
۱. قبل از شروع
تایپ کردن کد راهی عالی برای تقویت حافظه و تعمیق درک شما از مطالب است. در حالی که کپی-پیست کردن میتواند در زمان صرفهجویی کند، سرمایهگذاری روی این تمرین میتواند در درازمدت منجر به کارایی بیشتر و مهارتهای کدنویسی قویتر شود.
در این آزمایشگاه کد، یاد خواهید گرفت که چگونه یک فایل باینری تقسیمبندی تصویر به زبان C++ بسازید که مستقیماً روی دستگاه اندروید با استفاده از زمان اجرای روی دستگاه با کارایی بالای گوگل، LiteRT ، اجرا شود. این آزمایشگاه کد به جای استفاده از Kotlin یا Android Studio، بر ساخت یک فایل باینری C++ تمرکز دارد. شما آن را با CMake یا Bazel کامپایل متقابل خواهید کرد و با استفاده از ADB آن را مستقر خواهید کرد. همان API ++LiteRT روی هر پلتفرمی (اندروید، لینوکس، Embedded) کار میکند و این، پایه و اساس مفیدی برای برنامههای کاربردی با عملکرد حیاتی، رباتیک و سیستمهای لبهای است.
شما کل مراحل را طی خواهید کرد:
- راهاندازی محیط ساخت (CMake + Android NDK یا Bazel).
- اتصال LiteRT C++ SDK - چه از طریق یک نسخه از پیش ساخته شده و چه از طریق سورس کد.
- استفاده از سایهزنهای محاسباتی OpenGL ES برای پیشپردازش و پسپردازش تصویر با شتابدهندهی GPU.
- اجرای مدل تقسیمبندی
selfie_multiclassبا رابط برنامهنویسی کاربردی LiteRT C++. - تسریع استنتاج در CPU ، GPU (OpenCL) و NPU (Qualcomm / MediaTek).
- پسپردازش خروجی مدل خام به یک تصویر قطعهبندی شده با رنگهای ترکیبی.
- استقرار در یک دستگاه اندروید فیزیکی با ADB و بازیابی نتیجه.
در نهایت، چیزی شبیه به تصویر زیر تولید خواهید کرد - یک تصویر ثابت که از طریق کل خط لوله پردازش میشود، و هر یک از 6 کلاس تقسیمبندی با رنگی متمایز پوشانده شدهاند:

پیشنیازها
این آزمایشگاه کد برای توسعهدهندگانی طراحی شده است که با ++C آشنا هستند و میخواهند تجربه اجرای مدلهای یادگیری ماشین در اندروید در لایه ++C را کسب کنند. شما باید با موارد زیر آشنا باشید:
- اصول اولیه ++C (اشارهگرها، بردارها، شاملها)
- مفاهیم اولیه اندروید/ADB (
adb push،adb shell). - استفاده از ترمینال و اسکریپتهای شل در لینوکس یا macOS.
آنچه یاد خواهید گرفت
- چگونه یک فایل باینری C++ را برای اندروید با
arm64-v8aبا CMake + NDK یا Bazel کامپایل کنیم. - نحوه استفاده از رابط برنامهنویسی کاربردی (API) LiteRT C++ (
Environment،CompiledModel،TensorBuffer) برای استنتاج کارآمد روی دستگاه. - چگونه شیدرهای محاسباتی OpenGL ES 3.1، پیشپردازش و پسپردازش را بهطور کامل روی GPU تسریع میکنند.
- نحوه پیکربندی LiteRT برای شتابدهی CPU، GPU (OpenCL) و NPU (Qualcomm HTP، MediaTek APU، Google Tensor).
- تفاوت بین استنتاج همزمان (
Run) و ناهمزمان (RunAsync). - نحوه استقرار و اجرای یک فایل باینری ++C در اندروید با استفاده از ADB.
آنچه نیاز دارید
- یک دستگاه لینوکس یا macOS (کاربران ویندوز باید از WSL2 استفاده کنند).
- اندروید NDK r25c یا بالاتر ( دانلود ).
- برای مسیر CMake : CMake ≥ ۳.۲۲ (
sudo apt-get install cmake). - برای مسیر Bazel : Bazel نصب شده، به علاوه مخزن کامل نمونههای LiteRT.
- ADB را در
PATH(ابزارهای پلتفرم اندروید) خود قرار دهید. - یک دستگاه اندروید فیزیکی - بهترین آزمایش روی گلکسی S24/S25 یا پیکسل.
۲. قطعهبندی تصویر
قطعهبندی تصویر یک وظیفه بینایی کامپیوتر است که به هر پیکسل در تصویر یک برچسب کلاس اختصاص میدهد. برخلاف تشخیص شیء که یک کادر مرزی رسم میکند، قطعهبندی درک دقیقی از محل شروع و پایان هر شیء ارائه میدهد.
