
1. Trước khi bắt đầu
Việc nhập mã là một cách hiệu quả để tạo trí nhớ cơ bắp và hiểu sâu hơn về tài liệu. Mặc dù việc sao chép và dán có thể giúp bạn tiết kiệm thời gian, nhưng việc đầu tư vào phương pháp này có thể giúp bạn đạt được hiệu quả cao hơn và kỹ năng lập trình tốt hơn về lâu dài.
Trong lớp học lập trình này, bạn sẽ tìm hiểu cách tạo một tệp nhị phân phân đoạn hình ảnh C++ chạy trực tiếp trên thiết bị Android bằng cách sử dụng thời gian chạy hiệu suất cao trên thiết bị của Google, LiteRT. Thay vì sử dụng Kotlin hoặc Android Studio, lớp học lập trình này tập trung vào việc tạo một tệp nhị phân C++. Bạn sẽ biên dịch chéo bằng CMake hoặc Bazel và triển khai bằng ADB. Cùng một API LiteRT C++ hoạt động trên mọi nền tảng (Android, Linux, nhúng), khiến API này trở thành nền tảng hữu ích cho các ứng dụng quan trọng về hiệu suất, robot và hệ thống biên.
Bạn sẽ trải qua toàn bộ quy trình:
- Thiết lập môi trường tạo bản dựng (CMake + Android NDK hoặc Bazel).
- Liên kết LiteRT C++ SDK – từ bản phát hành được tạo sẵn hoặc từ nguồn.
- Sử dụng chương trình đổ bóng điện toán OpenGL ES để xử lý trước và sau hình ảnh được tăng tốc bằng GPU.
- Chạy mô hình phân đoạn
selfie_multiclassbằng LiteRT C++ API. - Tăng tốc suy luận trên CPU, GPU (OpenCL) và NPU (Qualcomm / MediaTek).
- Xử lý hậu kỳ đầu ra của mô hình thô thành một hình ảnh phân đoạn pha trộn màu.
- Triển khai đến một thiết bị Android thực bằng ADB và truy xuất kết quả.
Cuối cùng, bạn sẽ tạo ra một hình ảnh tương tự như hình ảnh sau đây – một hình ảnh tĩnh được xử lý thông qua toàn bộ quy trình, trong đó mỗi lớp phân đoạn trong số 6 lớp được phủ lên một màu riêng biệt:

Điều kiện tiên quyết
Lớp học lập trình này dành cho những nhà phát triển thành thạo C++ và muốn có kinh nghiệm chạy các mô hình học máy trên Android ở lớp C++. Bạn cần thông thạo:
- Kiến thức cơ bản về C++ (con trỏ, vectơ, bao gồm).
- Các khái niệm cơ bản về Android/ADB (
adb push,adb shell). - Sử dụng cửa sổ dòng lệnh và tập lệnh shell trên Linux hoặc macOS.
Kiến thức bạn sẽ học được
- Cách biên dịch chéo một tệp nhị phân C++ cho
arm64-v8aAndroid bằng CMake + NDK hoặc Bazel. - Cách sử dụng LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) để suy luận hiệu quả trên thiết bị. - Cách chương trình đổ bóng điện toán OpenGL ES 3.1 tăng tốc quá trình xử lý trước và sau hoàn toàn trên GPU.
- Cách định cấu hình LiteRT để tăng tốc CPU, GPU (OpenCL) và NPU (Qualcomm HTP, MediaTek APU, Google Tensor).
- Sự khác biệt giữa suy luận đồng bộ (
Run) và không đồng bộ (RunAsync). - Cách triển khai và chạy tệp nhị phân C++ trên Android bằng ADB.
Bạn cần có
- Máy chạy Linux hoặc macOS (người dùng Windows nên sử dụng WSL2).
- Android NDK r25c trở lên (tải xuống).
- Đối với đường dẫn CMake: CMake ≥ 3.22 (
sudo apt-get install cmake). - Đối với đường dẫn Bazel: Bazel đã cài đặt, cộng với toàn bộ kho lưu trữ mẫu LiteRT.
- ADB trong
PATH(Công cụ nền tảng Android). - Một thiết bị Android thực – tốt nhất là đã được kiểm thử trên Galaxy S24/S25 hoặc Pixel.
