
1. Прежде чем начать
Написание кода на клавиатуре — отличный способ развить мышечную память и углубить понимание материала. Хотя копирование и вставка могут сэкономить время, вложение средств в эту практику в долгосрочной перспективе приведет к большей эффективности и более сильным навыкам программирования.
В этом практическом занятии вы научитесь создавать исполняемый файл сегментации изображений на C++, который будет работать непосредственно на устройстве Android, используя высокопроизводительную среду выполнения Google LiteRT . Вместо Kotlin или Android Studio, это практическое занятие сосредоточено на создании исполняемого файла на C++. Вы будете кросс-компилировать его с помощью CMake или Bazel и развертывать с помощью ADB. Тот же API LiteRT на C++ работает на любой платформе (Android, Linux, встроенные системы), что делает его полезной основой для критически важных с точки зрения производительности приложений, робототехники и периферийных систем.
Вы пройдете весь процесс от начала до конца:
- Настройка среды сборки (CMake + Android NDK или Bazel).
- Подключение SDK LiteRT C++ — либо из предварительно собранного релиза, либо из исходного кода.
- Использование вычислительных шейдеров OpenGL ES для ускоренной обработки изображений на графическом процессоре (GPU) на этапах предварительной и постобработки.
- Запуск модели сегментации
selfie_multiclassс использованием API LiteRT C++. - Ускорение вывода данных на ЦП , ГП (OpenCL) и НПУ (Qualcomm/MediaTek).
- Постобработка исходных данных модели для получения сегментированного изображения с цветовым смешиванием.
- Развертывание на физическом устройстве Android с использованием ADB и получение результата.
В итоге вы получите нечто похожее на следующее изображение — статическое изображение, обработанное с помощью полного конвейера, на котором каждый из 6 классов сегментации выделен отдельным цветом:

Предварительные требования
Этот практический курс предназначен для разработчиков, хорошо знакомых с C++, которые хотят получить опыт запуска моделей машинного обучения на Android на уровне C++. Вам необходимо знать:
- Основы C++ (указатели, векторы, включения).
- Основные понятия Android/ADB (
adb push,adb shell). - Использование терминала и скриптов оболочки в Linux или macOS.
Что вы узнаете
- Как выполнить кросс-компиляцию исполняемого файла C++ для Android
arm64-v8aс помощью CMake + NDK или Bazel. - Как использовать API LiteRT C++ (
Environment,CompiledModel,TensorBuffer) для эффективного выполнения вычислений на устройстве. - Как вычислительные шейдеры OpenGL ES 3.1 ускоряют предварительную и постобработку исключительно на графическом процессоре.
- Как настроить LiteRT для ускорения работы на ЦП, ГП (OpenCL) и НПУ (Qualcomm HTP, MediaTek APU, Google Tensor).
- Разница между синхронным (
Run) и асинхронным (RunAsync) выводом. - Как развернуть и запустить исполняемый файл C++ на Android с помощью ADB.
Что вам понадобится
- Для работы потребуется компьютер под управлением Linux или macOS (пользователям Windows следует использовать WSL2).
- Android NDK r25c или более поздняя версия ( скачать ).
- Для пути к CMake : CMake ≥ 3.22 (
sudo apt-get install cmake). - Для пути к Bazel : Bazel установлен, а также полный репозиторий примеров LiteRT.
- Добавьте ADB в переменную
PATH(Android Platform Tools). - Физическое устройство Android — наилучшие результаты тестирования были получены на Galaxy S24/S25 или Pixel.
2. Сегментация изображений
Сегментация изображений — это задача компьютерного зрения, которая присваивает метку класса каждому пикселю изображения. В отличие от обнаружения объектов, которое рисует ограничивающую рамку, сегментация обеспечивает точное, пиксельно-точное понимание того, где начинается и заканчивается каждый объект.