این آزمایشگاه کد از مدل selfie_multiclass_256x256 استفاده میکند که هر پیکسل را در یکی از ۶ کلاس زیر طبقهبندی میکند:
فهرست کلاس | بخش |
0 | پیشینه |
۱ | مو |
۲ | پوست بدن |
۳ | پوست صورت |
۴ | لباس |
۵ | لوازم جانبی (عینک، جواهرات و غیره) |
مدل یک تانسور اعشاری با شکل [1, 256, 256, 6] خروجی میدهد. برای هر یک از پیکسلهای 256×256، 6 امتیاز اطمینان وجود دارد - یکی برای هر کلاس. کلاسی که بالاترین امتیاز را داشته باشد، آن پیکسل (argmax) را برنده میشود.
LiteRT: عملکرد در لبه
LiteRT نسل بعدی گوگل با عملکرد بالا برای مدلهای TFLite است. API ++C آن به شما امکان دسترسی مستقیم و کمهزینه به شتابدهندههای سختافزاری را با رابط کاربری سازگار در هر سه مورد میدهد:
- CPU — سازگار با همه سیستمها؛ زمان استنتاج حدود ۱۲۸ میلیثانیه در یک دستگاه میانرده.
- GPU (OpenCL) — استنتاج حدود ۱ میلیثانیه؛ بسته به استراتژی بافر، حدود ۱۷ تا ۴۳ میلیثانیه از ابتدا تا انتها.
- واحد پردازش عصبی (NPU) - حدود ۹ تا ۲۸ میلیثانیه در دستگاههای مجهز به پردازندههای کوالکام اسنپدراگون، مدیاتک دایمنسیتی ۹۴۰۰ و گوگل تنسور، بسته به کامپایل AOT در مقابل JIT.
انتزاع کلیدی CompiledModel است: مدل از قبل کامپایل شده و برای سختافزار هدف در زمان بارگذاری بهینه شده است، که استنتاج را به یک فراخوانی Run() روی بافرهای از پیش تخصیصیافته کاهش میدهد.
۳. آماده شوید
مخزن را کلون کنید
git clone https://github.com/google-ai-edge/litert-samples.git
تمام منابع این آزمایشگاه کد در:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
این دایرکتوری دو زیرپروژه دارد که هر کدام یک نسخه کامل از یک نمونه هستند:
دایرکتوری | سیستم ساخت | وابستگی به LiteRT |
| CMake + اندروید NDK | |
| بازل | LiteRT را از منبع کامپایل میکند. |
یک مسیر را انتخاب کنید و آن را دنبال کنید. کد بین دو دایرکتوری یکسان است - فقط سیستم ساخت و استراتژی وابستگی متفاوت است. اگر میخواهید سریعترین راهاندازی را داشته باشید، use_prebuilt_litert/ را انتخاب کنید. اگر نیاز دارید خود LiteRT را تغییر دهید یا در یک monorepo موجود Bazel کار کنید، build_from_source/ استفاده کنید.
نکتهای در مورد مسیرهای فایل
تمام مسیرهای فایل در این آموزش از فرمت لینوکس/مک استفاده میکنند. کاربران ویندوز باید از WSL2 استفاده کنند.
مرور کلی دایرکتوری
هر دو زیرپروژه طرحبندی منبع یکسانی دارند:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
علاوه بر این:
-
use_prebuilt_litert/CMakeLists.txt،build_prebuilt.sh،deploy_and_run_on_android.shوthird_party/stb/را اضافه میکند. -
build_from_source/یک فایل BazelBUILDاضافه میکند وdeploy_and_run_on_android.shکه بهbazel-bin/اشاره دارد، استفاده میکند.
۴. ساختار پروژه را درک کنید
سه نقطه ورودی، یک خط لوله
main_cpu.cc ، main_gpu.cc و main_npu.cc هر کدام شامل یک تابع main() هستند که کل خط لوله تقسیمبندی را هدایت میکند. این خط لوله در هر سه مورد یکسان است؛ فقط پیکربندی شتابدهنده LiteRT و استراتژی بافر متفاوت است:
فایل | شتابدهنده | استراتژی بافر |
| | حافظه پردازنده |
| | حافظه CPU با پشتیبانی OpenCL |
| | حافظه CPU با قابلیت پشتیبانگیری از CPU |
هر سه نرمافزار ImageProcessor (محاسبه سایهزنهای OpenGL ES برای پیشپردازش و پسپردازش) و ImageUtils (ورودی/خروجی تصویر STB) یکسانی دارند.
