
1. ก่อนเริ่มต้น
การพิมพ์โค้ดเป็นวิธีที่ยอดเยี่ยมในการสร้างความจำของกล้ามเนื้อและเพิ่มความเข้าใจในเนื้อหา แม้ว่าการคัดลอกและวางจะช่วยประหยัดเวลาได้ แต่การลงทุนในแนวทางปฏิบัตินี้จะช่วยเพิ่มประสิทธิภาพและทักษะการเขียนโค้ดในระยะยาว
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีสร้างไบนารีการแบ่งกลุ่มรูปภาพใน C++ ที่ทำงานบนอุปกรณ์ Android โดยตรงโดยใช้รันไทม์ในอุปกรณ์ที่มีประสิทธิภาพสูงของ Google ซึ่งก็คือ LiteRT Codelab นี้มุ่งเน้นการสร้างไบนารี C++ แทนการใช้ Kotlin หรือ Android Studio คุณจะคอมไพล์ข้ามด้วย CMake หรือ Bazel และติดตั้งใช้งานโดยใช้ ADB LiteRT C++ API เดียวกันนี้ใช้ได้ในทุกแพลตฟอร์ม (Android, Linux, ระบบฝังตัว) จึงเป็นรากฐานที่มีประโยชน์สำหรับแอปพลิเคชันที่สำคัญต่อประสิทธิภาพ หุ่นยนต์ และระบบ Edge
คุณจะได้รับคำแนะนำเกี่ยวกับไปป์ไลน์ทั้งหมด
- การตั้งค่าสภาพแวดล้อมของบิลด์ (CMake + Android NDK หรือ Bazel)
- การลิงก์ LiteRT C++ SDK ไม่ว่าจะจากรุ่นที่สร้างไว้ล่วงหน้าหรือจากแหล่งที่มา
- ใช้เชดเดอร์การประมวลผล OpenGL ES สำหรับการประมวลผลรูปภาพก่อนและหลังที่มีการเร่ง GPU
- เรียกใช้
selfie_multiclassโมเดลการแบ่งกลุ่มด้วย LiteRT C++ API - เร่งการอนุมานใน CPU, GPU (OpenCL) และ NPU (Qualcomm / MediaTek)
- การประมวลผลเอาต์พุตโมเดลดิบหลังการประมวลผลเป็นรูปภาพการแบ่งกลุ่มที่ผสมสี
- การติดตั้งใช้งานในอุปกรณ์ Android จริงด้วย ADB และการดึงผลลัพธ์
ในท้ายที่สุด คุณจะได้ผลลัพธ์ที่คล้ายกับรูปภาพต่อไปนี้ ซึ่งเป็นรูปภาพแบบคงที่ที่ประมวลผลผ่านไปป์ไลน์ทั้งหมด โดยมีการซ้อนทับคลาสการแบ่งกลุ่มทั้ง 6 คลาสในสีที่แตกต่างกัน

ข้อกำหนดเบื้องต้น
Codelab นี้ออกแบบมาสำหรับนักพัฒนาซอฟต์แวร์ที่คุ้นเคยกับ C++ และต้องการได้รับประสบการณ์ในการเรียกใช้โมเดลแมชชีนเลิร์นนิงบน Android ที่เลเยอร์ C++ คุณควรคุ้นเคยกับสิ่งต่อไปนี้
- พื้นฐานของ C++ (พอยน์เตอร์ เวกเตอร์ รวมถึง)
- แนวคิดพื้นฐานของ Android/ADB (
adb push,adb shell) - การใช้เทอร์มินัลและสคริปต์เชลล์ใน Linux หรือ macOS
สิ่งที่คุณจะได้เรียนรู้
- วิธีคอมไพล์ข้ามไบนารี C++ สำหรับ Android
arm64-v8aด้วย CMake + NDK หรือ Bazel - วิธีใช้ LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) เพื่อการอนุมานในอุปกรณ์อย่างมีประสิทธิภาพ - Compute Shader ของ OpenGL ES 3.1 เร่งการประมวลผลเบื้องต้นและภายหลังทั้งหมดใน GPU ได้อย่างไร
- วิธีกำหนดค่า LiteRT สำหรับการเร่งความเร็ว CPU, GPU (OpenCL) และ NPU (Qualcomm HTP, MediaTek APU, Google Tensor)
- ความแตกต่างระหว่างการอนุมานแบบซิงโครนัส (
Run) และแบบอะซิงโครนัส (RunAsync) - วิธีติดตั้งใช้งานและเรียกใช้ไบนารี C++ ใน Android โดยใช้ ADB
สิ่งที่คุณต้องมี
- เครื่อง Linux หรือ macOS (ผู้ใช้ Windows ควรใช้ WSL2)
