง 0 ถึง 255
สุดท้าย ให้โหลดค่าใหม่ลงในรูปภาพที่แปลงแล้ว
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. ตรวจสอบผลลัพธ์
ตอนนี้ ให้พล็อตรูปภาพเพื่อดูผลลัพธ์ของการส่งผ่านตัวกรองเหนือรูปภาพ
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

พิจารณาค่าตัวกรองต่อไปนี้และผลกระทบที่มีต่อรูปภาพ
การใช้ [-1,0,1,-2,0,2,-1,0,1] จะทำให้ได้ชุดเส้นแนวตั้งที่ชัดเจนมาก
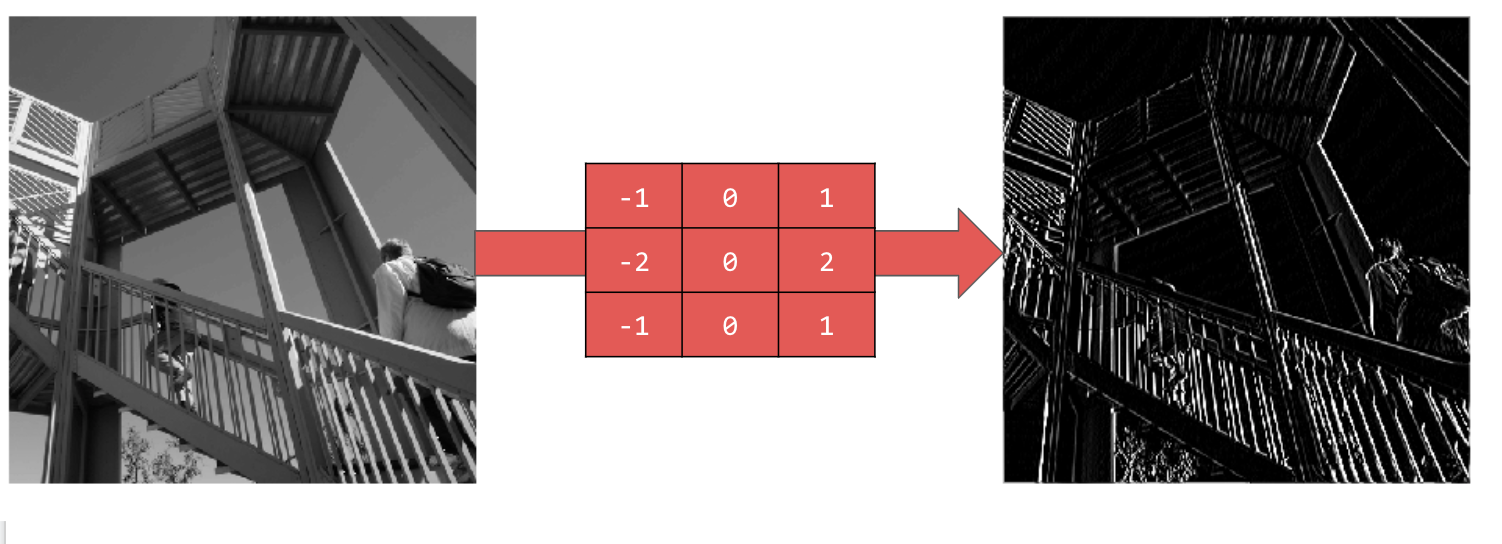
การใช้ [-1,-2,-1,0,0,0,1,2,1] จะทำให้ได้เส้นแนวนอน
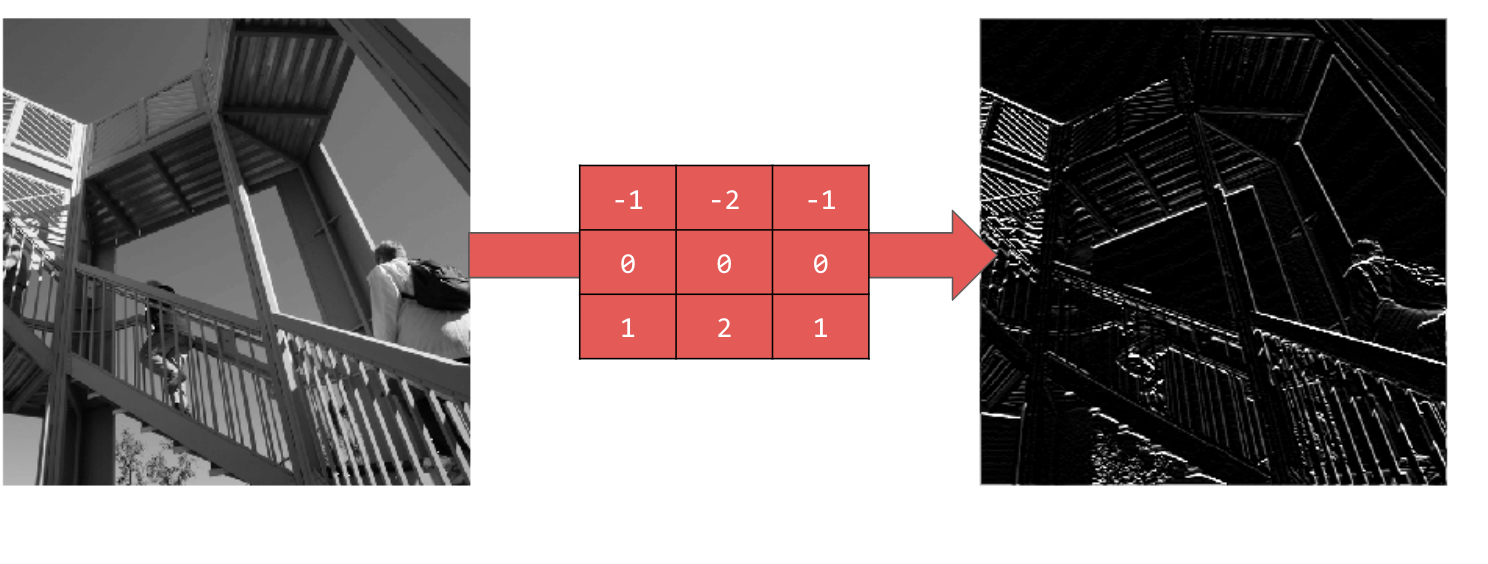
ลองใช้ค่าต่างๆ นอกจากนี้ ให้ลองใช้ฟิลเตอร์ขนาดอื่นๆ เช่น 5x5 หรือ 7x7
6. ทำความเข้าใจการรวมกลุ่ม