В этом практическом задании используется модель selfie_multiclass_256x256 , которая классифицирует каждый пиксель по одному из 6 классов :
Классовый указатель | Сегмент |
0 | Фон |
1 | Волосы |
2 | Кожа тела |
3 | Кожа лица |
4 | Одежда |
5 | Аксессуары (очки, украшения и т. д.) |
Модель выдает тензор с плавающей запятой формы [1, 256, 256, 6] . Для каждого пикселя размером 256×256 имеется 6 оценок достоверности — по одной для каждого класса. Класс с наивысшей оценкой получает этот пиксель (argmax).
LiteRT: Производительность на границе возможностей
LiteRT — это высокопроизводительная среда выполнения нового поколения от Google для моделей TFLite. Ее API на C++ обеспечивает прямой доступ к аппаратным ускорителям с минимальными накладными расходами и имеет единый интерфейс для всех трех типов устройств:
- CPU — универсально совместим; время выполнения операции вывода составляет около 128 мс на устройстве среднего уровня.
- GPU (OpenCL) — примерно 1 мс на вывод; 17–43 мс в сквозном режиме в зависимости от стратегии буферизации.
- NPU — ~9–28 мс в сквозном режиме на устройствах с процессорами Qualcomm Snapdragon, MediaTek Dimensity 9400 и Google Tensor, в зависимости от компиляции AOT или JIT.
Ключевой абстракцией является CompiledModel : модель предварительно компилируется и оптимизируется для целевого оборудования во время загрузки, сводя вывод к вызову Run() на предварительно выделенных буферах.
3. Подготовка к работе
Клонируйте репозиторий
git clone https://github.com/google-ai-edge/litert-samples.git
Все материалы для этой практической работы находятся в:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
В этой директории находятся два подпроекта, каждый из которых представляет собой полную сборку одного и того же примера:
Каталог | Система сборки | зависимость LiteRT |
| CMake + Android NDK | Готовый файл |
| Базель | Компилирует LiteRT из исходного кода. |
Выберите один путь и следуйте ему. Код в обеих директориях идентичен — различаются только система сборки и стратегия зависимостей. Если вам нужна самая быстрая настройка, выберите use_prebuilt_litert/ . Если вам нужно изменить сам LiteRT или работать в рамках существующего монорепозитория Bazel, используйте build_from_source/ .
Примечание о путях к файлам.
Все пути к файлам в этом руководстве указаны в формате Linux/macOS. Пользователям Windows следует использовать WSL2.
Обзор каталога
Оба подпроекта имеют одинаковую структуру исходного кода:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Кроме того:
-
use_prebuilt_litert/добавляетCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shиthird_party/stb/. -
build_from_source/добавляет файлBUILDBazel и использует скриптdeploy_and_run_on_android.shуказывающий наbazel-bin/.
4. Разберитесь в структуре проекта.
Три точки входа, один трубопровод
Файлы main_cpu.cc , main_gpu.cc и main_npu.cc содержат функцию main() , которая управляет всем конвейером сегментации. Конвейер идентичен во всех трех файлах; различаются только конфигурация ускорителя LiteRT и стратегия буферизации:
Файл | Акселератор | Стратегия буферизации |
| | память ЦП |
| | Память ЦП с бэкендом OpenCL |
| | Память ЦП с резервным использованием ЦП |
Все три используют одни и те же утилиты ImageProcessor (вычислительные шейдеры OpenGL ES для предварительной и постобработки) и ImageUtils (ввод-вывод изображений STB).
Полный конвейер
Каждая точка входа имеет одинаковую пятиэтапную структуру:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Загрузка —
ImageUtils::LoadImage()декодирует JPEG-изображение в память ЦП, используя библиотеку изображений STB. - Функция ` upload` —
processor.CreateOpenGLTexture()загружает исходные пиксели в текстуру графического процессора (OpenGL RGBA8). - Предварительная обработка —
processor.PreprocessInputForSegmentation()запускает вычислительный шейдер GLSL, который изменяет размер текстуры до 256×256 и нормализует значения пикселей от[0, 1]до[-1, 1]. Результат попадает в GPU SSBO. - Infer — Данные SSBO записываются в
TensorBufferLiteRT, аcompiled_model.Run()(илиRunAsync()) выполняет модель. - Постобработка — 6-канальный выходной сигнал модели в формате с плавающей запятой разделяется на 6 одноканальных масок SSBO, которые затем смешиваются по цвету с исходным изображением.
