
1. Antes de comenzar
Escribir código es una excelente manera de desarrollar la memoria muscular y profundizar tu comprensión del material. Si bien copiar y pegar puede ahorrar tiempo, invertir en esta práctica puede generar una mayor eficiencia y mejores habilidades de programación a largo plazo.
En este codelab, aprenderás a compilar un archivo binario de segmentación de imágenes en C++ que se ejecuta directamente en un dispositivo Android con el entorno de ejecución de alto rendimiento integrado en el dispositivo de Google, LiteRT. En lugar de usar Kotlin o Android Studio, este codelab se enfoca en compilar un objeto binario de C++. Lo compilarás de forma cruzada con CMake o Bazel y lo implementarás con ADB. La misma API de C++ de LiteRT funciona en cualquier plataforma (Android, Linux, integrada), lo que la convierte en una base útil para aplicaciones críticas para el rendimiento, robótica y sistemas perimetrales.
Recorrerás toda la canalización:
- Configurar el entorno de compilación (CMake + NDK de Android o Bazel)
- Vincular el SDK de C++ de LiteRT, ya sea desde una versión precompilada o desde la fuente
- Usa sombreadores de cómputos de OpenGL ES para el preprocesamiento y posprocesamiento de imágenes acelerados por GPU.
- Ejecución del modelo de segmentación de
selfie_multiclasscon la API de C++ de LiteRT. - Aceleración de la inferencia en CPU, GPU (OpenCL) y NPU (Qualcomm / MediaTek).
- Procesamiento posterior del resultado del modelo sin procesar en una imagen de segmentación combinada con colores.
- Se realiza la implementación en un dispositivo Android físico con ADB y se recupera el resultado.
Al final, obtendrás algo similar a la siguiente imagen: una imagen estática procesada a través de toda la canalización, con cada una de las 6 clases de segmentación superpuestas en un color distinto:

Requisitos previos
Este codelab está diseñado para desarrolladores que se sientan cómodos con C++ y deseen adquirir experiencia en la ejecución de modelos de aprendizaje automático en Android en la capa de C++. Debes estar familiarizado con lo siguiente:
- Conceptos básicos de C++ (punteros, vectores, includes)
- Conceptos básicos de Android y ADB (
adb push,adb shell) - Usar una terminal y secuencias de comandos de shell en Linux o macOS
Qué aprenderás
- Cómo realizar una compilación cruzada de un objeto binario de C++ para Android
arm64-v8acon CMake + NDK o Bazel - Cómo usar la API de C++ de LiteRT (
Environment,CompiledModel,TensorBuffer) para realizar inferencias eficientes integrado en el dispositivo - Cómo los sombreadores de cómputos de OpenGL ES 3.1 aceleran el procesamiento previo y posterior por completo en la GPU
- Cómo configurar LiteRT para la aceleración de CPU, GPU (OpenCL) y NPU (Qualcomm HTP, MediaTek APU, Google Tensor)
- Diferencia entre la inferencia síncrona (
Run) y la asíncrona (RunAsync). - Cómo implementar y ejecutar un archivo binario de C++ en Android con adb
Requisitos
- Una máquina Linux o macOS (los usuarios de Windows deben usar WSL2)
- NDK de Android r25c o posterior (descargar)
- Para Ruta de CMake: CMake ≥ 3.22 (
sudo apt-get install cmake). - Para la ruta de Bazel: Bazel instalado y el repositorio completo de muestras de LiteRT.
- ADB en tus
PATH(herramientas de la plataforma de Android) - Un dispositivo Android físico (se recomienda probarlo en un Galaxy S24/S25 o Pixel)
2. Segmentación de imágenes
La segmentación de imágenes es una tarea de visión artificial que asigna una etiqueta de clase a cada píxel de una imagen. A diferencia de la detección de objetos, que dibuja un cuadro delimitador, la segmentación produce una comprensión precisa y perfecta de dónde comienza y termina cada objeto.
