
1. Antes de começar
Neste codelab, você vai aprender sobre convoluções e por que elas são tão poderosas em cenários de visão computacional.
No codelab anterior, você criou uma rede neural profunda (DNN) simples para visão computacional de itens de moda. Isso era limitado porque exigia que a peça de roupa fosse a única coisa na foto e estivesse centralizada.
Claro que esse não é um cenário realista. É importante que sua DNN consiga identificar a peça de roupa em fotos com outros objetos ou em que ela não esteja posicionada na frente e no centro. Para isso, use convoluções.
Pré-requisitos
Este codelab se baseia no trabalho concluído em duas partes anteriores: Conheça o "Hello, World" do machine learning e Crie um modelo de visão computacional. Conclua esses codelabs antes de continuar.
O que você vai aprender
- O que são convoluções
- Como criar um mapa de recursos
- O que é pooling?
O que você vai criar
- Um mapa de recursos de uma imagem
O que é necessário
O código do restante do codelab pode ser executado no Colab.
Você também vai precisar do TensorFlow instalado e das bibliotecas que instalou no codelab anterior.
2. O que são convoluções?
Uma convolução é um filtro que passa por uma imagem, a processa e extrai os atributos importantes.
Digamos que você tenha uma imagem de uma pessoa usando um tênis. Como você detectaria que um tênis está presente na imagem? Para que seu programa "veja" a imagem como um tênis, você precisa extrair os recursos importantes e desfocar os recursos desnecessários. Isso é chamado de mapeamento de recursos.
O processo de mapeamento de recursos é teoricamente simples. Você vai verificar cada pixel da imagem e analisar os pixels vizinhos. Multiplique os valores desses pixels pelos pesos equivalentes em um filtro.
Exemplo:
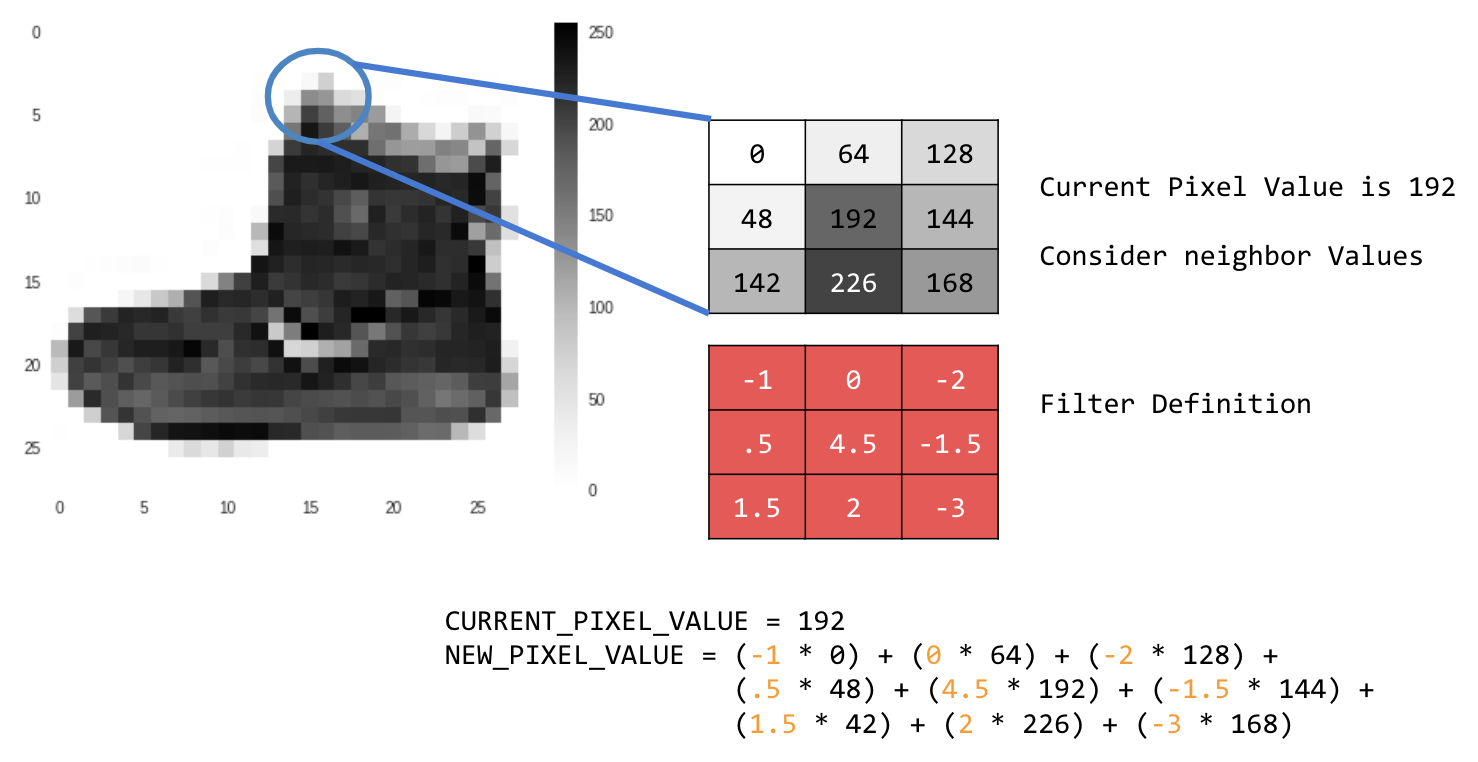
Nesse caso, uma matriz de convolução 3x3, ou kernel de imagem, é especificada.
