
1. Antes de começar
Digitar o código é uma ótima maneira de criar memória muscular e aprofundar seu entendimento do material. Embora copiar e colar possa economizar tempo, investir nessa prática pode levar a uma maior eficiência e habilidades de programação mais fortes a longo prazo.
Neste codelab, você vai aprender a criar um binário de segmentação de imagens em C++ que é executado diretamente em um dispositivo Android usando o ambiente de execução de alta performance no dispositivo do Google, o LiteRT. Em vez de usar Kotlin ou Android Studio, este codelab se concentra na criação de um binário C++. Você vai fazer a compilação cruzada com CMake ou Bazel e implantar usando o ADB. A mesma API LiteRT C++ funciona em qualquer plataforma (Android, Linux, incorporada), o que a torna uma base útil para aplicativos essenciais para o desempenho, robótica e sistemas de borda.
Você vai conhecer todo o pipeline:
- Configurar o ambiente de build (CMake + Android NDK ou Bazel).
- Vincular o SDK LiteRT C++ de uma versão pré-criada ou da origem.
- Usar sombreadores de computação OpenGL ES para pré e pós-processamento de imagens acelerado por GPU.
- Executar o modelo de segmentação
selfie_multiclasscom a API C++ do LiteRT. - Acelerar a inferência em CPU, GPU (OpenCL) e NPU (Qualcomm / MediaTek).
- Pós-processamento da saída do modelo bruto em uma imagem de segmentação com combinação de cores.
- Implantação em um dispositivo Android físico com ADB e recuperação do resultado.
No final, você vai produzir algo semelhante à imagem a seguir: uma imagem estática processada em todo o pipeline, com cada uma das seis classes de segmentação sobrepostas em uma cor distinta:

Pré-requisitos
Este codelab foi criado para desenvolvedores com experiência em C++ que querem aprender a executar modelos de machine learning no Android na camada C++. Você precisa:
- Fundamentos de C++ (ponteiros, vetores, inclusões).
- Conceitos básicos do Android/ADB (
adb push,adb shell). - Usar um terminal e scripts de shell no Linux ou macOS.
O que você vai aprender
- Como fazer a compilação cruzada de um binário C++ para Android
arm64-v8acom CMake + NDK ou Bazel. - Como usar a API C++ do LiteRT (
Environment,CompiledModel,TensorBuffer) para inferência eficiente no dispositivo. - Como os sombreadores de computação do OpenGL ES 3.1 aceleram o pré e o pós-processamento totalmente na GPU.
- Como configurar o LiteRT para aceleração de CPU, GPU (OpenCL) e NPU (Qualcomm HTP, MediaTek APU, Google Tensor).
- A diferença entre inferência síncrona (
Run) e assíncrona (RunAsync). - Como implantar e executar um binário C++ no Android usando o ADB.
O que é necessário
- Uma máquina Linux ou macOS. Usuários do Windows precisam usar o WSL2.
- Android NDK r25c ou mais recente (download).
- Para Caminho do CMake: CMake ≥ 3.22 (
sudo apt-get install cmake). - Para Caminho do Bazel: Bazel instalado e o repositório completo de amostras do LiteRT.
- ADB em
PATH(Android Platform Tools). - Um dispositivo Android físico. O ideal é testar no Galaxy S24/S25 ou no Pixel.
2. Segmentação de imagens
A segmentação de imagem é uma tarefa de visão computacional que atribui um rótulo de classe a cada pixel em uma imagem. Ao contrário da detecção de objetos, que desenha uma caixa delimitadora, a segmentação produz uma compreensão precisa e perfeita em termos de pixels de onde cada objeto começa e termina.
Este codelab usa o modelo selfie_multiclass_256x256, que classifica cada pixel em uma das 16 classes:
Índice de classes | Segmento |
0 | Contexto |
1 | Cabelos |
2 | Pele do corpo |
3 | Pele do rosto |
4 | Roupas |
5 | Acessórios (óculos, joias etc.) |
O modelo gera um tensor de ponto flutuante de forma [1, 256, 256, 6]. Para cada um dos pixels de 256 x 256, há seis pontuações de confiança, uma por classe. A classe com a maior pontuação vence esse pixel (argmax).
