
1. Sebelum memulai
Mengetik kode adalah cara yang bagus untuk membangun memori otot dan memperdalam pemahaman Anda tentang materi. Meskipun salin tempel dapat menghemat waktu, berinvestasi dalam praktik ini dapat menghasilkan efisiensi yang lebih besar dan keterampilan coding yang lebih kuat dalam jangka panjang.
Dalam codelab ini, Anda akan mempelajari cara membuat biner segmentasi gambar C++ yang berjalan langsung di perangkat Android menggunakan runtime berperforma tinggi di perangkat Google, LiteRT. Alih-alih menggunakan Kotlin atau Android Studio, codelab ini berfokus pada pembuatan biner C++. Anda akan mengompilasinya secara silang dengan CMake atau Bazel dan men-deploy-nya menggunakan ADB. LiteRT C++ API yang sama berfungsi di platform apa pun (Android, Linux, embedded), sehingga menjadi fondasi yang berguna untuk aplikasi yang penting performanya, robotik, dan sistem edge.
Anda akan mempelajari seluruh pipeline:
- Menyiapkan lingkungan build (CMake + Android NDK atau Bazel).
- Menautkan LiteRT C++ SDK — baik dari rilis yang sudah dibuat sebelumnya maupun dari sumber.
- Menggunakan shader komputasi OpenGL ES untuk pra-pemrosesan dan pasca-pemrosesan gambar yang dipercepat GPU.
- Menjalankan model segmentasi
selfie_multiclassdengan LiteRT C++ API. - Mempercepat inferensi di CPU, GPU (OpenCL), dan NPU (Qualcomm / MediaTek).
- Memproses output model mentah menjadi gambar segmentasi yang dipadukan warnanya.
- Men-deploy ke perangkat Android fisik dengan ADB dan mengambil hasilnya.
Pada akhirnya, Anda akan menghasilkan sesuatu yang mirip dengan gambar berikut — gambar statis yang diproses melalui seluruh pipeline, dengan setiap dari 6 kelas segmentasi yang ditumpuk dalam warna yang berbeda:

Prasyarat
Codelab ini dirancang untuk developer yang sudah terbiasa dengan C++ dan ingin mendapatkan pengalaman menjalankan model machine learning di Android pada lapisan C++. Anda harus memahami:
- Dasar-dasar C++ (pointer, vektor, include).
- Konsep dasar Android/ADB (
adb push,adb shell). - Menggunakan terminal dan skrip shell di Linux atau macOS.
Yang akan Anda pelajari
- Cara mengompilasi silang biner C++ untuk Android
arm64-v8adengan CMake + NDK atau Bazel. - Cara menggunakan LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) untuk inferensi efisien di perangkat. - Cara shader komputasi OpenGL ES 3.1 mempercepat pra- dan pasca-pemrosesan sepenuhnya di GPU.
- Cara mengonfigurasi LiteRT untuk akselerasi CPU, GPU (OpenCL), dan NPU (Qualcomm HTP, MediaTek APU, Google Tensor).
- Perbedaan antara inferensi sinkron (
Run) dan asinkron (RunAsync). - Cara men-deploy dan menjalankan biner C++ di Android menggunakan ADB.
Yang Anda butuhkan
- Mesin Linux atau macOS (pengguna Windows harus menggunakan WSL2).
- Android NDK r25c atau yang lebih baru (download).
- Untuk jalur CMake: CMake ≥ 3.22 (
sudo apt-get install cmake). - Untuk jalur Bazel: Bazel yang diinstal, ditambah repositori contoh LiteRT lengkap.
- ADB di
PATH(Android Platform Tools). - Perangkat Android fisik — sebaiknya diuji di Galaxy S24/S25 atau Pixel.
2. Segmentasi Gambar
Segmentasi gambar adalah tugas computer vision yang menetapkan label kelas ke setiap piksel dalam gambar. Tidak seperti deteksi objek, yang menggambar kotak pembatas, segmentasi menghasilkan pemahaman yang presisi dan sempurna tentang di mana setiap objek dimulai dan berakhir.
