
1. לפני שמתחילים
הקלדת קוד היא דרך מצוינת לפתח זיכרון שרירי ולהעמיק את ההבנה של החומר. העתקה והדבקה יכולות לחסוך זמן, אבל השקעה בתרגול הזה יכולה להוביל ליעילות רבה יותר ולכישורי תכנות טובים יותר בטווח הארוך.
בשיעור Codelab הזה נסביר איך ליצור קובץ בינארי של חלוקת תמונות למקטעים ב-C++ שפועל ישירות במכשיר Android באמצעות זמן הריצה במכשיר של Google, LiteRT, שמאפשר ביצועים גבוהים. במקום להשתמש ב-Kotlin או ב-Android Studio, ב-Codelab הזה נתמקד בבניית קובץ בינארי של C++. תבצעו קומפילציה צולבת באמצעות CMake או Bazel ותפרסו אותו באמצעות ADB. אותו LiteRT C++ API פועל בכל פלטפורמה (Android, Linux, מוטמעת), ולכן הוא מהווה בסיס שימושי לאפליקציות קריטיות לביצועים, לרובוטיקה ולמערכות קצה.
תעברו על כל תהליך הצינור:
- הגדרת סביבת build (CMake + Android NDK או Bazel).
- קישור ל-SDK של LiteRT C++ – מגרסה מוכנה מראש או ממקור.
- שימוש בOpenGL ES compute shaders לעיבוד מקדים ועיבוד סופי של תמונות באמצעות מעבד גרפי.
- הפעלת מודל הפילוח
selfie_multiclassבאמצעות LiteRT C++ API. - האצת ההסקה ב-CPU, ב-GPU (OpenCL) וב-NPU (Qualcomm / MediaTek).
- עיבוד שלאחר יצירת התמונה של פלט המודל הגולמי לתמונה של פילוח עם מיזוג צבעים.
- פריסה למכשיר Android פיזי באמצעות ADB ואחזור התוצאה.
בסופו של דבר, תקבלו משהו דומה לתמונה הבאה – תמונה סטטית שעברה עיבוד דרך כל צינור העיבוד, כשכל אחת מ-6 קטגוריות הפילוח מופיעה בצבע שונה:

דרישות מוקדמות
ה-Codelab הזה מיועד למפתחים שמכירים את שפת C++ ורוצים לצבור ניסיון בהרצת מודלים של למידת מכונה ב-Android בשכבת C++. חשוב שתכירו את:
- יסודות C++ (מצביעים, וקטורים, כולל).
- מושגים בסיסיים ב-Android/ADB (
adb push,adb shell). - שימוש בטרמינל ובסקריפטים של מעטפת ב-Linux או ב-macOS.
מה תלמדו
- איך לבצע קומפילציה צולבת של קובץ בינארי של C++ ל-Android
arm64-v8aבאמצעות CMake + NDK או Bazel. - איך משתמשים ב-LiteRT C++ API (
Environment, CompiledModel, TensorBuffer) להסקת מסקנות יעילה במכשיר. - איך שיידרים לחישוב ב-OpenGL ES 3.1 מאיצים את העיבוד המקדים והעיבוד שלאחר מכן, באופן מלא ב-GPU.
- איך מגדירים את LiteRT להאצת CPU, GPU (OpenCL) ו-NPU (Qualcomm HTP, MediaTek APU, Google Tensor).
- ההבדל בין הסקה סינכרונית (
Run) לבין הסקה אסינכרונית (RunAsync). - איך פורסים ומריצים קובץ בינארי של C++ ב-Android באמצעות ADB.
הדרישות
- מחשב Linux או macOS (משתמשי Windows צריכים להשתמש ב-WSL2).
- Android NDK גרסה r25c ואילך (להורדה).
- בקטע CMake path: CMake ≥ 3.22 (
sudo apt-get install cmake). - בקטע Bazel path: Bazel מותקן, בנוסף למאגר הדוגמאות המלא של LiteRT.
- ADB ב-
PATH(Android Platform Tools). - מכשיר Android פיזי – מומלץ לבדוק במכשירי Galaxy S24/S25 או Pixel.
2. חלוקת תמונות למקטעים
חלוקת תמונות למקטעים היא משימה של ראייה ממוחשבת שמקצה תווית של סיווג לכל פיקסל בתמונה. בניגוד לזיהוי אובייקטים, שבו מצוירת תיבת תוחמת, בפילוח מתקבלת הבנה מדויקת של המקום שבו כל אובייקט מתחיל ומסתיים, ברמת הפיקסל.
