
1. قبل البدء
كتابة الرموز البرمجية هي طريقة رائعة لتعزيز الذاكرة العضلية وتعميق فهمك للمادة. على الرغم من أنّ عملية النسخ واللصق يمكن أن توفّر الوقت، إلا أنّ الاستثمار في هذه الممارسة يمكن أن يؤدي إلى زيادة الكفاءة وتعزيز مهارات الترميز على المدى الطويل.
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية إنشاء برنامج ثنائي لتقسيم الصور بلغة C++ يعمل مباشرةً على جهاز Android باستخدام وقت التشغيل العالي الأداء من Google على الأجهزة فقط، وهو LiteRT. بدلاً من استخدام Kotlin أو "استوديو Android"، يركّز هذا الدرس التطبيقي حول الترميز على إنشاء ملف ثنائي C++. ستتم ترجمة الرمز البرمجي بشكل متوافق مع أنظمة التشغيل المختلفة باستخدام CMake أو Bazel، ثم سيتم نشره باستخدام ADB. تعمل واجهة برمجة التطبيقات نفسها المستندة إلى C++ في LiteRT على أي منصة (Android وLinux والأنظمة المضمّنة)، ما يجعلها أساسًا مفيدًا للتطبيقات والأنظمة الطرفية والروبوتات التي تتطلّب أداءً عاليًا.
ستنتقل خلال مسار الإعداد الكامل:
- إعداد بيئة الإنشاء (CMake + حزمة تطوير البرامج (NDK) لنظام التشغيل Android أو Bazel)
- ربط حزمة LiteRT C++ SDK، إما من إصدار مُنشأ مسبقًا أو من المصدر
- استخدام برامج تظليل الحوسبة OpenGL ES لمعالجة الصور المسبقة واللاحقة بشكل مسرَّع باستخدام وحدة معالجة الرسومات
- تشغيل نموذج تقسيم
selfie_multiclassباستخدام واجهة برمجة التطبيقات LiteRT C++ - تسريع الاستنتاج على وحدة المعالجة المركزية ووحدة معالجة الرسومات (OpenCL) ووحدة المعالجة العصبية (Qualcomm / MediaTek)
- معالجة مخرجات النموذج الأولية بعد المعالجة وتحويلها إلى صورة تجزئة مدمجة الألوان
- نشر التطبيق على جهاز Android حقيقي باستخدام ADB واسترداد النتيجة
في النهاية، ستحصل على صورة مشابهة للصورة التالية، وهي صورة ثابتة تمت معالجتها من خلال مسار المعالجة الكامل، مع تراكب كل فئة من فئات التقسيم الست بلون مختلف:

المتطلبات الأساسية
هذا الدرس التطبيقي حول الترميز مخصّص للمطوّرين الذين يجيدون لغة C++ ويريدون اكتساب خبرة في تشغيل نماذج تعلُّم الآلة على Android في طبقة C++. يجب أن تكون على دراية بما يلي:
- أساسيات C++ (المؤشرات والمتجهات وعمليات التضمين)
- مفاهيم Android/ADB الأساسية (
adb pushوadb shell) - استخدام وحدة طرفية ونصوص برمجية في Linux أو macOS
أهداف الدورة التعليمية
- كيفية تجميع ملف C++ ثنائي متوافق مع Android
arm64-v8aباستخدام CMake + NDK أو Bazel - كيفية استخدام واجهة برمجة تطبيقات LiteRT C++ (
EnvironmentوCompiledModelوTensorBuffer) لإجراء استنتاج فعّال على الجهاز فقط - كيف تساهم برامج التظليل الحسابية في OpenGL ES 3.1 في تسريع عمليات المعالجة المسبقة واللاحقة على وحدة معالجة الرسومات بالكامل
- كيفية ضبط LiteRT للتسريع باستخدام وحدة المعالجة المركزية ووحدة معالجة الرسومات (OpenCL) ووحدة المعالجة العصبية (Qualcomm HTP وMediaTek APU وGoogle Tensor)
- الفرق بين الاستنتاج المتزامن (
Run) وغير المتزامن (RunAsync) - كيفية نشر وتشغيل ملف C++ ثنائي على Android باستخدام ADB
المتطلبات
- جهاز Linux أو macOS (على مستخدمي Windows استخدام WSL2)
- الإصدار 25c أو إصدار أحدث من Android NDK (تنزيل)
- بالنسبة إلى مسار CMake: CMake ≥ 3.22 (
sudo apt-get install cmake). - بالنسبة إلى مسار Bazel: يجب تثبيت Bazel، بالإضافة إلى مستودع نماذج LiteRT الكامل.
