
1. 시작하기 전에
코드를 입력하는 것은 근육 기억을 만들고 자료에 대한 이해를 심화하는 좋은 방법입니다. 복사하여 붙여넣기는 시간을 절약할 수 있지만, 이 방법을 활용하면 장기적으로 효율성을 높이고 코딩 기술을 강화할 수 있습니다.
이 Codelab에서는 Google의 고성능 온디바이스 런타임인 LiteRT를 사용하여 Android 기기에서 직접 실행되는 C++ 이미지 분할 바이너리를 빌드하는 방법을 알아봅니다. 이 Codelab에서는 Kotlin이나 Android 스튜디오를 사용하는 대신 C++ 바이너리를 빌드하는 데 중점을 둡니다. CMake 또는 Bazel로 교차 컴파일하고 ADB를 사용하여 배포합니다. 동일한 LiteRT C++ API는 모든 플랫폼 (Android, Linux, 임베디드)에서 작동하므로 성능이 중요한 애플리케이션, 로봇 공학, 에지 시스템에 유용한 기반이 됩니다.
전체 파이프라인을 살펴봅니다.
- 빌드 환경 설정 (CMake + Android NDK 또는 Bazel)
- 사전 빌드된 출시 또는 소스에서 LiteRT C++ SDK 연결
- GPU 가속 이미지 사전 처리 및 사후 처리에 OpenGL ES 컴퓨팅 셰이더 사용
- LiteRT C++ API로
selfie_multiclass분할 모델 실행 - CPU, GPU (OpenCL), NPU (Qualcomm / MediaTek)에서 추론을 가속화합니다.
- 원시 모델 출력을 색상 혼합 세분화 이미지로 후처리합니다.
- ADB를 사용하여 실제 Android 기기에 배포하고 결과를 가져옵니다.
결과적으로 다음 이미지와 유사한 결과물이 생성됩니다. 전체 파이프라인을 통해 처리된 정적 이미지로, 6개의 분할 클래스가 각각 고유한 색상으로 오버레이됩니다.

기본 요건
이 Codelab은 C++에 익숙하며 C++ 레이어에서 Android에서 머신러닝 모델을 실행하는 경험을 쌓고 싶은 개발자를 위해 설계되었습니다. 다음을 잘 알고 있어야 합니다.
- C++ 기본사항 (포인터, 벡터, 포함)
- 기본 Android/ADB 개념 (
adb push,adb shell) - Linux 또는 macOS에서 터미널 및 셸 스크립트 사용
학습할 내용
- CMake + NDK 또는 Bazel을 사용하여 Android
arm64-v8a용 C++ 바이너리를 교차 컴파일하는 방법 - 효율적인 온디바이스 추론을 위해 LiteRT C++ API (
Environment,CompiledModel,TensorBuffer)를 사용하는 방법 - OpenGL ES 3.1 컴퓨팅 셰이더가 GPU에서 전처리 및 후처리를 완전히 가속화하는 방법
- CPU, GPU (OpenCL), NPU (Qualcomm HTP, MediaTek APU, Google Tensor) 가속을 위해 LiteRT를 구성하는 방법
- 동기 (
Run) 추론과 비동기 (RunAsync) 추론의 차이점 - ADB를 사용하여 Android에 C++ 바이너리를 배포하고 실행하는 방법
필요한 항목
- Linux 또는 macOS 머신 (Windows 사용자는 WSL2 사용)
- Android NDK r25c 이상 (다운로드)
- CMake 경로: CMake ≥ 3.22 (
sudo apt-get install cmake) - Bazel 경로: Bazel이 설치되어 있고 전체 LiteRT 샘플 저장소가 있습니다.
PATH(Android 플랫폼 도구)의 ADB- 실제 Android 기기 - Galaxy S24/S25 또는 Pixel에서 테스트하는 것이 가장 좋습니다.
2. 이미지 분할
이미지 분할은 이미지의 모든 픽셀에 클래스 라벨을 할당하는 컴퓨터 비전 작업입니다. 경계 상자를 그리는 객체 감지와 달리 세그멘테이션은 각 객체의 시작과 끝을 정확한 픽셀 단위로 이해합니다.
