
1. Hinweis
In diesem Codelab erfahren Sie mehr über Faltungen und warum sie in Computer Vision-Szenarien so leistungsstark sind.
Im vorherigen Codelab haben Sie ein einfaches neuronales Deep-Learning-Netzwerk (DNN) für die Computer Vision von Modeartikeln erstellt. Diese Einschränkung war erforderlich, weil das Kleidungsstück das einzige Objekt auf dem Bild sein und zentriert werden musste.
Das ist natürlich kein realistisches Szenario. Ihr DNN sollte das Kleidungsstück auch auf Bildern mit anderen Objekten oder wenn es nicht mittig platziert ist, erkennen können. Dazu müssen Sie Faltungen verwenden.
Voraussetzungen
Dieses Codelab baut auf den Arbeiten auf, die in den beiden vorherigen Teilen „Hello, World“ des maschinellen Lernens und Computer-Vision-Modell erstellen abgeschlossen wurden. Bitte arbeiten Sie diese Codelabs durch, bevor Sie fortfahren.
Lerninhalte
- Was sind Faltungen?
- Feature-Map erstellen
- Was ist Pooling?
Umfang
- Eine Feature-Karte eines Bildes
Voraussetzungen
Den Code für den Rest des Codelabs finden Sie in Colab.
Außerdem müssen Sie TensorFlow und die Bibliotheken installiert haben, die Sie im vorherigen Codelab installiert haben.
2. Was sind Faltungen?
Eine Faltung ist ein Filter, der auf ein Bild angewendet wird, dieses verarbeitet und die wichtigen Merkmale extrahiert.
Angenommen, Sie haben ein Bild einer Person, die einen Sneaker trägt. Wie würden Sie erkennen, dass sich ein Sneaker auf dem Bild befindet? Damit Ihr Programm das Bild als Sneaker „erkennt“, müssen Sie die wichtigen Merkmale extrahieren und die unwichtigen Merkmale unkenntlich machen. Das wird als Funktionszuordnung bezeichnet.
Der Prozess der Funktionszuordnung ist theoretisch einfach. Sie scannen jedes Pixel im Bild und sehen sich dann die benachbarten Pixel an. Sie multiplizieren die Werte dieser Pixel mit den entsprechenden Gewichten in einem Filter.
Beispiel:
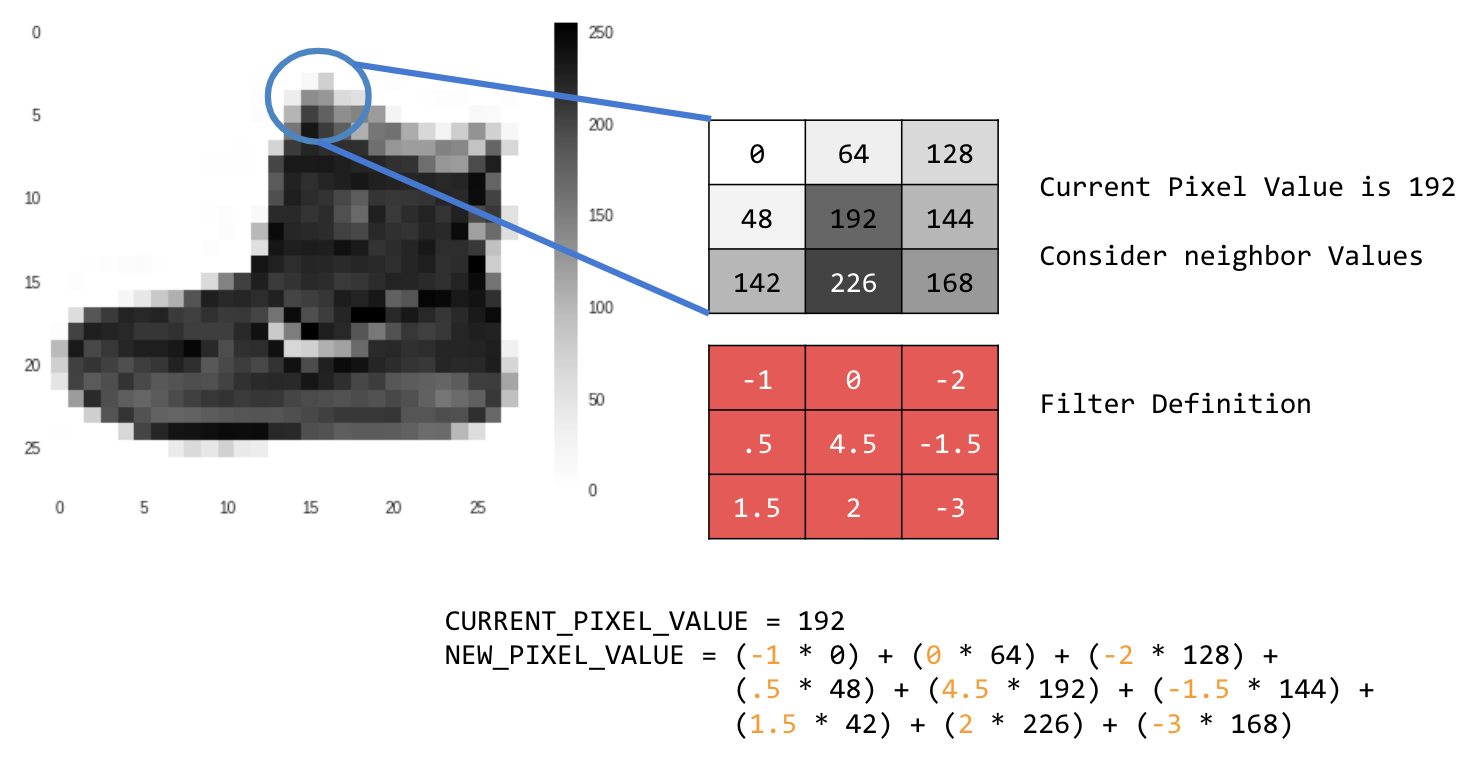
In diesem Fall wird eine 3×3-Faltungsmatrix oder ein Bildkernel angegeben.
Der aktuelle Pixelwert ist 192. Sie können den Wert des neuen Pixels berechnen, indem Sie die Nachbarwerte mit den im Filter angegebenen Werten multiplizieren und den neuen Pixelwert als endgültigen Betrag festlegen.