בשיעור Codelab הזה נשתמש במודל selfie_multiclass_256x256, שמסווג כל פיקסל לאחת מ-6 קטגוריות:
אינדקס הכיתה | Segment |
0 | רקע |
1 | שיער |
2 | עור הגוף |
3 | עור הפנים |
4 | בגדים |
5 | אביזרים (משקפיים, תכשיטים וכו') |
הפלט של המודל הוא טנסור של מספרים ממשיים בצורה [1, 256, 256, 6]. לכל אחד מהפיקסלים בגודל 256x256 יש 6 ציוני מהימנות – אחד לכל סיווג. הסיווג עם הניקוד הכי גבוה זוכה בפיקסל הזה (argmax).
LiteRT: ביצועים ב-Edge
LiteRT הוא זמן הריצה של הדור הבא של Google, עם ביצועים גבוהים למודלים של TFLite. ממשק ה-API שלו ב-C++ מאפשר גישה ישירה עם תקורה נמוכה למאיצי חומרה עם ממשק עקבי בכל שלושת המקרים:
- CPU – תואם לכל המכשירים; הסקת מסקנות של ~128 ms במכשיר בינוני.
- GPU (OpenCL) – הסקה של כ-1 אלפית השנייה; כ-17 עד 43 אלפיות השנייה מקצה לקצה, בהתאם לשיטת המאגר.
- NPU – כ-9 עד 28 אלפיות השנייה מקצה לקצה במכשירי Qualcomm Snapdragon, MediaTek Dimensity 9400 ו-Google Tensor, בהתאם ל-AOT לעומת. הידור JIT.
ההפשטה העיקרית היא CompiledModel: המודל עובר קומפילציה מראש ואופטימיזציה לחומרה הייעודית בזמן הטעינה, וכך ההסקה מצטמצמת לקריאה של Run() במאגרי נתונים שהוקצו מראש.
3. להגדרה
שכפול המאגר
git clone https://github.com/google-ai-edge/litert-samples.git
כל המשאבים של ה-Codelab הזה נמצאים ב:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
בספרייה הזו יש שני תת-פרויקטים, שכל אחד מהם הוא בנייה מלאה של אותו מדגם:
ספרייה | מערכת build | תלות ב-LiteRT |
| CMake + Android NDK |
|
| Bazel | הידור של LiteRT מהמקור |
בוחרים באחת מהאפשרויות ופועלים לפי ההוראות. הקוד זהה בשתי הספריות – ההבדל היחיד הוא במערכת build ובאסטרטגיית התלות. אם רוצים לבצע את ההגדרה הכי מהר, בוחרים באפשרות use_prebuilt_litert/. אם אתם צריכים לשנות את LiteRT עצמו או לעבוד בתוך מאגר Bazel monorepo קיים, אתם יכולים להשתמש ב-build_from_source/.
הערה לגבי נתיבי קבצים
כל נתיבי הקבצים במדריך הזה הם בפורמט Linux/macOS. משתמשי Windows צריכים להשתמש ב-WSL2.
סקירה כללית של הספרייה
לשני פרויקטי המשנה יש את אותו פריסת מקור:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
בנוסף:
-
use_prebuilt_litert/הוסיף/ה אתCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shו-third_party/stb/. -
build_from_source/מוסיף קובץBUILDשל Bazel ומשתמש ב-deploy_and_run_on_android.shשמצביע עלbazel-bin/.
4. הסבר על מבנה הפרויקט
שלוש נקודות כניסה, צינור אחד
כל אחד מהקבצים main_cpu.cc, main_gpu.cc ו-main_npu.cc מכיל פונקציה main() שמפעילה את כל פייפליין הפילוח. הצינור זהה בכל שלושת המקרים, רק ההגדרה של מאיץ LiteRT ואסטרטגיית המאגר שונות:
קובץ | Accelerator | אסטרטגיית מאגר |
|
| זיכרון CPU |
|
| זיכרון מעבד עם קצה עורפי של OpenCL |
|
| זיכרון המעבד עם מעבר חזרה למעבד |
לשלושתם יש את אותם כלי עזר של ImageProcessor (OpenGL ES compute shaders לעיבוד מקדים ועיבוד פוסט) ושל ImageUtils (STB image I/O).
