
1. 시작하기 전에
이 Codelab에서는 컨볼루션과 컨볼루션이 컴퓨터 비전 시나리오에서 강력한 이유를 알아봅니다.
이전 Codelab에서는 패션 상품의 컴퓨터 비전을 위한 간단한 심층신경망 (DNN)을 만들었습니다. 의류 상품이 사진에 유일하게 등장해야 하고 중앙에 배치되어야 한다는 요구사항이 있었기 때문에 제한되었습니다.
물론 이는 현실적인 시나리오가 아닙니다. DNN이 다른 객체가 있는 사진이나 전면 중앙에 배치되지 않은 사진에서 의류를 식별할 수 있어야 합니다. 이를 위해서는 컨볼루션을 사용해야 합니다.
기본 요건
이 Codelab은 이전 두 편인 머신러닝의 'Hello, World' 시작하기와 컴퓨터 비전 모델 빌드에서 완료한 작업을 기반으로 합니다. 계속하기 전에 해당 Codelab을 완료하세요.
학습할 내용
- 컨볼루션이란 무엇인가요?
- 기능 맵을 만드는 방법
- 풀링이란 무엇인가요?
빌드할 항목
- 이미지의 특징 지도
필요한 항목
나머지 Codelab의 코드는 Colab에서 실행할 수 있습니다.
TensorFlow도 설치해야 하며 이전 Codelab에서 설치한 라이브러리도 필요합니다.
2. 컨볼루션이란 무엇인가요?
컨볼루션은 이미지를 전달 및 처리하고 중요한 특성을 추출하는 필터입니다.
스니커즈를 착용한 사람의 이미지가 있다고 가정해 보겠습니다. 이미지에 운동화가 있는지 어떻게 감지할 수 있을까요? 프로그램이 이미지를 운동화로 인식하려면 중요한 특징을 추출하고 중요하지 않은 특징은 흐리게 처리해야 합니다. 이를 기능 매핑이라고 합니다.
기능 매핑 프로세스는 이론적으로 간단합니다. 이미지의 모든 픽셀을 스캔한 다음 인접한 픽셀을 살펴봅니다. 이러한 픽셀의 값에 필터의 해당 가중치를 곱합니다.
예를 들면 다음과 같습니다.
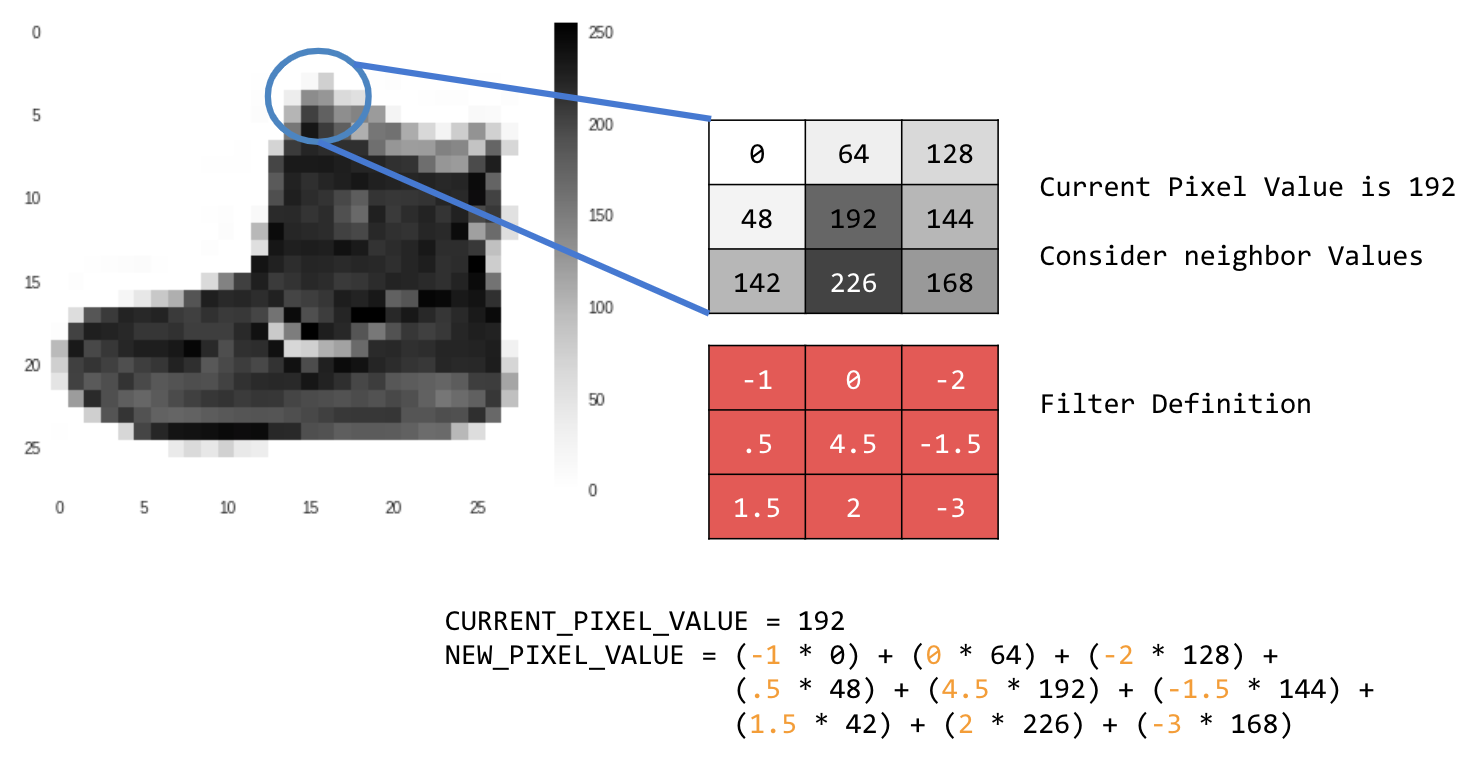
