
۱. قبل از شروع
در این آزمایشگاه کد، شما در مورد کانولوشنها و دلیل قدرتمند بودن آنها در سناریوهای بینایی کامپیوتر خواهید آموخت.
در آزمایشگاه کد قبلی، شما یک شبکه عصبی عمیق (DNN) ساده برای بینایی کامپیوتر اقلام مد ایجاد کردید. این کار محدود بود زیرا لازم بود که لباس تنها چیز موجود در تصویر باشد و باید در مرکز قرار میگرفت.
البته، این یک سناریوی واقعبینانه نیست. شما میخواهید DNN شما بتواند لباس را در تصاویر با اشیاء دیگر یا جایی که در جلو و مرکز قرار ندارد، شناسایی کند. برای انجام این کار، باید از پیچشها استفاده کنید.
پیشنیازها
این آزمایشگاه کد بر اساس کارهایی که در دو بخش قبلی، «به «سلام دنیا»ی یادگیری ماشین سلام کنید» و «یک مدل بینایی کامپیوتر بسازید » انجام شده است. لطفاً قبل از ادامه، این آزمایشگاههای کد را تکمیل کنید.
آنچه یاد خواهید گرفت
- کانولوشن چیست؟
- نحوه ایجاد نقشه ویژگی
- جمع کردن چیست؟
آنچه خواهید ساخت
- نقشه ویژگی یک تصویر
آنچه نیاز دارید
میتوانید کد مربوط به بقیهی بخشهای Codelab که در Colab اجرا میشوند را پیدا کنید.
همچنین به TensorFlow و کتابخانههایی که در codelab قبلی نصب کردهاید، نیاز خواهید داشت.
۲. کانولوشنها چیستند؟
کانولوشن فیلتری است که از روی یک تصویر عبور میکند، آن را پردازش میکند و ویژگیهای مهم را استخراج میکند.
فرض کنید تصویری از شخصی دارید که کفش کتانی پوشیده است. چگونه تشخیص میدهید که کفش کتانی در تصویر وجود دارد؟ برای اینکه برنامه شما تصویر را به عنوان یک کفش کتانی "ببیند"، باید ویژگیهای مهم را استخراج کرده و ویژگیهای غیرضروری را محو کنید. به این کار نگاشت ویژگی میگویند.
فرآیند نگاشت ویژگی از لحاظ تئوری ساده است. شما هر پیکسل در تصویر را اسکن میکنید و سپس به پیکسلهای همسایه آن نگاه میکنید. مقادیر آن پیکسلها را در وزنهای معادل در یک فیلتر ضرب میکنید.