خط لوله کامل
هر نقطه ورود از ساختار پنج مرحلهای یکسانی پیروی میکند:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- بارگذاری —
ImageUtils::LoadImage()با استفاده از کتابخانه تصویر STB، فایل JPEG را در حافظه CPU رمزگشایی میکند. - آپلود —
processor.CreateOpenGLTexture()پیکسلهای خام را روی یک بافت GPU (OpenGL RGBA8) آپلود میکند. - پیشپردازش —
processor.PreprocessInputForSegmentation()یک سایهزن محاسباتی GLSL را اجرا میکند که اندازه بافت را به 256×256 تغییر میدهد و مقادیر پیکسلها را از[0, 1]به[-1, 1]نرمالسازی میکند. نتیجه در یک SSBO مربوط به GPU قرار میگیرد. - استنتاج - دادههای SSBO در یک LiteRT
TensorBufferنوشته میشوند وcompiled_model.Run()(یاRunAsync()) مدل را اجرا میکند. - پسپردازش - خروجی شناور ۶ کاناله مدل به ۶ SSBO ماسک تک کاناله تبدیل میشود که سپس با ترکیب رنگی به تصویر اصلی بازگردانده میشوند.
- ذخیره —
ImageUtils::SaveImage()تصویر نهایی RGBA را به صورت PNG مینویسد.
۵. رابطهای برنامهنویسی کاربردی (API) هسته LiteRT C++
قبل از ساخت، با سه نوع کلیدی LiteRT C++ که در تمام نقاط ورودی استفاده میشوند، آشنا شوید. همه آنها در فضای نام litert:: قرار دارند.
litert::Environment
Environment زمینه ریشه برای همه عملیات LiteRT است. آن را یک بار ایجاد کنید و به CompiledModel::Create ارسال کنید. برای استفاده از NPU، آن را با دایرکتوری کتابخانه افزونه فروشنده پیکربندی کنید.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel مدل TFLite شما را برای سختافزار درخواستی در زمان ساخت بارگذاری و پیشکامپایل میکند. سپس استنتاج به پر کردن بافرها و فراخوانی Run() کاهش مییابد.
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
