
1. Avant de commencer
Taper du code est un excellent moyen de développer votre mémoire musculaire et d'approfondir votre compréhension du contenu. Bien que le copier-coller puisse vous faire gagner du temps, investir dans cette pratique peut vous permettre de gagner en efficacité et d'améliorer vos compétences en programmation à long terme.
Dans cet atelier de programmation, vous allez apprendre à créer un binaire de segmentation d'image C++ qui s'exécute directement sur un appareil Android à l'aide de LiteRT, le moteur d'exécution haute performance de Google sur l'appareil. Au lieu d'utiliser Kotlin ou Android Studio, cet atelier de programmation se concentre sur la création d'un binaire C++. Vous allez le compiler de manière croisée avec CMake ou Bazel, puis le déployer à l'aide d'ADB. La même API LiteRT C++ fonctionne sur n'importe quelle plate-forme (Android, Linux, embarquée), ce qui en fait une base utile pour les applications critiques en termes de performances, la robotique et les systèmes périphériques.
Vous allez parcourir l'intégralité du pipeline :
- Configurer l'environnement de compilation (CMake + NDK Android ou Bazel).
- Associer le SDK LiteRT C++, soit à partir d'une version précompilée, soit à partir de la source.
- Utilisation des nuanceurs de calcul OpenGL ES pour le prétraitement et le post-traitement des images accélérés par GPU.
- Exécution du modèle de segmentation
selfie_multiclassavec l'API LiteRT C++. - Accélération de l'inférence sur CPU, GPU (OpenCL) et NPU (Qualcomm / MediaTek).
- Post-traitement de la sortie brute du modèle en une image de segmentation avec mélange de couleurs.
- Déploiement sur un appareil Android physique avec ADB et récupération du résultat.
À la fin, vous obtiendrez quelque chose de semblable à l'image suivante : une image statique traitée tout au long du pipeline, avec chacune des six classes de segmentation superposées dans une couleur distincte :

Prérequis
Cet atelier de programmation s'adresse aux développeurs à l'aise avec le langage C++ qui souhaitent acquérir de l'expérience dans l'exécution de modèles de machine learning sur Android au niveau C++. Vous devez maîtriser les éléments suivants :
- Principes de base de C++ (pointeurs, vecteurs, inclusions).
- Concepts de base d'Android/ADB (
adb push,adb shell). - Utiliser un terminal et des scripts shell sur Linux ou macOS
Points abordés
- Comment compiler de manière croisée un binaire C++ pour Android
arm64-v8aavec CMake+NDK ou Bazel. - Comment utiliser l'API LiteRT C++ (
Environment,CompiledModel,TensorBuffer) pour une inférence efficace sur l'appareil. - Découvrez comment les nuanceurs de calcul OpenGL ES 3.1 accélèrent le prétraitement et le post-traitement entièrement sur le GPU.
- Comment configurer LiteRT pour l'accélération du processeur, du GPU (OpenCL) et de l'unité de traitement neuronal (Qualcomm HTP, MediaTek APU, Google Tensor).
- Différence entre l'inférence synchrone (
Run) et asynchrone (RunAsync). - Découvrez comment déployer et exécuter un binaire C++ sur Android à l'aide d'ADB.
Prérequis
- Une machine Linux ou macOS (les utilisateurs Windows doivent utiliser WSL2).
- Android NDK r25c ou version ultérieure (télécharger).
- Pour Chemin d'accès à CMake : CMake ≥ 3.22 (
sudo apt-get install cmake). - Pour Bazel path : Bazel installé, ainsi que le dépôt complet des exemples LiteRT.
- ADB dans votre
PATH(outils de plate-forme Android). - Un appareil Android physique (testé de préférence sur un Galaxy S24/S25 ou un Pixel).
2. Segmentation d'images
La segmentation d'image est une tâche de vision par ordinateur qui attribue une étiquette de classe à chaque pixel d'une image. Contrairement à la détection d'objets, qui dessine un cadre de délimitation, la segmentation permet de comprendre précisément, au pixel près, où commence et où se termine chaque objet.
