
1. Prima di iniziare
In questo codelab, imparerai a conoscere le convoluzioni e perché sono così efficaci negli scenari di computer vision.
Nel codelab precedente, hai creato una semplice rete neurale profonda (DNN) per la visione artificiale di articoli di moda. Questo criterio era limitato perché richiedeva che l'indumento fosse l'unica cosa presente nell'immagine e che fosse centrato.
Ovviamente, questo non è uno scenario realistico. È importante che la DNN sia in grado di identificare il capo di abbigliamento nelle immagini con altri oggetti o quando non è posizionato al centro. Per farlo, dovrai utilizzare le convoluzioni.
Prerequisiti
Questo codelab si basa sul lavoro completato in due puntate precedenti: Say hello to the "Hello, World" of machine learning e Build a computer vision model. Completa questi codelab prima di continuare.
Cosa imparerai a fare
- Che cosa sono le convoluzioni
- Come creare una mappa delle funzionalità
- Che cos'è il pooling
Cosa creerai
- Una mappa delle funzionalità di un'immagine
Che cosa ti serve
Puoi trovare il codice per il resto del codelab in esecuzione in Colab.
Dovrai anche installare TensorFlow e le librerie installate nel codelab precedente.
2. Che cosa sono le convoluzioni?
Una convoluzione è un filtro che passa sopra un'immagine, la elabora ed estrae le caratteristiche importanti.
Supponiamo di avere un'immagine di una persona che indossa una scarpa da ginnastica. Come faresti a rilevare la presenza di una scarpa da ginnastica nell'immagine? Affinché il programma "veda" l'immagine come una scarpa da ginnastica, devi estrarre le caratteristiche importanti e sfocare quelle non essenziali. Questa operazione viene chiamata mappatura delle funzionalità.
Il processo di mappatura delle funzionalità è teoricamente semplice. Verrà eseguita la scansione di ogni pixel dell'immagine e verranno esaminati i pixel vicini. Moltiplica i valori di questi pixel per i pesi equivalenti in un filtro.
Ad esempio:
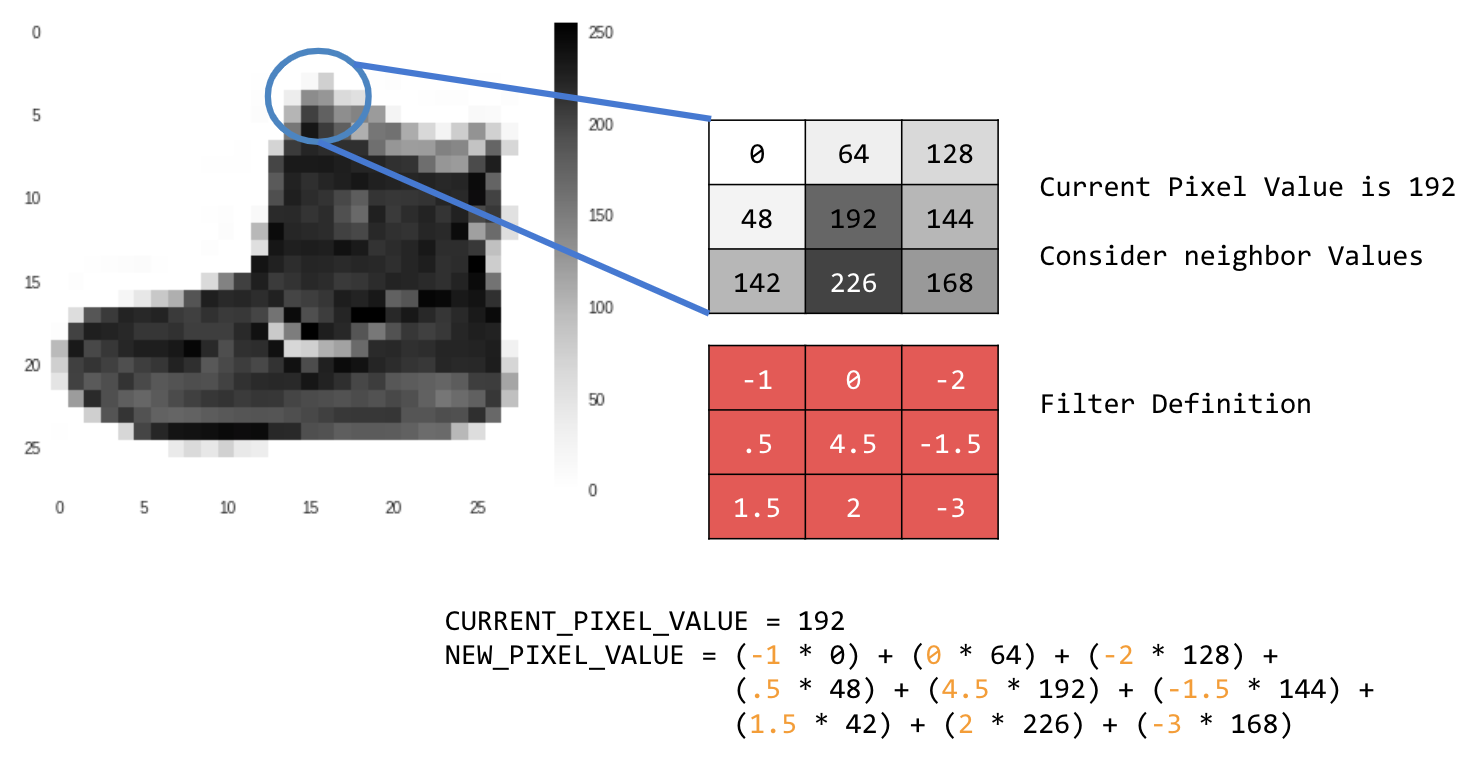
In questo caso, viene specificata una matrice di convoluzione 3x3 o un kernel dell'immagine.