- Android NDK r25c ขึ้นไป (ดาวน์โหลด)
- สำหรับเส้นทาง CMake: CMake ≥ 3.22 (
sudo apt-get install cmake) - สำหรับเส้นทาง Bazel: ติดตั้ง Bazel และที่เก็บตัวอย่าง LiteRT แบบเต็ม
- ADB ใน
PATH(Android Platform Tools) - อุปกรณ์ Android จริง - ทดสอบได้ดีที่สุดใน Galaxy S24/S25 หรือ Pixel
2. การแบ่งกลุ่มรูปภาพ
การแบ่งกลุ่มรูปภาพคืองานด้านคอมพิวเตอร์วิทัศน์ที่กำหนดป้ายกำกับคลาสให้กับทุกพิกเซลในรูปภาพ การแบ่งกลุ่มจะสร้างความเข้าใจที่แม่นยำระดับพิกเซลเกี่ยวกับจุดเริ่มต้นและจุดสิ้นสุดของแต่ละออบเจ็กต์ ซึ่งต่างจากการตรวจหาออบเจ็กต์ที่วาดกรอบล้อมรอบ
Codelab นี้ใช้โมเดล selfie_multiclass_256x256 ซึ่งจัดประเภทแต่ละพิกเซลเป็น 1 ใน 6 คลาสต่อไปนี้
ดัชนีชั้นเรียน | กลุ่ม |
0 | ฉากหลัง |
1 | ทำผม |
2 | ผิวหนัง |
3 | ผิวหน้า |
4 | เสื้อผ้า |
5 | เครื่องประดับ (แว่นตา เครื่องเพชรพลอย ฯลฯ) |
โมเดลจะแสดงผลเทนเซอร์จำนวนลอยตัวที่มีรูปร่าง [1, 256, 256, 6] สำหรับแต่ละพิกเซลขนาด 256x256 จะมีคะแนนความเชื่อมั่น 6 คะแนน ซึ่งเป็นคะแนนสำหรับแต่ละคลาส คลาสที่มีคะแนนสูงสุดจะเป็นผู้ชนะพิกเซลนั้น (argmax)
LiteRT: ประสิทธิภาพที่ Edge
LiteRT คือรันไทม์ประสิทธิภาพสูงรุ่นถัดไปของ Google สำหรับโมเดล TFLite API ของ C++ ช่วยให้คุณเข้าถึงตัวเร่งฮาร์ดแวร์ได้โดยตรงโดยมีค่าใช้จ่ายต่ำและมีอินเทอร์เฟซที่สอดคล้องกันในทั้ง 3 อย่าง
- CPU - เข้ากันได้กับทุกอุปกรณ์ การอนุมานใช้เวลาประมาณ 128 มิลลิวินาทีในอุปกรณ์ระดับกลาง
- GPU (OpenCL) — การอนุมาน ~1 มิลลิวินาที; ~17–43 มิลลิวินาทีแบบครบวงจร ขึ้นอยู่กับกลยุทธ์บัฟเฟอร์
- NPU — เวลาในการประมวลผลตั้งแต่ต้นจนจบประมาณ 9-28 มิลลิวินาทีในอุปกรณ์ Qualcomm Snapdragon, MediaTek Dimensity 9400 และ Google Tensor ขึ้นอยู่กับ AOT การคอมไพล์ JIT
การแยกข้อมูลที่สำคัญคือ CompiledModel: โมเดลได้รับการคอมไพล์ล่วงหน้าและเพิ่มประสิทธิภาพสำหรับฮาร์ดแวร์เป้าหมายในเวลาที่ใช้ในการโหลด ซึ่งจะลดการอนุมานเป็นการเรียก Run() ในบัฟเฟอร์ที่จัดสรรไว้ล่วงหน้า
3. ตั้งค่า
โคลนที่เก็บ
git clone https://github.com/google-ai-edge/litert-samples.git
แหล่งข้อมูลทั้งหมดสำหรับ Codelab นี้อยู่ใน
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
ไดเรกทอรีนี้มีโปรเจ็กต์ย่อย 2 โปรเจ็กต์ ซึ่งแต่ละโปรเจ็กต์เป็นบิลด์ที่สมบูรณ์ของตัวอย่างเดียวกัน
ไดเรกทอรี | ระบบบิลด์ | ทรัพยากร Dependency ของ LiteRT |
| CMake + Android NDK |
|
| Bazel | คอมไพล์ LiteRT จากแหล่งที่มา |
เลือกเส้นทางใดเส้นทางหนึ่งแล้วทำตาม โค้ดในทั้ง 2 ไดเรกทอรีจะเหมือนกันทุกประการ มีเพียงระบบบิลด์และกลยุทธ์การอ้างอิงเท่านั้นที่แตกต่างกัน หากต้องการตั้งค่าให้เร็วที่สุด ให้เลือก use_prebuilt_litert/ หากต้องการแก้ไข LiteRT เองหรือทำงานภายในที่เก็บข้อมูลแบบ Monorepo ของ Bazel ที่มีอยู่ ให้ใช้ build_from_source/