- Сохранение —
ImageUtils::SaveImage()записывает итоговое изображение в формате RGBA как PNG.
5. Основные API LiteRT на C++
Перед сборкой ознакомьтесь с тремя ключевыми типами LiteRT C++, используемыми во всех точках входа. Все они находятся в пространстве имен litert:: .
litert::Environment
Environment — это корневой контекст для всех операций LiteRT. Создайте его один раз и передайте в CompiledModel::Create . Для использования NPU настройте его, указав каталог библиотеки плагинов поставщика.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
Функция CompiledModel загружает и предварительно компилирует вашу модель TFLite для запрошенного оборудования на этапе создания. Затем вывод сводится к заполнению буферов и вызову функции Run() .
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Тензорные буферы хранят входные/выходные данные. Всегда создавайте их из CompiledModel , чтобы они имели правильный размер и выравнивание для целевого оборудования.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Макросы обработки ошибок
Макро | Поведение |
| При сбое присваивает значение или вызывает функцию |
| Вызывает метод |
| Присваивает или передает ошибку вызывающей стороне. |
6. Сборка — Вариант A: Предварительно собранный LiteRT C++ SDK (CMake)
Это рекомендуемый путь, если вам не нужно модифицировать сам LiteRT. Скрипт сборки обрабатывает загрузку заголовков SDK, копирование вашего .so , получение STB и запуск CMake + NDK одной командой.
