
1. Prima di iniziare
Digitare il codice è un ottimo modo per sviluppare la memoria muscolare e approfondire la comprensione del materiale. Sebbene il copia e incolla possa farti risparmiare tempo, investire in questa pratica può portare a una maggiore efficienza e a competenze di programmazione più solide nel lungo periodo.
In questo codelab imparerai a creare un file binario di segmentazione dell'immagine C++ che viene eseguito direttamente su un dispositivo Android utilizzando LiteRT, il runtime on-device ad alte prestazioni di Google. Anziché utilizzare Kotlin o Android Studio, questo codelab si concentra sulla creazione di un binario C++. Eseguirai la compilazione incrociata con CMake o Bazel e lo implementerai utilizzando ADB. La stessa API LiteRT C++ funziona su qualsiasi piattaforma (Android, Linux, incorporata), il che la rende una base utile per applicazioni critiche per le prestazioni, robotica e sistemi edge.
Esaminerai l'intera pipeline:
- Configurazione dell'ambiente di build (CMake + Android NDK o Bazel).
- Collegamento dell'SDK LiteRT C++: da una release precompilata o dall'origine.
- Utilizzo di shader di calcolo OpenGL ES per il pre- e post-processing delle immagini con accelerazione GPU.
- Esecuzione del modello di segmentazione
selfie_multiclasscon l'API C++ LiteRT. - Accelerazione dell'inferenza su CPU, GPU (OpenCL) e NPU (Qualcomm / MediaTek).
- Post-elaborazione dell'output del modello non elaborato in un'immagine di segmentazione con fusione dei colori.
- Deployment su un dispositivo Android fisico con ADB e recupero del risultato.
Alla fine, otterrai un risultato simile all'immagine seguente: un'immagine statica elaborata tramite l'intera pipeline, con ciascuna delle sei classi di segmentazione sovrapposta in un colore distinto:

Prerequisiti
Questo codelab è pensato per gli sviluppatori che hanno familiarità con C++ e che vogliono acquisire esperienza nell'esecuzione di modelli di machine learning su Android a livello C++. Devi avere familiarità con:
- Nozioni di base di C++ (puntatori, vettori, include).
- Concetti di base di Android/ADB (
adb push,adb shell). - Utilizzando un terminale e script shell su Linux o macOS.
Obiettivi didattici
- Come eseguire la cross-compilazione di un file binario C++ per Android
arm64-v8acon CMake + NDK o Bazel. - Come utilizzare l'API LiteRT C++ (
Environment,CompiledModel,TensorBuffer) per un'inferenza efficiente sul dispositivo. - In che modo gli shader di calcolo OpenGL ES 3.1 accelerano la pre-elaborazione e la post-elaborazione interamente sulla GPU.
- Come configurare LiteRT per l'accelerazione di CPU, GPU (OpenCL) e NPU (Qualcomm HTP, MediaTek APU, Google Tensor).
- La differenza tra inferenza sincrona (
Run) e asincrona (RunAsync). - Come eseguire il deployment ed eseguire un file binario C++ su Android utilizzando ADB.
Che cosa ti serve
- Un computer Linux o macOS (gli utenti Windows devono utilizzare WSL2).
- Android NDK r25c o versioni successive (scarica).
- Per CMake path: CMake ≥ 3.22 (
sudo apt-get install cmake). - Per Percorso Bazel: Bazel installato, più il repository completo degli esempi LiteRT.
- ADB in
PATH(Android Platform Tools). - Un dispositivo Android fisico, testato al meglio su Galaxy S24/S25 o Pixel.
2. Segmentazione dell'immagine
La segmentazione delle immagini è un'attività di computer vision che assegna un'etichetta di classe a ogni pixel di un'immagine. A differenza del rilevamento degli oggetti, che disegna un riquadro di delimitazione, la segmentazione produce una comprensione precisa e perfetta al pixel di dove inizia e finisce ogni oggetto.
Questo codelab utilizza il modello selfie_multiclass_256x256, che classifica ogni pixel in una delle 6 classi:
Indice della classe | Segmento |
0 | Sfondo |
1 | Capelli |
2 | Pelle del corpo |
3 | Pelle del viso |
4 | Indumenti |
5 | Accessori (occhiali, gioielli e così via) |
Il modello restituisce un tensore float di forma [1, 256, 256, 6]. Per ciascuno dei 256 × 256 pixel, sono presenti 6 punteggi di confidenza, uno per classe. La classe con il punteggio più alto vince quel pixel (argmax).
