
1. Zanim zaczniesz
Wpisywanie kodu to świetny sposób na wyrobienie pamięci mięśniowej i pogłębienie wiedzy. Kopiowanie i wklejanie może oszczędzić czas, ale inwestowanie w tę praktykę może w dłuższej perspektywie zwiększyć wydajność i poprawić umiejętności kodowania.
Z tego ćwiczenia dowiesz się, jak utworzyć binarny plik segmentacji obrazu w C++, który działa bezpośrednio na urządzeniu z Androidem przy użyciu wydajnego środowiska wykonawczego na urządzeniu LiteRT od Google. To ćwiczenie koncentruje się na tworzeniu pliku binarnego w C++, a nie na używaniu Kotlina czy Androida Studio. Skompilujesz go krzyżowo za pomocą CMake lub Bazel i wdrożysz za pomocą ADB. Ten sam interfejs LiteRT C++ API działa na każdej platformie (Android, Linux, systemy wbudowane), co czyni go przydatną podstawą dla aplikacji o krytycznym znaczeniu dla wydajności, robotyki i systemów brzegowych.
Przeprowadzimy Cię przez cały potok:
- Skonfiguruj środowisko kompilacji (CMake + Android NDK lub Bazel).
- Połączenie pakietu LiteRT C++ SDK – z gotowej wersji lub z kodu źródłowego.
- Używanie shaderów obliczeniowych OpenGL ES do wstępnego i końcowego przetwarzania obrazów z akceleracją GPU.
- Uruchamianie modelu segmentacji
selfie_multiclassza pomocą interfejsu LiteRT C++ API. - Przyspieszanie wnioskowania na CPU, GPU (OpenCL) i NPU (Qualcomm / MediaTek).
- Przetwarzanie końcowe surowych danych wyjściowych modelu w obraz segmentacji z mieszaniem kolorów.
- wdrażanie na fizycznym urządzeniu z Androidem za pomocą ADB i pobieranie wyniku;
Na koniec uzyskasz obraz podobny do tego poniżej – statyczny obraz przetworzony w pełnym potoku, z każdą z 6 klas segmentacji nałożoną w innym kolorze:

Wymagania wstępne
Te ćwiczenia z programowania są przeznaczone dla deweloperów, którzy dobrze znają język C++ i chcą zdobyć doświadczenie w uruchamianiu modeli uczenia maszynowego na Androidzie na poziomie C++. Musisz znać:
- Podstawy C++ (wskaźniki, wektory, dyrektywy include).
- Podstawowe pojęcia dotyczące Androida i ADB (
adb push,adb shell). - Używanie terminala i skryptów powłoki w systemie Linux lub macOS.
Czego się nauczysz
- Jak skompilować krzyżowo plik binarny C++ na Androida
arm64-v8aza pomocą CMake + NDK lub Bazel. - Jak używać interfejsu LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) do wydajnego wnioskowania na urządzeniu. - Jak shadery obliczeniowe OpenGL ES 3.1 przyspieszają przetwarzanie wstępne i końcowe w całości na GPU.
- Jak skonfigurować LiteRT pod kątem akceleracji na procesorze, GPU (OpenCL) i NPU (Qualcomm HTP, MediaTek APU, Google Tensor).
- Różnica między wnioskowaniem synchronicznym (
Run) a asynchronicznym (RunAsync). - Jak wdrożyć i uruchomić plik binarny C++ na Androidzie za pomocą ADB.
Czego potrzebujesz
- urządzenie z systemem Linux lub macOS (użytkownicy systemu Windows powinni używać WSL2);
- Android NDK w wersji r25c lub nowszej (pobierz).
- W przypadku ścieżki CMake: CMake ≥ 3.22 (
sudo apt-get install cmake). - W przypadku ścieżki Bazel: zainstalowany Bazel oraz pełne repozytorium próbek LiteRT.
