
1. शुरू करने से पहले
कोड टाइप करने से, आपको कोड याद रखने में मदद मिलती है. साथ ही, इससे आपको कॉन्टेंट को बेहतर तरीके से समझने में मदद मिलती है. कॉपी-पेस्ट करने से समय बच सकता है. हालांकि, इस तरीके का इस्तेमाल करने से, लंबे समय में कोडिंग की बेहतर क्षमताएं हासिल की जा सकती हैं और कोडिंग को ज़्यादा असरदार बनाया जा सकता है.
इस कोडलैब में, आपको C++ इमेज सेगमेंटेशन बाइनरी बनाने का तरीका बताया जाएगा. यह बाइनरी, Google के हाई-परफ़ॉर्मेंस वाले ऑन-डिवाइस रनटाइम, LiteRT का इस्तेमाल करके सीधे तौर पर Android डिवाइस पर चलती है. इस कोडलैब में, Kotlin या Android Studio का इस्तेमाल करने के बजाय, C++ बाइनरी बनाने पर फ़ोकस किया गया है. इसे CMake या Bazel के साथ क्रॉस-कंपाइल किया जाएगा और ADB का इस्तेमाल करके डिप्लॉय किया जाएगा. LiteRT C++ API, किसी भी प्लैटफ़ॉर्म (Android, Linux, एम्बेड किया गया) पर काम करता है. इसलिए, यह परफ़ॉर्मेंस के लिहाज़ से ज़रूरी ऐप्लिकेशन, रोबोटिक्स, और एज सिस्टम के लिए एक उपयोगी आधार है.
आपको पूरी पाइपलाइन के बारे में बताया जाएगा:
- बिल्ड एनवायरमेंट सेट अप करना (CMake + Android NDK या Bazel).
- LiteRT C++ SDK को लिंक करना — पहले से बनी रिलीज़ से या सोर्स से.
- जीपीयू की मदद से इमेज को तेज़ी से प्रोसेस करने के लिए, OpenGL ES कंप्यूट शेडर का इस्तेमाल किया जाता है.
- LiteRT C++ API की मदद से,
selfie_multiclassसेगमेंटेशन मॉडल को चलाया जा रहा है. - सीपीयू, जीपीयू (OpenCL), और एनपीयू (Qualcomm / MediaTek) पर अनुमान लगाने की प्रोसेस को तेज़ किया गया है.
- कच्चे मॉडल के आउटपुट को पोस्टप्रोसेस करके, रंग के हिसाब से सेगमेंट की गई इमेज में बदला गया है.
- ADB की मदद से, किसी Android डिवाइस पर ऐप्लिकेशन को डिप्लॉय करना और नतीजे पाना.
आखिर में, आपको कुछ ऐसी इमेज मिलेगी. यह पूरी पाइपलाइन के ज़रिए प्रोसेस की गई एक स्टैटिक इमेज है. इसमें सेगमेंटेशन की छह क्लास में से हर एक को अलग रंग में दिखाया गया है:

ज़रूरी शर्तें
यह कोडलैब, C++ का इस्तेमाल करने वाले डेवलपर के लिए बनाया गया है. इसमें, C++ लेयर पर Android में मशीन लर्निंग मॉडल चलाने का तरीका बताया गया है. आपको इनके बारे में जानकारी होनी चाहिए:
- C++ की बुनियादी बातें (पॉइंटर, वेक्टर, शामिल करें).
- Android/ADB के बुनियादी कॉन्सेप्ट (
adb push,adb shell). - Linux या macOS पर टर्मिनल और शेल स्क्रिप्ट का इस्तेमाल करना.
आपको क्या सीखने को मिलेगा
- CMake + NDK या Bazel का इस्तेमाल करके, Android
arm64-v8aके लिए C++ बाइनरी को क्रॉस-कंपाइल करने का तरीका. - डिवाइस पर बेहतर तरीके से अनुमान लगाने के लिए, LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) का इस्तेमाल कैसे करें. - OpenGL ES 3.1 के कंप्यूट शेडर, प्री-प्रोसेसिंग और पोस्ट-प्रोसेसिंग को पूरी तरह से जीपीयू पर कैसे तेज़ करते हैं.
- सीपीयू, जीपीयू (OpenCL), और एनपीयू (Qualcomm HTP, MediaTek APU, Google Tensor) ऐक्सेलरेटर के लिए LiteRT को कॉन्फ़िगर करने का तरीका.
- सिंक्रोनस (
Run) और एसिंक्रोनस (RunAsync) इन्फ़रेंस के बीच अंतर. - ADB का इस्तेमाल करके, Android पर C++ बाइनरी को डिप्लॉय और चलाने का तरीका.
आपको किन चीज़ों की ज़रूरत होगी
- Linux या macOS मशीन (Windows का इस्तेमाल करने वाले लोगों को WSL2 का इस्तेमाल करना चाहिए).
- Android NDK r25c या इसके बाद का वर्शन (डाउनलोड करें).
- CMake पाथ के लिए: CMake ≥ 3.22 (
sudo apt-get install cmake). - Bazel पाथ के लिए: Bazel इंस्टॉल किया गया हो. साथ ही, LiteRT के सभी सैंपल वाली रिपॉज़िटरी मौजूद हो.
- अपने
PATH(Android प्लैटफ़ॉर्म टूल) में ADB. - Android डिवाइस — इसे Galaxy S24/S25 या Pixel पर सबसे अच्छी तरह से टेस्ट किया जा सकता है.
