
১. শুরু করার আগে
কোড টাইপ করা মাসল মেমোরি তৈরি করার এবং বিষয়বস্তু সম্পর্কে আপনার বোঝাপড়া গভীর করার একটি চমৎকার উপায়। যদিও কপি-পেস্ট করা সময় বাঁচাতে পারে, দীর্ঘমেয়াদে এই অভ্যাসে বিনিয়োগ করলে তা আরও বেশি কর্মদক্ষতা এবং শক্তিশালী কোডিং দক্ষতার দিকে নিয়ে যেতে পারে।
এই কোডল্যাবে, আপনি শিখবেন কীভাবে গুগলের উচ্চ-ক্ষমতাসম্পন্ন অন-ডিভাইস রানটাইম, LiteRT ব্যবহার করে একটি C++ ইমেজ সেগমেন্টেশন বাইনারি তৈরি করতে হয়, যা সরাসরি একটি অ্যান্ড্রয়েড ডিভাইসে চলে। Kotlin বা Android Studio ব্যবহার করার পরিবর্তে, এই কোডল্যাবটি একটি C++ বাইনারি তৈরির উপর আলোকপাত করে। আপনি এটিকে CMake বা Bazel দিয়ে ক্রস-কম্পাইল করবেন এবং ADB ব্যবহার করে ডেপ্লয় করবেন। একই LiteRT C++ API যেকোনো প্ল্যাটফর্মে (অ্যান্ড্রয়েড, লিনাক্স, এমবেডেড) কাজ করে, যা এটিকে পারফরম্যান্স-নির্ভর অ্যাপ্লিকেশন, রোবোটিক্স এবং এজ সিস্টেমের জন্য একটি কার্যকর ভিত্তি তৈরি করে।
আপনি সম্পূর্ণ পাইপলাইনটি ঘুরে দেখবেন:
- বিল্ড এনভায়রনমেন্ট সেট আপ করা (CMake + Android NDK অথবা Bazel)।
- LiteRT C++ SDK লিঙ্ক করা — হয় কোনো প্রি-বিল্ট রিলিজ থেকে অথবা সোর্স থেকে।
- জিপিইউ-ত্বরিত চিত্র প্রাক- এবং উত্তর-প্রক্রিয়াকরণের জন্য ওপেনজিএল ইএস কম্পিউট শেডার ব্যবহার।
- LiteRT C++ API ব্যবহার করে
selfie_multiclassসেগমেন্টেশন মডেলটি চালানো হচ্ছে। - সিপিইউ , জিপিইউ (ওপেনসিএল) এবং এনপিইউ (কোয়ালকম/মিডিয়াটেক)-এ ইনফারেন্সের গতি বৃদ্ধি করা।
- মডেলের কাঁচা আউটপুটকে পোস্টপ্রসেসিং করে একটি রঙ-মিশ্রিত সেগমেন্টেশন ছবিতে রূপান্তর করা।
- এডিবি ব্যবহার করে একটি বাস্তব অ্যান্ড্রয়েড ডিভাইসে ডেপ্লয় করা এবং ফলাফল পুনরুদ্ধার করা।
সবশেষে, আপনি নিচের ছবিটির মতো কিছু একটা তৈরি করবেন — একটি স্থির ছবি যা সম্পূর্ণ পাইপলাইনের মাধ্যমে প্রক্রিয়াজাত করা হয়েছে, এবং যার উপর ৬টি সেগমেন্টেশন ক্লাসের প্রত্যেকটি একটি স্বতন্ত্র রঙে স্থাপন করা হয়েছে:

পূর্বশর্ত
এই কোডল্যাবটি C++ এ স্বচ্ছন্দ ডেভেলপারদের জন্য ডিজাইন করা হয়েছে, যারা C++ লেয়ারে অ্যান্ড্রয়েডে মেশিন লার্নিং মডেল চালানোর অভিজ্ঞতা অর্জন করতে চান। আপনার নিম্নলিখিত বিষয়গুলির সাথে পরিচিতি থাকা উচিত:
- সি++ এর মৌলিক বিষয়সমূহ (পয়েন্টার, ভেক্টর, ইনক্লুড)।
- অ্যান্ড্রয়েড/এডিবি-র প্রাথমিক ধারণা (
adb push,adb shell)। - লিনাক্স বা ম্যাকওএস-এ টার্মিনাল এবং শেল স্ক্রিপ্ট ব্যবহার করা।
আপনি যা শিখবেন
- CMake + NDK অথবা Bazel ব্যবহার করে কীভাবে Android
arm64-v8aএর জন্য একটি C++ বাইনারি ক্রস-কম্পাইল করবেন। - ডিভাইসে কার্যকর ইনফারেন্সের জন্য LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) কীভাবে ব্যবহার করবেন। - কিভাবে OpenGL ES 3.1 কম্পিউট শেডারগুলো সম্পূর্ণভাবে GPU-তে প্রি- এবং পোস্ট-প্রসেসিংকে ত্বরান্বিত করে।
- সিপিইউ, জিপিইউ (ওপেনসিএল), এবং এনপিইউ (কোয়ালকম এইচটিপি, মিডিয়াটেক এপিইউ, গুগল টেনসর) অ্যাক্সিলারেশনের জন্য কীভাবে LiteRT কনফিগার করবেন।
- সিনক্রোনাস (
Run) এবং অ্যাসিনক্রোনাস (RunAsync) ইনফারেন্সের মধ্যে পার্থক্য। - ADB ব্যবহার করে অ্যান্ড্রয়েডে কীভাবে একটি C++ বাইনারি ডেপ্লয় এবং রান করা যায়।
আপনার যা যা লাগবে