2. Phân đoạn hình ảnh
Phân đoạn hình ảnh là một nhiệm vụ thị giác máy tính, trong đó chỉ định nhãn lớp cho mọi pixel trong hình ảnh. Không giống như tính năng phát hiện đối tượng (vẽ một khung hình chữ nhật), tính năng phân đoạn tạo ra thông tin chính xác đến từng pixel về vị trí bắt đầu và kết thúc của từng đối tượng.
Lớp học lập trình này sử dụng mô hình selfie_multiclass_256x256, phân loại từng pixel thành một trong 6 lớp:
Chỉ mục lớp | Phân đoạn |
0 | Thông tin khái quát |
1 | Hiệu làm tóc |
2 | Da cơ thể |
3 | Da mặt |
4 | Quần áo |
5 | Phụ kiện (kính, đồ trang sức, v.v.) |
Mô hình này xuất ra một tensor số thực có hình dạng [1, 256, 256, 6]. Đối với mỗi pixel 256×256, có 6 điểm số độ tin cậy – một điểm cho mỗi lớp. Lớp có điểm số cao nhất sẽ thắng pixel đó (argmax).
LiteRT: Hiệu suất ở rìa
LiteRT là thời gian chạy hiệu suất cao thế hệ tiếp theo của Google dành cho các mô hình TFLite. API C++ của Vulkan cho phép bạn truy cập trực tiếp vào các bộ tăng tốc phần cứng với mức hao tổn thấp và giao diện nhất quán trên cả 3 nền tảng:
- CPU – tương thích trên mọi thiết bị; suy luận ~128 mili giây trên thiết bị tầm trung.
- GPU (OpenCL) – Suy luận ~1 mili giây; ~17–43 mili giây từ đầu đến cuối, tuỳ thuộc vào chiến lược vùng đệm.
- NPU – Độ trễ từ đầu đến cuối khoảng 9–28 mili giây trên các thiết bị Qualcomm Snapdragon, MediaTek Dimensity 9400 và Google Tensor, tuỳ thuộc vào AOT. Biên dịch JIT.
Trừu tượng hoá khoá là CompiledModel: mô hình được biên dịch trước và tối ưu hoá cho phần cứng mục tiêu tại thời gian tải, giảm suy luận thành một lệnh gọi Run() trên các vùng đệm được phân bổ trước.
3. Bắt đầu thiết lập
Sao chép kho lưu trữ
git clone https://github.com/google-ai-edge/litert-samples.git
Tất cả tài nguyên cho lớp học lập trình này đều nằm trong:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Thư mục này có 2 dự án con, mỗi dự án là một bản dựng hoàn chỉnh của cùng một mẫu:
Thư mục | Hệ thống xây dựng | Phần phụ thuộc LiteRT |
| CMake + Android NDK | Được tạo sẵn |
| Bazel | Biên dịch LiteRT từ nguồn |
Chọn một đường dẫn và làm theo đường dẫn đó. Mã này giống nhau giữa hai thư mục – chỉ khác nhau về hệ thống xây dựng và chiến lược phần phụ thuộc. Nếu bạn muốn thiết lập nhanh nhất, hãy chọn use_prebuilt_litert/. Nếu bạn cần sửa đổi chính LiteRT hoặc làm việc trong một monorepo (một kho duy nhất) Bazel hiện có, hãy sử dụng build_from_source/.
Lưu ý về đường dẫn tệp
Tất cả đường dẫn tệp trong hướng dẫn này đều sử dụng định dạng Linux/macOS. Người dùng Windows nên sử dụng WSL2.
Tổng quan về thư mục
Cả hai dự án con đều dùng chung một bố cục nguồn:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Ngoài ra:
use_prebuilt_litert/thêmCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shvàthird_party/stb/.build_from_source/thêm một tệpBUILDBazel và sử dụngdeploy_and_run_on_android.shtrỏ đếnbazel-bin/.
4. Tìm hiểu cấu trúc dự án
3 điểm truy cập, 1 quy trình
main_cpu.cc, main_gpu.cc và main_npu.cc mỗi thành phần đều chứa một hàm main() điều khiển toàn bộ quy trình phân đoạn. Quy trình này giống nhau ở cả 3 trường hợp; chỉ có cấu hình trình tăng tốc LiteRT và chiến lược bộ nhớ đệm là khác nhau:
Tệp | Trình tăng tốc | Chiến lược đệm |
|
| Bộ nhớ CPU |
|
| Bộ nhớ CPU có phần phụ trợ OpenCL |
|
| Bộ nhớ CPU có tính năng dự phòng CPU |
Cả ba đều dùng chung các tiện ích ImageProcessor (chương trình đổ bóng điện toán OpenGL ES để xử lý trước và xử lý sau) và ImageUtils (STB image I/O).
