
1. Başlamadan önce
Kod yazmak, kas hafızası oluşturmak ve materyali daha iyi anlamak için harika bir yöntemdir. Kopyalama ve yapıştırma işlemi zaman kazandırsa da bu uygulamaya yatırım yapmak uzun vadede daha fazla verimlilik ve daha güçlü kodlama becerileri sağlayabilir.
Bu codelab'de, Google'ın yüksek performanslı cihaz üzerinde çalışma zamanı LiteRT'yi kullanarak doğrudan bir Android cihazda çalışan bir C++ görüntü segmentasyonu ikili programı oluşturmayı öğreneceksiniz. Bu codelab, Kotlin veya Android Studio kullanmak yerine C++ ikili dosyası oluşturmaya odaklanmaktadır. CMake veya Bazel ile çapraz derleyip ADB kullanarak dağıtırsınız. Aynı LiteRT C++ API, herhangi bir platformda (Android, Linux, yerleştirilmiş) çalışır. Bu nedenle, performansı kritik öneme sahip uygulamalar, robotik ve uç sistemler için faydalı bir temel oluşturur.
Tüm ardışık düzeni adım adım inceleyeceksiniz:
- Derleme ortamını ayarlama (CMake + Android NDK veya Bazel).
- LiteRT C++ SDK'sını önceden oluşturulmuş bir sürümden veya kaynaktan bağlama.
- GPU hızlandırmalı görüntü ön ve son işleme için OpenGL ES bilgi işlem gölgelendiricilerini kullanma.
- LiteRT C++ API ile
selfie_multiclasssegmentasyon modelini çalıştırma. - CPU, GPU (OpenCL) ve NPU (Qualcomm / MediaTek) üzerinde çıkarım hızlandırma.
- Ham model çıkışını renk karışımlı bir segmentasyon görüntüsüne dönüştürmek için son işlem yapma.
- ADB ile fiziksel bir Android cihaza dağıtma ve sonucu alma.
Sonunda, aşağıdaki resme benzer bir sonuç elde edersiniz. Bu resimde, 6 segmentasyon sınıfının her biri farklı bir renkte yer alacak şekilde tam ardışık düzen üzerinden işlenmiş statik bir resim gösterilir:

Ön koşullar
Bu codelab, C++ ile rahat çalışan ve C++ katmanında Android'de makine öğrenimi modelleri çalıştırma konusunda deneyim kazanmak isteyen geliştiriciler için tasarlanmıştır. Aşağıdaki konular hakkında bilgi sahibi olmanız gerekir:
- C++ temelleri (işaretçiler, vektörler, include'lar).
- Temel Android/ADB kavramları (
adb push,adb shell). - Linux veya macOS'te terminal ve kabuk komut dosyaları kullanma.
Neler öğreneceksiniz?
- CMake + NDK veya Bazel ile Android
arm64-v8aiçin C++ ikili programını çapraz derleme - Cihaz üzerinde verimli çıkarım için LiteRT C++ API'sini (
Environment,CompiledModel,TensorBuffer) kullanma. - OpenGL ES 3.1 işlem gölgelendiricilerinin, ön ve son işlemeyi tamamen GPU'da nasıl hızlandırdığı.
- LiteRT'yi CPU, GPU (OpenCL) ve NPU (Qualcomm HTP, MediaTek APU, Google Tensor) hızlandırma için yapılandırma
- Eşzamanlı (
Run) ve eşzamansız (RunAsync) çıkarım arasındaki fark. - ADB kullanarak Android'de C++ ikili programı dağıtma ve çalıştırma
İhtiyacınız olanlar
- Linux veya macOS makine (Windows kullanıcıları WSL2'yi kullanmalıdır).
- Android NDK r25c veya sonraki sürümler (indirin).
- CMake yolu için: CMake ≥ 3.22 (
sudo apt-get install cmake). - Bazel yolu için: Bazel'in yüklü olması ve LiteRT örnekleri deposunun tamamı.
PATH(Android Platform Araçları) içindeki ADB.- Fiziksel bir Android cihaz (en iyi test Galaxy S24/S25 veya Pixel'de yapılır).
2. Görüntü Segmentasyonu
Görüntü segmentasyonu, bir görüntüdeki her piksele bir sınıf etiketi atayan bir bilgisayarla görme görevidir. Sınırlayıcı kutu çizen nesne algılamanın aksine, segmentasyon her nesnenin nerede başlayıp nerede bittiğine dair piksel düzeyinde kesin bir anlayış sağlar.