หมายเหตุเกี่ยวกับเส้นทางของไฟล์
เส้นทางของไฟล์ทั้งหมดในบทแนะนำนี้ใช้รูปแบบ Linux/macOS ผู้ใช้ Windows ควรใช้ WSL2
ภาพรวมไดเรกทอรี
ทั้ง 2 โปรเจ็กต์ย่อยใช้เลย์เอาต์แหล่งที่มาเดียวกัน
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
คำอธิบายเพิ่มเติม
use_prebuilt_litert/เพิ่มCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shและthird_party/stb/build_from_source/เพิ่มไฟล์BUILDของ Bazel และใช้deploy_and_run_on_android.shที่ชี้ไปที่bazel-bin/
4. ทำความเข้าใจโครงสร้างโปรเจ็กต์
จุดแรกเข้า 3 จุด ไปป์ไลน์เดียว
main_cpu.cc, main_gpu.cc และ main_npu.cc แต่ละรายการมีฟังก์ชัน main() ที่ขับเคลื่อนไปป์ไลน์การแบ่งกลุ่มทั้งหมด ไปป์ไลน์เหมือนกันทั้ง 3 รุ่น มีเพียงการกำหนดค่าตัวเร่ง LiteRT และกลยุทธ์บัฟเฟอร์เท่านั้นที่แตกต่างกัน
ไฟล์ | Accelerator | กลยุทธ์การบัฟเฟอร์ |
|
| หน่วยความจำ CPU |
|
| หน่วยความจำ CPU ที่มีแบ็กเอนด์ OpenCL |
|
| หน่วยความจำ CPU ที่มี CPU สำรอง |
ทั้ง 3 รายการใช้ยูทิลิตี ImageProcessor (OpenGL ES Compute Shader สำหรับการประมวลผลล่วงหน้าและหลังการประมวลผล) และ ImageUtils (STB Image I/O) เดียวกัน
ไปป์ไลน์ทั้งหมด
ทุกจุดแรกเข้ามีโครงสร้าง 5 เฟสเดียวกัน ดังนี้
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- โหลด -
ImageUtils::LoadImage()ถอดรหัส JPEG ลงในหน่วยความจำ CPU โดยใช้ไลบรารีรูปภาพ STB - อัปโหลด -
processor.CreateOpenGLTexture()อัปโหลดพิกเซลดิบไปยังพื้นผิว GPU (OpenGL RGBA8) - ประมวลผลล่วงหน้า —
processor.PreprocessInputForSegmentation()เรียกใช้ GLSL Compute Shader ที่ปรับขนาดเท็กซ์เจอร์เป็น 256x256 และปรับค่าพิกเซลให้เป็นมาตรฐานจาก[0, 1]เป็น[-1, 1]ผลลัพธ์จะอยู่ใน SSBO ของ GPU - อนุมาน - ข้อมูล SSBO จะเขียนลงใน LiteRT
TensorBufferและcompiled_model.Run()(หรือRunAsync()) จะเรียกใช้โมเดล - การประมวลผลภายหลัง - เอาต์พุตแบบลอยตัว 6 แชแนลของโมเดลจะถูกแยกออกเป็น SSBO ของมาสก์แบบแชแนลเดียว 6 รายการ จากนั้นจะมีการผสมสีกลับไปยังรูปภาพต้นฉบับ
- บันทึก —
ImageUtils::SaveImage()เขียนรูปภาพ RGBA สุดท้ายเป็น PNG
5. Core LiteRT C++ APIs
ก่อนที่จะสร้าง ให้ทำความคุ้นเคยกับประเภท C++ หลัก 3 ประเภทของ LiteRT ที่ใช้ในทุกจุดแรกเข้า ทั้งหมดอยู่ในเนมสเปซ litert::
litert::Environment
Environment คือบริบทรูทสำหรับการดำเนินการ LiteRT ทั้งหมด สร้างครั้งเดียวแล้วส่งไปยัง CompiledModel::Create สำหรับการใช้งาน NPU ให้กำหนดค่าด้วยไดเรกทอรีไลบรารีปลั๊กอินของผู้ให้บริการ
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel จะโหลดและคอมไพล์ล่วงหน้าโมเดล TFLite สำหรับฮาร์ดแวร์ที่ขอในเวลาที่สร้าง จากนั้นการอนุมานจะลดลงเป็นการเติมบัฟเฟอร์และเรียกใช้ Run()