برای مثال:
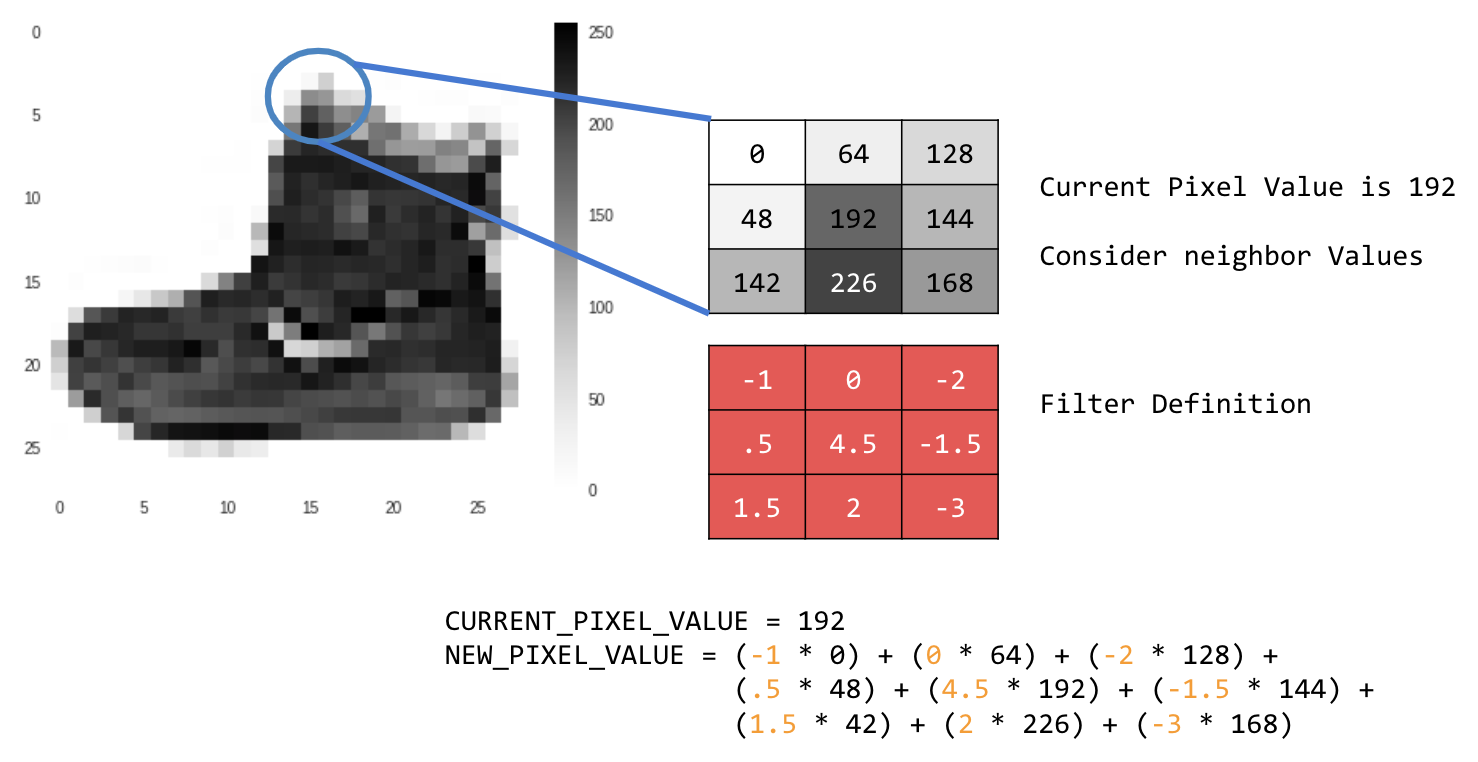
در این حالت، یک ماتریس کانولوشن ۳x۳ یا هسته تصویر مشخص شده است.
مقدار پیکسل فعلی ۱۹۲ است. میتوانید مقدار پیکسل جدید را با نگاه کردن به مقادیر همسایه، ضرب کردن آنها در مقادیر مشخص شده در فیلتر و تبدیل مقدار پیکسل جدید به مقدار نهایی، محاسبه کنید.
اکنون زمان آن رسیده است که با ایجاد یک کانولوشن پایه روی یک تصویر دوبعدی خاکستری، نحوه عملکرد کانولوشنها را بررسی کنیم.
شما این را با تصویر صعود از SciPy نشان خواهید داد. این یک تصویر داخلی خوب با زوایا و خطوط زیاد است.
۳. شروع به کدنویسی کنید
با وارد کردن چند کتابخانه پایتون و تصویر صعود شروع کنید:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
در مرحله بعد، از کتابخانه Pyplot به matplotlib برای رسم تصویر استفاده کنید تا بدانید چه شکلی است:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

میبینید که این تصویر یک راهپله است. میتوانید ویژگیهای زیادی را امتحان و جدا کنید. برای مثال، خطوط عمودی قوی وجود دارد.
تصویر به صورت یک آرایه NumPy ذخیره میشود، بنابراین میتوانیم تصویر تبدیلشده را تنها با کپی کردن آن آرایه ایجاد کنیم. متغیرهای size_x و size_y ابعاد تصویر را نگه میدارند تا بتوانید بعداً روی آن حلقه بزنید.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
۴. ماتریس کانولوشن را ایجاد کنید
ابتدا، یک ماتریس کانولوشن (یا هسته) را به صورت یک آرایه ۳x۳ بسازید:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
حالا، پیکسلهای خروجی را محاسبه کنید. روی تصویر تکرار کنید، یک حاشیه ۱ پیکسلی باقی بگذارید، و هر یک از همسایههای پیکسل فعلی را در مقدار تعریف شده در فیلتر ضرب کنید.
