
1. Hinweis
Wenn Sie Code eingeben, können Sie Ihr Muskelgedächtnis trainieren und Ihr Verständnis des Materials vertiefen. Auch wenn das Kopieren und Einfügen von Code Zeit sparen kann, kann sich die Investition in diese Praxis langfristig in Form von höherer Effizienz und besseren Programmierkenntnissen auszahlen.
In diesem Codelab erfahren Sie, wie Sie ein binäres C++-Programm für die Bildsegmentierung erstellen, das direkt auf einem Android-Gerät ausgeführt wird. Dazu verwenden Sie die leistungsstarke On-Device-Laufzeit LiteRT von Google. In diesem Codelab wird kein Kotlin oder Android Studio verwendet, sondern ein C++-Binärprogramm erstellt. Sie werden sie mit CMake oder Bazel cross-compilieren und mit ADB bereitstellen. Dieselbe LiteRT C++ API funktioniert auf jeder Plattform (Android, Linux, eingebettet). Sie ist daher eine nützliche Grundlage für leistungsintensive Anwendungen, Robotik und Edge-Systeme.
Sie durchlaufen die gesamte Pipeline:
- Richten Sie die Build-Umgebung ein (CMake + Android NDK oder Bazel).
- Das LiteRT C++ SDK wird entweder über eine vorgefertigte Version oder über den Quellcode verknüpft.
- Verwendung von OpenGL ES-Compute-Shadern für die GPU-beschleunigte Vor- und Nachbearbeitung von Bildern.
- Das
selfie_multiclass-Segmentierungsmodell mit der LiteRT C++ API ausführen. - Beschleunigung der Inferenz auf CPU, GPU (OpenCL) und NPU (Qualcomm / MediaTek).
- Nachbearbeitung der Rohausgabe des Modells in ein farblich gemischtes Segmentierungsbild.
- Bereitstellung auf einem physischen Android-Gerät mit ADB und Abrufen des Ergebnisses.
Am Ende erhalten Sie ein Ergebnis, das dem folgenden Bild ähnelt: ein statisches Bild, das durch die gesamte Pipeline verarbeitet wurde und auf dem jede der sechs Segmentierungsklassen in einer anderen Farbe dargestellt ist:

Vorbereitung
Dieses Codelab richtet sich an Entwickler, die mit C++ vertraut sind und Machine-Learning-Modelle auf der C++-Ebene auf Android ausführen möchten. Sie sollten sich mit Folgendem auskennen:
- C++-Grundlagen (Zeiger, Vektoren, Includes)
- Grundlegende Android-/ADB-Konzepte (
adb push,adb shell). - Verwenden eines Terminals und von Shell-Skripts unter Linux oder macOS.
Lerninhalte
- So wird eine C++-Binärdatei für Android
arm64-v8amit CMake + NDK oder Bazel cross-compiliert. - Verwendung der LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) für effiziente Inferenz auf dem Gerät. - Wie OpenGL ES 3.1-Compute-Shader die Vor- und Nachbearbeitung vollständig auf der GPU beschleunigen.
- So konfigurieren Sie LiteRT für die Beschleunigung durch CPU, GPU (OpenCL) und NPU (Qualcomm HTP, MediaTek APU, Google Tensor).
- Der Unterschied zwischen synchroner (
Run) und asynchroner (RunAsync) Inferenz. - So stellen Sie eine C++-Binärdatei auf Android bereit und führen sie mit ADB aus.
Voraussetzungen
- Ein Linux- oder macOS-Computer (Windows-Nutzer sollten WSL2 verwenden).
- Android NDK r25c oder höher (herunterladen).
- Für CMake-Pfad: CMake ≥ 3.22 (
sudo apt-get install cmake). - Für Bazel-Pfad: Bazel ist installiert und das vollständige LiteRT-Beispielrepository ist vorhanden.
- ADB in Ihren
PATH(Android Platform Tools). - Ein physisches Android-Gerät, das am besten auf dem Galaxy S24/S25 oder Pixel getestet wurde.
2. Bildsegmentierung
Die Bildsegmentierung ist eine Aufgabe im Bereich Computer Vision, bei der jedem Pixel in einem Bild ein Klassenlabel zugewiesen wird. Im Gegensatz zur Objekterkennung, bei der ein Begrenzungsrahmen gezeichnet wird, liefert die Segmentierung eine präzise, pixelgenaue Darstellung davon, wo jedes Objekt beginnt und endet.