LiteRT: performance no perímetro
O LiteRT é o ambiente de execução de alta performance de última geração do Google para modelos do TFLite. A API C++ oferece acesso direto e de baixa sobrecarga a aceleradores de hardware com uma interface consistente nas três opções:
- CPU: compatibilidade universal; inferência de ~128 ms em um dispositivo intermediário.
- GPU (OpenCL): inferência de ~1 ms; de ~17 a 43 ms de ponta a ponta, dependendo da estratégia de buffer.
- NPU: ~9 a 28 ms de ponta a ponta em dispositivos Qualcomm Snapdragon, MediaTek Dimensity 9400 e Google Tensor, dependendo de AOT x. Compilação JIT.
A abstração principal é CompiledModel: o modelo é pré-compilado e otimizado para o hardware de destino no tempo de carregamento, reduzindo a inferência a uma chamada Run() em buffers pré-alocados.
3. Começar a configuração
Clonar o repositório
git clone https://github.com/google-ai-edge/litert-samples.git
Todos os recursos deste codelab estão em:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Esse diretório tem dois subprojetos, cada um com um build completo da mesma amostra:
Diretório | Sistema de build | Dependência do LiteRT |
| CMake + Android NDK |
|
| Bazel | Compila o LiteRT da origem |
Escolha um caminho e siga-o. O código é idêntico entre os dois diretórios. Apenas o sistema de build e a estratégia de dependência são diferentes. Se quiser a configuração mais rápida, escolha use_prebuilt_litert/. Se você precisar modificar o LiteRT ou trabalhar em um monorepo do Bazel, use build_from_source/.
Observação sobre caminhos de arquivos
Todos os caminhos de arquivo neste tutorial usam o formato Linux/macOS. Os usuários do Windows precisam usar o WSL2.
Visão geral do diretório
Os dois subprojetos compartilham o mesmo layout de origem:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Além disso:
use_prebuilt_litert/adicionaCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shethird_party/stb/.build_from_source/adiciona um arquivoBUILDdo Bazel e usadeploy_and_run_on_android.shapontando parabazel-bin/.
4. Entender a estrutura do projeto
Três pontos de entrada, um pipeline
main_cpu.cc, main_gpu.cc e main_npu.cc contêm uma função main() que impulsiona todo o pipeline de segmentação. O pipeline é idêntico nos três. Apenas a configuração do acelerador LiteRT e a estratégia de buffer são diferentes:
Arquivo | Accelerator | Estratégia de buffer |
|
| Memória da CPU |
|
| Memória da CPU com back-end OpenCL |
|
| Memória da CPU com fallback da CPU |
Os três compartilham os mesmos utilitários ImageProcessor (sombreadores de computação OpenGL ES para pré-processamento e pós-processamento) e ImageUtils (E/S de imagem STB).
O pipeline completo
Cada ponto de entrada segue a mesma estrutura de cinco fases:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Carregar:
ImageUtils::LoadImage()decodifica o JPEG na memória da CPU usando a biblioteca de imagens STB. - Upload: o
processor.CreateOpenGLTexture()faz upload dos pixels brutos para uma textura da GPU (OpenGL RGBA8). - Pré-processamento:
processor.PreprocessInputForSegmentation()executa um sombreador de computação GLSL que redimensiona a textura para 256×256 e normaliza os valores de pixel de[0, 1]para[-1, 1]. O resultado fica em um SSBO da GPU. - Inferência: os dados do SSBO são gravados em um
TensorBufferdo LiteRT, e ocompiled_model.Run()(ouRunAsync()) executa o modelo. - Pós-processamento: a saída de ponto flutuante de seis canais do modelo é desentrelaçada em seis SSBOs de máscara de canal único, que são combinados por cores de volta à imagem original.
- Salvar: o
ImageUtils::SaveImage()grava a imagem RGBA final como PNG.