- ADB w
PATH(Android Platform Tools). - Fizyczne urządzenie z Androidem – najlepiej przetestować na Galaxy S24/S25 lub Pixelu.
2. Segmentacja obrazu
Segmentacja obrazu to zadanie z zakresu widzenia komputerowego, które przypisuje etykietę klasy do każdego piksela na obrazie. W przeciwieństwie do wykrywania obiektów, które rysuje ramkę ograniczającą, segmentacja zapewnia precyzyjne, dokładne co do piksela zrozumienie, gdzie każdy obiekt się zaczyna i kończy.
W tym ćwiczeniu w Codelabs używamy modelu selfie_multiclass_256x256, który klasyfikuje każdy piksel w jednej z 6 klas:
Indeks klasy | Segment |
0 | Tło |
1 | Usługi fryzjerskie |
2 | Skóra ciała |
3 | Skóra twarzy |
4 | Ubranie |
5 | Akcesoria (okulary, biżuteria itp.) |
Model zwraca tensor zmiennoprzecinkowy o kształcie [1, 256, 256, 6]. Dla każdego z 256 × 256 pikseli jest 6 wskaźników ufności – po jednym na każdą klasę. Klasa z najwyższym wynikiem wygrywa ten piksel (argmax).
LiteRT: wydajność na urządzeniach brzegowych
LiteRT to środowisko wykonawcze nowej generacji od Google o wysokiej wydajności, przeznaczone dla modeli TFLite. Interfejs C++ API zapewnia bezpośredni dostęp do akceleratorów sprzętowych o niskim obciążeniu z jednolitym interfejsem na wszystkich 3 platformach:
- CPU – uniwersalna zgodność; czas wnioskowania na urządzeniu średniej klasy to ok. 128 ms.
- GPU (OpenCL) – wnioskowanie trwa około 1 ms, a cały proces około 17–43 ms w zależności od strategii buforowania.
- NPU – ok. 9–28 ms od początku do końca na urządzeniach z układami Qualcomm Snapdragon, MediaTek Dimensity 9400 i Google Tensor, w zależności od tego, czy używana jest funkcja AOT. kompilacja JIT,
Kluczową abstrakcją jest CompiledModel: model jest wstępnie skompilowany i zoptymalizowany pod kątem docelowego sprzętu w czasie wczytywania, co sprowadza wnioskowanie do wywołania Run() w przypadku wstępnie przydzielonych buforów.
3. Konfiguracja
Klonowanie repozytorium
git clone https://github.com/google-ai-edge/litert-samples.git
Wszystkie zasoby do tego ćwiczenia znajdziesz w:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
W tym katalogu znajdują się 2 podprojekty, z których każdy zawiera kompletną kompilację tego samego przykładu:
Katalog | System kompilacji | Zależność LiteRT |
| CMake + Android NDK | Gotowe |
| Bazel | Kompiluje LiteRT ze źródła |
Wybierz jedną ścieżkę i postępuj zgodnie z instrukcjami. Kod w obu katalogach jest identyczny – różnią się tylko system kompilacji i strategia zależności. Jeśli chcesz przeprowadzić najszybszą konfigurację, wybierz use_prebuilt_litert/. Jeśli musisz zmodyfikować samą bibliotekę LiteRT lub pracować w ramach istniejącego repozytorium Bazel, użyj build_from_source/.
Uwaga dotycząca ścieżek do plików
Wszystkie ścieżki do plików w tym samouczku są w formacie Linux/macOS. Użytkownicy systemu Windows powinni używać WSL2.
Omówienie katalogu
Oba podprojekty mają ten sam układ źródłowy:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Dodatkowo:
use_prebuilt_litert/dodaje użytkownikówCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shithird_party/stb/.build_from_source/dodaje plik BazelBUILDi używadeploy_and_run_on_android.shwskazującego nabazel-bin/.