הפייפליין המלא
לכל נקודת כניסה יש את אותו מבנה של חמישה שלבים:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Load –
ImageUtils::LoadImage()מפענח את ה-JPEG לזיכרון המעבד באמצעות ספריית התמונות STB. - העלאה –
processor.CreateOpenGLTexture()מעלה את הפיקסלים הגולמיים למרקם GPU (OpenGL RGBA8). - Preprocess –
processor.PreprocessInputForSegmentation()מפעיל הצללה לחישוב GLSL שמשנה את גודל הטקסטורה ל-256x256 ומנרמל את ערכי הפיקסלים מ-[0, 1]ל-[-1, 1]. התוצאה נשמרת ב-SSBO של ה-GPU. - Infer – נתוני SSBO נכתבים ל-LiteRT
TensorBufferו-compiled_model.Run()(אוRunAsync()) מפעיל את המודל. - עיבוד אחרי יצירת התמונה – הפלט של המודל, שהוא מספר צף של 6 ערוצים, מפוצל ל-6 מאגרי SSBO של מסכות בערוץ יחיד, ואז מתבצע מיזוג צבעים בחזרה לתמונה המקורית.
- שמירה –
ImageUtils::SaveImage()כותב את תמונת ה-RGBA הסופית כ-PNG.
5. Core LiteRT C++ APIs
לפני שמתחילים לבנות, כדאי להכיר את שלושת הסוגים העיקריים של LiteRT C++ שמשמשים בכל נקודות הכניסה. כל הפריטים נמצאים במרחב השמות litert::.
litert::Environment
Environment הוא ההקשר הבסיסי לכל הפעולות של LiteRT. יוצרים אותו פעם אחת ומעבירים אותו אל CompiledModel::Create. כדי להשתמש ב-NPU, צריך להגדיר אותו באמצעות ספריית הפלאגין של הספק.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel טוען ומבצע קומפילציה מראש של מודל TFLite עבור החומרה המבוקשת בזמן הבנייה. ההסקה מצטמצמת למילוי מאגרי נתונים ולביצוע קריאה ל-Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
מאגרי טנסורים מכילים נתוני קלט ופלט. תמיד יוצרים אותם מתוך CompiledModel כדי שהגודל והמיקום שלהם יתאימו לחומרה של מכשיר היעד.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
פקודות מאקרו לטיפול בשגיאות
Macro | התנהגות |
| הפונקציה מקצה או קוראת ל- |
| הפונקציה |
| הקצאה או הפצה של שגיאה למתקשר |