Toàn bộ quy trình
Mọi điểm truy cập đều tuân theo cùng một cấu trúc gồm 5 giai đoạn:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Tải –
ImageUtils::LoadImage()giải mã JPEG vào bộ nhớ CPU bằng thư viện hình ảnh STB. - Tải lên –
processor.CreateOpenGLTexture()tải các pixel thô lên một hoạ tiết GPU (OpenGL RGBA8). - Xử lý trước –
processor.PreprocessInputForSegmentation()chạy một chương trình đổ bóng điện toán GLSL giúp đổi kích thước hoạ tiết thành 256×256 và chuẩn hoá các giá trị pixel từ[0, 1]thành[-1, 1]. Kết quả sẽ nằm trong một SSBO GPU. - Suy luận – Dữ liệu SSBO được ghi vào
TensorBuffervàcompiled_model.Run()LiteRT (hoặcRunAsync()) sẽ thực thi mô hình. - Postprocess – Đầu ra là số thực 6 kênh của mô hình được tách thành 6 SSBO mặt nạ một kênh, sau đó được pha trộn màu trở lại hình ảnh gốc.
- Lưu –
ImageUtils::SaveImage()ghi hình ảnh RGBA cuối cùng dưới dạng PNG.
5. Các API C++ Core LiteRT
Trước khi tạo, hãy làm quen với 3 loại LiteRT C++ chính được dùng trên tất cả các điểm truy cập. Tất cả đều nằm trong không gian tên litert::.
litert::Environment
Environment là bối cảnh gốc cho mọi thao tác LiteRT. Tạo một lần rồi truyền đến CompiledModel::Create. Để sử dụng NPU, hãy định cấu hình NPU bằng thư mục thư viện trình bổ trợ của nhà cung cấp.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel tải và biên dịch trước mô hình TFLite cho phần cứng được yêu cầu tại thời điểm tạo. Sau đó, suy luận sẽ giảm xuống thành việc điền vào các vùng đệm và gọi Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Vùng đệm tensor lưu trữ dữ liệu đầu vào/đầu ra. Luôn tạo các thành phần này từ CompiledModel để chúng có kích thước và căn chỉnh chính xác cho phần cứng mục tiêu.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Macro xử lý lỗi
Macro | Hành vi |
| Chỉ định hoặc gọi |
| Gọi |
| Chỉ định hoặc truyền lỗi cho người gọi |