Cet atelier de programmation utilise le modèle selfie_multiclass_256x256, qui classe chaque pixel dans l'une des six classes suivantes :
Index de classe | Segment |
0 | Arrière-plan |
1 | Coiffure |
2 | Peau du corps |
3 | Peau du visage |
4 | Vêtements |
5 | Accessoires (lunettes, bijoux, etc.) |
Le modèle génère un tenseur float de forme [1, 256, 256, 6]. Pour chacun des 256 x 256 pixels, il existe six scores de confiance (un par classe). La classe ayant obtenu le score le plus élevé remporte ce pixel (argmax).
LiteRT : performances en périphérie
LiteRT est l'environnement d'exécution hautes performances de nouvelle génération de Google pour les modèles TFLite. Son API C++ vous permet d'accéder directement et sans surcharge aux accélérateurs matériels avec une interface cohérente pour les trois :
- CPU : universellement compatible ; inférence d'environ 128 ms sur un appareil de milieu de gamme.
- GPU (OpenCL) : inférence d'environ 1 ms ; de 17 à 43 ms de bout en bout selon la stratégie de tampon.
- NPU : latence de bout en bout d'environ 9 à 28 ms sur les appareils Qualcomm Snapdragon, MediaTek Dimensity 9400 et Google Tensor, selon que la compilation AOT est utilisée ou non. Compilation JIT.
L'abstraction clé est CompiledModel : le modèle est précompilé et optimisé pour le matériel cible au moment du chargement, ce qui réduit l'inférence à un appel Run() sur des tampons préalloués.
3. Configuration
Cloner le dépôt
git clone https://github.com/google-ai-edge/litert-samples.git
Toutes les ressources de cet atelier de programmation se trouvent dans :
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Ce répertoire comporte deux sous-projets, chacun étant une compilation complète du même exemple :
Annuaire | Système de compilation | Dépendance LiteRT |
| CMake + NDK Android |
|
| Bazel | Compiler LiteRT à partir de la source |
Choisissez un parcours et suivez-le. Le code est identique entre les deux répertoires. Seuls le système de compilation et la stratégie de dépendances diffèrent. Si vous souhaitez une configuration rapide, sélectionnez use_prebuilt_litert/. Si vous devez modifier LiteRT lui-même ou travailler dans un monorepo Bazel existant, utilisez build_from_source/.
Remarque sur les chemins d'accès aux fichiers
Tous les chemins d'accès aux fichiers de ce tutoriel utilisent le format Linux/macOS. Les utilisateurs de Windows doivent utiliser WSL2.
Présentation de l'annuaire
Les deux sous-projets partagent la même mise en page source :
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
De plus :
use_prebuilt_litert/ajouteCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shetthird_party/stb/.build_from_source/ajoute un fichierBUILDBazel et utilisedeploy_and_run_on_android.shpointant versbazel-bin/.
4. Comprendre la structure du projet
Trois points d'entrée, un seul pipeline
main_cpu.cc, main_gpu.cc et main_npu.cc contiennent chacun une fonction main() qui pilote l'ensemble du pipeline de segmentation. Le pipeline est identique pour les trois, seules la configuration de l'accélérateur LiteRT et la stratégie de mémoire tampon diffèrent :
Fichier | Accélérateur | Stratégie de mise en mémoire tampon |
|
| Mémoire du processeur |
|
| Mémoire du processeur avec backend OpenCL |
|
| Mémoire du processeur avec processeur de secours |
Les trois partagent les mêmes utilitaires ImageProcessor (nuanceurs de calcul OpenGL ES pour le prétraitement et le post-traitement) et ImageUtils (E/S d'image STB).