6. Build — Option A: Prebuilt LiteRT C++ SDK (CMake)
זהו המסלול המומלץ אם אין צורך לשנות את LiteRT עצמו. סקריפט הבנייה מטפל בהורדה של כותרות ה-SDK, בהעתקה של .so, באחזור של STB ובהפעלת CMake + NDK בפקודה אחת.
שלב 1 – מקבלים את libLiteRt.so מ-Maven
זמן הריצה של LiteRT נשלח כספרייה משותפת בתוך AAR של Android ב-Google Maven. מורידים את הקובץ ומחלצים את arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
אם נדרשת תמיכה ב-GPU, צריך גם לחלץ את מאיץ OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

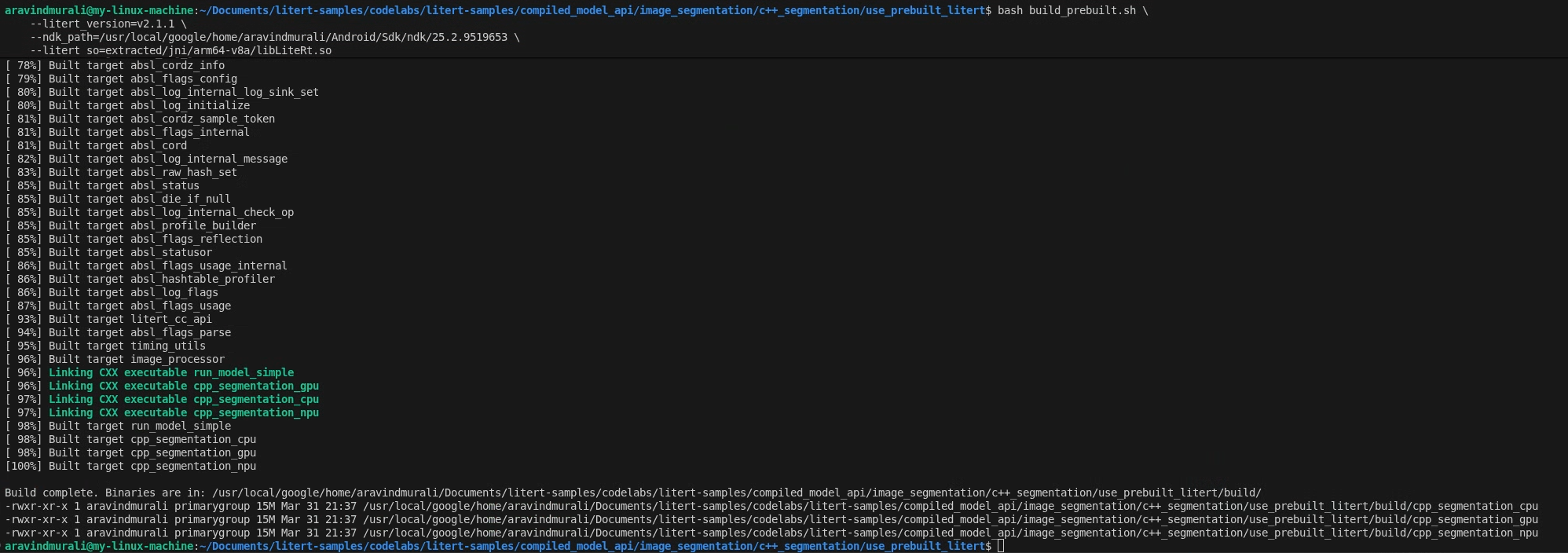
שלב 2 – הפעלת build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
הסקריפט:
- הורדה של
litert_cc_sdk.zip(כותרות SDK + קובצי cmake) מגרסת ה-LiteRT ב-GitHub – הדילוג מתבצע בהפעלות הבאות אם הקבצים כבר קיימים. - מעתיקים את
libLiteRt.soאלlitert_cc_sdk/. - הורדה של כותרות תמונות של STB אל
third_party/stb/– אם הן קיימות, המערכת מדלגת על השלב הזה. - מגדירים ויוצרים באמצעות CMake באמצעות Android NDK toolchain ל-
arm64-v8aב-android-26.
אם הפעולה תצליח, יופיעו שלושה קבצים בינאריים ב-build/:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
מה CMakeLists.txt עושה
פתיחת CMakeLists.txt. הוא דורש C++20, מושך את LiteRT SDK דרך add_subdirectory, מקשר OpenGL ES 3 (GLESv3) ו-EGL, ואז משתמש בפקודת מאקרו של helper כדי ליצור כל קובץ בינארי ממקור main_*.cc שלו:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. בנייה – אפשרות ב': בנייה באמצעות Bazel (ממקור)
כדאי לבחור בדרך הזו אם אתם מעדיפים את Bazel כמערכת build שלכם, שמקמפלת את זמן הריצה של LiteRT מהמקור, או אם אתם צריכים לעבוד בסביבת עבודה קיימת של Bazel.
דרישות מוקדמות
בנוסף ל-NDK ול-ADB שמפורטים בקטע 'לפני שמתחילים', תצטרכו:
- Bazel מותקן ב-
PATH. - שיבוט מלא של מאגר קוד המקור של הדוגמאות של LiteRT.