2. इमेज सेगमेंटेशन
इमेज सेगमेंटेशन, कंप्यूटर विज़न का एक टास्क है. इसमें किसी इमेज के हर पिक्सल को क्लास लेबल असाइन किया जाता है. ऑब्जेक्ट डिटेक्शन में, बाउंडिंग बॉक्स बनाया जाता है. हालांकि, सेगमेंटेशन में हर ऑब्जेक्ट के शुरू और खत्म होने की सटीक जानकारी मिलती है.
इस कोडलैब में selfie_multiclass_256x256 मॉडल का इस्तेमाल किया गया है. यह मॉडल, हर पिक्सल को छह क्लास में से किसी एक में बांटता है:
क्लास इंडेक्स | सेगमेंट |
0 | बैकग्राउंड |
1 | बाल |
2 | शरीर की त्वचा |
3 | चेहरे की त्वचा |
4 | कपड़े |
5 | ऐक्सेसरी (चश्मा, गहने वगैरह) |
मॉडल, [1, 256, 256, 6] शेप का फ़्लोट टेंसर आउटपुट करता है. हर 256×256 पिक्सल के लिए, भरोसेमंद होने के छह स्कोर होते हैं. हर क्लास के लिए एक स्कोर. जिस क्लास का स्कोर सबसे ज़्यादा होता है वह पिक्सल जीत जाती है (argmax).
LiteRT: परफ़ॉर्मेंस ऐट द एज
LiteRT, TFLite मॉडल के लिए Google का बनाया हुआ, अगली-पीढ़ी की टेक्नोलॉजी वाला हाई-परफ़ॉर्मेंस रनटाइम है. इसके C++ एपीआई की मदद से, आपको हार्डवेयर ऐक्सलरेटर का ऐक्सेस मिलता है. साथ ही, तीनों के लिए एक जैसा इंटरफ़ेस मिलता है:
- सीपीयू — सभी डिवाइसों के साथ काम करता है; मिड-रेंज डिवाइस पर ~128 मि॰से॰ में अनुमान लगाता है.
- जीपीयू (OpenCL) — अनुमान लगाने में ~1 मि॰से॰ लगता है; बफ़र की रणनीति के आधार पर, शुरू से आखिर तक ~17–43 मि॰से॰ लगते हैं.
- एनपीयू — Qualcomm Snapdragon, MediaTek Dimensity 9400, और Google Tensor डिवाइसों पर, एओटी के आधार पर ~9–28 मि॰से॰. JIT कंपाइलेशन.
मुख्य ऐब्स्ट्रैक्शन CompiledModel है: मॉडल को लोड करने के समय, टारगेट हार्डवेयर के लिए पहले से कंपाइल और ऑप्टिमाइज़ किया जाता है. इससे, अनुमान लगाने की प्रोसेस को पहले से तय किए गए बफ़र पर Run() कॉल तक सीमित किया जा सकता है.
3. सेट अप करें
रिपॉज़िटरी को क्लोन करना
git clone https://github.com/google-ai-edge/litert-samples.git
इस कोडलैब के सभी संसाधन यहां मौजूद हैं:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
इस डायरेक्ट्री में दो सब-प्रोजेक्ट हैं. दोनों एक ही सैंपल के पूरे बिल्ड हैं:
डायरेक्ट्री | बिल्ड सिस्टम | LiteRT डिपेंडेंसी |
| CMake + Android NDK | पहले से तैयार किए गए |
| Bazel | सोर्स से LiteRT को कंपाइल करता है |
कोई एक तरीका चुनें और उसका पालन करें. दोनों डायरेक्ट्री में कोड एक जैसा है. सिर्फ़ बिल्ड सिस्टम और डिपेंडेंसी की रणनीति अलग-अलग है. अगर आपको सबसे तेज़ सेटअप चाहिए, तो use_prebuilt_litert/ को चुनें. अगर आपको LiteRT में बदलाव करना है या किसी मौजूदा Bazel मोनोरिपो में काम करना है, तो build_from_source/ का इस्तेमाल करें.
फ़ाइल पाथ के बारे में जानकारी
इस ट्यूटोरियल में, फ़ाइल के सभी पाथ Linux/macOS फ़ॉर्मैट का इस्तेमाल करते हैं. Windows का इस्तेमाल करने वाले लोगों को WSL2 का इस्तेमाल करना चाहिए.
डायरेक्ट्री की खास जानकारी
दोनों सब-प्रोजेक्ट में एक ही सोर्स लेआउट का इस्तेमाल किया जाता है:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
इसके अलावा:
use_prebuilt_litert/नेCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.sh, औरthird_party/stb/को जोड़ा है.build_from_source/, BazelBUILDफ़ाइल जोड़ता है औरbazel-bin/की ओर इशारा करने वालेdeploy_and_run_on_android.shका इस्तेमाल करता है.