5. APIs principais do LiteRT C++
Antes de criar, familiarize-se com os três tipos principais de C++ do LiteRT usados em todos os pontos de entrada. Todos estão no namespace litert::.
litert::Environment
O Environment é o contexto raiz de todas as operações do LiteRT. Crie uma vez e transmita para CompiledModel::Create. Para uso da NPU, configure-a com o diretório da biblioteca de plug-ins do fornecedor.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
O CompiledModel carrega e pré-compila seu modelo do TFLite para o hardware solicitado no momento da construção. A inferência é reduzida ao preenchimento de buffers e à chamada de Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Os buffers de tensor armazenam dados de entrada/saída. Sempre crie-os no CompiledModel para que tenham o tamanho e o alinhamento corretos para o hardware de destino.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Macros de tratamento de erros
Macro | Comportamento |
| Atribui ou chama |
| Chama |
| Atribui ou propaga o erro ao autor da chamada. |
6. Build — Opção A: SDK C++ LiteRT pré-criado (CMake)
Esse é o caminho recomendado se você não precisar modificar o LiteRT. O script de build faz o download dos cabeçalhos do SDK, copia seu .so, busca o STB e invoca o CMake + NDK em um único comando.
Etapa 1: extrair libLiteRt.so do Maven
O LiteRT envia o tempo de execução como uma biblioteca compartilhada em um AAR do Android no Google Maven. Faça o download e extraia o arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Para suporte a GPU, extraia também o acelerador OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

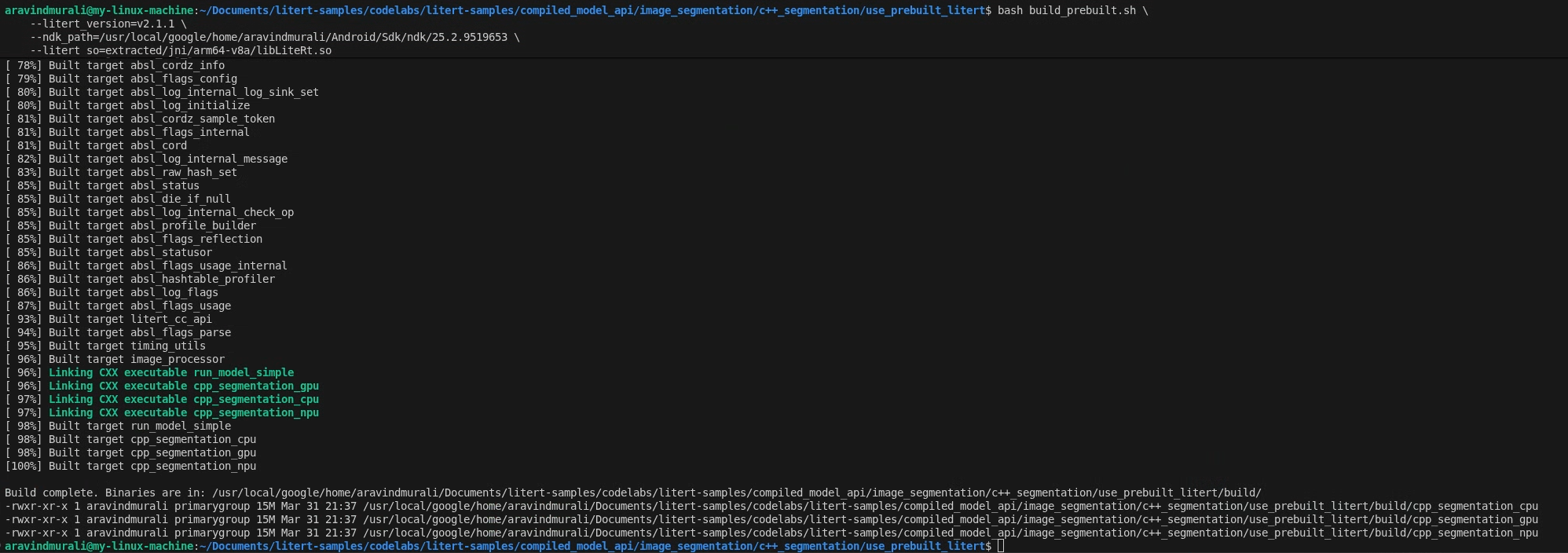
Etapa 2: executar build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
O script faz o seguinte:
- Faça o download de
litert_cc_sdk.zip(cabeçalhos do SDK + arquivos cmake) da versão do LiteRT no GitHub. Essa etapa é ignorada em execuções subsequentes se já estiver presente. - Copie
libLiteRt.soparalitert_cc_sdk/. - Faça o download dos cabeçalhos de imagem da STB em
third_party/stb/. Essa etapa será ignorada se eles já estiverem presentes. - Configure e crie com o CMake usando o conjunto de ferramentas do Android NDK para
arm64-v8aemandroid-26.