Jetzt ist es an der Zeit, sich anzusehen, wie Faltungen funktionieren. Dazu erstellen Sie eine einfache Faltung auf einem zweidimensionalen Graustufenbild.
Das wird mit dem Ascent-Bild aus SciPy demonstriert. Es ist ein schönes integriertes Bild mit vielen Winkeln und Linien.
3. Programmieren starten
Importieren Sie zuerst einige Python-Bibliotheken und das Bild vom Aufstieg:
import cv2
import numpy as np
from scipy import misc
i = misc.ascent()
Verwenden Sie als Nächstes die Pyplot-Bibliothek matplotlib, um das Bild zu zeichnen, damit Sie sehen, wie es aussieht:
import matplotlib.pyplot as plt
plt.grid(False)
plt.gray()
plt.axis('off')
plt.imshow(i)
plt.show()

Sie sehen, dass es sich um ein Bild eines Treppenhauses handelt. Es gibt viele Funktionen, die Sie ausprobieren und isolieren können. Beispiel: Es gibt starke vertikale Linien.
Das Bild wird als NumPy-Array gespeichert. Wir können das transformierte Bild also einfach durch Kopieren dieses Arrays erstellen. Die Variablen „size_x“ und „size_y“ enthalten die Abmessungen des Bildes, sodass Sie es später durchlaufen können.
i_transformed = np.copy(i)
size_x = i_transformed.shape[0]
size_y = i_transformed.shape[1]
4. Faltungsmatrix erstellen
Erstellen Sie zuerst eine Faltungsmatrix (oder einen Kernel) als 3x3-Array:
# This filter detects edges nicely
# It creates a filter that only passes through sharp edges and straight lines.
# Experiment with different values for fun effects.
#filter = [ [0, 1, 0], [1, -4, 1], [0, 1, 0]]
# A couple more filters to try for fun!
filter = [ [-1, -2, -1], [0, 0, 0], [1, 2, 1]]
#filter = [ [-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]
# If all the digits in the filter don't add up to 0 or 1, you
# should probably do a weight to get it to do so
# so, for example, if your weights are 1,1,1 1,2,1 1,1,1
# They add up to 10, so you would set a weight of .1 if you want to normalize them
weight = 1
Berechnen Sie nun die Ausgabepixel. Das Bild wird durchlaufen, wobei ein 1‑Pixel-Rand berücksichtigt wird. Jeder Nachbar des aktuellen Pixels wird mit dem im Filter definierten Wert multipliziert.
Das bedeutet, dass der Nachbar des aktuellen Pixels darüber und links davon mit dem Element oben links im Filter multipliziert wird. Multiplizieren Sie das Ergebnis dann mit dem Gewicht und achten Sie darauf, dass das Ergebnis im Bereich von 0 bis 255 liegt.