6. Tạo – Lựa chọn A: SDK C++ LiteRT tạo sẵn (CMake)
Đây là đường dẫn được đề xuất nếu bạn không cần sửa đổi chính LiteRT. Tập lệnh bản dựng xử lý việc tải tiêu đề SDK xuống, sao chép .so, tìm nạp STB và gọi CMake + NDK trong một lệnh duy nhất.
Bước 1 — Tải libLiteRt.so xuống từ Maven
LiteRT cung cấp thời gian chạy dưới dạng một thư viện dùng chung bên trong AAR Android trên Google Maven. Tải tệp này xuống rồi giải nén arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Để hỗ trợ GPU, hãy trích xuất cả trình tăng tốc OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

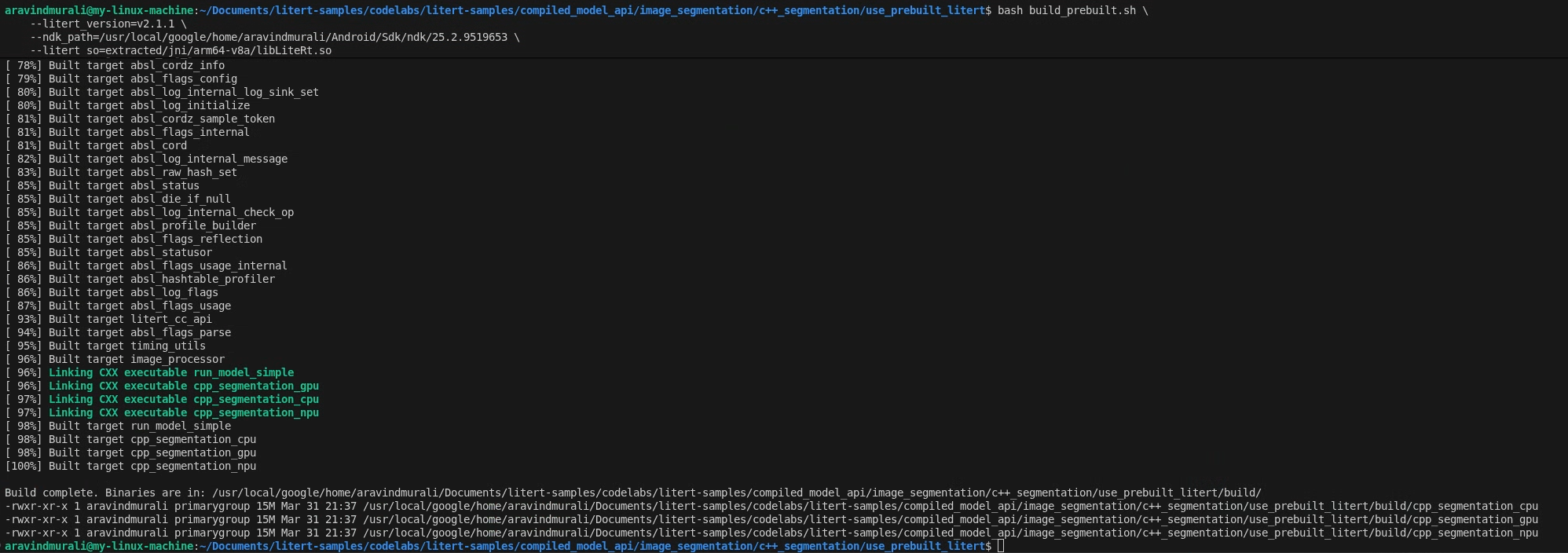
Bước 2 – Chạy build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Tập lệnh sẽ:
- Tải
litert_cc_sdk.zip(tiêu đề SDK + tệp cmake) xuống từ bản phát hành LiteRT trên GitHub – bỏ qua ở các lần chạy tiếp theo nếu đã có. - Sao chép
libLiteRt.sovàolitert_cc_sdk/. - Tải tiêu đề hình ảnh STB xuống
third_party/stb/– bỏ qua nếu có. - Định cấu hình và tạo bằng CMake bằng cách sử dụng chuỗi công cụ Android NDK cho
arm64-v8atạiandroid-26.
Khi thành công, bạn sẽ thấy 3 tệp nhị phân trong build/:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Chức năng của CMakeLists.txt
Mở CMakeLists.txt. Thao tác này yêu cầu C++20, kéo SDK LiteRT qua add_subdirectory, liên kết OpenGL ES 3 (GLESv3) và EGL, sau đó sử dụng macro trợ giúp để tạo từng tệp nhị phân từ nguồn main_*.cc:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Xây dựng – Lựa chọn B: Xây dựng bằng Bazel (Từ nguồn)
Chọn đường dẫn này nếu bạn muốn Bazel làm hệ thống xây dựng, hệ thống này sẽ biên dịch thời gian chạy LiteRT từ nguồn hoặc nếu bạn cần làm việc trong một không gian làm việc Bazel hiện có.
Điều kiện tiên quyết
Ngoài NDK và ADB được liệt kê trong phần "Trước khi bắt đầu", bạn sẽ cần:
- Bazel đã được cài đặt và có trên
PATHcủa bạn. - Bản sao đầy đủ của kho lưu trữ nguồn mẫu LiteRT.