Bu codelab'de, her pikseli 6 sınıftan birine sınıflandıran selfie_multiclass_256x256 modeli kullanılır:
Sınıf dizini | Segment |
0 | Arka plan |
1 | Saç |
2 | Vücut derisi |
3 | Yüz cildi |
4 | Kıyafet |
5 | Aksesuarlar (gözlük, mücevher vb.) |
Model, [1, 256, 256, 6] şeklindeki bir kayan nokta tensörü çıkarır. 256x256 pikselin her biri için 6 güven puanı vardır (sınıf başına bir puan). En yüksek puana sahip sınıf, pikseli kazanır (argmax).
LiteRT: Uçta Performans
LiteRT, Google'ın TFLite modelleri için yeni nesil, yüksek performanslı çalışma zamanıdır. C++ API'si, üçü arasında tutarlı bir arayüzle donanım hızlandırıcılarına doğrudan ve düşük ek yükle erişmenizi sağlar:
- CPU: Evrensel olarak uyumludur. Orta sınıf bir cihazda çıkarım süresi yaklaşık 128 ms'dir.
- GPU (OpenCL): ~1 ms çıkarım; arabellek stratejisine bağlı olarak ~17-43 ms uçtan uca.
- NPU: AOT'ye bağlı olarak Qualcomm Snapdragon, MediaTek Dimensity 9400 ve Google Tensor cihazlarda uçtan uca ~9-28 ms. JIT derleme.
Temel soyutlama CompiledModel: Model, yükleme sırasında hedef donanım için önceden derlenir ve optimize edilir. Böylece çıkarım, önceden ayrılmış arabelleklerdeki bir Run() çağrısına indirgenir.
3. Kurun
Depoyu klonlama
git clone https://github.com/google-ai-edge/litert-samples.git
Bu codelab'deki tüm kaynaklar şu konumda yer alır:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Bu dizinde, her biri aynı örneğin eksiksiz bir derlemesi olan iki alt proje bulunur:
Dizin | Derleme sistemi | LiteRT bağımlılığı |
| CMake + Android NDK | Önceden oluşturulmuş |
| Bazel | LiteRT'yi kaynaktan derler. |
Bir yol seçip bu yolu izleyin. İki dizindeki kod aynıdır. Yalnızca derleme sistemi ve bağımlılık stratejisi farklıdır. En hızlı kurulumu istiyorsanız use_prebuilt_litert/ seçeneğini belirleyin. LiteRT'nin kendisini değiştirmeniz veya mevcut bir Bazel monoreposunda çalışmanız gerekiyorsa build_from_source/ kullanın.
Dosya yollarıyla ilgili not
Bu eğitimdeki tüm dosya yollarında Linux/macOS biçimi kullanılır. Windows kullanıcıları WSL2'yi kullanmalıdır.
Dizine genel bakış
Her iki alt proje de aynı kaynak düzenini paylaşıyor:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Ayrıca:
use_prebuilt_litert/;CMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shvethird_party/stb/adlı kullanıcıları ekledi.build_from_source/, bir BazelBUILDdosyası ekler vebazel-bin/'ü işaret edendeploy_and_run_on_android.sh'yi kullanır.
4. Proje yapısını anlama
Üç giriş noktası, tek bir işlem hattı
main_cpu.cc, main_gpu.cc ve main_npu.cc öğelerinin her birinde, tam segmentasyon işlem hattını çalıştıran bir main() işlevi bulunur. Üçünde de ardışık düzen aynıdır. Yalnızca LiteRT hızlandırıcı yapılandırması ve arabellek stratejisi farklıdır:
Dosya | Accelerator | Arabellek stratejisi |
|
| CPU belleği |
|
| OpenCL arka ucuyla CPU belleği |
|
| CPU geri dönüşüyle CPU belleği |
Üçü de aynı ImageProcessor (ön işleme ve son işleme için OpenGL ES işlem gölgelendiricileri) ve ImageUtils (STB görüntü G/Ç) yardımcı programlarını kullanır.