Se tudo der certo, você vai encontrar três binários em build/:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
O que CMakeLists.txt faz
Abra CMakeLists.txt. Ele exige C++20, extrai o SDK LiteRT via add_subdirectory, vincula o OpenGL ES 3 (GLESv3) e o EGL e usa uma macro auxiliar para criar cada binário da origem main_*.cc:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Criação — Opção B: criar com o Bazel (da origem)
Escolha esse caminho se preferir o Bazel como sistema de build, que compila o tempo de execução do LiteRT da origem, ou se precisar trabalhar em um espaço de trabalho do Bazel.
Pré-requisitos
Além do NDK e do ADB listados na seção "Antes de começar", você vai precisar de:
- O Bazel instalado e no seu
PATH. - Um clone completo do repositório de origem de amostras do LiteRT.
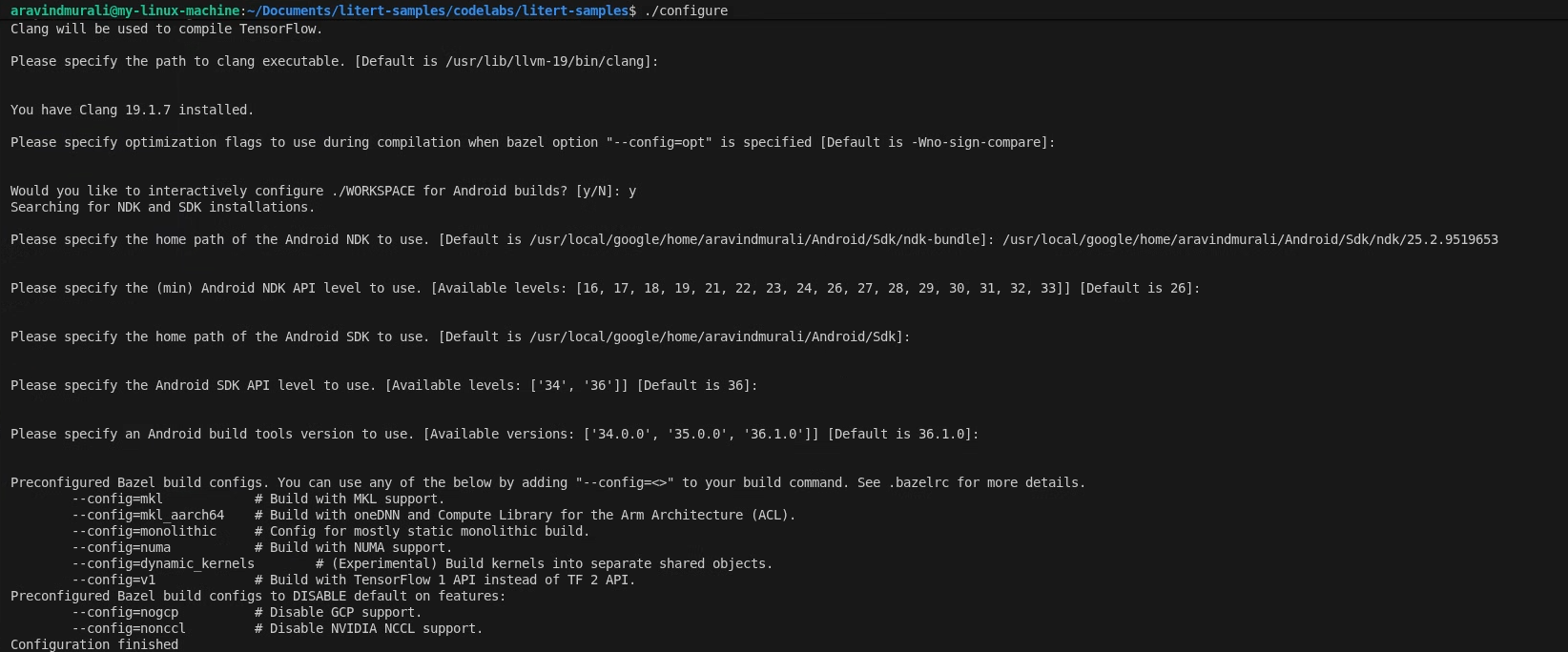
Etapa 1: configurar o espaço de trabalho de amostras do LiteRT
Todos os comandos são executados na raiz do repositório de amostras do LiteRT.
cd /path/to/litert-samples
./configure
Quando solicitado:
- Aceite os padrões para Python e caminho da biblioteca Python.