4. प्रोजेक्ट के स्ट्रक्चर को समझना
तीन एंट्री पॉइंट, एक पाइपलाइन
main_cpu.cc, main_gpu.cc, और main_npu.cc में से हर एक में main() फ़ंक्शन होता है, जो पूरे सेगमेंटेशन पाइपलाइन को कंट्रोल करता है. तीनों में पाइपलाइन एक जैसी है. सिर्फ़ LiteRT ऐक्सलरेटर कॉन्फ़िगरेशन और बफ़र रणनीति अलग-अलग है:
फ़ाइल | Accelerator | बफ़र की रणनीति |
|
| सीपीयू मेमोरी |
|
| OpenCL बैकएंड के साथ सीपीयू मेमोरी |
|
| सीपीयू फ़ॉलबैक के साथ सीपीयू मेमोरी |
इन तीनों में, ImageProcessor (प्रीप्रोसेसिंग और पोस्टप्रोसेसिंग के लिए OpenGL ES कंप्यूट शेडर) और ImageUtils (एसटीबी इमेज I/O) यूटिलिटी का इस्तेमाल किया जाता है.
पूरी पाइपलाइन
हर एंट्री पॉइंट में पांच चरणों का स्ट्रक्चर होता है:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- लोड करें —
ImageUtils::LoadImage()STB इमेज लाइब्रेरी का इस्तेमाल करके, JPEG को सीपीयू मेमोरी में डिकोड करता है. - अपलोड करें —
processor.CreateOpenGLTexture(), रॉ पिक्सल को GPU टेक्सचर (OpenGL RGBA8) में अपलोड करता है. - प्रीप्रोसेस —
processor.PreprocessInputForSegmentation(), GLSL कंप्यूट शेडर चलाता है. यह शेडर, टेक्सचर का साइज़ बदलकर 256×256 कर देता है. साथ ही, पिक्सल वैल्यू को[0, 1]से[-1, 1]तक सामान्य कर देता है. नतीजा, GPU SSBO में दिखता है. - अनुमान लगाना — SSBO डेटा को LiteRT
TensorBufferमें लिखा जाता है औरcompiled_model.Run()(याRunAsync()) मॉडल को एक्ज़ीक्यूट करता है. - पोस्टप्रोसेस — मॉडल के छह-चैनल वाले फ़्लोट आउटपुट को छह सिंगल-चैनल मास्क SSBO में बदल दिया जाता है. इसके बाद, इन्हें ओरिजनल इमेज पर वापस रंग के साथ ब्लेंड कर दिया जाता है.
- सेव करें —
ImageUtils::SaveImage()फ़ाइनल RGBA इमेज को PNG के तौर पर लिखता है.
5. Core LiteRT C++ API
बनाने से पहले, LiteRT C++ के तीन मुख्य टाइप के बारे में जान लें. इनका इस्तेमाल सभी एंट्री पॉइंट पर किया जाता है. ये सभी litert:: नेमस्पेस में मौजूद हैं.
litert::Environment
Environment, LiteRT के सभी ऑपरेशन के लिए रूट कॉन्टेक्स्ट है. इसे एक बार बनाएं और CompiledModel::Create को पास करें. एनपीयू के इस्तेमाल के लिए, इसे वेंडर प्लगिन लाइब्रेरी डायरेक्ट्री के साथ कॉन्फ़िगर करें.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel, अनुरोध किए गए हार्डवेयर के लिए, कंस्ट्रक्शन के समय आपके TFLite मॉडल को लोड और प्री-कंपाइल करता है. इसके बाद, अनुमान लगाने की प्रोसेस में बफ़र भरने और Run() को कॉल करने की प्रोसेस शामिल होती है.
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
टेंसर बफ़र, इनपुट/आउटपुट डेटा को सेव करते हैं. इन्हें हमेशा CompiledModel से बनाएं, ताकि ये टारगेट किए गए हार्डवेयर के लिए सही साइज़ के हों और सही तरीके से अलाइन किए गए हों.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
गड़बड़ी ठीक करने वाले मैक्रो
मैक्रो | व्यवहार |
| यह कुकी, अनुरोध पूरा न होने पर |
| एक्सप्रेशन से गड़बड़ी का पता चलने पर, |
| यह फ़ंक्शन, कॉल करने वाले व्यक्ति को गड़बड़ी असाइन करता है या उसके बारे में बताता है |
6. बिल्ड — विकल्प A: पहले से बनाया गया LiteRT C++ SDK (CMake)
अगर आपको LiteRT में बदलाव नहीं करना है, तो यह तरीका अपनाने का सुझाव दिया जाता है. बिल्ड स्क्रिप्ट, एसडीके हेडर डाउनलोड करने, आपके .so को कॉपी करने, एसटीबी फ़ेच करने, और एक ही कमांड में CMake + NDK को लागू करने का काम करती है.