Tam ardışık düzen
Her giriş noktası aynı beş aşamalı yapıyı izler:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Yükleme:
ImageUtils::LoadImage(), STB görüntü kitaplığını kullanarak JPEG'i CPU belleğinde kodunu çözer. - Yükleme:
processor.CreateOpenGLTexture(), ham pikselleri bir GPU dokusuna (OpenGL RGBA8) yükler. - Ön işleme:
processor.PreprocessInputForSegmentation(), dokuyu 256×256 boyutuna yeniden boyutlandıran ve piksel değerlerini[0, 1]ile[-1, 1]arasında normalleştiren bir GLSL işlem gölgelendiricisi çalıştırır. Sonuç, GPU SSBO'ya yerleştirilir. - Infer: SSBO verileri bir LiteRT
TensorBuffer'ye yazılır vecompiled_model.Run()(veyaRunAsync()) modeli yürütür. - İşlem sonrası: Modelin 6 kanallı kayan nokta çıkışı, 6 tek kanallı maske SSBO'larına ayrılır ve ardından renk karıştırma işlemiyle orijinal resme geri karıştırılır.
- Kaydet:
ImageUtils::SaveImage()son RGBA görüntüsünü PNG olarak yazar.
5. Core LiteRT C++ API'leri
Oluşturma işlemine başlamadan önce tüm giriş noktalarında kullanılan üç temel LiteRT C++ türü hakkında bilgi edinin. Tümü litert:: ad alanında bulunur.
litert::Environment
Environment, tüm LiteRT işlemleri için kök bağlamdır. Bir kez oluşturup CompiledModel::Create'a iletin. NPU kullanımı için satıcı eklenti kitaplığı diziniyle yapılandırın.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel, TFLite modelinizi oluşturma sırasında istenen donanım için yükler ve önceden derler. Çıkarım daha sonra arabellekleri doldurmaya ve Run() işlevini çağırmaya indirgenir.
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Tensör arabellekleri, giriş/çıkış verilerini tutar. Hedef donanım için doğru şekilde boyutlandırılıp hizalanmaları amacıyla bunları her zaman CompiledModel üzerinden oluşturun.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Hata işleme makroları
Makro | Davranış |
| Başarısızlık durumunda |
| İfade hata döndürürse |
| Arayana hata atama veya hatayı yayma |
6. Derleme - A Seçeneği: Önceden derlenmiş LiteRT C++ SDK'sı (CMake)
LiteRT'nin kendisini değiştirmeniz gerekmiyorsa bu yolu kullanmanız önerilir. Derleme komut dosyası, SDK üstbilgilerini indirme, .so dosyanızı kopyalama, STB'yi getirme ve CMake + NDK'yı tek bir komutla çağırma işlemlerini gerçekleştirir.
1. adım: Maven'dan libLiteRt.so alın