- ADB في
PATH(أدوات منصة Android) - جهاز Android فعلي، ويُفضّل اختباره على هواتف Galaxy S24 أو S25 أو Pixel
2. تقسيم الصور إلى شرائح
تقسيم الصور هو مهمة من مهام رؤية الكمبيوتر، وتتمثّل في تخصيص تصنيف لكل بكسل في الصورة. على عكس ميزة "رصد العناصر" التي ترسم مربّعًا محيطًا، تقدّم ميزة "التقسيم الدلالي" فهمًا دقيقًا ومثاليًا لمكان بداية كل عنصر ونهايته.
يستخدم هذا الدرس التطبيقي حول الترميز نموذج selfie_multiclass_256x256 الذي يصنّف كل بكسل إلى إحدى 6 فئات:
فهرس الفئات | تقسيم |
0 | خلفية |
1 | شعر |
2 | بشرة الجسم |
3 | بشرة الوجه |
4 | ملابس |
5 | الإكسسوارات (النظارات والمجوهرات وما إلى ذلك) |
يُخرج النموذج موترًا عائمًا بالشكل [1, 256, 256, 6]. لكل بكسل من وحدات البكسل 256×256، هناك 6 درجات ثقة، درجة واحدة لكل فئة. تفوز الفئة التي حصلت على أعلى نتيجة بالبكسل (argmax).
LiteRT: الأداء على الأجهزة الطرفية
LiteRT هو وقت التشغيل العالي الأداء من الجيل التالي من Google لنماذج TFLite. تتيح لك واجهة برمجة التطبيقات C++ الوصول المباشر إلى أدوات تسريع الأجهزة بدون تكلفة إضافية وبواجهة متسقة على مستوى جميع الأدوات الثلاث:
- وحدة المعالجة المركزية (CPU): متوافقة مع جميع الأجهزة، ويبلغ وقت الاستدلال فيها حوالي 128 ملي ثانية على جهاز متوسط المدى.
- وحدة معالجة الرسومات (OpenCL): استنتاج يستغرق حوالي 1 ملي ثانية، ووقت شامل يتراوح بين 17 و43 ملي ثانية تقريبًا حسب استراتيجية المخزن المؤقت.
- وحدة المعالجة العصبية (NPU): من 9 إلى 28 ملي ثانية من البداية إلى النهاية على أجهزة Qualcomm Snapdragon وMediaTek Dimensity 9400 وGoogle Tensor، وذلك حسب وضع التشغيل "الاستماع فقط" (AOT). تجميع أثناء التنفيذ
التجريد الأساسي هو CompiledModel: يتم تجميع النموذج مسبقًا وتحسينه للأجهزة المستهدَفة في مدّة التحميل، ما يقلّل من الاستنتاج إلى استدعاء Run() على المخازن المؤقتة المخصّصة مسبقًا.
3- طريقة الإعداد
إنشاء نسخة طبق الأصل من المستودع
git clone https://github.com/google-ai-edge/litert-samples.git
تتوفّر جميع المراجع لهذا الدرس التطبيقي حول الترميز في:
litert-samples/compiled_model_api/image_segmentation/c++_segmentation/
يحتوي هذا الدليل على مشروعَين فرعيَّين، كلّ منهما عبارة عن إصدار كامل من النموذج نفسه:
الدليل | نظام التصميم | التبعية LiteRT |
| CMake + Android NDK |
|
| Bazel | تجميع LiteRT من المصدر |
اختَر مسارًا واحدًا واتّبِعه. الرمز متطابق بين الدليلَين، ويختلف نظام التصميم واستراتيجية الاعتمادية فقط. إذا كنت تريد إعدادًا سريعًا، اختَر use_prebuilt_litert/. إذا كنت بحاجة إلى تعديل LiteRT نفسه أو العمل ضمن مستودع Bazel أحادي كبير حالي، استخدِم build_from_source/.
ملاحظة حول مسارات الملفات
تستخدم جميع مسارات الملفات في هذا البرنامج التعليمي تنسيق Linux/macOS. على مستخدمي Windows استخدام WSL2.