- একটি লিনাক্স বা ম্যাকওএস মেশিন (উইন্ডোজ ব্যবহারকারীদের WSL2 ব্যবহার করা উচিত)।
- অ্যান্ড্রয়েড এনডিকে আর২৫সি বা তার পরবর্তী সংস্করণ ( ডাউনলোড করুন )।
- CMake পাথের জন্য: CMake ≥ 3.22 (
sudo apt-get install cmake)। - Bazel পাথের জন্য: Bazel ইনস্টল করা থাকতে হবে, সাথে সম্পূর্ণ LiteRT স্যাম্পল রিপোজিটরিও থাকতে হবে।
- আপনার
PATHএ ADB (অ্যান্ড্রয়েড প্ল্যাটফর্ম টুলস)। - একটি বাস্তব অ্যান্ড্রয়েড ডিভাইস — গ্যালাক্সি এস২৪/এস২৫ বা পিক্সেলে সবচেয়ে ভালোভাবে পরীক্ষা করা যায়।
২. চিত্র বিভাজন
ইমেজ সেগমেন্টেশন হলো কম্পিউটার ভিশনের একটি কাজ, যা একটি ছবির প্রতিটি পিক্সেলকে একটি শ্রেণি লেবেল প্রদান করে। অবজেক্ট ডিটেকশনের মতো নয়, যা একটি বাউন্ডিং বক্স অঙ্কন করে, সেগমেন্টেশন প্রতিটি বস্তুর শুরু ও শেষ সম্পর্কে একটি সুনির্দিষ্ট এবং পিক্সেল-পারফেক্ট ধারণা দেয়।
এই কোডল্যাবটি selfie_multiclass_256x256 মডেলটি ব্যবহার করে, যা প্রতিটি পিক্সেলকে ৬টি শ্রেণীর মধ্যে একটিতে শ্রেণীবদ্ধ করে:
শ্রেণী সূচক | সেগমেন্ট |
০ | পটভূমি |
১ | চুল |
২ | শরীরের ত্বক |
৩ | মুখের ত্বক |
৪ | পোশাক |
৫ | আনুষঙ্গিক সামগ্রী (চশমা, গয়না ইত্যাদি) |
মডেলটি [1, 256, 256, 6] আকারের একটি ফ্লোট টেনসর আউটপুট করে। প্রতিটি 256×256 পিক্সেলের জন্য 6টি কনফিডেন্স স্কোর থাকে — প্রতিটি ক্লাসের জন্য একটি করে। সর্বোচ্চ স্কোরযুক্ত ক্লাসটি সেই পিক্সেলটি (argmax) জিতে নেয়।
LiteRT: পারফরম্যান্স অ্যাট দ্য এজ
LiteRT হলো TFLite মডেলগুলোর জন্য গুগলের পরবর্তী প্রজন্মের উচ্চ-ক্ষমতাসম্পন্ন রানটাইম। এর C++ API আপনাকে তিনটি ক্ষেত্রেই একটি সামঞ্জস্যপূর্ণ ইন্টারফেসের মাধ্যমে হার্ডওয়্যার অ্যাক্সিলারেটরগুলোতে সরাসরি ও স্বল্প-ওভারহেডে অ্যাক্সেস দেয়:
- সিপিইউ — সর্বজনীনভাবে সামঞ্জস্যপূর্ণ; মাঝারি মানের ডিভাইসে ইনফারেন্স সময় প্রায় ১২৮ মিলিসেকেন্ড।
- GPU (OpenCL) — ইনফারেন্সের জন্য প্রায় ১ মিলিসেকেন্ড; বাফার কৌশলের উপর নির্ভর করে এন্ড-টু-এন্ড প্রায় ১৭–৪৩ মিলিসেকেন্ড।
- NPU — AOT বনাম JIT কম্পাইলেশনের উপর নির্ভর করে Qualcomm Snapdragon, MediaTek Dimensity 9400, এবং Google Tensor ডিভাইসগুলিতে এন্ড-টু-এন্ড প্রায় ৯–২৮ মিলিসেকেন্ড।
মূল অ্যাবস্ট্রাকশনটি হলো CompiledModel : মডেলটি লোড করার সময় টার্গেট হার্ডওয়্যারের জন্য প্রি-কম্পাইল এবং অপ্টিমাইজ করা হয়, যা প্রি-অ্যালোকেটেড বাফারগুলিতে একটি Run() কলের মাধ্যমে ইনফারেন্সকে সীমিত করে।
৩. প্রস্তুত হন
রিপোজিটরি ক্লোন করুন
git clone https://github.com/google-ai-edge/litert-samples.git
এই কোডল্যাবের সমস্ত রিসোর্স এখানে রয়েছে:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
এই ডিরেক্টরিতে দুটি উপ-প্রকল্প রয়েছে, যার প্রতিটি একই স্যাম্পলের একটি সম্পূর্ণ বিল্ড:
ডিরেক্টরি | বিল্ড সিস্টেম | LiteRT নির্ভরতা |
| CMake + Android NDK | পূর্বনির্মাণ |
| বাজেল | উৎস থেকে LiteRT সংকলন করে |
একটি পথ বেছে নিন এবং সেটি অনুসরণ করুন। দুটি ডিরেক্টরির মধ্যে কোড হুবহু একই — শুধু বিল্ড সিস্টেম এবং ডিপেন্ডেন্সি স্ট্র্যাটেজি ভিন্ন। আপনি যদি দ্রুততম সেটআপ চান, তাহলে use_prebuilt_litert/ বেছে নিন। যদি আপনার LiteRT নিজেই পরিবর্তন করার প্রয়োজন হয় অথবা কোনো বিদ্যমান Bazel monorepo-এর মধ্যে কাজ করতে হয়, তাহলে build_from_source/ ব্যবহার করুন।