En este codelab, se usa el modelo selfie_multiclass_256x256, que clasifica cada píxel en una de 6 clases:
Índice de clase | Segmentar |
0 | Fondo |
1 | Cabello |
2 | Piel del cuerpo |
3 | Piel del rostro |
4 | Ropa |
5 | Accesorios (gafas, joyas, etc.) |
El modelo genera un tensor de números de punto flotante con la forma [1, 256, 256, 6]. Para cada uno de los píxeles de 256 × 256, hay 6 puntuaciones de confianza, una por clase. La clase con la puntuación más alta gana ese píxel (argmax).
LiteRT: Rendimiento en el borde
LiteRT es el entorno de ejecución de alto rendimiento y nueva generación de Google para los modelos de TFLite. Su API de C++ te brinda acceso directo y de baja sobrecarga a los aceleradores de hardware con una interfaz coherente en los tres:
- CPU: Es compatible con todos los dispositivos y tiene una inferencia de ~128 ms en un dispositivo de gama media.
- GPU (OpenCL): Inferencias de ~1 ms; de ~17 a 43 ms de extremo a extremo, según la estrategia de búfer.
- NPU: De 9 a 28 ms de extremo a extremo en dispositivos Qualcomm Snapdragon, MediaTek Dimensity 9400 y Google Tensor, según la compilación AOT. Compilación JIT.
La abstracción clave es CompiledModel: El modelo se compila previamente y se optimiza para el hardware de destino en el tiempo de carga, lo que reduce la inferencia a una llamada Run() en búferes preasignados.
3. Prepárate
Clona el repositorio
git clone https://github.com/google-ai-edge/litert-samples.git
Todos los recursos para este codelab se encuentran en la siguiente ubicación:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Este directorio tiene dos subproyectos, cada uno con una compilación completa de la misma muestra:
Directorio | Sistema de compilación | Dependencia de LiteRT |
| CMake y NDK de Android |
|
| Bazel | Compila LiteRT desde la fuente |
Elige un camino y síguelo. El código es idéntico en ambos directorios, solo difieren el sistema de compilación y la estrategia de dependencia. Si quieres la configuración más rápida, elige use_prebuilt_litert/. Si necesitas modificar LiteRT o trabajar dentro de un monorepo de Bazel existente, usa build_from_source/.
Nota sobre las rutas de acceso a archivos
Todas las rutas de acceso de archivos de este instructivo usan el formato de Linux/macOS. Los usuarios de Windows deben usar WSL2.
Descripción general del directorio
Ambos subproyectos comparten el mismo diseño de origen:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Además:
use_prebuilt_litert/agregaCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shythird_party/stb/.build_from_source/agrega un archivoBUILDde Bazel y usadeploy_and_run_on_android.shque apunta abazel-bin/.
4. Comprende la estructura del proyecto
Tres puntos de entrada, una canalización
main_cpu.cc, main_gpu.cc y main_npu.cc contienen una función main() que controla toda la canalización de segmentación. La canalización es idéntica en los tres casos; solo difieren la configuración del acelerador LiteRT y la estrategia de búfer:
Archivo | Accelerator | Estrategia de búfer |
|
| Memoria de CPU |
|
| Memoria de CPU con backend de OpenCL |
|
| Memoria de CPU con CPU de resguardo |
Los tres comparten las mismas utilidades ImageProcessor (sombreadores de cómputos de OpenGL ES para el preprocesamiento y el posprocesamiento) y ImageUtils (E/S de imágenes de STB).
