
1. Прежде чем начать
В этой лабораторной работе вы узнаете о свертках и о том, почему они так эффективны в сценариях компьютерного зрения.
В предыдущей лабораторной работе вы создали простую глубокую нейронную сеть (DNN) для компьютерного зрения на предметах одежды. Это было ограничено, поскольку требовалось, чтобы предмет одежды был единственным объектом на изображении и располагался по центру.
Конечно, это нереалистичный сценарий. Вам нужно, чтобы ваша DNN могла идентифицировать предмет одежды на снимках среди других объектов или там, где он не находится в центре. Для этого вам понадобятся свёртки.
Предпосылки
Эта практическая работа основана на работе, выполненной в двух предыдущих частях: «Здравствуйте, мир!» машинного обучения и «Создание модели компьютерного зрения ». Пожалуйста, выполните эти практическую работу, прежде чем продолжить.
Чему вы научитесь
- Что такое извилины
- Как создать карту объектов
- Что такое объединение?
Что вы построите
- Карта характеристик изображения
Что вам понадобится
Код остальной части лабораторной работы можно найти в Colab .
Вам также понадобится установленный TensorFlow и библиотеки, которые вы установили в предыдущей лабораторной работе.
2. Что такое извилины?
Свёртка — это фильтр, который проходит по изображению, обрабатывает его и извлекает важные особенности.
Допустим, у вас есть изображение человека в кроссовке. Как определить, что на изображении есть кроссовка? Чтобы программа «распознала» изображение как кроссовку, вам нужно выделить важные детали и размыть несущественные. Это называется картированием признаков .
Процесс картирования признаков теоретически прост. Вы сканируете каждый пиксель изображения, а затем анализируете соседние с ним пиксели. Значения этих пикселей умножаются на эквивалентные веса фильтра.
Например:
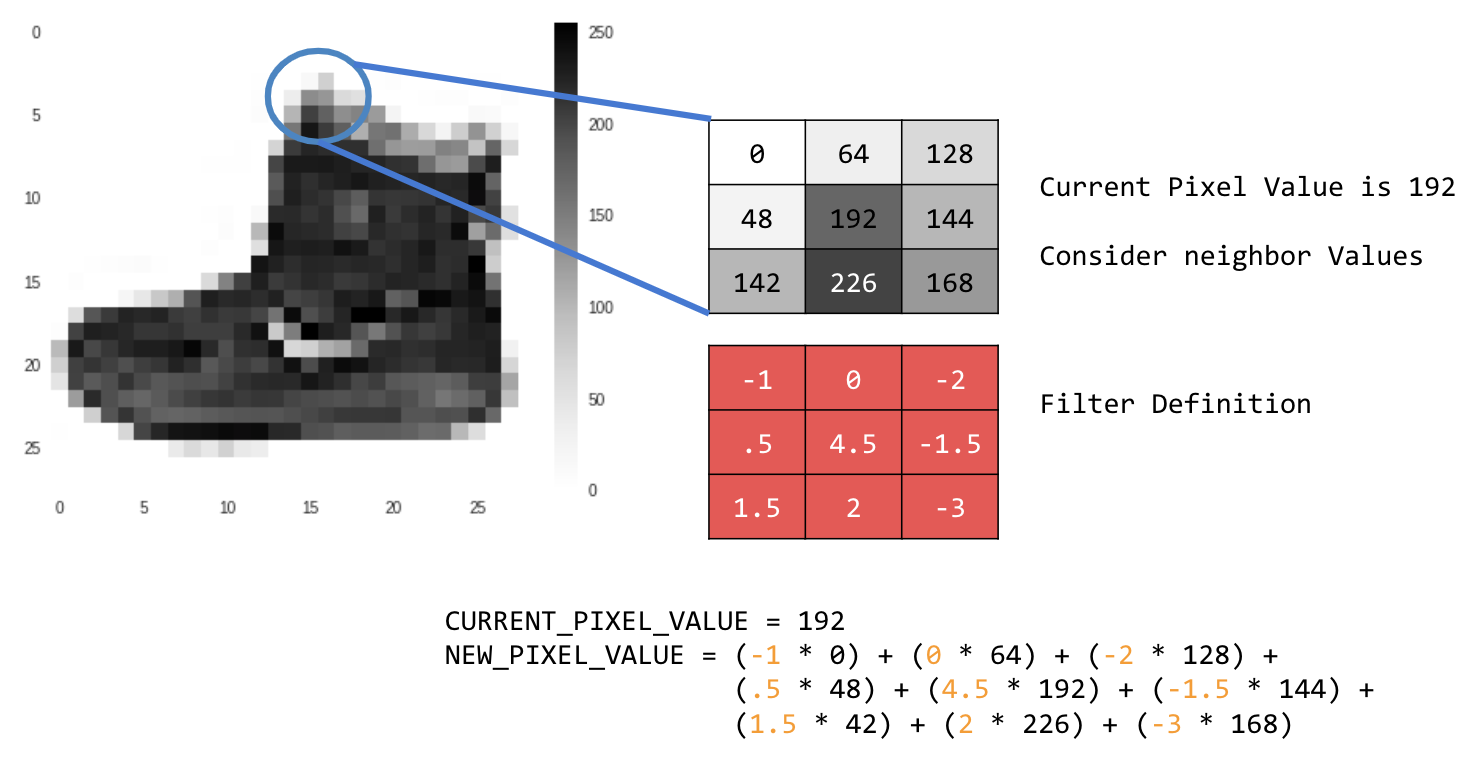
В этом случае задается матрица свертки 3x3 или ядро изображения.