이 경우 3x3 컨볼루션 행렬 또는 이미지 커널이 지정됩니다.
현재 픽셀 값은 192입니다. 이웃 값을 살펴보고 필터에 지정된 값을 곱한 후 새 픽셀 값을 최종 금액으로 만들어 새 픽셀 값을 계산할 수 있습니다.
이제 2D 그레이 스케일 이미지에서 기본 컨볼루션을 만들어 컨볼루션의 작동 방식을 살펴볼 차례입니다.
SciPy의 ascent 이미지를 사용하여 이를 보여줍니다. 각도와 선이 많은 멋진 내장 사진입니다.
3. 코딩 시작하기
먼저 Python 라이브러리와 등반 사진을 가져옵니다.
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
다음으로 Pyplot 라이브러리 matplotlib를 사용하여 이미지를 그려서 이미지가 어떻게 표시되는지 확인합니다.
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

계단통 이미지임을 알 수 있습니다. 다양한 기능을 시도하고 격리할 수 있습니다. 예를 들어 강한 세로선이 있습니다.
이미지는 NumPy 배열로 저장되므로 해당 배열을 복사하여 변환된 이미지를 만들 수 있습니다. size_x 및 size_y 변수에는 이미지의 크기가 저장되므로 나중에 반복할 수 있습니다.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. 컨볼루션 행렬 만들기
먼저 컨볼루션 행렬 (또는 커널)을 3x3 배열로 만듭니다.
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
이제 출력 픽셀을 계산합니다. 이미지를 반복하여 1픽셀 여백을 남기고 현재 픽셀의 각 이웃을 필터에 정의된 값으로 곱합니다.
즉, 현재 픽셀의 위쪽과 왼쪽에 있는 이웃이 필터의 왼쪽 상단 항목과 곱해집니다. 그런 다음 결과에 가중치를 곱하고 결과가 0~255 범위에 있는지 확인합니다.