שלב 1 – הגדרת סביבת העבודה של דוגמאות LiteRT
כל הפקודות מופעלות מהשורש של מאגר הדוגמאות של LiteRT
cd /path/to/litert-samples
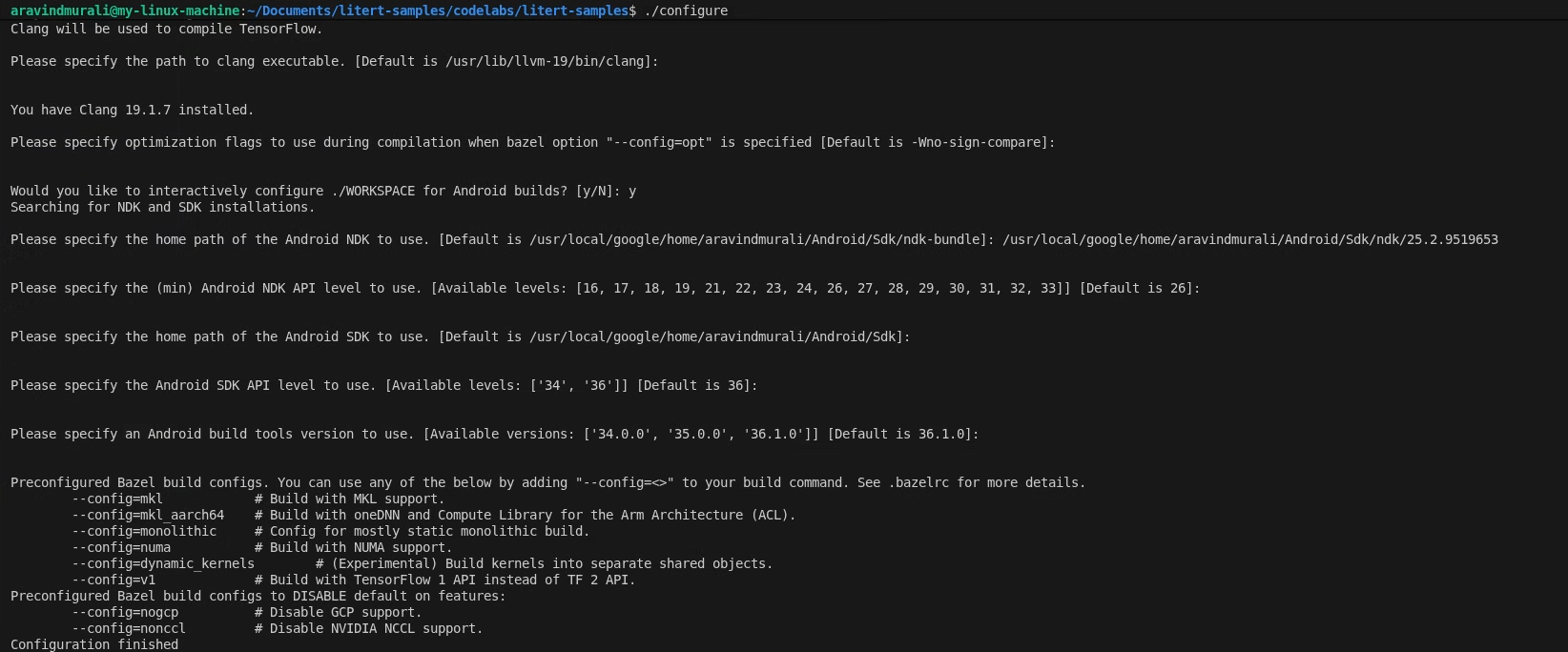
./configure
כשמוצגת בקשה:
- מאשרים את ברירות המחדל עבור Python ונתיב Python lib.
- תשובה N לתמיכה ב-ROCm וב-CUDA.
- בוחרים באפשרות clang (נבדק עם גרסה 18.1.3) כקומפיילר.
- מאשרים את דגלי האופטימיזציה שמוגדרים כברירת מחדל.
- משיבים Y כדי להגדיר את WORKSPACE לגרסאות build של Android.
- מגדירים את הרמה המינימלית של Android NDK ל-26 לפחות.
- מזינים את הנתיב אל Android SDK.
- מגדירים את רמת ה-API של Android SDK לערך ברירת המחדל (36) ואת כלי הבנייה ל-36.0.0.