بافرهای تانسور دادههای ورودی/خروجی را نگه میدارند. همیشه آنها را از CompiledModel ایجاد کنید تا اندازه و ترازبندی آنها برای سختافزار هدف به درستی انجام شود.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
ماکروهای مدیریت خطا
ماکرو | رفتار |
| در صورت عدم موفقیت، تابع |
| اگر عبارت خطا برگرداند، تابع |
| خطا را به فراخواننده اختصاص میدهد یا منتشر میکند |
۶. ساخت - گزینه الف: کیت توسعه نرمافزار LiteRT C++ از پیش ساخته شده (CMake)
اگر نیازی به تغییر خود LiteRT ندارید، این مسیر توصیه میشود. اسکریپت ساخت، دانلود هدرهای SDK، کپی کردن .so ، دریافت STB و فراخوانی CMake + NDK را در یک دستور واحد مدیریت میکند.
مرحله ۱ - دریافت libLiteRt.so از Maven
LiteRT زمان اجرای خود را به عنوان یک کتابخانه مشترک درون یک Android AAR در Google Maven ارائه میدهد. آن را دانلود کنید و فایل arm64-v8a را از حالت .so خارج کنید:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
برای پشتیبانی از GPU، شتابدهنده OpenCL/GL را نیز استخراج کنید:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

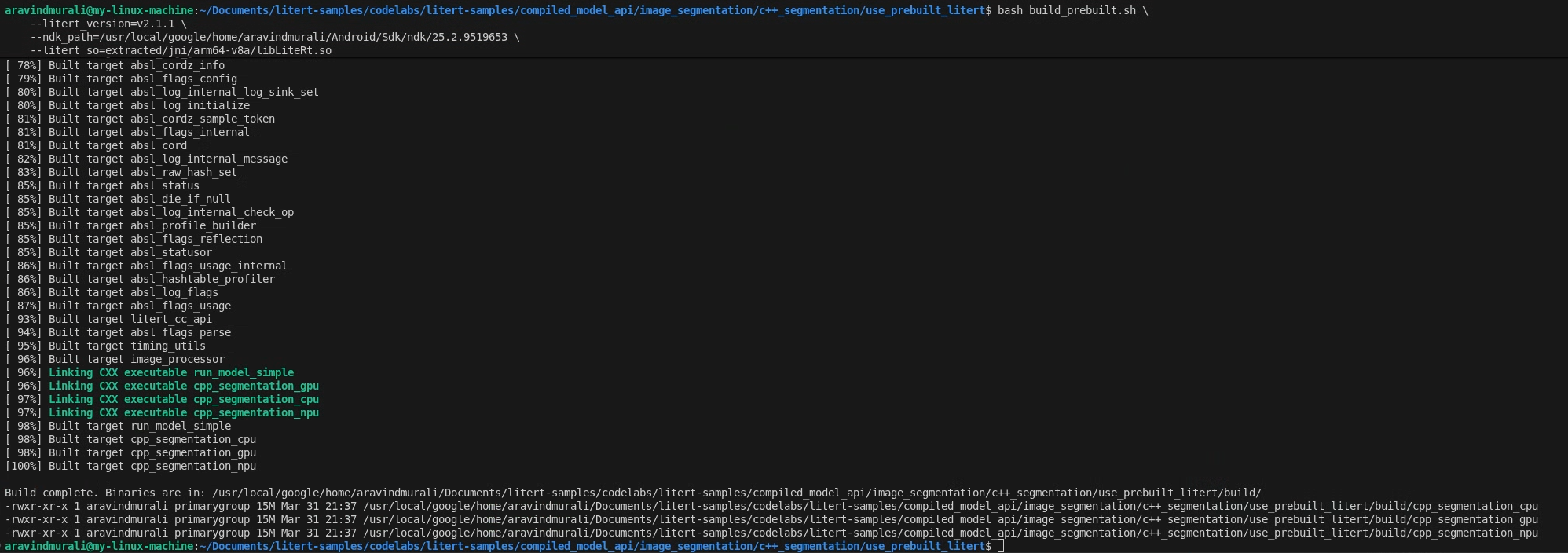
مرحله ۲ - اجرای build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
اسکریپت:
- فایل
litert_cc_sdk.zip(هدرهای SDK + فایلهای cmake) را از نسخه LiteRT GitHub دانلود کنید - در صورت وجود، در اجراهای بعدی نادیده گرفته میشود. -
libLiteRt.soدرlitert_cc_sdk/کپی کنید. - دانلود هدرهای تصویر STB در
third_party/stb/— در صورت وجود، نادیده گرفته میشود. - با استفاده از ابزار Android NDK برای
arm64-v8aدرandroid-26، با CMake پیکربندی و ساخته شود.
در صورت موفقیت، سه فایل باینری در build/ مشاهده خواهید کرد:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
کاری که CMakeLists.txt انجام میدهد
