
1. 始める前に
コードを入力することは、筋肉の記憶を構築し、教材の理解を深めるのに最適な方法です。コピー&ペーストは時間を節約できますが、この方法に投資することで、長期的には効率が向上し、コーディング スキルが向上します。
この Codelab では、Google の高性能オンデバイス ランタイムである LiteRT を使用して、Android デバイスで直接実行される C++ 画像セグメンテーション バイナリを構築する方法を学びます。この Codelab では、Kotlin や Android Studio ではなく、C++ バイナリのビルドに焦点を当てます。CMake または Bazel でクロス コンパイルし、ADB を使用してデプロイします。同じ LiteRT C++ API があらゆるプラットフォーム(Android、Linux、組み込み)で動作するため、パフォーマンスが重要なアプリケーション、ロボット工学、エッジ システムの有用な基盤となります。
パイプライン全体について説明します。
- ビルド環境(CMake + Android NDK または Bazel)の設定。
- LiteRT C++ SDK をリンクする(事前ビルドされたリリースまたはソースから)。
- GPU アクセラレーションによる画像の前処理と後処理に OpenGL ES コンピューティング シェーダーを使用します。
- LiteRT C++ API を使用して
selfie_multiclassセグメンテーション モデルを実行する。 - CPU、GPU(OpenCL)、NPU(Qualcomm / MediaTek)での推論を高速化。
- 未加工のモデル出力を後処理して、色をブレンドしたセグメンテーション画像にします。
- ADB を使用して Android デバイスにデプロイし、結果を取得する。
最終的に、次の画像のようなものが生成されます。これは、パイプライン全体で処理された静止画像で、6 つのセグメンテーション クラスがそれぞれ異なる色でオーバーレイされています。

前提条件
この Codelab は、C++ に精通しており、C++ レイヤで Android 上で ML モデルを実行する経験を積みたいデベロッパーを対象としています。以下について把握しておく必要があります。
- C++ の基礎(ポインタ、ベクトル、インクルード)。
- Android/ADB の基本コンセプト(
adb push、adb shell)。 - Linux または macOS でターミナルとシェル スクリプトを使用する。
学習内容
- CMake + NDK または Bazel を使用して Android
arm64-v8a用の C++ バイナリをクロス コンパイルする方法。 - 効率的なオンデバイス推論に LiteRT C++ API(
Environment、CompiledModel、TensorBuffer)を使用する方法。 - OpenGL ES 3.1 コンピューティング シェーダーが GPU 上で前処理と後処理を完全に高速化する方法。
- CPU、GPU(OpenCL)、NPU(Qualcomm HTP、MediaTek APU、Google Tensor)の高速化のために LiteRT を設定する方法。
- 同期(
Run)推論と非同期(RunAsync)推論の違い。 - ADB を使用して Android で C++ バイナリをデプロイして実行する方法。
必要なもの
- Linux または macOS マシン(Windows ユーザーは WSL2 を使用する必要があります)。
- Android NDK r25c 以降(ダウンロード)。
- CMake パスの場合: CMake ≥ 3.22(
sudo apt-get install cmake)。 - Bazel のパス: Bazel がインストールされ、LiteRT サンプル リポジトリ全体がインストールされている。
PATH(Android プラットフォーム ツール)の ADB。- 物理的な Android デバイス - Galaxy S24/S25 または Google Pixel でテストするのが最適です。
