
1. शुरू करने से पहले
इस कोडलैब में, आपको कनवोल्यूशन के बारे में जानकारी मिलेगी. साथ ही, यह भी पता चलेगा कि कंप्यूटर विज़न के मामलों में ये कितने असरदार होते हैं.
पिछले कोडलैब में, आपने फ़ैशन आइटम के कंप्यूटर विज़न के लिए एक सामान्य डीप न्यूरल नेटवर्क (डीएनएन) बनाया था. इस सुविधा का इस्तेमाल सीमित तौर पर किया जा सकता था, क्योंकि इसके लिए ज़रूरी था कि फ़ोटो में सिर्फ़ कपड़े का आइटम दिखे और वह बीच में हो.
ज़ाहिर है, यह एक काल्पनिक स्थिति है. आपको अपने DNN को इस तरह से ट्रेन करना होगा कि वह कपड़ों की इमेज में मौजूद अन्य ऑब्जेक्ट के साथ-साथ, कपड़ों की पहचान कर सके. साथ ही, वह ऐसी इमेज में भी कपड़ों की पहचान कर सके जिनमें कपड़ों को सामने और बीच में नहीं रखा गया है. इसके लिए, आपको कनवोल्यूशन का इस्तेमाल करना होगा.
ज़रूरी शर्तें
यह कोडलैब, पिछले दो कोडलैब पर आधारित है. ये कोडलैब हैं, मशीन लर्निंग की दुनिया में आपका स्वागत है और कंप्यूटर विज़न मॉडल बनाना. आगे बढ़ने से पहले, कृपया उन कोडलैब को पूरा करें.
आपको क्या सीखने को मिलेगा
- कनवोल्यूशन क्या होते हैं
- सुविधाओं का मैप बनाने का तरीका
- पूलिंग क्या है
आपको क्या बनाने को मिलेगा
- किसी इमेज का फ़ीचर मैप
आपको इन चीज़ों की ज़रूरत होगी
कोडलैब के बाकी बचे हिस्से का कोड, Colab में चल रहा है.
आपके डिवाइस पर TensorFlow इंस्टॉल होना चाहिए. साथ ही, पिछले कोडलैब में इंस्टॉल की गई लाइब्रेरी भी होनी चाहिए.
2. कनवोल्यूशन क्या होते हैं?
कनवोल्यूशन एक फ़िल्टर होता है. यह किसी इमेज पर लागू होता है, उसे प्रोसेस करता है, और उसकी अहम जानकारी निकालता है.
मान लें कि आपके पास किसी व्यक्ति की ऐसी इमेज है जिसमें उसने स्नीकर पहने हुए हैं. आपको कैसे पता चलेगा कि इमेज में एक स्नीकर मौजूद है? आपके प्रोग्राम को इमेज में स्नीकर दिखाने के लिए, आपको ज़रूरी सुविधाओं को हाइलाइट करना होगा और गैर-ज़रूरी सुविधाओं को धुंधला करना होगा. इसे सुविधा मैपिंग कहा जाता है.
सैद्धांतिक तौर पर, सुविधा मैपिंग की प्रोसेस आसान है. आपको इमेज के हर पिक्सल को स्कैन करना होगा. इसके बाद, उसके आस-पास के पिक्सल को देखना होगा. उन पिक्सल की वैल्यू को फ़िल्टर में मौजूद बराबर वज़न से गुणा किया जाता है.