4. Struktura projektu
3 punkty wejścia, 1 potok
main_cpu.cc, main_gpu.cc i main_npu.cc zawierają funkcję main(), która obsługuje cały proces segmentacji. Wszystkie 3 potoki są identyczne. Różnią się tylko konfiguracją akceleratora LiteRT i strategią buforowania:
Plik | Akcelerator | Strategia buforowania |
|
| Pamięć procesora |
|
| Pamięć procesora z backendem OpenCL |
|
| Pamięć procesora z rezerwą procesora |
Wszystkie 3 narzędzia korzystają z tych samych funkcji ImageProcessor (shadery obliczeniowe OpenGL ES do przetwarzania wstępnego i końcowego) i ImageUtils (STB image I/O).
Pełny potok
Każdy punkt wejścia ma taką samą 5-fazową strukturę:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Wczytywanie –
ImageUtils::LoadImage()dekoduje obraz JPEG w pamięci procesora za pomocą biblioteki obrazów STB. - Prześlij –
processor.CreateOpenGLTexture()przesyła nieprzetworzone piksele do tekstury GPU (OpenGL RGBA8). - Preprocess (Przetwarzanie wstępne) –
processor.PreprocessInputForSegmentation()uruchamia shader obliczeniowy GLSL, który zmienia rozmiar tekstury na 256 × 256 i normalizuje wartości pikseli z[0, 1]na[-1, 1]. Wynik trafia do SSBO procesora graficznego. - Wnioskowanie – dane SSBO są zapisywane w LiteRT
TensorBuffericompiled_model.Run()(lubRunAsync()) wykonuje model. - Przetwarzanie końcowe – 6-kanałowe dane wyjściowe modelu w formacie zmiennoprzecinkowym są rozdzielane na 6 buforów SSBO z maskami 1-kanałowymi, które są następnie mieszane kolorystycznie z oryginalnym obrazem.
- Zapisz –
ImageUtils::SaveImage()zapisuje końcowy obraz RGBA jako PNG.
5. Podstawowe interfejsy API LiteRT C++
Przed rozpoczęciem tworzenia zapoznaj się z 3 głównymi typami C++ LiteRT używanymi we wszystkich punktach wejścia. Wszystkie znajdują się w przestrzeni nazw litert::.
litert::Environment
Symbol Environment to kontekst główny wszystkich operacji LiteRT. Utwórz go raz i przekaż do funkcji CompiledModel::Create. W przypadku korzystania z NPU skonfiguruj go za pomocą katalogu biblioteki wtyczek dostawcy.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel wczytuje i wstępnie kompiluje model TFLite dla żądanego sprzętu w momencie tworzenia. Wnioskowanie sprowadza się wtedy do wypełniania buforów i wywoływania funkcji Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Bufory tensorów zawierają dane wejściowe i wyjściowe. Zawsze twórz je w CompiledModel, aby miały odpowiedni rozmiar i były prawidłowo dopasowane do docelowego urządzenia.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Makra obsługi błędów
Makro | Zachowanie |
| Przypisuje lub wywołuje |
| Wywołuje funkcję |
| Przypisuje lub propaguje błąd do wywołującego. |
6. Kompilacja – opcja A: wstępnie skompilowany pakiet LiteRT C++ SDK (CMake)
Jest to zalecana ścieżka, jeśli nie musisz modyfikować samego LiteRT. Skrypt kompilacji pobiera nagłówki pakietu SDK, kopiuje plik .so, pobiera STB i wywołuje CMake + NDK za pomocą jednego polecenia.