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
บัฟเฟอร์เทนเซอร์จะเก็บข้อมูลอินพุต/เอาต์พุต สร้างจาก CompiledModel เสมอเพื่อให้มีขนาดที่ถูกต้องและจัดแนวให้ตรงกับฮาร์ดแวร์เป้าหมาย
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
มาโครการจัดการข้อผิดพลาด
มาโคร | พฤติกรรม |
| กำหนดหรือเรียกใช้ |
| เรียกใช้ |
| กำหนดหรือส่งต่อข้อผิดพลาดไปยังผู้เรียกใช้ |
6. สร้าง - ตัวเลือก ก: C++ SDK ของ LiteRT ที่สร้างไว้ล่วงหน้า (CMake)
นี่คือเส้นทางที่แนะนำหากคุณไม่จำเป็นต้องแก้ไข LiteRT เอง สคริปต์บิลด์จะจัดการการดาวน์โหลดส่วนหัวของ SDK, การคัดลอก .so, การดึงข้อมูล STB และการเรียกใช้ CMake + NDK ในคำสั่งเดียว
ขั้นตอนที่ 1 - รับ libLiteRt.so จาก Maven
LiteRT จัดส่งรันไทม์เป็นไลบรารีที่ใช้ร่วมกันภายใน AAR ของ Android ใน Google Maven ดาวน์โหลดและแตกไฟล์ arm64-v8a .so โดยทำดังนี้
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
หากต้องการรองรับ GPU ให้แตกตัวเร่ง OpenCL/GL ด้วย
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

ขั้นตอนที่ 2 - เรียกใช้ build_prebuilt.sh
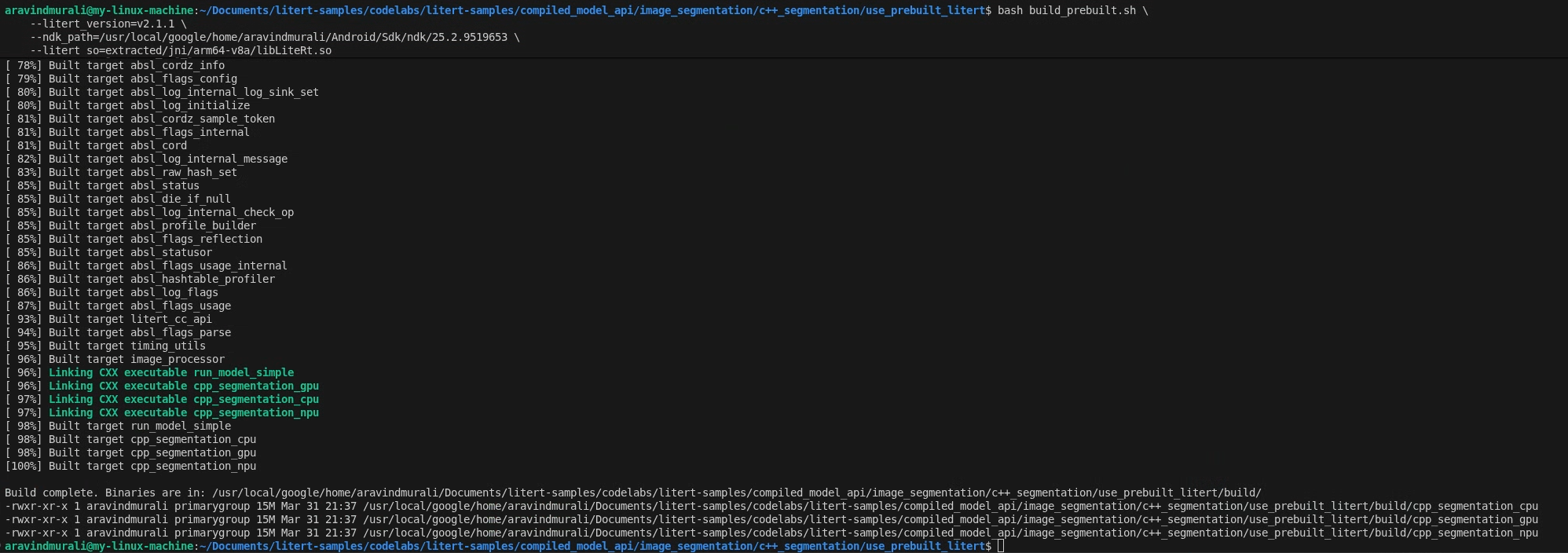
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
สคริปต์จะทำสิ่งต่อไปนี้
- ดาวน์โหลด
litert_cc_sdk.zip(ส่วนหัวของ SDK + ไฟล์ cmake) จากรุ่น LiteRT ใน GitHub ซึ่งจะข้ามในครั้งต่อๆ ไปหากมีอยู่แล้ว - คัดลอก
libLiteRt.soไปยังlitert_cc_sdk/ - ดาวน์โหลดส่วนหัวของรูปภาพ STB ลงใน
third_party/stb/— ข้ามหากมีอยู่ - กำหนดค่าและสร้างด้วย CMake โดยใช้ชุดเครื่องมือ Android NDK สำหรับ
arm64-v8aที่android-26
เมื่อสำเร็จแล้ว คุณจะเห็นไบนารี 3 รายการใน build/ ดังนี้
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
สิ่งที่ CMakeLists.txt ทำ
เปิด CMakeLists.txt โดยต้องใช้ C++20 ดึง SDK ของ LiteRT ผ่าน add_subdirectory ลิงก์ OpenGL ES 3 (GLESv3) และ EGL จากนั้นใช้มาโครตัวช่วยเพื่อสร้างไบนารีแต่ละรายการจากแหล่งที่มา main_*.cc
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. สร้าง - ตัวเลือก ข: สร้างด้วย Bazel (จากแหล่งที่มา)
เลือกเส้นทางนี้หากต้องการใช้ Bazel เป็นระบบบิลด์ ซึ่งจะคอมไพล์รันไทม์ LiteRT จากแหล่งที่มา หรือหากต้องการทำงานภายในพื้นที่ทำงาน Bazel ที่มีอยู่
ข้อกำหนดเบื้องต้น
นอกจาก NDK และ ADB ที่ระบุไว้ในส่วน "ก่อนเริ่มต้น" แล้ว คุณจะต้องมีสิ่งต่อไปนี้
- Bazel ติดตั้งและอยู่ใน
PATH - การโคลนที่เก็บแหล่งที่มาของตัวอย่าง LiteRT แบบเต็ม
ขั้นตอนที่ 1 — กำหนดค่าพื้นที่ทำงานตัวอย่าง LiteRT
คำสั่งทั้งหมดจะทำงานจากรูทของที่เก็บตัวอย่าง LiteRT
cd /path/to/litert-samples
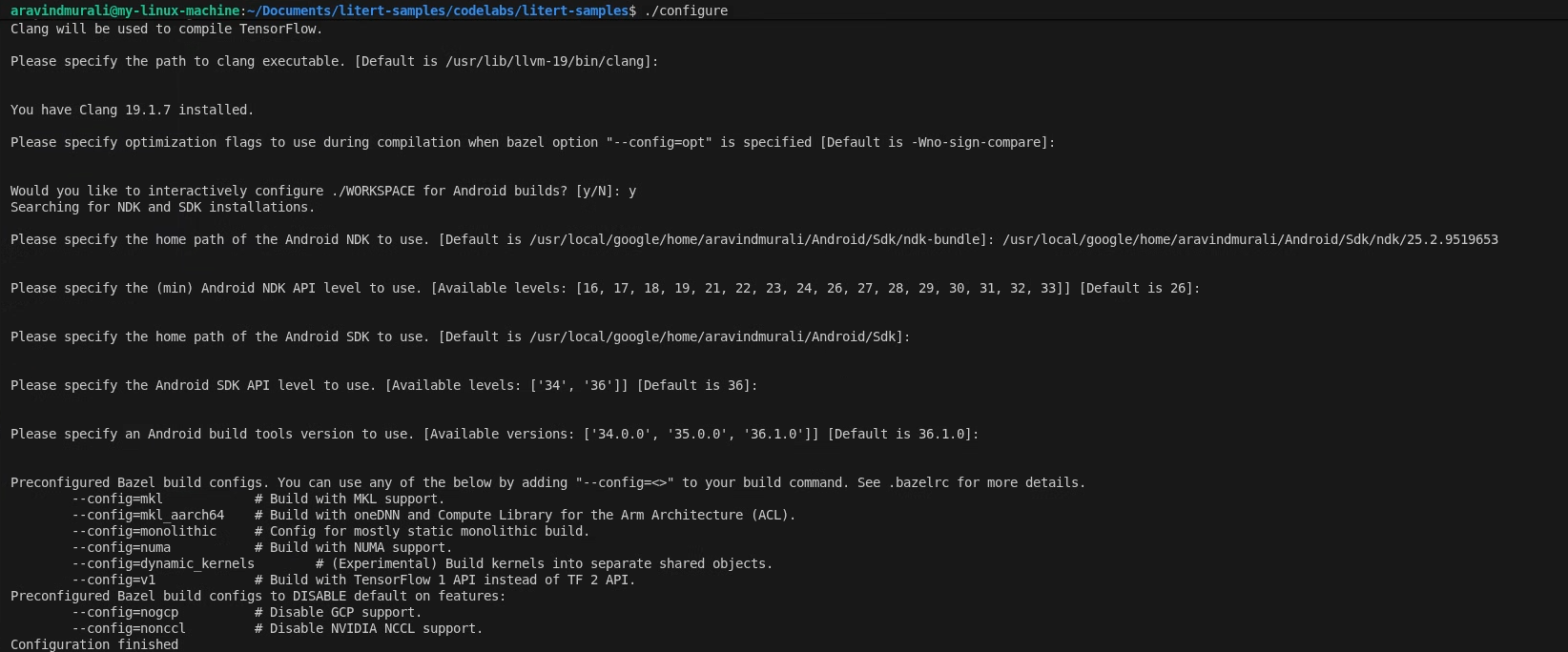
./configure
เมื่อได้รับข้อความแจ้ง ให้ทำดังนี้