이 Codelab에서는 각 픽셀을 다음 6개 클래스 중 하나로 분류하는 selfie_multiclass_256x256 모델을 사용합니다.
클래스 색인 | 세그먼트 |
0 | 배경 |
1 | 헤어 |
2 | 신체 피부 |
3 | 얼굴 피부 |
4 | 옷 |
5 | 액세서리 (안경, 주얼리 등) |
모델은 [1, 256, 256, 6] 모양의 부동 소수점 텐서를 출력합니다. 256×256 픽셀 각각에 클래스당 하나씩 6개의 신뢰도 점수가 있습니다. 점수가 가장 높은 클래스가 해당 픽셀을 획득합니다 (argmax).
LiteRT: 에지에서의 성능
LiteRT는 TFLite 모델을 위한 Google의 차세대 고성능 런타임입니다. C++ API를 사용하면 다음 세 가지 모두에서 일관된 인터페이스로 오버헤드가 적은 하드웨어 가속기에 직접 액세스할 수 있습니다.
- CPU - 범용 호환성, 중급 기기에서 추론 시간은 약 128ms입니다.
- GPU (OpenCL) - 추론 ~1ms, 버퍼 전략에 따라 엔드 투 엔드 ~17~43ms
- NPU: Qualcomm Snapdragon, MediaTek Dimensity 9400, Google Tensor 기기에서 AOT와 비교하여 엔드 투 엔드 ~9~28ms JIT 컴파일
핵심 추상화는 CompiledModel입니다. 모델은 로드 시 타겟 하드웨어에 맞게 사전 컴파일되고 최적화되어 추론이 미리 할당된 버퍼에 대한 Run() 호출로 줄어듭니다.
3. 설정
저장소 복제
git clone https://github.com/google-ai-edge/litert-samples.git
이 Codelab의 모든 리소스는 다음 위치에 있습니다.
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
이 디렉터리에는 동일한 샘플의 완전한 빌드인 하위 프로젝트가 두 개 있습니다.
디렉터리 | 빌드 시스템 | LiteRT 종속 항목 |
| CMake + Android NDK | 사전 빌드 |
| Bazel | 소스에서 LiteRT를 컴파일합니다. |
한 가지 길을 선택하고 그 길을 따르세요. 코드는 두 디렉터리 간에 동일하며 빌드 시스템과 종속 항목 전략만 다릅니다. 가장 빠른 설정을 원한다면 use_prebuilt_litert/을 선택하세요. LiteRT 자체를 수정하거나 기존 Bazel 모노레포 내에서 작업해야 하는 경우 build_from_source/를 사용하세요.
파일 경로 참고사항
이 가이드의 모든 파일 경로는 Linux/macOS 형식을 사용합니다. Windows 사용자는 WSL2를 사용해야 합니다.
디렉터리 개요
두 하위 프로젝트는 동일한 소스 레이아웃을 공유합니다.
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
추가 조치:
use_prebuilt_litert/님이CMakeLists.txt님,build_prebuilt.sh님,deploy_and_run_on_android.sh님,third_party/stb/님을 추가합니다.build_from_source/는 BazelBUILD파일을 추가하고bazel-bin/을 가리키는deploy_and_run_on_android.sh를 사용합니다.
4. 프로젝트 구조 이해
진입점 3개, 파이프라인 1개
main_cpu.cc, main_gpu.cc, main_npu.cc에는 전체 세분화 파이프라인을 실행하는 main() 함수가 각각 포함되어 있습니다. 파이프라인은 세 가지 모두에서 동일합니다. LiteRT 액셀러레이터 구성과 버퍼 전략만 다릅니다.
파일 | 가속기 | 버퍼 전략 |
|
| CPU 메모리 |
|
| OpenCL 백엔드를 사용하는 CPU 메모리 |
|
| CPU 대체가 있는 CPU 메모리 |
세 가지 모두 동일한 ImageProcessor (전처리 및 후처리를 위한 OpenGL ES 컴퓨팅 셰이더) 및 ImageUtils (STB 이미지 I/O) 유틸리티를 공유합니다.
전체 파이프라인
모든 진입점은 동일한 5단계 구조를 따릅니다.