Krok 1. Pobierz libLiteRt.so z Maven
LiteRT dostarcza środowisko wykonawcze jako bibliotekę współdzieloną w pliku AAR na Androida w Google Maven. Pobierz i rozpakuj arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Aby uzyskać obsługę GPU, wyodrębnij też akcelerator OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

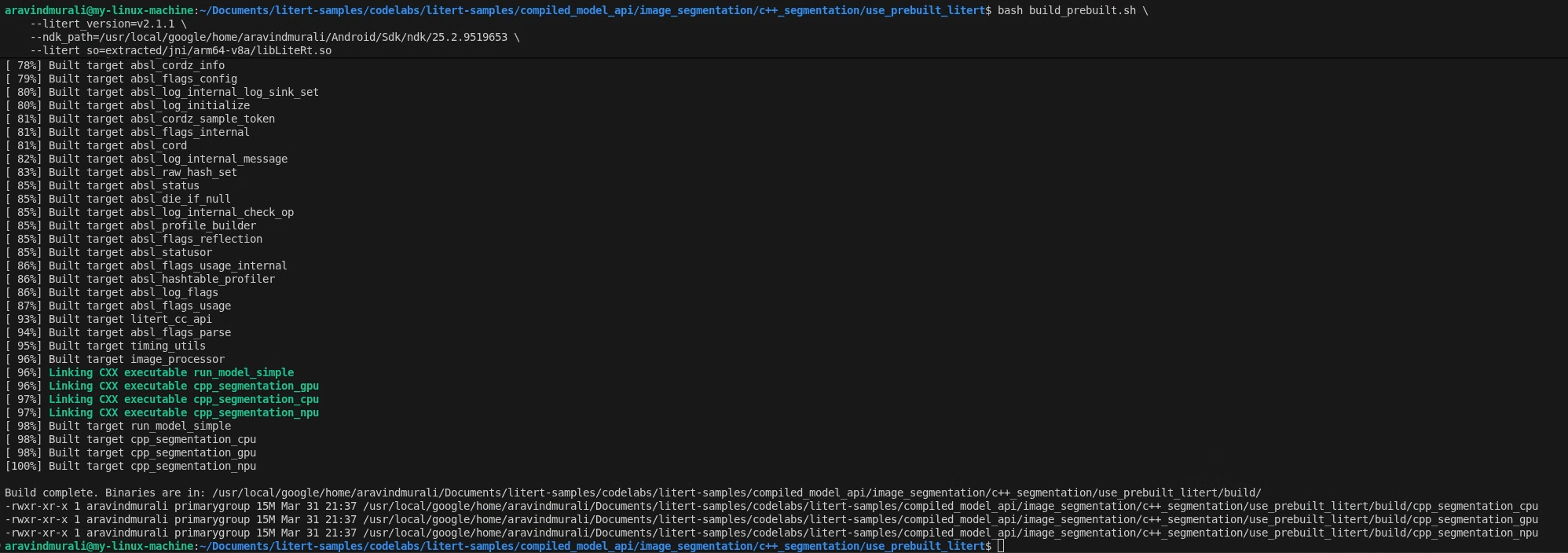
Krok 2. Uruchom build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Skrypt wykona te działania:
- Pobierz
litert_cc_sdk.zip(nagłówki pakietu SDK + pliki cmake) z wersji LiteRT na GitHubie – pomijane w kolejnych uruchomieniach, jeśli są już obecne. - Skopiuj
libLiteRt.sodolitert_cc_sdk/. - Pobierz nagłówki obrazów STB do
third_party/stb/– pomijane, jeśli są obecne. - Skonfiguruj i skompiluj projekt za pomocą CMake przy użyciu łańcucha narzędzi Android NDK dla
arm64-v8aw lokalizacjiandroid-26.
Po zakończeniu w folderze build/ zobaczysz 3 pliki binarne:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Działanie CMakeLists.txt
Otwórz pokój CMakeLists.txt. Wymaga C++20, pobiera pakiet LiteRT SDK za pomocą add_subdirectory, łączy OpenGL ES 3 (GLESv3) i EGL, a następnie używa makra pomocniczego do tworzenia każdego pliku binarnego z jego źródła main_*.cc:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Kompilacja – opcja B: kompilacja za pomocą Bazela (z kodu źródłowego)
Wybierz tę ścieżkę, jeśli wolisz Bazel jako system kompilacji, który kompiluje środowisko wykonawcze LiteRT ze źródeł, lub jeśli musisz pracować w istniejącym obszarze roboczym Bazel.