این بدان معناست که همسایه پیکسل فعلی که در بالا و سمت چپ آن قرار دارد، در آیتم بالا سمت چپ در فیلتر ضرب میشود. سپس، نتیجه را در وزن ضرب کنید و مطمئن شوید که نتیجه در محدوده ۰ تا ۲۵۵ باشد.
در نهایت، مقدار جدید را در تصویر تبدیلشده بارگذاری کنید:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
۵. نتایج را بررسی کنید
حالا، تصویر را رسم کنید تا تأثیر عبور فیلتر بر روی آن را ببینید:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

مقادیر فیلتر زیر و تأثیر آنها بر تصویر را در نظر بگیرید.
استفاده از [-1,0,1,-2,0,2,-1,0,1] مجموعهای بسیار قوی از خطوط عمودی به شما میدهد:
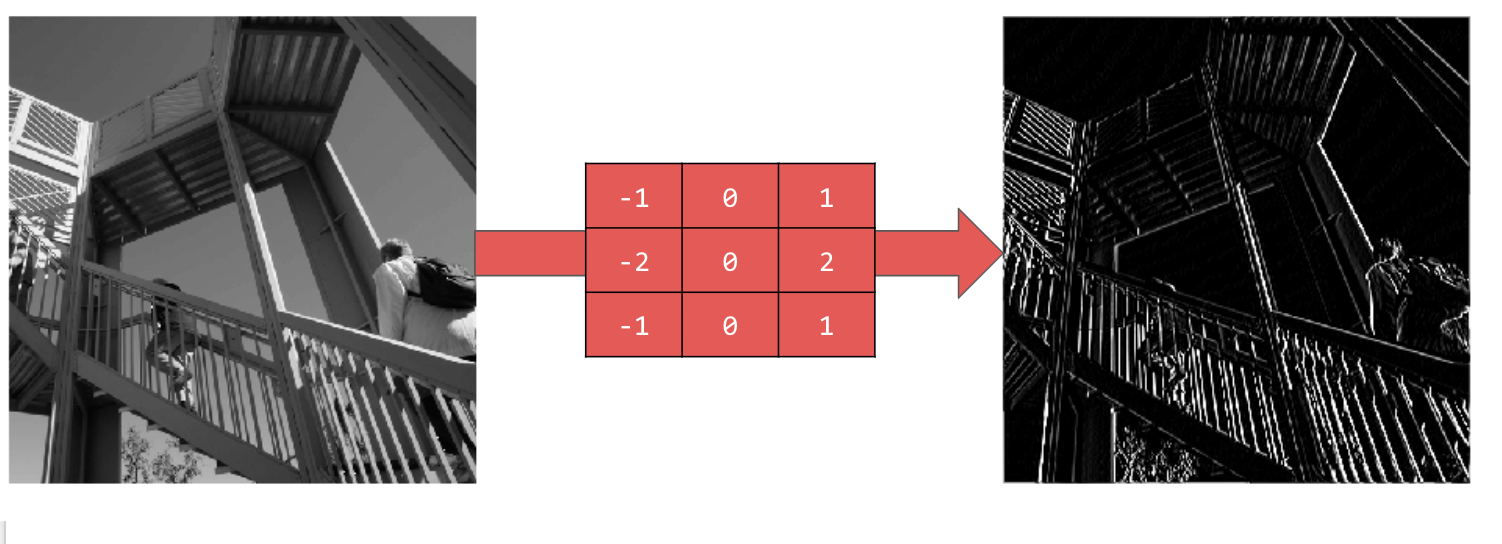