نظرة عامة على الدليل
يتشارك كلا المشروعَين الفرعيَين في تنسيق المصدر نفسه:
<variant>/
├── main_cpu.cc # CPU inference entry point
├── main_gpu.cc # GPU (OpenCL) inference entry point
├── main_npu.cc # NPU (Qualcomm / MediaTek) entry point
├── image_processor.h/.cc # OpenGL ES preprocessing and postprocessing
├── image_utils.h/.cc # STB-based image load / save utilities
├── timing_utils.h/.cc # Profiling helpers
├── shaders/ # GLSL ES 3.1 compute shaders
│ ├── preprocess_compute.glsl
│ ├── resize_compute.glsl
│ ├── mask_blend_compute.glsl
│ ├── deinterleave_masks.glsl
│ └── passthrough_shader.vert
├── models/
│ ├── selfie_multiclass_256x256.tflite (CPU / GPU / NPU JIT)
│ ├── selfie_multiclass_256x256_SM8650.tflite (Qualcomm S24 AOT)
│ └── selfie_multiclass_256x256_SM8750.tflite (Qualcomm S25 AOT)
└── test_images/
└── image.jpeg
علاوة على ذلك:
- يضيف
use_prebuilt_litert/كلاً منCMakeLists.txtوbuild_prebuilt.shوdeploy_and_run_on_android.shوthird_party/stb/. - تضيف
build_from_source/ملفBUILDفي Bazel وتستخدمdeploy_and_run_on_android.shللإشارة إلىbazel-bin/.
4. فهم بنية المشروع
ثلاث نقاط دخول، مسار واحد
يحتوي كل من main_cpu.cc وmain_gpu.cc وmain_npu.cc على دالة main() التي تدير مسار التقسيم الكامل. تكون سلسلة المعالجة متطابقة في جميع الأنواع الثلاثة، ويختلف فقط إعداد مسرّع LiteRT واستراتيجية التخزين المؤقت:
ملف | مسرِّعة أعمال | استراتيجية التخزين المؤقت |
|
| ذاكرة وحدة المعالجة المركزية |
|
| ذاكرة وحدة المعالجة المركزية مع برنامج OpenCL |
|
| ذاكرة وحدة المعالجة المركزية مع خيار الرجوع إلى وحدة المعالجة المركزية |
تتشارك جميعها في الأداتَين ImageProcessor (تظليلات الحوسبة في OpenGL ES للمعالجة المسبقة واللاحقة) وImageUtils (إدخال/إخراج صور STB).
مسار المعالجة الكامل
تتّبع كل نقطة دخول البنية نفسها المكوّنة من خمس مراحل:
Load → GPU upload → Preprocess (shader) → Inference (LiteRT) → Postprocess (shader) → Save
- التحميل:
ImageUtils::LoadImage()يفك ترميز ملف JPEG إلى ذاكرة وحدة المعالجة المركزية باستخدام مكتبة صور جهاز فك التشفير. - التحميل:
processor.CreateOpenGLTexture()يحمّل وحدات البكسل الأولية إلى نسيج وحدة معالجة الرسومات (OpenGL RGBA8). - المعالجة المسبقة: ينفّذ
processor.PreprocessInputForSegmentation()برنامج تظليل حسابي GLSL يعيد ضبط حجم النسيج إلى 256×256 ويحوّل قيم البكسل إلى قيم عادية من[0, 1]إلى[-1, 1]. تظهر النتيجة في مخزن SSBO لوحدة معالجة الرسومات. - الاستنتاج: تتم كتابة بيانات SSBO في
TensorBufferوcompiled_model.Run()(أوRunAsync()) في LiteRT، ويتم تنفيذ النموذج. - المعالجة اللاحقة: يتم فصل الناتج ذو الفاصلة العائمة المكوّن من 6 قنوات في النموذج إلى 6 مخازن مؤقتة للتخزين المنظَّم (SSBO) ذات قناة واحدة، ثم يتم دمج الألوان مرة أخرى في الصورة الأصلية.
- حفظ:
ImageUtils::SaveImage()يكتب صورة RGBA النهائية بتنسيق PNG.
5- واجهات برمجة تطبيقات Core LiteRT C++
قبل البدء في الإنشاء، تعرَّف على أنواع C++ الرئيسية الثلاثة في LiteRT المستخدَمة في جميع نقاط الدخول. تتوفّر جميعها في مساحة الاسم litert::.
litert::Environment
Environment هو سياق الجذر لجميع عمليات LiteRT. أنشئها مرة واحدة ومرِّرها إلى CompiledModel::Create. لاستخدام وحدة المعالجة العصبية، عليك ضبطها باستخدام دليل مكتبة المكوّن الإضافي الخاص بالمورّد.
// For CPU or GPU - no extra options needed
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// For NPU: point at the vendor dispatch library directory on the device
std::vector<litert::Environment::Option> opts;
opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
"/data/local/tmp/cpp_segmentation_android/npu/"});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(opts)));
litert::CompiledModel
تحمّل CompiledModel نموذج TFLite وتجمّعه مسبقًا للأجهزة المطلوبة في وقت الإنشاء. بعد ذلك، يتم تقليل الاستدلال إلى ملء المخازن المؤقتة واستدعاء Run().