Шаг 1 — Получите libLiteRt.so из Maven
LiteRT поставляется со своей средой выполнения в виде разделяемой библиотеки внутри Android AAR-архива .so созданного с помощью Google Maven. Скачайте его и распакуйте файл arm64-v8a :
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Для поддержки графического процессора также необходимо извлечь ускоритель OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

Шаг 2 — Запустите build_prebuilt.sh
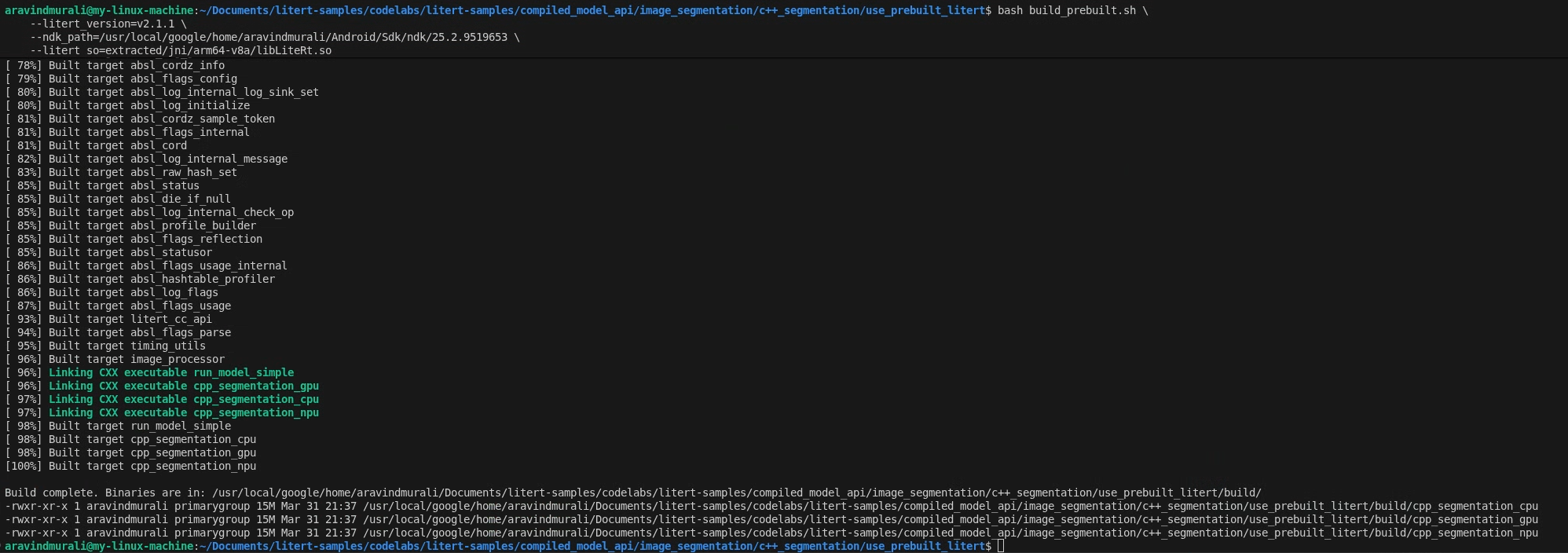
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Сценарий будет:
- Загрузите
litert_cc_sdk.zip(заголовочные файлы SDK + файлы cmake) из репозитория LiteRT на GitHub — при последующих запусках этот шаг будет пропущен, если файл уже присутствует. - Скопируйте
libLiteRt.soвlitert_cc_sdk/. - Загрузка заголовков образа STB в
third_party/stb/— пропускается, если присутствует. - Настройка и сборка с помощью CMake с использованием набора инструментов Android NDK для
arm64-v8aвandroid-26.
В случае успеха вы увидите три исполняемых файла в build/ :
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Что делает CMakeLists.txt
Откройте CMakeLists.txt . Он требует C++20, подключает SDK LiteRT с помощью add_subdirectory , связывает OpenGL ES 3 ( GLESv3 ) и EGL, а затем использует вспомогательный макрос для создания каждого бинарного файла из исходного кода main_*.cc :