Il valore attuale del pixel è 192. Puoi calcolare il valore del nuovo pixel esaminando i valori vicini, moltiplicandoli per i valori specificati nel filtro e impostando il nuovo valore del pixel come importo finale.
Ora è il momento di scoprire come funzionano le convoluzioni creando una convoluzione di base su un'immagine in scala di grigi 2D.
Lo dimostrerai con l'immagine di salita di SciPy. È una bella immagine integrata con molti angoli e linee.
3. Inizia a programmare
Inizia importando alcune librerie Python e l'immagine della salita:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
Successivamente, utilizza la libreria Pyplot matplotlib per disegnare l'immagine in modo da sapere come appare:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

Puoi vedere che è l'immagine di una tromba delle scale. Esistono molte funzionalità che puoi provare e isolare. Ad esempio, ci sono linee verticali marcate.
L'immagine viene memorizzata come array NumPy, quindi possiamo creare l'immagine trasformata semplicemente copiando l'array. Le variabili size_x e size_y conterranno le dimensioni dell'immagine, in modo da poterle scorrere in un secondo momento.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. Crea la matrice di convoluzione
Innanzitutto, crea una matrice di convoluzione (o kernel) come array 3x3:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
Ora calcola i pixel di output. Itera sull'immagine, lasciando un margine di 1 pixel, e moltiplica ciascuno dei vicini del pixel corrente per il valore definito nel filtro.
Ciò significa che il vicino del pixel corrente sopra e a sinistra verrà moltiplicato per l'elemento in alto a sinistra del filtro. Quindi, moltiplica il risultato per il peso e assicurati che il risultato sia compreso tra 0 e 255.
Infine, carica il nuovo valore nell'immagine trasformata:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. Esaminare i risultati
Ora traccia l'immagine per vedere l'effetto del passaggio del filtro:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

Considera i seguenti valori del filtro e il loro impatto sull'immagine.
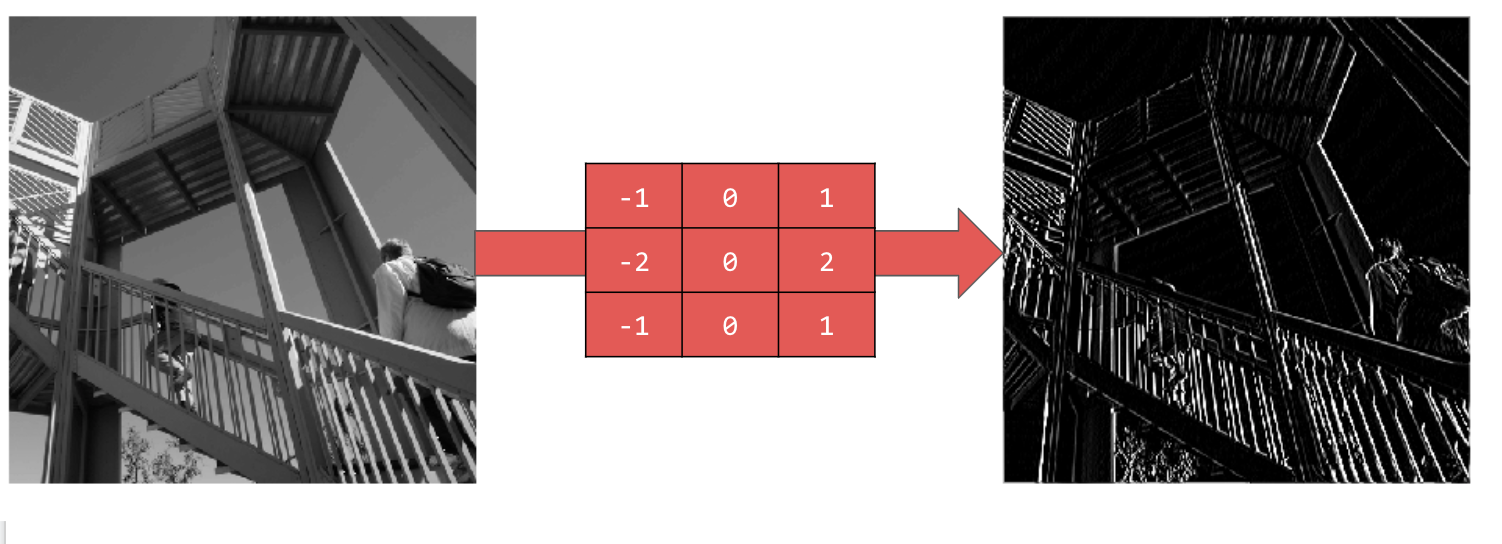
L'utilizzo di [-1,0,1,-2,0,2,-1,0,1] produce un insieme molto forte di linee verticali:
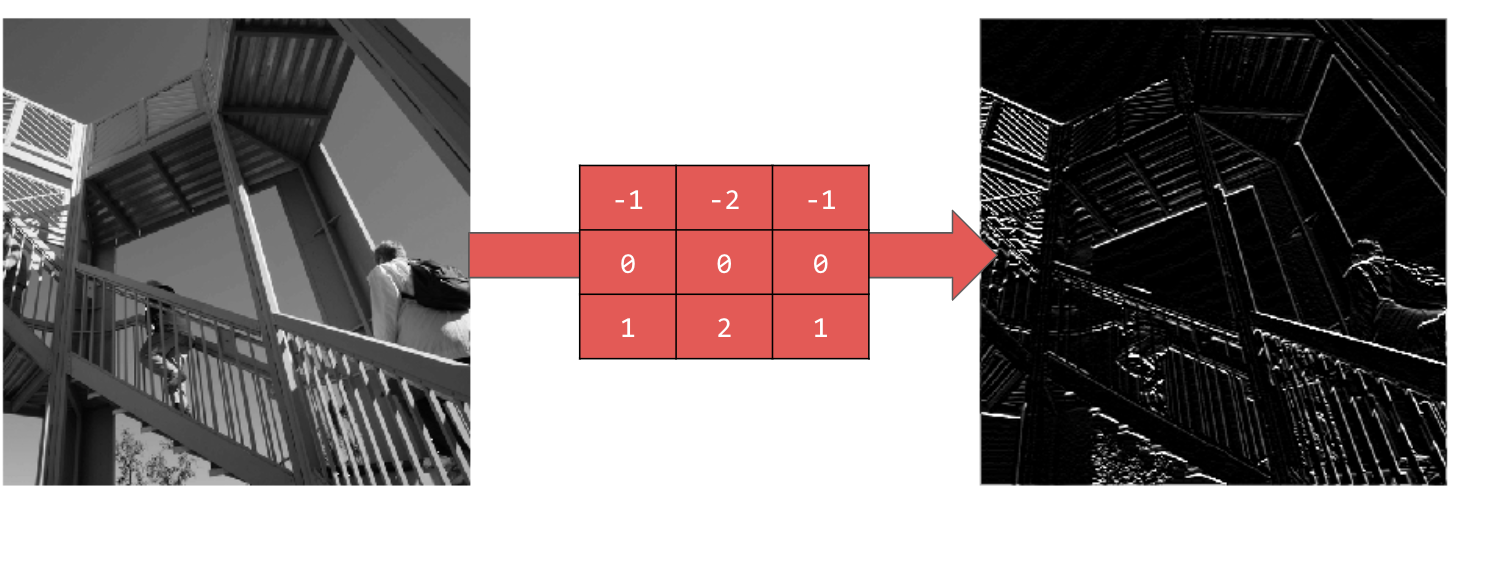
L'utilizzo di [-1,-2,-1,0,0,0,1,2,1] produce linee orizzontali:
Esplora valori diversi. Inoltre, prova filtri di dimensioni diverse, ad esempio 5x5 o 7x7.
6. Informazioni sul pooling
Ora che hai identificato le caratteristiche essenziali dell'immagine, cosa fai? Come utilizzi la mappa delle caratteristiche risultante per classificare le immagini?
Analogamente alle convoluzioni, il pooling aiuta notevolmente a rilevare le caratteristiche. I livelli di pooling riducono la quantità complessiva di informazioni in un'immagine, mantenendo le funzionalità rilevate come presenti.