पहला चरण — Maven से libLiteRt.so पाएं
LiteRT, Google Maven पर Android AAR में, अपने रनटाइम को शेयर की गई लाइब्रेरी के तौर पर शिप करता है. इसे डाउनलोड करें और arm64-v8a .so को एक्सट्रैक्ट करें:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
जीपीयू के लिए, OpenCL/GL ऐक्सलरेटर भी निकालें:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

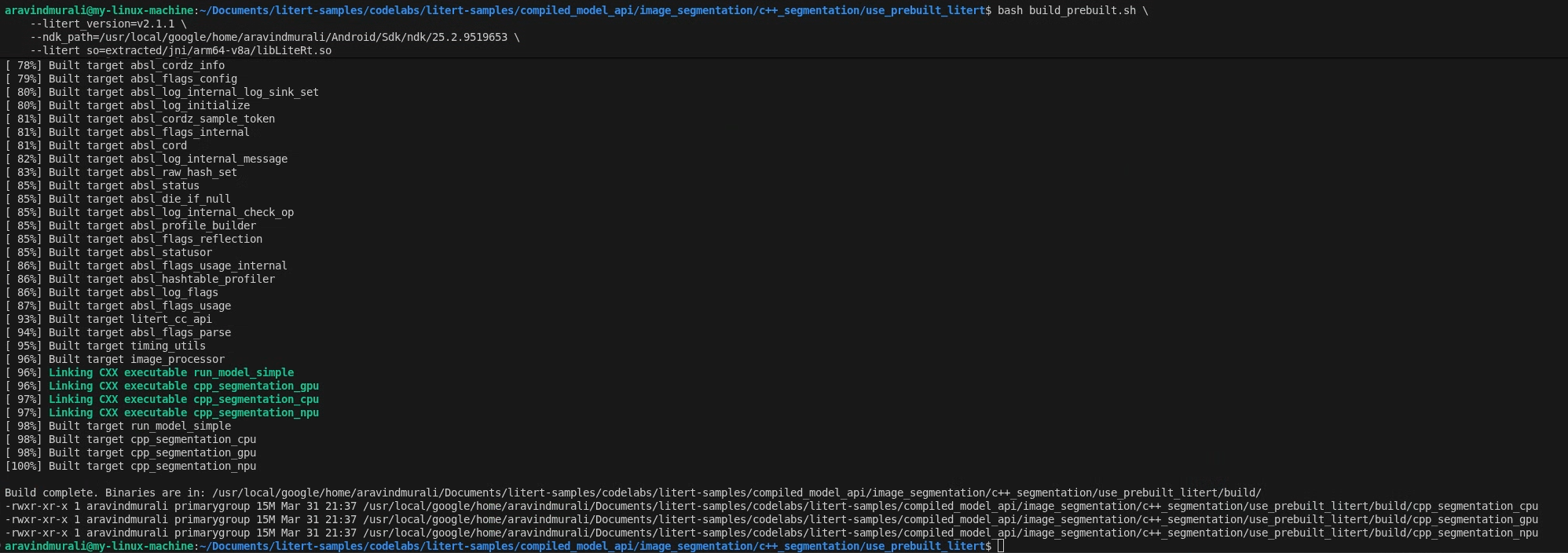
दूसरा चरण — build_prebuilt.sh शुरू करें
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
स्क्रिप्ट में ये काम किए जाएंगे:
- LiteRT GitHub रिलीज़ से
litert_cc_sdk.zip(SDK हेडर + cmake फ़ाइलें) डाउनलोड करें. अगर ये फ़ाइलें पहले से मौजूद हैं, तो बाद में इन्हें डाउनलोड नहीं किया जाएगा. libLiteRt.soकोlitert_cc_sdk/में कॉपी करें.- एसटीबी इमेज हेडर को
third_party/stb/में डाउनलोड करें. अगर यह मौजूद है, तो इसे छोड़ दिया जाएगा. android-26परarm64-v8aके लिए, Android NDK टूलचेन का इस्तेमाल करके CMake के साथ कॉन्फ़िगर और बिल्ड करें.
सफल होने पर, आपको build/ में तीन बाइनरी दिखेंगी:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
CMakeLists.txt क्या करता है
CMakeLists.txt खोलें. इसके लिए C++20 की ज़रूरत होती है. यह add_subdirectory के ज़रिए LiteRT SDK को पुल करता है, OpenGL ES 3 (GLESv3) और EGL को लिंक करता है. इसके बाद, main_*.cc सोर्स से हर बाइनरी बनाने के लिए, हेल्पर मैक्रो का इस्तेमाल करता है:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. बनाना — दूसरा विकल्प: Bazel की मदद से बनाना (सोर्स से)
अगर आपको Bazel को अपने बिल्ड सिस्टम के तौर पर इस्तेमाल करना है, तो यह पाथ चुनें. Bazel, सोर्स से LiteRT रनटाइम को कंपाइल करता है. इसके अलावा, अगर आपको किसी मौजूदा Bazel वर्कस्पेस में काम करना है, तो भी यह पाथ चुनें.
ज़रूरी शर्तें
"शुरू करने से पहले" सेक्शन में दिए गए NDK और ADB के अलावा, आपको इनकी भी ज़रूरत होगी:
- आपके
PATHपर Bazel इंस्टॉल हो. - LiteRT के सैंपल सोर्स रिपॉज़िटरी का पूरा क्लोन.