Codelab ini menggunakan model selfie_multiclass_256x256, yang mengklasifikasikan setiap piksel ke dalam salah satu dari 6 kelas:
Indeks kelas | Segmen |
0 | Latar belakang |
1 | Rambut |
2 | Kulit tubuh |
3 | Kulit wajah |
4 | Pakaian |
5 | Aksesori (kacamata, perhiasan, dll.) |
Model ini menghasilkan tensor float dengan bentuk [1, 256, 256, 6]. Untuk setiap piksel 256x256, ada 6 skor keyakinan — satu per kelas. Class dengan skor tertinggi memenangkan piksel tersebut (argmax).
LiteRT: Performa di Edge
LiteRT adalah runtime berperforma tinggi generasi berikutnya dari Google untuk model TFLite. API C++-nya memberi Anda akses langsung dengan overhead rendah ke akselerator hardware dengan antarmuka yang konsisten di ketiga akselerator tersebut:
- CPU — kompatibel secara universal; inferensi ~128 md pada perangkat kelas menengah.
- GPU (OpenCL) — inferensi ~1 md; end-to-end ~17–43 md, bergantung pada strategi buffer.
- NPU — ~9–28 md end-to-end di perangkat Qualcomm Snapdragon, MediaTek Dimensity 9400, dan Google Tensor, bergantung pada AOT vs. Kompilasi JIT.
Abstraksi utamanya adalah CompiledModel: model telah dikompilasi dan dioptimalkan sebelumnya untuk hardware target pada waktu pemuatan, sehingga mengurangi inferensi menjadi panggilan Run() pada buffer yang telah dialokasikan sebelumnya.
3. Memulai persiapan
Melakukan cloning repositori
git clone https://github.com/google-ai-edge/litert-samples.git
Semua resource untuk codelab ini ada di:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Direktori ini memiliki dua sub-project, yang masing-masing merupakan build lengkap dari sampel yang sama:
Direktori | Sistem build | Dependensi LiteRT |
| CMake + Android NDK |
|
| Bazel | Mengompilasi LiteRT dari sumber |
Pilih salah satu jalur dan ikuti. Kodenya identik di antara kedua direktori — hanya sistem build dan strategi dependensi yang berbeda. Jika Anda menginginkan penyiapan tercepat, pilih use_prebuilt_litert/. Jika Anda perlu mengubah LiteRT itu sendiri atau bekerja dalam monorepo Bazel yang ada, gunakan build_from_source/.
Catatan tentang jalur file
Semua jalur file dalam tutorial ini menggunakan format Linux/macOS. Pengguna Windows harus menggunakan WSL2.
Ringkasan direktori
Kedua sub-project memiliki tata letak sumber yang sama:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Selain itu:
use_prebuilt_litert/menambahkanCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.sh, danthird_party/stb/.build_from_source/menambahkan fileBUILDBazel dan menggunakandeploy_and_run_on_android.shyang mengarah kebazel-bin/.
4. Memahami struktur project
Tiga titik entri, satu pipeline
main_cpu.cc, main_gpu.cc, dan main_npu.cc masing-masing berisi fungsi main() yang mendorong pipeline segmentasi penuh. Pipeline ini identik di ketiganya; hanya konfigurasi akselerator LiteRT dan strategi buffer yang berbeda:
File | Akselerator | Strategi buffer |
|
| Memori CPU |
|
| Memori CPU dengan backend OpenCL |
|
| Memori CPU dengan penggantian CPU |
Ketiganya berbagi utilitas ImageProcessor (shader komputasi OpenGL ES untuk pra-pemrosesan dan pasca-pemrosesan) dan ImageUtils (I/O gambar STB) yang sama.