- Responda N para suporte a ROCm e CUDA.
- Selecione clang (testado com 18.1.3) como o compilador.
- Aceite as flags de otimização padrão.
- Responda Y para configurar o WORKSPACE para builds do Android.
- Defina o nível mínimo do Android NDK como pelo menos 26.
- Informe o caminho para o SDK do Android.
- Defina o nível da API do SDK do Android como padrão (36) e as ferramentas de build como 36.0.0.
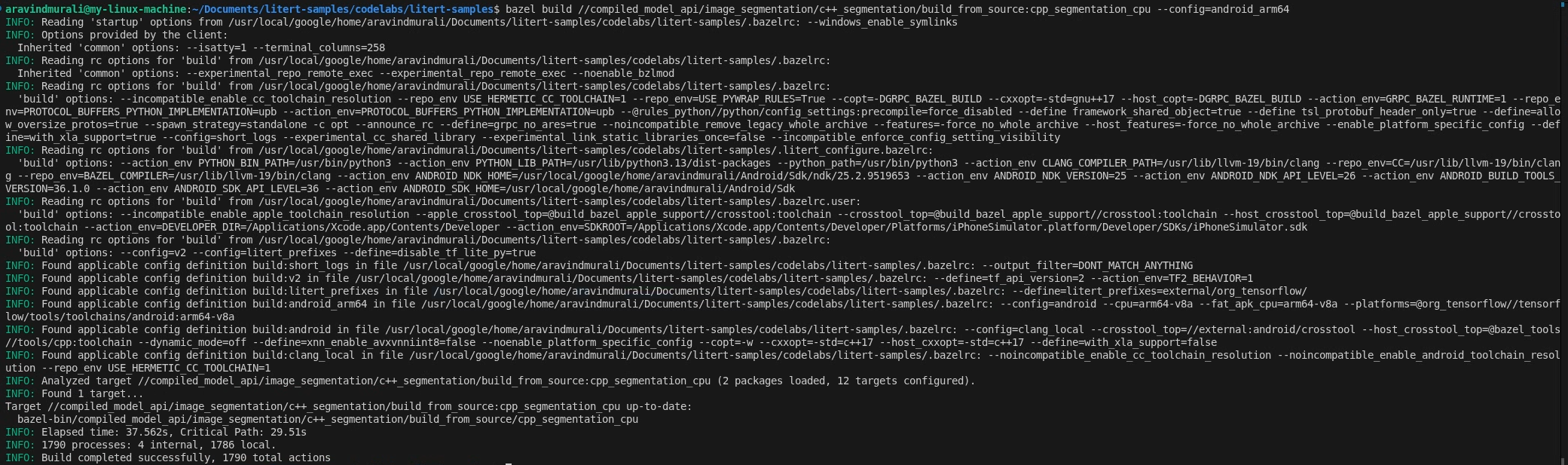
Etapa 2: criar os destinos de CPU e GPU
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Etapa 3: criar a meta de NPU
Qualcomm HTP
- Baixe e extraia o SDK do QAIRT v2.41 ou mais recente.
- Verifique se o conteúdo extraído do SDK está em um subdiretório chamado
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Crie, transmitindo o caminho pai que termina com
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
A flag --nocheck_visibility é obrigatória porque alguns destinos LiteRT upstream têm visibilidade padrão restrita.
APU MediaTek
Nenhum outro SDK é necessário. O ambiente de execução do NeuroPilot é uma biblioteca do sistema em dispositivos Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
Arquivo BUILD
Abra build_from_source/BUILD. Ele define quatro destinos cc_binary, um por acelerador mais um destino dedicado da NPU MediaTek, cada um dependendo dos destinos compartilhados das bibliotecas image_processor, image_utils e timing_utils:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
A meta da GPU adiciona libLiteRtClGlAccelerator.so como uma dependência de dados para que o Bazel a inclua nos runfiles. As metas de NPU adicionam arquivos de envio do fornecedor e plug-in do compilador .so como dependências de dados.