2. 画像セグメンテーション
画像セグメンテーションは、画像のすべてのピクセルにクラスラベルを割り当てるコンピュータ ビジョン タスクです。境界ボックスを描画するオブジェクト検出とは異なり、セグメンテーションでは、各オブジェクトの開始位置と終了位置を正確に把握できます。
この Codelab では、各ピクセルを 6 つのクラスのいずれかに分類する selfie_multiclass_256x256 モデルを使用します。
クラス インデックス | セグメント |
0 | 背景 |
1 | ヘアカット |
2 | 体の皮膚 |
3 | 顔の肌 |
4 | 服 |
5 | アクセサリー(メガネ、ジュエリーなど) |
モデルは、形状 [1, 256, 256, 6] の浮動小数点テンソルを出力します。256×256 ピクセルごとに、6 つの信頼スコア(クラスごとに 1 つ)があります。スコアが最も高いクラスがそのピクセルを獲得します(argmax)。
LiteRT: エッジでのパフォーマンス
LiteRT は、TFLite モデル用の Google の次世代高性能ランタイムです。C++ API を使用すると、3 つすべてで一貫したインターフェースを使用して、ハードウェア アクセラレータに直接アクセスできます。
- CPU - 汎用的に互換性があり、ミドルレンジ デバイスで約 128 ミリ秒の推論。
- GPU(OpenCL) - 推論に約 1 ミリ秒、バッファ戦略に応じてエンドツーエンドに約 17 ~ 43 ミリ秒。
- NPU - Qualcomm Snapdragon、MediaTek Dimensity 9400、Google Tensor デバイスで AOT との比較に応じて 9 ~ 28 ミリ秒のエンドツーエンド。JIT コンパイル。
主な抽象化は CompiledModel です。モデルは読み込み時にターゲット ハードウェア用に事前コンパイルされ、最適化されます。これにより、推論は事前割り当てされたバッファに対する Run() 呼び出しに削減されます。
3. セットアップする
リポジトリのクローンを作成する
git clone https://github.com/google-ai-edge/litert-samples.git
この Codelab のリソースはすべて次の場所にあります。
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
このディレクトリには 2 つのサブプロジェクトがあり、それぞれが同じサンプルの完全なビルドです。
ディレクトリ | ビルドシステム | LiteRT の依存関係 |
| CMake + Android NDK | 事前構築済みの |
| Bazel | ソースから LiteRT をコンパイルする |
いずれかのパスを選択して、それに沿って操作します。コードは 2 つのディレクトリ間で同一です。ビルドシステムと依存関係戦略のみが異なります。セットアップを最も速く行うには、use_prebuilt_litert/ を選択します。LiteRT 自体を変更する必要がある場合や、既存の Bazel モノレポ内で作業する場合は、build_from_source/ を使用します。
ファイルパスに関する注意事項
このチュートリアルのファイルパスはすべて Linux/macOS 形式です。Windows ユーザーは WSL2 を使用する必要があります。
ディレクトリの概要
両方のサブプロジェクトは同じソース レイアウトを共有します。
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
また、次の方法もあります。
use_prebuilt_litert/がCMakeLists.txt、build_prebuilt.sh、deploy_and_run_on_android.sh、third_party/stb/を追加します。build_from_source/は BazelBUILDファイルを追加し、bazel-bin/を指すdeploy_and_run_on_android.shを使用します。