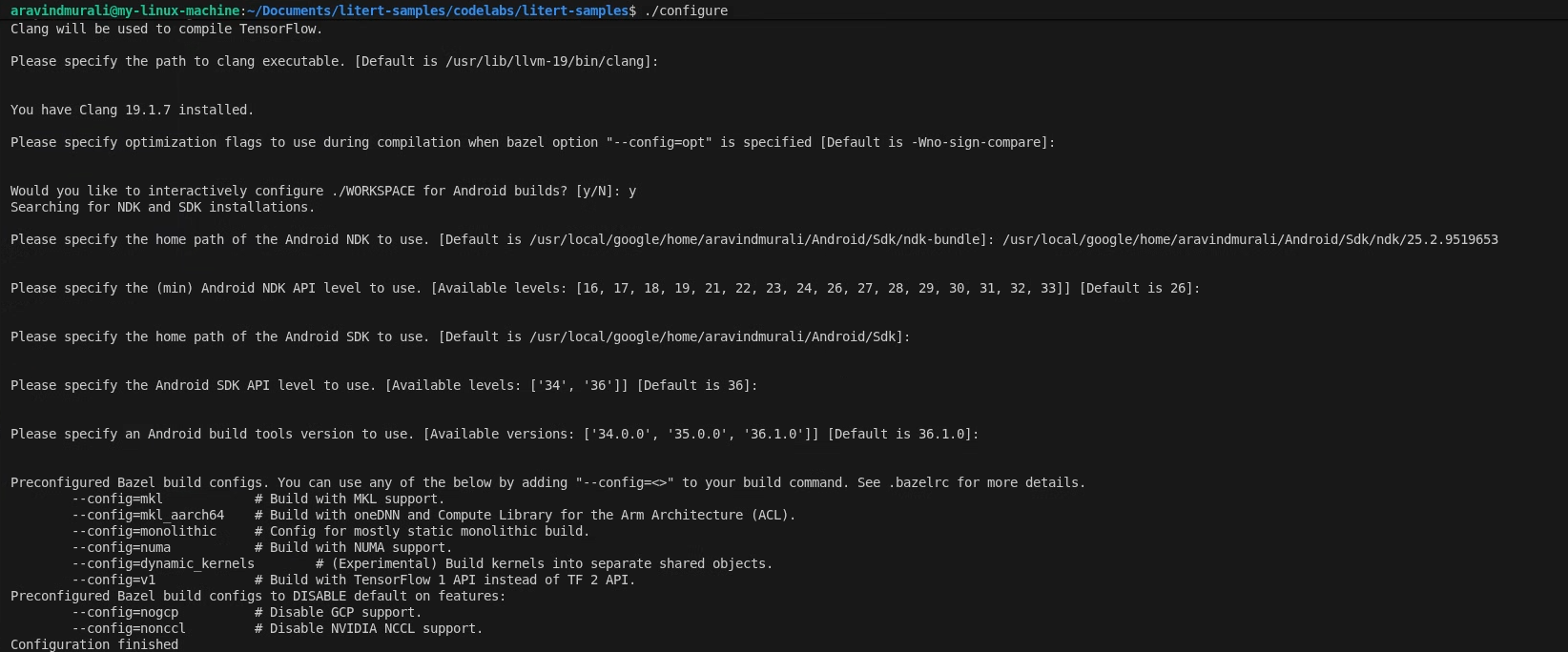
Bước 1 – Định cấu hình không gian làm việc mẫu LiteRT
Tất cả các lệnh đều chạy từ gốc của kho lưu trữ mẫu LiteRT
cd /path/to/litert-samples
./configure
Khi thấy lời nhắc:
- Chấp nhận các giá trị mặc định cho đường dẫn Python và đường dẫn thư viện Python.
- Trả lời N cho ROCm và CUDA.
- Chọn clang (đã thử nghiệm với 18.1.3) làm trình biên dịch.
- Chấp nhận các cờ tối ưu hoá mặc định.
- Trả lời Y để định cấu hình WORKSPACE cho các bản dựng Android.
- Đặt cấp độ Android NDK tối thiểu thành ít nhất là 26.
- Cung cấp đường dẫn đến SDK Android.
- Đặt cấp độ API SDK Android thành mặc định (36) và công cụ xây dựng thành 36.0.0.