استفاده از [-1,-2,-1,0,0,0,1,2,1] خطوط افقی ایجاد میکند:
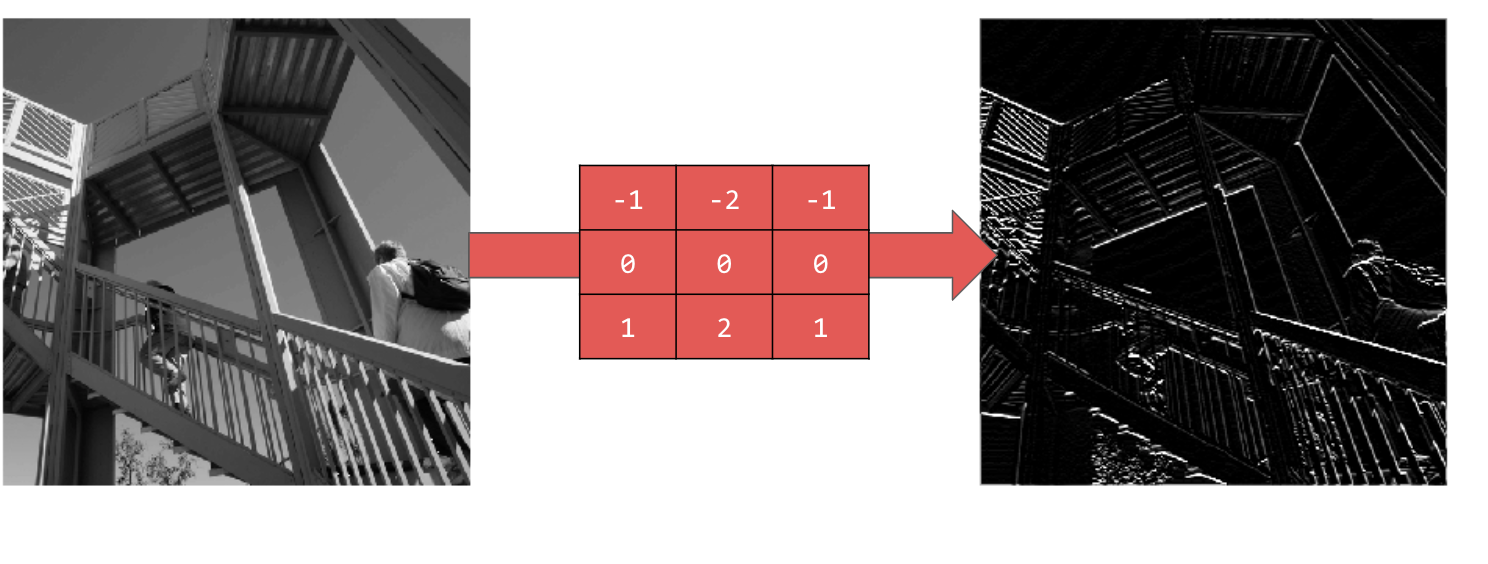
مقادیر مختلف را بررسی کنید! همچنین، فیلترهای با اندازههای مختلف، مانند ۵x۵ یا ۷x۷ را امتحان کنید.
۶. درک ادغام (pooling)
حالا که ویژگیهای اساسی تصویر را شناسایی کردهاید، چه میکنید؟ چگونه از نقشه ویژگی حاصل برای طبقهبندی تصاویر استفاده میکنید؟
مشابه با کانولوشن، ادغام لایهها به تشخیص ویژگیها کمک زیادی میکند. ادغام لایهها، حجم کلی اطلاعات موجود در یک تصویر را کاهش میدهد و در عین حال ویژگیهای شناسایی شده موجود را حفظ میکند.
انواع مختلفی از pooling وجود دارد، اما شما از نوعی به نام Maximum (Max) Pooling استفاده خواهید کرد.