ফাইল পাথ সম্পর্কে একটি নোট
এই টিউটোরিয়ালের সমস্ত ফাইল পাথ লিনাক্স/ম্যাকওএস ফরম্যাটে ব্যবহার করা হয়েছে। উইন্ডোজ ব্যবহারকারীদের WSL2 ব্যবহার করা উচিত।
ডিরেক্টরি ওভারভিউ
উভয় উপ-প্রকল্পের উৎস বিন্যাস একই:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
এছাড়াও:
-
use_prebuilt_litert/এর সাথেCMakeLists.txt,build_prebuilt.sh,deploy_and_run_on_android.shএবংthird_party/stb/যুক্ত হয়। -
build_from_source/একটি BazelBUILDফাইল যোগ করে এবংbazel-bin/কে নির্দেশ করেdeploy_and_run_on_android.shব্যবহার করে।
৪. প্রকল্পের কাঠামো বুঝুন
তিনটি প্রবেশপথ, একটি পাইপলাইন
main_cpu.cc , main_gpu.cc , এবং main_npu.cc প্রত্যেকটিতে একটি main() ফাংশন রয়েছে যা সম্পূর্ণ সেগমেন্টেশন পাইপলাইনটি পরিচালনা করে। এই পাইপলাইনটি তিনটি ক্ষেত্রেই অভিন্ন; শুধুমাত্র LiteRT অ্যাক্সিলারেটর কনফিগারেশন এবং বাফার স্ট্র্যাটেজিতে পার্থক্য রয়েছে:
ফাইল | অ্যাক্সিলারেটর | বাফার কৌশল |
| | সিপিইউ মেমরি |
| | OpenCL ব্যাকএন্ড সহ সিপিইউ মেমরি |
| | সিপিইউ ফলব্যাক সহ সিপিইউ মেমরি |
তিনটিতেই একই ImageProcessor (প্রিপ্রসেসিং ও পোস্টপ্রসেসিং-এর জন্য OpenGL ES কম্পিউট শেডার) এবং ImageUtils (STB ইমেজ I/O) ইউটিলিটি রয়েছে।
সম্পূর্ণ পাইপলাইন
প্রতিটি প্রবেশপথ একই পাঁচ-পর্যায়ের কাঠামো অনুসরণ করে:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- লোড —
ImageUtils::LoadImage()STB ইমেজ লাইব্রেরি ব্যবহার করে JPEG ফাইলটিকে ডিকোড করে CPU মেমরিতে নিয়ে আসে। - আপলোড —
processor.CreateOpenGLTexture()কাঁচা পিক্সেলগুলোকে একটি GPU টেক্সচারে (OpenGL RGBA8) আপলোড করে। - প্রিপ্রসেস —
processor.PreprocessInputForSegmentation()একটি GLSL কম্পিউট শেডার চালায় যা টেক্সচারটিকে 256×256 আকারে রিসাইজ করে এবং পিক্সেল মানগুলিকে[0, 1]থেকে[-1, 1]পরিসরে নর্মালাইজ করে। এর ফলাফল একটি GPU SSBO-তে জমা হয়। - ইনফার — SSBO ডেটা একটি LiteRT
TensorBufferএ লেখা হয় এবংcompiled_model.Run()(বাRunAsync()) মডেলটিকে এক্সিকিউট করে। - পোস্টপ্রসেস — মডেলের ৬-চ্যানেল ফ্লোট আউটপুটকে ডিইন্টারলিভ করে ৬টি একক-চ্যানেল মাস্ক SSBO-তে পরিণত করা হয়, যেগুলোকে পরবর্তীতে মূল ছবির উপর পুনরায় কালার-ব্লেন্ড করা হয়।
- সংরক্ষণ —
ImageUtils::SaveImage()চূড়ান্ত RGBA ছবিটিকে PNG ফরম্যাটে লিখে দেয়।
৫. কোর LiteRT C++ এপিআই
বিল্ড করার আগে, সমস্ত এন্ট্রি পয়েন্টে ব্যবহৃত LiteRT C++ এর তিনটি প্রধান টাইপের সাথে পরিচিত হয়ে নিন। সবগুলোই litert:: নেমস্পেসের অন্তর্গত।
litert::Environment
Environment হলো সমস্ত LiteRT অপারেশনের মূল কনটেক্সট। এটি একবার তৈরি করুন এবং CompiledModel::Create এ পাস করুন। NPU ব্যবহারের জন্য, ভেন্ডর প্লাগইন লাইব্রেরি ডিরেক্টরি দিয়ে এটি কনফিগার করুন।
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
CompiledModel কনস্ট্রাকশনের সময় অনুরোধ করা হার্ডওয়্যারের জন্য আপনার TFLite মডেলটি লোড এবং প্রি-কম্পাইল করে। এরপর ইনফারেন্সের কাজটি বাফার পূরণ করা এবং Run() কল করার মধ্যে সীমাবদ্ধ থাকে।