// CPU
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path,
litert::HwAccelerators::kCpu));
// GPU (pass an Options object with GpuOptions configured)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, gpu_options));
// NPU (pass an Options object with kNpu | kCpu and vendor options)
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, npu_options));
litert::TensorBuffer
تحتوي مخازن مؤقتة للموتر على بيانات الإدخال/الإخراج. يجب دائمًا إنشاء هذه الأصول من CompiledModel لضمان أن تكون بالحجم الصحيح ومتوافقة مع الأجهزة المستهدَفة.
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
// Write preprocessed float data, run, read results
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed_data)));
LITERT_ABORT_IF_ERROR(
compiled_model.Run(input_buffers, output_buffers));
LITERT_ABORT_IF_ERROR(
output_buffers[0].Read(absl::MakeSpan(output_data)));
وحدات ماكرو لمعالجة الأخطاء
وحدة الماكرو | السلوك |
| يتم تعيين القيمة |
| يتم استدعاء |
| تعيين الخطأ أو نشره للمتصل |
6. إنشاء — الخيار أ: حزمة LiteRT C++ SDK المُنشأة مسبقًا (CMake)
هذا هو المسار المقترَح إذا لم تكن بحاجة إلى تعديل LiteRT نفسه. يتولّى نص البرمجة الإنشائي تنزيل عناوين SDK ونسخ .so وجلب STB واستدعاء CMake وNDK في أمر واحد.
الخطوة 1: الحصول على libLiteRt.so من Maven
تتضمّن LiteRT وقت التشغيل كمكتبة مشترَكة داخل ملف AAR لنظام Android على Google Maven. نزِّل الملف واستخرِج arm64-v8a .so:
# Download the AAR
wget -O litert.aar \
"https://dl.google.com/dl/android/maven2/com/google/ai/edge/litert/litert/2.1.3/litert-2.1.3.aar"
# Extract the runtime library
unzip litert.aar "jni/arm64-v8a/libLiteRt.so" -d extracted/