- ยอมรับค่าเริ่มต้นสำหรับเส้นทาง Python และ Python lib
- ตอบ N เพื่อรองรับ ROCm และ CUDA
- เลือก clang (ทดสอบกับ 18.1.3) เป็นคอมไพเลอร์
- ยอมรับค่าสถานะการเพิ่มประสิทธิภาพเริ่มต้น
- ตอบ Y เพื่อกำหนดค่า WORKSPACE สำหรับบิลด์ Android
- ตั้งค่าระดับ Android NDK ขั้นต่ำเป็นอย่างน้อย 26
- ระบุเส้นทางไปยัง Android SDK
- ตั้งค่าระดับ API ของ Android SDK เป็นค่าเริ่มต้น (36) และเครื่องมือบิลด์เป็น 36.0.0
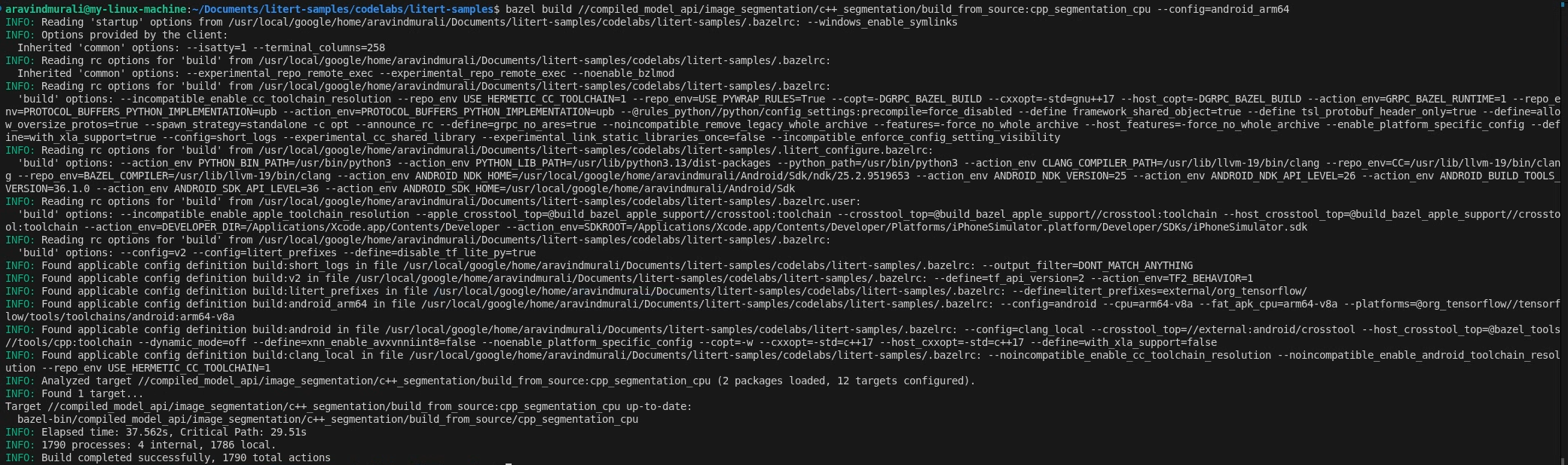
ขั้นตอนที่ 2 - สร้างเป้าหมาย CPU และ GPU
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
ขั้นตอนที่ 3 — สร้างเป้าหมาย NPU
Qualcomm HTP
- ดาวน์โหลด QAIRT SDK v2.41 ขึ้นไป แล้วแตกไฟล์
- ตรวจสอบว่าเนื้อหา SDK ที่แยกออกมาอยู่ภายในไดเรกทอรีย่อยชื่อ
latest//path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - สร้างโดยส่งเส้นทางหลักที่ลงท้ายด้วย
/bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
ต้องใช้--nocheck_visibilityเนื่องจากเป้าหมาย LiteRT บางรายการต้นทางมีค่าเริ่มต้นการมองเห็นที่จำกัด
APU ของ MediaTek
ไม่จำเป็นต้องใช้ SDK เพิ่มเติม รันไทม์ NeuroPilot เป็นไลบรารีระบบในอุปกรณ์ Dimensity 9400
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
ไฟล์ BUILD
เปิด build_from_source/BUILD โดยจะกำหนดcc_binaryเป้าหมาย 4 รายการ ซึ่งเป็นเป้าหมายสำหรับตัวเร่งความเร็ว 1 รายการและเป้าหมาย NPU ของ MediaTek โดยเฉพาะ แต่ละรายการจะขึ้นอยู่กับเป้าหมายไลบรารี image_processor, image_utils และ timing_utils ที่ใช้ร่วมกัน
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
เป้าหมาย GPU จะเพิ่ม libLiteRtClGlAccelerator.so เป็นการขึ้นต่อกันของข้อมูลเพื่อให้ Bazel รวมไว้ในไฟล์ที่เรียกใช้ เป้าหมาย NPU จะเพิ่มไฟล์ปลั๊กอินการจัดส่งของผู้ให้บริการและคอมไพเลอร์ .so เป็นการอ้างอิงข้อมูล
8. การประมวลผลล่วงหน้าที่เร่งด้วย GPU ด้วย Compute Shader
โดยทั้ง 3 จุดแรกเข้าจะใช้ไปป์ไลน์เชดเดอร์การคำนวณ OpenGL ES เดียวกันสำหรับการประมวลผลล่วงหน้า การทำความเข้าใจเรื่องนี้เป็นกุญแจสำคัญในการทำความเข้าใจว่าเหตุใดเส้นทาง GPU จึงเร็วกว่าเส้นทาง CPU มาก
ตั้งค่าบริบท EGL แบบไม่มีส่วนหัว
ImageProcessor::InitializeGL() จะสร้าง headless EGL context ซึ่งเป็น OpenGL context ที่ไม่มีหน้าต่างหรือจอแสดงผลแนบอยู่ นี่เป็นแนวทางปฏิบัติมาตรฐานสำหรับการประมวลผล GPU นอกหน้าจอบน Android จากนั้นจะคอมไพล์โปรแกรม Compute Shader GLSL 5 รายการจากดิสก์
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
อัปโหลดรูปภาพอินพุตไปยัง GPU
ImageUtils::LoadImage() (ผ่านไลบรารี STB) จะถอดรหัส JPEG เป็นหน่วยความจำ CPU จากนั้นอัปโหลดไปยังเท็กซ์เจอร์ GPU
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