Wymagania wstępne
Oprócz pakietu NDK i narzędzia ADB wymienionych w sekcji „Zanim zaczniesz” potrzebujesz:
- Bazel zainstalowany na
PATH. - Pełna kopia repozytorium źródłowego próbek LiteRT.
Krok 1. Skonfiguruj obszar roboczy z przykładowymi plikami LiteRT
Wszystkie polecenia są uruchamiane z katalogu głównego repozytorium próbek LiteRT.
cd /path/to/litert-samples
./configure
Gdy pojawi się odpowiedni komunikat:
- Zaakceptuj domyślne ścieżki do Pythona i biblioteki Pythona.
- Odpowiedz N na pytanie o obsługę ROCm i CUDA.
- Jako kompilator wybierz clang (testowany w wersji 18.1.3).
- Zaakceptuj domyślne flagi optymalizacji.
- Odpowiedz Y, aby skonfigurować WORKSPACE na potrzeby kompilacji Androida.
- Ustaw minimalny poziom Android NDK na co najmniej 26.
- Podaj ścieżkę do pakietu Android SDK.
- Ustaw domyślny poziom interfejsu Android SDK API (36) i narzędzia do kompilacji na 36.0.0.
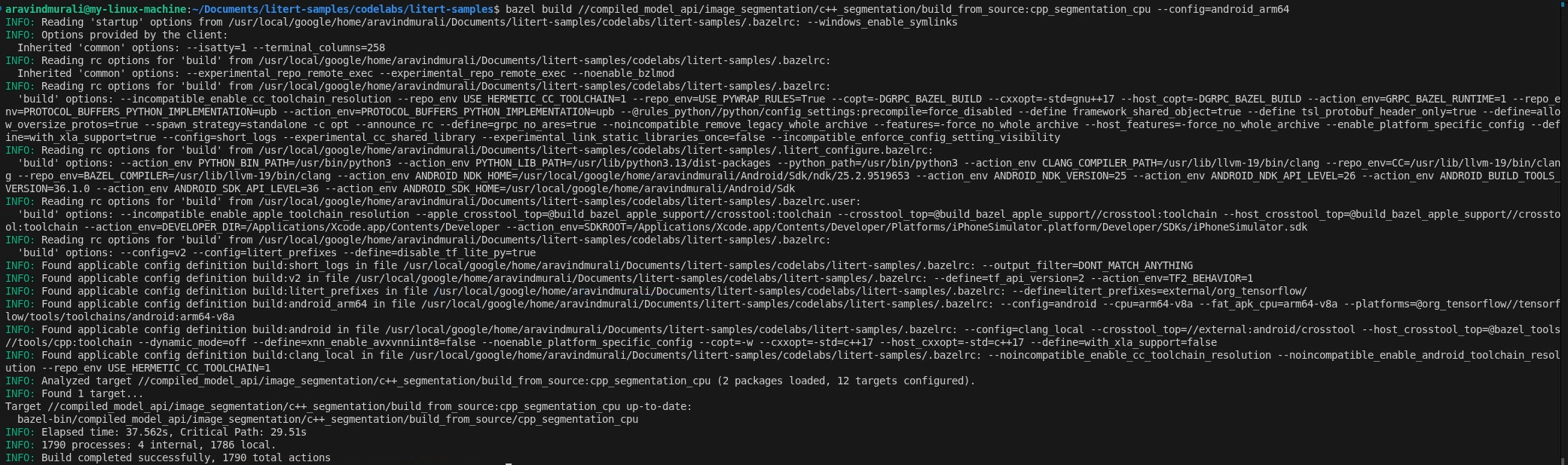
Krok 2. Skompiluj środowiska docelowe procesora i procesora graficznego
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Krok 3. Utwórz element docelowy NPU
Qualcomm HTP
- Pobierz pakiet QAIRT SDK w wersji 2.41 lub nowszej i go rozpakuj.