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
টেনসর বাফার ইনপুট/আউটপুট ডেটা ধারণ করে। এগুলিকে সর্বদা CompiledModel থেকে তৈরি করুন, যাতে টার্গেট হার্ডওয়্যারের জন্য এগুলির আকার ও অ্যালাইনমেন্ট সঠিক থাকে।
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
ত্রুটি-পরিচালনা ম্যাক্রো
ম্যাক্রো | আচরণ |
| ব্যর্থ হলে অ্যাসাইন করে অথবা |
| এক্সপ্রেশনটি ত্রুটি ফেরত দিলে |
| কলকারীকে ত্রুটি বরাদ্দ বা প্রচার করে |
৬. বিল্ড — বিকল্প A: আগে থেকে তৈরি LiteRT C++ SDK (CMake)
যদি আপনার LiteRT নিজে পরিবর্তন করার প্রয়োজন না হয়, তবে এটিই প্রস্তাবিত পদ্ধতি। বিল্ড স্ক্রিপ্টটি একটিমাত্র কমান্ডের মাধ্যমে SDK হেডার ডাউনলোড করা, আপনার .so ফাইল কপি করা, STB ফেচ করা এবং CMake ও NDK চালু করার কাজগুলো সম্পন্ন করে।
ধাপ ১ — Maven থেকে libLiteRt.so সংগ্রহ করুন।
LiteRT তার রানটাইমকে Google Maven-এ একটি Android AAR-এর ভেতরে শেয়ার্ড লাইব্রেরি হিসেবে সরবরাহ করে। এটি ডাউনলোড করুন এবং arm64-v8a .so ফাইলটি এক্সট্র্যাক্ট করুন:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
GPU সমর্থনের জন্য, OpenCL/GL অ্যাক্সিলারেটরটিও এক্সট্র্যাক্ট করুন:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

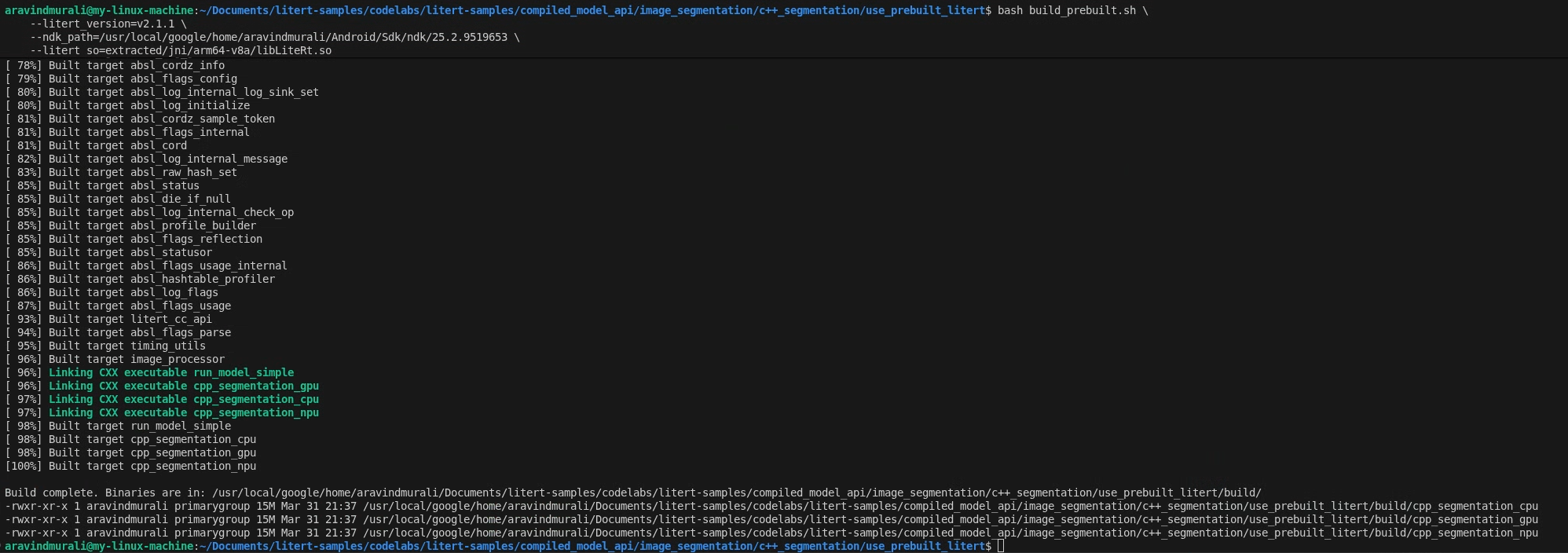
ধাপ ২ — build_prebuilt.sh চালান
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
স্ক্রিপ্টটি করবে:
- LiteRT গিটহাব রিলিজ থেকে
litert_cc_sdk.zip(SDK হেডার + cmake ফাইল) ডাউনলোড করুন — যদি এটি আগে থেকে উপস্থিত থাকে, তবে পরবর্তী রানগুলিতে এটি এড়িয়ে যাওয়া হবে। -
libLiteRt.solitert_cc_sdk/এ কপি করুন। - STB ইমেজ হেডারগুলি
third_party/stb/ফোল্ডারে ডাউনলোড করুন — উপস্থিত থাকলে এটি বাদ দেওয়া হবে। -
android-26এarm64-v8aএর জন্য Android NDK টুলচেইন ব্যবহার করে CMake দিয়ে কনফিগার ও বিল্ড করুন।
সফল হলে আপনি build/ এ তিনটি বাইনারি দেখতে পাবেন:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
CMakeLists.txt যা করে
CMakeLists.txt খুলুন। এটির জন্য C++20 প্রয়োজন, এটি add_subdirectory এর মাধ্যমে LiteRT SDK যুক্ত করে, OpenGL ES 3 ( GLESv3 ) এবং EGL লিঙ্ক করে, এবং তারপর একটি হেল্পার ম্যাক্রো ব্যবহার করে প্রতিটি বাইনারিকে তার main_*.cc সোর্স থেকে তৈরি করে:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
৭. বিল্ড — বিকল্প বি: বেজেল দিয়ে বিল্ড করুন (সোর্স থেকে)
এই পথটি বেছে নিন যদি আপনি আপনার বিল্ড সিস্টেম হিসেবে বেজেল (Bazel) পছন্দ করেন, যা সোর্স থেকে লিটার্ট (LiteRT) রানটাইম কম্পাইল করে, অথবা যদি আপনার একটি বিদ্যমান বেজেল ওয়ার্কস্পেসের মধ্যে কাজ করার প্রয়োজন হয়।
পূর্বশর্ত
'শুরু করার আগে' অংশে তালিকাভুক্ত NDK এবং ADB ছাড়াও আপনার নিম্নলিখিত জিনিসগুলির প্রয়োজন হবে:
- Bazel ইনস্টল করা হয়েছে এবং এটি আপনার
PATHএ রয়েছে। - LiteRT স্যাম্পল সোর্স রিপোজিটরিটির একটি সম্পূর্ণ ক্লোন।
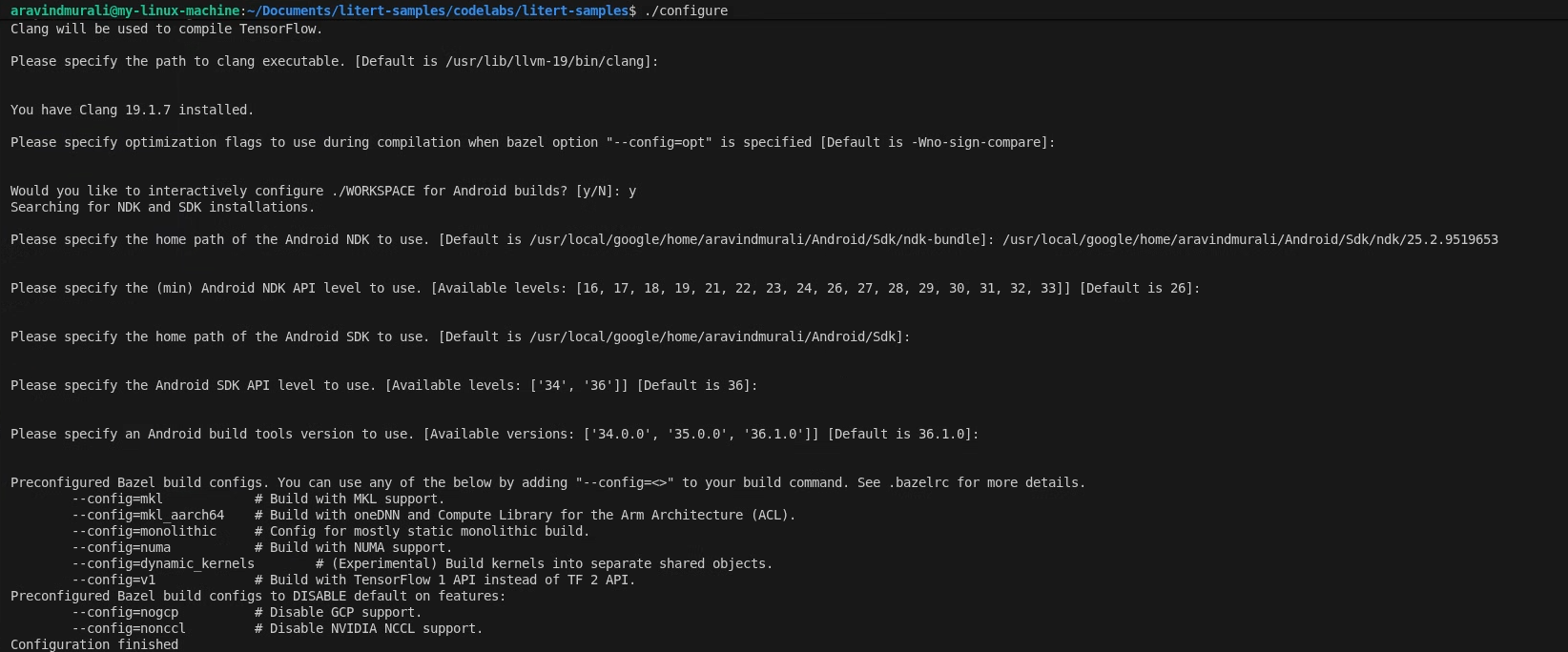
ধাপ ১ — LiteRT স্যাম্পল ওয়ার্কস্পেস কনফিগার করুন
সমস্ত কমান্ড LiteRT স্যাম্পল রিপোজিটরির রুট থেকে চালানো হয়।
cd /path/to/litert-samples