จากจุดนี้ รูปภาพต้นฉบับจะอยู่ในหน่วยความจำของ GPU เป็นพื้นผิว OpenGL
Compute Shader ก่อนการประมวลผล
shaders/preprocess_compute.glsl จะส่งกลุ่มเธรด 8×8 ไปยังตารางเอาต์พุต 256×256 แต่ละเทรดจะจัดการพิกเซลเอาต์พุต 1 พิกเซล โดยจะสุ่มตัวอย่างพื้นผิวอินพุตโดยใช้การกรองแบบไบลิเนียร์ (ปรับขนาดฮาร์ดแวร์ฟรี) แปลงค่า [0, 1] RGB เป็น [-1, 1] และเขียนไปยัง SSBO เอาต์พุต
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
สำหรับเส้นทางมาตรฐาน (ไม่ใช่การคัดลอกแบบไม่ใช้หน่วยความจำ) ระบบจะอ่าน SSBO นี้กลับไปยัง CPU แล้วเขียนลงในเทนเซอร์ LiteRT
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. การอนุมาน CPU
เปิด main_cpu.cc การตั้งค่า LiteRT มี 3 บรรทัดดังนี้
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
หลังจากการประมวลผลล่วงหน้า การอนุมานจะเป็นการเรียกแบบซิงโครนัสครั้งเดียว
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() จะบล็อกจนกว่าการอนุมานจะเสร็จสมบูรณ์ selfie_multiclass_256x256.tflite โมเดลจุดลอยตัวทำงานบนแกน ARM Cortex และโดยปกติจะใช้เวลาประมาณ 116-128 มิลลิวินาทีในอุปกรณ์ระดับกลาง
การใช้งานไบนารี:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. การอนุมาน GPU (OpenCL)
เปิด main_gpu.cc เส้นทาง GPU จะมีแนวคิด 2 อย่างที่ไม่มีในเส้นทาง CPU ได้แก่ litert::Options สำหรับกำหนดค่าตัวเร่ง GPU (ด้วยแบ็กเอนด์ OpenCL) และการดำเนินการแบบอะซิงโครนัส
กำหนดค่าตัวเลือก GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
การอนุมานแบบอะซิงโครนัส
เส้นทาง GPU ใช้ RunAsync() แทน Run() ซึ่งจะส่งงานไปยังคิวคำสั่งของ GPU และกลับมาทันที จากนั้นให้ซิงค์ก่อนอ่านผลลัพธ์
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
การออกแบบที่ไม่บล็อกนี้ช่วยให้คุณซ้อนทับงานของ CPU กับการดำเนินการของ GPU ในไปป์ไลน์แบบเรียลไทม์ได้
การใช้งานไบนารี:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Postprocess - Deinterleave and Blend
หลังจาก Run() หรือ RunAsync() เสร็จสมบูรณ์แล้ว output_buffers[0] จะเก็บอาร์เรย์ลอยแบบแบนที่มีรูปร่าง [256 × 256 × 6] ในลำดับที่สลับกัน คะแนน 6 คลาสสำหรับพิกเซล (row, col) อยู่ที่ดัชนี (row * 256 + col) * 6 ถึง (row * 256 + col) * 6 + 5
แยกเป็น SSBO มาสก์ 6 รายการ
ตัวช่วย CPU จะแยกอาร์เรย์ที่สลับกันออกเป็นอาร์เรย์ลอยตัวแบบช่องทางเดียว 6 รายการ แล้วอัปโหลดแต่ละรายการไปยัง SSBO ของ GPU ของตัวเอง
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
มาสก์การผสมสีลงในรูปภาพต้นฉบับ
processor.ApplyColoredMasks() เรียกใช้ Shader mask_blend_compute.glsl สำหรับพิกเซลเอาต์พุตแต่ละพิกเซล ระบบจะค้นหาคลาสที่มีคะแนนสูงสุด (argmax ใน SSBO ของมาสก์ทั้ง 6) และผสมสีที่เกี่ยวข้องกับพิกเซลรูปภาพต้นฉบับ โดยมีการกำหนดสีทั้ง 6 สีในแต่ละจุดแรกเข้าดังนี้