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Сборка — Вариант B: Сборка с помощью Bazel (из исходного кода)
Выберите этот путь, если вы предпочитаете использовать Bazel в качестве системы сборки, которая компилирует среду выполнения LiteRT из исходного кода, или если вам необходимо работать в существующей рабочей области Bazel.
Предварительные требования
Помимо NDK и ADB, перечисленных в разделе «Перед началом работы», вам потребуется:
- Bazel установлен и добавлен в переменную
PATH. - Полная копия репозитория исходного кода примеров LiteRT.
Шаг 1 — Настройка рабочей области примеров LiteRT
Все команды запускаются из корневого каталога репозитория примеров LiteRT.
cd /path/to/litert-samples
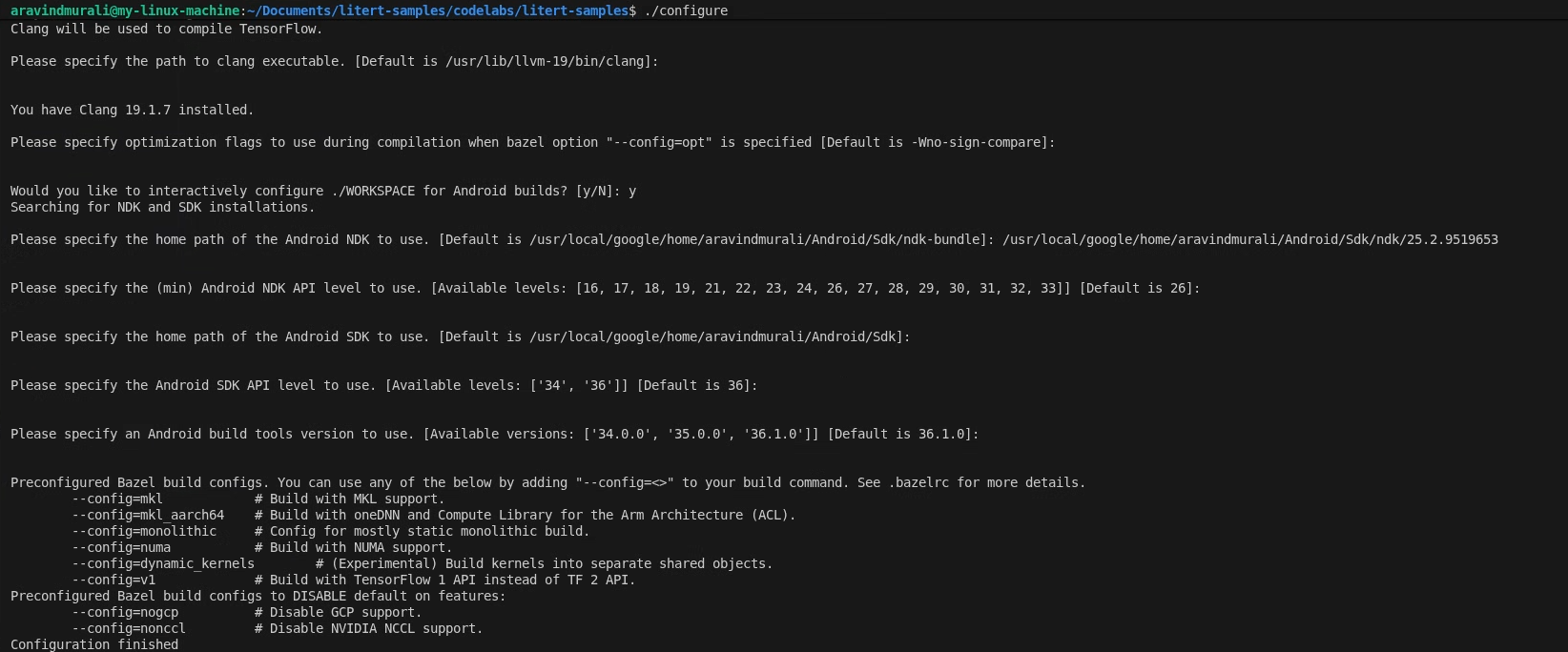
./configure
При появлении запроса:
- Принять значения по умолчанию для Python и пути к библиотекам Python.
- Ответ N на вопрос о поддержке ROCm и CUDA.
- Выберите clang (протестировано с версией 18.1.3) в качестве компилятора.
- Принять флаги оптимизации по умолчанию.
- Ответьте Y , чтобы настроить рабочее пространство для сборок Android.
- Установите минимальный уровень Android NDK не ниже 26 .
- Укажите путь к вашему Android SDK.
- Установите уровень API Android SDK на значение по умолчанию ( 36 ) и установите уровень инструментов сборки на 36.0.0 .