In diesem Codelab wird das Modell selfie_multiclass_256x256 verwendet, das jedes Pixel in eine von 6 Klassen einteilt:
Klassenindex | Segment |
0 | Hintergrund |
1 | Haar |
2 | Körperhaut |
3 | Gesichtshaut |
4 | Kleidung |
5 | Zubehör (Brillen, Schmuck usw.) |
Das Modell gibt einen Gleitkommatensor der Form [1, 256, 256, 6] aus. Für jedes der 256 × 256 Pixel gibt es sechs Konfidenzwerte, einen für jede Klasse. Die Klasse mit dem höchsten Wert gewinnt diesen Pixel (argmax).
LiteRT: Leistung am Edge
LiteRT ist die leistungsstarke Laufzeit der nächsten Generation von Google für TFLite-Modelle. Die C++-API bietet direkten Zugriff auf Hardwarebeschleuniger mit geringem Overhead und einer einheitlichen Schnittstelle für alle drei:
- CPU: Universell kompatibel; Inferenz dauert auf einem Mittelklassegerät etwa 128 ms.
- GPU (OpenCL): Inferenz dauert etwa 1 ms, End-to-End-Zeit je nach Pufferstrategie etwa 17–43 ms.
- NPU: ~9–28 ms End-to-End auf Geräten mit Qualcomm Snapdragon, MediaTek Dimensity 9400 und Google Tensor, je nach AOT. Just-in-time-Kompilierung.
Die wichtigste Abstraktion ist CompiledModel: Das Modell wird zur Ladezeit vorkompiliert und für die Zielhardware optimiert. Die Inferenz wird so auf einen Run()-Aufruf für vorab zugewiesene Puffer reduziert.
3. Einrichten
Repository klonen
git clone https://github.com/google-ai-edge/litert-samples.git
Alle Ressourcen für dieses Codelab befinden sich in:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
Dieses Verzeichnis enthält zwei Unterprojekte, die jeweils einen vollständigen Build desselben Beispiels darstellen:
Verzeichnis | Build-System | LiteRT-Abhängigkeit |
| CMake + Android NDK | Vorgefertigte |
| Bazel | Kompiliert LiteRT aus dem Quellcode |
Wählen Sie einen Pfad aus und folgen Sie ihm. Der Code ist in beiden Verzeichnissen identisch. Nur das Build-System und die Abhängigkeitsstrategie unterscheiden sich. Wenn Sie die schnellste Einrichtung wünschen, wählen Sie use_prebuilt_litert/ aus. Wenn Sie LiteRT selbst ändern oder in einem vorhandenen Bazel-Monorepo arbeiten müssen, verwenden Sie build_from_source/.
Hinweis zu Dateipfaden
Alle Dateipfade in dieser Anleitung verwenden das Linux-/macOS-Format. Windows-Nutzer sollten WSL2 verwenden.
Verzeichnisübersicht
Beide Teilprojekte haben dasselbe Quelllayout:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
Weitere Schritte:
use_prebuilt_litert/fügtCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shundthird_party/stb/hinzu.build_from_source/fügt eine Bazel-DateiBUILDhinzu und verwendetdeploy_and_run_on_android.sh, die aufbazel-bin/verweist.
4. Projektstruktur verstehen
Drei Einstiegspunkte, eine Pipeline
main_cpu.cc, main_gpu.cc und main_npu.cc enthalten jeweils eine main()-Funktion, die die gesamte Segmentierungspipeline steuert. Die Pipeline ist für alle drei identisch. Nur die LiteRT-Beschleunigerkonfiguration und die Pufferstrategie unterscheiden sich:
Datei | Beschleuniger | Pufferstrategie |
|
| CPU-Speicher |
|
| CPU-Speicher mit OpenCL-Backend |
|
| CPU-Speicher mit CPU-Fallback |
Alle drei verwenden dieselben ImageProcessor- (OpenGL ES-Compute-Shader für die Vor- und Nachbearbeitung) und ImageUtils-Dienstprogramme (STB-Bild-I/O).