./configure
জিজ্ঞাসা করা হলে:
- পাইথন এবং পাইথন লাইব্রেরি পাথের জন্য ডিফল্ট মান গ্রহণ করুন।
- ROCm এবং CUDA সমর্থনের ক্ষেত্রে N উত্তর দিন।
- কম্পাইলার হিসেবে clang (18.1.3 সংস্করণে পরীক্ষিত) নির্বাচন করুন।
- ডিফল্ট অপ্টিমাইজেশন ফ্ল্যাগগুলো গ্রহণ করুন।
- অ্যান্ড্রয়েড বিল্ডের জন্য ওয়ার্কস্পেস কনফিগার করতে Y উত্তর দিন।
- অ্যান্ড্রয়েড এনডিকে-এর সর্বনিম্ন স্তর কমপক্ষে ২৬- এ সেট করুন।
- আপনার অ্যান্ড্রয়েড এসডিকে-এর পাথ প্রদান করুন।
- অ্যান্ড্রয়েড SDK API লেভেল ডিফল্ট ( 36 ) এবং বিল্ড টুলস 36.0.0 -এ সেট করুন।
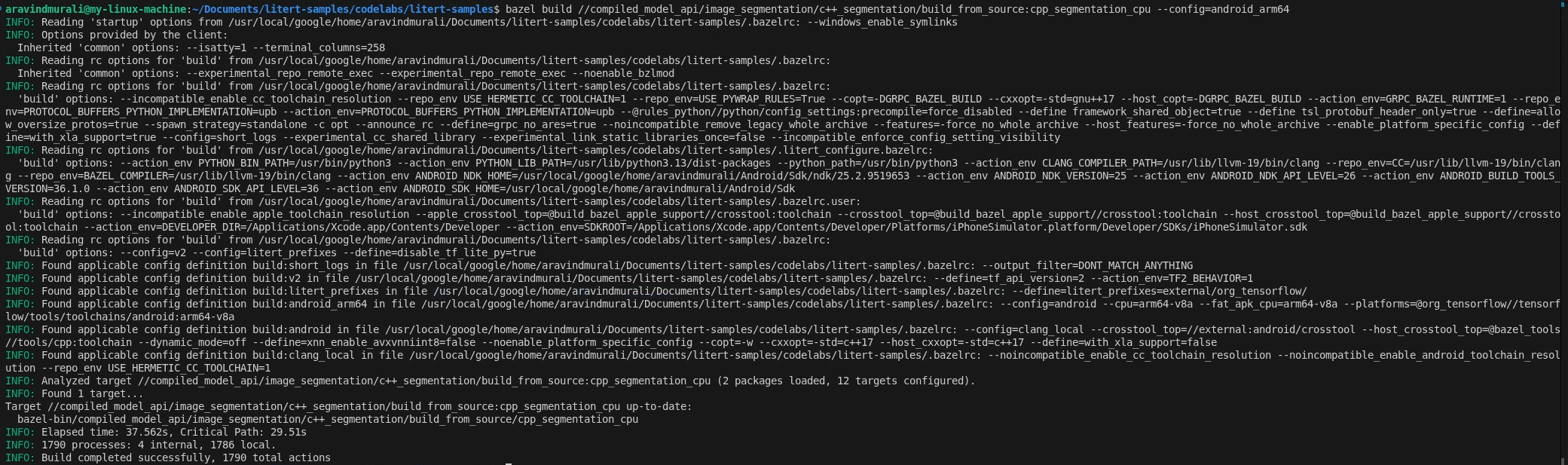
ধাপ ২ — সিপিইউ এবং জিপিইউ টার্গেটগুলো তৈরি করুন
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
ধাপ ৩ — এনপিইউ টার্গেট তৈরি করুন
কোয়ালকম এইচটিপি
- QAIRT SDK v2.41 বা তার পরবর্তী সংস্করণ ডাউনলোড করে এক্সট্র্যাক্ট করুন।
- নিশ্চিত করুন যে এক্সট্র্যাক্ট করা SDK কন্টেন্টগুলো
latest/নামের একটি সাবডিরেক্টরিতে রয়েছে:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... -
/দিয়ে শেষ হওয়া প্যারেন্ট পাথটি পাস করে বিল্ড করুন:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
--nocheck_visibility ফ্ল্যাগটি প্রয়োজন, কারণ কিছু আপস্ট্রিম LiteRT টার্গেটে ডিফল্ট ভিজিবিলিটি সীমাবদ্ধ থাকে।
মিডিয়াটেক এপিইউ
কোনো অতিরিক্ত SDK-এর প্রয়োজন নেই। NeuroPilot রানটাইম হলো Dimensity 9400 ডিভাইসগুলোর একটি সিস্টেম লাইব্রেরি।
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
BUILD ফাইল
build_from_source/BUILD খুলুন। এটি চারটি cc_binary টার্গেট সংজ্ঞায়িত করে — প্রতিটি অ্যাক্সিলারেটরের জন্য একটি এবং একটি ডেডিকেটেড মিডিয়াটেক এনপিইউ টার্গেট — যার প্রতিটি শেয়ার্ড image_processor , image_utils , এবং timing_utils লাইব্রেরি টার্গেটগুলোর উপর নির্ভরশীল:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
GPU টার্গেট libLiteRtClGlAccelerator.so একটি ডেটা ডিপেন্ডেন্সি হিসেবে যুক্ত করে, ফলে Bazel এটিকে রানফাইলগুলোতে অন্তর্ভুক্ত করে। NPU টার্গেটগুলো ভেন্ডর ডিসপ্যাচ এবং কম্পাইলার প্লাগইন .so ফাইলগুলোকে ডেটা ডিপেন্ডেন্সি হিসেবে যুক্ত করে।
৮. কম্পিউট শেডার ব্যবহার করে জিপিইউ-ত্বরিত প্রিপ্রসেসিং
তিনটি এন্ট্রি পয়েন্টই প্রিপ্রসেসিংয়ের জন্য একই OpenGL ES কম্পিউট শেডার পাইপলাইন ব্যবহার করে। জিপিইউ পাথ কেন সিপিইউ পাথের চেয়ে এত দ্রুত, তা বুঝতে হলে এটি বোঝা অত্যন্ত গুরুত্বপূর্ণ।
একটি হেডলেস EGL কনটেক্সট সেট আপ করুন
ImageProcessor::InitializeGL() একটি হেডলেস EGL কনটেক্সট তৈরি করে — এটি এমন একটি OpenGL কনটেক্সট যার সাথে কোনো উইন্ডো বা ডিসপ্লে সংযুক্ত থাকে না। অ্যান্ড্রয়েডে অফ-স্ক্রিন GPU কম্পিউটের জন্য এটি একটি প্রচলিত পদ্ধতি। এরপর এটি ডিস্ক থেকে পাঁচটি GLSL কম্পিউট শেডার প্রোগ্রাম কম্পাইল করে:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
ইনপুট ছবিটি জিপিইউ-তে আপলোড করুন।
ImageUtils::LoadImage() (STB লাইব্রেরির মাধ্যমে) দ্বারা JPEG ফাইলটি CPU মেমরিতে ডিকোড করা হয়, তারপর একটি GPU টেক্সচারে আপলোড করা হয়:
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