CMakeLists.txt را باز کنید. این فایل به C++20 نیاز دارد، LiteRT SDK را از طریق add_subdirectory دریافت میکند، OpenGL ES 3 ( GLESv3 ) و EGL را لینک میکند، سپس از یک ماکروی کمکی برای ایجاد هر فایل باینری از سورس main_*.cc آن استفاده میکند:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
۷. ساخت - گزینه ب: ساخت با Bazel (از منبع)
اگر Bazel را به عنوان سیستم ساخت خود ترجیح میدهید، که زمان اجرای LiteRT را از منبع کامپایل میکند، یا اگر نیاز دارید در یک فضای کاری Bazel موجود کار کنید، این مسیر را انتخاب کنید.
پیشنیازها
علاوه بر NDK و ADB که در بخش «قبل از شروع» ذکر شدهاند، به موارد زیر نیز نیاز خواهید داشت:
- Bazel نصب شده و در
PATHشما قرار دارد. - یک کلون کامل از مخزن منبع نمونههای LiteRT.
مرحله ۱ - پیکربندی فضای کاری نمونههای LiteRT
همه دستورات از ریشه مخزن نمونههای LiteRT اجرا میشوند
cd /path/to/litert-samples
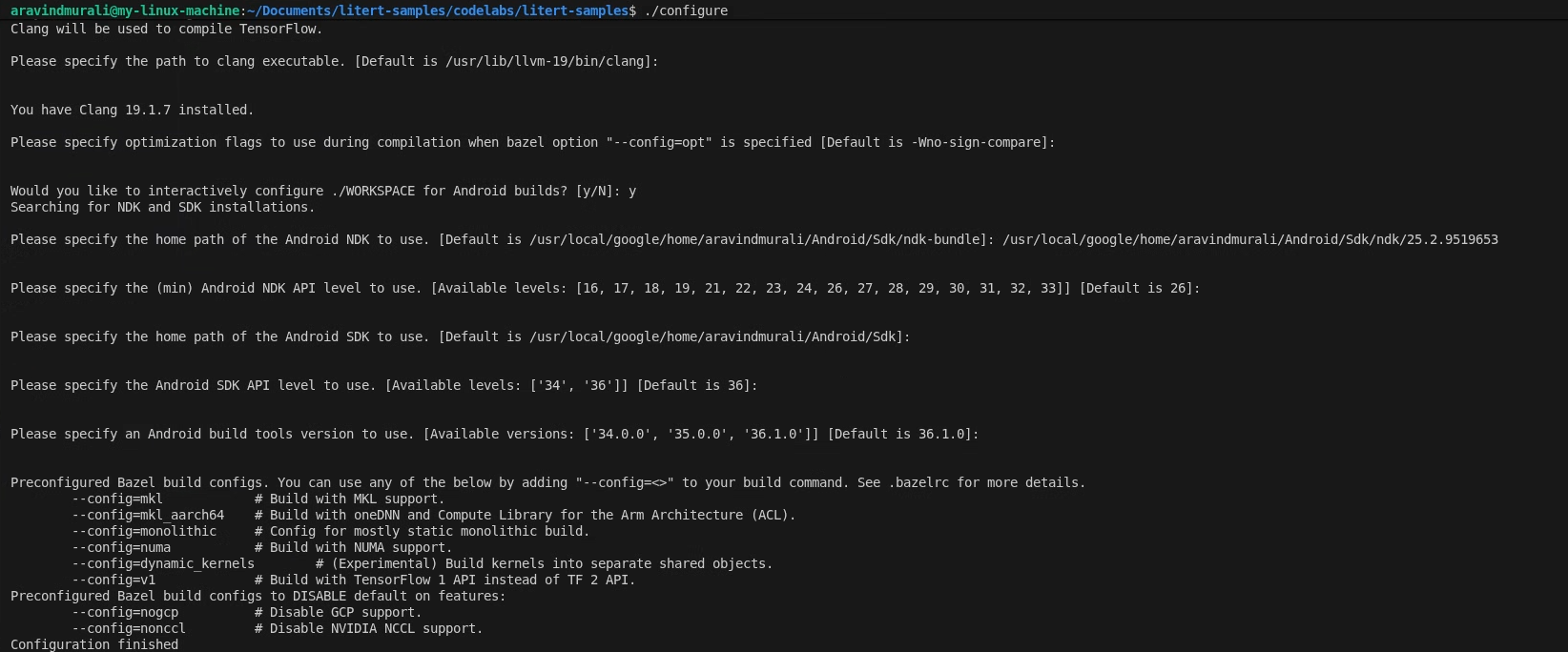
./configure
وقتی از شما خواسته شد:
- مقادیر پیشفرض برای پایتون و مسیر کتابخانه پایتون را بپذیرید.
- به پشتیبانی ROCm و CUDA با N پاسخ دهید.
- clang (که با نسخه ۱۸.۱.۳ تست شده) را به عنوان کامپایلر انتخاب کنید.
- پرچمهای بهینهسازی پیشفرض را بپذیرید.
- برای پیکربندی فضای کاری (WORKSPACE) برای ساختهای اندروید، به Y پاسخ دهید.
- حداقل سطح Android NDK را روی حداقل ۲۶ تنظیم کنید.
- مسیر SDK اندروید خود را وارد کنید.
- سطح API کیت توسعه نرمافزار اندروید (Android SDK API) را روی پیشفرض ( 36 ) تنظیم کنید و ابزارهای ساخت را روی 36.0.0 قرار دهید.
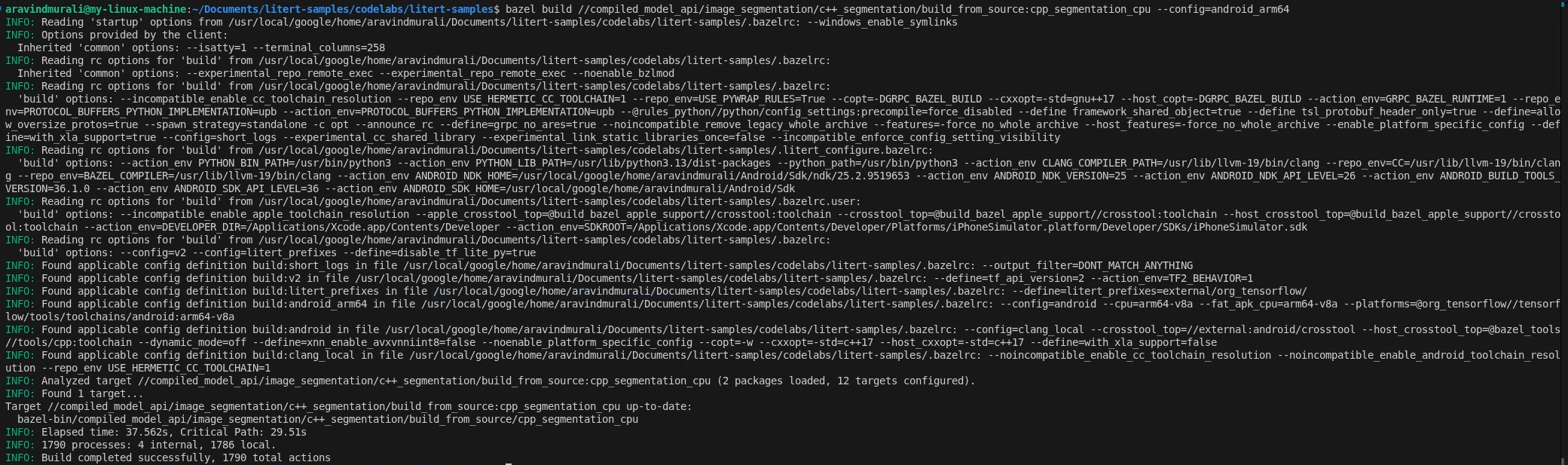
مرحله ۲ - اهداف CPU و GPU را بسازید
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
مرحله ۳ — هدف NPU را بسازید
کوالکام HTP
- QAIRT SDK نسخه ۲.۴۱ یا بالاتر را دانلود و از حالت فشرده خارج کنید.