Die vollständige Pipeline
Jeder Einstiegspunkt folgt derselben fünfphasigen Struktur:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- Laden:
ImageUtils::LoadImage()decodiert das JPEG mithilfe der STB-Bildbibliothek in den CPU-Arbeitsspeicher. - Hochladen:
processor.CreateOpenGLTexture()lädt die Rohpixel in eine GPU-Textur (OpenGL RGBA8) hoch. - Vorverarbeiten:
processor.PreprocessInputForSegmentation()führt einen GLSL-Compute-Shader aus, der die Größe der Textur auf 256 × 256 ändert und die Pixelwerte von[0, 1]auf[-1, 1]normalisiert. Das Ergebnis wird in einem GPU-SSBO gespeichert. - Infer: SSBO-Daten werden in ein LiteRT-
TensorBuffergeschrieben undcompiled_model.Run()(oderRunAsync()) führt das Modell aus. - Nachbearbeitung: Die 6-Kanal-Gleitkommazahl-Ausgabe des Modells wird in 6 SSBOs mit Einzelkanalmasken deinterleaved, die dann farblich wieder in das Originalbild eingefügt werden.
- Speichern:
ImageUtils::SaveImage()schreibt das endgültige RGBA-Bild als PNG.
5. Core LiteRT C++ APIs
Bevor Sie mit der Entwicklung beginnen, sollten Sie sich mit den drei wichtigsten LiteRT C++-Typen vertraut machen, die in allen Einstiegspunkten verwendet werden. Alle befinden sich im Namespace litert::.
litert::Environment
Der Environment ist der Stammkontext für alle LiteRT-Vorgänge. Erstellen Sie es einmal und übergeben Sie es an CompiledModel::Create. Konfigurieren Sie die NPU-Nutzung mit dem Verzeichnis der Vendor-Plugin-Bibliothek.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel lädt und vorkompiliert Ihr TFLite-Modell für die angeforderte Hardware zur Konstruktionszeit. Die Inferenz beschränkt sich dann auf das Füllen von Puffern und das Aufrufen von Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
Tensor-Puffer enthalten Ein-/Ausgabedaten. Erstellen Sie sie immer über CompiledModel, damit sie die richtige Größe und Ausrichtung für die Zielhardware haben.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
Makros zur Fehlerbehandlung
Macro | Verhalten |
| Weist |
| Ruft |
| Weist dem Aufrufer einen Fehler zu oder gibt ihn weiter |
6. Build – Option A: Vorgefertigtes LiteRT C++ SDK (CMake)