Pipeline complet
Chaque point d'entrée suit la même structure en cinq phases :
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Load :
ImageUtils::LoadImage()décode le fichier JPEG dans la mémoire du processeur à l'aide de la bibliothèque d'images STB. - Importer :
processor.CreateOpenGLTexture()importe les pixels bruts dans une texture GPU (OpenGL RGBA8). - Prétraitement :
processor.PreprocessInputForSegmentation()exécute un nuanceur de calcul GLSL qui redimensionne la texture à 256 x 256 et normalise les valeurs de pixels de[0, 1]à[-1, 1]. Le résultat est placé dans un SSBO GPU. - Infer : les données SSBO sont écrites dans un
TensorBufferLiteRT etcompiled_model.Run()(ouRunAsync()) exécute le modèle. - Post-traitement : la sortie flottante à six canaux du modèle est désentrelacée en six SSBO de masque à canal unique, qui sont ensuite mélangés à nouveau avec les couleurs de l'image d'origine.
- Enregistrer :
ImageUtils::SaveImage()écrit l'image RGBA finale au format PNG.
5. API C++ Core LiteRT
Avant de commencer à créer, familiarisez-vous avec les trois principaux types C++ LiteRT utilisés dans tous les points d'entrée. Tous se trouvent dans l'espace de noms litert::.
litert::Environment
Environment est le contexte racine pour toutes les opérations LiteRT. Créez-le une fois et transmettez-le à CompiledModel::Create. Pour l'utilisation du NPU, configurez-le avec le répertoire de la bibliothèque de plug-ins du fournisseur.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel charge et précompile votre modèle TFLite pour le matériel demandé au moment de la construction. L'inférence se réduit alors au remplissage des tampons et à l'appel de Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Les tampons Tensor contiennent les données d'entrée/de sortie. Créez-les toujours à partir de CompiledModel pour qu'ils soient correctement dimensionnés et alignés pour le matériel cible.