Pipeline lengkap
Setiap titik entri mengikuti struktur lima fase yang sama:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Pemuatan —
ImageUtils::LoadImage()mendekode JPEG ke dalam memori CPU menggunakan library gambar STB. - Upload —
processor.CreateOpenGLTexture()mengupload piksel mentah ke tekstur GPU (OpenGL RGBA8). - Pra-pemrosesan —
processor.PreprocessInputForSegmentation()menjalankan shader komputasi GLSL yang mengubah ukuran tekstur menjadi 256x256 dan menormalisasi nilai piksel dari[0, 1]menjadi[-1, 1]. Hasilnya berada di SSBO GPU. - Inferensi — Data SSBO ditulis ke
TensorBufferdancompiled_model.Run()LiteRT (atauRunAsync()) menjalankan model. - Postprocess — Output float 6 saluran model di-deinterleave menjadi 6 SSBO mask saluran tunggal, yang kemudian dicampur warna kembali ke gambar asli.
- Simpan —
ImageUtils::SaveImage()menulis gambar RGBA akhir sebagai PNG.
5. API C++ Core LiteRT
Sebelum membangun, pelajari tiga jenis utama C++ LiteRT yang digunakan di semua titik entri. Semua berada di namespace litert::.
litert::Environment
Environment adalah konteks root untuk semua operasi LiteRT. Buat sekali dan teruskan ke CompiledModel::Create. Untuk penggunaan NPU, konfigurasikan dengan direktori library plugin vendor.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel memuat dan mengompilasi model TFLite Anda sebelumnya untuk hardware yang diminta pada waktu pembuatan. Inferensi kemudian direduksi menjadi mengisi buffer dan memanggil Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Buffer tensor menyimpan data input/output. Selalu buat dari CompiledModel agar ukurannya benar dan selaras untuk hardware target.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Makro penanganan error
Makro | Perilaku |
| Menetapkan atau memanggil |
| Memanggil |
| Menetapkan atau menyebarkan error ke pemanggil |
6. Build — Opsi A: SDK C++ LiteRT yang telah dibuat sebelumnya (CMake)
Ini adalah jalur yang direkomendasikan jika Anda tidak perlu mengubah LiteRT itu sendiri. Skrip build menangani download header SDK, menyalin .so, mengambil STB, dan memanggil CMake + NDK dalam satu perintah.
Langkah 1 — Dapatkan libLiteRt.so dari Maven