La canalización completa
Todos los puntos de entrada siguen la misma estructura de cinco fases:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Load:
ImageUtils::LoadImage()decodifica el JPEG en la memoria de la CPU con la biblioteca de imágenes de STB. - Carga:
processor.CreateOpenGLTexture()sube los píxeles sin procesar a una textura de GPU (OpenGL RGBA8). - Preprocess:
processor.PreprocessInputForSegmentation()ejecuta un sombreador de procesamiento de GLSL que cambia el tamaño de la textura a 256 × 256 y normaliza los valores de píxeles de[0, 1]a[-1, 1]. El resultado se almacena en un SSBO de la GPU. - Infer: Los datos del SSBO se escriben en un
TensorBuffery uncompiled_model.Run()(oRunAsync()) de LiteRT, que ejecuta el modelo. - Postprocess: Los datos de salida de coma flotante de 6 canales del modelo se desentrelazan en 6 SSBO de máscara de un solo canal, que luego se vuelven a combinar con la imagen original.
- Guardar:
ImageUtils::SaveImage()escribe la imagen RGBA final como PNG.
5. APIs de C++ de Core LiteRT
Antes de compilar, familiarízate con los tres tipos clave de LiteRT C++ que se usan en todos los puntos de entrada. Todos viven en el espacio de nombres litert::.
litert::Environment
El objeto Environment es el contexto raíz para todas las operaciones de LiteRT. Crea el objeto una vez y pásalo a CompiledModel::Create. Para el uso de la NPU, configúrala con el directorio de la biblioteca de complementos del proveedor.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel carga y precompila tu modelo de TFLite para el hardware solicitado en el momento de la construcción. Luego, la inferencia se reduce a completar búferes y llamar a Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Los búferes de tensores contienen datos de entrada y salida. Siempre créalas desde CompiledModel para que tengan el tamaño y la alineación correctos para el hardware de destino.