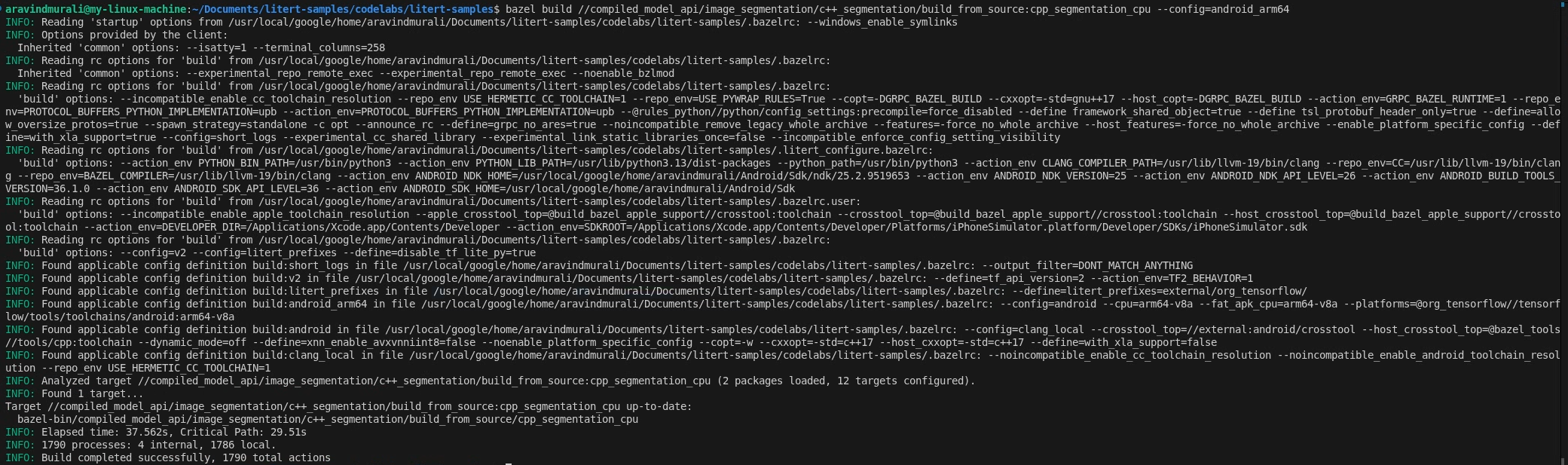
Bước 2 – Tạo các mục tiêu CPU và GPU
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Bước 3 – Tạo mục tiêu NPU
Qualcomm HTP
- Tải QAIRT SDK phiên bản 2.41 trở lên xuống rồi giải nén.
- Đảm bảo nội dung SDK đã trích xuất nằm trong một thư mục con có tên là
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Tạo bản dựng, truyền đường dẫn mẹ kết thúc bằng
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Cần có cờ --nocheck_visibility vì một số mục tiêu LiteRT ở nguồn trên có chế độ hiển thị mặc định bị hạn chế.
APU của MediaTek
Bạn không cần phải có SDK khác. Thời gian chạy NeuroPilot là một thư viện hệ thống trên các thiết bị Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
Tệp BUILD
Mở build_from_source/BUILD. Thư viện này xác định 4 mục tiêu cc_binary – một mục tiêu cho mỗi bộ tăng tốc, cộng với một mục tiêu NPU MediaTek chuyên dụng – mỗi mục tiêu phụ thuộc vào các mục tiêu thư viện image_processor, image_utils và timing_utils dùng chung:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
Mục tiêu GPU thêm libLiteRtClGlAccelerator.so làm phần phụ thuộc dữ liệu để Bazel đưa phần phụ thuộc này vào runfiles. Các mục tiêu NPU sẽ thêm các tệp .so trình bổ trợ trình biên dịch và điều phối của nhà cung cấp dưới dạng các phần phụ thuộc dữ liệu.
8. Xử lý trước tăng tốc bằng GPU với chương trình đổ bóng điện toán
Cả 3 điểm truy cập đều sử dụng cùng một quy trình chương trình đổ bóng điện toán OpenGL ES để xử lý trước. Việc hiểu rõ điều này là chìa khoá để hiểu lý do đường dẫn GPU nhanh hơn nhiều so với đường dẫn CPU.
Thiết lập bối cảnh EGL không có giao diện người dùng
ImageProcessor::InitializeGL() tạo một ngữ cảnh EGL không có giao diện người dùng – một ngữ cảnh OpenGL không có cửa sổ hoặc màn hình nào được đính kèm. Đây là phương pháp tiêu chuẩn để tính toán GPU ngoài màn hình trên Android. Sau đó, chương trình này sẽ biên dịch 5 chương trình đổ bóng điện toán GLSL từ đĩa:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Tải hình ảnh đầu vào lên GPU
JPEG được ImageUtils::LoadImage() giải mã thành bộ nhớ CPU (thông qua thư viện STB), sau đó được tải lên một kết cấu GPU:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
Từ thời điểm này, hình ảnh gốc sẽ nằm trong bộ nhớ GPU dưới dạng hoạ tiết OpenGL.