LiteRT mengirimkan runtime-nya sebagai library bersama di dalam AAR Android di Google Maven. Download dan ekstrak arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Untuk dukungan GPU, ekstrak juga akselerator OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

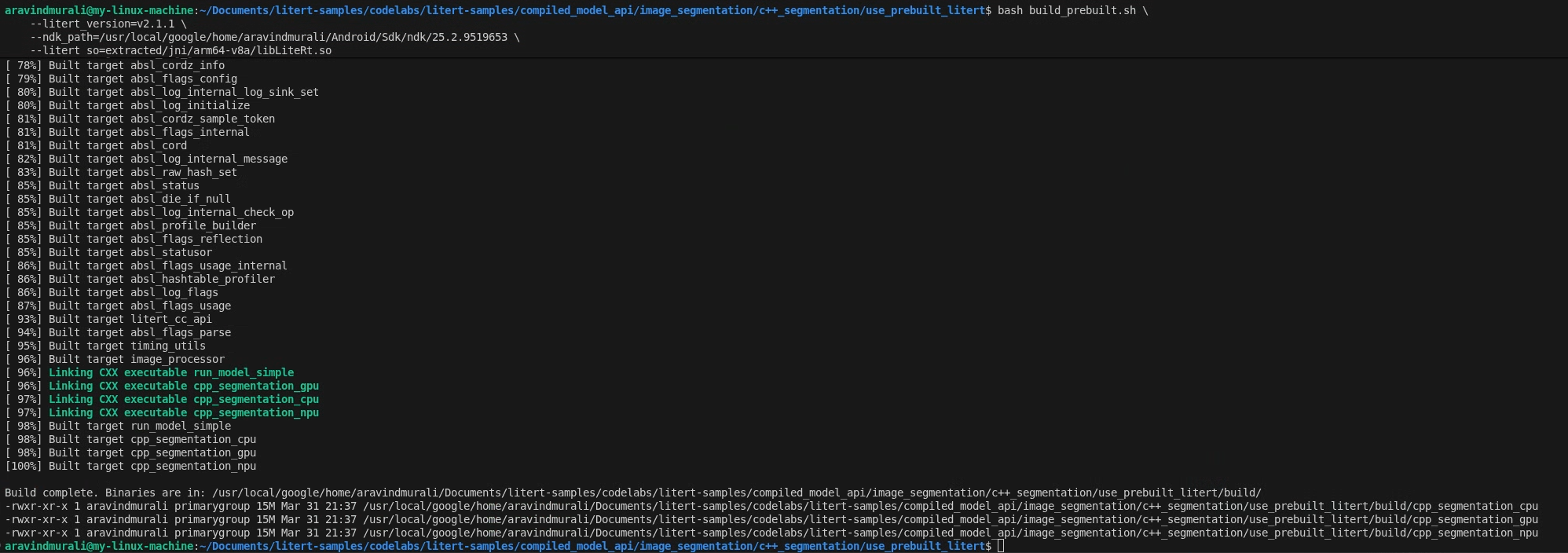
Langkah 2 — Jalankan build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Skrip akan:
- Download
litert_cc_sdk.zip(header SDK + file cmake) dari rilis LiteRT GitHub — dilewati pada proses berikutnya jika sudah ada. - Salin
libLiteRt.sokelitert_cc_sdk/. - Download header gambar STB ke
third_party/stb/— dilewati jika ada. - Konfigurasi dan build dengan CMake menggunakan toolchain Android NDK untuk
arm64-v8adiandroid-26.
Jika berhasil, Anda akan melihat tiga biner di build/:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Yang dilakukan CMakeLists.txt
Buka CMakeLists.txt. Contoh ini memerlukan C++20, menarik LiteRT SDK melalui add_subdirectory, menautkan OpenGL ES 3 (GLESv3) dan EGL, lalu menggunakan makro helper untuk membuat setiap biner dari sumber main_*.cc-nya:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Build — Opsi B: Build dengan Bazel (Dari Sumber)
Pilih jalur ini jika Anda lebih memilih Bazel sebagai sistem build, yang mengompilasi runtime LiteRT dari sumber, atau jika Anda perlu bekerja dalam ruang kerja Bazel yang ada.
Prasyarat
Selain NDK dan ADB yang tercantum di bagian "Sebelum memulai", Anda akan memerlukan:
- Bazel diinstal dan ada di
PATHAnda. - Clone lengkap repositori sumber contoh LiteRT.
Langkah 1 — Konfigurasi ruang kerja contoh LiteRT
Semua perintah dijalankan dari root repositori contoh LiteRT
cd /path/to/litert-samples
./configure
Saat diminta:
- Terima default untuk jalur Python dan Python lib.
- Menjawab N untuk dukungan ROCm dan CUDA.
- Pilih clang (diuji dengan 18.1.3) sebagai compiler.
- Terima tanda pengoptimalan default.
- Jawab Y untuk mengonfigurasi WORKSPACE untuk build Android.
- Tetapkan level NDK Android minimum ke setidaknya 26.
- Berikan jalur ke Android SDK Anda.
- Setel level API Android SDK ke default (36) dan alat build ke 36.0.0.