Dies ist der empfohlene Pfad, wenn Sie LiteRT selbst nicht ändern müssen. Das Build-Skript übernimmt das Herunterladen der SDK-Header, das Kopieren von .so, das Abrufen von STB und das Aufrufen von CMake + NDK in einem einzigen Befehl.
Schritt 1: libLiteRt.so von Maven abrufen
Die LiteRT-Laufzeit wird als gemeinsam genutzte Bibliothek in einem Android-AAR auf Google Maven ausgeliefert. Laden Sie die Datei herunter und extrahieren Sie die arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
Für die GPU-Unterstützung extrahieren Sie auch den OpenCL/GL-Beschleuniger:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

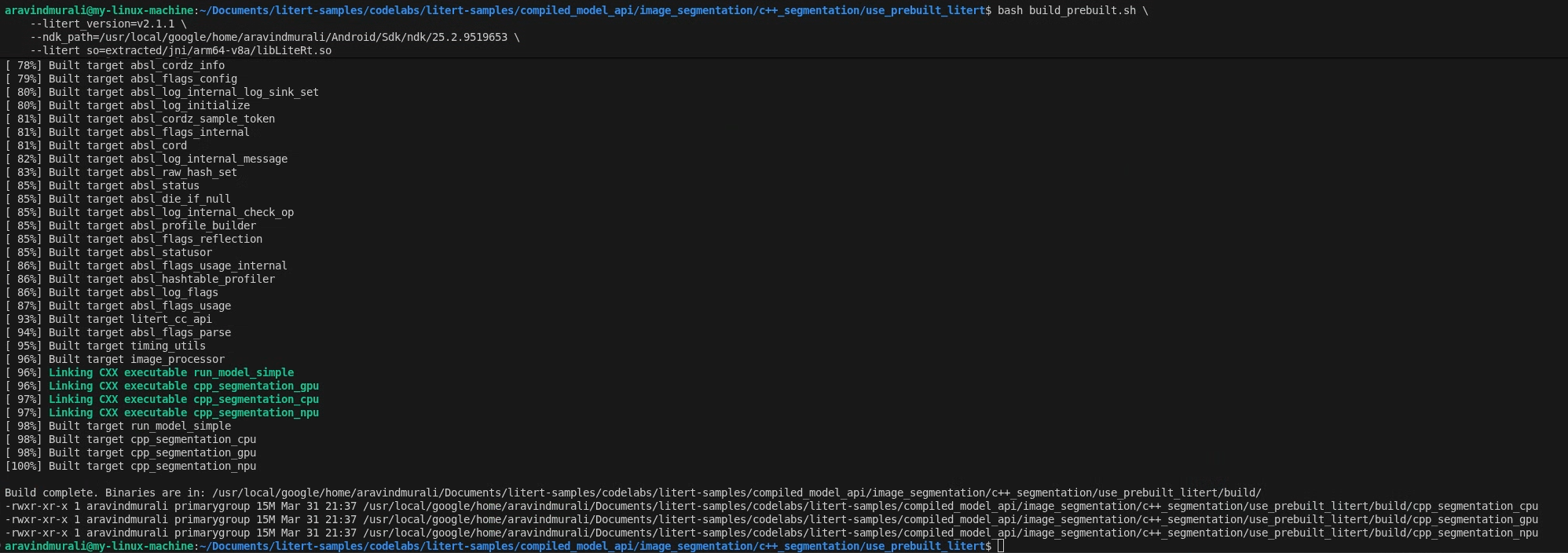
Schritt 2: build_prebuilt.sh ausführen
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
Das Skript führt Folgendes aus:
- Laden Sie
litert_cc_sdk.zip(SDK-Header + CMake-Dateien) aus der LiteRT-GitHub-Version herunter. Dieser Schritt wird bei nachfolgenden Ausführungen übersprungen, wenn die Datei bereits vorhanden ist. - Kopieren Sie
libLiteRt.soinlitert_cc_sdk/. - STB-Image-Header in
third_party/stb/herunterladen – wird übersprungen, falls vorhanden. - Konfigurieren und erstellen Sie mit CMake unter Verwendung der Android NDK-Toolchain für
arm64-v8aunterandroid-26.
Bei Erfolg werden drei Binärdateien in build/ angezeigt:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
Aufgabe von CMakeLists.txt
Öffnen Sie CMakeLists.txt. Es erfordert C++20, ruft das LiteRT SDK über add_subdirectory auf, verknüpft OpenGL ES 3 (GLESv3) und EGL und verwendet dann ein Hilfsmakro, um jedes Binärprogramm aus der zugehörigen main_*.cc-Quelle zu erstellen:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. Build – Option B: Mit Bazel erstellen (aus der Quelle)
Wählen Sie diesen Pfad aus, wenn Sie Bazel als Build-System bevorzugen, mit dem die LiteRT-Laufzeit aus dem Quellcode kompiliert wird, oder wenn Sie in einem vorhandenen Bazel-Arbeitsbereich arbeiten müssen.
Vorbereitung
Zusätzlich zu den im Abschnitt „Vorbereitung“ aufgeführten NDK- und ADB-Tools benötigen Sie:
- Bazel ist installiert und befindet sich in Ihrem
PATH. - Ein vollständiger Klon des Quell-Repositorys der LiteRT-Beispiele.