4. プロジェクトの構造を理解する
3 つのエントリ ポイント、1 つのパイプライン
main_cpu.cc、main_gpu.cc、main_npu.cc にはそれぞれ、完全なセグメンテーション パイプラインを駆動する main() 関数が含まれています。パイプラインは 3 つすべてで同じです。LiteRT アクセラレータの構成とバッファ戦略のみが異なります。
ファイル | アクセラレータ | バッファ戦略 |
|
| CPU メモリ |
|
| OpenCL バックエンドの CPU メモリ |
|
| CPU フォールバック付きの CPU メモリ |
3 つすべてが同じ ImageProcessor(プリプロセスとポストプロセスのための OpenGL ES コンピューティング シェーダー)と ImageUtils(STB 画像 I/O)ユーティリティを共有します。
完全なパイプライン
すべてのエントリ ポイントは、同じ 5 フェーズの構造に従います。
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- 読み込み -
ImageUtils::LoadImage()は、STB 画像ライブラリを使用して JPEG を CPU メモリにデコードします。 - アップロード -
processor.CreateOpenGLTexture()は、未加工のピクセルを GPU テクスチャ(OpenGL RGBA8)にアップロードします。 - 前処理 -
processor.PreprocessInputForSegmentation()は、テクスチャのサイズを 256×256 に変更し、ピクセル値を[0, 1]から[-1, 1]に正規化する GLSL コンピューティング シェーダーを実行します。結果は GPU SSBO に格納されます。 - 推論 - SSBO データが LiteRT
TensorBufferに書き込まれ、compiled_model.Run()(またはRunAsync())がモデルを実行します。 - 後処理 - モデルの 6 チャンネルの浮動小数点出力が 6 つの単一チャンネル マスク SSBO にデインターリーブされ、元の画像にカラーブレンドされます。
- 保存 -
ImageUtils::SaveImage()は最終的な RGBA 画像を PNG として書き込みます。
5. Core LiteRT C++ API
ビルドする前に、すべてのエントリ ポイントで使用される 3 つの主要な LiteRT C++ 型を理解しておいてください。すべて litert:: Namespace に存在します。
litert::Environment
Environment は、すべての LiteRT オペレーションのルート コンテキストです。一度作成して CompiledModel::Create に渡します。NPU の使用については、ベンダー プラグイン ライブラリ ディレクトリで構成します。
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel は、構築時にリクエストされたハードウェア用に TFLite モデルを読み込んで事前コンパイルします。推論は、バッファの入力と Run() の呼び出しに縮小されます。
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
テンソル バッファは入出力データを保持します。常に CompiledModel から作成して、ターゲット ハードウェアに合わせてサイズと配置が正しくなるようにします。
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
エラー処理マクロ
マクロ | 動作 |
| 失敗時に |
| 式がエラーを返した場合は |
| エラーを呼び出し元に割り当てるか、伝播します。 |
6. ビルド - オプション A: 事前ビルドされた LiteRT C++ SDK(CMake)