LiteRT, çalışma zamanını Google Maven'deki bir Android AAR'de paylaşılan kitaplık olarak gönderir. İndirin ve arm64-v8a .so dosyasını çıkarın:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
GPU desteği için OpenCL/GL hızlandırıcıyı da çıkarın:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

2. adım: build_prebuilt.sh testini çalıştırın
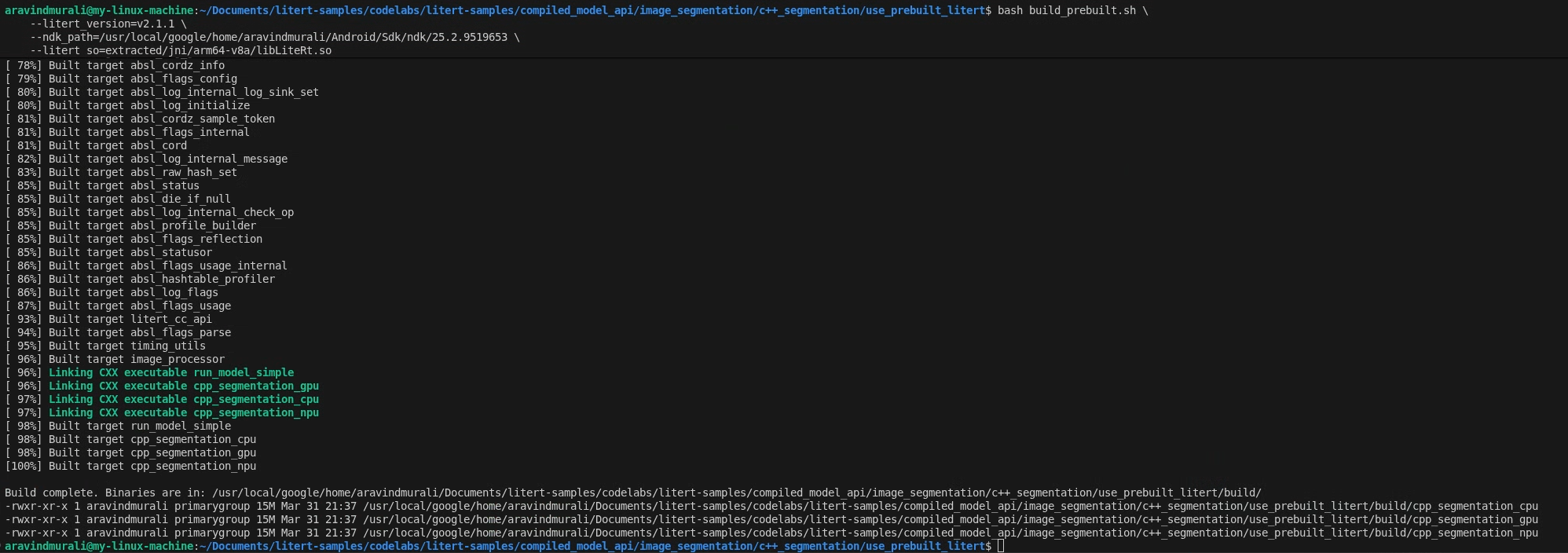
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Komut dosyası:
- LiteRT GitHub sürümünden
litert_cc_sdk.zip(SDK üstbilgileri + cmake dosyaları) indirin. Bu dosyalar mevcutsa sonraki çalıştırmalarda atlanır. libLiteRt.sodosyasınılitert_cc_sdk/içine kopyalayın.- STB resim başlıklarını
third_party/stb/içine indirin. Varsa bu adım atlanır. android-26adresindekiarm64-v8aiçin Android NDK araç zincirini kullanarak CMake ile yapılandırın ve derleyin.
Başarılı olursa build/ içinde üç ikili dosya görürsünüz:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
CMakeLists.txt ne işe yarar?
CMakeLists.txt adlı kişiyi aç. C++20 gerektirir, add_subdirectory aracılığıyla LiteRT SDK'sını çeker, OpenGL ES 3 (GLESv3) ve EGL'yi bağlar, ardından her ikili programı main_*.cc kaynağından oluşturmak için yardımcı bir makro kullanır:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Derleme - B Seçeneği: Bazel ile Derleme (Kaynaktan)
LiteRT çalışma zamanını kaynaktan derleyen derleme sistemi olarak Bazel'i tercih ediyorsanız veya mevcut bir Bazel çalışma alanında çalışmanız gerekiyorsa bu yolu seçin.
Ön koşullar
"Başlamadan önce" bölümünde listelenen NDK ve ADB'ye ek olarak şunlara ihtiyacınız olacaktır:
- Bazel'in
PATHcihazınıza yüklenmiş olması gerekir. - LiteRT örnekleri kaynak deposunun tam klonu.
1. adım: LiteRT örnekleri çalışma alanını yapılandırın
Tüm komutlar LiteRT örnekleri deposunun kökünden çalıştırılır.
cd /path/to/litert-samples
./configure
İstendiğinde:
- Python ve Python kitaplık yolu için varsayılanları kabul edin.
- ROCm ve CUDA desteği için N yanıtını verin.
- Derleyici olarak clang'ı (18.1.3 ile test edilmiştir) seçin.
- Varsayılan optimizasyon işaretlerini kabul edin.
- Android derlemeleri için WORKSPACE'i yapılandırmak üzere Y yanıtını verin.
- Minimum Android NDK düzeyini en az 26 olarak ayarlayın.
- Android SDK'nızın yolunu belirtin.
- Android SDK API düzeyini varsayılan (36) olarak, derleme araçlarını ise 36.0.0 olarak ayarlayın.