Текущее значение пикселя равно 192. Вы можете рассчитать значение нового пикселя, посмотрев на значения соседних пикселов, умножив их на значения, указанные в фильтре, и сделав новое значение пикселя окончательной суммой.
Теперь пришло время изучить, как работают свертки, создав простую свертку на двумерном изображении в оттенках серого.
Вы продемонстрируете это на примере изображения подъёма из SciPy . Это прекрасное встроенное изображение с множеством углов и линий.
3. Начните кодировать
Начнем с импорта некоторых библиотек Python и изображения восхождения:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
Далее воспользуйтесь библиотекой Pyplot matplotlib чтобы нарисовать изображение и увидеть, как оно выглядит:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

Видно, что это изображение лестничного пролёта. На нём есть множество деталей, которые можно попытаться выделить. Например, чёткие вертикальные линии.
Изображение хранится в виде массива NumPy, поэтому мы можем создать преобразованное изображение, просто скопировав его. Переменные size_x и size_y будут содержать размеры изображения, чтобы вы могли перебрать его в цикле.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. Создайте матрицу свертки
Сначала создадим матрицу свертки (или ядро) в виде массива 3x3:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
Теперь вычислим количество выходных пикселей. Проходим по изображению, оставляя отступ в 1 пиксель, и умножаем каждого из соседей текущего пикселя на значение, заданное в фильтре.
