
1. Antes de comenzar
En este codelab, aprenderás sobre las convoluciones y por qué son tan poderosas en situaciones de visión artificial.
En el codelab anterior, creaste una red neuronal profunda (DNN) simple para la visión artificial de artículos de moda. Esto se limitó porque se requería que la prenda fuera lo único que apareciera en la foto y que estuviera centrada.
Por supuesto, esta no es una situación realista. Querrás que tu DNN pueda identificar la prenda en fotos con otros objetos o en las que no esté ubicada en el centro y de frente. Para ello, deberás usar convoluciones.
Requisitos previos
Este codelab se basa en el trabajo completado en dos entregas anteriores: Saluda al "Hola, mundo" del aprendizaje automático y Crea un modelo de visión por computadora. Completa esos codelabs antes de continuar.
Qué aprenderás
- Qué son las convoluciones
- Cómo crear un mapa de funciones
- Qué es la agrupación
Qué compilarás
- Mapa de características de una imagen
Requisitos
Puedes encontrar el código del resto del codelab en ejecución en Colab.
También necesitarás tener instalado TensorFlow y las bibliotecas que instalaste en el codelab anterior.
2. ¿Qué son las convoluciones?
Una convolución es un filtro que pasa por sobre una imagen, la procesa y extrae los atributos importantes.
Supongamos que tienes una imagen de una persona que usa una zapatilla. ¿Cómo detectarías que hay una zapatilla en la imagen? Para que tu programa "vea" la imagen como una zapatilla, deberás extraer las características importantes y desenfocar las que no lo son. Esto se denomina asignación de atributos.
El proceso de asignación de funciones es teóricamente simple. Analizarás cada píxel de la imagen y, luego, observarás los píxeles vecinos. Multiplicas los valores de esos píxeles por los pesos equivalentes en un filtro.
Por ejemplo:
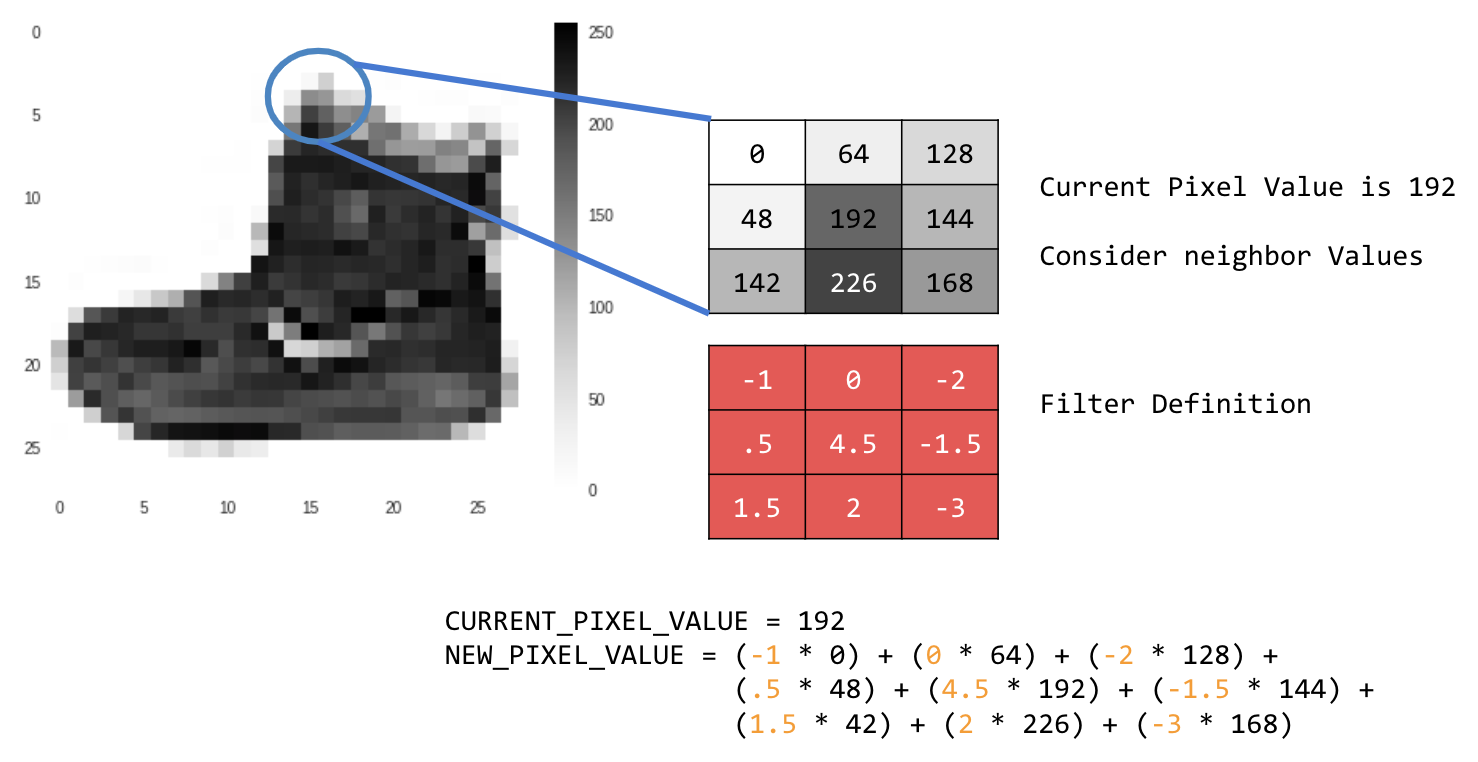
En este caso, se especifica una matriz de convolución de 3 x 3, o kernel de imagen.