روی تصویر حرکت کنید و در هر نقطه، پیکسل و همسایههای نزدیک آن در سمت راست، پایین و سمت راست-پایین را در نظر بگیرید. بزرگترین آنها (از این رو حداکثر ادغام) را انتخاب کرده و در تصویر جدید بارگذاری کنید. بنابراین، تصویر جدید یک چهارم اندازه تصویر قدیمی خواهد بود. 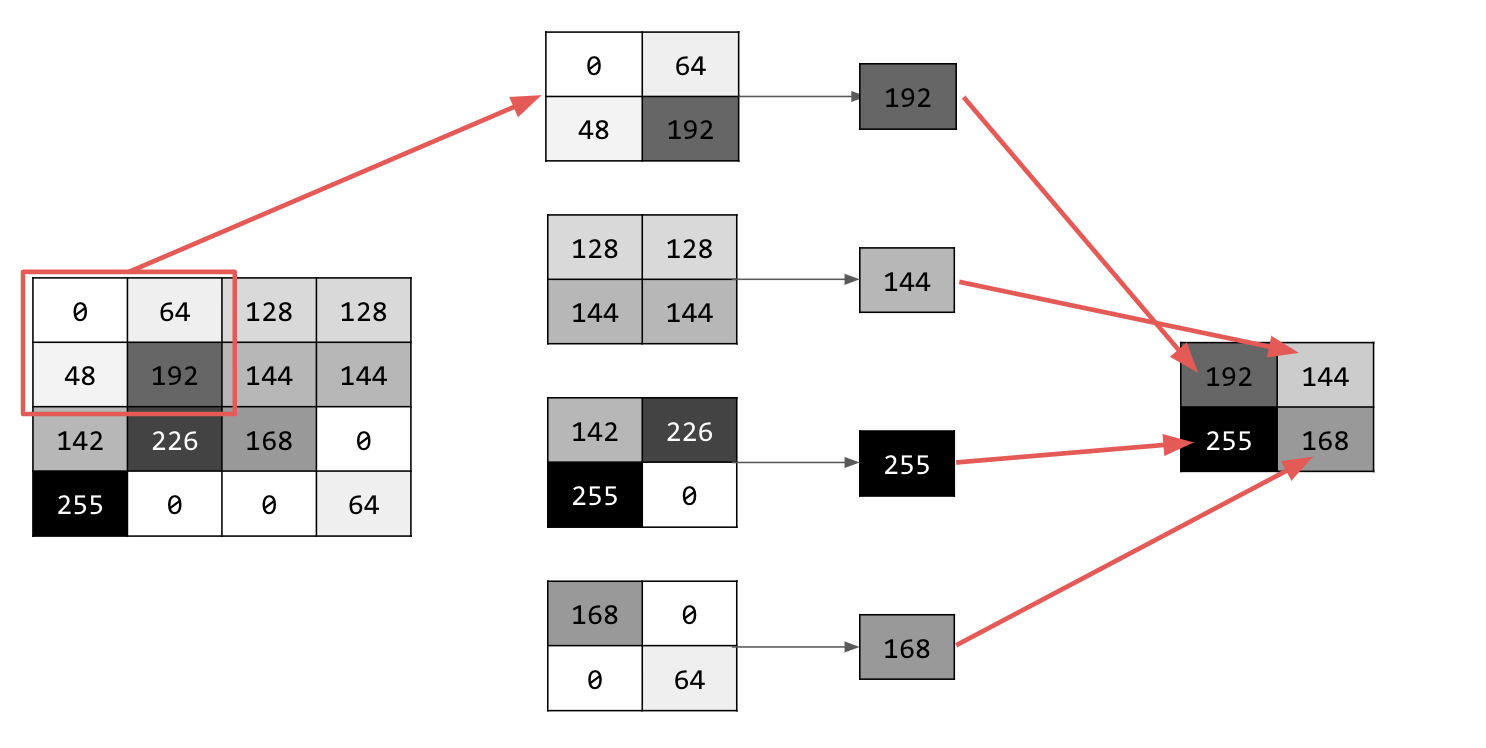
۷. کد مربوط به pooling را بنویسید
کد زیر یک pooling (2, 2) را نشان میدهد. آن را اجرا کنید تا خروجی را ببینید.
خواهید دید که با اینکه تصویر یک چهارم اندازه اصلی است، اما تمام ویژگیها را حفظ کرده است.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

به محورهای آن نمودار توجه کنید. تصویر اکنون ۲۵۶x۲۵۶ است، یک چهارم اندازه اصلی آن، و ویژگیهای شناسایی شده با وجود دادههای کمتر در تصویر، بهبود یافتهاند.
۸. تبریک
شما اولین مدل بینایی کامپیوتر خود را ساختهاید! برای یادگیری نحوهی بهبود بیشتر مدلهای بینایی کامپیوتر خود، به بخش «ساخت شبکههای عصبی کانولوشنی (CNN) برای بهبود بینایی کامپیوتر» مراجعه کنید.