এই পর্যায় থেকে মূল ছবিটি জিপিইউ মেমরিতে একটি ওপেনজিএল টেক্সচার হিসেবে থাকে।
প্রিপ্রসেস কম্পিউট শেডার
shaders/preprocess_compute.glsl ২৫৬×২৫৬ আউটপুট গ্রিড জুড়ে ৮×৮ থ্রেড গ্রুপ প্রেরণ করে। প্রতিটি থ্রেড একটি আউটপুট পিক্সেল পরিচালনা করে: এটি বাইলিনিয়ার ফিল্টারিং ব্যবহার করে ইনপুট টেক্সচার থেকে স্যাম্পল নেয় (বিনা মূল্যে হার্ডওয়্যার রিসাইজ), [0, 1] RGB মানকে [-1, 1] এ রূপান্তর করে, এবং আউটপুট SSBO-তে লেখে।
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
স্ট্যান্ডার্ড (নন-জিরো-কপি) পাথের ক্ষেত্রে, এই SSBO-টি এরপর CPU-তে রিড করে LiteRT টেনসরে লেখা হয়:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
৯. সিপিইউ ইনফারেন্স
main_cpu.cc খুলুন। LiteRT সেটআপটি তিনটি লাইনের:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
প্রিপ্রসেসিং-এর পরে, ইনফারেন্স একটি একক সিঙ্ক্রোনাস কল:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
ইনফারেন্স সম্পূর্ণ না হওয়া পর্যন্ত Run() ব্লক করে রাখে। selfie_multiclass_256x256.tflite ফ্লোটিং-পয়েন্ট মডেলটি ARM Cortex কোরে চলে এবং একটি মাঝারি মানের ডিভাইসে সাধারণত ~১১৬–১২৮ মিলিসেকেন্ড সময় নেয়।
বাইনারি ব্যবহার:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
১০. জিপিইউ ইনফারেন্স (ওপেনসিএল)
main_gpu.cc খুলুন। GPU পাথে এমন দুটি ধারণা রয়েছে যা CPU পাথে নেই: GPU অ্যাক্সিলারেটর কনফিগার করার জন্য litert::Options (OpenCL ব্যাকএন্ড সহ), এবং অ্যাসিঙ্ক্রোনাস এক্সিকিউশন।
জিপিইউ বিকল্পগুলি কনফিগার করুন
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
অ্যাসিঙ্ক্রোনাস ইনফারেন্স
GPU পাথে Run() এর পরিবর্তে RunAsync() ব্যবহৃত হয়। এটি GPU কমান্ড কিউতে কাজ জমা দেয় এবং সাথে সাথে রিটার্ন করে। এরপর ফলাফল পড়ার আগে আপনি সিনক্রোনাইজ করেন:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
এই নন-ব্লকিং ডিজাইনটি আপনাকে একটি রিয়েল-টাইম পাইপলাইনে সিপিইউ-এর কাজের সাথে জিপিইউ-এর কার্য সম্পাদনকে ওভারল্যাপ করতে দেয়।
বাইনারি ব্যবহার:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
১১. পোস্টপ্রসেস — ডিইন্টারলিভ এবং ব্লেন্ড
Run() বা RunAsync() সম্পন্ন হওয়ার পর, output_buffers[0] -এ [256 × 256 × 6] আকারের একটি ফ্ল্যাট ফ্লোট অ্যারে ইন্টারলিভড অর্ডারে থাকে। পিক্সেল (row, col) -এর জন্য ৬টি ক্লাস স্কোর (row * 256 + col) * 6 থেকে (row * 256 + col) * 6 + 5 পর্যন্ত ইন্ডেক্সে থাকে।
৬টি মাস্ক এসএসবিও-তে ডিইন্টারলিভ করুন
একটি সিপিইউ হেল্পার ইন্টারলিভড অ্যারেটিকে ৬টি সিঙ্গেল-চ্যানেল ফ্লোট অ্যারেতে বিভক্ত করে এবং প্রত্যেকটিকে তার নিজস্ব জিপিইউ SSBO-তে আপলোড করে।
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
মূল ছবির উপর কালার-ব্লেন্ড মাস্ক প্রয়োগ করুন
processor.ApplyColoredMasks() ফাংশনটি mask_blend_compute.glsl শেডারটি চালায়। প্রতিটি আউটপুট পিক্সেলের জন্য এটি সর্বোচ্চ স্কোর (৬টি মাস্ক SSBO-এর মধ্যে argmax) সহ ক্লাসটি খুঁজে বের করে এবং মূল ইমেজ পিক্সেলের উপর সংশ্লিষ্ট রঙটিকে আলফা-কম্পোজিট করে। ছয়টি রঙ প্রতিটি এন্ট্রি পয়েন্টে সংজ্ঞায়িত করা থাকে:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