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Macros de gestion des erreurs
Macro | Comportement |
| Attribue ou appelle |
| Appelle |
| Attribue ou propage l'erreur à l'appelant |
6. Compilation : option A : SDK LiteRT C++ précompilé (CMake)
Il s'agit du chemin recommandé si vous n'avez pas besoin de modifier LiteRT lui-même. Le script de compilation gère le téléchargement des en-têtes du SDK, la copie de votre .so, la récupération de STB et l'appel de CMake + NDK en une seule commande.
Étape 1 : Obtenez libLiteRt.so depuis Maven
LiteRT fournit son environnement d'exécution sous forme de bibliothèque partagée dans un fichier AAR Android sur Google Maven. Téléchargez-le et extrayez le arm64-v8a .so :
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Pour la prise en charge du GPU, extrayez également l'accélérateur OpenCL/GL :
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

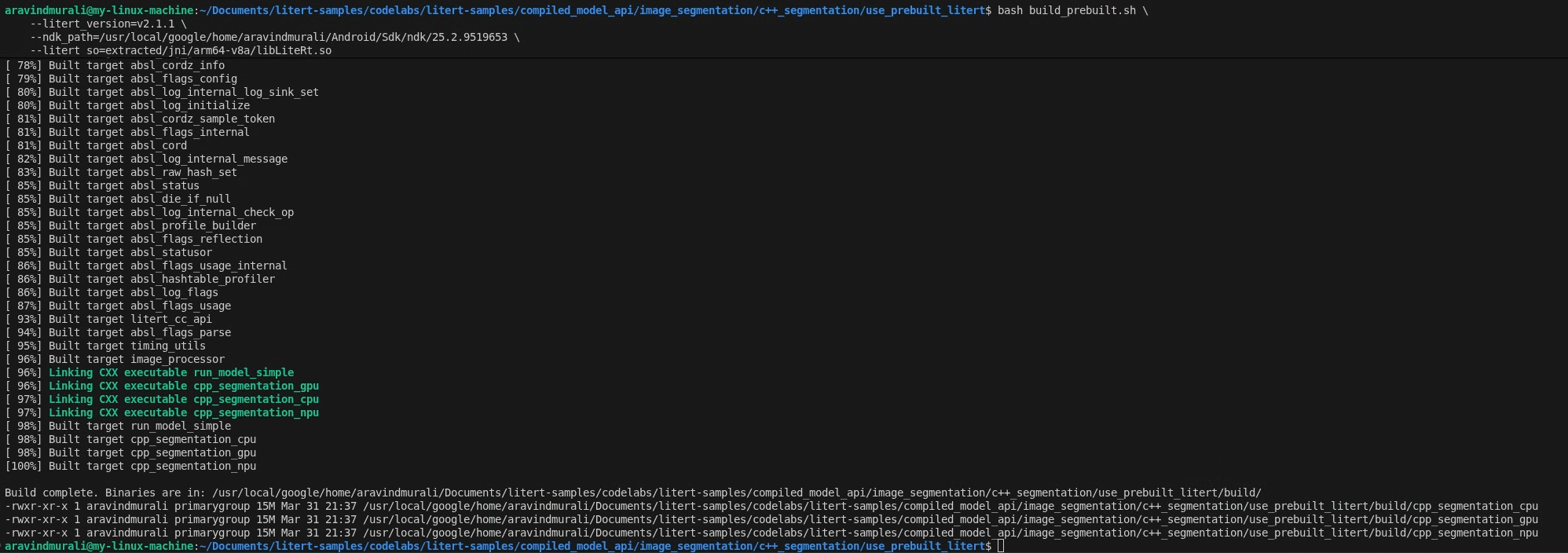
Étape 2 : Exécuter build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Le script va :
- Téléchargez
litert_cc_sdk.zip(en-têtes du SDK + fichiers cmake) à partir de la version LiteRT GitHub. Cette étape est ignorée lors des exécutions suivantes si le fichier est déjà présent. - Copiez
libLiteRt.sodanslitert_cc_sdk/. - Téléchargez les en-têtes d'image STB dans
third_party/stb/(cette étape est ignorée s'ils sont déjà présents). - Configurez et compilez avec CMake en utilisant la chaîne d'outils Android NDK pour
arm64-v8aàandroid-26.