- Sprawdź, czy wyodrębniona zawartość pakietu SDK znajduje się w podkatalogu o nazwie
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Build, przekazując ścieżkę elementu nadrzędnego kończącą się znakiem
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Flaga --nocheck_visibility jest wymagana, ponieważ niektóre cele LiteRT wyższego poziomu mają domyślnie ograniczoną widoczność.
MediaTek APU
Nie potrzeba żadnego dodatkowego pakietu SDK. Środowisko wykonawcze NeuroPilot to biblioteka systemowa na urządzeniach z Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
Plik BUILD
Otwórz pokój build_from_source/BUILD. Definiuje 4 elementy docelowe – po jednym na każdy akcelerator oraz dedykowany element docelowy NPU MediaTek – z których każdy zależy od udostępnionych elementów docelowych biblioteki image_processor, image_utils i timing_utils:cc_binary
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
Cel GPU dodaje libLiteRtClGlAccelerator.so jako zależność danych, więc Bazel uwzględnia go w plikach wykonywalnych. Cele NPU dodają pliki wysyłki dostawcy i wtyczki kompilatora.so jako zależności danych.
8. Przetwarzanie wstępne z akceleracją przez GPU za pomocą shaderów obliczeniowych
Wszystkie 3 punkty wejścia korzystają z tej samej ścieżki cieniowania obliczeniowego OpenGL ES do przetwarzania wstępnego. Zrozumienie tego jest kluczowe, aby dowiedzieć się, dlaczego ścieżka GPU jest znacznie szybsza niż ścieżka CPU.
Konfigurowanie kontekstu EGL bez interfejsu graficznego
ImageProcessor::InitializeGL() tworzy kontekst EGL bez interfejsu graficznego – kontekst OpenGL bez dołączonego okna lub wyświetlacza. Jest to standardowa praktyka w przypadku obliczeń na GPU poza ekranem na Androidzie. Następnie kompiluje 5 programów cieniowania obliczeniowego GLSL z dysku:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Prześlij obraz wejściowy do procesora graficznego.
Obraz JPEG jest dekodowany do pamięci procesora przez ImageUtils::LoadImage() (za pomocą biblioteki STB), a następnie przesyłany do tekstury GPU:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
Od tego momentu oryginalny obraz jest przechowywany w pamięci GPU jako tekstura OpenGL.
Wstępny shader obliczeniowy
shaders/preprocess_compute.glsl wysyła grupy wątków 8 × 8 na siatkę wyjściową 256 × 256. Każdy wątek obsługuje jeden piksel wyjściowy: próbkuje teksturę wejściową za pomocą filtrowania dwuliniowego (bezpłatne skalowanie sprzętowe), konwertuje wartość RGB [0, 1] na [-1, 1] i zapisuje ją w wyjściowym SSBO:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
W przypadku standardowej ścieżki (bez kopiowania zerowego) ten SSBO jest następnie odczytywany z powrotem do procesora i zapisywany w tensorze LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Wnioskowanie na procesorze
Otwórz pokój main_cpu.cc. Konfiguracja LiteRT składa się z 3 wierszy:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Po wstępnym przetworzeniu wnioskowanie jest pojedynczym wywołaniem synchronicznym:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() blokuje do momentu zakończenia wnioskowania. Model selfie_multiclass_256x256.tflite zmiennoprzecinkowy działa na rdzeniach ARM Cortex i zwykle zajmuje ok. 116–128 ms na urządzeniu ze średniej półki.
Użycie pliku binarnego:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Wnioskowanie na GPU (OpenCL)
Otwórz pokój main_gpu.cc. Ścieżka GPU wprowadza 2 koncepcje, które nie występują na ścieżce CPU: litert::Options do konfigurowania akceleratora GPU (z backendem OpenCL) i wykonywanie asynchroniczne.