LiteRT: prestazioni a livello perimetrale
LiteRT è il runtime di nuova generazione ad alte prestazioni di Google per i modelli TFLite. La sua API C++ ti offre un accesso diretto e a basso overhead agli acceleratori hardware con un'interfaccia coerente per tutti e tre:
- CPU: compatibilità universale; inferenza di circa 128 ms su un dispositivo di fascia media.
- GPU (OpenCL): inferenza di circa 1 ms; end-to-end di circa 17-43 ms a seconda della strategia di buffer.
- NPU: ~9-28 ms end-to-end su dispositivi Qualcomm Snapdragon, MediaTek Dimensity 9400 e Google Tensor, a seconda della modalità AOT. Compilazione JIT.
L'astrazione chiave è CompiledModel: il modello viene precompilato e ottimizzato per l'hardware di destinazione al tempo di caricamento, riducendo l'inferenza a una chiamata Run() su buffer preallocati.
3. Configurazione
Clona il repository
git clone https://github.com/google-ai-edge/litert-samples.git
Tutte le risorse per questo codelab si trovano in:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Questa directory ha due progetti secondari, ognuno dei quali è una build completa dello stesso esempio:
Directory | Sistema di compilazione | Dipendenza LiteRT |
| CMake + Android NDK | Prebuilt |
| Bazel | Compila LiteRT dall'origine |
Scegli un percorso e seguilo. Il codice è identico tra le due directory. Cambiano solo il sistema di compilazione e la strategia di dipendenza. Se vuoi la configurazione più rapida, scegli use_prebuilt_litert/. Se devi modificare LiteRT o lavorare all'interno di un monorepo Bazel esistente, utilizza build_from_source/.
Una nota sui percorsi dei file
Tutti i percorsi dei file in questo tutorial utilizzano il formato Linux/macOS. Gli utenti Windows devono utilizzare WSL2.
Panoramica della directory
Entrambi i progetti secondari condividono lo stesso layout di origine:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Inoltre:
use_prebuilt_litert/aggiungeCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shethird_party/stb/.build_from_source/aggiunge un fileBUILDBazel e utilizzadeploy_and_run_on_android.shche punta abazel-bin/.
4. Informazioni sulla struttura del progetto
Tre punti di ingresso, una pipeline
main_cpu.cc, main_gpu.cc e main_npu.cc contengono ciascuno una funzione main() che gestisce l'intera pipeline di segmentazione. La pipeline è identica per tutti e tre; cambiano solo la configurazione dell'acceleratore LiteRT e la strategia di buffer:
File | Acceleratore | Strategia di buffer |
|
| Memoria CPU |
|
| Memoria CPU con backend OpenCL |
|
| Memoria CPU con fallback della CPU |
Tutti e tre condividono le stesse utilità ImageProcessor (shader di calcolo OpenGL ES per la preelaborazione e la post-elaborazione) e ImageUtils (I/O immagini STB).
L'intera pipeline
Ogni punto di accesso segue la stessa struttura in cinque fasi:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Caricamento:
ImageUtils::LoadImage()decodifica il JPEG nella memoria della CPU utilizzando la libreria di immagini STB. - Carica:
processor.CreateOpenGLTexture()carica i pixel non elaborati in una texture GPU (OpenGL RGBA8). - Preprocess (Preelabora):
processor.PreprocessInputForSegmentation()esegue uno shader di calcolo GLSL che ridimensiona la texture a 256 × 256 e normalizza i valori dei pixel da[0, 1]a[-1, 1]. Il risultato viene inserito in un SSBO della GPU. - Infer: i dati SSBO vengono scritti in un
TensorBufferLiteRT ecompiled_model.Run()(oRunAsync()) esegue il modello. - Post-elaborazione: l'output float a 6 canali del modello viene deinterlacciato in 6 SSBO di maschere a canale singolo, che vengono poi ricombinate a colori nell'immagine originale.
- Salva:
ImageUtils::SaveImage()scrive l'immagine RGBA finale come PNG.