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Macros de control de errores
Macro | Comportamiento |
| Asigna o llama a |
| Llama a |
| Asigna o propaga el error al llamador |
6. Compilación: Opción A: SDK de C++ de LiteRT prediseñado (CMake)
Esta es la ruta de acceso recomendada si no necesitas modificar LiteRT. La secuencia de comandos de compilación controla la descarga de los encabezados del SDK, la copia de tu .so, la recuperación de STB y la invocación de CMake y el NDK en un solo comando.
Paso 1: Obtén libLiteRt.so de Maven
LiteRT envía su tiempo de ejecución como una biblioteca compartida dentro de un AAR de Android en Google Maven. Descárgalo y extrae el archivo arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Para la compatibilidad con la GPU, también extrae el acelerador OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

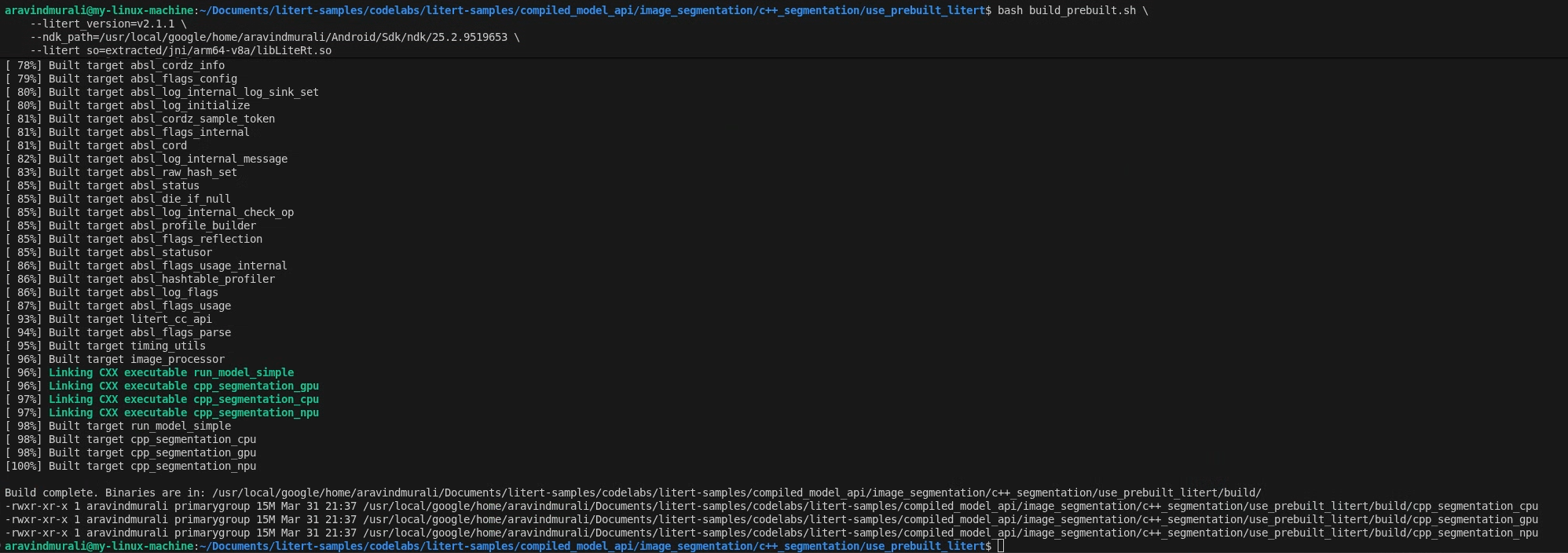
Paso 2: Ejecuta build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
La secuencia de comandos hará lo siguiente:
- Descarga
litert_cc_sdk.zip(encabezados del SDK y archivos cmake) de la versión de LiteRT en GitHub. Se omite en ejecuciones posteriores si ya está presente. - Copia
libLiteRt.soenlitert_cc_sdk/. - Descarga los encabezados de la imagen de la STB en
third_party/stb/, se omite si ya están presentes. - Configura y compila con CMake usando la cadena de herramientas del NDK de Android para
arm64-v8aenandroid-26.
Si la operación se realiza correctamente, verás tres archivos binarios en build/:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Qué hace CMakeLists.txt