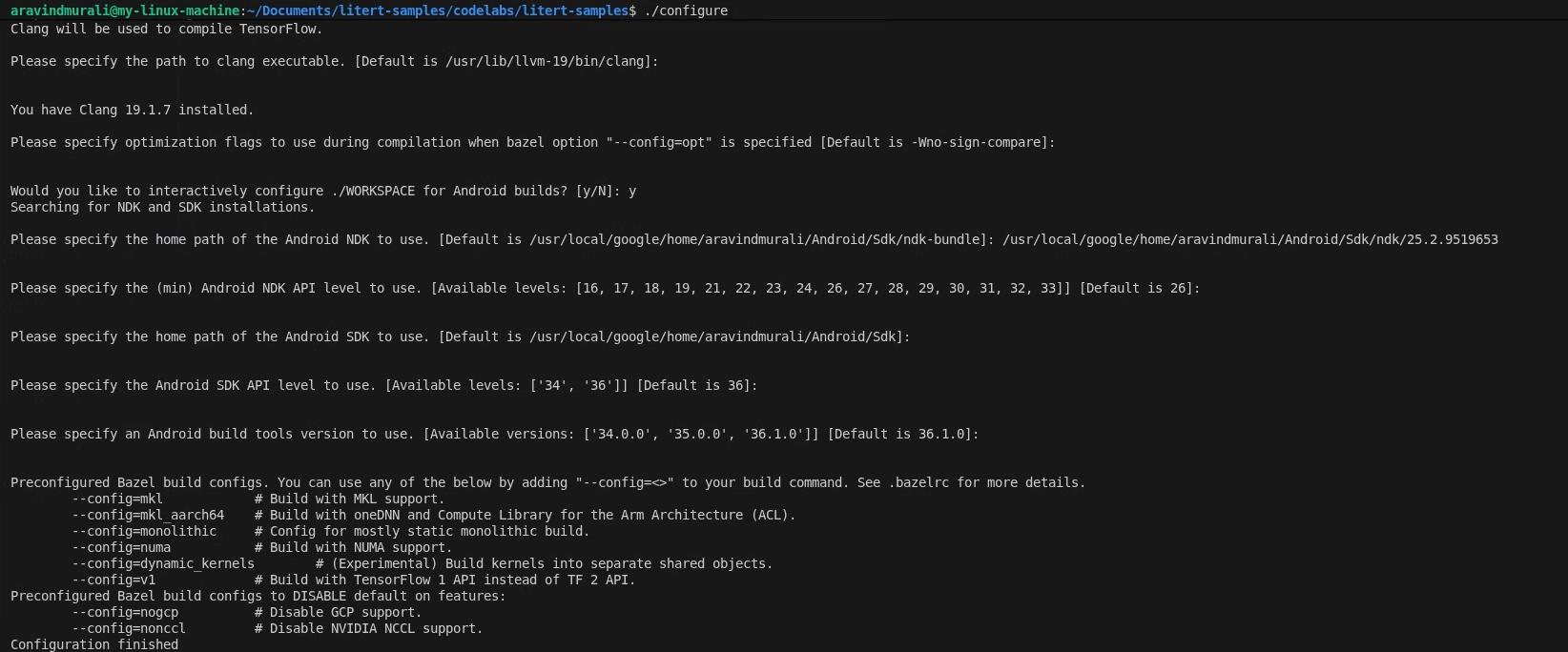
पहला चरण — LiteRT के सैंपल वर्कस्पेस को कॉन्फ़िगर करना
सभी कमांड, LiteRT के सैंपल रिपॉज़िटरी के रूट से चलती हैं
cd /path/to/litert-samples
./configure
प्रॉम्प्ट दिखने पर:
- Python और Python lib पाथ के लिए डिफ़ॉल्ट सेटिंग स्वीकार करें.
- ROCm और CUDA के साथ काम करने की सुविधा के लिए, N पर क्लिक करें.
- कंपाइलर के तौर पर clang (18.1.3 के साथ टेस्ट किया गया) चुनें.
- डिफ़ॉल्ट ऑप्टिमाइज़ेशन फ़्लैग स्वीकार करें.
- Android बिल्ड के लिए WORKSPACE को कॉन्फ़िगर करने के लिए, Y पर क्लिक करें.
- Android NDK का कम से कम लेवल 26 पर सेट करें.
- अपने Android SDK का पाथ दें.
- Android SDK के एपीआई लेवल को डिफ़ॉल्ट (36) पर सेट करें और बिल्ड टूल को 36.0.0 पर सेट करें.
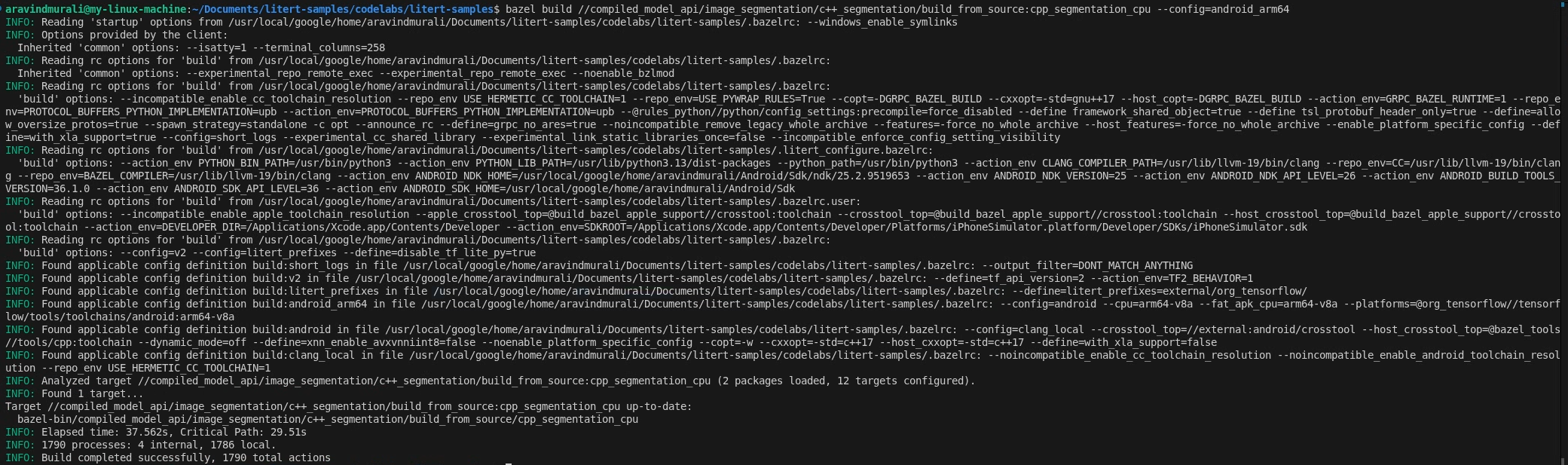
दूसरा चरण — सीपीयू और जीपीयू टारगेट बनाना
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
तीसरा चरण — एनपीयू का टारगेट सेट करना
Qualcomm HTP
- QAIRT SDK v2.41 या इसके बाद का वर्शन डाउनलोड करें और उसे एक्सट्रैक्ट करें.