5. API C++ Core LiteRT
Prima di creare, acquisisci familiarità con i tre tipi C++ LiteRT chiave utilizzati in tutti i punti di ingresso. Tutti si trovano nello spazio dei nomi litert::.
litert::Environment
Environment è il contesto principale per tutte le operazioni LiteRT. Crealo una volta e passalo a CompiledModel::Create. Per l'utilizzo della NPU, configurala con la directory della libreria dei plug-in del fornitore.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel carica e precompila il modello TFLite per l'hardware richiesto al momento della creazione. L'inferenza si riduce quindi al riempimento dei buffer e alla chiamata di Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
I buffer tensore contengono i dati di input/output. Creali sempre da CompiledModel in modo che abbiano le dimensioni e l'allineamento corretti per l'hardware di destinazione.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Macro di gestione degli errori
Macro | Comportamento |
| Assegna o chiama |
| Chiama |
| Assegna o propaga l'errore al chiamante |
6. Build - Opzione A: SDK LiteRT C++ precompilato (CMake)
Questo è il percorso consigliato se non devi modificare LiteRT. Lo script di build gestisce il download delle intestazioni dell'SDK, la copia di .so, il recupero di STB e l'invocazione di CMake + NDK in un unico comando.
Passaggio 1: scarica libLiteRt.so da Maven
LiteRT distribuisce il proprio runtime come libreria condivisa all'interno di un AAR Android su Google Maven. Scaricalo ed estrai arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Per il supporto GPU, estrai anche l'acceleratore OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

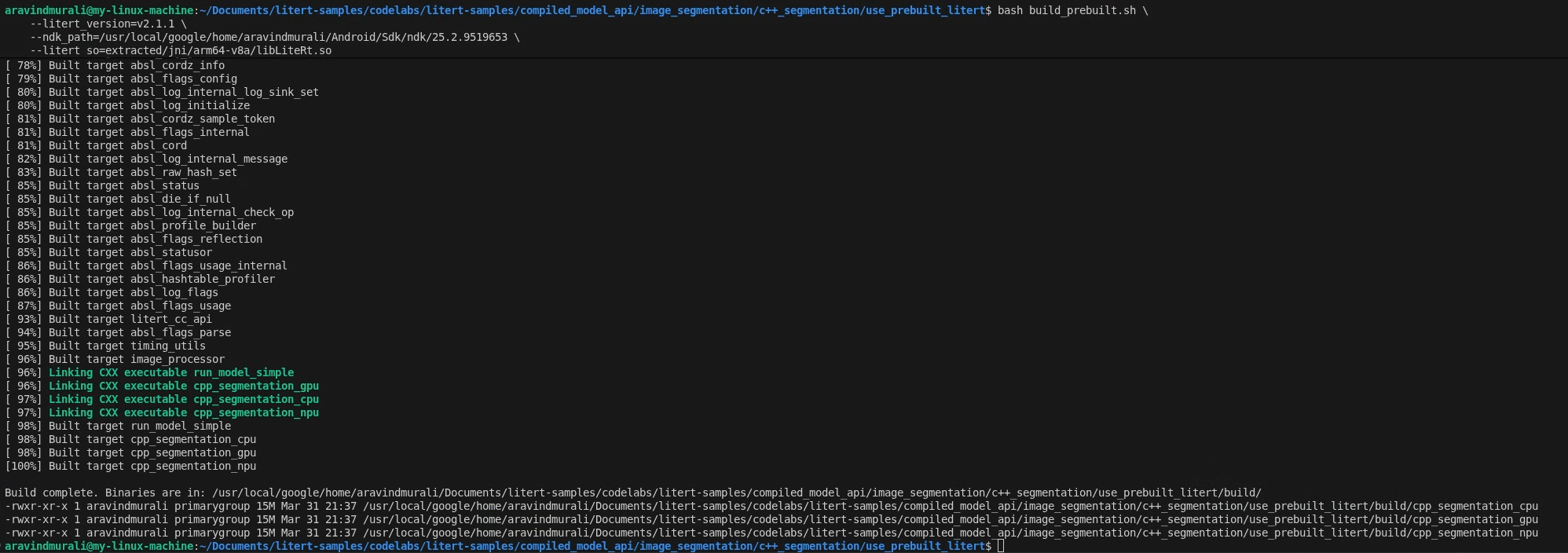
Passaggio 2: esegui build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Lo script:
- Scarica
litert_cc_sdk.zip(intestazioni SDK + file cmake) dalla release di LiteRT GitHub. L'operazione viene ignorata nelle esecuzioni successive se i file sono già presenti. - Copia
libLiteRt.soinlitert_cc_sdk/. - Scarica le intestazioni delle immagini STB in
third_party/stb/. Questo passaggio viene ignorato se le intestazioni sono già presenti. - Configura e compila con CMake utilizzando la toolchain Android NDK per
arm64-v8ainandroid-26.