En cas de réussite, trois binaires s'affichent dans build/ :
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Fonction CMakeLists.txt
Ouvrez CMakeLists.txt. Il nécessite C++20, extrait le SDK LiteRT via add_subdirectory, lie OpenGL ES 3 (GLESv3) et EGL, puis utilise une macro d'assistance pour créer chaque binaire à partir de sa source main_*.cc :
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Compiler : option B : compiler avec Bazel (à partir de la source)
Choisissez ce chemin si vous préférez Bazel comme système de compilation, qui compile le runtime LiteRT à partir de la source, ou si vous devez travailler dans un espace de travail Bazel existant.
Prérequis
En plus du NDK et d'ADB listés dans la section "Avant de commencer", vous aurez besoin des éléments suivants :
- Bazel doit être installé et se trouver dans votre
PATH. - Clone complet du dépôt source des exemples LiteRT.
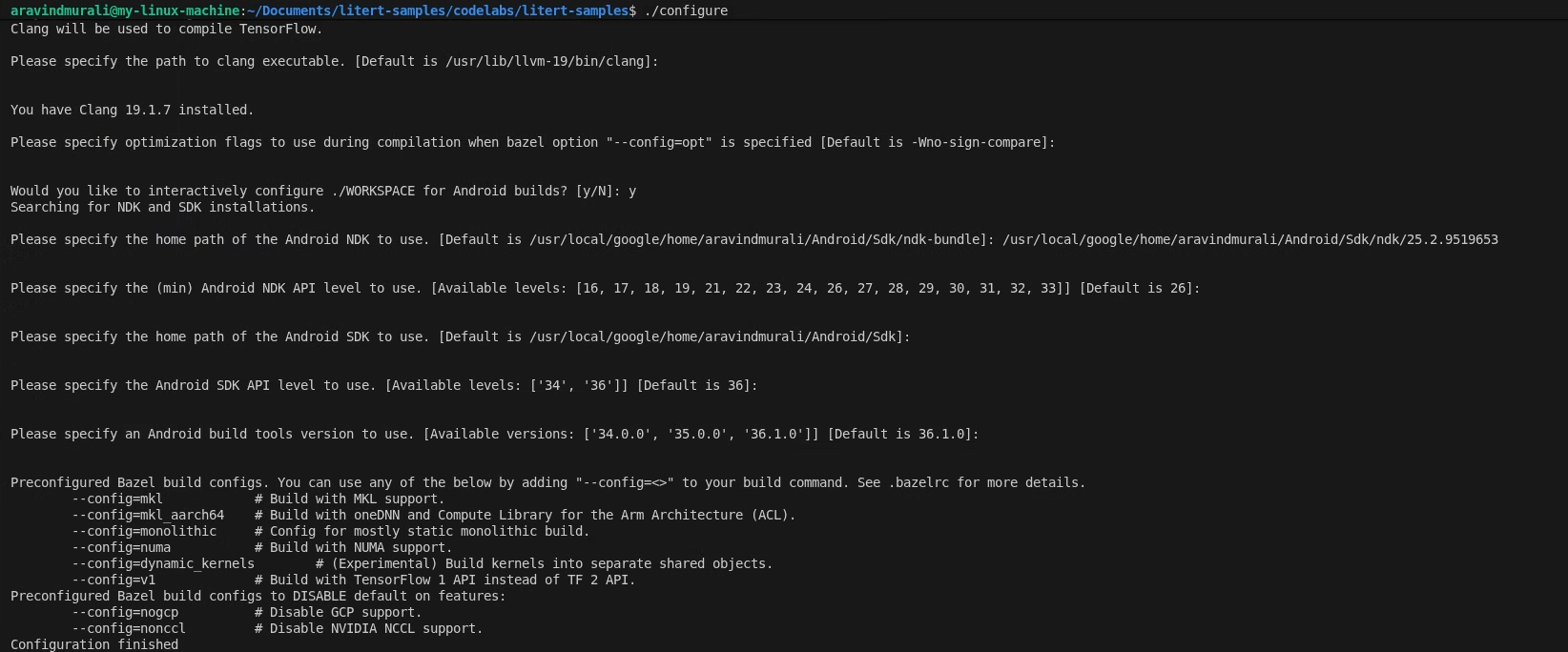
Étape 1 : Configurez l'espace de travail des exemples LiteRT
Toutes les commandes sont exécutées à partir de la racine du dépôt d'exemples LiteRT.
cd /path/to/litert-samples
./configure
Lorsque vous y êtes invité :
- Acceptez les valeurs par défaut pour le chemin d'accès à Python et à la bibliothèque Python.
- Répondez N à la prise en charge de ROCm et CUDA.
- Sélectionnez clang (testé avec la version 18.1.3) comme compilateur.
- Acceptez les options d'optimisation par défaut.
- Répondez Y pour configurer l'ESPACE DE TRAVAIL pour les compilations Android.
- Définissez le niveau minimal du NDK Android sur 26 ou plus.
- Indiquez le chemin d'accès à votre SDK Android.
- Définissez le niveau d'API du SDK Android sur la valeur par défaut (36) et les outils de compilation sur 36.0.0.