Abre CMakeLists.txt. Requiere C++20, incorpora el SDK de LiteRT a través de add_subdirectory, vincula OpenGL ES 3 (GLESv3) y EGL, y, luego, usa una macro auxiliar para crear cada objeto binario a partir de su fuente main_*.cc:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Compilación: Opción B: Compila con Bazel (desde el código fuente)
Elige esta ruta si prefieres Bazel como tu sistema de compilación, que compila el tiempo de ejecución de LiteRT desde el código fuente, o si necesitas trabajar en un espacio de trabajo de Bazel existente.
Requisitos previos
Además del NDK y ADB que se indican en la sección "Antes de comenzar", necesitarás lo siguiente:
- Bazel instalado y en tu
PATH - Es una clonación completa del repositorio de código fuente de muestras de LiteRT.
Paso 1: Configura el espacio de trabajo de muestras de LiteRT
Todos los comandos se ejecutan desde la raíz del repositorio de muestras de LiteRT.
cd /path/to/litert-samples
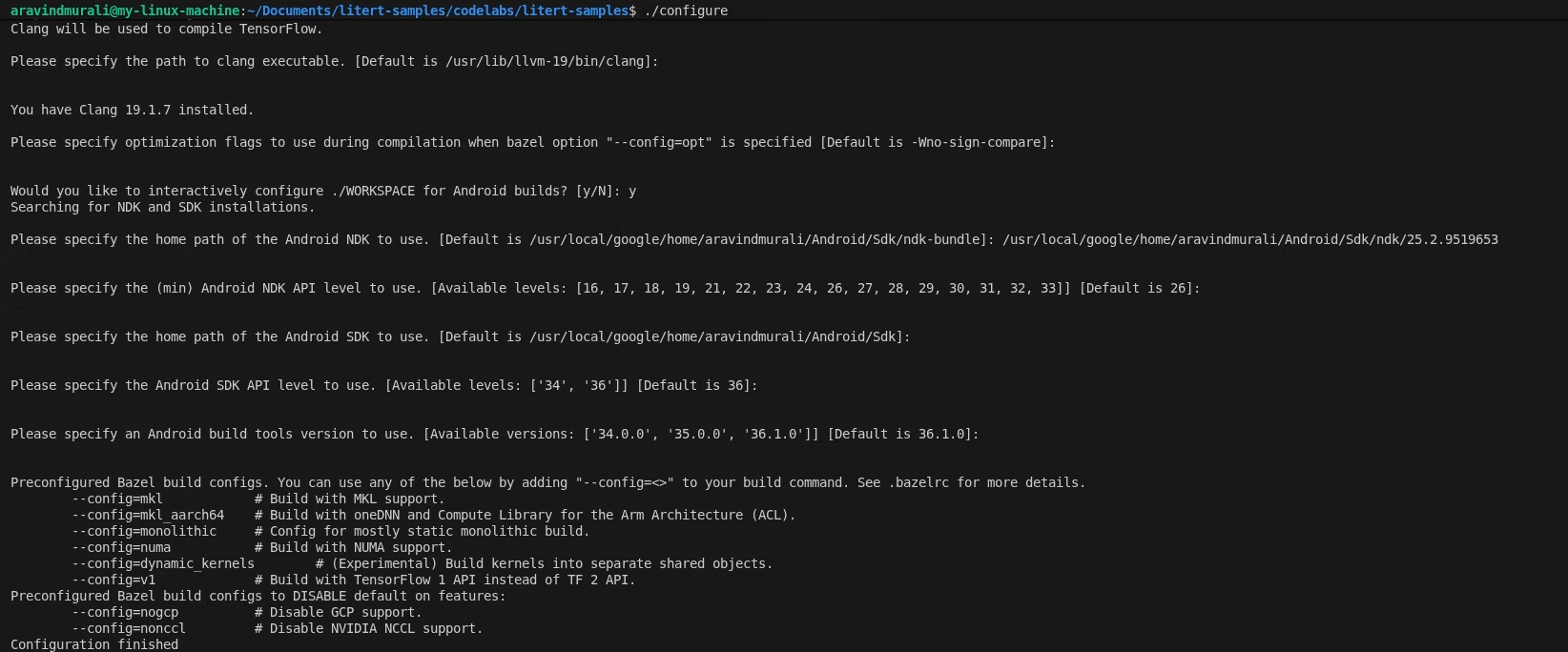
./configure
Realice las siguientes acciones cuando se le solicite:
- Acepta los valores predeterminados para Python y la ruta de acceso a la biblioteca de Python.
- Responde N a la compatibilidad con ROCm y CUDA.
- Selecciona clang (probado con la versión 18.1.3) como el compilador.
- Acepta las marcas de optimización predeterminadas.
- Responde Y para configurar el WORKSPACE para las compilaciones de Android.
- Establece el nivel mínimo del NDK de Android en, al menos, 26.
- Proporciona la ruta de acceso a tu SDK de Android.
- Establece el nivel de API del SDK de Android en el valor predeterminado (36) y las herramientas de compilación en 36.0.0.