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- 로드 -
ImageUtils::LoadImage()는 STB 이미지 라이브러리를 사용하여 JPEG를 CPU 메모리로 디코딩합니다. - 업로드 -
processor.CreateOpenGLTexture()는 원시 픽셀을 GPU 텍스처 (OpenGL RGBA8)에 업로드합니다. - 전처리 -
processor.PreprocessInputForSegmentation()는 텍스처 크기를 256x256으로 조절하고 픽셀 값을[0, 1]에서[-1, 1]로 정규화하는 GLSL 컴퓨팅 셰이더를 실행합니다. 결과는 GPU SSBO에 저장됩니다. - 추론 - SSBO 데이터가 LiteRT
TensorBuffer에 기록되고compiled_model.Run()(또는RunAsync())가 모델을 실행합니다. - 후처리 - 모델의 6채널 부동 소수점 출력이 6개의 단일 채널 마스크 SSBO로 디인터리브된 후 원래 이미지에 다시 색상 혼합됩니다.
- 저장 -
ImageUtils::SaveImage()는 최종 RGBA 이미지를 PNG로 작성합니다.
5. 핵심 LiteRT C++ API
빌드하기 전에 모든 진입점에서 사용되는 세 가지 주요 LiteRT C++ 유형을 숙지하세요. 모두 litert:: 네임스페이스에 있습니다.
litert::Environment
Environment는 모든 LiteRT 작업의 루트 컨텍스트입니다. 한 번 만들어 CompiledModel::Create에 전달합니다. NPU 사용의 경우 공급업체 플러그인 라이브러리 디렉터리로 구성합니다.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel는 생성 시간에 요청된 하드웨어에 맞게 TFLite 모델을 로드하고 사전 컴파일합니다. 그러면 추론이 버퍼를 채우고 Run()를 호출하는 것으로 줄어듭니다.
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
텐서 버퍼는 입력/출력 데이터를 보유합니다. 항상 CompiledModel에서 만들어야 대상 하드웨어에 맞게 크기가 조정되고 정렬됩니다.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
오류 처리 매크로
Macro | 동작 |
| 실패 시 |
| 표현식에서 오류가 반환되면 |
| 호출자에게 오류를 할당하거나 전파합니다. |
6. 빌드 - 옵션 A: 사전 빌드된 LiteRT C++ SDK (CMake)