Laden Sie den neuen Wert in das transformierte Bild:
for x in range(1,size_x-1):
for y in range(1,size_y-1):
output_pixel = 0.0
output_pixel = output_pixel + (i[x - 1, y-1] * filter[0][0])
output_pixel = output_pixel + (i[x, y-1] * filter[0][1])
output_pixel = output_pixel + (i[x + 1, y-1] * filter[0][2])
output_pixel = output_pixel + (i[x-1, y] * filter[1][0])
output_pixel = output_pixel + (i[x, y] * filter[1][1])
output_pixel = output_pixel + (i[x+1, y] * filter[1][2])
output_pixel = output_pixel + (i[x-1, y+1] * filter[2][0])
output_pixel = output_pixel + (i[x, y+1] * filter[2][1])
output_pixel = output_pixel + (i[x+1, y+1] * filter[2][2])
output_pixel = output_pixel * weight
if(output_pixel<0):
output_pixel=0
if(output_pixel>255):
output_pixel=255
i_transformed[x, y] = output_pixel
5. Ergebnisse prüfen
Stellen Sie das Bild nun grafisch dar, um die Auswirkungen des Filters zu sehen:
# Plot the image. Note the size of the axes -- they are 512 by 512
plt.gray()
plt.grid(False)
plt.imshow(i_transformed)
#plt.axis('off')
plt.show()

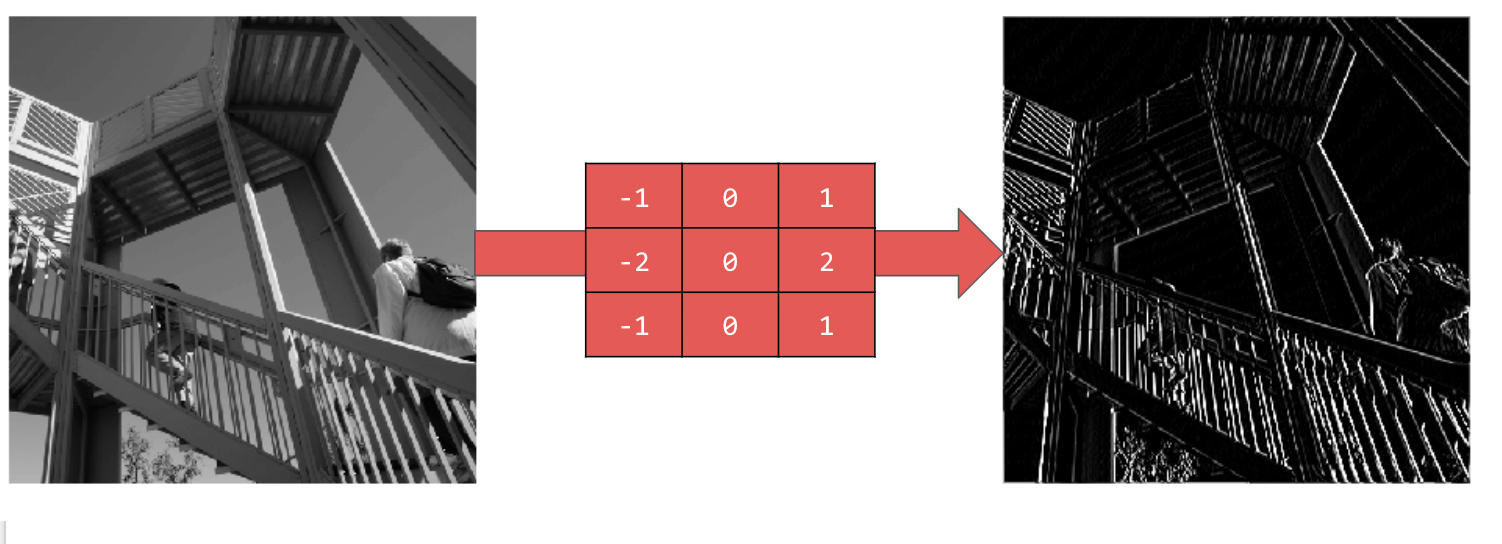
Sehen Sie sich die folgenden Filterwerte und ihre Auswirkungen auf das Bild an.