In caso di esito positivo, in build/ vedrai tre file binari:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Cosa fa CMakeLists.txt
Apri CMakeLists.txt. Richiede C++20, incorpora l'SDK LiteRT tramite add_subdirectory, collega OpenGL ES 3 (GLESv3) ed EGL, quindi utilizza una macro helper per creare ogni file binario dalla relativa origine main_*.cc:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Build — Option B: Build with Bazel (From Source)
Scegli questo percorso se preferisci Bazel come sistema di compilazione, che compila il runtime LiteRT dal codice sorgente, o se devi lavorare all'interno di uno spazio di lavoro Bazel esistente.
Prerequisiti
Oltre a NDK e ADB elencati nella sezione "Prima di iniziare", ti serviranno:
- Bazel installato e sul tuo
PATH. - Una clonazione completa del repository di origine degli esempi di LiteRT.
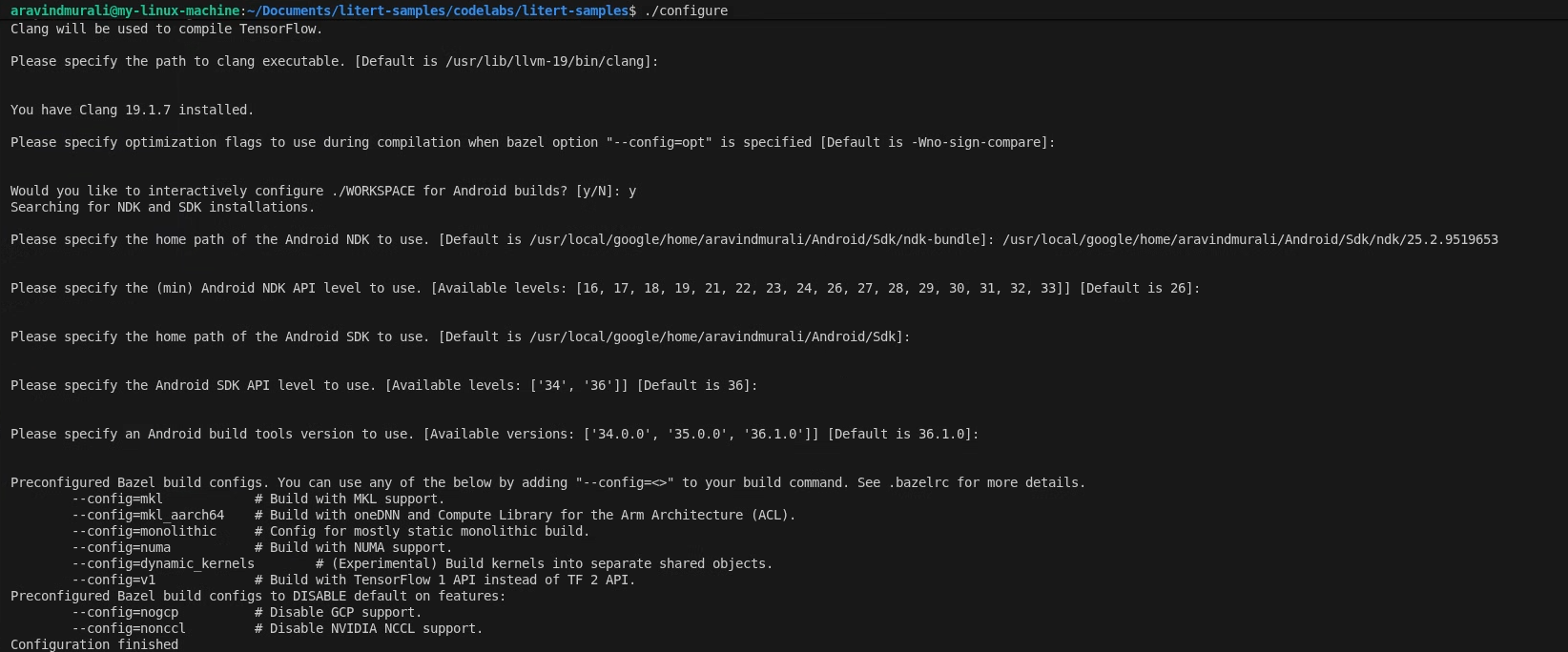
Passaggio 1: configura lo spazio di lavoro degli esempi LiteRT
Tutti i comandi vengono eseguiti dalla radice del repository di esempi LiteRT
cd /path/to/litert-samples
./configure
Quando richiesto:
- Accetta i valori predefiniti per Python e il percorso della libreria Python.