마지막으로 변환된 이미지에 새 값을 로드합니다.
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. 결과 검토
이제 이미지를 플롯하여 필터를 통과하는 효과를 확인합니다.
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

다음 필터 값과 이미지에 미치는 영향을 살펴보세요.
[-1,0,1,-2,0,2,-1,0,1] 을 사용하면 매우 강력한 세트의 세로선이 표시됩니다.
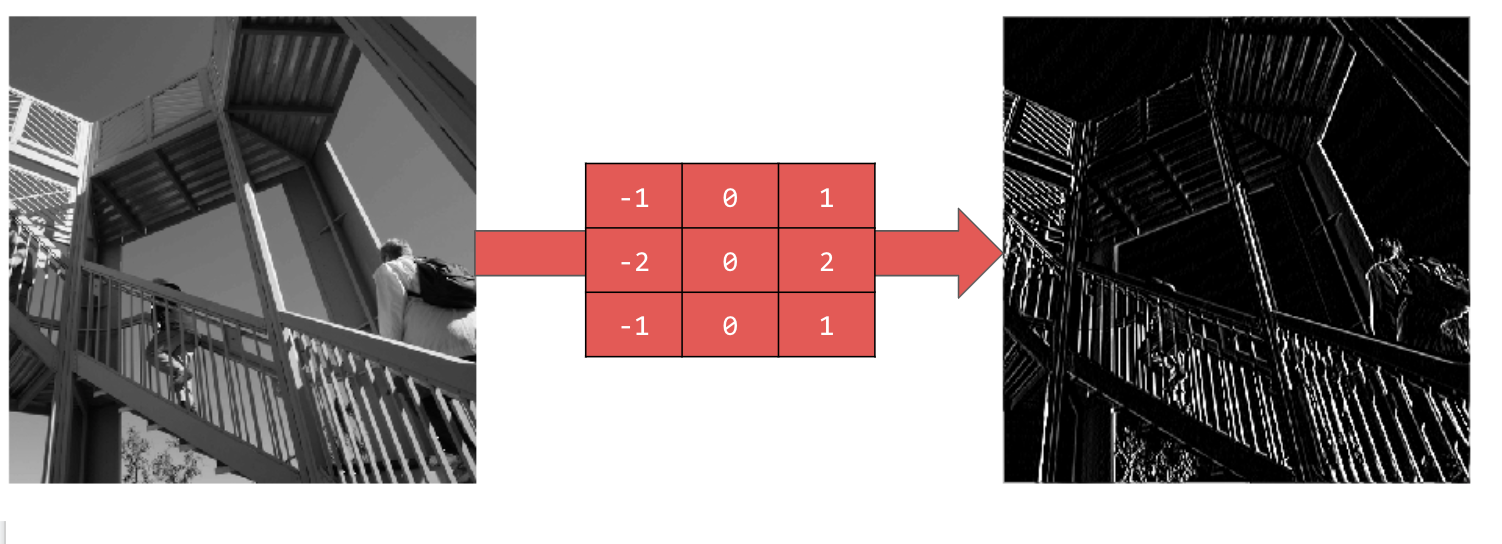
[-1,-2,-1,0,0,0,1,2,1] 을 사용하면 수평선이 표시됩니다.