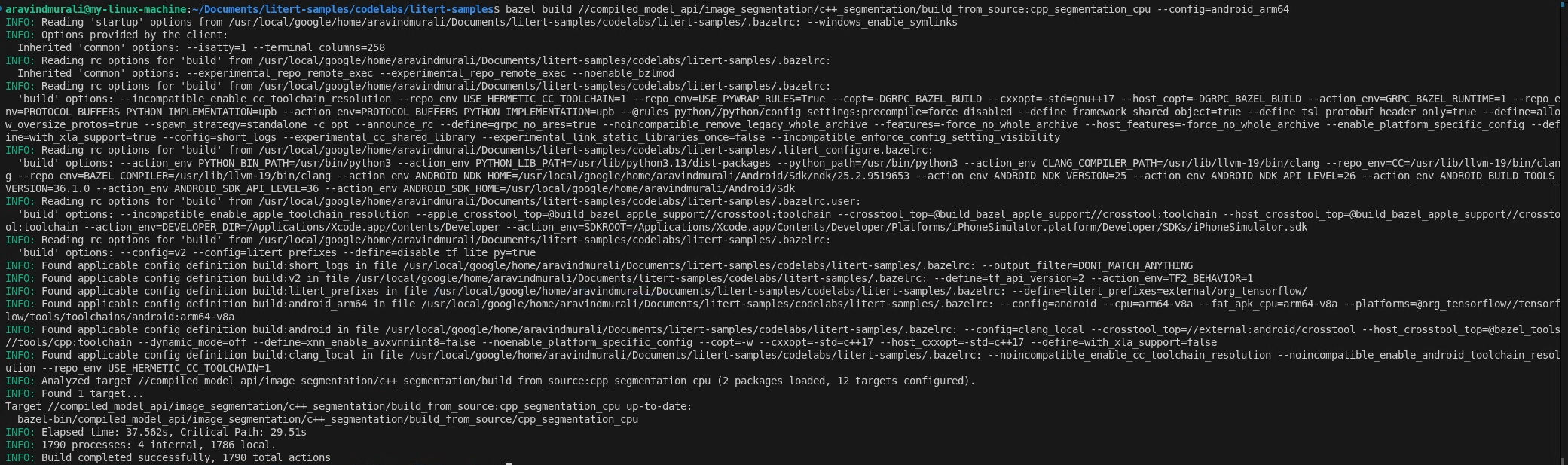
Langkah 2 — Bangun target CPU dan GPU
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Langkah 3 — Bangun target NPU
Qualcomm HTP
- Download QAIRT SDK v2.41 atau yang lebih baru, lalu ekstrak.
- Pastikan konten SDK yang diekstrak berada di dalam subdirektori bernama
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Buat, dengan meneruskan jalur induk yang diakhiri dengan
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Flag --nocheck_visibility diperlukan karena beberapa target LiteRT upstream memiliki default visibilitas terbatas.
APU MediaTek
Tidak diperlukan SDK tambahan. Runtime NeuroPilot adalah library sistem di perangkat Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
File BUILD
Buka build_from_source/BUILD. Library ini menentukan empat target cc_binary — satu per akselerator ditambah target NPU MediaTek khusus — yang masing-masing bergantung pada target library image_processor, image_utils, dan timing_utils bersama:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
Target GPU menambahkan libLiteRtClGlAccelerator.so sebagai dependensi data sehingga Bazel menyertakannya dalam file yang dapat dijalankan. Target NPU menambahkan file .so plugin pengiriman vendor dan compiler sebagai dependensi data.
8. Pra-Pemrosesan yang Dipercepat GPU dengan Shader Komputasi
Ketiga titik entri menggunakan pipeline shader komputasi OpenGL ES yang sama untuk praproses. Memahaminya adalah kunci untuk memahami mengapa jalur GPU jauh lebih cepat daripada jalur CPU.
Menyiapkan konteks EGL headless
ImageProcessor::InitializeGL() membuat konteks EGL tanpa tampilan — konteks OpenGL tanpa jendela atau tampilan terlampir. Ini adalah praktik standar untuk komputasi GPU di luar layar di Android. Kemudian, program ini mengompilasi lima program shader komputasi GLSL dari disk:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Mengupload gambar input ke GPU
JPEG didekodekan ke dalam memori CPU oleh ImageUtils::LoadImage() (melalui library STB), lalu diupload ke tekstur GPU:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
Mulai saat ini, gambar asli berada di memori GPU sebagai tekstur OpenGL.