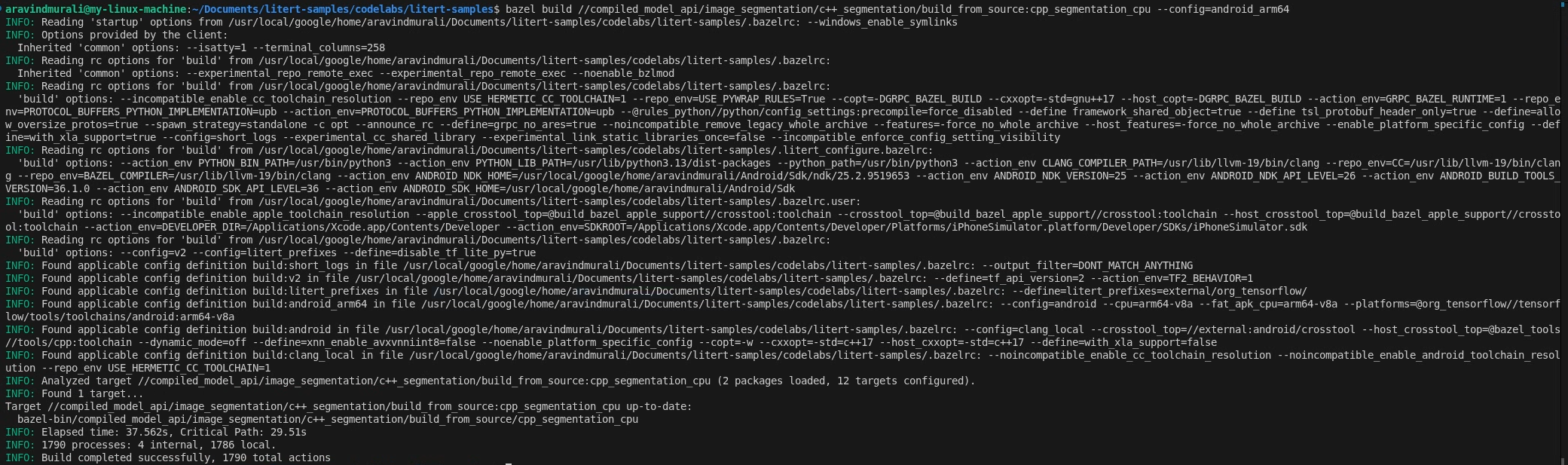
2. adım: CPU ve GPU hedeflerini oluşturun
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
3. adım: NPU hedefini oluşturun
Qualcomm HTP
- QAIRT SDK'sının 2.41 veya sonraki bir sürümünü indirip ayıklayın.
- Ayıklanan SDK içeriklerinin
latest/adlı bir alt dizinde olduğundan emin olun:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... /ile biten üst öğe yolunu ileterek oluşturun:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Bazı yukarı akış LiteRT hedeflerinde görünürlük varsayılanları kısıtlanmış olduğundan --nocheck_visibility işareti zorunludur.
MediaTek APU
Başka bir SDK gerekmez. NeuroPilot çalışma zamanı, Dimensity 9400 cihazlardaki bir sistem kitaplığıdır.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
BUILD dosyası
build_from_source/BUILD adlı kişiyi aç. Paylaşılan image_processor, image_utils ve timing_utils kitaplık hedeflerine bağlı olarak her hızlandırıcı için birer tane olmak üzere dört cc_binary hedef ve özel bir MediaTek NPU hedefi tanımlar:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
GPU hedefi, libLiteRtClGlAccelerator.so öğesini veri bağımlılığı olarak ekler. Böylece Bazel, bu öğeyi runfiles'a dahil eder. NPU hedefleri, tedarikçi dağıtım ve derleyici eklentisi .so dosyalarını veri bağımlılıkları olarak ekler.
8. Compute Shader'larla GPU Hızlandırmalı Ön İşleme
Üç giriş noktasının tümünde, ön işleme için aynı OpenGL ES hesaplama gölgelendirici işlem hattı kullanılır. Bu durumu anlamak, GPU yolunun neden CPU yolundan çok daha hızlı olduğunu anlamak için önemlidir.
Gözetimsiz EGL bağlamı ayarlama
ImageProcessor::InitializeGL(), pencere veya ekranı olmayan bir OpenGL bağlamı olan başsız EGL bağlamı oluşturur. Bu, Android'de ekran dışı GPU hesaplama için standart bir uygulamadır. Ardından, diskteki beş GLSL işlem gölgelendirici programını derler:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Giriş resmini GPU'ya yükleyin.
JPEG, ImageUtils::LoadImage() tarafından (STB kitaplığı aracılığıyla) CPU belleğinde kod çözülür ve ardından bir GPU dokusuna yüklenir:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
Bu noktadan itibaren orijinal resim, GPU belleğinde OpenGL dokusu olarak bulunur.