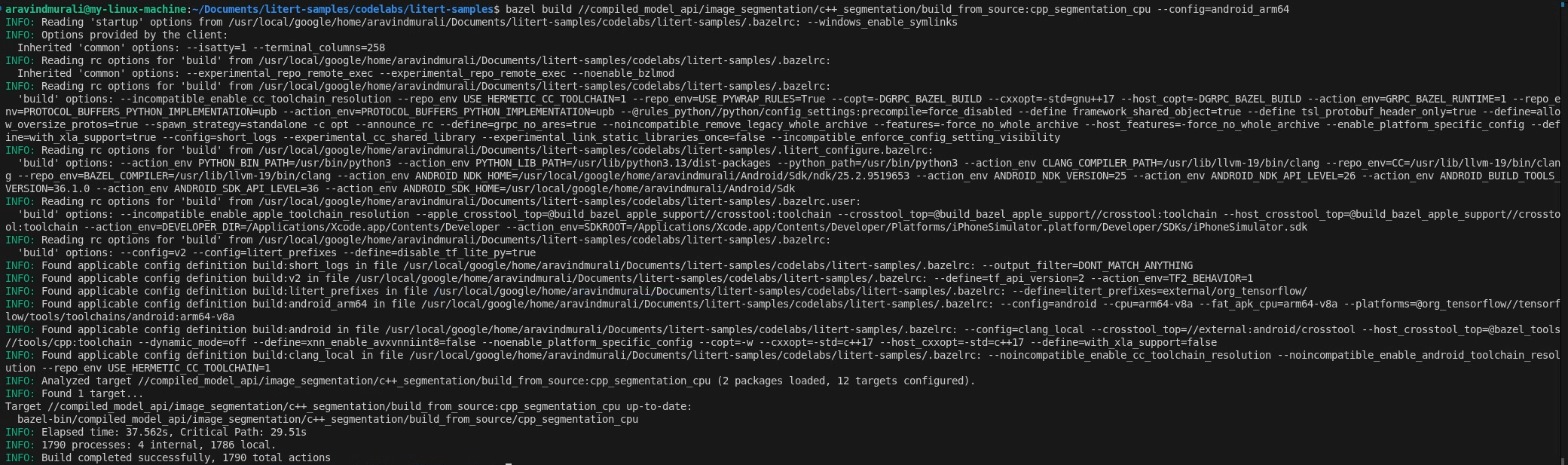
שלב 2 – בניית יעדי המעבד (CPU) והמעבד הגרפי (GPU)
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
שלב 3 – בניית היעד של ה-NPU
Qualcomm HTP
- מורידים את QAIRT SDK גרסה 2.41 ואילך ומחלצים אותו.
- מוודאים שהתוכן שחולץ מ-SDK נמצא בתוך ספריית משנה בשם
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Build, העברת נתיב האב שמסתיים ב-
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
הדגל --nocheck_visibility נדרש כי לחלק מיעדי LiteRT במעלה הזרם יש הגדרות ברירת מחדל של חשיפה מוגבלת.
MediaTek APU
אין צורך ב-SDK נוסף. זמן הריצה של NeuroPilot הוא ספריית מערכת במכשירי Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
הקובץ BUILD
פתיחת build_from_source/BUILD. הוא מגדיר ארבעה cc_binary יעדים – אחד לכל מאיץ ועוד יעד ייעודי של MediaTek NPU – כל אחד מהם תלוי ביעדי הספרייה המשותפת image_processor, image_utils ו-timing_utils:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
יעד ה-GPU מוסיף את libLiteRtClGlAccelerator.so כתלות בנתונים, כך ש-Bazel כולל אותו בקבצים להרצה. ה-NPU מכוון להוספה של קובצי .so של תוסף מהדר ושליחה של ספק כהסתמכויות על נתונים.
8. עיבוד מקדים מואץ באמצעות GPU עם Compute Shaders
כל שלוש נקודות הכניסה משתמשות באותו צינור (pipeline) של shader לחישוב OpenGL ES לעיבוד מקדים. הבנת התהליך הזה היא המפתח להבנת הסיבה לכך שהנתיב של ה-GPU מהיר בהרבה מהנתיב של ה-CPU.
הגדרת הקשר EGL ללא ראש
ImageProcessor::InitializeGL() יוצר הקשר EGL ללא ראש – הקשר OpenGL ללא חלון או תצוגה מצורפים. זוהי שיטה סטנדרטית לחישוב GPU מחוץ למסך ב-Android. לאחר מכן, הוא קומפל את חמש התוכניות של GLSL compute shader מהדיסק:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
מעלים את תמונת הקלט ל-GPU
קובץ ה-JPEG מפוענח לזיכרון ה-CPU על ידי ImageUtils::LoadImage() (באמצעות ספריית STB), ואז מועלה לטקסטורה של ה-GPU:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
מנקודה זו, התמונה המקורית נמצאת בזיכרון של ה-GPU כטקסטורה של OpenGL.
ה-shader של המחשוב לעיבוד מקדים
shaders/preprocess_compute.glsl dispatches 8×8 thread groups across the 256×256 output grid. כל שרשור מטפל בפיקסל פלט אחד: הוא דוגם את מרקם הקלט באמצעות סינון דו-ליניארי (שינוי גודל חומרה בחינם), ממיר את ערך ה-RGB [0, 1] ל-[-1, 1] וכותב ל-SSBO של הפלט:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
בנתיב הרגיל (לא אפס-עותק), ה-SSBO הזה נקרא בחזרה ל-CPU ונכתב לטנזור LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. הסקת מסקנות ב-CPU
פתיחת main_cpu.cc. ההגדרה של LiteRT היא שלוש שורות:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
אחרי העיבוד המקדים, ההסקה היא קריאה סינכרונית יחידה:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() חוסם עד להשלמת ההסקה. מודל הנקודה הצפה selfie_multiclass_256x256.tflite פועל על ליבות ARM Cortex ונמשך בדרך כלל כ-116 עד 128 אלפיות השנייה במכשיר בינוני.