उदाहरण के लिए:
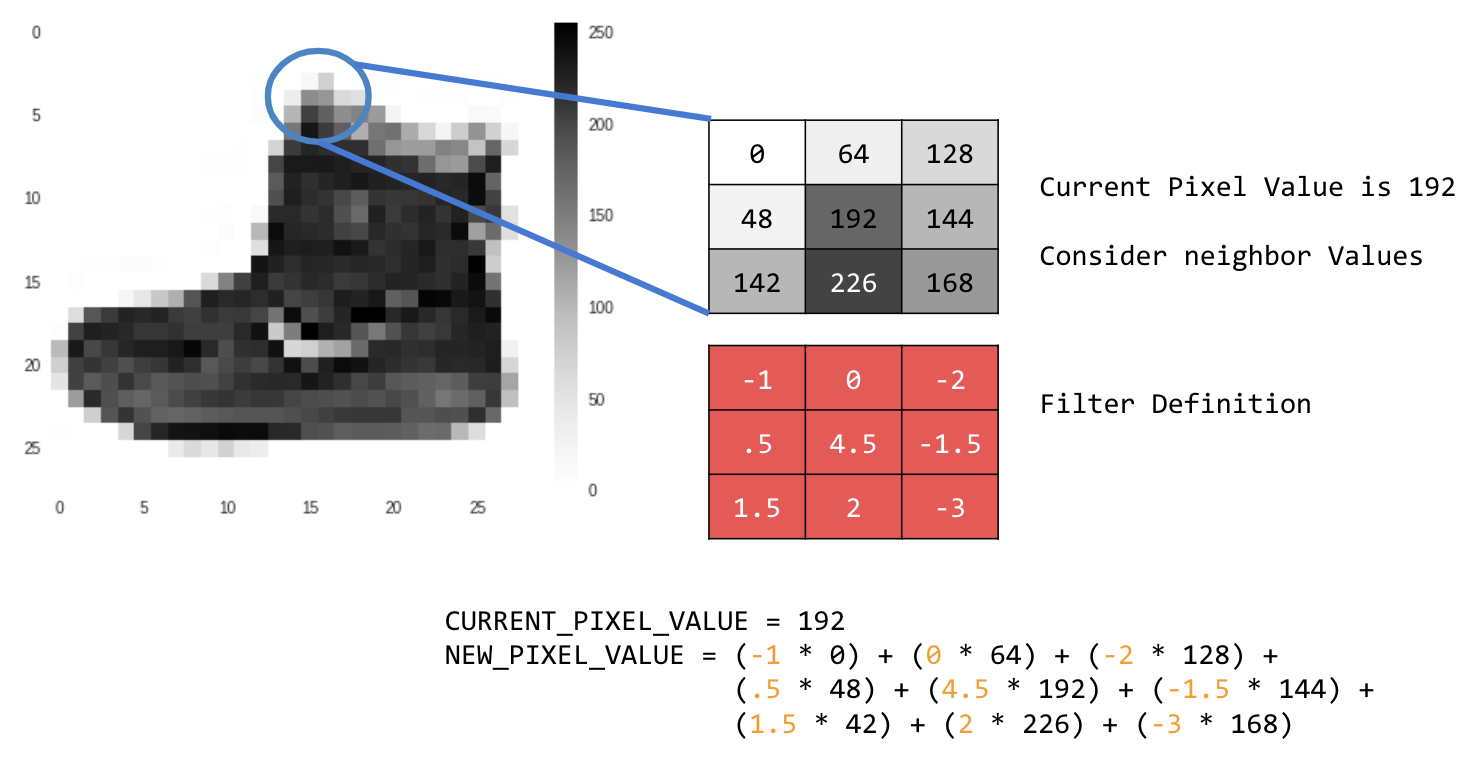
इस मामले में, 3x3 कनवोल्यूशन मैट्रिक्स या इमेज कर्नेल तय किया गया है.
मौजूदा पिक्सल वैल्यू 192 है. आस-पास के पिक्सल की वैल्यू देखकर, नए पिक्सल की वैल्यू का हिसाब लगाया जा सकता है. इसके लिए, आस-पास के पिक्सल की वैल्यू को फ़िल्टर में दी गई वैल्यू से गुणा करें. इसके बाद, नए पिक्सल की वैल्यू को फ़ाइनल वैल्यू के तौर पर सेट करें.
अब यह जानने का समय है कि कनवोल्यूशन कैसे काम करते हैं. इसके लिए, हम 2D ग्रेस्केल इमेज पर एक बुनियादी कनवोल्यूशन बनाएंगे.
इसे SciPy की एसेंट इमेज की मदद से दिखाया जाएगा. यह एक अच्छी बिल्ट-इन इमेज है, जिसमें कई ऐंगल और लाइनें हैं.
3. कोडिंग शुरू करें
कुछ Python लाइब्रेरी और ascent फ़ोटो इंपोर्ट करके शुरू करें:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
इसके बाद, इमेज बनाने के लिए Pyplot लाइब्रेरी matplotlib का इस्तेमाल करें, ताकि आपको पता चल सके कि इमेज कैसी दिखती है:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

इसमें सीढ़ियों की इमेज दिख रही है. ऐसी कई सुविधाएं हैं जिन्हें आज़माया जा सकता है और अलग किया जा सकता है. उदाहरण के लिए, इसमें वर्टिकल लाइनें साफ़ तौर पर दिख रही हैं.