0.1f এর আলফা আভাটিকে সূক্ষ্ম রাখে, ফলে মূল ছবিটি দৃশ্যমান থাকে।
আউটপুট সংরক্ষণ করুন
চূড়ান্ত মিশ্রিত RGBA ফ্লোট SSBO-টি পুনরায় পড়া হয়, [0, 1] পরিসরে ক্ল্যাম্প করা হয়, unsigned char এ রূপান্তর করা হয় এবং PNG হিসাবে সংরক্ষণ করা হয়:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
১২. ডিভাইসে স্থাপন ও চালনা করুন
আপনার অ্যান্ড্রয়েড ডিভাইসটি USB ব্যবহার করে সংযুক্ত করুন এবং ADB সংযোগ যাচাই করুন:
adb devices

deploy_and_run_on_android.sh ব্যবহার করুন
প্রতিটি ভ্যারিয়েন্টের নিজস্ব ডিপ্লয় স্ক্রিপ্ট আছে। CMake ভ্যারিয়েন্টটি build/ ডিরেক্টরিকে নির্দেশ করে; Bazel ভ্যারিয়েন্টটি bazel-bin/ ডিরেক্টরিকে নির্দেশ করে। উভয় স্ক্রিপ্টই:
- ডিভাইসে
/data/local/tmp/cpp_segmentation_android/ফোল্ডারটি তৈরি করুন। - বাইনারি, জিএলএসএল শেডার, মডেল, টেস্ট ইমেজ এবং রানটাইম
.soফাইলগুলো পুশ করুন। -
adb shellব্যবহার করে ইনফারেন্স চালান। -
output_segmented.pngফাইলটি আপনার মেশিনে ফিরিয়ে আনুন।
CMake ভ্যারিয়েন্ট ( use_prebuilt_litert/ )
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
বেজেল ভ্যারিয়েন্ট ( build_from_source/ )
LiteRT স্যাম্পল রিপো রুট থেকে এই কমান্ডগুলো চালান:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
--phone ফ্ল্যাগটি নিয়ন্ত্রণ করে কোন ডিভাইস-নির্দিষ্ট মডেল এবং ভেন্ডর লাইব্রেরি ব্যবহার করা হবে। সমর্থিত মানগুলি হলো: s24 (Snapdragon 8 Gen 3), s25 (Snapdragon 8 Elite), dim9400 (MediaTek Dimensity 9400), pixel8 (Tensor G3), pixel9 (Tensor G4), pixel10 (Tensor G5), এবং pixel11 (Tensor G6)।
অনুমানের সময়
ইনফারেন্সের পরে, PrintTiming() একটি সম্পূর্ণ প্রোফাইলিং ব্রেকডাউন প্রিন্ট করে:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
স্যামসাং এস২৫ আল্ট্রা (স্ন্যাপড্রাগন ৮ এলিট)-এ রেফারেন্স পারফরম্যান্স:
অ্যাক্সিলারেটর | এক্সিকিউশন টাইপ | অনুমান | E2E |
সিপিইউ | সিঙ্ক | ~১১৬–১২৮ মিলিসেকেন্ড | ~১৫৭ মিলিসেকেন্ড |
জিপিইউ (ওপেনসিএল) | অ্যাসিঙ্ক | ~০.৯৫ মিলিসেকেন্ড | ~৩৫–৪৩ মিলিসেকেন্ড |
১৩. উন্নত (ঐচ্ছিক): এনপিইউ ইনফারেন্স
সর্বোচ্চ পারফরম্যান্সের জন্য, LiteRT ভেন্ডর-নির্দিষ্ট প্লাগইন লাইব্রেরি ব্যবহার করে NPU অ্যাক্সিলারেশন সমর্থন করে। NPU পাথের মাধ্যমে এন্ড-টু-এন্ড ল্যাটেন্সি সর্বনিম্ন ৯ মিলিসেকেন্ড পর্যন্ত অর্জন করা সম্ভব।
সমর্থিত ডিভাইস এবং মোড
চিপ | ডিভাইসের উদাহরণ | মোড | E2E |
কোয়ালকম এসএম৮৬৫০ | গ্যালাক্সি এস২৪ | এওটি | ~১৭ মিলিসেকেন্ড |
কোয়ালকম এসএম৮৭৫০ | গ্যালাক্সি এস২৫ | এওটি | ~১৭ মিলিসেকেন্ড |
কোয়ালকম (যেকোনো) | — | জেআইটি | ~২৮ মিলিসেকেন্ড |
মিডিয়াটেক ডাইমেনসিটি ৯৪০০ | — | জেআইটি | ~৯ মিলিসেকেন্ড |
গুগল টেনসর জি৩-জি৬ | পিক্সেল ৮-১১ | AOT/JIT | বিভিন্ন |
AOT (অহেড-অফ-টাইম) একটি ডিভাইস-নির্দিষ্ট প্রি-কম্পাইলড মডেল ব্যবহার করে (যেমন, selfie_multiclass_256x256_SM8650.tflite )। এগুলি সবচেয়ে দ্রুততম বিকল্প, কিন্তু চিপ-নির্দিষ্ট।
JIT (জাস্ট-ইন-টাইম) স্ট্যান্ডার্ড selfie_multiclass_256x256.tflite ব্যবহার করে এবং রানটাইমে NPU-তে কম্পাইল করে — ফলে প্রথমবার চলার সময় এটি ধীরগতির হয় এবং চিপ-নিরপেক্ষ।