LiteRT 자체를 수정할 필요가 없는 경우 이 경로를 사용하는 것이 좋습니다. 빌드 스크립트는 SDK 헤더 다운로드, .so 복사, STB 가져오기, 단일 명령어에서 CMake + NDK 호출을 처리합니다.
1단계: Maven에서 libLiteRt.so 가져오기
LiteRT는 Google Maven의 Android AAR 내에서 런타임을 공유 라이브러리로 제공합니다. 다운로드하고 arm64-v8a .so를 추출합니다.
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
GPU 지원의 경우 OpenCL/GL 가속기도 추출합니다.
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

2단계: build_prebuilt.sh 실행
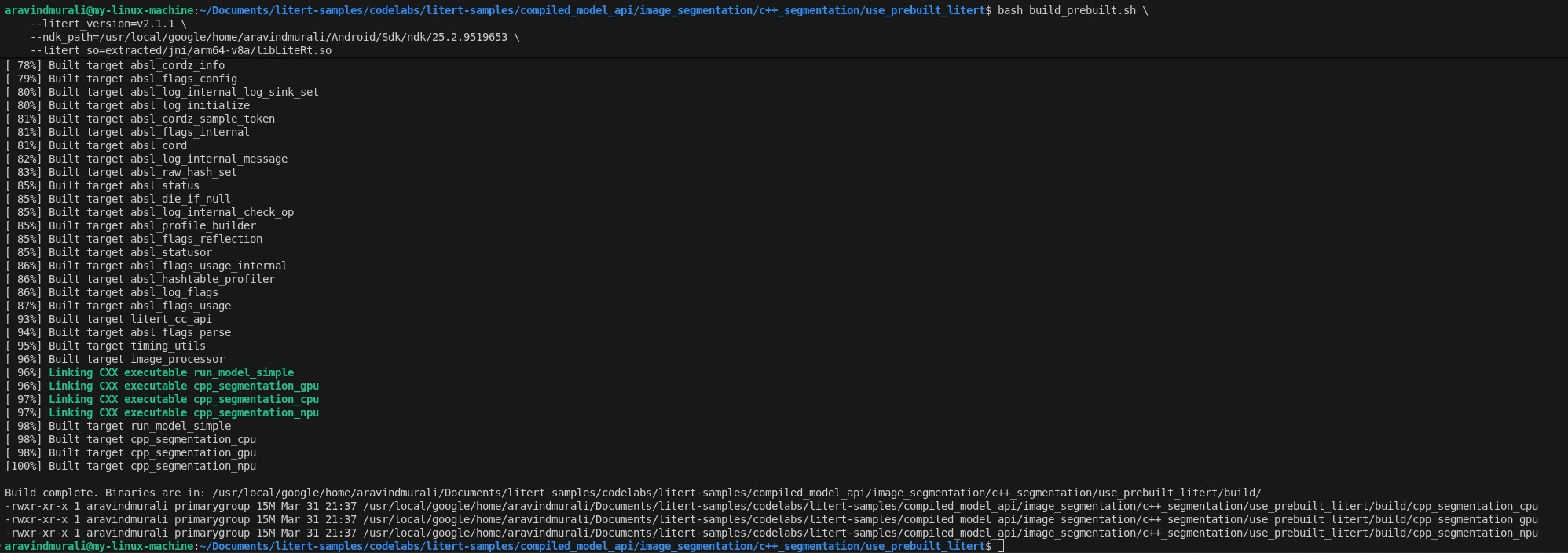
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
스크립트는 다음을 수행합니다.
- LiteRT GitHub 출시에서
litert_cc_sdk.zip(SDK 헤더 + cmake 파일)를 다운로드합니다. 이미 있는 경우 후속 실행에서 건너뜁니다. libLiteRt.so를litert_cc_sdk/에 복사합니다.- STB 이미지 헤더를
third_party/stb/에 다운로드합니다. 있는 경우 건너뜁니다. android-26에서arm64-v8a용 Android NDK 도구 모음을 사용하여 CMake로 구성하고 빌드합니다.
성공하면 build/에 다음 세 개의 바이너리가 표시됩니다.
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
CMakeLists.txt의 역할
CMakeLists.txt를 엽니다. C++20이 필요하고 add_subdirectory를 통해 LiteRT SDK를 가져오고 OpenGL ES 3 (GLESv3) 및 EGL을 연결한 다음 도우미 매크로를 사용하여 main_*.cc 소스에서 각 바이너리를 만듭니다.
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. 빌드 - 옵션 B: Bazel로 빌드 (소스에서)
소스에서 LiteRT 런타임을 컴파일하는 빌드 시스템으로 Bazel을 선호하거나 기존 Bazel 작업공간 내에서 작업해야 하는 경우 이 경로를 선택하세요.
기본 요건
'시작하기 전에' 섹션에 나열된 NDK 및 ADB 외에 다음이 필요합니다.
- Bazel이 설치되어 있고
PATH에 있어야 합니다. - LiteRT 샘플 소스 저장소의 전체 클론입니다.
1단계: LiteRT 샘플 작업공간 구성
모든 명령어는 LiteRT 샘플 저장소의 루트에서 실행됩니다.