8. Pré-processamento acelerado por GPU com shaders de computação
Todos os três pontos de entrada usam o mesmo pipeline de pré-processamento de sombreador de computação do OpenGL ES. Entender isso é fundamental para saber por que o caminho da GPU é muito mais rápido do que o da CPU.
Configurar um contexto EGL sem comando
ImageProcessor::InitializeGL() cria um contexto EGL sem interface, ou seja, um contexto OpenGL sem janela ou tela anexada. Essa é uma prática padrão para computação de GPU fora da tela no Android. Em seguida, ele compila os cinco programas de sombreador de computação do GLSL do disco:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Faça upload da imagem de entrada para a GPU.
O JPEG é decodificado na memória da CPU por ImageUtils::LoadImage() (usando a biblioteca STB) e depois enviado para uma textura da GPU:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
A partir desse ponto, a imagem original fica na memória da GPU como uma textura OpenGL.
O shader de computação de pré-processamento
shaders/preprocess_compute.glsl envia grupos de threads 8x8 na grade de saída 256x256. Cada thread processa um pixel de saída: ele faz amostragem da textura de entrada usando filtragem bilinear (redimensionamento de hardware sem custo financeiro), converte o valor RGB [0, 1] em [-1, 1] e grava no SSBO de saída:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Para o caminho padrão (sem cópia zero), esse SSBO é lido de volta para a CPU e gravado no tensor LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Inferência de CPU
Abra main_cpu.cc. A configuração do LiteRT tem três linhas:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Após o pré-processamento, a inferência é uma única chamada síncrona:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() é bloqueado até que a inferência seja concluída. O modelo de usar pontos flutuantes selfie_multiclass_256x256.tflite é executado nos núcleos ARM Cortex e geralmente leva de 116 a 128 ms em um dispositivo intermediário.
Uso binário:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Inferência de GPU (OpenCL)
Abra main_gpu.cc. O caminho da GPU apresenta dois conceitos não presentes no caminho da CPU: litert::Options para configurar o acelerador de GPU (com o back-end OpenCL) e a execução assíncrona.
Configurar opções de GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Inferência assíncrona
O caminho da GPU usa RunAsync() em vez de Run(). Isso envia o trabalho para a fila de comandos da GPU e retorna imediatamente. Depois, sincronize antes de ler os resultados:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Esse design não bloqueador permite sobrepor o trabalho da CPU com a execução da GPU em um pipeline em tempo real.
Uso binário:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Pós-processamento: desentrelaçar e combinar
Depois que Run() ou RunAsync() for concluído, output_buffers[0] vai conter uma matriz de ponto flutuante simples de forma [256 × 256 × 6] em ordem intercalada. As seis pontuações de classe para o pixel (row, col) estão nos índices (row * 256 + col) * 6 a (row * 256 + col) * 6 + 5.
Intercalar em seis SSBOs de máscara
Um auxiliar de CPU divide a matriz intercalada em seis matrizes de ponto flutuante de canal único e faz upload de cada uma para o próprio SSBO da GPU:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Máscaras de combinação de cores na imagem original
O processor.ApplyColoredMasks() executa o shader mask_blend_compute.glsl. Para cada pixel de saída, ele encontra a classe com a maior pontuação (argmax nos seis SSBOs de máscara) e combina a cor correspondente com o pixel de imagem original usando composição alfa. As seis cores são definidas em cada ponto de entrada:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
O alfa de 0.1f mantém a sutileza da tonalidade para que a imagem original permaneça visível.
Salvar a saída
O SSBO de ponto flutuante RGBA combinado final é lido de volta, fixado em [0, 1], convertido em unsigned char e salvo como PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Implantar e executar no dispositivo
Conecte seu dispositivo Android usando USB e verifique a conectividade ADB:
adb devices

Usar deploy_and_run_on_android.sh
Cada variante tem um script de implantação próprio. A variante do CMake aponta para o diretório build/, e a do Bazel aponta para bazel-bin/. Os dois scripts:
- Crie
/data/local/tmp/cpp_segmentation_android/no dispositivo. - Envie o binário, os sombreadores GLSL, o modelo, a imagem de teste e os arquivos de tempo de execução
.so. - Execute a inferência usando
adb shell. - Puxe
output_segmented.pngde volta para sua máquina.