เมื่อระบุฟีเจอร์ที่สำคัญของรูปภาพแล้ว คุณควรทำอย่างไร คุณใช้แผนที่ฟีเจอร์ที่ได้เพื่อจัดประเภทรูปภาพอย่างไร
พูลลิ่งช่วยในการตรวจหาฟีเจอร์ได้เป็นอย่างมากเช่นเดียวกับ Convolution เลเยอร์การรวมจะลดปริมาณข้อมูลโดยรวมในรูปภาพขณะที่ยังคงรักษาฟีเจอร์ที่ตรวจพบว่ามีอยู่
การรวมกลุ่มมีหลายประเภท แต่คุณจะใช้ประเภทที่เรียกว่าการรวมกลุ่มสูงสุด (Max)
วนซ้ำในรูปภาพ และที่แต่ละจุด ให้พิจารณาพิกเซลและพิกเซลที่อยู่ติดกันทางด้านขวา ด้านล่าง และด้านขวาล่าง จากนั้นนำค่าที่ใหญ่ที่สุด (จึงเรียกว่าการรวมค่าสูงสุด) มาใส่ในรูปภาพใหม่ ดังนั้น รูปภาพใหม่จะมีขนาด 1 ใน 4 ของรูปภาพเก่า 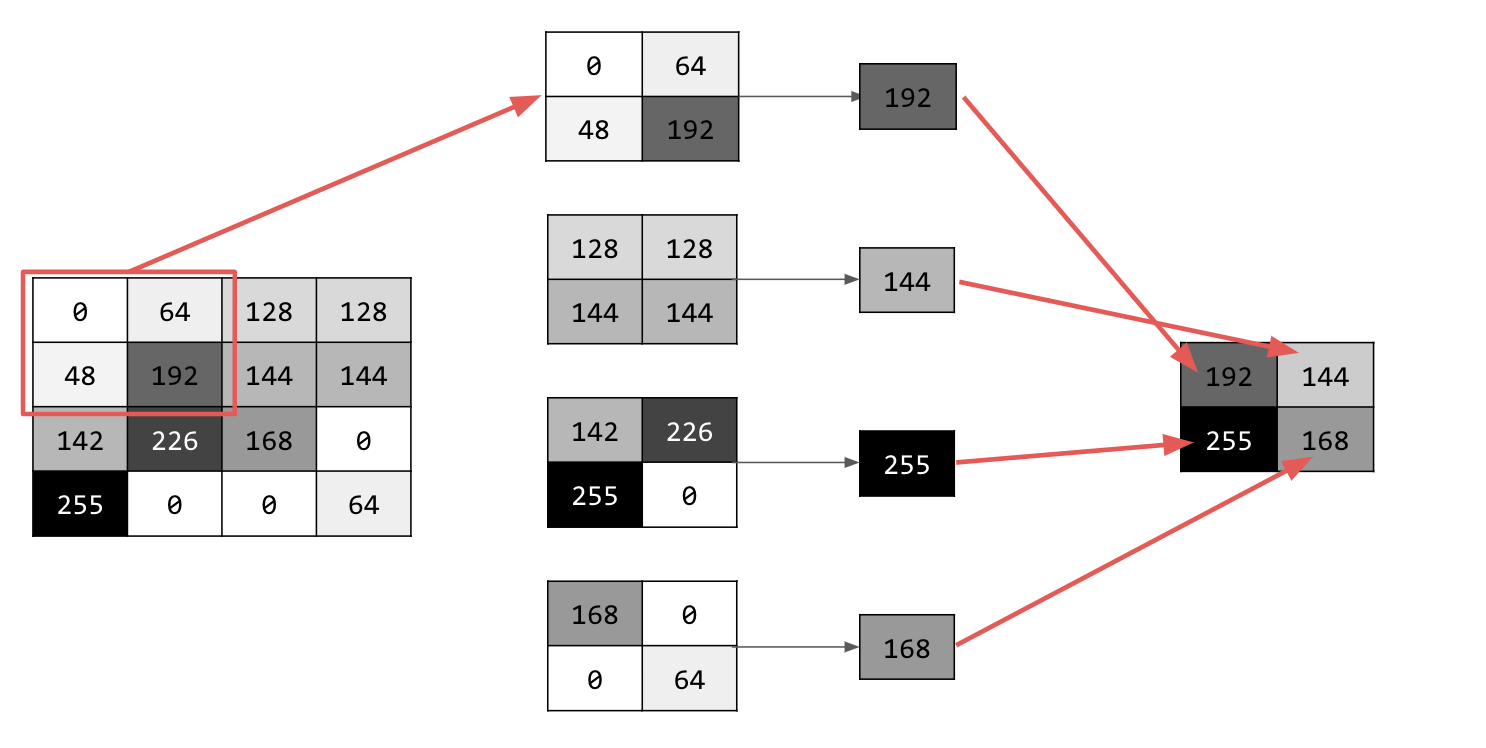
7. เขียนโค้ดสำหรับการรวม
โค้ดต่อไปนี้จะแสดงการจัดกลุ่ม (2, 2) เรียกใช้เพื่อดูเอาต์พุต
คุณจะเห็นว่าแม้ว่ารูปภาพจะมีขนาดเพียง 1 ใน 4 ของรูปภาพต้นฉบับ แต่ก็ยังคงมีฟีเจอร์ทั้งหมดไว้
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

สังเกตแกนของพล็อตนั้น ตอนนี้รูปภาพมีขนาด 256x256 ซึ่งเป็น 1 ใน 4 ของขนาดเดิม และฟีเจอร์ที่ตรวจพบได้รับการปรับปรุงแม้ว่าตอนนี้รูปภาพจะมีข้อมูลน้อยลงก็ตาม
8. ขอแสดงความยินดี
คุณสร้างโมเดลคอมพิวเตอร์วิทัศน์แรกแล้ว หากต้องการดูวิธีปรับปรุงโมเดลการมองเห็นด้วยคอมพิวเตอร์เพิ่มเติม ให้ไปที่สร้างเครือข่ายประสาทแบบคอนโวลูชัน (CNN) เพื่อปรับปรุงการมองเห็นด้วยคอมพิวเตอร์