इमेज को NumPy ऐरे के तौर पर सेव किया जाता है. इसलिए, हम सिर्फ़ उस ऐरे को कॉपी करके, बदली गई इमेज बना सकते हैं. size_x और size_y वैरिएबल, इमेज के डाइमेंशन को सेव करेंगे, ताकि बाद में आप इसे लूप कर सकें.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. कनवोल्यूशन मैट्रिक्स बनाना
सबसे पहले, 3x3 ऐरे के तौर पर कनवोल्यूशन मैट्रिक्स (या कर्नेल) बनाएं:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
अब, आउटपुट पिक्सल की गिनती करें. इमेज पर एक-एक करके काम करें. इसके लिए, एक पिक्सल का मार्जिन छोड़ें. इसके बाद, मौजूदा पिक्सल के हर पड़ोसी पिक्सल को फ़िल्टर में तय की गई वैल्यू से गुणा करें.
इसका मतलब है कि मौजूदा पिक्सल के ऊपर और बाईं ओर मौजूद पिक्सल को, फ़िल्टर में सबसे ऊपर बाईं ओर मौजूद आइटम से गुणा किया जाएगा. इसके बाद, नतीजे को वेट से गुणा करें और पक्का करें कि नतीजा 0 से 255 के बीच हो.
आखिर में, बदली गई इमेज में नई वैल्यू लोड करें:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. नतीजों की जांच करना