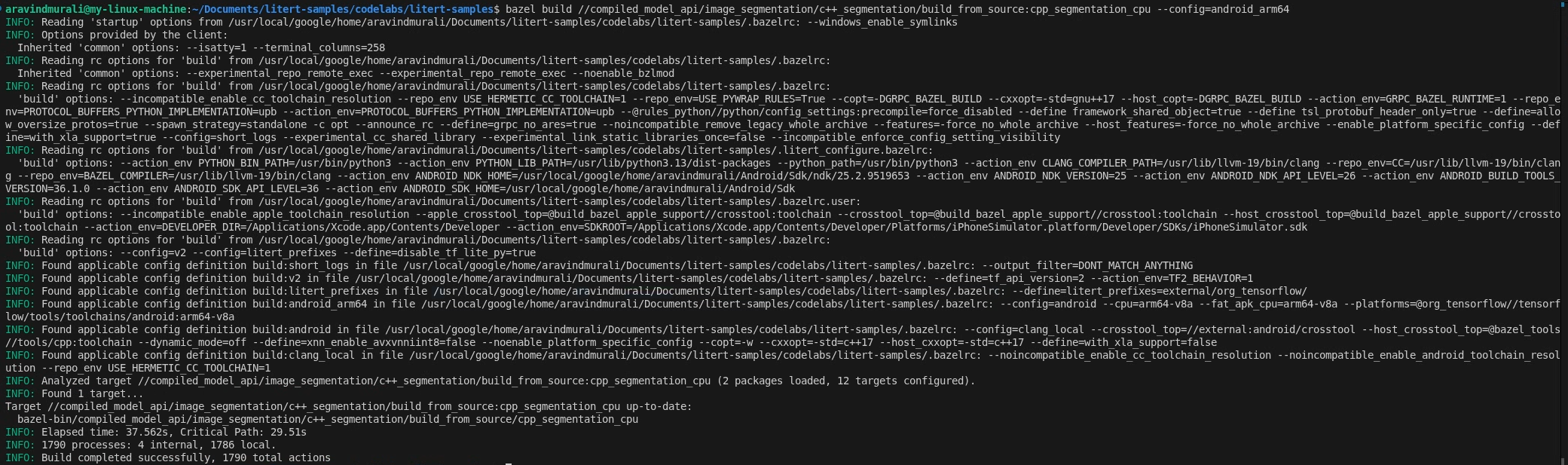
Paso 2: Compila los destinos de CPU y GPU
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Paso 3: Compila el destino de la NPU
Qualcomm HTP
- Descarga el SDK de QAIRT v2.41 o una versión posterior y extráelo.
- Asegúrate de que el contenido del SDK extraído esté dentro de un subdirectorio llamado
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Compila y pasa la ruta principal que termina en
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Se requiere la marca --nocheck_visibility porque algunos destinos de LiteRT ascendentes tienen valores predeterminados de visibilidad restringida.
APU de MediaTek
No se requiere ningún SDK adicional. El tiempo de ejecución de NeuroPilot es una biblioteca del sistema en los dispositivos Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
El archivo BUILD
Abre build_from_source/BUILD. Define cuatro destinos de cc_binary (uno por acelerador más un destino de NPU de MediaTek dedicado), cada uno de los cuales depende de los destinos de biblioteca compartidos image_processor, image_utils y timing_utils:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
El destino de la GPU agrega libLiteRtClGlAccelerator.so como una dependencia de datos para que Bazel la incluya en los runfiles. Los destinos de la NPU agregan archivos .so de complementos del compilador y de envío del proveedor como dependencias de datos.
8. Preprocesamiento acelerado por GPU con sombreadores de procesamiento
Los tres puntos de entrada usan la misma canalización de sombreadores de cómputos de OpenGL ES para el procesamiento previo. Comprenderlo es clave para saber por qué la ruta de la GPU es mucho más rápida que la de la CPU.
Cómo configurar un contexto de EGL sin interfaz gráfica
ImageProcessor::InitializeGL() crea un contexto de EGL sin interfaz gráfica, es decir, un contexto de OpenGL sin ventana ni pantalla adjuntas. Esta es una práctica estándar para el procesamiento de GPU fuera de la pantalla en Android. Luego, compila los cinco programas de ComputeShader GLSL desde el disco:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Sube la imagen de entrada a la GPU
ImageUtils::LoadImage() decodifica el JPEG en la memoria de la CPU (a través de la biblioteca de STB) y, luego, lo sube a una textura de la GPU:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
A partir de este punto, la imagen original reside en la memoria de la GPU como una textura OpenGL.