cd /path/to/litert-samples
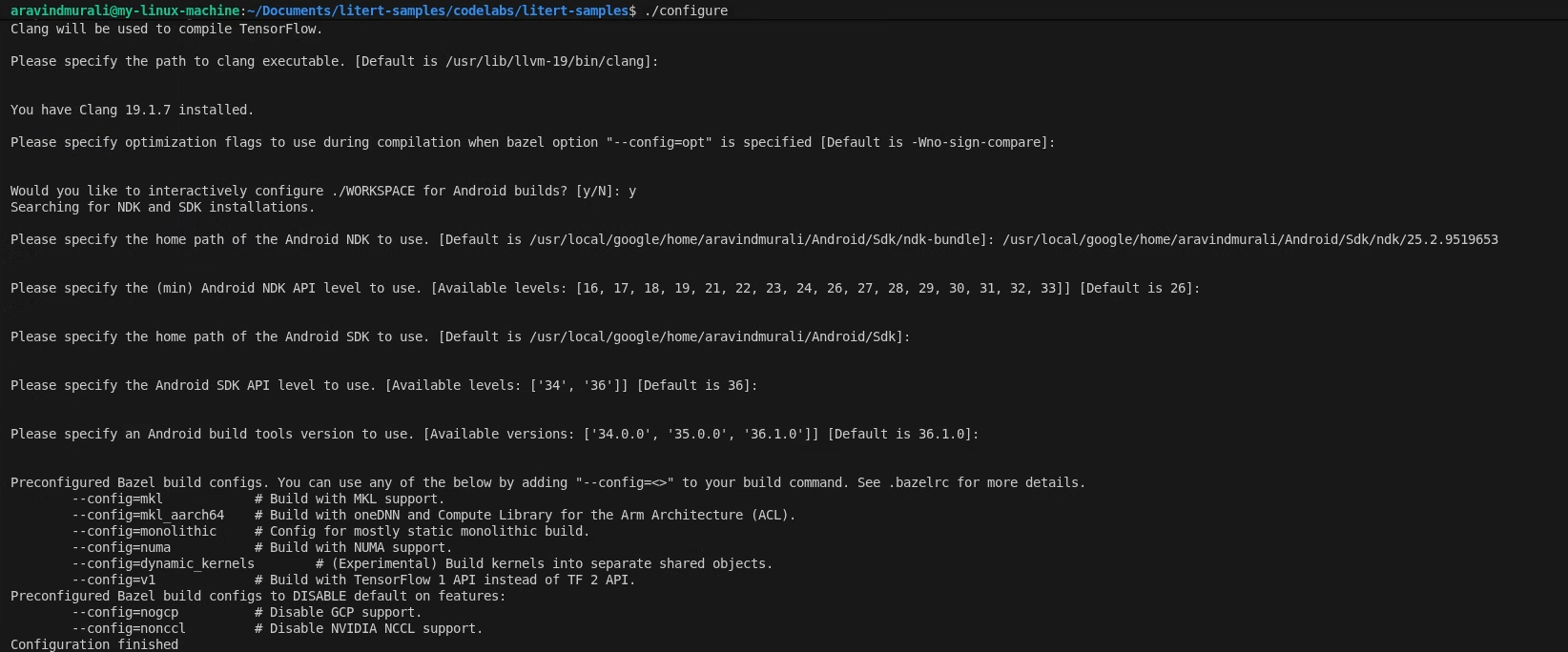
./configure
메시지가 표시되면 다음을 수행합니다.
- Python 및 Python lib 경로의 기본값을 수락합니다.
- ROCm 및 CUDA 지원에 N으로 대답합니다.
- 컴파일러로 clang (18.1.3으로 테스트됨)을 선택합니다.
- 기본 최적화 플래그를 수락합니다.
- Y를 입력하여 Android 빌드의 WORKSPACE를 구성합니다.
- 최소 Android NDK 수준을 26 이상으로 설정합니다.
- Android SDK 경로를 제공합니다.
- Android SDK API 수준을 기본값 (36)으로 설정하고 빌드 도구를 36.0.0으로 설정합니다.