El valor actual del píxel es 192. Puedes calcular el valor del píxel nuevo observando los valores de los píxeles vecinos, multiplicándolos por los valores especificados en el filtro y haciendo que el valor del píxel nuevo sea la cantidad final.
Ahora es el momento de explorar cómo funcionan las convoluciones creando una convolución básica en una imagen en escala de grises 2D.
Lo demostrarás con la imagen de ascenso de SciPy. Es una buena imagen integrada con muchos ángulos y líneas.
3. Comienza a programar
Comienza por importar algunas bibliotecas de Python y la imagen del ascenso:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
A continuación, usa la biblioteca Pyplot matplotlib para dibujar la imagen y saber cómo se ve:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

Puedes ver que es la imagen de una escalera. Hay muchas funciones que puedes probar y aislar. Por ejemplo, hay líneas verticales definidas.
La imagen se almacena como un array de NumPy, por lo que podemos crear la imagen transformada con solo copiar ese array. Las variables size_x y size_y contendrán las dimensiones de la imagen para que puedas iterar sobre ella más adelante.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. Crea la matriz de convolución
Primero, crea una matriz de convolución (o kernel) como un array de 3x3:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
Ahora, calcula los píxeles de salida. Itera sobre la imagen, dejando un margen de 1 píxel, y multiplica cada uno de los píxeles vecinos del píxel actual por el valor definido en el filtro.