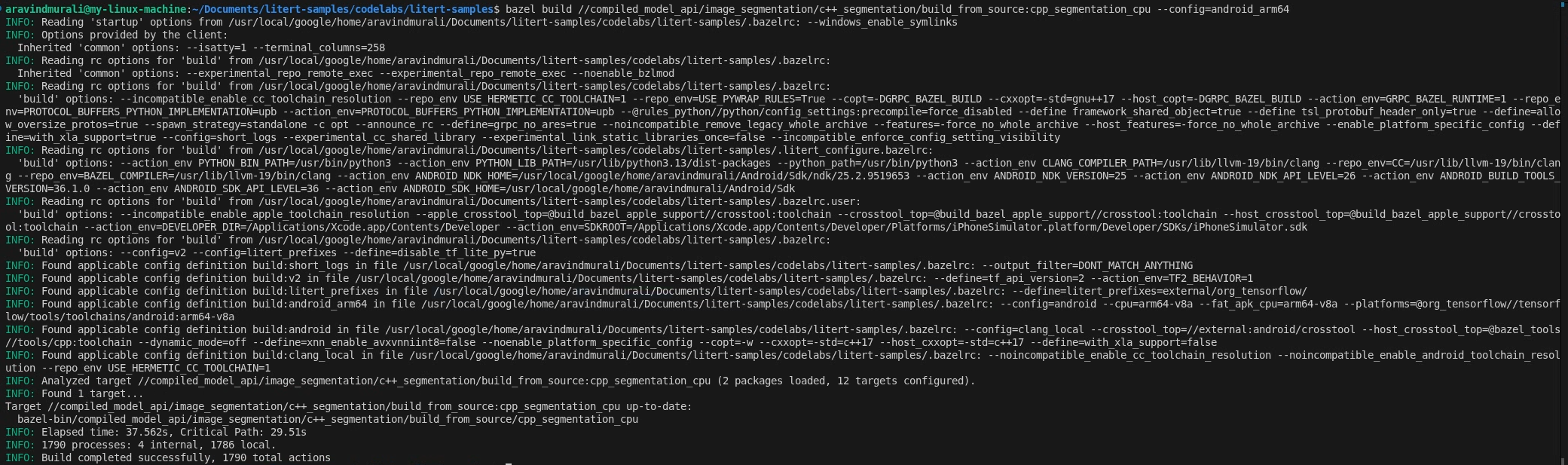
Шаг 2 — Создание целевых платформ для ЦП и ГП
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Шаг 3 — Создание целевого объекта NPU
Qualcomm HTP
- Загрузите и распакуйте QAIRT SDK версии 2.41 или более поздней.
- Убедитесь, что извлеченное содержимое SDK находится в подкаталоге с именем
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Выполните сборку, указав родительский путь, заканчивающийся на
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Флаг --nocheck_visibility необходим, поскольку для некоторых целевых платформ LiteRT по умолчанию установлены ограничения на видимость.
MediaTek APU
Дополнительный SDK не требуется. Среда выполнения NeuroPilot представляет собой системную библиотеку на устройствах Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
Файл BUILD
Откройте build_from_source/BUILD . В нем определены четыре цели cc_binary — по одной для каждого ускорителя плюс выделенная цель для NPU MediaTek — каждая в зависимости от общих целей библиотек image_processor , image_utils и timing_utils :
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
Для целевого объекта GPU в качестве зависимости данных добавляется libLiteRtClGlAccelerator.so , поэтому Bazel включает его в исполняемые файлы. Для целевых объектов NPU в качестве зависимостей данных добавляются файлы vendor dispatch и compiler plugin .so .
8. Ускоренная на графическом процессоре предобработка с использованием вычислительных шейдеров.
Все три точки входа используют один и тот же конвейер вычислительных шейдеров OpenGL ES для предварительной обработки. Понимание этого конвейера является ключом к пониманию того, почему путь через GPU намного быстрее, чем путь через CPU.
Настройте контекст EGL без графического интерфейса.
ImageProcessor::InitializeGL() создает контекст EGL без графического интерфейса — контекст OpenGL без прикрепленного окна или дисплея. Это стандартная практика для вычислений на GPU вне экрана на Android. Затем она компилирует пять программ шейдеров GLSL с диска:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Загрузите входное изображение на графический процессор.
Изображение JPEG декодируется в память ЦП с помощью ImageUtils::LoadImage() (через библиотеку STB), а затем загружается в текстуру графического процессора:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
С этого момента исходное изображение хранится в памяти графического процессора в виде текстуры OpenGL.