- مطمئن شوید که محتوای SDK استخراجشده درون زیرشاخهای به نام
latest/قرار دارد:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - ساخت، ارسال مسیر والد که به
/ختم میشود:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
پرچم --nocheck_visibility الزامی است زیرا برخی از اهداف LiteRT بالادستی، پیشفرضهای محدودی برای قابلیت مشاهده دارند.
پردازندهی کمکی مدیاتک (APU)
هیچ SDK اضافی مورد نیاز نیست. زمان اجرای NeuroPilot یک کتابخانه سیستمی در دستگاههای Dimension 9400 است.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
فایل BUILD
build_from_source/BUILD باز کنید. این فایل چهار هدف cc_binary را تعریف میکند - یکی برای هر شتابدهنده به علاوه یک هدف اختصاصی NPU مدیاتک - که هر کدام به اهداف کتابخانهای مشترک image_processor ، image_utils و timing_utils بستگی دارند:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
هدف GPU، libLiteRtClGlAccelerator.so را به عنوان یک وابستگی داده اضافه میکند، بنابراین Bazel آن را در فایلهای اجرایی قرار میدهد. هدفهای NPU، فایلهای vendor dispatch و compiler .so را به عنوان وابستگی داده اضافه میکنند.
۸. پیشپردازش شتابیافته توسط GPU با سایهزنهای محاسباتی
هر سه نقطه ورودی از همان خط لوله سایهزن محاسباتی OpenGL ES برای پیشپردازش استفاده میکنند. درک آن، کلید درک این است که چرا مسیر GPU بسیار سریعتر از مسیر CPU است.
یک زمینه EGL بدون سر (headless) راهاندازی کنید
ImageProcessor::InitializeGL() یک زمینه EGL بدون سر ایجاد میکند - یک زمینه OpenGL بدون هیچ پنجره یا نمایشگری متصل. این یک روش استاندارد برای محاسبات GPU خارج از صفحه در اندروید است. سپس پنج برنامه سایهزن محاسباتی GLSL را از دیسک کامپایل میکند:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
تصویر ورودی را به پردازنده گرافیکی (GPU) آپلود کنید
فایل JPEG توسط ImageUtils::LoadImage() (از طریق کتابخانه STB) در حافظه CPU رمزگشایی شده و سپس به یک بافت GPU آپلود میشود:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
از این نقطه به بعد، تصویر اصلی به عنوان یک بافت OpenGL در حافظه GPU قرار میگیرد.
سایهزن محاسباتی پیشپردازش
shaders/preprocess_compute.glsl گروههای رشتهای ۸×۸ را در سراسر شبکه خروجی ۲۵۶×۲۵۶ توزیع میکند. هر رشته یک پیکسل خروجی را مدیریت میکند: بافت ورودی را با استفاده از فیلتر دوخطی (تغییر اندازه سختافزاری به صورت رایگان) نمونهبرداری میکند، مقدار RGB [0, 1] را به [-1, 1] تبدیل میکند و در SSBO خروجی مینویسد:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
برای مسیر استاندارد (نسخه غیر صفر)، این SSBO سپس به CPU خوانده شده و در تانسور LiteRT نوشته میشود:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
۹. استنتاج CPU
main_cpu.cc را باز کنید. تنظیمات LiteRT شامل سه خط است:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
پس از پیشپردازش، استنتاج یک فراخوانی همزمان واحد است:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
بلوکهای Run() تا زمانی که استنتاج کامل شود، اجرا میشوند. مدل ممیز شناور selfie_multiclass_256x256.tflite روی هستههای ARM Cortex اجرا میشود و معمولاً در یک دستگاه میانرده حدود ۱۱۶ تا ۱۲۸ میلیثانیه طول میکشد.