- पक्का करें कि निकाले गए SDK टूल का कॉन्टेंट,
latest/नाम की सबडायरेक्ट्री में हो:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - बनाएं. इसके लिए, पैरंट पाथ के आखिर में
/जोड़ें:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
--nocheck_visibility फ़्लैग ज़रूरी है, क्योंकि अपस्ट्रीम LiteRT के कुछ टारगेट के लिए, दिखने की डिफ़ॉल्ट सेटिंग पर पाबंदी लगी होती है.
MediaTek APU
इसके लिए, किसी अन्य एसडीके की ज़रूरत नहीं होती. NeuroPilot रनटाइम, Dimensity 9400 डिवाइसों पर एक सिस्टम लाइब्रेरी है.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
BUILD फ़ाइल
build_from_source/BUILD खोलें. इसमें चार cc_binary टारगेट तय किए गए हैं. हर ऐक्सलरेटर के लिए एक टारगेट और MediaTek NPU के लिए एक अलग टारगेट. ये सभी, शेयर की गई image_processor, image_utils, और timing_utils लाइब्रेरी टारगेट पर निर्भर करते हैं:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
GPU टारगेट, libLiteRtClGlAccelerator.so को डेटा डिपेंडेंसी के तौर पर जोड़ता है, ताकि Bazel इसे रनफ़ाइल में शामिल कर सके. एनपीयू टारगेट, वेंडर डिस्पैच और कंपाइलर प्लगिन .so फ़ाइलों को डेटा डिपेंडेंसी के तौर पर जोड़ते हैं.
8. कंप्यूट शेडर की मदद से, जीपीयू की मदद से तेज़ी से प्रीप्रोसेसिंग करना
तीनों एंट्री पॉइंट, प्रीप्रोसेसिंग के लिए एक ही OpenGL ES कंप्यूट शेडर पाइपलाइन का इस्तेमाल करते हैं. इसे समझना इसलिए ज़रूरी है, ताकि यह पता चल सके कि जीपीयू पाथ, सीपीयू पाथ से इतना ज़्यादा तेज़ क्यों है.
हेडलेस EGL कॉन्टेक्स्ट सेट अप करना
ImageProcessor::InitializeGL() एक हेडलेस EGL कॉन्टेक्स्ट बनाता है. यह एक ऐसा OpenGL कॉन्टेक्स्ट होता है जिसमें कोई विंडो या डिसप्ले अटैच नहीं होता. Android पर, स्क्रीन से बाहर जीपीयू कंप्यूट के लिए यह स्टैंडर्ड तरीका है. इसके बाद, यह डिस्क से पांच GLSL कंप्यूट शेडर प्रोग्राम कंपाइल करता है:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
इनपुट इमेज को GPU पर अपलोड करना
JPEG को ImageUtils::LoadImage() (एसटीबी लाइब्रेरी के ज़रिए) सीपीयू मेमोरी में डिकोड किया जाता है. इसके बाद, इसे GPU टेक्सचर पर अपलोड किया जाता है:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
इस पॉइंट से, ओरिजनल इमेज, जीपीयू मेमोरी में OpenGL टेक्सचर के तौर पर सेव हो जाती है.
प्रीप्रोसेस कंप्यूट शेडर
shaders/preprocess_compute.glsl 8×8 थ्रेड ग्रुप को 256×256 आउटपुट ग्रिड में डिसपैच करता है. हर थ्रेड, एक आउटपुट पिक्सल को हैंडल करता है: यह बाइलिनियर फ़िल्टरिंग (मुफ़्त में हार्डवेयर का साइज़ बदलने की सुविधा) का इस्तेमाल करके, इनपुट टेक्सचर का सैंपल लेता है. साथ ही, [0, 1] आरजीबी वैल्यू को [-1, 1] में बदलता है और आउटपुट एसएसबीओ में लिखता है:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
स्टैंडर्ड (नॉन-ज़ीरो-कॉपी) पाथ के लिए, इस SSBO को वापस सीपीयू में पढ़ा जाता है और LiteRT टेंसर में लिखा जाता है:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. सीपीयू इंफ़रंस
main_cpu.cc खोलें. LiteRT का सेटअप तीन लाइनों का होता है:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
प्रीप्रोसेसिंग के बाद, अनुमान लगाने के लिए एक ही सिंक्रोनस कॉल किया जाता है:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run(), अनुमान लगाने की प्रोसेस पूरी होने तक ब्लॉक करता है. selfie_multiclass_256x256.tflite फ़्लोटिंग-पॉइंट मॉडल, ARM Cortex कोर पर काम करता है. आम तौर पर, यह मॉडल मिड-रेंज डिवाइस पर ~116–128 मि॰से॰ लेता है.