Chương trình đổ bóng điện toán tiền xử lý
shaders/preprocess_compute.glsl gửi 8×8 nhóm luồng trên lưới đầu ra 256×256. Mỗi luồng xử lý một pixel đầu ra: luồng này lấy mẫu kết cấu đầu vào bằng cách sử dụng bộ lọc song tuyến (thay đổi kích thước phần cứng miễn phí), chuyển đổi giá trị RGB [0, 1] thành [-1, 1] và ghi vào SSBO đầu ra:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Đối với đường dẫn tiêu chuẩn (không sao chép), SSBO này sẽ được đọc lại vào CPU và ghi vào tensor LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Suy luận CPU
Mở main_cpu.cc. Thiết lập LiteRT có 3 dòng:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Sau khi xử lý trước, suy luận là một lệnh gọi đồng bộ duy nhất:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() sẽ chặn cho đến khi quá trình suy luận hoàn tất. Mô hình dấu phẩy động selfie_multiclass_256x256.tflite chạy trên các lõi ARM Cortex và thường mất khoảng 116 – 128 mili giây trên một thiết bị tầm trung.
Cách sử dụng tệp nhị phân:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Suy luận GPU (OpenCL)
Mở main_gpu.cc. Đường dẫn GPU giới thiệu 2 khái niệm không có trong đường dẫn CPU: litert::Options để định cấu hình trình tăng tốc GPU (với phần phụ trợ OpenCL) và quá trình thực thi không đồng bộ.
Định cấu hình các lựa chọn về GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Suy luận không đồng bộ
Đường dẫn GPU sử dụng RunAsync() thay vì Run(). Thao tác này sẽ gửi công việc đến hàng đợi lệnh GPU và trả về ngay lập tức. Sau đó, bạn đồng bộ hoá trước khi đọc kết quả:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Thiết kế không chặn này cho phép bạn chồng chéo hoạt động của CPU với quá trình thực thi GPU trong một quy trình theo thời gian thực.
Cách sử dụng tệp nhị phân:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Xử lý hậu kỳ – Loại bỏ hiệu ứng đan xen và trộn
Sau khi Run() hoặc RunAsync() hoàn tất, output_buffers[0] sẽ giữ một mảng số thực có độ chính xác đơn dạng phẳng [256 × 256 × 6] theo thứ tự xen kẽ. 6 điểm số của lớp cho pixel (row, col) nằm ở các chỉ mục từ (row * 256 + col) * 6 đến (row * 256 + col) * 6 + 5.
Phân tách thành 6 SSBO mặt nạ
Trình trợ giúp CPU chia mảng xen kẽ thành 6 mảng số thực có một kênh và tải từng mảng lên SSBO GPU riêng:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Mặt nạ pha trộn màu trên hình ảnh gốc
processor.ApplyColoredMasks() chạy chương trình đổ bóng mask_blend_compute.glsl. Đối với mỗi pixel đầu ra, nó sẽ tìm thấy loại có điểm số cao nhất (argmax trên 6 SSBO mặt nạ) và kết hợp màu tương ứng với điểm ảnh hình ảnh ban đầu. Sáu màu được xác định trong mỗi điểm truy cập:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
Alpha của 0.1f giữ cho sắc thái có độ đậm vừa phải để hình ảnh gốc vẫn hiển thị.
Lưu kết quả
SSBO số thực RGBA kết hợp cuối cùng được đọc lại, giới hạn ở [0, 1], chuyển đổi thành unsigned char và lưu dưới dạng PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Triển khai và chạy trên thiết bị
Kết nối thiết bị Android bằng USB và xác minh khả năng kết nối ADB:
adb devices

Sử dụng deploy_and_run_on_android.sh
Mỗi biến thể có một tập lệnh triển khai riêng. Biến thể CMake trỏ đến thư mục build/; biến thể Bazel trỏ đến bazel-bin/. Cả hai tập lệnh:
- Tạo
/data/local/tmp/cpp_segmentation_android/trên thiết bị. - Đẩy các tệp nhị phân, chương trình đổ bóng GLSL, mô hình, hình ảnh kiểm thử và thời gian chạy
.so. - Chạy suy luận bằng
adb shell. - Kéo
output_segmented.pngvề lại máy.
Biến thể CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Biến thể Bazel (build_from_source/)
Chạy các lệnh này từ thư mục gốc của kho lưu trữ mẫu LiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
Cờ --phone kiểm soát việc sử dụng mô hình và thư viện nhà cung cấp dành riêng cho thiết bị. Giá trị được hỗ trợ: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) và pixel11 (Tensor G6).