Esto significa que el vecino del píxel actual que se encuentra arriba y a la izquierda se multiplicará por el elemento superior izquierdo del filtro. Luego, multiplica el resultado por el peso y asegúrate de que el resultado esté en el rango de 0 a 255.
Por último, carga el valor nuevo en la imagen transformada:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. Analiza los resultados
Ahora, grafica la imagen para ver el efecto de pasar el filtro sobre ella:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

Considera los siguientes valores de filtro y su impacto en la imagen.
Usar [-1,0,1,-2,0,2,-1,0,1] te proporciona un conjunto muy sólido de líneas verticales:
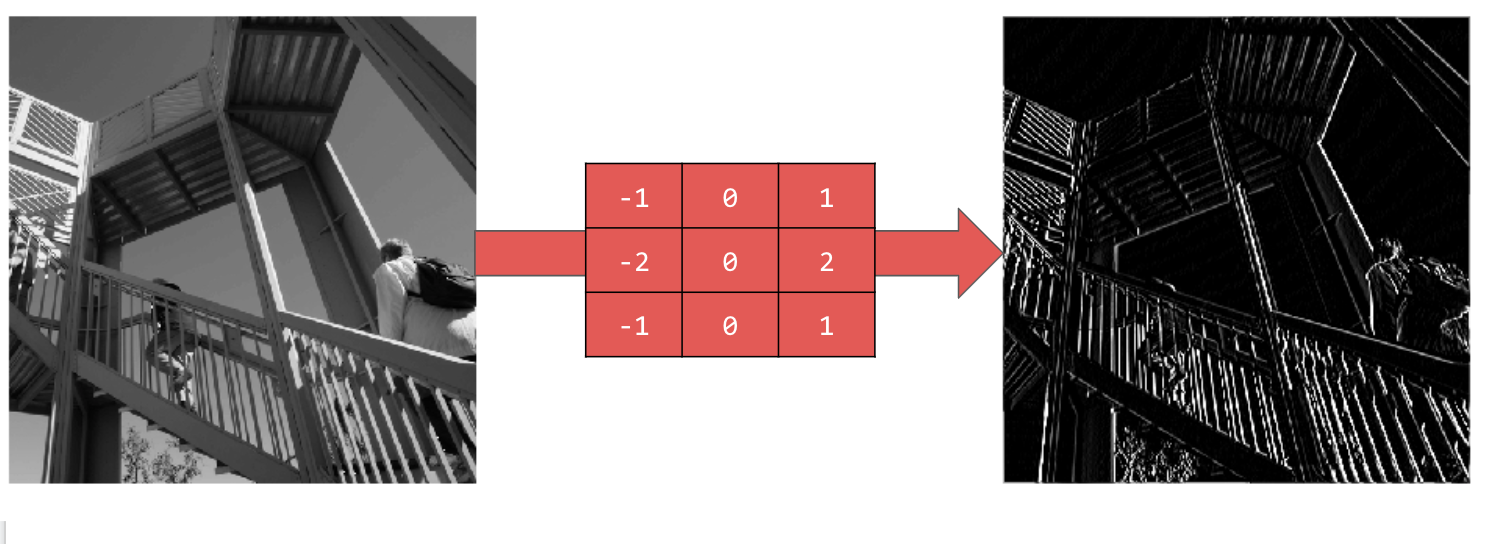
Usar [-1,-2,-1,0,0,0,1,2,1] te da líneas horizontales:
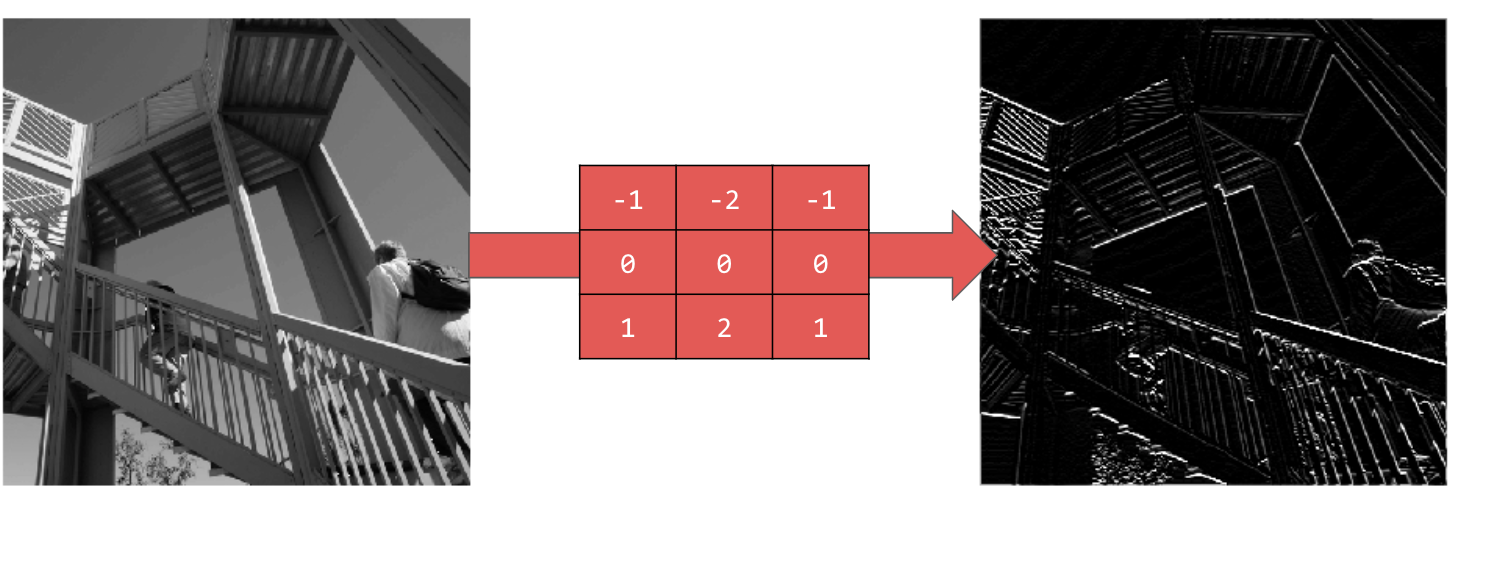
Explora diferentes valores. Además, prueba con filtros de diferentes tamaños, como 5 x 5 o 7 x 7.
6. Información sobre la reducción
Ahora que identificaste las características esenciales de la imagen, ¿qué haces? ¿Cómo usas el mapa de características resultante para clasificar imágenes?
Al igual que las convoluciones, el agrupamiento ayuda mucho a detectar atributos. Las capas de agrupación reducen la cantidad total de información en una imagen y, al mismo tiempo, conservan las características que se detectan como presentes.
Existen varios tipos diferentes de pooling, pero usarás uno llamado pooling máximo (Max).