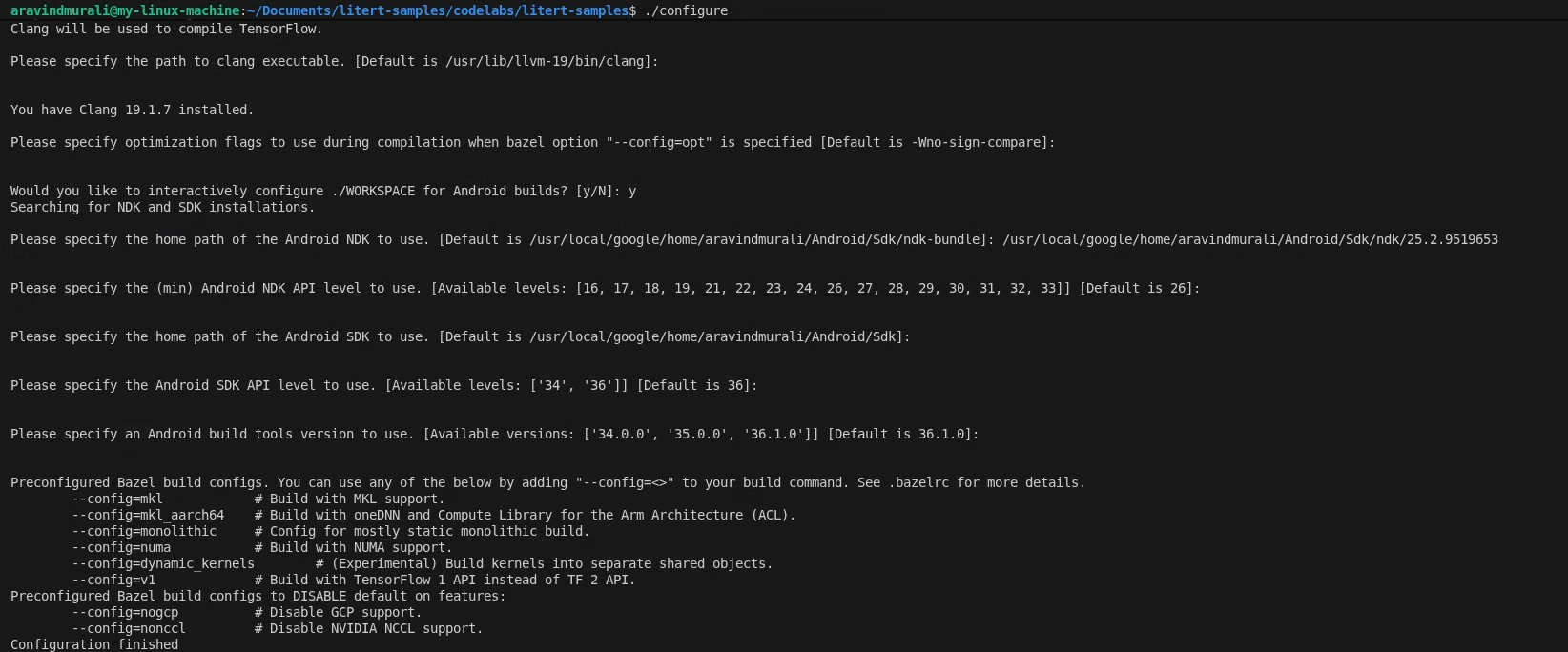
Schritt 1: LiteRT-Beispielarbeitsbereich konfigurieren
Alle Befehle werden im Stammverzeichnis des LiteRT-Beispiel-Repositorys ausgeführt.
cd /path/to/litert-samples
./configure
Tun Sie Folgendes, wenn Sie dazu aufgefordert werden:
- Übernehmen Sie die Standardwerte für den Python- und den Python-Bibliothekspfad.
- Antworte mit N auf die Frage nach der Unterstützung von ROCm und CUDA.
- Wählen Sie clang (getestet mit 18.1.3) als Compiler aus.
- Standard-Optimierungs-Flags akzeptieren
- Antworten Sie mit Y, um den WORKSPACE für Android-Builds zu konfigurieren.
- Legen Sie das minimale Android-NDK-Level auf mindestens 26 fest.
- Geben Sie den Pfad zu Ihrem Android SDK an.
- Legen Sie die Android SDK API-Ebene auf den Standardwert (36) und die Build-Tools auf 36.0.0 fest.