Mit [-1,0,1,-2,0,2,-1,0,1] erhalten Sie eine sehr starke Gruppe vertikaler Linien:
Mit [-1,-2,-1,0,0,0,1,2,1] erhalten Sie horizontale Linien:
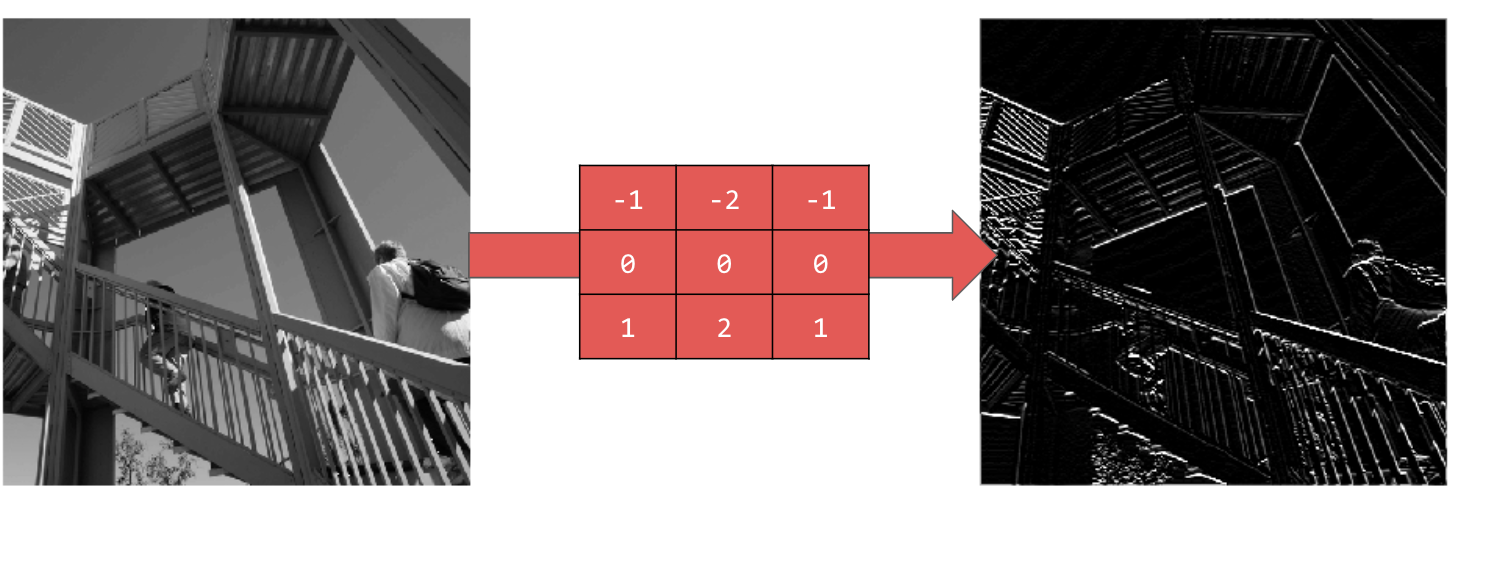
Probieren Sie verschiedene Werte aus. Versuchen Sie es auch mit Filtern unterschiedlicher Größe, z. B. 5 × 5 oder 7 × 7.
6. Pooling verstehen
Nachdem Sie die wesentlichen Merkmale des Bildes identifiziert haben, was tun Sie als Nächstes? Wie verwenden Sie die resultierende Feature-Map, um Bilder zu klassifizieren?
Ähnlich wie bei Faltungen hilft Pooling dabei, Merkmale zu erkennen. Durch Pooling-Ebenen wird die Gesamtmenge an Informationen in einem Bild reduziert, während die erkannten Merkmale beibehalten werden.
Es gibt verschiedene Arten von Pooling, aber Sie verwenden eine namens „Maximum Pooling“.