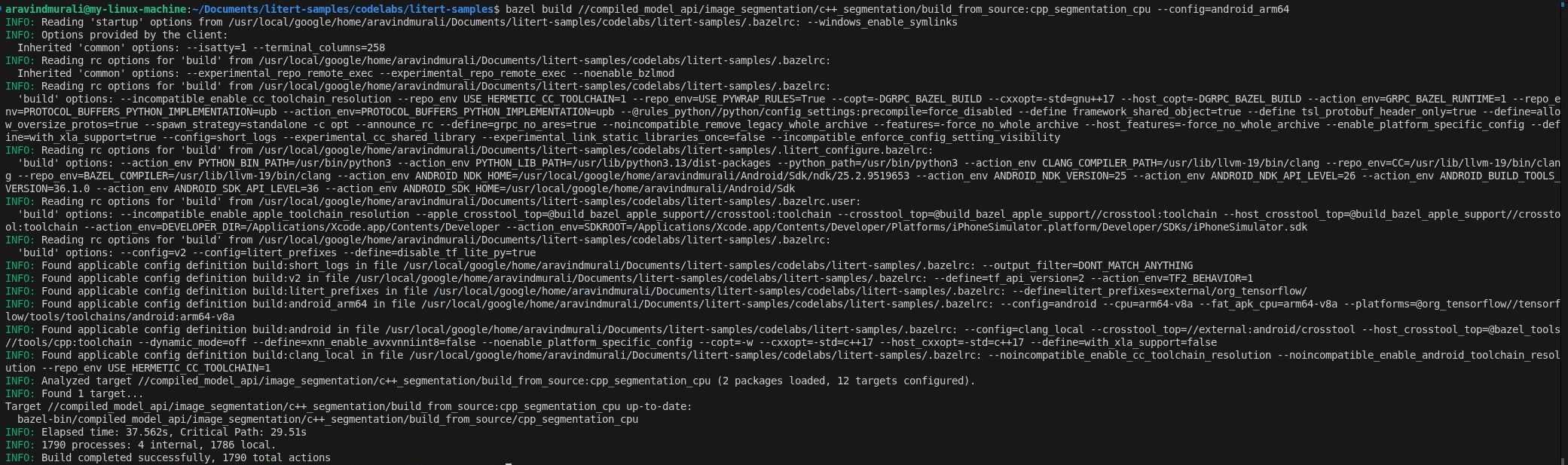
Étape 2 : Compiler les cibles du CPU et du GPU
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Étape 3 : Créez la cible NPU
Qualcomm HTP
- Téléchargez et extrayez le SDK QAIRT v2.41 ou version ultérieure.
- Assurez-vous que le contenu du SDK extrait se trouve dans un sous-répertoire nommé
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Créez le chemin d'accès parent se terminant par
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
L'indicateur --nocheck_visibility est obligatoire, car certains cibles LiteRT en amont ont des paramètres de visibilité par défaut limités.
APU MediaTek
Vous n'avez besoin d'aucun SDK supplémentaire. L'environnement d'exécution NeuroPilot est une bibliothèque système sur les appareils Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
Le fichier BUILD
Ouvrez build_from_source/BUILD. Il définit quatre cibles cc_binary (une par accélérateur, plus une cible NPU MediaTek dédiée), chacune dépendant des cibles de bibliothèque partagées image_processor, image_utils et timing_utils :
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
La cible GPU ajoute libLiteRtClGlAccelerator.so en tant que dépendance de données afin que Bazel l'inclue dans les runfiles. Les cibles NPU ajoutent les fichiers de dispatch du fournisseur et du plug-in du compilateur .so en tant que dépendances de données.
8. Prétraitement accéléré par GPU avec des nuanceurs de calcul
Les trois points d'entrée utilisent le même pipeline de nuanceurs de calcul OpenGL ES pour le prétraitement. Il est essentiel de comprendre ce concept pour comprendre pourquoi le chemin d'accès au GPU est beaucoup plus rapide que celui au CPU.
Configurer un contexte EGL sans affichage
ImageProcessor::InitializeGL() crée un contexte EGL sans affichage, c'est-à-dire un contexte OpenGL sans fenêtre ni écran associés. Il s'agit d'une pratique courante pour le calcul GPU hors écran sur Android. Il compile ensuite les cinq programmes de nuanceur de calcul GLSL à partir du disque :
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Importer l'image d'entrée sur le GPU
Le fichier JPEG est décodé dans la mémoire du processeur par ImageUtils::LoadImage() (via la bibliothèque STB), puis importé dans une texture GPU :
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
À partir de ce moment, l'image d'origine réside dans la mémoire du GPU sous forme de texture OpenGL.