2단계: CPU 및 GPU 타겟 빌드
# CPU
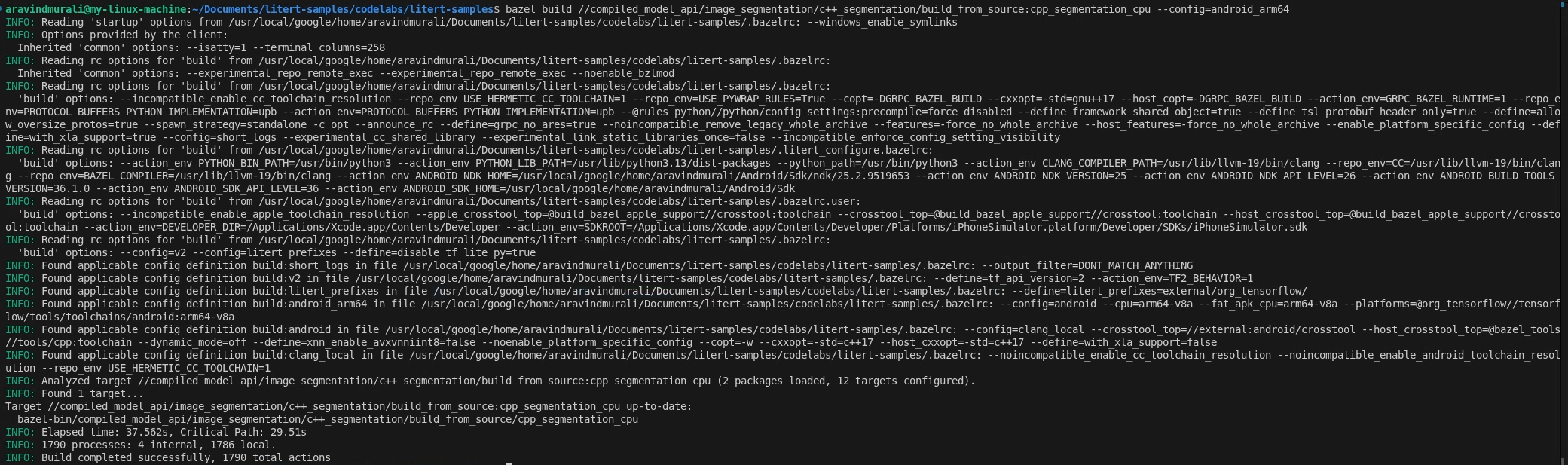
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
3단계: NPU 타겟 빌드
Qualcomm HTP
- QAIRT SDK v2.41 이상을 다운로드하고 추출합니다.
- 추출된 SDK 콘텐츠가
latest/라는 하위 디렉터리 내에 있는지 확인합니다./path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... /로 끝나는 상위 경로를 전달하여 빌드합니다.bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
일부 업스트림 LiteRT 타겟에는 제한된 공개 상태 기본값이 있으므로 --nocheck_visibility 플래그가 필요합니다.
MediaTek APU
추가 SDK는 필요하지 않습니다. NeuroPilot 런타임은 Dimensity 9400 기기의 시스템 라이브러리입니다.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
BUILD 파일
build_from_source/BUILD를 엽니다. 액셀러레이터당 하나씩, 전용 MediaTek NPU 타겟을 포함한 4개의 cc_binary 타겟을 정의합니다. 각 타겟은 공유 image_processor, image_utils, timing_utils 라이브러리 타겟에 종속됩니다.
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
GPU 타겟은 libLiteRtClGlAccelerator.so를 데이터 종속 항목으로 추가하므로 Bazel이 이를 runfile에 포함합니다. NPU 타겟은 공급업체 디스패치 및 컴파일러 플러그인 .so 파일을 데이터 종속 항목으로 추가합니다.
8. 컴퓨트 셰이더를 사용한 GPU 가속 전처리
세 진입점 모두 전처리를 위해 동일한 OpenGL ES 컴퓨팅 셰이더 파이프라인을 사용합니다. 이를 이해하는 것은 GPU 경로가 CPU 경로보다 훨씬 빠른 이유를 이해하는 데 중요합니다.
헤드리스 EGL 컨텍스트 설정
ImageProcessor::InitializeGL()는 헤드리스 EGL 컨텍스트(창이나 디스플레이가 연결되지 않은 OpenGL 컨텍스트)를 만듭니다. 이는 Android의 화면 외 GPU 컴퓨팅의 표준 사례입니다. 그런 다음 디스크에서 5개의 GLSL 컴퓨팅 셰이더 프로그램을 컴파일합니다.
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
입력 이미지를 GPU에 업로드합니다.
JPEG는 ImageUtils::LoadImage()에 의해 CPU 메모리로 디코딩된 후 (STB 라이브러리를 통해) GPU 텍스처에 업로드됩니다.
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
이때부터 원본 이미지는 OpenGL 텍스처로 GPU 메모리에 저장됩니다.
전처리 컴퓨팅 셰이더
shaders/preprocess_compute.glsl는 256×256 출력 그리드에 8×8 스레드 그룹을 디스패치합니다. 각 스레드는 하나의 출력 픽셀을 처리합니다. 스레드는 양선형 필터링 (무료 하드웨어 크기 조절)을 사용하여 입력 텍스처를 샘플링하고, [0, 1] RGB 값을 [-1, 1]로 변환하고, 출력 SSBO에 씁니다.