El sombreador de procesamiento previo de procesamiento
shaders/preprocess_compute.glsl envía grupos de subprocesos de 8 × 8 a través de la cuadrícula de salida de 256 × 256. Cada subproceso controla un píxel de salida: muestrea la textura de entrada con un filtro bilineal (cambio de tamaño de hardware gratuito), convierte el valor RGB de [0, 1] en [-1, 1] y escribe en el SSBO de salida:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Para la ruta estándar (sin copia cero), este SSBO se vuelve a leer en la CPU y se escribe en el tensor de LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. Inferencia de CPU
Abre main_cpu.cc. La configuración de LiteRT consta de tres líneas:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Después del procesamiento previo, la inferencia es una sola llamada síncrona:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run() se bloquea hasta que se completa la inferencia. El modelo de punto flotante selfie_multiclass_256x256.tflite se ejecuta en los núcleos ARM Cortex y suele tardar entre 116 y 128 ms en un dispositivo de gama media.
Uso binario:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. Inferencia en GPU (OpenCL)
Abre main_gpu.cc. La ruta de GPU introduce dos conceptos que no están presentes en la ruta de CPU: litert::Options para configurar el acelerador de GPU (con el backend de OpenCL) y la ejecución asíncrona.
Cómo configurar las opciones de GPU
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Inferencia asíncrona
La ruta de GPU usa RunAsync() en lugar de Run(). Esto envía trabajo a la cola de comandos de la GPU y regresa de inmediato. Luego, sincroniza antes de leer los resultados:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Este diseño no bloqueante te permite superponer el trabajo de la CPU con la ejecución de la GPU en una canalización en tiempo real.
Uso binario:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Posprocesamiento: Desentrelazado y combinación
Después de que se completan Run() o RunAsync(), output_buffers[0] contiene un array de números de punto flotante planos de forma [256 × 256 × 6] en orden intercalado. Las 6 puntuaciones de clase para el píxel (row, col) se encuentran en los índices (row * 256 + col) * 6 a (row * 256 + col) * 6 + 5.
Desentrelaza en 6 SSBO de máscara
Un asistente de CPU divide el array intercalado en 6 arrays de números de punto flotante de un solo canal y sube cada uno a su propio SSBO de GPU:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Mezcla de colores de las máscaras en la imagen original
processor.ApplyColoredMasks() ejecuta el sombreador mask_blend_compute.glsl. Para cada píxel de salida, encuentra la clase con la puntuación más alta (argmax en los 6 SSBO de máscara) y compone alfa el color correspondiente sobre el píxel de la imagen original. Los seis colores se definen en cada punto de entrada:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
El canal alfa de 0.1f mantiene el tinte sutil para que la imagen original siga siendo visible.
Cómo guardar el resultado
El SSBO de punto flotante RGBA combinado final se lee, se ajusta a [0, 1], se convierte a unsigned char y se guarda como PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Implementa y ejecuta en el dispositivo
Conecta tu dispositivo Android con un cable USB y verifica la conectividad de ADB:
adb devices

Usa deploy_and_run_on_android.sh
Cada variante tiene su propio script de implementación. La variante de CMake apunta al directorio build/, mientras que la variante de Bazel apunta a bazel-bin/. Ambas secuencias de comandos:
- Crea
/data/local/tmp/cpp_segmentation_android/en el dispositivo. - Envía los archivos binarios, los sombreadores GLSL, el modelo, la imagen de prueba y los archivos de tiempo de ejecución
.so. - Ejecuta la inferencia con
adb shell. - Tira de
output_segmented.pnghacia tu máquina.
Variante de CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Variante de Bazel (build_from_source/)
Ejecuta estos comandos desde la raíz del repo de muestras de LiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
La marca --phone controla qué bibliotecas de proveedores y modelos específicos del dispositivo se usan. Valores admitidos: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) y pixel11 (Tensor G6).
Tiempo de inferencia
Después de la inferencia, PrintTiming() imprime un desglose completo de la generación de perfiles:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Rendimiento de referencia en el Samsung S25 Ultra (Snapdragon 8 Elite):
Accelerator | Tipo de ejecución | Inferencia | E2E |
CPU | Sincronizar | Entre 116 y 128 ms | Aproximadamente 157 ms |
GPU (OpenCL) | Asíncrono | ~0.95 ms | Entre 35 y 43 ms |
13. Avanzado (opcional): Inferencias de la NPU
Para obtener el máximo rendimiento, LiteRT admite la aceleración de la NPU con bibliotecas de complementos específicas del proveedor. La ruta de la NPU puede lograr una latencia de extremo a extremo de hasta 9 ms.