बाइनरी का इस्तेमाल:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. GPU Inference (OpenCL)
main_gpu.cc खोलें. जीपीयू पाथ में दो ऐसे कॉन्सेप्ट शामिल हैं जो सीपीयू पाथ में मौजूद नहीं हैं: litert::Options, OpenCL बैकएंड के साथ जीपीयू ऐक्सेलरेटर को कॉन्फ़िगर करने के लिए और एसिंक्रोनस एक्ज़ीक्यूशन के लिए.
GPU के विकल्प कॉन्फ़िगर करना
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
एसिंक्रोनस इन्फ़रेंस
GPU पाथ में Run() के बजाय RunAsync() का इस्तेमाल किया जाता है. इससे काम को जीपीयू कमांड लाइन में सबमिट किया जाता है और यह तुरंत वापस आ जाता है. इसके बाद, नतीजों को पढ़ने से पहले सिंक करें:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
इस नॉन-ब्लॉकिंग डिज़ाइन की मदद से, रीयल-टाइम पाइपलाइन में सीपीयू के काम को जीपीयू के एक्ज़ीक्यूशन के साथ ओवरलैप किया जा सकता है.
बाइनरी का इस्तेमाल:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. प्रोसेस होने के बाद — डीइंटरलीव और ब्लेंड करें
Run() या RunAsync() पूरा होने के बाद, output_buffers[0] में इंटरलीव किए गए क्रम में [256 × 256 × 6] शेप का फ़्लैट फ़्लोट ऐरे होता है. पिक्सेल (row, col) के लिए छह क्लास स्कोर, इंडेक्स (row * 256 + col) * 6 से (row * 256 + col) * 6 + 5 पर हैं.
मास्क किए गए छह एसएसबीओ में अलग-अलग करें
सीपीयू हेल्पर, इंटरलीव किए गए ऐरे को छह सिंगल-चैनल फ़्लोट ऐरे में बांटता है. इसके बाद, हर ऐरे को अपने जीपीयू एसएसबीओ पर अपलोड करता है:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
ओरिजनल इमेज पर कलर-ब्लेंड मास्क
processor.ApplyColoredMasks(), mask_blend_compute.glsl शेडर को चलाता है. यह हर आउटपुट पिक्सल के लिए, सबसे ज़्यादा स्कोर वाला क्लास ढूंढता है (छह मास्क एसएसबीओ में से सबसे ज़्यादा). इसके बाद, ओरिजनल इमेज पिक्सल पर उससे जुड़े रंग को ऐल्फ़ा-कंपोज़िट करता है. छह रंगों को हर एंट्री पॉइंट में तय किया जाता है:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
0.1f के ऐल्फ़ा से, रंग हल्का रहता है. इससे ओरिजनल इमेज दिखती रहती है.
आउटपुट सेव करना
फ़ाइनल ब्लेंड किए गए RGBA फ़्लोट SSBO को वापस पढ़ा जाता है. इसे [0, 1] पर क्लैंप किया जाता है, unsigned char में बदला जाता है, और PNG के तौर पर सेव किया जाता है:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. डिप्लॉय करें और डिवाइस पर चलाएं
यूएसबी का इस्तेमाल करके अपने Android डिवाइस को कनेक्ट करें और एडीबी कनेक्टिविटी की पुष्टि करें:
adb devices

deploy_and_run_on_android.sh का इस्तेमाल करें
हर वैरिएंट की अपनी डिप्लॉय स्क्रिप्ट होती है. CMake वैरिएंट, build/ डायरेक्ट्री की ओर इशारा करता है. वहीं, Bazel वैरिएंट, bazel-bin/ की ओर इशारा करता है. दोनों स्क्रिप्ट:
- डिवाइस पर
/data/local/tmp/cpp_segmentation_android/बनाएं. - बाइनरी, GLSL शेडर, मॉडल, टेस्ट इमेज, और रनटाइम
.soफ़ाइलें पुश करें. adb shellका इस्तेमाल करके अनुमान लगाएं.output_segmented.pngको वापस अपनी मशीन पर खींचें.
CMake वैरिएंट (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Bazel वैरिएंट (build_from_source/)
LiteRT samples repo root से ये कमांड चलाएं:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
--phone फ़्लैग से यह कंट्रोल किया जाता है कि डिवाइस के हिसाब से कौनसे मॉडल और वेंडर लाइब्रेरी इस्तेमाल की जाती हैं. इन वैल्यू का इस्तेमाल किया जा सकता है: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5), और pixel11 (Tensor G6).
अनुमान लगाने का समय
अनुमान लगाने के बाद, PrintTiming() पूरी प्रोफ़ाइलिंग का ब्यौरा प्रिंट करता है:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Samsung S25 Ultra (Snapdragon 8 Elite) पर परफ़ॉर्मेंस का रेफ़रंस:
Accelerator | एक्ज़ीक्यूशन का टाइप | अनुमान | E2E |
सीपीयू | सिंक करें | ~116–128 मि॰से॰ | ~157 मि॰से॰ |
GPU (OpenCL) | Async | ~0.95 मि॰से॰ | ~35–43 मि॰से॰ |
13. ऐडवांस (ज़रूरी नहीं): एनपीयू इन्फ़रेंस
बेहतरीन परफ़ॉर्मेंस के लिए, LiteRT वेंडर के हिसाब से प्लगिन लाइब्रेरी का इस्तेमाल करके, एनपीयू को तेज़ करने की सुविधा देता है. एनपीयू पाथ से, एंड-टू-एंड लेटेंसी को 9 मि॰से॰ तक कम किया जा सकता है.