अब इमेज को प्लॉट करें, ताकि उस पर फ़िल्टर लगाने का असर देखा जा सके:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

यहां फ़िल्टर की वैल्यू और इमेज पर उनके असर के बारे में बताया गया है.
[-1,0,1,-2,0,2,-1,0,1] का इस्तेमाल करने पर, आपको वर्टिकल लाइनों का एक बहुत मज़बूत सेट मिलता है:
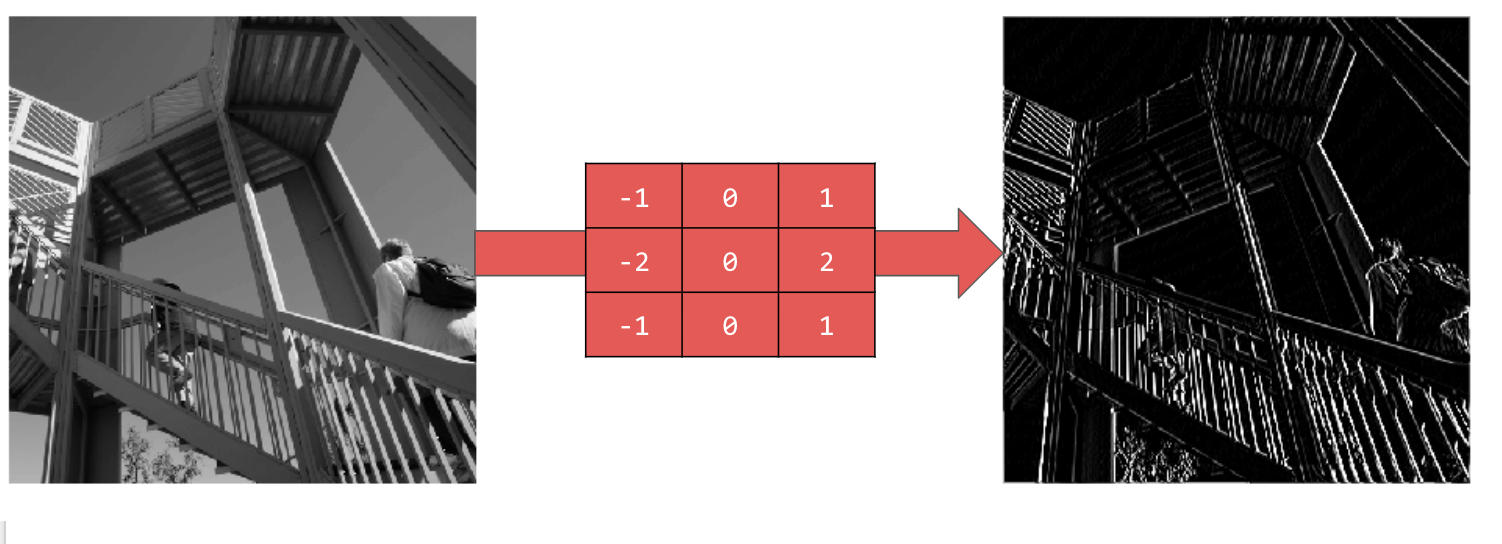
[-1,-2,-1,0,0,0,1,2,1] का इस्तेमाल करने पर, आपको हॉरिज़ॉन्टल लाइनें मिलती हैं:
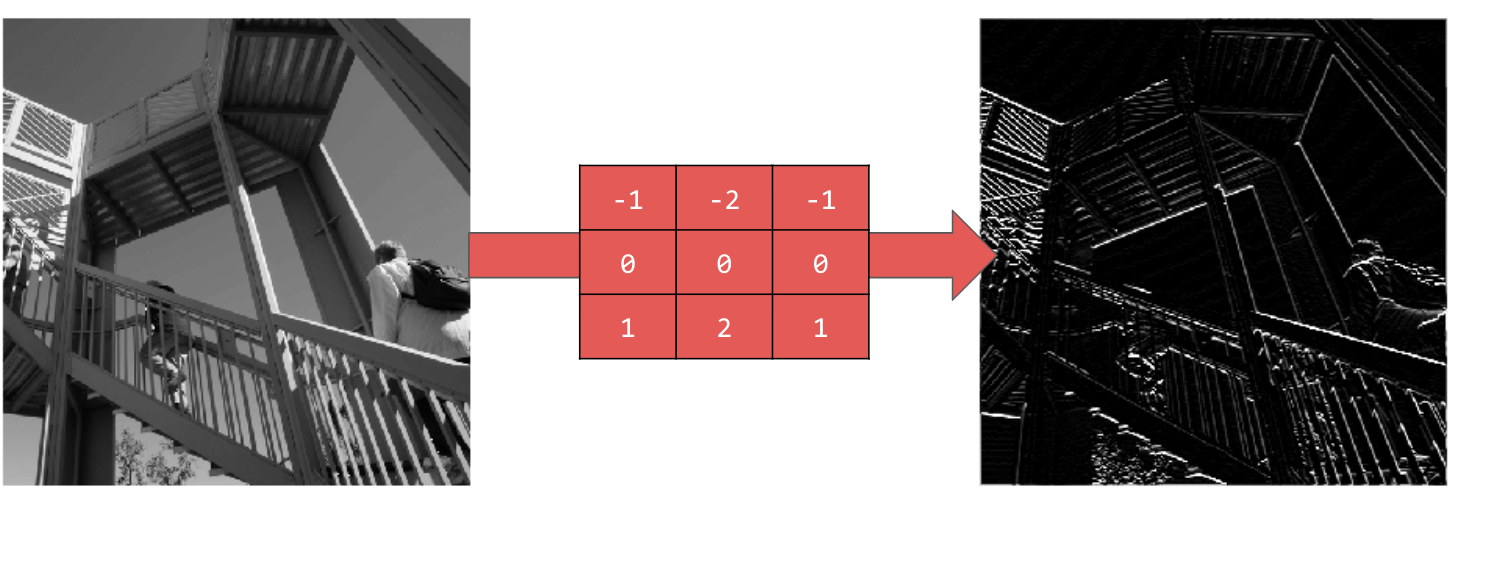
अलग-अलग वैल्यू एक्सप्लोर करें! इसके अलावा, अलग-अलग साइज़ के फ़िल्टर आज़माएं. जैसे, 5x5 या 7x7.
6. पूलिंग के बारे में जानकारी
अब आपने इमेज की ज़रूरी सुविधाओं की पहचान कर ली है. इसके बाद, आपको क्या करना चाहिए? इमेज को कैटगरी में बांटने के लिए, फ़ीचर मैप का इस्तेमाल कैसे किया जाता है?
कनवोल्यूशन की तरह ही, पूलिंग से सुविधाओं का पता लगाने में काफ़ी मदद मिलती है. पूलिंग लेयर, इमेज में मौजूद जानकारी को कम करती हैं. हालांकि, इससे इमेज में मौजूद उन सुविधाओं पर कोई असर नहीं पड़ता जिन्हें पहचान लिया गया है.
पूलिंग कई तरह की होती है, लेकिन आपको मैक्सिमम (मैक्स) पूलिंग का इस्तेमाल करना होगा.