للحصول على دعم وحدة معالجة الرسومات، استخرِج أيضًا أداة تسريع OpenCL/GL:
unzip litert.aar "jni/arm64-v8a/libLiteRtClGlAccelerator.so" -d extracted/

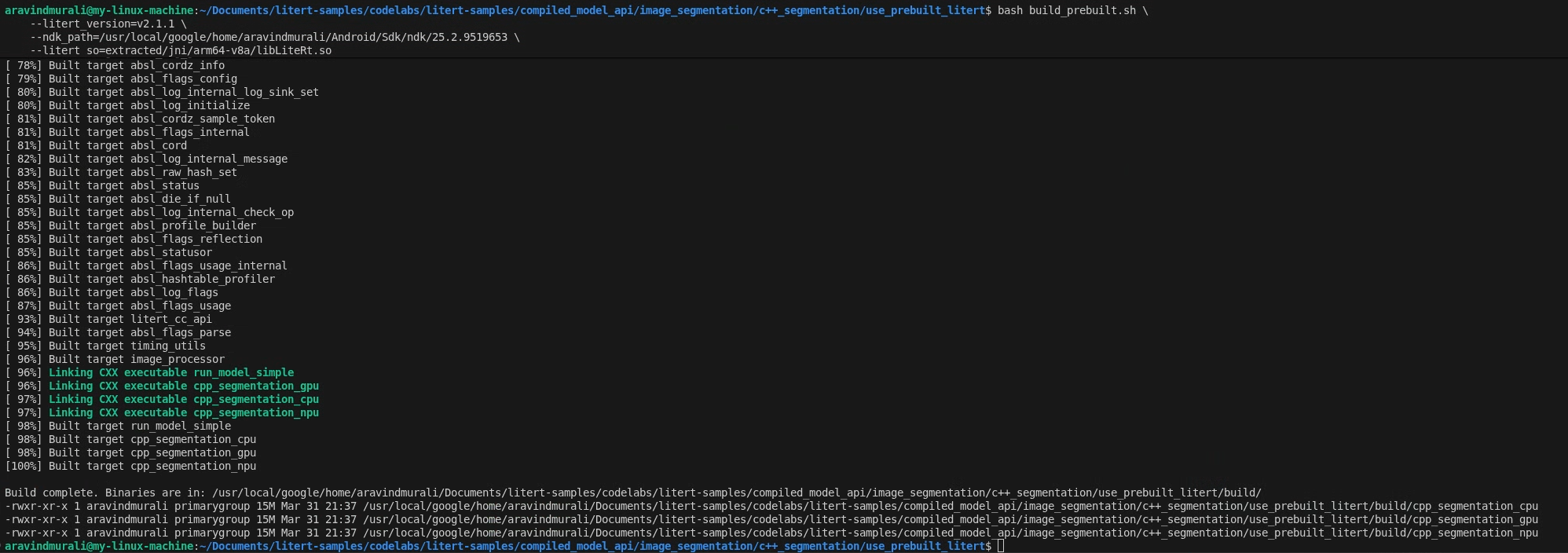
الخطوة 2: تشغيل build_prebuilt.sh
cd litert-samples/compiled_model_api/image_segmentation/c++_segmentation/use_prebuilt_litert/
bash build_prebuilt.sh \
--litert_version=2.1.3 \
--ndk_path=/path/to/android-ndk \
--litert_so=extracted/jni/arm64-v8a/libLiteRt.so
سيؤدي النص البرمجي إلى ما يلي:
- نزِّل
litert_cc_sdk.zip(عناوين حزمة SDK وملفات cmake) من إصدار LiteRT على GitHub. سيتم تخطّي هذه الخطوة في عمليات التشغيل اللاحقة إذا كانت الملفات متوفّرة. - انسخ
libLiteRt.soإلىlitert_cc_sdk/. - تنزيل عناوين صور STB إلى
third_party/stb/- يتم تخطّي هذه الخطوة إذا كانت العناوين متوفّرة. - ضبط CMake وإنشاء التطبيق باستخدام مجموعة أدوات Android NDK للتطبيق
arm64-v8aفيandroid-26
عند النجاح، ستظهر لك ثلاثة ملفات ثنائية في build/:
build/cpp_segmentation_cpu
build/cpp_segmentation_gpu
build/cpp_segmentation_npu
وظيفة CMakeLists.txt
فتح "CMakeLists.txt" يتطلّب C++20، ويجلب حزمة تطوير البرامج (SDK) الخاصة بـ LiteRT من خلال add_subdirectory، ويربط OpenGL ES 3 (GLESv3) وEGL، ثم يستخدم ماكرو مساعدًا لإنشاء كل برنامج ثنائي من مصدر main_*.cc:
macro(add_segmentation_target target_name main_source)
add_executable(${target_name} ${main_source})
target_link_libraries(${target_name}
PRIVATE
image_processor image_utils timing_utils litert_cc_api
absl::log absl::check EGL GLESv3 android log
)
endmacro()
add_segmentation_target(cpp_segmentation_cpu main_cpu.cc)