کاربرد دودویی:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
۱۰. استنتاج GPU (OpenCL)
main_gpu.cc را باز کنید. مسیر GPU دو مفهوم را معرفی میکند که در مسیر CPU وجود ندارند: litert::Options برای پیکربندی شتابدهنده GPU (با Backend OpenCL) و اجرای ناهمزمان.
پیکربندی گزینههای پردازنده گرافیکی
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
استنتاج ناهمزمان
مسیر GPU به جای Run() RunAsync() ) استفاده میکند. این کار، کار را به صف دستورات GPU ارسال میکند و بلافاصله برمیگرداند. سپس قبل از خواندن نتایج، همگامسازی میکنید:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
این طراحی غیر مسدودکننده به شما امکان میدهد تا کار CPU را با اجرای GPU در یک خط لوله بلادرنگ همپوشانی کنید.
کاربرد دودویی:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
۱۱. پسپردازش - حذف لایههای میانی و ترکیب آنها
پس از اتمام Run() یا RunAsync() ، output_buffers[0] یک آرایه اعشاری مسطح به شکل [256 × 256 × 6] را به صورت لایه لایه نگهداری میکند. امتیازهای کلاس 6 برای پیکسل (row, col) در اندیسهای (row * 256 + col) * 6 تا (row * 256 + col) * 6 + 5 قرار دارند.
جدا کردن به 6 ماسک SSBO
یک کمککننده CPU آرایه درهمتنیده را به 6 آرایه شناور تک کاناله تقسیم میکند و هر کدام را به SSBO GPU خود آپلود میکند:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
ماسکهای ترکیب رنگ روی تصویر اصلی
processor.ApplyColoredMasks() شیدر mask_blend_compute.glsl را اجرا میکند. برای هر پیکسل خروجی، کلاسی را که بالاترین امتیاز (argmax در 6 SSBO ماسک) را دارد پیدا میکند و رنگ مربوطه را روی پیکسل تصویر اصلی آلفا-کامپوزیت میکند. شش رنگ در هر نقطه ورودی تعریف شدهاند:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
آلفای 0.1f رنگ را ملایم نگه میدارد تا تصویر اصلی قابل مشاهده باقی بماند.
خروجی را ذخیره کنید
SSBO اعشاری RGBA ترکیبشدهی نهایی دوباره خوانده میشود، به [0, 1] محدود میشود، به unsigned char تبدیل میشود و با فرمت PNG ذخیره میشود:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
۱۲. استقرار و اجرا روی دستگاه
دستگاه اندروید خود را با استفاده از USB وصل کنید و اتصال ADB را بررسی کنید:
adb devices

از deploy_and_run_on_android.sh استفاده کنید
هر نوع اسکریپت استقرار مخصوص به خود را دارد. نوع CMake به دایرکتوری build/ اشاره میکند؛ نوع Bazel به bazel-bin/ . هر دو اسکریپت:
-
/data/local/tmp/cpp_segmentation_android/را روی دستگاه ایجاد کنید. - فایلهای باینری، شیدرهای GLSL، مدل، تصویر آزمایشی و فایلهای
.soزمان اجرا را ارسال کنید. - اجرای استنتاج با استفاده از
adb shell. -
output_segmented.pngبه دستگاه خود برگردانید.
نوع CMake ( use_prebuilt_litert/ )
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
نوع Bazel ( build_from_source/ )
این دستورات را از ریشه مخزن LiteRT samples اجرا کنید:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
پرچم --phone کنترل میکند که از کدام مدل و کتابخانههای سازندهی خاص دستگاه استفاده شود. مقادیر پشتیبانیشده: s24 (اسنپدراگون ۸ نسل ۳)، s25 (اسنپدراگون ۸ الیت)، dim9400 (مدیاتک دایمنسیتی ۹۴۰۰)، pixel8 (تنسور G3)، pixel9 (تنسور G4)، pixel10 (تنسور G5) و pixel11 (تنسور G6).
زمانبندی استنتاج
پس از استنتاج، PrintTiming() یک تجزیه و تحلیل کامل از پروفایلها را چاپ میکند:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
عملکرد مرجع روی سامسونگ S25 اولترا (اسنپدراگون ۸ الیت):
شتابدهنده | نوع اجرا | استنتاج | E2E |
پردازنده | همگامسازی | حدود ۱۱۶ تا ۱۲۸ میلیثانیه | حدود ۱۵۷ میلیثانیه |
پردازنده گرافیکی (OpenCL) | ناهمگامسازی | ~۰.۹۵ میلیثانیه | حدود ۳۵ تا ۴۳ میلیثانیه |
۱۳. پیشرفته (اختیاری): استنتاج NPU
برای حداکثر عملکرد، LiteRT از شتابدهی NPU با استفاده از کتابخانههای افزونه مخصوص فروشنده پشتیبانی میکند. مسیر NPU میتواند به تأخیر انتها به انتها تا 9 میلیثانیه برسد.