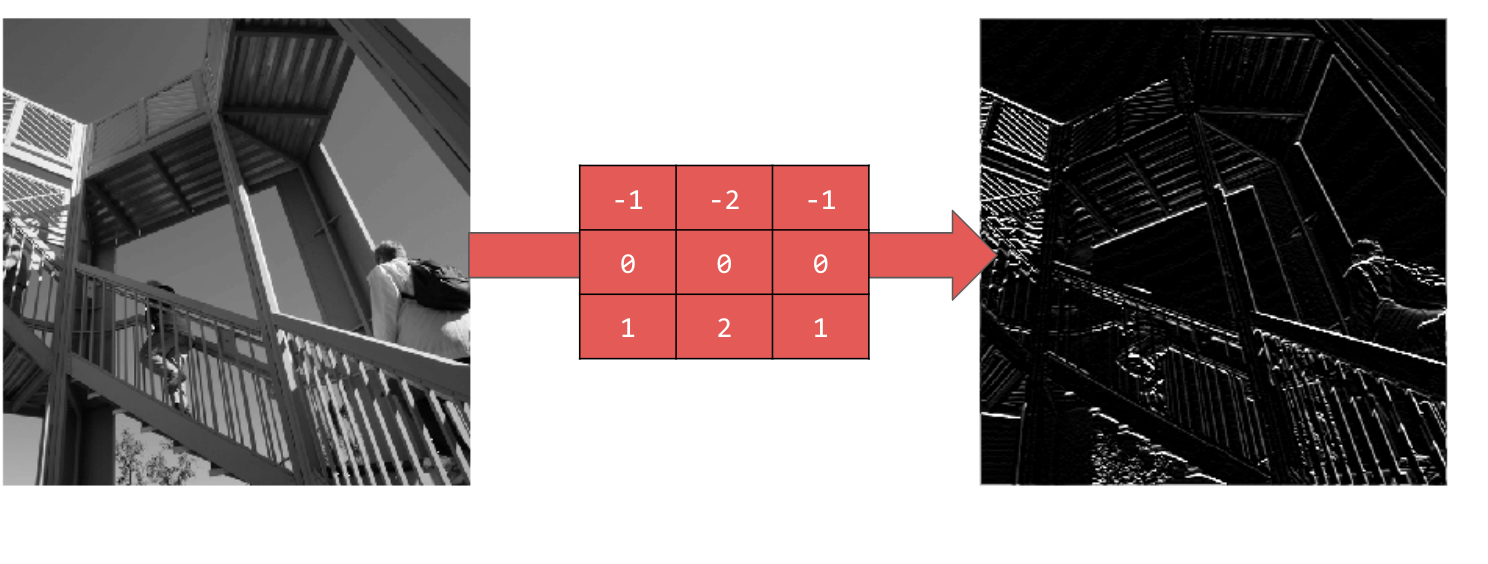
다양한 값을 살펴보세요. 5x5 또는 7x7과 같이 크기가 다른 필터를 사용해 보세요.
6. 풀링 이해
이제 이미지의 필수 기능을 식별했으므로 어떻게 해야 할까요? 결과 특성 맵을 사용하여 이미지를 분류하는 방법은 무엇인가요?
컨볼루션과 마찬가지로 풀링은 특징을 감지하는 데 큰 도움이 됩니다. 풀링 레이어는 이미지를 통해 감지된 특징을 유지하면서 이미지의 전체 정보 양을 줄입니다.
풀링에는 여러 가지 유형이 있지만 여기에서는 최대 풀링 (Max Pooling)이라는 유형을 사용합니다.