LiteRT 自体を変更する必要がない場合は、このパスをおすすめします。ビルド スクリプトは、SDK ヘッダーのダウンロード、.so のコピー、STB の取得、CMake と NDK の呼び出しを 1 つのコマンドで処理します。
ステップ 1 - Maven から libLiteRt.so を取得する
LiteRT は、Google Maven の Android AAR 内の共有ライブラリとしてランタイムを配布します。ダウンロードして arm64-v8a .so を抽出します。
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
GPU をサポートするには、OpenCL/GL アクセラレータも抽出します。
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

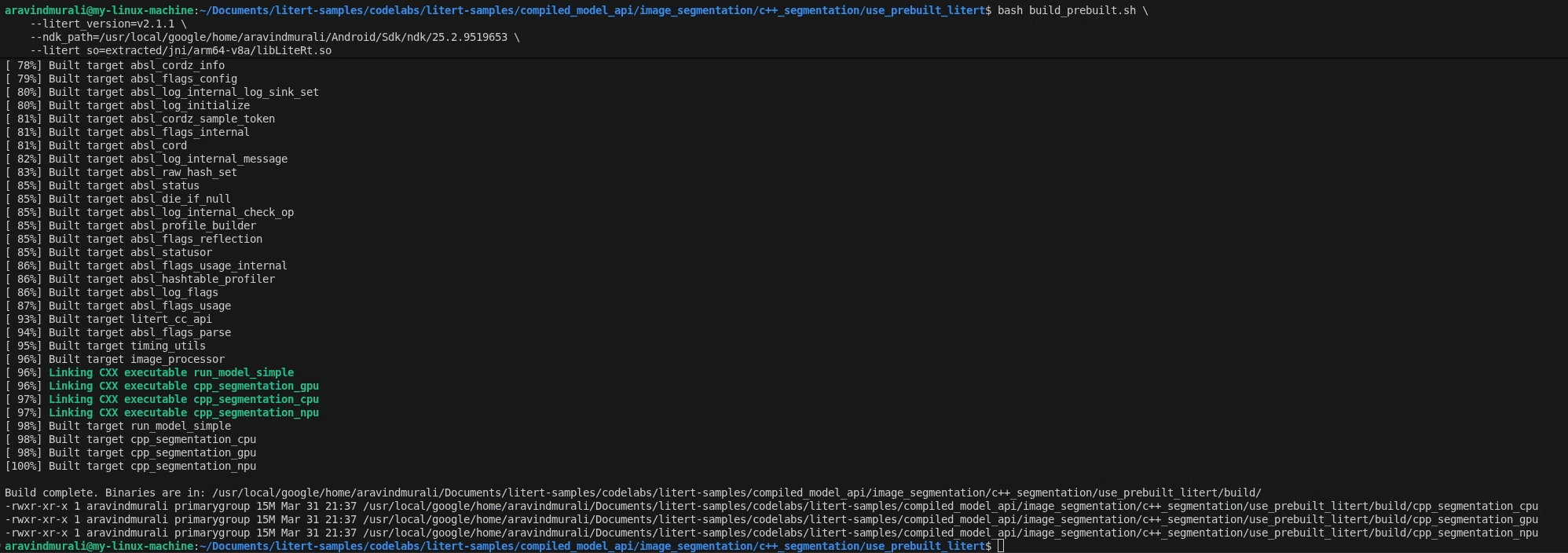
ステップ 2 - build_prebuilt.sh を実行する
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
このスクリプトによって行われる処理は次のとおりです。
- LiteRT GitHub リリースから
litert_cc_sdk.zip(SDK ヘッダー + cmake ファイル)をダウンロードします。すでに存在する場合は、後続の実行でスキップされます。 libLiteRt.soをlitert_cc_sdk/にコピーします。- STB イメージ ヘッダーを
third_party/stb/にダウンロードします。存在する場合はスキップされます。 android-26のarm64-v8a用 Android NDK ツールチェーンを使用して、CMake で構成してビルドします。
成功すると、build/ に 3 つのバイナリが表示されます。
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
CMakeLists.txt が行うこと
CMakeLists.txt を開きます。C++20 が必要で、add_subdirectory を介して LiteRT SDK を取得し、OpenGL ES 3(GLESv3)と EGL をリンクしてから、ヘルパー マクロを使用して main_*.cc ソースから各バイナリを作成します。
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. ビルド - オプション B: Bazel を使用してビルドする(ソースから)
ビルドシステムとして Bazel を使用してソースから LiteRT ランタイムをコンパイルする場合や、既存の Bazel ワークスペース内で作業する必要がある場合は、このパスを選択します。
前提条件
「始める前に」セクションに記載されている NDK と ADB に加えて、次のものが必要です。
- Bazel がインストールされ、
PATHに含まれている。 - LiteRT サンプル ソース リポジトリの完全なクローン。
ステップ 1 - LiteRT サンプル ワークスペースを構成する
すべてのコマンドは LiteRT サンプル リポジトリのルートから実行します。
cd /path/to/litert-samples
./configure
プロンプトが表示されたら、次の操作を行います。
- Python と Python lib パスのデフォルトを受け入れます。
- ROCm と CUDA のサポートについては、「N」と答えます。
- コンパイラとして clang(18.1.3 でテスト済み)を選択します。
- デフォルトの最適化フラグを受け入れます。
- Android ビルドのワークスペースを構成するには、Y と答えます。
- 最小 Android NDK レベルを 26 以上に設定します。
- Android SDK のパスを指定します。
- Android SDK API レベルをデフォルト(36)に、ビルドツールを 36.0.0 に設定します。
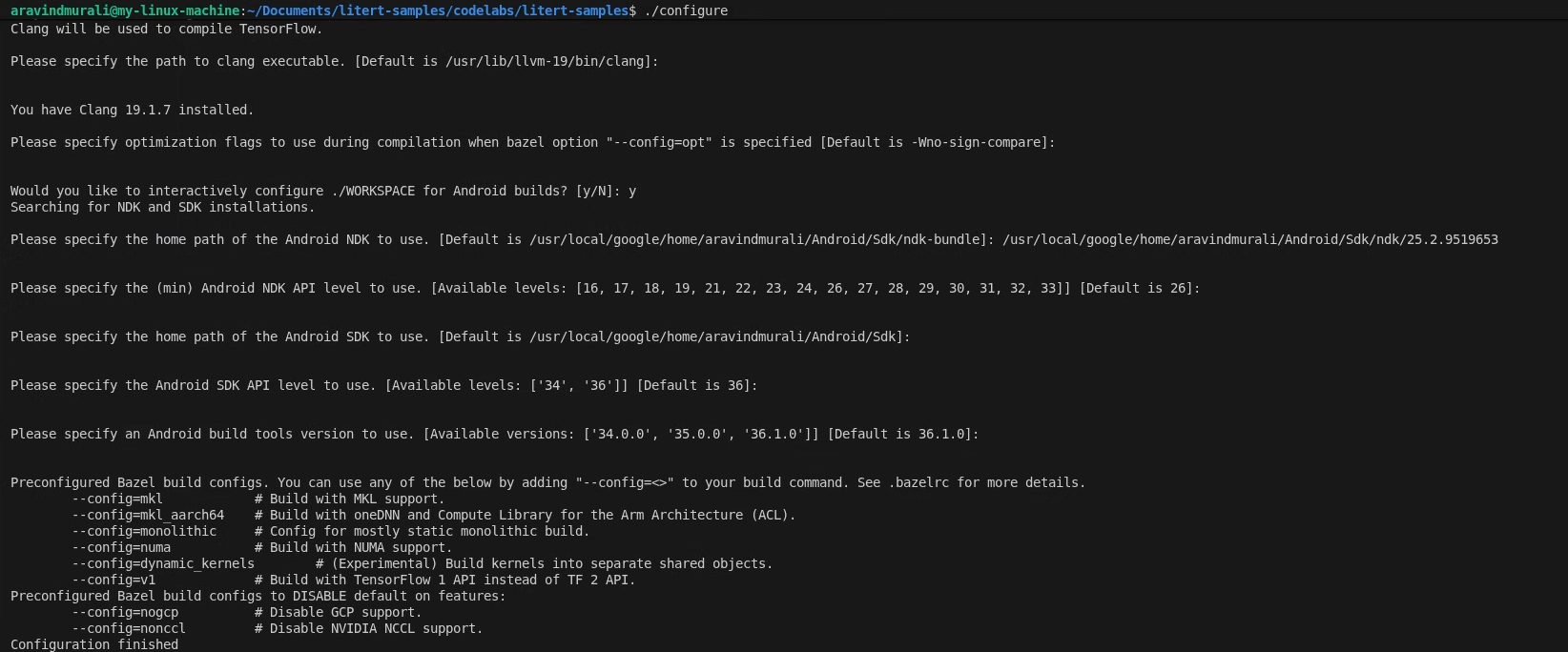