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
ค่าอัลฟ่าของ 0.1f จะทำให้สีอ่อนๆ มองเห็นได้ชัดเจนเพื่อให้รูปภาพต้นฉบับยังคงมองเห็นได้
บันทึกเอาต์พุต
ระบบจะอ่าน SSBO แบบลอย RGBA ที่ผสมแล้วกลับมา หนีบเป็น [0, 1] แปลงเป็น unsigned char และบันทึกเป็น PNG
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. ติดตั้งใช้งานและเรียกใช้บนอุปกรณ์
เชื่อมต่ออุปกรณ์ Android โดยใช้ USB และยืนยันการเชื่อมต่อ ADB โดยทำดังนี้
adb devices

ใช้ deploy_and_run_on_android.sh
แต่ละตัวแปรจะมีสคริปต์การติดตั้งใช้งานของตัวเอง ตัวแปร CMake จะชี้ไปที่ไดเรกทอรี build/ ส่วนตัวแปร Bazel จะชี้ไปที่ bazel-bin/ ทั้ง 2 สคริปต์
- สร้าง
/data/local/tmp/cpp_segmentation_android/ในอุปกรณ์ - ส่งไบนารี, Shader GLSL, โมเดล, รูปภาพทดสอบ และไฟล์รันไทม์
.so - เรียกใช้การอนุมานโดยใช้
adb shell - ดึง
output_segmented.pngกลับไปที่เครื่อง
ตัวแปร CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
ตัวแปร Bazel (build_from_source/)
เรียกใช้คำสั่งต่อไปนี้จากรูทของที่เก็บตัวอย่าง LiteRT
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
แฟล็ก --phone จะควบคุมว่าควรใช้ไลบรารีโมเดลและไลบรารีของผู้ให้บริการใดที่เฉพาะเจาะจงสำหรับอุปกรณ์ ค่าที่รองรับ: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) และ pixel11 (Tensor G6)
เวลาในการอนุมาน
หลังจากอนุมานแล้ว PrintTiming() จะพิมพ์รายละเอียดการวิเคราะห์โปรไฟล์แบบเต็ม
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
ประสิทธิภาพอ้างอิงใน Samsung S25 Ultra (Snapdragon 8 Elite):
Accelerator | ประเภทการดำเนินการ | การอนุมาน | E2E |
CPU | ซิงค์ | ~116–128 มิลลิวินาที | ~157 มิลลิวินาที |
GPU (OpenCL) | Async | ~0.95 มิลลิวินาที | ~35–43 มิลลิวินาที |
13. ขั้นสูง (ไม่บังคับ): การอนุมาน NPU
LiteRT รองรับการเร่งความเร็ว NPU โดยใช้ไลบรารีปลั๊กอินเฉพาะของผู้ให้บริการเพื่อให้ได้ประสิทธิภาพสูงสุด เส้นทาง NPU สามารถลดเวลาในการตอบสนองตั้งแต่ต้นจนจบได้ต่ำสุดที่ 9 มิลลิวินาที
อุปกรณ์และโหมดที่รองรับ
ชิป | ตัวอย่างอุปกรณ์ | โหมด | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 มิลลิวินาที |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 มิลลิวินาที |
Qualcomm (ไม่จำกัด) | — | JIT | ~28 มิลลิวินาที |
MediaTek Dimensity 9400 | — | JIT | ~9 มิลลิวินาที |
Google Tensor G3-G6 | Pixel 8-11 | AOT/JIT | แตกต่างกันไป |
AOT (Ahead-of-Time) ใช้โมเดลที่คอมไพล์ล่วงหน้าเฉพาะอุปกรณ์ (เช่น selfie_multiclass_256x256_SM8650.tflite) ซึ่งเป็นตัวเลือกที่เร็วที่สุดแต่จะขึ้นอยู่กับชิป