Variante do CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Variante do Bazel (build_from_source/)
Execute estes comandos na raiz do repositório de amostras do LiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
A flag --phone controla quais bibliotecas de modelo e fornecedor específicas do dispositivo são usadas. Valores aceitos: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) e pixel11 (Tensor G6).
Tempo de inferência
Após a inferência, PrintTiming() imprime um detalhamento completo do perfil:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Desempenho de referência no Samsung S25 Ultra (Snapdragon 8 Elite):
Accelerator | Tipo de execução | Inferência | E2E |
CPU | Sincronização | ~116–128 ms | ~157 ms |
GPU (OpenCL) | Assíncrona | ~0,95 ms | 35 a 43 ms |
13. Avançado (opcional): inferência de NPU
Para ter o máximo de desempenho, o LiteRT oferece suporte à aceleração de NPU usando bibliotecas de plug-ins específicas do fornecedor. O caminho da NPU pode atingir uma latência de ponta a ponta de até 9 ms.
Dispositivos e modos compatíveis
Ícone | Exemplo de dispositivo | Modo | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 ms |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 ms |
Qualcomm (qualquer) | — | JIT | ~28 ms |
MediaTek Dimensity 9400 | — | JIT | ~9 ms |
Google Tensor G3 a G6 | Pixel 8 a 11 | AOT/JIT | Varia |
AOT (Ahead-of-Time) usa um modelo pré-compilado específico do dispositivo (por exemplo, selfie_multiclass_256x256_SM8650.tflite). Essa é a opção mais rápida, mas é específica do chip.
O JIT (Just-in-Time) usa o selfie_multiclass_256x256.tflite padrão e compila para a NPU durante a execução. A primeira execução é mais lenta e independente do chip.
Pré-requisitos extras
Qualcomm HTP:
- SDK do QAIRT v2.41 ou mais recente (fornece arquivos
libQnnHtp.so, stub ou skel.so). libLiteRtDispatch_Qualcomm.sodo lançamento das bibliotecas de tempo de execução da NPU LiteRT no GitHub.
APU MediaTek:
libLiteRtDispatch_MediaTek.sodas bibliotecas de tempo de execução da NPU LiteRT.- Tempo de execução do NeuroPilot (já é uma biblioteca do sistema em dispositivos Dimensity 9400. Não é necessário fazer nada).
Google Tensor:
libLiteRtDispatch_GoogleTensor.sodas bibliotecas de tempo de execução da NPU LiteRT.
Ambiente e opções da NPU
main_npu.cc aponta o Environment para o diretório da biblioteca de envio do fornecedor no dispositivo e define opções de desempenho específicas do fornecedor:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
Para MediaTek, substitua o bloco GetQualcommOptions():
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Implantar para NPU
Variante do CMake: Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Variante do CMake: MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Variante do Bazel: Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Variante do Bazel: MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Variante do Bazel: Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Para a variante do Bazel, as bibliotecas do SDK da QAIRT são coletadas automaticamente da árvore de runfiles bazel-bin quando LITERT_QAIRT_SDK é definido no tempo de build. A variante do CMake exige que a flag --host_npu_lib aponte para o SDK do QAIRT extraído.
14. Parabéns!
Você criou e executou um pipeline de segmentação de imagens em C++ no Android usando o LiteRT. Você aprendeu a:
- Faça a compilação cruzada de um binário C++ para Android
arm64-v8acom CMake + NDK ou Bazel. - Use a API C++ do LiteRT (
Environment,CompiledModel,TensorBuffer) para inferência eficiente no dispositivo. - Pré-processe dados de imagem na GPU com sombreadores de computação OpenGL ES 3.1.
- Executar inferência síncrona de CPU e inferência assíncrona de GPU (OpenCL).
- Configure a aceleração da NPU para dispositivos Qualcomm, MediaTek e Google Tensor.
- Implante e execute um binário C++ no Android usando o ADB.
Próximas etapas
- Troque por um modelo TFLite diferente (por exemplo, estimativa de profundidade ou detecção de postura).
- Integre o pipeline C++ a um app Android NDK usando JNI.
- Crie um perfil de uso da memória com o Android GPU Inspector e a saída de tempo.
- Conheça a quantização de modelos para reduzir ainda mais a latência de inferência da NPU.