Ön işleme hesaplama gölgelendiricisi
shaders/preprocess_compute.glsl 256×256 çıkış ızgarasında 8×8 iş parçacığı grupları gönderir. Her iş parçacığı bir çıkış pikselini işler: Giriş dokusunu çift doğrusal filtreleme (ücretsiz donanım yeniden boyutlandırma) kullanarak örnekler, [0, 1] RGB değerini [-1, 1] değerine dönüştürür ve çıkış SSBO'ya yazar:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Standart (sıfır kopyalı olmayan) yol için bu SSBO daha sonra CPU'ya geri okunur ve LiteRT tensörüne yazılır:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. CPU Çıkarımı
main_cpu.cc adlı kişiyi aç. LiteRT kurulumu üç satırdan oluşur:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Ön işleme sonrasında çıkarım, tek bir eşzamanlı çağrıdır:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Çıkarım tamamlanana kadar Run() blokları. selfie_multiclass_256x256.tflite kayan nokta modeli, ARM Cortex çekirdeklerinde çalışır ve genellikle orta seviye bir cihazda ~116-128 ms sürer.
İkili program kullanımı:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. GPU çıkarımı (OpenCL)
main_gpu.cc adlı kişiyi aç. GPU yolunda, CPU yolunda bulunmayan iki kavram tanıtılır: GPU hızlandırıcıyı (OpenCL arka ucuyla) yapılandırmak için litert::Options ve eşzamansız yürütme.
GPU seçeneklerini yapılandırma
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Eşzamansız çıkarım
GPU yolu, Run() yerine RunAsync() kullanır. Bu, işi GPU komut sırasına gönderir ve hemen geri döner. Ardından, sonuçları okumadan önce senkronize edin:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Bu engellemeyen tasarım, gerçek zamanlı bir ardışık düzende CPU çalışmasını GPU yürütmeyle çakıştırmanıza olanak tanır.
İkili program kullanımı:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. İşleme sonrası: Araya girme ve karıştırma
Run() veya RunAsync() tamamlandıktan sonra output_buffers[0], şekli [256 × 256 × 6] olan düz bir kayan nokta dizisini aralıklı sırada tutar. (row, col) pikselinin 6 sınıf puanı, (row * 256 + col) * 6 ile (row * 256 + col) * 6 + 5 arasındaki indekslerde yer alır.
6 maskeli SSBO'ya ayır
CPU yardımcı programı, araya yerleştirilmiş diziyi 6 tek kanallı kayan nokta dizisine böler ve her birini kendi GPU SSBO'suna yükler:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Renk karıştırma maskelerini orijinal resme uygulayın
processor.ApplyColoredMasks(), mask_blend_compute.glsl gölgelendiricisini çalıştırır. Her çıktı pikseli için en yüksek puana sahip sınıfı (6 maske SSBO'ları arasında argmax) bulur ve ilgili rengi orijinal resim pikseli üzerinde alfa bileşimiyle oluşturur. Altı renk, her giriş noktasında tanımlanır:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
0.1f öğesinin alfa değeri, orijinal resmin görünür kalması için renk tonunu hafif tutar.
Çıkışı kaydetme
Son karıştırılmış RGBA kayan noktalı SSBO geri okunur, [0, 1] değerine sabitlenir, unsigned char değerine dönüştürülür ve PNG olarak kaydedilir:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Cihazda Dağıtma ve Çalıştırma
USB kullanarak Android cihazınızı bağlayın ve ADB bağlantısını doğrulayın:
adb devices

deploy_and_run_on_android.sh hareketini kullanın
Her varyantın kendi dağıtım komut dosyası vardır. CMake varyantı build/ dizinini, Bazel varyantı ise bazel-bin/ dizinini gösterir. Her iki komut dosyası:
- Cihazda
/data/local/tmp/cpp_segmentation_android/oluşturun. - İkili programı, GLSL gölgelendiricileri, modeli, test görüntüsünü ve çalışma zamanı
.sodosyalarını gönderin. adb shellkullanarak çıkarım çalıştırma.output_segmented.pngsimgesini makinenize doğru geri çekin.
CMake varyantı (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Bazel varyantı (build_from_source/)
Bu komutları LiteRT örnekleri deposunun kökünden çalıştırın:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
--phone işareti, cihaza özel hangi model ve satıcı kitaplıklarının kullanılacağını kontrol eder. Desteklenen değerler: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) ve pixel11 (Tensor G6).