Konfigurowanie opcji GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Wnioskowanie asynchroniczne
Ścieżka GPU używa RunAsync() zamiast Run(). Ta funkcja przesyła zadanie do kolejki poleceń GPU i natychmiast zwraca wynik. Następnie przed odczytaniem wyników musisz przeprowadzić synchronizację:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Ta nieblokująca architektura umożliwia nakładanie się pracy procesora i wykonywania zadań przez procesor graficzny w potoku w czasie rzeczywistym.
Użycie pliku binarnego:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Przetwarzanie końcowe – usuwanie przeplotu i mieszanie
Po zakończeniu działania funkcji Run() lub RunAsync() funkcja output_buffers[0] zawiera płaską tablicę liczb zmiennoprzecinkowych o kształcie [256 × 256 × 6] w kolejności przeplatanej. 6 wyników klas dla piksela (row, col) znajduje się w indeksach od (row * 256 + col) * 6 do (row * 256 + col) * 6 + 5.
Rozdzielanie na 6 buforów SSBO z maskami
Pomocniczy procesor CPU dzieli przeplataną tablicę na 6 pojedynczych tablic zmiennoprzecinkowych jednokanałowych i przesyła każdą z nich do własnego bufora SSBO na GPU:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Nakładanie masek z mieszaniem kolorów na oryginalny obraz
processor.ApplyColoredMasks() uruchamia cieniowanie mask_blend_compute.glsl. Dla każdego piksela wyjściowego znajduje klasę o najwyższym wyniku (argmax w 6 buforach SSBO maski) i nakłada odpowiedni kolor na piksel oryginalnego obrazu. 6 kolorów jest zdefiniowanych w każdym punkcie wejścia:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
Wartość alfa 0.1f sprawia, że odcień jest subtelny, a oryginalny obraz pozostaje widoczny.
Zapisywanie danych wyjściowych
Ostateczny mieszany bufor SSBO z wartościami RGBA w formacie zmiennoprzecinkowym jest odczytywany, ograniczany do zakresu [0, 1], konwertowany do formatu unsigned char i zapisywany jako plik PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Wdrażanie i uruchamianie na urządzeniu
Podłącz urządzenie z Androidem za pomocą USB i sprawdź łączność ADB:
adb devices

Używaj funkcji deploy_and_run_on_android.sh
Każdy wariant ma własny skrypt wdrażania. Wariant CMake wskazuje katalog build/, a wariant Bazel – katalog bazel-bin/. Oba skrypty:
- Utwórz
/data/local/tmp/cpp_segmentation_android/na urządzeniu. - Prześlij pliki binarne, shadery GLSL, model, obraz testowy i pliki środowiska wykonawczego
.so. - Przeprowadź wnioskowanie za pomocą
adb shell. - Cofnij
output_segmented.pngdo urządzenia.
Wariant CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Wariant Bazel (build_from_source/)
Uruchom te polecenia w głównym katalogu repozytorium próbek LiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
Flaga --phone określa, które biblioteki modeli i dostawców są używane na danym urządzeniu. Obsługiwane wartości: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) i pixel11 (Tensor G6).
Czas wnioskowania
Po wnioskowaniu PrintTiming() drukuje pełne zestawienie profilowania:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Wydajność referencyjna na telefonie Samsung S25 Ultra (Snapdragon 8 Elite):
Akcelerator | Typ wykonania | Wnioskowanie | E2E |
CPU | Synchronizacja | ~116–128 ms | ~157 ms |
GPU (OpenCL) | Dane asynchroniczne | ~0,95 ms | ~35–43 ms |
13. Zaawansowane (opcjonalnie): wnioskowanie na NPU
Aby zapewnić maksymalną wydajność, LiteRT obsługuje akcelerację NPU za pomocą bibliotek wtyczek specyficznych dla dostawcy. Ścieżka NPU może osiągnąć opóźnienie od początku do końca na poziomie zaledwie 9 ms.