Thời gian suy luận
Sau khi suy luận, PrintTiming() sẽ in thông tin chi tiết đầy đủ về việc phân tích tài nguyên:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Hiệu suất tham chiếu trên Samsung S25 Ultra (Snapdragon 8 Elite):
Trình tăng tốc | Loại thực thi | Suy luận | E2E |
CPU | Đồng bộ hoá | ~116 – 128 mili giây | ~157 mili giây |
GPU (OpenCL) | Không đồng bộ | ~0,95 mili giây | ~35–43 mili giây |
13. Nâng cao (Không bắt buộc): Suy luận NPU
Để đạt hiệu suất tối đa, LiteRT hỗ trợ tính năng tăng tốc NPU bằng cách sử dụng các thư viện trình bổ trợ dành riêng cho nhà cung cấp. Đường dẫn NPU có thể đạt được độ trễ đầu cuối thấp đến 9 mili giây.
Thiết bị và chế độ được hỗ trợ
Khối | Ví dụ về thiết bị | Chế độ | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 mili giây |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 mili giây |
Qualcomm (bất kỳ) | — | JIT | ~28 mili giây |
MediaTek Dimensity 9400 | — | JIT | ~9 mili giây |
Google Tensor G3 – G6 | Pixel 8 – 11 | AOT/JIT | Thay đổi |
AOT (Trước thời gian) sử dụng một mô hình được biên dịch trước dành riêng cho thiết bị (ví dụ: selfie_multiclass_256x256_SM8650.tflite). Đây là lựa chọn nhanh nhất nhưng dành riêng cho từng chip.
JIT (Trong khi thực thi) sử dụng selfie_multiclass_256x256.tflite tiêu chuẩn và biên dịch sang NPU trong thời gian chạy – lần chạy đầu tiên chậm hơn, độc lập với chip.
Điều kiện tiên quyết bổ sung
Qualcomm HTP:
- QAIRT SDK phiên bản 2.41 trở lên (cung cấp các tệp
libQnnHtp.so, stub hoặc skel.so). libLiteRtDispatch_Qualcomm.sotừ bản phát hành thư viện thời gian chạy NPU LiteRT trên GitHub.
APU MediaTek:
libLiteRtDispatch_MediaTek.sotừ bản phát hành thư viện thời gian chạy NPU LiteRT.- Thời gian chạy NeuroPilot (đã là một thư viện hệ thống trên các thiết bị Dimensity 9400 – không cần đẩy).
Google Tensor:
libLiteRtDispatch_GoogleTensor.sotừ bản phát hành thư viện thời gian chạy NPU LiteRT.
Môi trường và các lựa chọn của NPU
main_npu.cc trỏ Environment đến thư mục thư viện gửi của nhà cung cấp trên thiết bị, sau đó đặt các lựa chọn hiệu suất dành riêng cho nhà cung cấp:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
Đối với MediaTek, hãy thay thế khối GetQualcommOptions():
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Triển khai cho NPU
Biến thể CMake – Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Biến thể CMake – MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Biến thể Bazel – Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Biến thể Bazel – MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Biến thể Bazel – Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Đối với biến thể Bazel, các thư viện QAIRT SDK sẽ tự động được chọn từ cây tệp chạy bazel-bin khi LITERT_QAIRT_SDK được đặt tại thời gian xây dựng. Biến thể CMake yêu cầu cờ --host_npu_lib trỏ đến QAIRT SDK đã trích xuất.
14. Xin chúc mừng!
Bạn đã tạo và chạy thành công một quy trình phân đoạn hình ảnh C++ trên Android bằng LiteRT. Bạn đã tìm hiểu cách:
- Biên dịch chéo một tệp nhị phân C++ cho Android
arm64-v8abằng CMake + NDK hoặc Bazel. - Sử dụng LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) để suy luận hiệu quả trên thiết bị. - Xử lý trước dữ liệu hình ảnh trên GPU bằng chương trình đổ bóng điện toán OpenGL ES 3.1.
- Chạy suy luận CPU đồng bộ và suy luận GPU (OpenCL) không đồng bộ.
- Định cấu hình tính năng tăng tốc NPU cho các thiết bị Qualcomm, MediaTek và Google Tensor.
- Triển khai và chạy một tệp nhị phân C++ trên Android bằng ADB.
Các bước tiếp theo
- Thay thế bằng một mô hình TFLite khác (ví dụ: ước tính độ sâu hoặc phát hiện tư thế).
- Tích hợp quy trình C++ vào một ứng dụng Android NDK bằng JNI.
- Lập hồ sơ về mức sử dụng bộ nhớ bằng Trình kiểm tra GPU Android cùng với đầu ra thời gian.
- Khám phá việc định lượng mô hình để giảm thêm độ trễ suy luận NPU.