add_segmentation_target(cpp_segmentation_gpu main_gpu.cc)
add_segmentation_target(cpp_segmentation_npu main_npu.cc)
7. إنشاء — الخيار "ب": الإنشاء باستخدام Bazel (من المصدر)
اختَر هذا المسار إذا كنت تفضّل Bazel كنظام التصميم، والذي يجمع وقت تشغيل LiteRT من المصدر، أو إذا كنت بحاجة إلى العمل في مساحة عمل Bazel حالية.
المتطلبات الأساسية
بالإضافة إلى NDK وADB المُدرَجين في قسم "قبل البدء"، ستحتاج إلى ما يلي:
- Bazel مثبَّت على
PATH - نسخة طبق الأصل من مستودع المصدر لعينات LiteRT
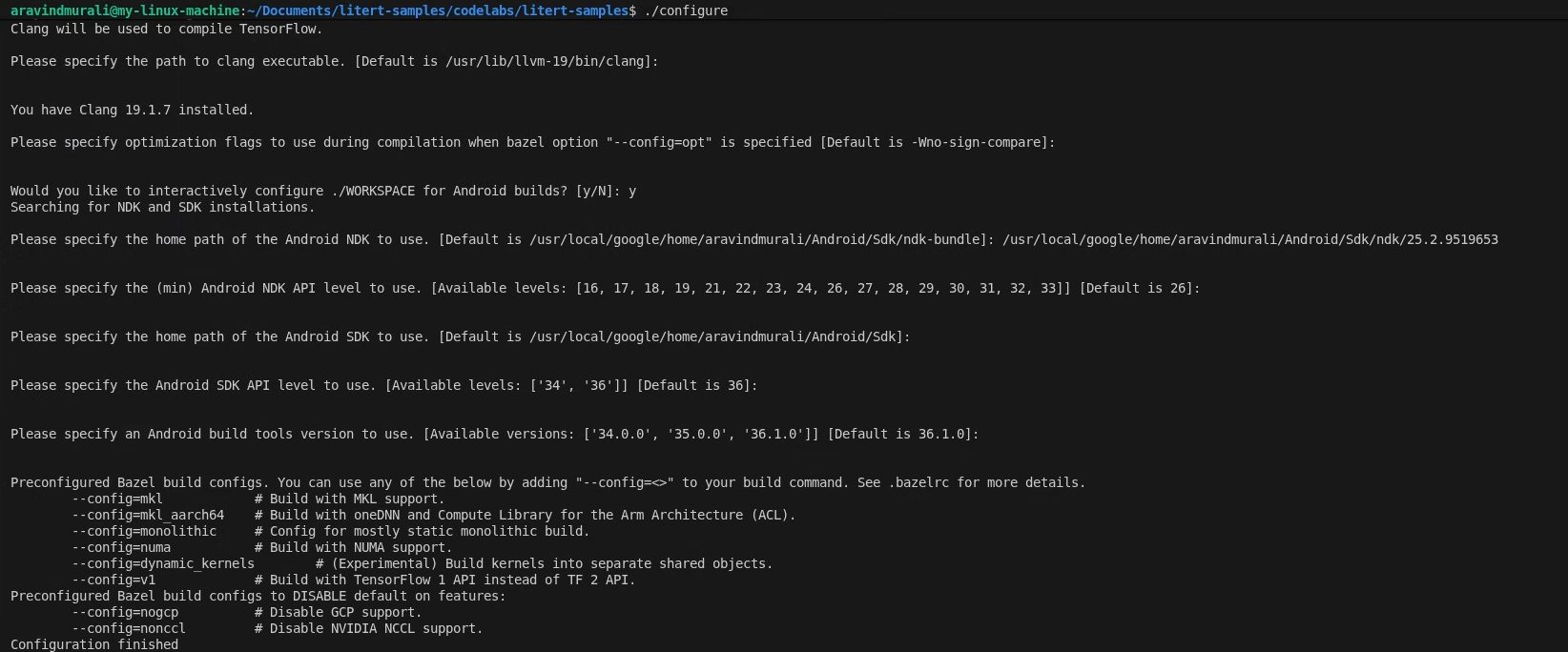
الخطوة 1: إعداد مساحة عمل عيّنات LiteRT
يتم تنفيذ جميع الأوامر من جذر مستودع نماذج LiteRT.
cd /path/to/litert-samples
./configure
عندما يُطلب منك ذلك:
- قبول الإعدادات التلقائية لمسار Python ومسار مكتبة Python
- الإجابة N بشأن توافق ROCm وCUDA
- اختَر clang (تمّ اختباره باستخدام الإصدار 18.1.3) كمترجم.
- قبول علامات التحسين التلقائي
- أدخِل Y لضبط WORKSPACE لإنشاء إصدارات Android.
- اضبط الحد الأدنى لمستوى Android NDK على 26 على الأقل.
- قدِّم مسار حزمة تطوير البرامج (SDK) لنظام التشغيل Android.
- اضبط مستوى واجهة برمجة التطبيقات لحزمة تطوير البرامج (SDK) لنظام التشغيل Android على القيمة التلقائية (36) وأدوات الإنشاء على 36.0.0.
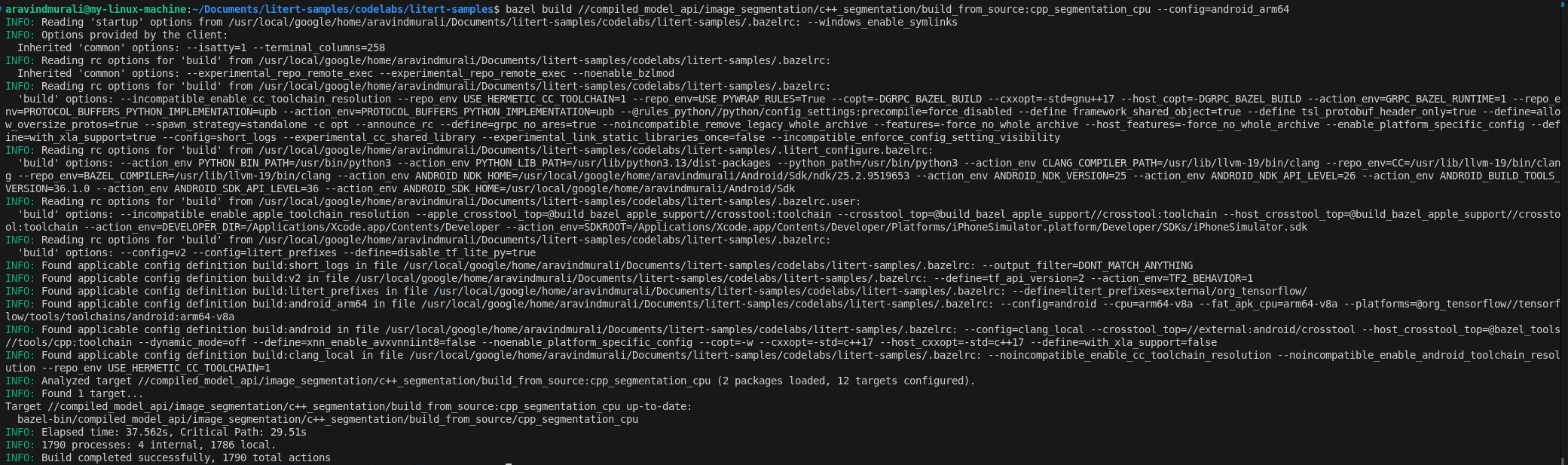
الخطوة 2: إنشاء استهدافات وحدة المعالجة المركزية ووحدة معالجة الرسومات
# CPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_cpu \
--config=android_arm64
# GPU
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_gpu \
--config=android_arm64
الخطوة 3: إنشاء استهداف NPU
Qualcomm HTP
- نزِّل الإصدار 2.41 أو إصدارًا أحدث من حزمة QAIRT SDK واستخرِجه.