JIT (Just-in-Time) ใช้ selfie_multiclass_256x256.tflite มาตรฐานและคอมไพล์ไปยัง NPU ในรันไทม์ ซึ่งจะทำงานช้ากว่าในการเรียกใช้ครั้งแรก แต่ไม่ขึ้นอยู่กับชิป
ข้อกำหนดเบื้องต้นเพิ่มเติม
Qualcomm HTP:
- QAIRT SDK v2.41 ขึ้นไป (มีไฟล์
libQnnHtp.so, สตับ หรือสเกล.so) libLiteRtDispatch_Qualcomm.soจากการเผยแพร่ไลบรารีรันไทม์ของ NPU สำหรับ LiteRT ใน GitHub
APU ของ MediaTek:
libLiteRtDispatch_MediaTek.soจากการเปิดตัวไลบรารีรันไทม์ของ NPU ใน LiteRT- รันไทม์ NeuroPilot (เป็นไลบรารีระบบในอุปกรณ์ Dimensity 9400 อยู่แล้ว จึงไม่ต้องพุช)
Google Tensor:
libLiteRtDispatch_GoogleTensor.soจากการเปิดตัวไลบรารีรันไทม์ของ NPU ใน LiteRT
สภาพแวดล้อมและตัวเลือก NPU
main_npu.cc จะชี้ Environment ไปยังไดเรกทอรีไลบรารีการจัดส่งของผู้ให้บริการในอุปกรณ์ จากนั้นตั้งค่าตัวเลือกประสิทธิภาพเฉพาะของผู้ให้บริการ
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
สำหรับ MediaTek ให้แทนที่บล็อก GetQualcommOptions() ดังนี้
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
ติดตั้งใช้งานสำหรับ NPU
ตัวแปร CMake - Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
ตัวแปร CMake - MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
รุ่น Bazel - Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
รุ่น Bazel - MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
ตัวแปร Bazel - Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
สำหรับตัวแปร Bazel ระบบจะเลือกไลบรารี QAIRT SDK โดยอัตโนมัติจากbazel-binทรี runfiles เมื่อตั้งค่า LITERT_QAIRT_SDK ในเวลาบิลด์ ตัวแปร CMake ต้องมีแฟล็ก --host_npu_lib เพื่อชี้ไปยัง QAIRT SDK ที่แยกออกมา
14. ยินดีด้วย
คุณสร้างและเรียกใช้ไปป์ไลน์การแบ่งกลุ่มรูปภาพ C++ บน Android โดยใช้ LiteRT เรียบร้อยแล้ว คุณได้เรียนรู้วิธีต่อไปนี้
- คอมไพล์ข้ามไบนารี C++ สำหรับ Android
arm64-v8aด้วย CMake + NDK หรือ Bazel - ใช้ LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) เพื่อการอนุมานในอุปกรณ์อย่างมีประสิทธิภาพ - ประมวลผลข้อมูลรูปภาพล่วงหน้าใน GPU ด้วยเชดเดอร์การประมวลผล OpenGL ES 3.1
- เรียกใช้การอนุมาน CPU แบบซิงโครนัส และการอนุมาน GPU (OpenCL) แบบอะซิงโครนัส
- กำหนดค่าการเร่ง NPU สำหรับอุปกรณ์ Qualcomm, MediaTek และ Google Tensor
- ติดตั้งใช้งานและเรียกใช้ไบนารี C++ ใน Android โดยใช้ ADB
ขั้นตอนถัดไป
- สลับไปใช้โมเดล TFLite อื่น (เช่น การประมาณความลึกหรือการตรวจหาท่าทาง)
- ผสานรวมไปป์ไลน์ C++ เข้ากับแอป Android NDK โดยใช้ JNI
- สร้างโปรไฟล์การใช้งานหน่วยความจำด้วย Android GPU Inspector ควบคู่ไปกับเอาต์พุตการจับเวลา
- สำรวจการหาปริมาณโมเดลเพื่อลดเวลาในการตอบสนองของการอนุมาน NPU เพิ่มเติม