Шейдер предварительной обработки вычислений
В shaders/preprocess_compute.glsl распределено 8×8 групп потоков по выходной сетке 256×256. Каждый поток обрабатывает один выходной пиксель: он считывает входную текстуру с помощью билинейной фильтрации (аппаратное изменение размера бесплатно), преобразует значение RGB [0, 1] в [-1, 1] и записывает в выходной SSBO:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
При стандартном (без нулевого копирования) пути этот SSBO затем считывается обратно в ЦП и записывается в тензор LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Вывод данных ЦП
Откройте main_cpu.cc . Настройка LiteRT состоит всего из трех строк:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
После предварительной обработки вывод осуществляется одним синхронным вызовом:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() блокируется до завершения вывода. Модель selfie_multiclass_256x256.tflite с плавающей запятой работает на ядрах ARM Cortex и обычно занимает ~116–128 мс на устройствах среднего уровня.
Использование бинарных файлов:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Вывод данных на графическом процессоре (OpenCL)
Откройте main_gpu.cc . Путь к GPU вводит два понятия, отсутствующие в пути к CPU: litert::Options для настройки графического ускорителя (с бэкендом OpenCL) и асинхронное выполнение.
Настройка параметров графического процессора
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Асинхронный вывод
В пути к графическому процессору используется RunAsync() вместо Run() . Это отправляет задачу в очередь команд графического процессора и немедленно возвращает результат. Затем происходит синхронизация перед чтением результатов:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Такая неблокирующая архитектура позволяет совмещать работу ЦП и выполнение на ГП в режиме реального времени.
Использование бинарных файлов:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Постобработка — Удаление чередующихся слоев и смешивание
После завершения Run() или RunAsync() , output_buffers[0] содержит плоский массив чисел с плавающей запятой размером [256 × 256 × 6] в чередующемся порядке. 6 оценок классов для пикселя (row, col) находятся по индексам (row * 256 + col) * 6 до (row * 256 + col) * 6 + 5 .
Разделение на 6 масок SSBO
Вспомогательный процессор разделяет чередующийся массив на 6 одноканальных массивов чисел с плавающей запятой и загружает каждый в свой собственный графический процессор SSBO:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Наложение масок смешивания цветов на исходное изображение
processor.ApplyColoredMasks() запускает шейдер mask_blend_compute.glsl . Для каждого выходного пикселя она находит класс с наивысшим баллом (argmax по 6 значениям SSBO маски) и выполняет альфа-композицию соответствующего цвета на исходный пиксель изображения. Шесть цветов определены в каждой точке входа:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
Значение альфа-канала 0.1f обеспечивает едва заметный оттенок, благодаря чему исходное изображение остается видимым.
Сохраните результат.
Итоговое смешанное RGBA-изображение с плавающей запятой в формате SSBO считывается обратно, ограничивается диапазоном [0, 1] , преобразуется в unsigned char и сохраняется в формате PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Развертывание и запуск на устройстве
Подключите ваше устройство Android через USB и проверьте наличие соединения ADB:
adb devices

Используйте deploy_and_run_on_android.sh
Каждый вариант имеет свой собственный скрипт развертывания. Вариант CMake указывает на каталог build/ ; вариант Bazel указывает на bazel-bin/ . Оба скрипта:
- Создайте на устройстве папку
/data/local/tmp/cpp_segmentation_android/. - Загрузите исполняемый файл, GLSL-шейдеры, модель, тестовое изображение и файлы
.soсреды выполнения. - Запустите вывод с помощью
adb shell. - Скопируйте
output_segmented.pngобратно на свой компьютер.
Вариант CMake ( use_prebuilt_litert/ )
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Вариант Bazel ( build_from_source/ )
Выполните эти команды из корневой папки репозитория примеров LiteRT :
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
Флаг --phone определяет, какие библиотеки, специфичные для конкретного устройства и производителя, будут использоваться. Поддерживаемые значения: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) и pixel11 (Tensor G6).
Время выполнения вывода
После выполнения алгоритма PrintTiming() выводит полный анализ профилирования:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Результаты тестирования на Samsung S25 Ultra (Snapdragon 8 Elite):
Акселератор | Тип исполнения | Вывод | E2E |
Процессор | Синхронизация | ~116–128 мс | ~157 мс |
GPU (OpenCL) | Асинхронный | ~0,95 мс | ~35–43 мс |
13. Расширенные (необязательно): Вывод данных с использованием NPU
Для достижения максимальной производительности LiteRT поддерживает ускорение NPU с использованием библиотек плагинов от конкретных производителей. Путь NPU позволяет достичь сквозной задержки всего в 9 мс.