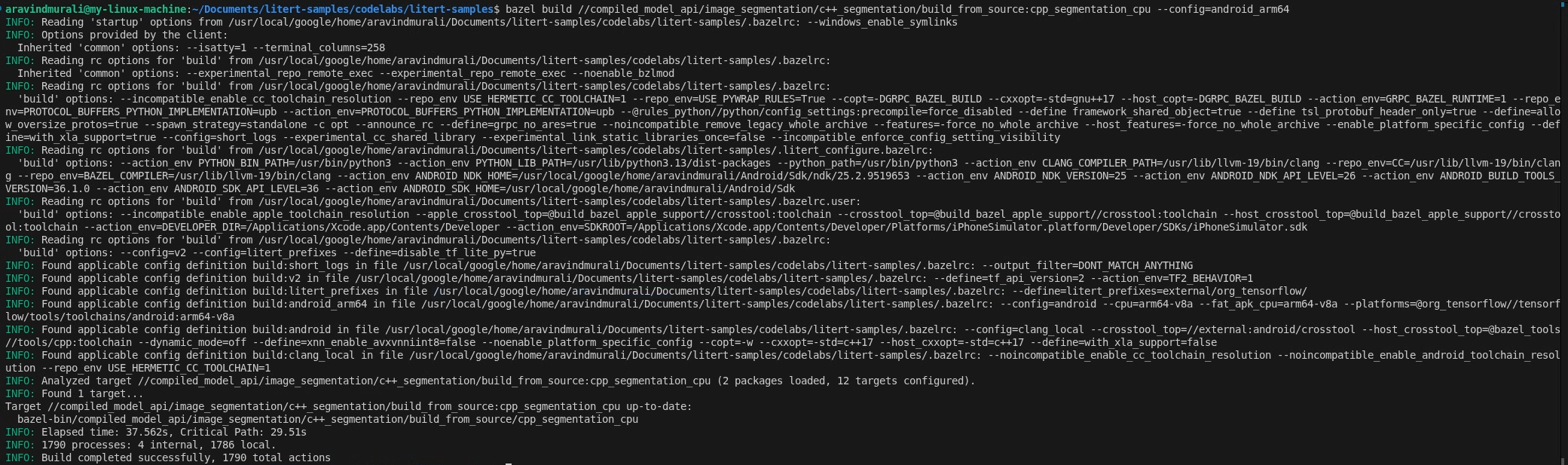
Schritt 2: CPU- und GPU-Ziele erstellen
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
Schritt 3: NPU-Ziel erstellen
Qualcomm HTP
- Laden Sie das QAIRT SDK v2.41 oder höher herunter und extrahieren Sie es.
- Achten Sie darauf, dass sich der extrahierte SDK-Inhalt in einem Unterverzeichnis namens
latest/befindet:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - Erstellen Sie den Build und übergeben Sie den übergeordneten Pfad, der mit
/endet:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
Das --nocheck_visibility-Flag ist erforderlich, weil für einige Upstream-LiteRT-Ziele standardmäßig eine eingeschränkte Sichtbarkeit gilt.
MediaTek APU
Es ist kein zusätzliches SDK erforderlich. Die NeuroPilot-Laufzeit ist eine Systembibliothek auf Geräten mit Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
Datei BUILD
Öffnen Sie build_from_source/BUILD. Es werden vier cc_binary-Ziele definiert – eines pro Beschleuniger und ein dediziertes MediaTek-NPU-Ziel –, die jeweils von den freigegebenen image_processor-, image_utils- und timing_utils-Bibliothekszielen abhängen:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
Das GPU-Ziel fügt libLiteRtClGlAccelerator.so als Datenabhängigkeit hinzu, damit Bazel es in die Runfiles aufnimmt. Die NPU-Ziele fügen die Dateien .so für die Versendung durch den Anbieter und das Compiler-Plug-in als Datenabhängigkeiten hinzu.
8. GPU-beschleunigte Vorverarbeitung mit Compute-Shadern
Alle drei Einstiegspunkte verwenden dieselbe OpenGL ES-Compute-Shader-Pipeline für die Vorverarbeitung. Das Verständnis dafür ist entscheidend, um zu verstehen, warum der GPU-Pfad so viel schneller ist als der CPU-Pfad.
Monitorlosen EGL-Kontext einrichten
ImageProcessor::InitializeGL() erstellt einen monitorlosen EGL-Kontext, einen OpenGL-Kontext ohne angehängtes Fenster oder Display. Dies ist die Standardvorgehensweise für die Off-Screen-GPU-Berechnung unter Android. Anschließend werden die fünf GLSL-Compute-Shader-Programme von der Festplatte kompiliert:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
Eingabebild auf die GPU hochladen
Das JPEG wird von ImageUtils::LoadImage() (über die STB-Bibliothek) in den CPU-Arbeitsspeicher decodiert und dann in eine GPU-Textur hochgeladen:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
Ab diesem Punkt befindet sich das Originalbild als OpenGL-Textur im GPU-Arbeitsspeicher.