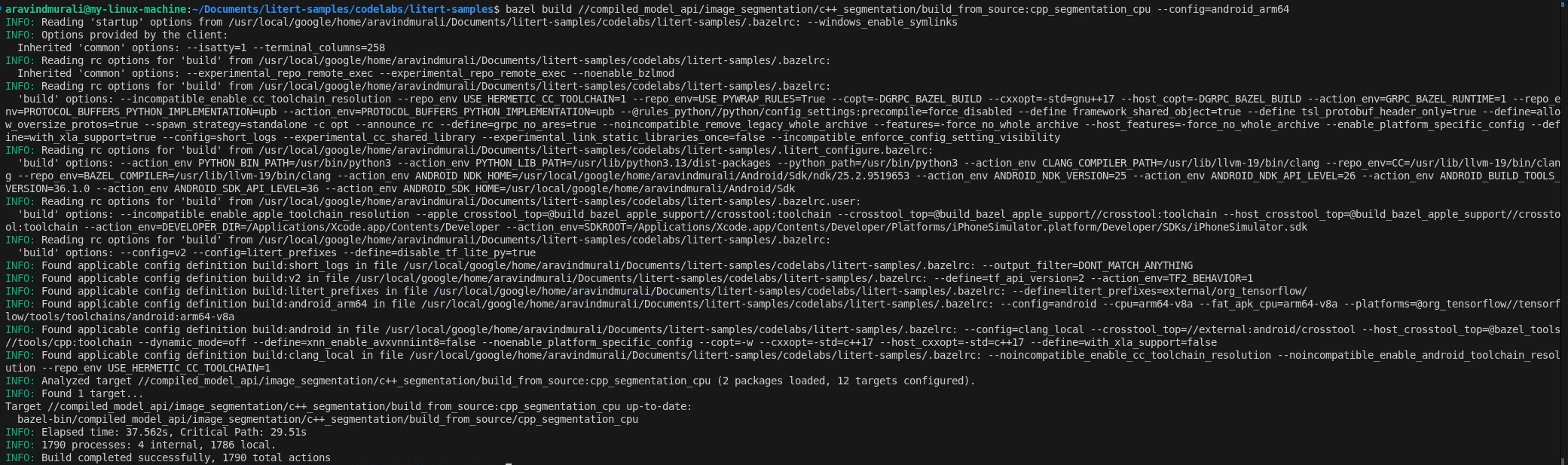
ステップ 2 - CPU ターゲットと GPU ターゲットをビルドする
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
ステップ 3 - NPU ターゲットをビルドする
Qualcomm HTP
- QAIRT SDK v2.41 以降をダウンロードして展開します。
- 抽出された SDK のコンテンツが
latest/という名前のサブディレクトリ内にあることを確認します。/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... /で終わる親パスを渡してビルドします。bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
--nocheck_visibility フラグが必要なのは、一部のアップストリーム LiteRT ターゲットで可視性のデフォルトが制限されているためです。
MediaTek APU
追加の SDK は不要です。NeuroPilot ランタイムは、Dimensity 9400 デバイスのシステム ライブラリです。
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
BUILD ファイル
build_from_source/BUILD を開きます。4 つの cc_binary ターゲット(アクセラレータごとに 1 つと、専用の MediaTek NPU ターゲット)を定義します。各ターゲットは、共有の image_processor、image_utils、timing_utils ライブラリ ターゲットに依存します。
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
GPU ターゲットは libLiteRtClGlAccelerator.so をデータ依存関係として追加するため、Bazel はこれを runfiles に含めます。NPU ターゲットは、ベンダー ディスパッチとコンパイラ プラグインの .so ファイルをデータ依存関係として追加します。
8. Compute シェーダーによる GPU アクセラレーションのプリプロセス
3 つのエントリ ポイントはすべて、同じ OpenGL ES コンピューティング シェーダー パイプラインをプリプロセスに使用します。この仕組みを理解することは、GPU パスが CPU パスよりもはるかに高速である理由を理解するうえで重要です。
ヘッドレス EGL コンテキストを設定する
ImageProcessor::InitializeGL() は、ヘッドレス EGL コンテキスト(ウィンドウやディスプレイが接続されていない OpenGL コンテキスト)を作成します。これは、Android のオフスクリーン GPU コンピューティングの標準的な方法です。次に、ディスクから 5 つの GLSL コンピューティング シェーダー プログラムをコンパイルします。
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
入力画像を GPU にアップロードする
JPEG は ImageUtils::LoadImage()(STB ライブラリ経由)によって CPU メモリにデコードされ、GPU テクスチャにアップロードされます。
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
この時点で、元の画像は OpenGL テクスチャとして GPU メモリに保存されます。
前処理コンピューティング シェーダー
shaders/preprocess_compute.glsl は、256×256 の出力グリッド全体に 8×8 スレッド グループをディスパッチします。各スレッドは 1 つの出力ピクセルを処理します。バイリニア フィルタリング(ハードウェア リサイズは無料)を使用して入力テクスチャをサンプリングし、[0, 1] RGB 値を [-1, 1] に変換して、出力 SSBO に書き込みます。