Esistono diversi tipi di pooling, ma utilizzerai quello chiamato pooling massimo.
Itera sull'immagine e, in ogni punto, considera il pixel e i suoi vicini immediati a destra, sotto e in basso a destra. Prendi il più grande (da cui il pooling max) e caricalo nella nuova immagine. Pertanto, la nuova immagine avrà una dimensione pari a un quarto di quella precedente. 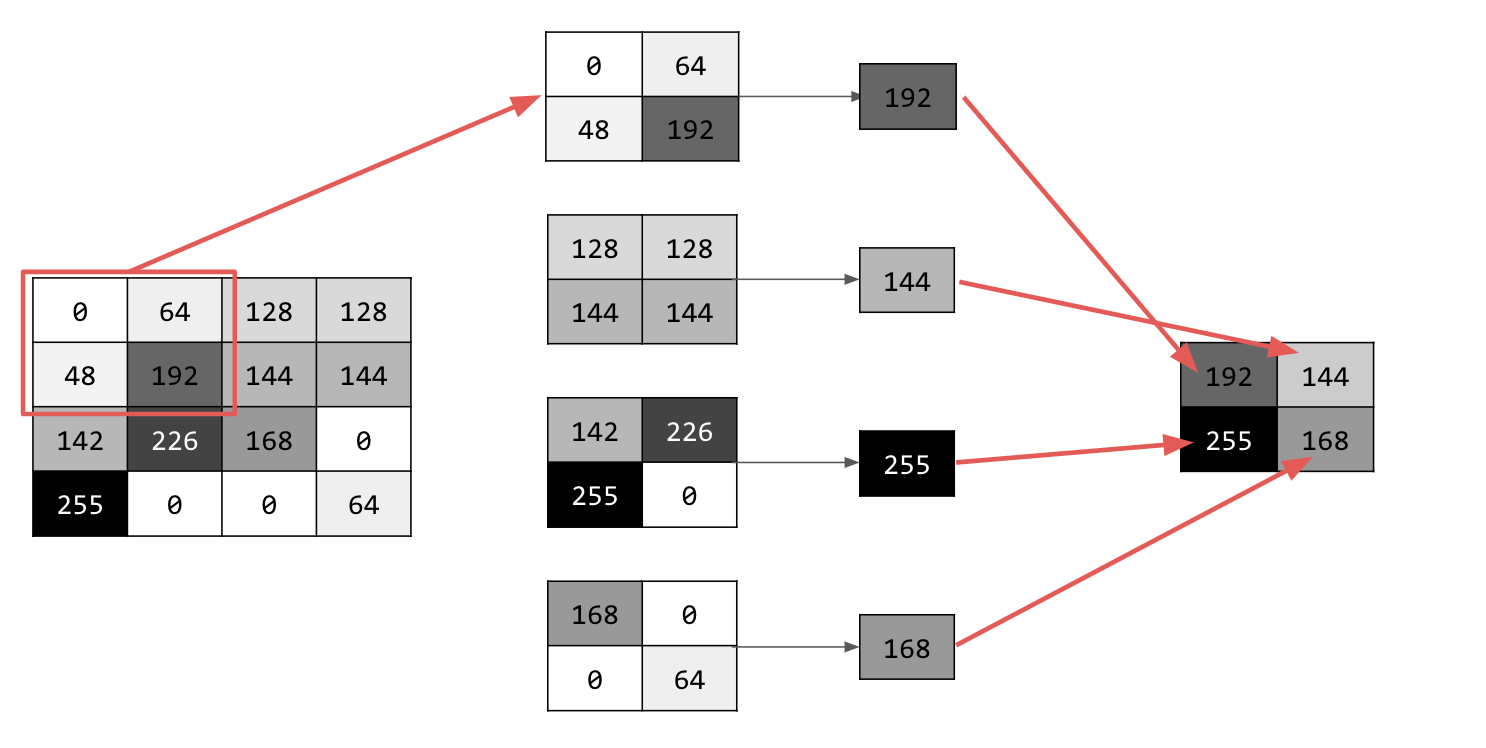
7. Scrivere codice per il pooling
Il seguente codice mostrerà un pooling (2, 2). Eseguilo per visualizzare l'output.
Vedrai che, sebbene l'immagine sia un quarto delle dimensioni dell'originale, ha mantenuto tutte le funzionalità.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

Nota gli assi del grafico. L'immagine ora è 256 x 256, un quarto delle dimensioni originali, e le funzionalità rilevate sono state migliorate nonostante ora ci siano meno dati nell'immagine.
8. Complimenti
Hai creato il tuo primo modello di computer vision. Per scoprire come migliorare ulteriormente i modelli di computer vision, vai a Creare reti neurali convoluzionali (CNN) per migliorare la computer vision.