Shader komputasi pra-pemrosesan
shaders/preprocess_compute.glsl mengirimkan grup thread 8x8 di seluruh petak output 256x256. Setiap thread menangani satu piksel output: thread mengambil sampel tekstur input menggunakan pemfilteran bilinear (pengubahan ukuran hardware gratis), mengonversi nilai RGB [0, 1] menjadi [-1, 1], dan menulis ke SSBO output:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Untuk jalur standar (non-zero-copy), SSBO ini kemudian dibaca kembali ke CPU dan ditulis ke dalam tensor LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Inferensi CPU
Buka main_cpu.cc. Penyiapan LiteRT terdiri dari tiga baris:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Setelah praproses, inferensi adalah satu panggilan sinkron:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() memblokir hingga inferensi selesai. Model floating-point selfie_multiclass_256x256.tflite berjalan di core ARM Cortex dan biasanya memerlukan waktu ~116–128 md di perangkat kelas menengah.
Penggunaan biner:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Inferensi GPU (OpenCL)
Buka main_gpu.cc. Jalur GPU memperkenalkan dua konsep yang tidak ada di jalur CPU: litert::Options untuk mengonfigurasi akselerator GPU (dengan backend OpenCL), dan eksekusi asinkron.
Mengonfigurasi opsi GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Inferensi asinkron
Jalur GPU menggunakan RunAsync(), bukan Run(). Fungsi ini mengirimkan pekerjaan ke antrean perintah GPU dan segera ditampilkan. Kemudian, Anda menyinkronkan sebelum membaca hasil:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Desain non-blocking ini memungkinkan Anda tumpang-tindih tugas CPU dengan eksekusi GPU dalam pipeline real-time.
Penggunaan biner:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Pasca-pemrosesan — Pisahkan dan Gabungkan
Setelah Run() atau RunAsync() selesai, output_buffers[0] menyimpan array float datar dengan bentuk [256 × 256 × 6] dalam urutan yang diselingi. 6 skor class untuk piksel (row, col) berada pada indeks (row * 256 + col) * 6 hingga (row * 256 + col) * 6 + 5.
Deinterleave menjadi 6 SSBO mask
Helper CPU membagi array yang disisipkan menjadi 6 array float saluran tunggal dan mengupload setiap array ke SSBO GPU-nya sendiri:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Memadukan warna mask ke gambar asli
processor.ApplyColoredMasks() menjalankan shader mask_blend_compute.glsl. Untuk setiap piksel output, model menemukan kelas dengan skor tertinggi (argmax di seluruh SSBO mask 6) dan menggabungkan warna yang sesuai dengan piksel gambar asli menggunakan alpha. Enam warna ditentukan di setiap titik entri:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
Alpha 0.1f menjaga warna tetap halus sehingga gambar asli tetap terlihat.
Menyimpan output
SSBO float RGBA akhir yang digabungkan dibaca kembali, di-clamp ke [0, 1], dikonversi ke unsigned char, dan disimpan sebagai PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Men-deploy dan Menjalankan di Perangkat
Hubungkan perangkat Android Anda menggunakan USB dan verifikasi konektivitas ADB:
adb devices

Gunakan deploy_and_run_on_android.sh
Setiap varian memiliki skrip deployment-nya sendiri. Varian CMake mengarah ke direktori build/; varian Bazel mengarah ke bazel-bin/. Kedua skrip:
- Buat
/data/local/tmp/cpp_segmentation_android/di perangkat. - Kirim file biner, shader GLSL, model, gambar pengujian, dan runtime
.so. - Jalankan inferensi menggunakan
adb shell. - Tarik
output_segmented.pngkembali ke komputer Anda.
Varian CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Varian Bazel (build_from_source/)
Jalankan perintah ini dari root repo sampelLiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
Flag --phone mengontrol library vendor dan model khusus perangkat yang digunakan. Nilai yang didukung: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5), dan pixel11 (Tensor G6).