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
표준 (비 제로 카피) 경로의 경우 이 SSBO는 CPU로 다시 읽어 LiteRT 텐서에 작성됩니다.
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. CPU 추론
main_cpu.cc를 엽니다. LiteRT 설정은 세 줄입니다.
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
전처리 후 추론은 단일 동기 호출입니다.
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run()는 추론이 완료될 때까지 차단됩니다. selfie_multiclass_256x256.tflite 부동 소수점 모델은 ARM Cortex 코어에서 실행되며 일반적으로 중급 기기에서 약 116~128ms가 걸립니다.
바이너리 사용량:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. GPU 추론 (OpenCL)
main_gpu.cc를 엽니다. GPU 경로에는 CPU 경로에는 없는 두 가지 개념이 도입됩니다. GPU 가속기 (OpenCL 백엔드 사용)를 구성하는 litert::Options와 비동기 실행입니다.
GPU 옵션 구성
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
비동기 추론
GPU 경로는 Run() 대신 RunAsync()를 사용합니다. 이렇게 하면 작업을 GPU 명령 대기열에 제출하고 즉시 반환됩니다. 그런 다음 결과를 읽기 전에 동기화합니다.
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
이 비차단 설계는 실시간 파이프라인에서 CPU 작업을 GPU 실행과 중첩할 수 있도록 지원합니다.
바이너리 사용량:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. 후처리 - 디인터리브 및 블렌드
Run() 또는 RunAsync()가 완료되면 output_buffers[0]는 인터리브 순서로 [256 × 256 × 6] 모양의 플랫 부동 소수점 배열을 보유합니다. 픽셀 (row, col)의 6개 클래스 점수는 색인 (row * 256 + col) * 6~(row * 256 + col) * 6 + 5에 있습니다.
6개의 마스크 SSBO로 디인터리브
CPU 도우미는 인터리브된 배열을 6개의 단일 채널 부동 소수점 배열로 분할하고 각 배열을 자체 GPU SSBO에 업로드합니다.
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
원본 이미지에 색상 혼합 마스크
processor.ApplyColoredMasks()은 mask_blend_compute.glsl 셰이더를 실행합니다. 각 출력 픽셀에 대해 점수가 가장 높은 클래스 (6개 마스크 SSBO에서 argmax)를 찾아 원래 이미지 픽셀 위에 해당 색상을 알파 합성합니다. 6가지 색상은 각 진입점에서 다음과 같이 정의됩니다.
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
0.1f의 알파는 색조를 미묘하게 유지하므로 원본 이미지가 계속 표시됩니다.
출력 저장
최종 혼합 RGBA 부동 소수점 SSBO가 다시 읽혀지고 [0, 1]로 고정되고 unsigned char로 변환되고 PNG로 저장됩니다.
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. 기기에 배포 및 실행
USB를 사용하여 Android 기기를 연결하고 ADB 연결을 확인합니다.
adb devices

deploy_and_run_on_android.sh 사용
각 변형에는 자체 배포 스크립트가 있습니다. CMake 변형은 build/ 디렉터리를 가리키고 Bazel 변형은 bazel-bin/을 가리킵니다. 두 스크립트 모두:
- 기기에서
/data/local/tmp/cpp_segmentation_android/를 만듭니다. - 바이너리, GLSL 셰이더, 모델, 테스트 이미지, 런타임
.so파일을 푸시합니다. adb shell를 사용하여 추론을 실행합니다.output_segmented.png를 컴퓨터로 다시 가져옵니다.
CMake 변형 (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Bazel 변형 (build_from_source/)
LiteRT 샘플 저장소 루트에서 다음 명령어를 실행합니다.
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
--phone 플래그는 사용되는 기기별 모델과 공급업체 라이브러리를 제어합니다. 지원되는 값: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5), pixel11 (Tensor G6)
추론 타이밍
추론 후 PrintTiming()는 전체 프로파일링 분석을 출력합니다.