O valor atual do pixel é 192. Para calcular o valor do novo pixel, analise os valores vizinhos, multiplique-os pelos valores especificados no filtro e defina o valor do novo pixel como o valor final.
Agora é hora de entender como as convoluções funcionam criando uma convolução básica em uma imagem em escala de cinza 2D.
Você vai demonstrar isso com a imagem de ascensão do SciPy. É uma imagem integrada com muitos ângulos e linhas.
3. Iniciar programação
Comece importando algumas bibliotecas do Python e a imagem da ascensão:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
Em seguida, use a biblioteca Pyplot matplotlib para desenhar a imagem e saber como ela é:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

É possível ver que é uma imagem de uma escada. Há muitos recursos que você pode testar e isolar. Por exemplo, há linhas verticais fortes.
A imagem é armazenada como uma matriz NumPy. Portanto, podemos criar a imagem transformada apenas copiando essa matriz. As variáveis size_x e size_y vão armazenar as dimensões da imagem para que você possa fazer um loop nela mais tarde.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. Criar a matriz de convolução
Primeiro, crie uma matriz de convolução (ou kernel) como uma matriz 3x3:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
Agora, calcule os pixels de saída. Itere sobre a imagem, deixando uma margem de 1 pixel, e multiplique cada um dos vizinhos do pixel atual pelo valor definido no filtro.