অতিরিক্ত পূর্বশর্ত
কোয়ালকম এইচটিপি:
- QAIRT SDK v2.41+ (
libQnnHtp.so, stub বা skel.soফাইল সরবরাহ করে)। - গিটহাবে LiteRT NPU রানটাইম লাইব্রেরি রিলিজ থেকে
libLiteRtDispatch_Qualcomm.so।
মিডিয়াটেক এপিইউ:
- LiteRT NPU রানটাইম লাইব্রেরি রিলিজ থেকে
libLiteRtDispatch_MediaTek.so। - নিউরোপাইলট রানটাইম (ডাইমেনসিটি ৯৪০০ ডিভাইসগুলোতে এটি আগে থেকেই একটি সিস্টেম লাইব্রেরি হিসেবে রয়েছে — নতুন করে কিছু যোগ করার প্রয়োজন নেই)।
গুগল টেনসর:
- LiteRT NPU রানটাইম লাইব্রেরি রিলিজ থেকে
libLiteRtDispatch_GoogleTensor.so।
এনপিইউ পরিবেশ এবং বিকল্পসমূহ
main_npu.cc ডিভাইসটিতে থাকা ভেন্ডর ডিসপ্যাচ লাইব্রেরি ডিরেক্টরিতে Environment নির্দেশ করে, তারপর ভেন্ডর-নির্দিষ্ট পারফরম্যান্স অপশনগুলো সেট করে:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
মিডিয়াটেকের জন্য, GetQualcommOptions() ব্লকটি প্রতিস্থাপন করুন:
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
NPU-এর জন্য স্থাপন করুন
CMake ভ্যারিয়েন্ট — Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
CMake ভ্যারিয়েন্ট — মিডিয়াটেক ডাইমেনসিটি ৯৪০০ (JIT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
বেজেল ভ্যারিয়েন্ট — কোয়ালকম এস২৫ (এওটি)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
বেজেল ভ্যারিয়েন্ট — মিডিয়াটেক ডাইমেনসিটি ৯৪০০ (জেআইটি)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
বেজেল ভ্যারিয়েন্ট — গুগল টেনসর পিক্সেল ৯ (জেআইটি)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
Bazel ভ্যারিয়েন্টের ক্ষেত্রে, বিল্ড করার সময় LITERT_QAIRT_SDK সেট করা থাকলে bazel-bin রানফাইল ট্রি থেকে QAIRT SDK লাইব্রেরিগুলো স্বয়ংক্রিয়ভাবে যুক্ত হয়ে যায়। CMake ভ্যারিয়েন্টের জন্য আপনার এক্সট্র্যাক্ট করা QAIRT SDK-কে নির্দেশ করতে --host_npu_lib ফ্ল্যাগটি প্রয়োজন হয়।
১৪. অভিনন্দন!
আপনি LiteRT ব্যবহার করে অ্যান্ড্রয়েডে সফলভাবে একটি C++ ইমেজ সেগমেন্টেশন পাইপলাইন তৈরি ও চালনা করেছেন। আপনি শিখেছেন কীভাবে:
- CMake + NDK অথবা Bazel ব্যবহার করে Android
arm64-v8aএর জন্য একটি C++ বাইনারি ক্রস-কম্পাইল করুন। - ডিভাইসে কার্যকর ইনফারেন্সের জন্য LiteRT C++ API (
Environment,CompiledModel,TensorBuffer) ব্যবহার করুন। - OpenGL ES 3.1 কম্পিউট শেডার ব্যবহার করে GPU-তে ইমেজ ডেটা প্রিপ্রসেস করুন।
- সিঙ্ক্রোনাস সিপিইউ ইনফারেন্স এবং অ্যাসিঙ্ক্রোনাস জিপিইউ (ওপেনসিএল) ইনফারেন্স চালান।
- কোয়ালকম, মিডিয়াটেক এবং গুগল টেনসর ডিভাইসগুলোর জন্য এনপিইউ অ্যাক্সিলারেশন কনফিগার করুন।
- ADB ব্যবহার করে অ্যান্ড্রয়েডে একটি C++ বাইনারি ডেপ্লয় এবং রান করুন।
পরবর্তী পদক্ষেপ
- একটি ভিন্ন TFLite মডেল (যেমন, গভীরতা অনুমান বা পোজ ডিটেকশন) ব্যবহার করুন।
- JNI ব্যবহার করে একটি অ্যান্ড্রয়েড NDK অ্যাপে C++ পাইপলাইন সংহত করুন।
- অ্যান্ড্রয়েড জিপিইউ ইন্সপেক্টর ব্যবহার করে টাইমিং আউটপুটের পাশাপাশি মেমরি ব্যবহারের প্রোফাইল দেখুন।
- NPU ইনফারেন্স ল্যাটেন্সি আরও কমাতে মডেল কোয়ান্টাইজেশন অন্বেষণ করুন।