Поддерживаемые устройства и режимы
Чип | Пример устройства | Режим | E2E |
Qualcomm SM8650 | Galaxy S24 | АОТ | ~17 мс |
Qualcomm SM8750 | Galaxy S25 | АОТ | ~17 мс |
Qualcomm (любая) | — | ДЖИТ | ~28 мс |
MediaTek Dimensity 9400 | — | ДЖИТ | ~9 мс |
Google Tensor G3-G6 | Пиксель 8-11 | AOT/JIT | Различный |
Технология AOT (Ahead-of-Time) использует предварительно скомпилированную модель, специфичную для конкретного устройства (например, selfie_multiclass_256x256_SM8650.tflite ). Это самый быстрый вариант, но он зависит от конкретного чипа.
JIT (Just-in-Time) использует стандартный файл selfie_multiclass_256x256.tflite и компилирует код для NPU во время выполнения — более медленный первый запуск, независимый от чипа.
Дополнительные предварительные условия
Quancomm HTP:
- QAIRT SDK v2.41+ (предоставляет
libQnnHtp.so, файлы-заглушки или скелетные файлы.so). -
libLiteRtDispatch_Qualcomm.soиз репозитория библиотек среды выполнения LiteRT NPU, размещенного на GitHub.
APU MediaTek:
-
libLiteRtDispatch_MediaTek.soиз релиза библиотек среды выполнения LiteRT NPU. - Библиотека NeuroPilot уже существует в качестве системной библиотеки на устройствах Dimensity 9400 — ничего добавлять не нужно).
Google Tensor:
-
libLiteRtDispatch_GoogleTensor.soиз релиза библиотек среды выполнения LiteRT NPU.
Среда и параметры NPU
main_npu.cc указывает Environment выполнения каталог библиотек диспетчеризации поставщика на устройстве, а затем устанавливает параметры производительности, специфичные для поставщика:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
Для процессоров MediaTek замените блок GetQualcommOptions() :
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Развертывание для NPU
Вариант CMake — Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Вариант CMake — MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Вариант Bazel — Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Вариант Bazel — MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Вариант Bazel — Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
В варианте с Bazel библиотеки QAIRT SDK автоматически подхватываются из дерева исполняемых файлов bazel-bin , если параметр LITERT_QAIRT_SDK установлен во время сборки. Вариант с CMake требует, чтобы флаг --host_npu_lib указывал на извлеченный вами QAIRT SDK.
14. Поздравляем!
Вы успешно создали и запустили конвейер сегментации изображений на C++ для Android с использованием LiteRT. Вы научились:
- Кросс-компиляция исполняемого файла C++ для Android
arm64-v8aс использованием CMake + NDK или Bazel. - Используйте API LiteRT C++ (
Environment,CompiledModel,TensorBuffer) для эффективного выполнения вычислений непосредственно на устройстве. - Предварительная обработка данных изображения на графическом процессоре с использованием вычислительных шейдеров OpenGL ES 3.1.
- Запустите синхронный вывод результатов на ЦП и асинхронный вывод результатов на ГП (OpenCL).
- Настройте ускорение NPU для устройств Qualcomm, MediaTek и Google Tensor.
- Разверните и запустите исполняемый файл C++ на Android с помощью ADB.
Следующие шаги
- Замените модель TFLite на другую (например, для оценки глубины или определения позы).
- Интегрируйте конвейер C++ в приложение Android NDK с помощью JNI.
- Анализ использования памяти с помощью Android GPU Inspector, а также вывод результатов измерений.
- Изучите возможности квантования моделей для дальнейшего снижения задержки при выполнении вычислений с помощью NPU.