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
標準(ゼロコピー以外)のパスでは、この SSBO が CPU に読み戻され、LiteRT テンソルに書き込まれます。
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. CPU 推論
main_cpu.cc を開きます。LiteRT の設定は 3 行です。
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
前処理後、推論は単一の同期呼び出しになります。
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() は、推論が完了するまでブロックされます。selfie_multiclass_256x256.tflite 浮動小数点モデルは ARM Cortex コアで実行され、通常はミッドレンジ デバイスで 116 ~ 128 ミリ秒程度かかります。
バイナリの使用:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. GPU 推論(OpenCL)
main_gpu.cc を開きます。GPU パスには、CPU パスにはない 2 つのコンセプトがあります。GPU アクセラレータ(OpenCL バックエンドを使用)を構成するための litert::Options と非同期実行です。
GPU オプションを構成する
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
非同期推論
GPU パスでは Run() ではなく RunAsync() を使用します。これは、GPU コマンドキューに作業を送信し、すぐに戻ります。結果を読み取る前に同期します。
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
このノンブロッキング設計により、リアルタイム パイプラインで CPU の処理と GPU の実行をオーバーラップさせることができます。
バイナリの使用:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. 後処理 - インターリーブ解除とブレンド
Run() または RunAsync() が完了すると、output_buffers[0] はインターリーブ順で形状 [256 × 256 × 6] のフラットな浮動小数点配列を保持します。ピクセル (row, col) の 6 つのクラススコアは、インデックス (row * 256 + col) * 6~(row * 256 + col) * 6 + 5 にあります。
6 つのマスク SSBO にデインターリーブ
CPU ヘルパーは、インターリーブされた配列を 6 つのシングル チャンネルの浮動小数点配列に分割し、それぞれを独自の GPU SSBO にアップロードします。
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
元の画像にカラーブレンド マスクを適用する
processor.ApplyColoredMasks() は mask_blend_compute.glsl シェーダーを実行します。出力ピクセルごとに、スコアが最も高いクラス(6 つのマスク SSBO の argmax)を見つけ、対応する色を元の画像ピクセルにアルファ合成します。6 つのカラーは、各エントリ ポイントで次のように定義されています。
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
0.1f のアルファ値により、元の画像がかすかに見えるように色合いが調整されます。
出力を保存する
最終的なブレンドされた RGBA 浮動小数点 SSBO が読み戻され、[0, 1] の範囲に収められ、unsigned char に変換され、PNG として保存されます。
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. デバイスにデプロイして実行する