Gehen Sie das Bild Pixel für Pixel durch und berücksichtigen Sie dabei jeweils das Pixel und seine direkten Nachbarn rechts, darunter und rechts unten. Nehmen Sie den größten Wert (daher Max-Pooling) und laden Sie ihn in das neue Bild. Das neue Bild ist also nur ein Viertel so groß wie das alte. 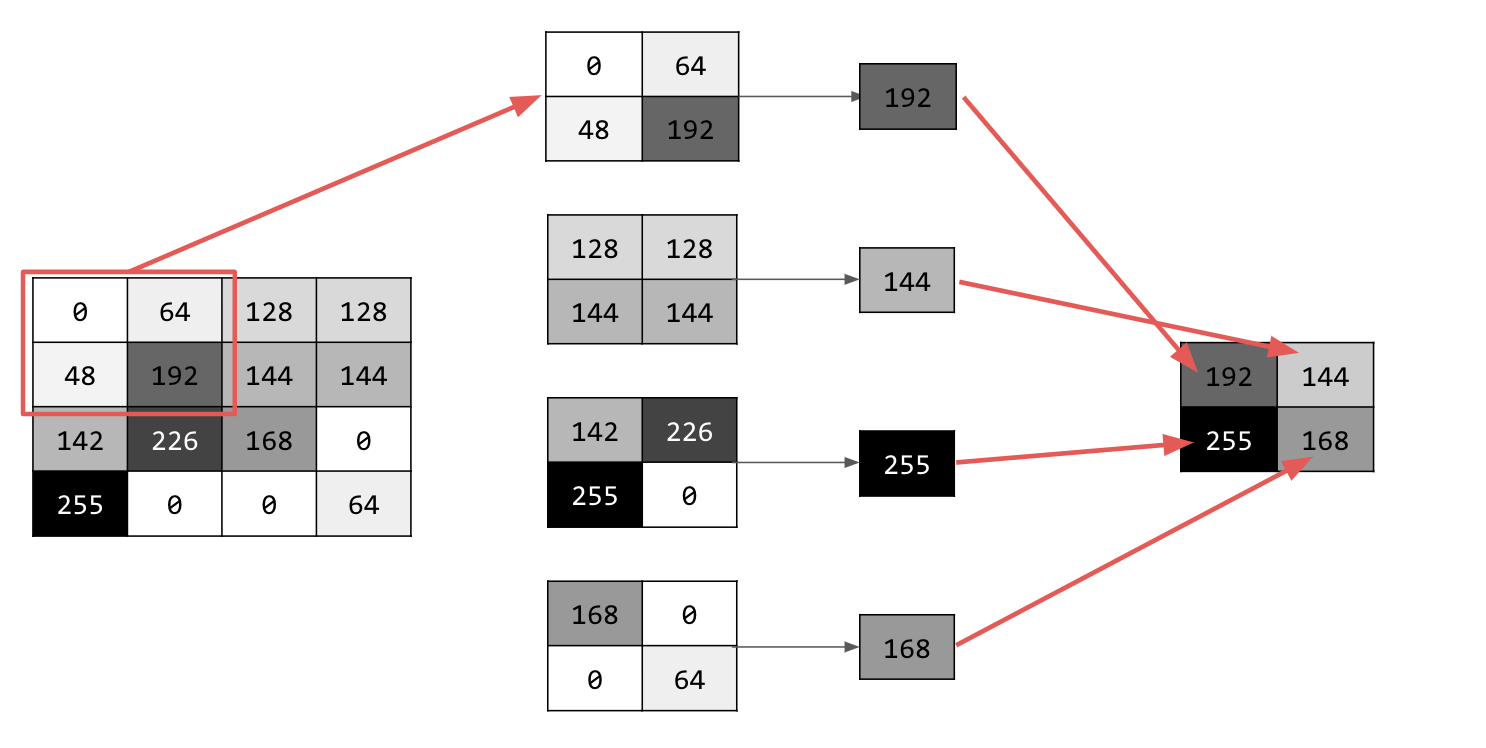
7. Code für Pooling schreiben
Der folgende Code zeigt ein (2, 2)-Pooling. Führen Sie den Code aus, um die Ausgabe zu sehen.
Das Bild ist nur noch ein Viertel so groß wie das Original, aber alle Funktionen sind erhalten geblieben.
new_x = int(size_x/2)
new_y = int(size_y/2)
newImage = np.zeros((new_x, new_y))
for x in range(0, size_x, 2):
for y in range(0, size_y, 2):
pixels = []
pixels.append(i_transformed[x, y])
pixels.append(i_transformed[x+1, y])
pixels.append(i_transformed[x, y+1])
pixels.append(i_transformed[x+1, y+1])
pixels.sort(reverse=True)
newImage[int(x/2),int(y/2)] = pixels[0]
# Plot the image. Note the size of the axes -- now 256 pixels instead of 512
plt.gray()
plt.grid(False)
plt.imshow(newImage)
#plt.axis('off')
plt.show()

Beachten Sie die Achsen dieses Diagramms. Das Bild hat jetzt eine Größe von 256 × 256 Pixeln, also ein Viertel der Originalgröße. Die erkannten Funktionen wurden trotz der geringeren Datenmenge im Bild optimiert.
8. Glückwunsch
Sie haben Ihr erstes Computer Vision-Modell erstellt. Informationen dazu, wie Sie Ihre Computer Vision-Modelle weiter optimieren können, finden Sie unter Convolutional Neural Networks (CNNs) zur Optimierung von Computer Vision erstellen.