- تأكَّد من أنّ محتوى حزمة SDK المستخرَج موجود داخل دليل فرعي باسم
latest/:/path/to/qairt_sdk/ └── latest/ ├── include/ ├── lib/ └── ... - أنشئ المسار، مع تمرير مسار العنصر الرئيسي الذي ينتهي بـ
/:bazel build \ //compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu \ --config=android_arm64 \ --nocheck_visibility \ --action_env LITERT_QAIRT_SDK=/path/to/qairt_sdk/
يجب استخدام العلامة --nocheck_visibility لأنّ بعض استهدافات LiteRT الأولية تتضمّن إعدادات تلقائية محدودة الظهور.
وحدة المعالجة المركزية (APU) من MediaTek
ولا يلزم توفير حزمة تطوير برامج (SDK) إضافية. وقت تشغيل NeuroPilot هو مكتبة نظام على أجهزة Dimensity 9400.
bazel build \
//compiled_model_api/image_segmentation/c++_segmentation/build_from_source:cpp_segmentation_npu_mtk \
--config=android_arm64 \
--nocheck_visibility
الملف BUILD
فتح "build_from_source/BUILD" يحدّد أربعة أهداف cc_binary، هدف واحد لكل مسرّع بالإضافة إلى هدف مخصّص لوحدة المعالجة العصبية (NPU) من MediaTek، ويعتمد كل هدف على أهداف المكتبات المشتركة image_processor وimage_utils وtiming_utils:
cc_binary(
name = "cpp_segmentation_cpu",
srcs = ["main_cpu.cc"],
deps = [
":image_processor",
":image_utils",
":timing_utils",
"@litert_archive//litert/cc:litert_api_with_dynamic_runtime",
"@com_google_absl//absl/time",
"@com_google_absl//absl/types:span",
] + gles_deps() + gl_native_deps(),
...
)
يضيف هدف وحدة معالجة الرسومات libLiteRtClGlAccelerator.so كعنصر تابع للبيانات، لذا يدرجه Bazel في ملفات التشغيل. تضيف استهدافات NPU ملفات إرسال المورّد ومكوّن إضافي للمترجم .so كعناصر تابعة للبيانات.
8. المعالجة المُسبقة المسرَّعة بواسطة وحدة معالجة الرسومات باستخدام برامج التظليل الحسابية
تستخدم نقاط الدخول الثلاثة نفسها مسار تظليل الحوسبة OpenGL ES نفسه للمعالجة المسبقة. ويُعدّ فهم ذلك أمرًا أساسيًا لمعرفة سبب سرعة مسار وحدة معالجة الرسومات مقارنةً بمسار وحدة المعالجة المركزية.