Nuanceur de calcul de prétraitement
shaders/preprocess_compute.glsl distribue des groupes de threads 8x8 sur la grille de sortie 256x256. Chaque thread gère un pixel de sortie : il échantillonne la texture d'entrée à l'aide du filtrage bilinéaire (redimensionnement matériel sans frais), convertit la valeur RVB [0, 1] en [-1, 1] et écrit dans le SSBO de sortie :
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Pour le chemin standard (sans copie nulle), ce SSBO est ensuite relu sur le CPU et écrit dans le Tensor LiteRT :
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Inférence du processeur
Ouvrez main_cpu.cc. La configuration LiteRT se compose de trois lignes :
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Après le prétraitement, l'inférence est un appel synchrone unique :
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() se bloque jusqu'à ce que l'inférence soit terminée. Le modèle à virgule flottante selfie_multiclass_256x256.tflite s'exécute sur les cœurs ARM Cortex et prend généralement entre 116 et 128 ms sur un appareil de milieu de gamme.
Utilisation binaire :
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Inférence GPU (OpenCL)
Ouvrez main_gpu.cc. Le chemin d'accès au GPU introduit deux concepts qui ne sont pas présents dans le chemin d'accès au CPU : litert::Options pour configurer l'accélérateur GPU (avec le backend OpenCL) et l'exécution asynchrone.
Configurer les options de GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Inférence asynchrone
Le chemin d'accès au GPU utilise RunAsync() au lieu de Run(). Cette méthode envoie le travail à la file d'attente des commandes du GPU et renvoie immédiatement un résultat. Vous synchronisez ensuite avant de lire les résultats :
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Cette conception non bloquante vous permet de superposer le travail du CPU à l'exécution du GPU dans un pipeline en temps réel.
Utilisation binaire :
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Post-traitement : désentrelacement et mélange
Une fois Run() ou RunAsync() terminé, output_buffers[0] contient un tableau de valeurs flottantes plates de forme [256 × 256 × 6] dans l'ordre entrelacé. Les six scores de classe pour le pixel (row, col) se trouvent aux index (row * 256 + col) * 6 à (row * 256 + col) * 6 + 5.
Désentrelacer en six SSBO de masque
Un utilitaire de processeur divise le tableau entrelacé en six tableaux float à canal unique et importe chacun d'eux dans son propre SSBO de GPU :
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Mélanger les masques de couleur à l'image d'origine
processor.ApplyColoredMasks() exécute le nuanceur mask_blend_compute.glsl. Pour chaque pixel de sortie, il trouve la classe avec le score le plus élevé (argmax sur les six SSBO de masque) et compose la couleur correspondante sur le pixel de l'image d'origine. Les six couleurs sont définies dans chaque point d'entrée :
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
L'alpha de 0.1f permet de conserver une teinte subtile afin que l'image d'origine reste visible.
Enregistrer le résultat
Le SSBO float RGBA final est relu, limité à [0, 1], converti en unsigned char et enregistré au format PNG :
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Déployer et exécuter sur un appareil
Connectez votre appareil Android à l'aide d'un câble USB et vérifiez la connectivité ADB :
adb devices

Utiliser deploy_and_run_on_android.sh
Chaque variante possède son propre script de déploiement. La variante CMake pointe vers le répertoire build/, tandis que la variante Bazel pointe vers bazel-bin/. Les deux scripts :
- Créez
/data/local/tmp/cpp_segmentation_android/sur l'appareil. - Transférez les fichiers binaires, les nuanceurs GLSL, le modèle, l'image de test et les fichiers d'exécution
.so. - Exécutez l'inférence à l'aide de
adb shell. - Extrayez
output_segmented.pngvers votre machine.
Variante CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Variante Bazel (build_from_source/)
Exécutez ces commandes à partir de la racine du dépôt d'exemples LiteRT :
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
L'indicateur --phone contrôle les bibliothèques de modèles et de fournisseurs spécifiques à l'appareil qui sont utilisées. Valeurs acceptées : s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) et pixel11 (Tensor G6).