Isso significa que o vizinho do pixel atual acima e à esquerda dele será multiplicado pelo item superior esquerdo no filtro. Em seguida, multiplique o resultado pelo peso e verifique se ele está no intervalo de 0 a 255.
Por fim, carregue o novo valor na imagem transformada:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. Analisar os resultados
Agora, crie o gráfico da imagem para ver o efeito da passagem do filtro sobre ela:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

Considere os seguintes valores de filtro e o impacto deles na imagem.
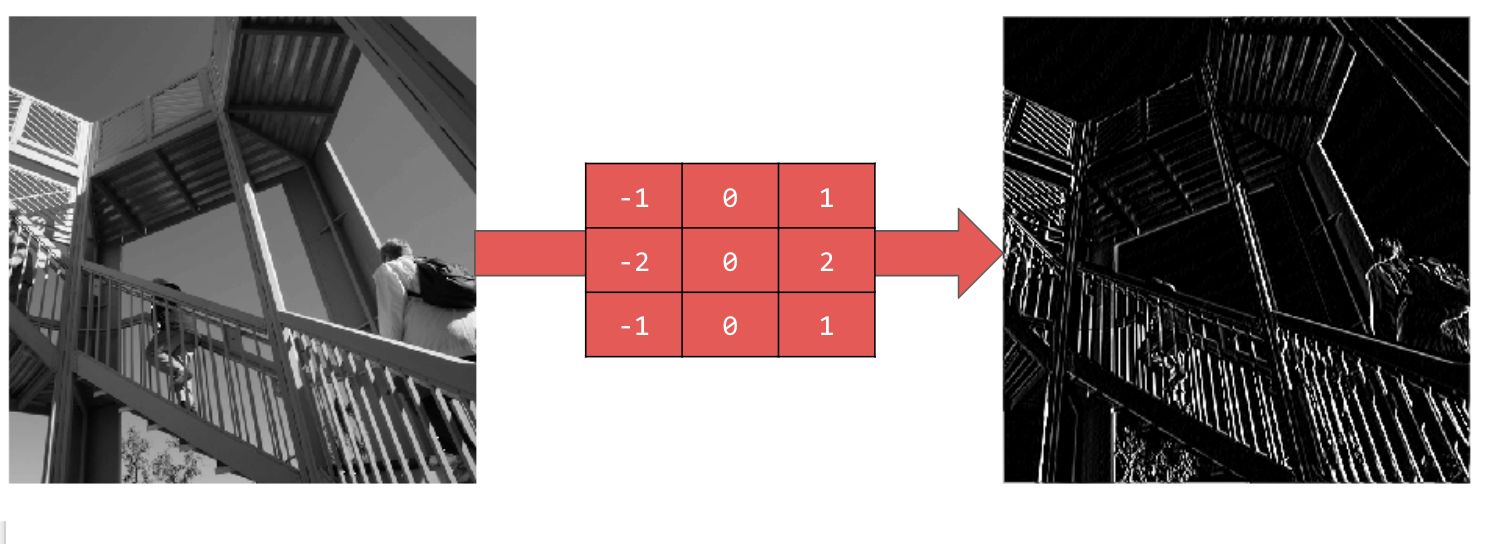
Usar [-1,0,1,-2,0,2,-1,0,1] oferece um conjunto muito forte de linhas verticais:
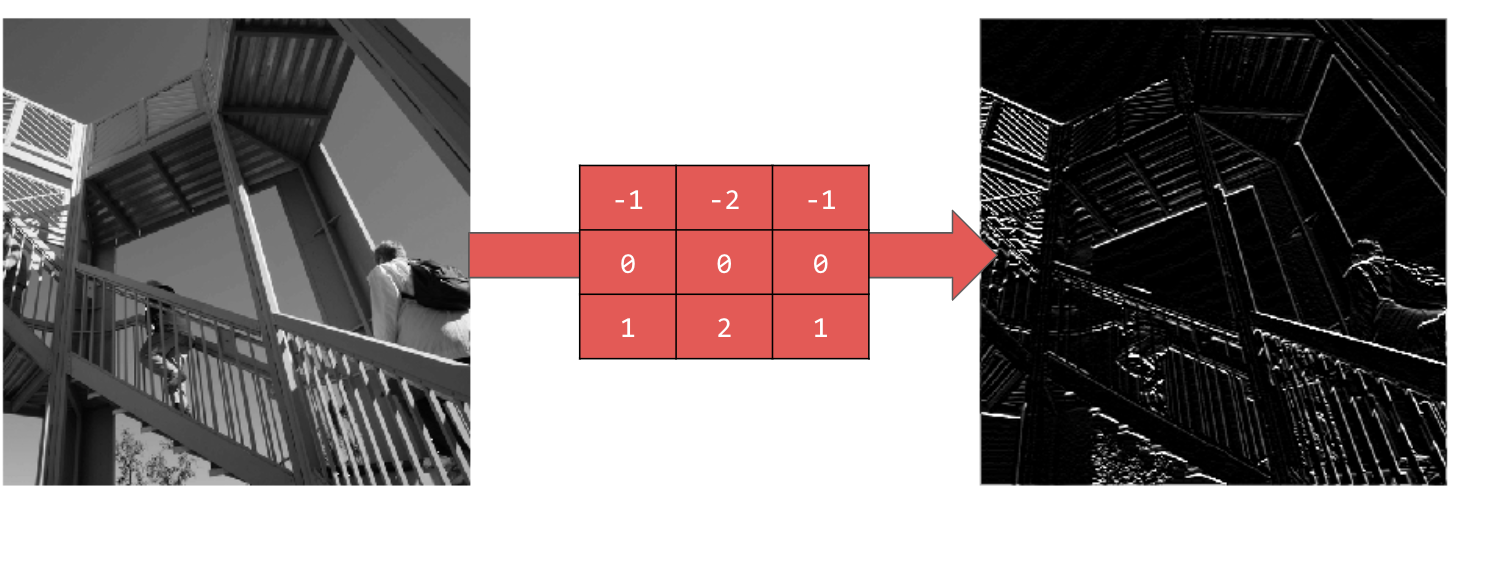
Usar [-1,-2,-1,0,0,0,1,2,1] gera linhas horizontais:
Explore valores diferentes! Além disso, teste filtros de tamanhos diferentes, como 5x5 ou 7x7.
6. Noções básicas sobre o agrupamento
Agora que você identificou os recursos essenciais da imagem, o que fazer? Como usar o mapa de recursos resultante para classificar imagens?
Assim como as convoluções, o pooling ajuda muito na detecção de recursos. As camadas de pooling reduzem a quantidade geral de informações em uma imagem, mantendo os recursos detectados como presentes.
Existem vários tipos diferentes de pooling, mas você vai usar um chamado pooling máximo (Max).