Dispositivos y modos compatibles
Chip | Ejemplo de dispositivo | Modo | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | Aproximadamente 17 ms |
Qualcomm SM8750 | Galaxy S25 | AOT | Aproximadamente 17 ms |
Qualcomm (cualquiera) | — | JIT | Aproximadamente 28 ms |
MediaTek Dimensity 9400 | — | JIT | Aprox. 9 ms |
Google Tensor G3 a G6 | Pixel 8 a 11 | AOT/JIT | Varía |
La compilación anticipada (AOT) usa un modelo precompilado específico del dispositivo (p.ej., selfie_multiclass_256x256_SM8650.tflite). Esta es la opción más rápida, pero es específica del chip.
JIT (Just-in-Time) usa el selfie_multiclass_256x256.tflite estándar y compila para la NPU en el tiempo de ejecución. Esto genera una primera ejecución más lenta y es independiente del chip.
Requisitos previos adicionales
Qualcomm HTP:
- SDK de QAIRT v2.41 o posterior (proporciona archivos
libQnnHtp.so, stub o skel.so). libLiteRtDispatch_Qualcomm.sode la versión de las bibliotecas de tiempo de ejecución de la NPU de LiteRT en GitHub.
APU de MediaTek:
libLiteRtDispatch_MediaTek.sode la versión de las bibliotecas de tiempo de ejecución de la NPU de LiteRT.- Tiempo de ejecución de NeuroPilot (ya es una biblioteca del sistema en dispositivos Dimensity 9400, por lo que no es necesario enviar nada).
Google Tensor:
libLiteRtDispatch_GoogleTensor.sode la versión de las bibliotecas de tiempo de ejecución de la NPU de LiteRT.
Entorno y opciones de la NPU
main_npu.cc apunta el Environment al directorio de la biblioteca de envío del proveedor en el dispositivo y, luego, establece opciones de rendimiento específicas del proveedor:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
En el caso de MediaTek, reemplaza el bloque GetQualcommOptions():
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Implementación para la NPU
Variante de CMake: Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
Variante de CMake: MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Variante de Bazel: Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Variante de Bazel: MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Variante de Bazel: Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
En el caso de la variante de Bazel, las bibliotecas del SDK de QAIRT se seleccionan automáticamente del árbol de archivos ejecutables bazel-bin cuando se establece LITERT_QAIRT_SDK en el tiempo de compilación. La variante de CMake requiere que la marca --host_npu_lib apunte a tu SDK de QAIRT extraído.
14. ¡Felicitaciones!
Compilaste y ejecutaste correctamente una canalización de segmentación de imágenes en C++ en Android con LiteRT. Aprendió a hacer lo siguiente:
- Compila de forma cruzada un archivo binario de C++ para Android
arm64-v8acon CMake + NDK o Bazel. - Usa la API de C++ de LiteRT (
Environment,CompiledModel,TensorBuffer) para realizar inferencias eficientes integrado en el dispositivo. - Preprocesa datos de imágenes en la GPU con sombreadores de cómputos de OpenGL ES 3.1.
- Ejecuta la inferencia de CPU síncrona y la inferencia de GPU asíncrona (OpenCL).
- Configura la aceleración de la NPU para dispositivos Qualcomm, MediaTek y Google Tensor.
- Implementa y ejecuta un archivo binario de C++ en Android con ADB.
Próximos pasos
- Intercambia un modelo de TFLite diferente (p.ej., estimación de profundidad o detección de poses).
- Integra la canalización de C++ en una app del NDK de Android con JNI.
- Genera un perfil del uso de memoria con el Inspector de GPU de Android junto con la salida de sincronización.
- Explora la cuantización del modelo para reducir aún más la latencia de inferencia de la NPU.