Çıkarım Zamanlaması
Çıkarım işleminden sonra PrintTiming(), tam bir profil oluşturma dökümü yazdırır:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Samsung S25 Ultra'daki (Snapdragon 8 Elite) referans performansı:
Accelerator | Yürütme türü | Çıkarım | E2E |
CPU | Sync | ~116-128 ms | ~157 ms |
GPU (OpenCL) | Asenk. | ~0,95 ms | ~35-43 ms |
13. Gelişmiş (isteğe bağlı): NPU çıkarımı
LiteRT, maksimum performans için tedarikçiye özel eklenti kitaplıklarını kullanarak NPU hızlandırmayı destekler. NPU yolu, 9 ms kadar düşük bir uçtan uca gecikme süresi sağlayabilir.
Desteklenen cihazlar ve modlar
Çip | Cihaz örneği | Mod | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 ms |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 ms |
Qualcomm (herhangi biri) | — | JIT | ~28 ms |
MediaTek Dimensity 9400 | — | JIT | ~9 ms |
Google Tensor G3-G6 | Pixel 8-11 | AOT/JIT | Değişir |
AOT (Ahead-of-Time), cihaza özel önceden derlenmiş bir model (ör. selfie_multiclass_256x256_SM8650.tflite) kullanır. Bunlar en hızlı seçenektir ancak çipe özeldir.
JIT (Just-in-Time), standart selfie_multiclass_256x256.tflite kullanır ve çalışma zamanında NPU'ya derler. Bu nedenle, ilk çalıştırma daha yavaştır ve çipten bağımsızdır.
Ek ön koşullar
Qualcomm HTP:
- QAIRT SDK v2.41 veya sonraki bir sürümü (
libQnnHtp.so, stub veya skel.sodosyaları sağlar). libLiteRtDispatch_Qualcomm.so, GitHub'daki LiteRT NPU çalışma zamanı kitaplıkları sürümünden.
MediaTek APU:
- LiteRT NPU çalışma zamanı kitaplıkları sürümünden
libLiteRtDispatch_MediaTek.so. - NeuroPilot çalışma zamanı (Dimensity 9400 cihazlarda zaten bir sistem kitaplığıdır, herhangi bir şeyin gönderilmesi gerekmez).
Google Tensor:
- LiteRT NPU çalışma zamanı kitaplıkları sürümünden
libLiteRtDispatch_GoogleTensor.so.
NPU ortamı ve seçenekleri
main_npu.cc, cihazdaki satıcı gönderim kitaplığı dizinini Environment ile gösterir ve ardından satıcıya özel performans seçeneklerini ayarlar:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
MediaTek için GetQualcommOptions() bloğunu değiştirin:
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
NPU için dağıtma
CMake varyantı: Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
CMake varyantı: MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Bazel varyantı: Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Bazel varyantı: MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Bazel varyantı: Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Bazel varyantında, LITERT_QAIRT_SDK derleme sırasında ayarlandığında QAIRT SDK kitaplıkları bazel-bin runfiles ağacından otomatik olarak alınır. CMake varyantı, --host_npu_lib işaretinin çıkarılan QAIRT SDK'nızı göstermesini gerektirir.
14. Tebrikler!
LiteRT'yi kullanarak Android'de başarıyla bir C++ görüntü segmentasyonu ardışık düzeni oluşturup çalıştırdınız. Öğrendikleriniz:
- CMake + NDK veya Bazel ile Android
arm64-v8aiçin C++ ikili programını çapraz derleyin. - Cihaz üzerinde verimli çıkarım için LiteRT C++ API'sini (
Environment,CompiledModel,TensorBuffer) kullanın. - OpenGL ES 3.1 işlem gölgelendiricileriyle görüntü verilerini GPU'da önceden işleyin.
- Eşzamanlı CPU çıkarımı ve eşzamansız GPU (OpenCL) çıkarımı çalıştırın.
- Qualcomm, MediaTek ve Google Tensor cihazlar için NPU hızlandırmayı yapılandırın.
- ADB'yi kullanarak Android'de C++ ikili dosyası dağıtma ve çalıştırma
Sonraki Adımlar
- Farklı bir TFLite modeli (ör. derinlik tahmini veya poz algılama) kullanın.
- JNI kullanarak C++ ardışık düzenini bir Android NDK uygulamasına entegre edin.
- Zamanlama çıkışının yanı sıra Android GPU Inspector ile bellek kullanımını profillendirin.
- NPU çıkarım gecikmesini daha da azaltmak için model nicemlemeyi keşfedin.