USB を使用して Android デバイスを接続し、ADB 接続を確認します。
adb devices

deploy_and_run_on_android.sh を使用する
各バリアントには独自のデプロイ スクリプトがあります。CMake バリアントは build/ ディレクトリを指し、Bazel バリアントは bazel-bin/ を指します。両方のスクリプト:
- デバイスに
/data/local/tmp/cpp_segmentation_android/を作成します。 - バイナリ、GLSL シェーダー、モデル、テスト画像、ランタイム
.soファイルを push します。 adb shellを使用して推論を実行します。output_segmented.pngをマシンにプルします。
CMake バリアント(use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Bazel バリアント(build_from_source/)
LiteRT サンプル リポジトリのルートから次のコマンドを実行します。
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
--phone フラグは、使用されるデバイス固有のモデル ライブラリとベンダー ライブラリを制御します。サポートされている値: s24(Snapdragon 8 Gen 3)、s25(Snapdragon 8 Elite)、dim9400(MediaTek Dimensity 9400)、pixel8(Tensor G3)、pixel9(Tensor G4)、pixel10(Tensor G5)、pixel11(Tensor G6)。
推論のタイミング
推論後、PrintTiming() はプロファイリングの完全な内訳を出力します。
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Samsung S25 Ultra(Snapdragon 8 Elite)でのパフォーマンスの目安:
アクセラレータ | 実行タイプ | 推論 | E2E |
CPU | 同期 | 約 116 ~ 128 ミリ秒 | 約 157 ミリ秒 |
GPU(OpenCL) | 非同期 | 約 0.95 ミリ秒 | 約 35 ~ 43 ミリ秒 |
13. 高度なオプション: NPU 推論
パフォーマンスを最大限に高めるため、LiteRT はベンダー固有のプラグイン ライブラリを使用して NPU アクセラレーションをサポートしています。NPU パスでは、エンドツーエンドのレイテンシを 9 ミリ秒まで短縮できます。
サポートされているデバイスとモード
チップ | デバイスの例 | モード | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | 約 17 ミリ秒 |
Qualcomm SM8750 | Galaxy S25 | AOT | 約 17 ミリ秒 |
Qualcomm(任意) | — | JIT | 約 28 ミリ秒 |
MediaTek Dimensity 9400 | — | JIT | ~ 9 ミリ秒 |
Google Tensor G3 ~ G6 | Google Pixel 8 ~ 11 | AOT/JIT | 場合によって異なる |
AOT(事前コンパイル)は、デバイス固有の事前コンパイル済みモデル(selfie_multiclass_256x256_SM8650.tflite など)を使用します。これは最も高速なオプションですが、チップ固有です。
JIT(Just-in-Time)は標準の selfie_multiclass_256x256.tflite を使用し、実行時に NPU にコンパイルします。初回実行は遅くなりますが、チップに依存しません。
追加の前提条件
Qualcomm HTP:
- QAIRT SDK v2.41 以降(
libQnnHtp.so、スタブまたはスケル.soファイルを提供)。 - GitHub でリリースされた LiteRT NPU ランタイム ライブラリの