Itera sobre la imagen y, en cada punto, considera el píxel y sus vecinos inmediatos a la derecha, debajo y a la derecha y debajo. Toma el más grande de esos valores (por lo tanto, max pooling) y cárgalo en la nueva imagen. Por lo tanto, la imagen nueva tendrá un cuarto del tamaño de la anterior. 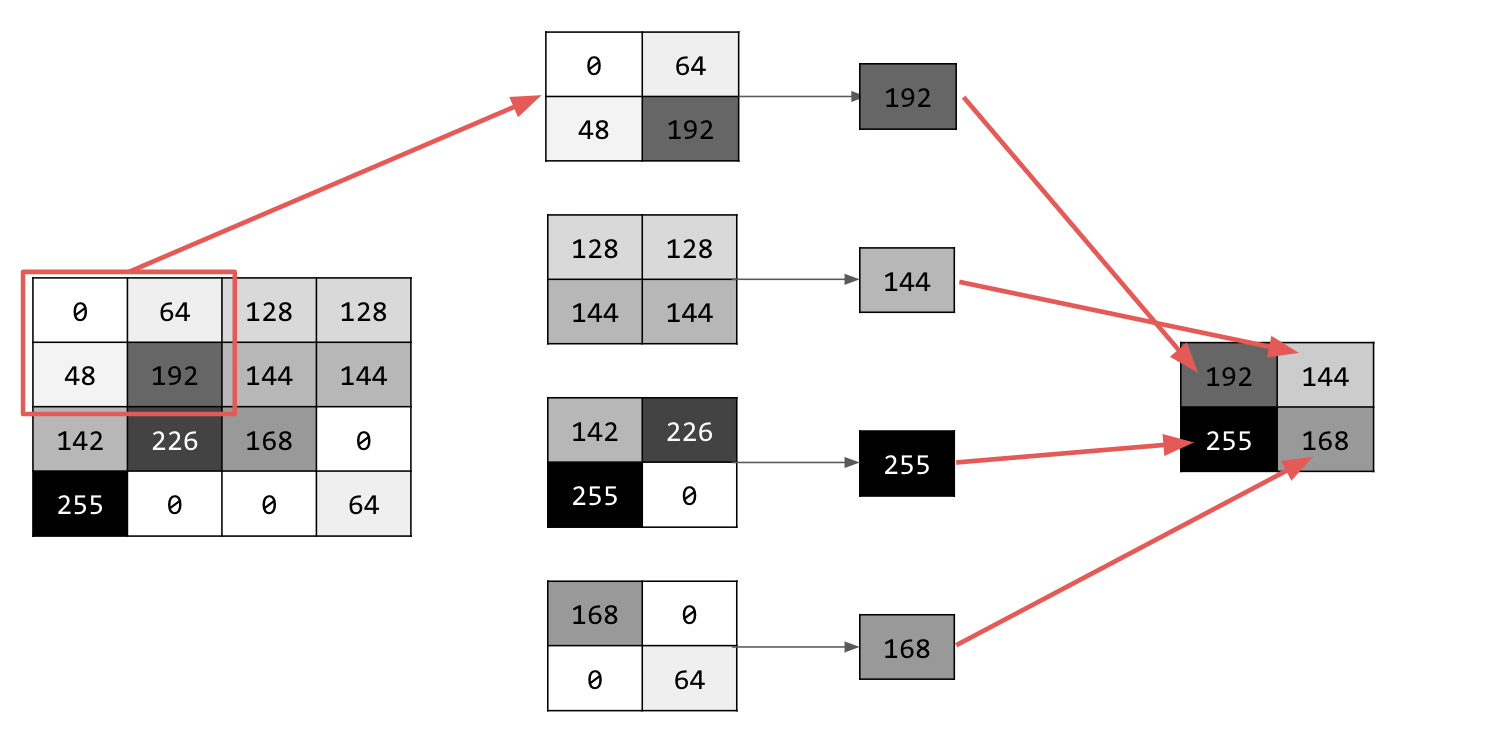
7. Escribe código para el pooling
El siguiente código mostrará un agrupamiento (2, 2). Ejecútalo para ver el resultado.
Verás que, si bien la imagen es un cuarto del tamaño original, conservó todas las características.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

Observa los ejes de ese gráfico. Ahora la imagen es de 256 x 256, un cuarto de su tamaño original, y las características detectadas se mejoraron a pesar de que ahora hay menos datos en la imagen.
8. Felicitaciones
Compilaste tu primer modelo de visión artificial. Para aprender a mejorar aún más tus modelos de visión artificial, continúa con Cómo compilar redes neuronales convolucionales (CNN) para mejorar la visión artificial.