इमेज पर बार-बार नज़र डालें. हर बार, पिक्सल और उसके आस-पास के पिक्सल पर ध्यान दें. जैसे, दाईं ओर, नीचे, और दाईं ओर नीचे मौजूद पिक्सल. उनमें से सबसे बड़ी वैल्यू लें (इसलिए, max पूलिंग) और उसे नई इमेज में लोड करें. इसलिए, नई इमेज का साइज़ पुरानी इमेज के साइज़ का एक-चौथाई होगा. 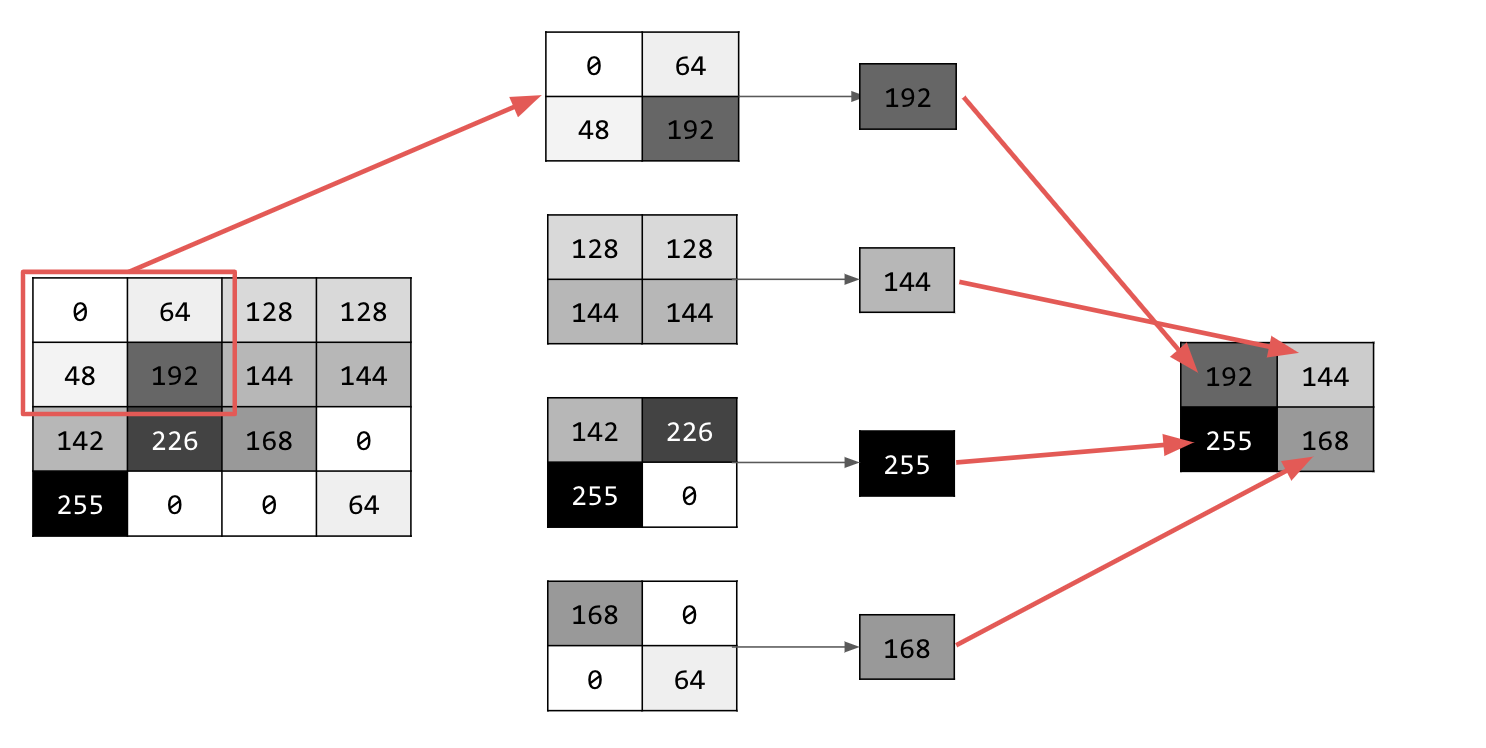
7. पूलिंग के लिए कोड लिखना
नीचे दिए गए कोड में, (2, 2) पूलिंग दिखाई गई है. आउटपुट देखने के लिए, इसे चलाएं.
आपको दिखेगा कि इमेज का साइज़, ओरिजनल इमेज के एक-चौथाई है. हालांकि, इसमें सभी सुविधाएं मौजूद हैं.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

उस प्लॉट के ऐक्सिस पर ध्यान दें. अब इमेज का साइज़ 256x256 है, जो इसके ओरिजनल साइज़ का एक-चौथाई है. साथ ही, इमेज में कम डेटा होने के बावजूद, पता लगाई गई सुविधाओं को बेहतर बनाया गया है.
8. बधाई हो
आपने अपना पहला कंप्यूटर विज़न मॉडल बना लिया है! अपने कंप्यूटर विज़न मॉडल को और बेहतर बनाने का तरीका जानने के लिए, कंप्यूटर विज़न को बेहतर बनाने के लिए, कॉन्वोल्यूशनल न्यूरल नेटवर्क (सीएनएन) बनाना पर जाएं.