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
삼성 S25 Ultra (Snapdragon 8 Elite)의 참조 성능:
가속기 | 실행 유형 | 추론 | E2E |
CPU | 동기화 | 약 116~128ms | ~157 ms |
GPU (OpenCL) | 비동기식 | ~0.95 ms | 35~43ms |
13. 고급 (선택사항): NPU 추론
최고의 성능을 위해 LiteRT는 공급업체별 플러그인 라이브러리를 사용하여 NPU 가속을 지원합니다. NPU 경로는 엔드 투 엔드 지연 시간을 9ms까지 낮출 수 있습니다.
지원되는 기기 및 모드
칩 | 기기 예 | 모드 | E2E |
Qualcomm SM8650 | 갤럭시 S24 | AOT | ~17 ms |
Qualcomm SM8750 | 갤럭시 S25 | AOT | ~17 ms |
Qualcomm (모두) | — | JIT | ~28 ms |
MediaTek Dimensity 9400 | — | JIT | 약 9ms |
Google Tensor G3~G6 | Pixel 8~11 | AOT/JIT | 경우에 따라 다름 |
AOT (Ahead-of-Time)는 기기별 사전 컴파일된 모델 (예: selfie_multiclass_256x256_SM8650.tflite)을 사용합니다. 이는 가장 빠른 옵션이지만 칩에 따라 다릅니다.
JIT (Just-in-Time)는 표준 selfie_multiclass_256x256.tflite를 사용하고 런타임에 NPU로 컴파일됩니다. 첫 번째 실행이 느리고 칩에 독립적입니다.
추가 기본 요건
Qualcomm HTP:
- QAIRT SDK v2.41 이상 (
libQnnHtp.so, 스텁 또는 스켈.so파일 제공) - GitHub의 LiteRT NPU 런타임 라이브러리 출시에서
libLiteRtDispatch_Qualcomm.so
MediaTek APU:
- LiteRT NPU 런타임 라이브러리에서
libLiteRtDispatch_MediaTek.so를 출시합니다. - NeuroPilot 런타임 (이미 Dimensity 9400 기기의 시스템 라이브러리임. 푸시할 필요 없음)
Google Tensor:
- LiteRT NPU 런타임 라이브러리에서
libLiteRtDispatch_GoogleTensor.so를 출시합니다.
NPU 환경 및 옵션
main_npu.cc는 기기의 공급업체 디스패치 라이브러리 디렉터리에서 Environment를 가리킨 다음 공급업체별 성능 옵션을 설정합니다.
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
MediaTek의 경우 GetQualcommOptions() 블록을 다음으로 바꿉니다.
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
NPU용으로 배포
CMake 변형 — Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
CMake 변형 — MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Bazel 변형 - Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Bazel 변형 - MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Bazel 변형 - Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Bazel 변형의 경우 빌드 시 LITERT_QAIRT_SDK이 설정되면 QAIRT SDK 라이브러리가 bazel-bin runfiles 트리에서 자동으로 선택됩니다. CMake 변형에는 추출된 QAIRT SDK를 가리키는 --host_npu_lib 플래그가 필요합니다.
14. 축하합니다.
LiteRT를 사용하여 Android에서 C++ 이미지 분할 파이프라인을 빌드하고 실행했습니다. 다음과 같은 내용을 배웠습니다.
- CMake + NDK 또는 Bazel을 사용하여 Android
arm64-v8a용 C++ 바이너리를 크로스 컴파일합니다. - 효율적인 온디바이스 추론을 위해 LiteRT C++ API (
Environment,CompiledModel,TensorBuffer)를 사용하세요. - OpenGL ES 3.1 컴퓨팅 셰이더를 사용하여 GPU에서 이미지 데이터를 사전 처리합니다.
- 동기 CPU 추론과 비동기 GPU (OpenCL) 추론을 실행합니다.
- Qualcomm, MediaTek, Google Tensor 기기의 NPU 가속을 구성합니다.
- ADB를 사용하여 Android에 C++ 바이너리 배포 및 실행
다음 단계
- 다른 TFLite 모델 (예: 깊이 추정 또는 포즈 감지)로 바꿉니다.
- JNI를 사용하여 C++ 파이프라인을 Android NDK 앱에 통합합니다.
- 타이밍 출력과 함께 Android GPU 검사기로 메모리 사용량을 프로파일링합니다.
- 모델 양자화를 살펴보고 NPU 추론 지연 시간을 더욱 줄이세요.