साथ काम करने वाले डिवाइस और मोड
चिप | डिवाइस का उदाहरण | मोड | E2E |
Qualcomm SM8650 | Galaxy S24 | एओटी | ~17 मि॰से॰ |
Qualcomm SM8750 | Galaxy S25 | एओटी | ~17 मि॰से॰ |
Qualcomm (कोई भी) | — | JIT | ~28 मि॰से॰ |
MediaTek Dimensity 9400 | — | JIT | ~9 मि॰से॰ |
Google Tensor G3-G6 | Pixel 8-11 | AOT/JIT | अलग-अलग हो सकता है |
एओटी (ऐड-ऑफ़-टाइम), डिवाइस के हिसाब से पहले से कंपाइल किए गए मॉडल का इस्तेमाल करता है. जैसे, selfie_multiclass_256x256_SM8650.tflite. ये सबसे तेज़ विकल्प हैं, लेकिन ये चिप के हिसाब से होते हैं.
JIT (Just-in-Time), स्टैंडर्ड selfie_multiclass_256x256.tflite का इस्तेमाल करता है और रनटाइम पर NPU में कंपाइल करता है. इससे पहली बार चलने में ज़्यादा समय लगता है. हालांकि, यह चिप पर निर्भर नहीं करता.
अन्य ज़रूरी शर्तें
Qualcomm HTP:
- QAIRT SDK v2.41+ (
libQnnHtp.so, स्टब या स्केल.soफ़ाइलें उपलब्ध कराता है). libLiteRtDispatch_Qualcomm.soको GitHub पर LiteRT NPU रनटाइम लाइब्रेरी के रिलीज़ किए गए वर्शन से डाउनलोड करें.
MediaTek APU:
libLiteRtDispatch_MediaTek.soसे लिया गया है.- NeuroPilot runtime (यह Dimensity 9400 डिवाइसों पर पहले से ही एक सिस्टम लाइब्रेरी है — इसे पुश करने की ज़रूरत नहीं है).
Google Tensor:
libLiteRtDispatch_GoogleTensor.soसे लिया गया है.
एनपीयू एनवायरमेंट और विकल्प
main_npu.cc, डिवाइस पर वेंडर की डिस्पैच लाइब्रेरी डायरेक्ट्री को Environment पर पॉइंट करता है. इसके बाद, वेंडर के हिसाब से परफ़ॉर्मेंस के विकल्प सेट करता है:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
MediaTek के लिए, GetQualcommOptions() ब्लॉक को बदलें:
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
एनपीयू के लिए डिप्लॉय करना
CMake वैरिएंट — Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
CMake वैरिएंट — MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Bazel का वैरिएंट — Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Bazel वैरिएंट — MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Bazel वैरिएंट — Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Bazel वैरिएंट के लिए, QAIRT SDK टूल की लाइब्रेरी, bazel-bin रनफ़ाइल ट्री से अपने-आप पिक हो जाती हैं. ऐसा तब होता है, जब LITERT_QAIRT_SDK को बिल्ड टाइम पर सेट किया जाता है. CMake वैरिएंट के लिए, --host_npu_lib फ़्लैग को एक्सट्रैक्ट किए गए QAIRT SDK की ओर पॉइंट करना ज़रूरी है.
14. बधाई हो!
आपने LiteRT का इस्तेमाल करके, Android पर C++ इमेज सेगमेंटेशन पाइपलाइन को बना लिया है और उसे चला लिया है. आपने इनके बारे में जानकारी पा ली है:
- CMake + NDK या Bazel की मदद से, Android
arm64-v8aके लिए C++ बाइनरी को क्रॉस-कंपाइल करें. - डिवाइस पर बेहतर तरीके से अनुमान लगाने के लिए, LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) का इस्तेमाल करें. - OpenGL ES 3.1 के कंप्यूट शेडर की मदद से, जीपीयू पर इमेज डेटा को पहले से प्रोसेस करें.
- सिंक्रोनस सीपीयू इन्फ़रेंस और एसिंक्रोनस जीपीयू (OpenCL) इन्फ़रेंस चलाएं.
- Qualcomm, MediaTek, और Google Tensor डिवाइसों के लिए, एनपीयू ऐक्सेलरेटर को कॉन्फ़िगर करें.
- ADB का इस्तेमाल करके, Android पर C++ बाइनरी को डिप्लॉय और रन करें.
अगले चरण
- किसी दूसरे TFLite मॉडल का इस्तेमाल करें. जैसे, गहराई का अनुमान लगाने या पोज़ का पता लगाने वाला मॉडल.
- JNI का इस्तेमाल करके, C++ पाइपलाइन को Android NDK ऐप्लिकेशन में इंटिग्रेट करें.
- Android GPU Inspector की मदद से, मेमोरी के इस्तेमाल की प्रोफ़ाइल बनाएं. साथ ही, टाइमिंग आउटपुट भी पाएं.
- एनपीयू इन्फ़रेंस के इंतज़ार के समय को और कम करने के लिए, मॉडल क्वांटाइज़ेशन एक्सप्लोर करें.