- Rispondi N per il supporto di ROCm e CUDA.
- Seleziona clang (testato con la versione 18.1.3) come compilatore.
- Accetta i flag di ottimizzazione predefiniti.
- Rispondi Y per configurare lo spazio di lavoro per le build Android.
- Imposta il livello minimo di Android NDK su almeno 26.
- Fornisci il percorso dell'SDK Android.
- Imposta il livello API dell'SDK Android su quello predefinito (36) e gli strumenti di compilazione su 36.0.0.
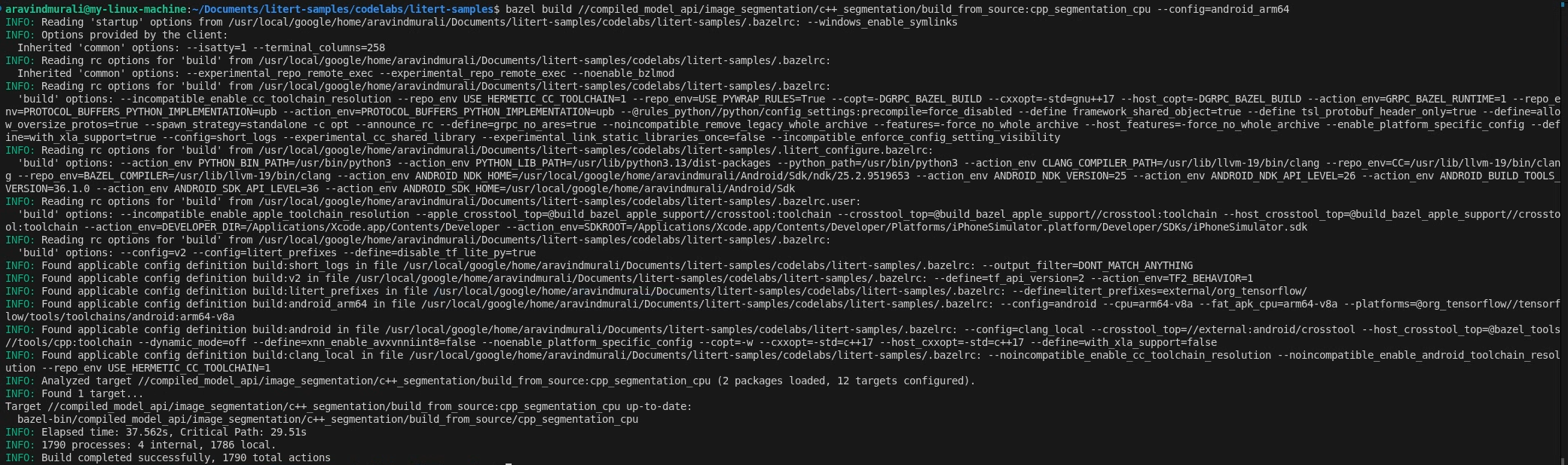
Passaggio 2: crea i target CPU e GPU
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Passaggio 3: crea il target NPU
Qualcomm HTP
- Scarica l'SDK QAIRT v2.41 o versioni successive ed estrailo.
- Assicurati che i contenuti dell'SDK estratti si trovino all'interno di una sottodirectory denominata
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Crea, passando il percorso principale che termina con
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Il flag --nocheck_visibility è necessario perché alcuni target LiteRT upstream hanno visibilità predefinita limitata.
APU MediaTek
Non è necessario un SDK aggiuntivo. Il runtime di NeuroPilot è una libreria di sistema sui dispositivi Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
Il file BUILD
Apri build_from_source/BUILD. Definisce quattro target cc_binary, uno per ogni acceleratore più un target NPU MediaTek dedicato, ciascuno a seconda dei target delle librerie condivise image_processor, image_utils e timing_utils:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
La destinazione GPU aggiunge libLiteRtClGlAccelerator.so come dipendenza dei dati, in modo che Bazel la includa nei runfile. Le destinazioni NPU aggiungono i file di plug-in di compilazione e invio del fornitore .so come dipendenze di dati.