libLiteRtDispatch_Qualcomm.so。
MediaTek APU:
- LiteRT NPU ランタイム ライブラリのリリースから
libLiteRtDispatch_MediaTek.soを削除 - NeuroPilot ランタイム(Dimensity 9400 デバイスではすでにシステム ライブラリになっています。プッシュする必要はありません)。
Google Tensor:
- LiteRT NPU ランタイム ライブラリのリリースから
libLiteRtDispatch_GoogleTensor.soを削除
NPU 環境とオプション
main_npu.cc は、デバイス上のベンダー ディスパッチ ライブラリ ディレクトリを Environment に指定し、ベンダー固有のパフォーマンス オプションを設定します。
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
MediaTek の場合、GetQualcommOptions() ブロックを置き換えます。
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
NPU 向けにデプロイする
CMake バリアント - Qualcomm S25(AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
CMake バリアント - MediaTek Dimensity 9400(JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Bazel バリアント - Qualcomm S25(AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Bazel バリエーション - MediaTek Dimensity 9400(JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Bazel バリアント - Google Tensor Google Pixel 9(JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Bazel バリアントの場合、ビルド時に LITERT_QAIRT_SDK が設定されていると、QAIRT SDK ライブラリは bazel-bin ランファイル ツリーから自動的に選択されます。CMake バリアントでは、解凍した QAIRT SDK を指す --host_npu_lib フラグが必要です。
14. 完了
LiteRT を使用して、Android で C++ 画像セグメンテーション パイプラインを正常にビルドして実行しました。ここでは、以下の方法を学びました。
- CMake + NDK または Bazel を使用して、Android
arm64-v8a用の C++ バイナリをクロス コンパイルします。 - 効率的なオンデバイス推論には、LiteRT C++ API(
Environment、CompiledModel、TensorBuffer)を使用します。 - OpenGL ES 3.1 コンピューティング シェーダーを使用して、GPU で画像データを前処理します。
- 同期 CPU 推論と非同期 GPU(OpenCL)推論を実行します。
- Qualcomm、MediaTek、Google Tensor デバイスの NPU アクセラレーションを設定します。
- ADB を使用して Android に C++ バイナリをデプロイして実行する。
次のステップ
- 別の TFLite モデル(深度推定やポーズ検出など)に置き換えます。
- JNI を使用して、C++ パイプラインを Android NDK アプリに統合します。
- タイミング出力とともに Android GPU Inspector でメモリ使用量をプロファイリングします。
- モデルの量子化を検討して、NPU 推論のレイテンシをさらに短縮します。