Binary usage:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. הסקת מסקנות ב-GPU (OpenCL)
פתיחת main_gpu.cc. בנתיב ה-GPU יש שני מושגים שלא קיימים בנתיב ה-CPU: litert::Options להגדרת מאיץ ה-GPU (עם קצה העורף של OpenCL), והרצה אסינכרונית.
הגדרת אפשרויות ה-GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
הסקת מסקנות אסינכרונית
נתיב ה-GPU משתמש ב-RunAsync() במקום ב-Run(). הפעולה הזו שולחת עבודה לתור הפקודות של ה-GPU וחוזרת מיד. לאחר מכן, מסנכרנים לפני שקוראים את התוצאות:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
העיצוב הלא חוסם הזה מאפשר לכם להחפיף עבודה של מעבד (CPU) עם הרצה של GPU בצינור עיבוד נתונים בזמן אמת.
Binary usage:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Postprocess — Deinterleave and Blend
אחרי ש-Run() או RunAsync() מסתיימים, output_buffers[0] מכיל מערך שטוח של מספרים ממשיים בצורה [256 × 256 × 6] בסדר משולב. 6 ציוני הסיווג של פיקסל (row, col) נמצאים באינדקסים (row * 256 + col) * 6 עד (row * 256 + col) * 6 + 5.
פירוק ל-6 מאגרי SSBO של מסכות
כדי לעשות זאת, עוזר ה-CPU מפצל את המערך השזור ל-6 מערכים של מספרים ממשיים בערוץ יחיד, ומעלה כל אחד מהם ל-SSBO משלו ב-GPU:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
מיזוג צבעים של מסכות עם התמונה המקורית
processor.ApplyColoredMasks() מריצה את תוכנת ההצללה mask_blend_compute.glsl. לכל פיקסל פלט, האלגוריתם מוצא את המחלקה עם הציון הכי גבוה (argmax בכל 6 ה-SSBO של המסכה) ומבצע שילוב אלפא של הצבע המתאים על פיקסל התמונה המקורי. ששת הצבעים מוגדרים בכל נקודת כניסה:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
האלפא של 0.1f שומר על גוון עדין כך שהתמונה המקורית נשארת גלויה.
שמירת הפלט
ה-SSBO הסופי של RGBA float נקרא בחזרה, מוגבל ל-[0, 1], מומר ל-unsigned char ונשמר כ-PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. פריסה והפעלה במכשיר
מחברים את מכשיר Android באמצעות USB ומוודאים שיש קישוריות ADB:
adb devices

שימוש ב-deploy_and_run_on_android.sh
לכל וריאנט יש סקריפט פריסה משלו. הווריאנט של CMake מצביע על הספרייה build/, והווריאנט של Bazel מצביע על bazel-bin/. שני הסקריפטים:
- יוצרים
/data/local/tmp/cpp_segmentation_android/במכשיר. - דוחפים את הקבצים הבינאריים, את ההצללות של GLSL, את המודל, את תמונת הבדיקה ואת קובצי זמן הריצה
.so. - מריצים הסקה באמצעות
adb shell. - מושכים את
output_segmented.pngבחזרה למחשב.
גרסת CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
וריאנט Bazel (build_from_source/)
מריצים את הפקודות האלה מהספרייה הראשית של מאגר הדוגמאות של LiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
הדגל --phone קובע באיזו תבנית ספציפית למכשיר ובאילו ספריות של ספקים נעשה שימוש. ערכים נתמכים: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) ו-pixel11 (Tensor G6).