8. Preelaborazione accelerata da GPU con Compute Shader
Tutti e tre i punti di ingresso utilizzano la stessa pipeline di shader di calcolo OpenGL ES per la preelaborazione. Comprenderlo è fondamentale per capire perché il percorso della GPU è molto più veloce di quello della CPU.
Configura un contesto EGL headless
ImageProcessor::InitializeGL() crea un contesto EGL headless, ovvero un contesto OpenGL senza finestra o display collegato. Si tratta di una pratica standard per il calcolo della GPU off-screen su Android. Poi compila i cinque programmi di shader di calcolo GLSL dal disco:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Carica l'immagine di input sulla GPU
Il JPEG viene decodificato nella memoria della CPU da ImageUtils::LoadImage() (tramite la libreria STB), quindi caricato in una texture della GPU:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
Da questo punto in poi, l'immagine originale risiede nella memoria della GPU come texture OpenGL.
Lo shader di calcolo di pre-elaborazione
shaders/preprocess_compute.glsl distribuisce gruppi di thread 8×8 nella griglia di output 256×256. Ogni thread gestisce un pixel di output: campiona la texture di input utilizzando il filtro bilineare (ridimensionamento hardware senza costi), converte il valore RGB [0, 1] in [-1, 1] e scrive nell'SSBO di output:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Per il percorso standard (non zero-copy), questo SSBO viene quindi letto di nuovo dalla CPU e scritto nel tensore LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Inferenza della CPU
Apri main_cpu.cc. La configurazione di LiteRT è composta da tre righe:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Dopo il pre-elaborazione, l'inferenza è una singola chiamata sincrona:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() blocchi fino al completamento dell'inferenza. Il modello con rappresentazione in virgola mobile selfie_multiclass_256x256.tflite viene eseguito sui core ARM Cortex e in genere richiede circa 116-128 ms su un dispositivo di fascia media.
Utilizzo del binario:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Inferenza GPU (OpenCL)
Apri main_gpu.cc. Il percorso della GPU introduce due concetti non presenti nel percorso della CPU: litert::Options per la configurazione dell'acceleratore GPU (con il backend OpenCL) e l'esecuzione asincrona.
Configura le opzioni della GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Inferenza asincrona
Il percorso GPU utilizza RunAsync() anziché Run(). Invia il lavoro alla coda di comandi della GPU e restituisce immediatamente. Poi sincronizza prima di leggere i risultati:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Questo design non bloccante ti consente di sovrapporre il lavoro della CPU all'esecuzione della GPU in una pipeline in tempo reale.
Utilizzo del binario:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Postprocess - Deinterleave and Blend
Al termine di Run() o RunAsync(), output_buffers[0] contiene un array di numeri in virgola mobile di forma [256 × 256 × 6] in ordine interleaved. I 6 punteggi della classe per il pixel (row, col) si trovano negli indici da (row * 256 + col) * 6 a (row * 256 + col) * 6 + 5.
Deinterleave in 6 SSBO maschera
Un helper della CPU suddivide l'array interleaved in sei array float a canale singolo e carica ciascuno nel proprio SSBO della GPU:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Maschere di fusione del colore sull'immagine originale
processor.ApplyColoredMasks() esegue lo shader mask_blend_compute.glsl. Per ogni pixel di output, trova la classe con il punteggio più alto (argmax tra i 6 SSBO della maschera) e compone il colore corrispondente sul pixel dell'immagine originale. I sei colori sono definiti in ogni punto di accesso:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
L'alpha di 0.1f mantiene la tinta tenue, in modo che l'immagine originale rimanga visibile.
Salva l'output
L'SSBO float RGBA finale combinato viene letto nuovamente, bloccato a [0, 1], convertito in unsigned char e salvato come PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Esegui il deployment e l'esecuzione sul dispositivo
Collega il tuo dispositivo Android tramite USB e verifica la connettività ADB:
adb devices

Utilizza deploy_and_run_on_android.sh
Ogni variante ha il proprio script di deployment. La variante CMake punta alla directory build/, mentre la variante Bazel punta a bazel-bin/. Entrambi gli script:
- Crea
/data/local/tmp/cpp_segmentation_android/sul dispositivo. - Esegui il push dei file binari, degli shader GLSL, del modello, dell'immagine di test e di runtime
.so. - Esegui l'inferenza utilizzando
adb shell. - Tira
output_segmented.pngverso la macchina.