Der Compute-Shader für die Vorverarbeitung
shaders/preprocess_compute.glsl verteilt 8×8-Threadgruppen auf das 256×256-Ausgaberaster. Jeder Thread verarbeitet ein Ausgabepixel: Er führt ein Sampling der Eingabetextur mit bilinearer Filterung durch (kostenlose Hardware-Größenanpassung), konvertiert den [0, 1]-RGB-Wert in [-1, 1] und schreibt in den SSBO der Ausgabe:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
Für den Standardpfad (ohne Zero-Copy) wird dieser SSBO dann zurück zur CPU gelesen und in den LiteRT-Tensor geschrieben:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9. CPU-Inferenz
Öffnen Sie main_cpu.cc. Die Einrichtung von LiteRT besteht aus drei Zeilen:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
Nach der Vorverarbeitung ist die Inferenz ein einzelner synchroner Aufruf:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
Run()-Blöcke bis zum Abschluss der Inferenz. Das selfie_multiclass_256x256.tflite-Gleitkommamodell wird auf den ARM Cortex-Kernen ausgeführt und dauert auf einem Mittelklassegerät in der Regel etwa 116–128 ms.
Binäre Verwendung:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. GPU-Inferenz (OpenCL)
Öffnen Sie main_gpu.cc. Im GPU-Pfad werden zwei Konzepte eingeführt, die im CPU-Pfad nicht vorhanden sind: litert::Options zum Konfigurieren des GPU-Beschleunigers (mit dem OpenCL-Backend) und die asynchrone Ausführung.
GPU-Optionen konfigurieren
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
Asynchrone Inferenz
Im GPU-Pfad wird RunAsync() anstelle von Run() verwendet. Dadurch wird Arbeit an die GPU-Befehlswarteschlange gesendet und sofort zurückgegeben. Sie synchronisieren dann, bevor Sie die Ergebnisse lesen:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
Dieses nicht blockierende Design ermöglicht es Ihnen, CPU-Arbeit mit der GPU-Ausführung in einer Echtzeit-Pipeline zu überlappen.
Binäre Verwendung:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. Nachbearbeitung – Deinterlace und Blending
Nach Abschluss von Run() oder RunAsync() enthält output_buffers[0] ein flaches Float-Array der Form [256 × 256 × 6] in verschachtelter Reihenfolge. Die 6 Klasseneinstufungen für Pixel (row, col) befinden sich an den Indexpositionen (row * 256 + col) * 6 bis (row * 256 + col) * 6 + 5.
In sechs Masken-SSBOs (Shader Storage Buffer Objects) deinterleaven
Ein CPU-Helfer teilt das verschachtelte Array in sechs Float-Arrays mit jeweils einem Kanal auf und lädt jedes in einen eigenen GPU-SSBO hoch:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
Masken farblich in das Originalbild einfügen
processor.ApplyColoredMasks() führt den Shader mask_blend_compute.glsl aus. Für jedes Ausgabepixel wird die Klasse mit dem höchsten Wert (argmax über die 6 Masken-SSBOs) ermittelt und die entsprechende Farbe wird per Alpha-Compositing über das Originalbildpixel gelegt. Die sechs Farben sind in jedem Einstiegspunkt definiert:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
Der Alphawert von 0.1f sorgt dafür, dass die Tönung dezent bleibt und das Originalbild sichtbar bleibt.
Ausgabe speichern
Der endgültige gemischte RGBA-Float-SSBO wird zurückgelesen, auf [0, 1] begrenzt, in unsigned char konvertiert und als PNG gespeichert:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. Auf Gerät bereitstellen und ausführen
Verbinden Sie Ihr Android-Gerät über USB und prüfen Sie die ADB-Verbindung:
adb devices

„deploy_and_run_on_android.sh“ verwenden
Jede Variante hat ein eigenes Bereitstellungsskript. Die CMake-Variante verweist auf das Verzeichnis build/, die Bazel-Variante auf bazel-bin/. Beide Skripts:
- Erstellen Sie
/data/local/tmp/cpp_segmentation_android/auf dem Gerät. - Pushen Sie die Binärdatei, GLSL-Shader, das Modell, das Testbild und die
.so-Laufzeitdateien. - Führen Sie die Inferenz mit
adb shellaus. - Ziehen Sie
output_segmented.pngzurück zu Ihrem Computer.
CMake-Variante (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
Bazel-Variante (build_from_source/)
Führen Sie diese Befehle im Stammverzeichnis des LiteRT-Beispiel-Repositorys aus:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
Mit dem Flag --phone wird gesteuert, welche gerätespezifischen Modell- und Anbieterbibliotheken verwendet werden. Unterstützte Werte: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5) und pixel11 (Tensor G6).