دستگاهها و حالتهای پشتیبانیشده
تراشه | مثال دستگاه | حالت | E2E |
کوالکام SM8650 | گلکسی اس ۲۴ | آ او تی | حدود ۱۷ میلیثانیه |
کوالکام SM8750 | گلکسی اس ۲۵ | آ او تی | حدود ۱۷ میلیثانیه |
کوالکام (هر کدام) | — | جیت | تقریباً ۲۸ میلیثانیه |
مدیاتک دایمنسیتی ۹۴۰۰ | — | جیت | تقریباً ۹ میلیثانیه |
گوگل تنسور G3-G6 | پیکسل ۸-۱۱ | AOT/JIT | متفاوت است |
AOT (Ahead-of-Time) از یک مدل از پیش کامپایل شده مخصوص دستگاه استفاده میکند (مثلاً selfie_multiclass_256x256_SM8650.tflite ). اینها سریعترین گزینه هستند اما مخصوص تراشه میباشند.
JIT (Just-in-Time) از فایل استاندارد selfie_multiclass_256x256.tflite استفاده میکند و در زمان اجرا به NPU کامپایل میشود - اجرای اولیه کندتر و مستقل از تراشه.
پیشنیازهای اضافی
کوالکام HTP:
- QAIRT SDK نسخه ۲.۴۱+ (فایلهای
libQnnHtp.so، stub یا skel.soرا ارائه میدهد). -
libLiteRtDispatch_Qualcomm.soاز کتابخانههای زمان اجرای LiteRT NPU که در گیتهاب منتشر شده است.
پردازندهی کمکی مدیاتک (APU):
-
libLiteRtDispatch_MediaTek.soاز نسخه کتابخانههای زمان اجرای LiteRT NPU. - زمان اجرای NeuroPilot (در حال حاضر یک کتابخانه سیستمی در دستگاههای Dimension 9400 وجود دارد - چیزی برای فشار دادن وجود ندارد).
گوگل تنسور:
-
libLiteRtDispatch_GoogleTensor.soاز نسخه کتابخانههای زمان اجرای LiteRT NPU.
محیط و گزینههای NPU
main_npu.cc Environment در دایرکتوری کتابخانه dispatch فروشنده روی دستگاه قرار میدهد، سپس گزینههای عملکرد خاص فروشنده را تنظیم میکند:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
برای مدیاتک، بلوک GetQualcommOptions() را جایگزین کنید:
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
استقرار برای NPU
نوع CMake — کوالکام S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
نوع CMake — مدیاتک دایمنسیتی ۹۴۰۰ (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
نوع Bazel — Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
نوع Bazel — مدیاتک دایمنسیتی ۹۴۰۰ (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
نوع Bazel - Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
برای نوع Bazel، کتابخانههای QAIRT SDK به طور خودکار از درخت فایلهای اجرایی bazel-bin هنگامی که LITERT_QAIRT_SDK در زمان ساخت تنظیم شده باشد، انتخاب میشوند. نوع CMake به پرچم --host_npu_lib نیاز دارد تا به QAIRT SDK استخراج شده شما اشاره کند.
۱۴. تبریک میگویم!
شما با موفقیت یک خط لوله قطعهبندی تصویر C++ را با استفاده از LiteRT در اندروید ساختید و اجرا کردید. شما یاد گرفتید که چگونه:
- کامپایل متقابل یک فایل باینری C++ برای اندروید
arm64-v8aبا CMake + NDK یا Bazel. - برای استنتاج کارآمد روی دستگاه، از رابط برنامهنویسی کاربردی LiteRT C++ (
Environment،CompiledModel،TensorBuffer) استفاده کنید. - پیشپردازش دادههای تصویر روی پردازنده گرافیکی (GPU) با استفاده از سایهزنهای محاسباتی OpenGL ES 3.1.
- استنتاج همزمان CPU و استنتاج ناهمزمان GPU (OpenCL) را اجرا کنید.
- پیکربندی شتاب NPU برای دستگاههای Qualcomm، MediaTek و Google Tensor.
- با استفاده از ADB، یک فایل باینری ++C را روی اندروید مستقر و اجرا کنید.
مراحل بعدی
- یک مدل TFLite متفاوت (مثلاً تخمین عمق یا تشخیص ژست) را جایگزین کنید.
- با استفاده از JNI، خط لوله C++ را در یک برنامه Android NDK ادغام کنید.
- نمایش میزان استفاده از حافظه با Android GPU Inspector در کنار زمانبندی خروجی.
- بررسی کوانتیزاسیون مدل برای کاهش بیشتر تأخیر استنتاج NPU.