Variante CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Variante Bazel (build_from_source/)
Esegui questi comandi dalla directory principale del repository di esempi di LiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
Il flag --phone controlla quali librerie di modelli e fornitori specifiche per il dispositivo vengono utilizzate. Valori supportati: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) e pixel11 (Tensor G6).
Tempi di inferenza
Dopo l'inferenza, PrintTiming() stampa una suddivisione completa del profilo:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Prestazioni di riferimento su Samsung S25 Ultra (Snapdragon 8 Elite):
Acceleratore | Tipo di esecuzione | Inferenza | E2E |
CPU | Sincronizza | ~116-128 ms | ~157 ms |
GPU (OpenCL) | Asinc | ~0,95 ms | ~35-43 ms |
13. Avanzato (facoltativo): inferenza NPU
Per ottenere le massime prestazioni, LiteRT supporta l'accelerazione della NPU utilizzando librerie di plug-in specifiche del fornitore. Il percorso della NPU può raggiungere una latenza end-to-end di soli 9 ms.
Dispositivi e modalità supportati
Chip | Esempio di dispositivo | Modalità | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 ms |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 ms |
Qualcomm (qualsiasi) | — | JIT | ~28 ms |
MediaTek Dimensity 9400 | — | JIT | ~9 ms |
Google Tensor G3-G6 | Pixel 8-11 | AOT/JIT | Variabile |
AOT (Ahead-of-Time) utilizza un modello precompilato specifico per il dispositivo (ad es. selfie_multiclass_256x256_SM8650.tflite). Questa è l'opzione più veloce, ma è specifica per il chip.
JIT (Just-in-Time) utilizza selfie_multiclass_256x256.tflite standard e compila la NPU in fase di runtime. La prima esecuzione è più lenta, ma indipendente dal chip.
Prerequisiti aggiuntivi
Qualcomm HTP:
- SDK QAIRT v2.41 o versioni successive (fornisce file
libQnnHtp.so, stub o skel.so). libLiteRtDispatch_Qualcomm.sodalla release delle librerie di runtime NPU LiteRT su GitHub.
APU MediaTek:
libLiteRtDispatch_MediaTek.sodalle librerie di runtime NPU LiteRT.- Runtime NeuroPilot (già una libreria di sistema sui dispositivi Dimensity 9400, quindi non è necessario eseguire il push).
Google Tensor:
libLiteRtDispatch_GoogleTensor.sodalle librerie di runtime NPU LiteRT.
Ambiente e opzioni NPU
main_npu.cc punta Environment alla directory della libreria di invio del fornitore sul dispositivo, quindi imposta le opzioni di rendimento specifiche del fornitore:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
Per MediaTek, sostituisci il blocco GetQualcommOptions():
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Deployment per NPU
Variante CMake: Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Variante CMake: MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Variante Bazel: Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Variante Bazel: MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Variante Bazel: Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Per la variante Bazel, le librerie dell'SDK QAIRT vengono selezionate automaticamente dall'albero dei runfile bazel-bin quando LITERT_QAIRT_SDK viene impostato al tempo di compilazione. La variante CMake richiede che il flag --host_npu_lib punti all'SDK QAIRT estratto.
14. Complimenti!
Hai creato ed eseguito correttamente una pipeline di segmentazione delle immagini C++ su Android utilizzando LiteRT. Hai imparato a:
- Compila in modo cross-compilato un file binario C++ per Android
arm64-v8acon CMake + NDK o Bazel. - Utilizza l'API C++ LiteRT (
Environment,CompiledModel,TensorBuffer) per un'inferenza efficiente sul dispositivo. - Preelabora i dati delle immagini sulla GPU con gli shader di calcolo OpenGL ES 3.1.
- Esegui l'inferenza sincrona della CPU e l'inferenza asincrona della GPU (OpenCL).
- Configura l'accelerazione della NPU per i dispositivi Qualcomm, MediaTek e Google Tensor.
- Esegui il deployment ed esegui un binario C++ su Android utilizzando ADB.
Passaggi successivi
- Sostituisci il modello TFLite con un altro (ad es. stima della profondità o rilevamento della postura).
- Integra la pipeline C++ in un'app Android NDK utilizzando JNI.
- Profila la memoria utilizzata con Android GPU Inspector insieme all'output di temporizzazione.
- Esplora la quantizzazione del modello per ridurre ulteriormente la latenza di inferenza della NPU.