תזמון ההסקה
אחרי ההסקה, PrintTiming() מדפיס פירוט מלא של הפרופיל:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
ביצועים לדוגמה במכשיר Samsung S25 Ultra (Snapdragon 8 Elite):
Accelerator | סוג הביצוע | הסקת מסקנות | E2E |
מעבד (CPU) | סנכרון | ~116–128 אלפיות השנייה | ~157 אלפיות השנייה |
GPU (OpenCL) | אסינכרוני | 0.95 אלפיות השנייה | ~35–43 אלפיות השנייה |
13. מתקדם (אופציונלי): הסקת מסקנות ב-NPU
כדי להשיג ביצועים מקסימליים, LiteRT תומך בהאצת NPU באמצעות ספריות פלאגין ספציפיות לספקים. בנתיב ה-NPU אפשר להשיג זמן אחזור מקצה לקצה של 9 אלפיות השנייה בלבד.
מכשירים ומצבים נתמכים
Chip | דוגמה למכשיר | מצב | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 אלפיות השנייה |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 אלפיות השנייה |
Qualcomm (כל ערך) | — | JIT | ~28 אלפיות השנייה |
MediaTek Dimensity 9400 | — | JIT | ~9 אלפיות השנייה |
Google Tensor G3-G6 | Pixel 8-11 | AOT/JIT | משתנה |
AOT (Ahead-of-Time) משתמש במודל שעבר קומפילציה מראש וספציפי למכשיר (למשל, selfie_multiclass_256x256_SM8650.tflite). זו האפשרות הכי מהירה, אבל היא ספציפית לשבב.
JIT (Just-in-Time) משתמש ב-selfie_multiclass_256x256.tflite הסטנדרטי ומבצע הידור ל-NPU בזמן הריצה – הריצה הראשונה איטית יותר, לא תלויה בשבב.
דרישות מוקדמות נוספות
Qualcomm HTP:
- QAIRT SDK v2.41+ (מספק קובצי
libQnnHtp.so, stub או skel.so). -
libLiteRtDispatch_Qualcomm.soמגרסת ההפצה של ספריות זמן הריצה של LiteRT NPU ב-GitHub.
MediaTek APU:
-
libLiteRtDispatch_MediaTek.soמגרסת ההפצה של ספריות זמן הריצה של LiteRT NPU. - זמן הריצה של NeuroPilot (כבר ספריית מערכת במכשירי Dimensity 9400 – אין צורך להעביר אותה).
Google Tensor:
-
libLiteRtDispatch_GoogleTensor.soמגרסת ההפצה של ספריות זמן הריצה של LiteRT NPU.
סביבת NPU ואפשרויות
main_npu.cc מצביע על ספריית השליחה של הספק במכשיר, ואז מגדיר אפשרויות ביצועים ספציפיות לספק:Environment
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
ב-MediaTek, מחליפים את הבלוק GetQualcommOptions():
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
פריסה ל-NPU
גרסת CMake – Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
גרסת CMake – MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
גרסת Bazel – Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
וריאציה של Bazel — MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
גרסת Bazel – Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
במקרה של וריאציית Bazel, ספריות QAIRT SDK נאספות אוטומטית מעץ bazel-bin runfiles כשמגדירים את LITERT_QAIRT_SDK בזמן ה-build. הווריאנט של CMake דורש שהדגל --host_npu_lib יצביע על QAIRT SDK שחולץ.
14. מעולה!
יצרתם והפעלתם בהצלחה פייפליין של חלוקת תמונות למקטעים ב-C++ ב-Android באמצעות LiteRT. למדתם איך:
- קומפילציה צולבת של קובץ בינארי C++ ל-Android
arm64-v8aבאמצעות CMake + NDK או Bazel. - כדי להסיק מסקנות ביעילות במכשיר, אפשר להשתמש ב-LiteRT C++ API (
Environment,CompiledModel,TensorBuffer). - עיבוד מוקדם של נתוני תמונה ב-GPU באמצעות הצללות חישוב של OpenGL ES 3.1.
- הפעלת היקש סינכרוני של CPU והיקש אסינכרוני של GPU (OpenCL).
- הגדרת האצת NPU למכשירי Qualcomm, MediaTek ו-Google Tensor.
- פריסה והפעלה של קובץ בינארי C++ ב-Android באמצעות ADB.
השלבים הבאים
- החלפה במודל TFLite אחר (למשל, הערכת עומק או זיהוי תנוחה).
- איך משלבים את צינור עיבוד הנתונים C++ באפליקציית Android NDK באמצעות JNI.
- פרופיל של השימוש בזיכרון באמצעות Android GPU Inspector לצד פלט של תזמון.
- כדאי לבדוק את האפשרות של כימות מודלים כדי להקטין עוד יותר את זמן האחזור של הסקת מסקנות ב-NPU.