Inferenz-Timing
Nach der Inferenz gibt PrintTiming() eine vollständige Profilaufschlüsselung aus:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
Referenzleistung auf dem Samsung Galaxy S25 Ultra (Snapdragon 8 Elite):
Beschleuniger | Ausführungstyp | Inferenz | E2E |
CPU | Synchronisieren | ~116–128 ms | ~157 ms |
GPU (OpenCL) | Asynchron | ~0,95 ms | ~35–43 ms |
13. Erweitert (optional): NPU-Inferenz
Für maximale Leistung unterstützt LiteRT die NPU-Beschleunigung mithilfe von anbieterspezifischen Plug-in-Bibliotheken. Über den NPU-Pfad kann eine End-to-End-Latenz von nur 9 ms erreicht werden.
Unterstützte Geräte und Modi
Chip | Gerätebeispiel | Modus | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 ms |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 ms |
Qualcomm (beliebig) | – | JIT | ~28 ms |
MediaTek Dimensity 9400 | – | JIT | ~9 ms |
Google Tensor G3 bis G6 | Pixel 8 bis Pixel 11 | AOT/JIT | Variabel |
AOT (Ahead-of-Time) verwendet ein gerätespezifisches vorkompiliertes Modell (z.B. selfie_multiclass_256x256_SM8650.tflite). Diese Option ist am schnellsten, aber chipspezifisch.
JIT (Just-in-Time) verwendet die Standard-selfie_multiclass_256x256.tflite und wird zur Laufzeit auf der NPU kompiliert. Das führt zu einem langsameren ersten Lauf, ist aber chipunabhängig.
Zusätzliche Voraussetzungen
Qualcomm HTP:
- QAIRT SDK v2.41+ (bietet
libQnnHtp.so-, Stub- oder Skel-Dateien.so). libLiteRtDispatch_Qualcomm.soaus dem Release der LiteRT NPU-Laufzeitbibliotheken auf GitHub.
MediaTek APU:
libLiteRtDispatch_MediaTek.soaus der Version der LiteRT NPU-Laufzeitbibliotheken.- NeuroPilot-Laufzeit (bereits eine Systembibliothek auf Geräten mit Dimensity 9400 – es muss nichts übertragen werden).
Google Tensor:
libLiteRtDispatch_GoogleTensor.soaus der Version der LiteRT NPU-Laufzeitbibliotheken.
NPU-Umgebung und -Optionen
main_npu.cc verweist Environment auf das Verzeichnis der Anbieter-Dispatch-Bibliothek auf dem Gerät und legt dann anbieterspezifische Leistungsoptionen fest:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
Ersetzen Sie für MediaTek den GetQualcommOptions()-Block:
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
Für NPU bereitstellen
CMake-Variante – Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
CMake-Variante – MediaTek Dimensity 9400 (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
Bazel-Variante – Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
Bazel-Variante – MediaTek Dimensity 9400 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
Bazel-Variante – Google Tensor Pixel 9 (JIT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Bei der Bazel-Variante werden QAIRT SDK-Bibliotheken automatisch aus dem bazel-bin-Runfiles-Baum ausgewählt, wenn LITERT_QAIRT_SDK zur Build-Zeit festgelegt ist. Für die CMake-Variante muss das Flag --host_npu_lib auf das extrahierte QAIRT SDK verweisen.
14. Glückwunsch!
Sie haben mit LiteRT erfolgreich eine C++-Pipeline für die Bildsegmentierung auf Android erstellt und ausgeführt. Sie haben Folgendes gelernt:
- C++-Binärdatei für Android
arm64-v8amit CMake + NDK oder Bazel cross-compilieren. - Verwenden Sie die LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) für eine effiziente Inferenz auf dem Gerät. - Bilddaten auf der GPU mit OpenGL ES 3.1-Compute-Shadern vorverarbeiten.
- Synchrone CPU-Inferenz und asynchrone GPU-Inferenz (OpenCL) ausführen.
- NPU-Beschleunigung für Geräte mit Qualcomm-, MediaTek- und Google Tensor-Prozessoren konfigurieren
- C++-Binärdatei mit ADB auf Android-Geräten bereitstellen und ausführen
Nächste Schritte
- Sie können ein anderes TFLite-Modell verwenden, z.B. zur Tiefenschätzung oder zur Erkennung von Posen.
- Die C++-Pipeline mit JNI in eine Android NDK-App einbinden.
- Arbeitsspeichernutzung mit dem Android GPU Inspector und Timing-Ausgabe analysieren
- Sie können die Modellquantisierung nutzen, um die NPU-Inferenzlatenz weiter zu reduzieren.