Это означает, что сосед текущего пикселя, расположенный выше и левее него, будет умножен на верхний левый элемент фильтра. Затем результат умножается на вес и результат должен находиться в диапазоне от 0 до 255.
Наконец, загрузите новое значение в преобразованное изображение:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. Изучите результаты.
Теперь постройте график изображения, чтобы увидеть эффект от пропускания по нему фильтра:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

Рассмотрим следующие значения фильтра и их влияние на изображение.
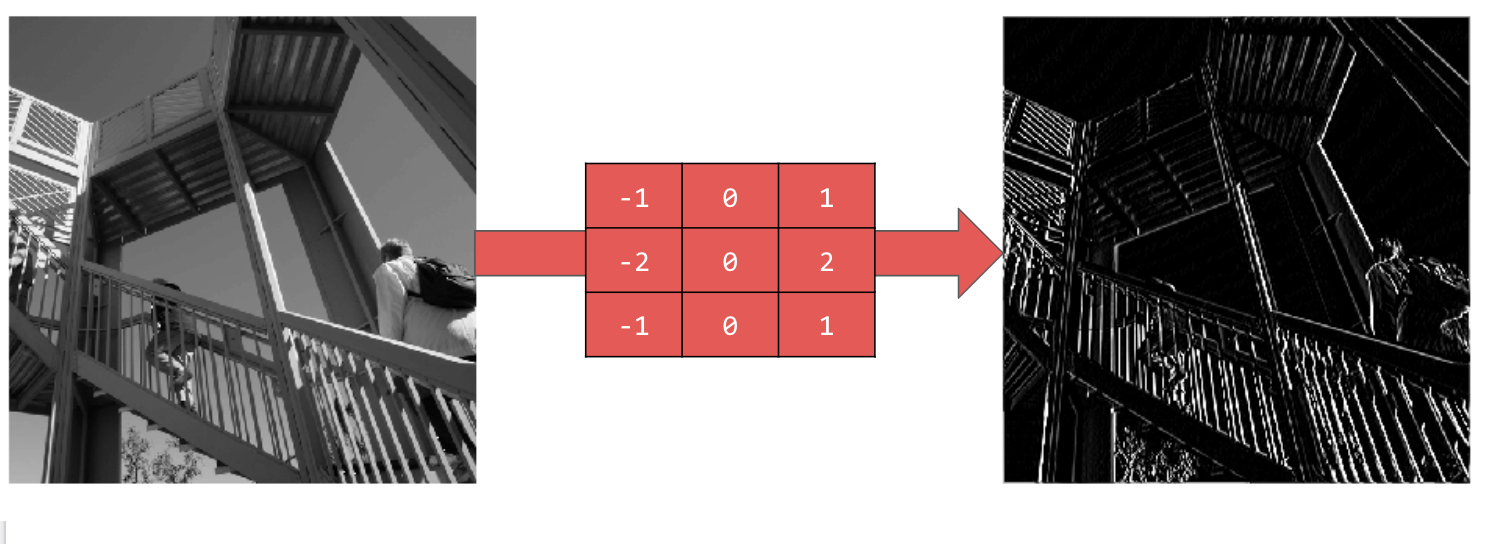
Использование [-1,0,1,-2,0,2,-1,0,1] дает очень сильный набор вертикальных линий:
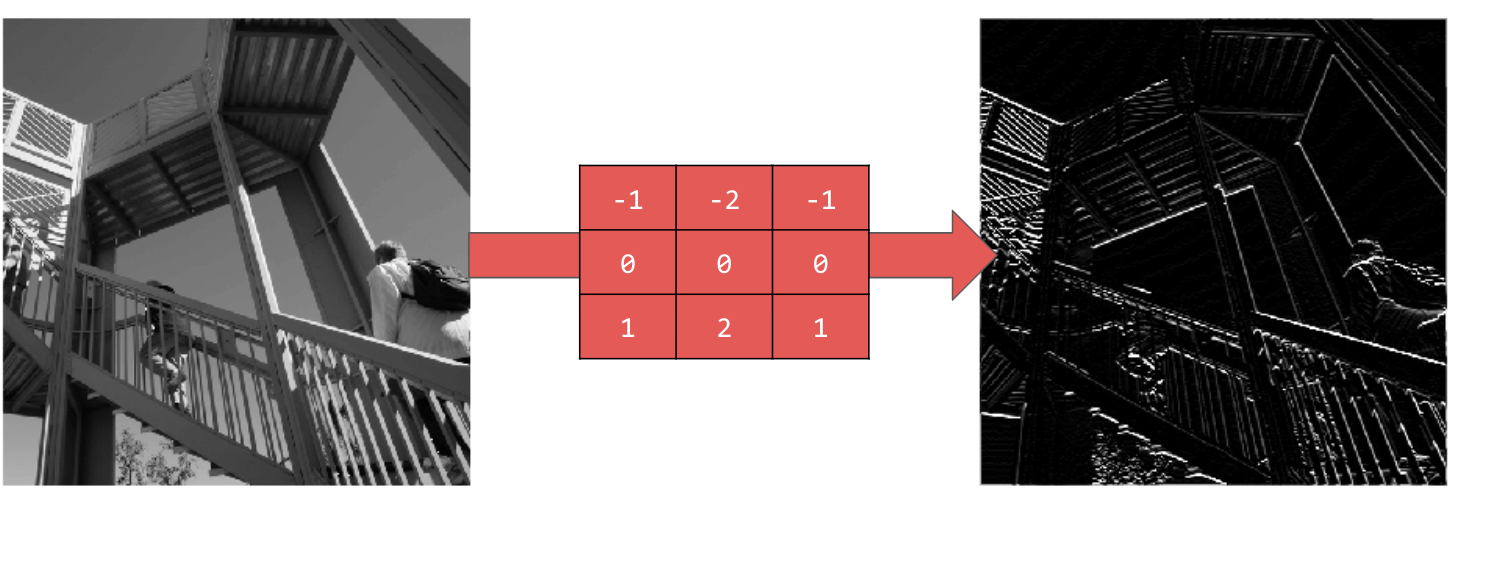
Использование [-1,-2,-1,0,0,0,1,2,1] дает горизонтальные линии:
Исследуйте разные значения! Также попробуйте фильтры разных размеров, например, 5x5 или 7x7.
6. Понимание объединения
Теперь, когда вы определили основные характеристики изображения, что делать дальше? Как использовать полученную карту характеристик для классификации изображений?
Подобно свёрткам, пулирование значительно облегчает обнаружение признаков. Пулинг слоёв сокращает общий объём информации на изображении, сохраняя при этом обнаруженные признаки.
Существует несколько различных типов объединения, но вы будете использовать один, который называется «Максимальное (макс) объединение».