Obsługiwane urządzenia i tryby
Chip | Przykład urządzenia | Tryb | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 ms |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 ms |
Qualcomm (dowolny) | – | JIT | ~28 ms |
MediaTek Dimensity 9400 | – | JIT | ~9 ms |
Google Tensor G3–G6 | Pixel 8–11 | AOT/JIT | W zależności od usługi |
AOT (Ahead-of-Time) korzysta z wstępnie skompilowanego modelu specyficznego dla urządzenia (np. selfie_multiclass_256x256_SM8650.tflite). Jest to najszybsza opcja, ale jest ona zależna od układu.
JIT (Just-in-Time) używa standardowego selfie_multiclass_256x256.tflite i kompiluje do NPU w czasie działania – wolniejsze pierwsze uruchomienie, niezależne od układu.
Dodatkowe wymagania wstępne
Qualcomm HTP:
- Pakiet SDK QAIRT w wersji 2.41 lub nowszej (zawiera pliki
libQnnHtp.so, stub lub skel.so). libLiteRtDispatch_Qualcomm.soz wersji bibliotek środowiska wykonawczego LiteRT NPU w GitHubie.
MediaTek APU:
libLiteRtDispatch_MediaTek.soz wersji bibliotek środowiska wykonawczego LiteRT NPU.- Środowisko wykonawcze NeuroPilot (jest już biblioteką systemową na urządzeniach z Dimensity 9400 – nie trzeba niczego wdrażać).
Google Tensor:
libLiteRtDispatch_GoogleTensor.soz wersji bibliotek środowiska wykonawczego LiteRT NPU.
Środowisko i opcje NPU
main_npu.cc wskazuje Environment w katalogu biblioteki wysyłania dostawcy na urządzeniu, a następnie ustawia opcje skuteczności dostawcy:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
W przypadku MediaTek zastąp blok GetQualcommOptions():
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Wdrażanie na potrzeby NPU
Wariant CMake – Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Wariant CMake – MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Wariant Bazel – Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Wariant Bazel – MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Wariant Bazel – Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
W przypadku wariantu Bazel biblioteki pakietu QAIRT SDK są automatycznie pobierane z drzewa bazel-bin plików wykonywalnych, gdy podczas kompilacji ustawiona jest wartość LITERT_QAIRT_SDK. Wariant CMake wymaga, aby flaga --host_npu_lib wskazywała wyodrębniony pakiet QAIRT SDK.
14. Gratulacje!
Udało Ci się skompilować i uruchomić potok segmentacji obrazów w C++ na Androidzie za pomocą LiteRT. Wiesz już, jak:
- Kompiluj krzyżowo plik binarny C++ na Androida
arm64-v8aza pomocą CMake + NDK lub Bazel. - Używaj interfejsu LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) do wydajnego wnioskowania na urządzeniu. - Wstępnie przetwarzaj dane obrazu na procesorze graficznym za pomocą shaderów obliczeniowych OpenGL ES 3.1.
- Uruchamiaj synchroniczne wnioskowanie na procesorze i asynchroniczne wnioskowanie na GPU (OpenCL).
- Skonfiguruj akcelerację NPU na urządzeniach Qualcomm, MediaTek i Google Tensor.
- Wdrażanie i uruchamianie pliku binarnego C++ na Androidzie za pomocą ADB.
Następne kroki
- Zastąpienie modelu TFLite innym modelem (np. do szacowania głębi lub wykrywania pozycji).
- Zintegruj potok C++ z aplikacją Android NDK za pomocą JNI.
- Profilowanie wykorzystania pamięci za pomocą narzędzia Android GPU Inspector wraz z danymi o czasie.
- Aby jeszcze bardziej zmniejszyć opóźnienie wnioskowania na NPU, zapoznaj się z kwantyzacją modelu.