이미지를 반복하고 각 지점에서 픽셀과 바로 오른쪽, 아래, 오른쪽 아래에 있는 이웃을 고려합니다. 이 중 가장 큰 값을 가져와 (따라서 max 풀링) 새 이미지에 로드합니다. 따라서 새 이미지는 이전 이미지의 1/4 크기가 됩니다. 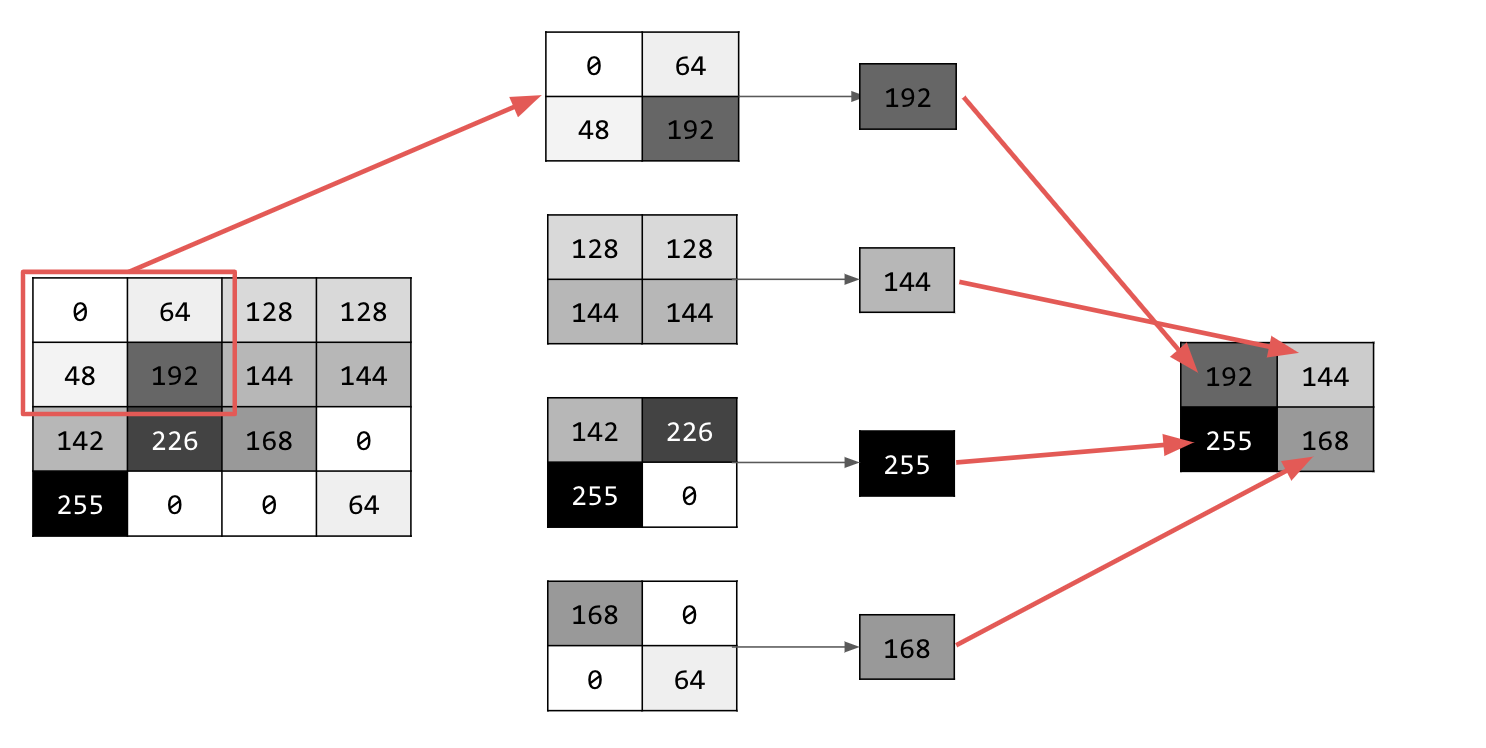
7. 풀링을 위한 코드 작성
다음 코드는 (2, 2) 풀링을 보여줍니다. 실행하여 출력을 확인합니다.
이미지가 원본의 1/4 크기이지만 모든 기능이 유지된 것을 확인할 수 있습니다.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

이 그래프의 축을 확인합니다. 이제 이미지가 원래 크기의 1/4인 256x256이 되었으며, 이미지에 포함된 데이터가 적은데도 감지된 특징이 개선되었습니다.
8. 축하합니다
첫 번째 컴퓨터 비전 모델을 빌드했습니다. 컴퓨터 비전 모델을 더욱 개선하는 방법을 알아보려면 컨볼루셔널 신경망 (CNN)을 빌드하여 컴퓨터 비전 개선으로 이동하세요.