Пройдитесь по изображению и в каждой точке рассмотрите пиксель и его ближайших соседей справа, снизу и справа снизу. Возьмите самый большой из них (и, следовательно, максимальный пул) и загрузите его в новое изображение. Таким образом, новое изображение будет вчетверо меньше старого. 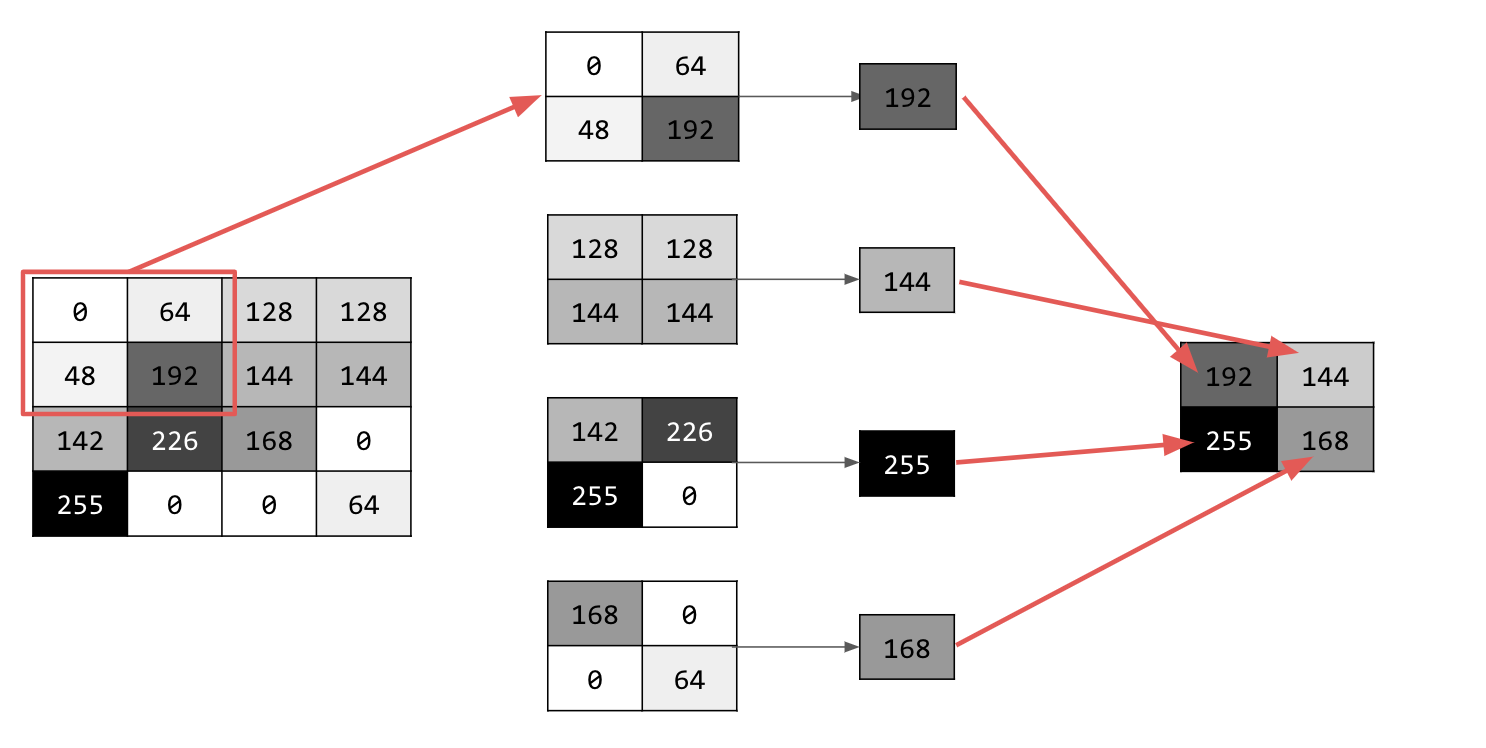
7. Напишите код для объединения
Следующий код демонстрирует объединение (2, 2). Запустите его, чтобы увидеть результат.
Вы увидите, что, хотя изображение в четыре раза меньше оригинала, оно сохранило все его особенности.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

Обратите внимание на оси графика. Изображение теперь имеет размер 256x256, что составляет одну четверть от исходного размера, а обнаруженные объекты улучшились, несмотря на то, что теперь на изображении меньше данных.
8. Поздравления
Вы создали свою первую модель компьютерного зрения! Чтобы узнать, как улучшить свои модели компьютерного зрения, перейдите к разделу «Создание свёрточных нейронных сетей (CNN) для улучшения компьютерного зрения» .