Itere sobre a imagem e, em cada ponto, considere o pixel e os vizinhos imediatos à direita, abaixo e abaixo à direita. Pegue o maior deles (daí o max pooling) e carregue na nova imagem. Assim, a nova imagem terá um quarto do tamanho da antiga. 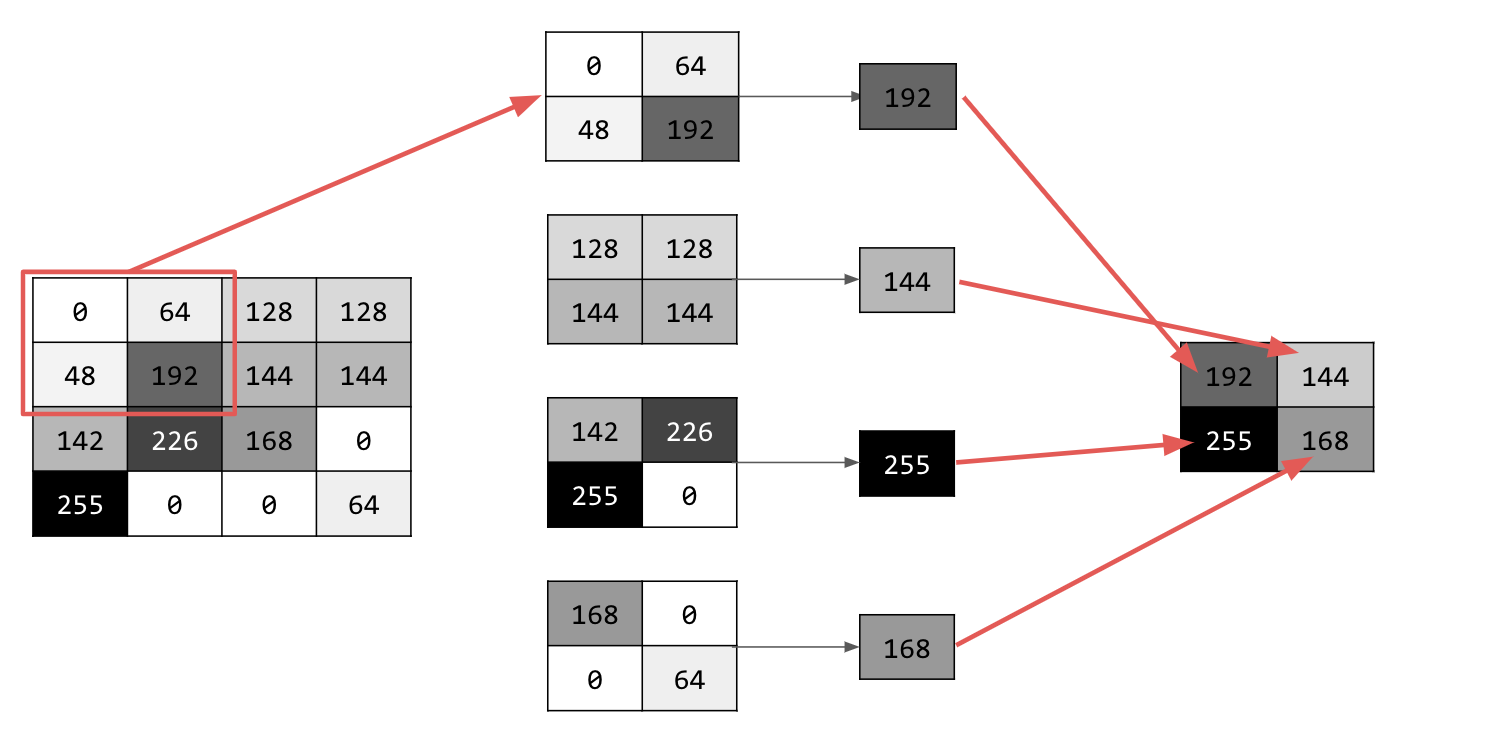
7. Escrever código para pooling
O código a seguir mostra um agrupamento (2, 2). Execute para conferir a saída.
Você vai notar que, embora a imagem tenha um quarto do tamanho da original, ela manteve todos os recursos.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

Observe os eixos desse gráfico. A imagem agora tem 256x256, um quarto do tamanho original, e os recursos detectados foram aprimorados, apesar de haver menos dados na imagem.
8. Parabéns
Você criou seu primeiro modelo de visão computacional. Para saber como melhorar ainda mais seus modelos de visão computacional, acesse Criar redes neurais convolucionais (CNNs) para melhorar a visão computacional.