Timing de l'inférence
Après l'inférence, PrintTiming() affiche une répartition complète du profil :
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Performances de référence sur le Samsung S25 Ultra (Snapdragon 8 Elite) :
Accélérateur | Type d'exécution | Inférence | E2E |
Processeur | Synchroniser | ~116–128 ms | ~157 ms |
GPU (OpenCL) | Asynchrone | ~0,95 ms | ~35–43 ms |
13. Avancé (facultatif) : inférence NPU
Pour des performances maximales, LiteRT est compatible avec l'accélération NPU à l'aide de bibliothèques de plug-ins spécifiques au fournisseur. Le chemin NPU peut atteindre une latence de bout en bout de 9 ms.
Appareils et modes compatibles
Chip | Exemple d'appareil | Mode | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 ms |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 ms |
Qualcomm (tous) | — | JIT | ~28 ms |
MediaTek Dimensity 9400 | — | JIT | ~9 ms |
Google Tensor G3-G6 | Pixel 8 à 11 | AOT/JIT | Variable |
La compilation anticipée utilise un modèle précompilé spécifique à l'appareil (par exemple, selfie_multiclass_256x256_SM8650.tflite). Il s'agit de l'option la plus rapide, mais elle est spécifique à la puce.
JIT (Just-in-Time) utilise le selfie_multiclass_256x256.tflite standard et compile le NPU au moment de l'exécution. La première exécution est plus lente, mais elle est indépendante du processeur.
Conditions préalables supplémentaires
Qualcomm HTP :
- SDK QAIRT v2.41 ou version ultérieure (fournit les fichiers
libQnnHtp.so, stub ou skel.so). libLiteRtDispatch_Qualcomm.soà partir de la version des bibliothèques d'exécution LiteRT NPU sur GitHub.
APU MediaTek :
libLiteRtDispatch_MediaTek.sode la version des bibliothèques d'exécution LiteRT NPU.- Runtime NeuroPilot (déjà une bibliothèque système sur les appareils Dimensity 9400 : rien à envoyer).
Google Tensor :
libLiteRtDispatch_GoogleTensor.sode la version des bibliothèques d'exécution LiteRT NPU.
Environnement et options de l'unité de traitement neuronal
main_npu.cc pointe Environment vers le répertoire de la bibliothèque de répartition du fournisseur sur l'appareil, puis définit les options de performances spécifiques au fournisseur :
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
Pour MediaTek, remplacez le bloc GetQualcommOptions() :
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Déployer pour NPU
Variante CMake : Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Variante CMake : MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Variante Bazel : Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Variante Bazel : MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Variante Bazel : Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Pour la variante Bazel, les bibliothèques du SDK QAIRT sont récupérées automatiquement à partir de l'arborescence des fichiers d'exécution bazel-bin lorsque LITERT_QAIRT_SDK est défini au moment de la compilation. La variante CMake nécessite que l'indicateur --host_npu_lib pointe vers le SDK QAIRT extrait.
14. Félicitations !
Vous avez réussi à créer et à exécuter un pipeline de segmentation d'images C++ sur Android à l'aide de LiteRT. Vous avez appris à effectuer les tâches suivantes :
- Effectuez une compilation croisée d'un binaire C++ pour Android
arm64-v8aavec CMake+NDK ou Bazel. - Utilisez l'API LiteRT C++ (
Environment,CompiledModel,TensorBuffer) pour une inférence efficace sur l'appareil. - Prétraitez les données d'image sur le GPU avec les nuanceurs de calcul OpenGL ES 3.1.
- Exécutez l'inférence CPU synchrone et l'inférence GPU (OpenCL) asynchrone.
- Configurez l'accélération NPU pour les appareils Qualcomm, MediaTek et Google Tensor.
- Déployez et exécutez un binaire C++ sur Android à l'aide d'ADB.
Étapes suivantes
- Remplacez le modèle TFLite par un autre (par exemple, pour l'estimation de la profondeur ou la détection de pose).
- Intégrez le pipeline C++ dans une application Android NDK à l'aide de JNI.
- Profilez l'utilisation de la mémoire avec Android GPU Inspector en plus de la sortie de timing.
- Explorez la quantification de modèle pour réduire davantage la latence d'inférence du NPU.