Waktu Inferensi
Setelah inferensi, PrintTiming() mencetak perincian pembuatan profil lengkap:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Performa referensi di Samsung S25 Ultra (Snapdragon 8 Elite):
Akselerator | Jenis eksekusi | Inferensi | E2E |
CPU | Sinkronisasi | ~116–128 md | ~157 md |
GPU (OpenCL) | Asinkron | ~0,95 md | ~35–43 md |
13. Lanjutan (Opsional): Inferensi NPU
Untuk performa maksimal, LiteRT mendukung akselerasi NPU menggunakan library plugin khusus vendor. Jalur NPU dapat mencapai latensi end-to-end serendah 9 md.
Perangkat dan mode yang didukung
Chip | Contoh perangkat | Mode | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 md |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 md |
Qualcomm (apa saja) | — | JIT | ~28 md |
MediaTek Dimensity 9400 | — | JIT | ~9 md |
Google Tensor G3-G6 | Pixel 8-11 | AOT/JIT | Bervariasi |
AOT (Ahead-of-Time) menggunakan model pra-kompilasi khusus perangkat (misalnya, selfie_multiclass_256x256_SM8650.tflite). Ini adalah opsi tercepat, tetapi khusus untuk chip.
JIT (Just-in-Time) menggunakan selfie_multiclass_256x256.tflite standar dan dikompilasi ke NPU saat runtime — lebih lambat pada run pertama, tidak bergantung pada chip.
Prasyarat tambahan
Qualcomm HTP:
- QAIRT SDK v2.41+ (menyediakan file
libQnnHtp.so, stub, atau skel.so). libLiteRtDispatch_Qualcomm.sodari rilis library runtime NPU LiteRT di GitHub.
APU MediaTek:
libLiteRtDispatch_MediaTek.sodari rilis library runtime NPU LiteRT.- Runtime NeuroPilot (sudah menjadi library sistem di perangkat Dimensity 9400 — tidak perlu melakukan push).
Google Tensor:
libLiteRtDispatch_GoogleTensor.sodari rilis library runtime NPU LiteRT.
Lingkungan dan opsi NPU
main_npu.cc mengarahkan Environment ke direktori library pengiriman vendor di perangkat, lalu menetapkan opsi performa khusus vendor:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
Untuk MediaTek, ganti blok GetQualcommOptions():
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Men-deploy untuk NPU
Varian CMake — Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Varian CMake — MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Varian Bazel — Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Varian Bazel — MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Varian Bazel — Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Untuk varian Bazel, library QAIRT SDK diambil secara otomatis dari hierarki file yang dijalankan bazel-bin saat LITERT_QAIRT_SDK disetel pada waktu build. Varian CMake memerlukan flag --host_npu_lib untuk mengarah ke QAIRT SDK yang diekstrak.
14. Selamat!
Anda telah berhasil membuat dan menjalankan pipeline segmentasi gambar C++ di Android menggunakan LiteRT. Anda telah mempelajari cara:
- Lakukan kompilasi silang biner C++ untuk Android
arm64-v8adengan CMake + NDK atau Bazel. - Gunakan LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) untuk inferensi efisien di perangkat. - Memproses data gambar di GPU dengan shader komputasi OpenGL ES 3.1.
- Menjalankan inferensi CPU sinkron, dan inferensi GPU (OpenCL) asinkron.
- Mengonfigurasi akselerasi NPU untuk perangkat Qualcomm, MediaTek, dan Google Tensor.
- Men-deploy dan menjalankan biner C++ di Android menggunakan ADB.
Langkah Berikutnya
- Ganti dengan model TFLite lain (misalnya, estimasi kedalaman atau deteksi postur).
- Integrasikan pipeline C++ ke dalam aplikasi Android NDK menggunakan JNI.
- Membuat profil penggunaan memori dengan Android GPU Inspector bersama dengan output pengaturan waktu.
- Jelajahi kuantisasi model untuk lebih mengurangi latensi inferensi NPU.