إعداد سياق EGL بلا واجهة مستخدم رسومية
ينشئ ImageProcessor::InitializeGL() سياق EGL بلا واجهة مستخدم رسومية، وهو سياق OpenGL بدون نافذة أو شاشة عرض مرفقة. هذه ممارسة معيارية لاحتساب وحدة معالجة الرسومات خارج الشاشة على Android. بعد ذلك، يتم تجميع برامج تظليل الحوسبة الخمسة GLSL من القرص:
processor.InitializeGL(
"shaders/passthrough_shader.vert",
"shaders/mask_blend_compute.glsl",
"shaders/resize_compute.glsl",
"shaders/preprocess_compute.glsl",
"shaders/deinterleave_masks.glsl");
تحميل صورة الإدخال إلى وحدة معالجة الرسومات
يتم فك ترميز ملف JPEG إلى ذاكرة وحدة المعالجة المركزية (CPU) من خلال ImageUtils::LoadImage() (عبر مكتبة STB)، ثم يتم تحميله إلى نسيج وحدة معالجة الرسومات (GPU):
auto img_data_cpu = ImageUtils::LoadImage(
input_file, width_orig, height_orig, channels_file, /*desired=*/3);
GLuint tex_id_orig = processor.CreateOpenGLTexture(
img_data_cpu, width_orig, height_orig, loaded_channels);
ImageUtils::FreeImageData(img_data_cpu); // CPU copy no longer needed
من هذه النقطة، يتم حفظ الصورة الأصلية في ذاكرة وحدة معالجة الرسومات كنسيج OpenGL.
أداة تظليل الحوسبة المسبقة
shaders/preprocess_compute.glsl ترسل مجموعات سلاسل محادثات 8×8 إلى شبكة الإخراج 256×256. يتعامل كل مؤشر ترابط مع بكسل إخراج واحد: فهو يأخذ عيّنات من نسيج الإدخال باستخدام فلترة ثنائية الخط (تغيير الحجم على مستوى الجهاز مجانًا)، ويحوّل قيمة RGB [0, 1] إلى [-1, 1]، ويكتب إلى SSBO الناتج:
vec2 uv = vec2(float(pos.x) / float(out_width - 1),
float(pos.y) / float(out_height - 1));
vec4 color_0_1 = texture(inputTexture, uv);
vec3 color_neg1_1 = (color_0_1.rgb * 2.0) - 1.0;
int base = (pos.y * out_width + pos.x) * num_channels;
preprocessed_output.data[base + 0] = color_neg1_1.r;
preprocessed_output.data[base + 1] = color_neg1_1.g;
preprocessed_output.data[base + 2] = color_neg1_1.b;
بالنسبة إلى المسار العادي (غير النسخ بدون وسيط)، تتم إعادة قراءة هذا المخزن المؤقت SSBO إلى وحدة المعالجة المركزية (CPU) وكتابته في موتر LiteRT:
std::vector<float> preprocessed(256 * 256 * num_channels);
processor.ReadBufferData(preprocessed_buffer_id, 0,
preprocessed.size() * sizeof(float),
preprocessed.data());
LITERT_ABORT_IF_ERROR(
input_buffers[0].Write(absl::MakeConstSpan(preprocessed)));
9- الاستنتاج على وحدة المعالجة المركزية
فتح "main_cpu.cc" يتألف إعداد LiteRT من ثلاثة أسطر:
// Create the root environment
LITERT_ASSIGN_OR_ABORT(auto env, litert::Environment::Create({}));
// Compile the model for the CPU
LITERT_ASSIGN_OR_ABORT(auto compiled_model,
litert::CompiledModel::Create(
env, model_path, litert::HwAccelerators::kCpu));
// Allocate input and output tensor buffers
LITERT_ASSIGN_OR_ABORT(auto input_buffers,
compiled_model.CreateInputBuffers());
LITERT_ASSIGN_OR_ABORT(auto output_buffers,
compiled_model.CreateOutputBuffers());
بعد المعالجة المُسبقة، تكون الاستنتاجات عبارة عن مكالمة متزامنة واحدة:
LITERT_ABORT_IF_ERROR(compiled_model.Run(input_buffers, output_buffers));
يتم حظر Run() إلى أن يكتمل الاستنتاج. يعمل نموذج selfie_multiclass_256x256.tflite ذو الفاصلة العائمة على نوى ARM Cortex ويستغرق عادةً من 116 إلى 128 ملي ثانية على جهاز متوسط المدى.
استخدام البيانات الثنائية:
cpp_segmentation_cpu <model_path> <input_image> <output_image>
10. الاستدلال باستخدام وحدة معالجة الرسومات (OpenCL)
فتح "main_gpu.cc" يتضمّن مسار وحدة معالجة الرسومات مفهومَين غير متوفّرَين في مسار وحدة المعالجة المركزية: litert::Options لإعداد مسرِّع وحدة معالجة الرسومات (باستخدام الخلفية OpenCL)، والتنفيذ غير المتزامن.
ضبط خيارات وحدة معالجة الرسومات
litert::Options CreateGpuOptions() {
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
LITERT_ASSIGN_OR_ABORT(auto& gpu_options, options.GetGpuOptions());
LITERT_ABORT_IF_ERROR(
gpu_options.SetBackend(litert::GpuOptions::Backend::kOpenCl));
// Allow CPU fallback for any ops not supported by the GPU delegate
options.SetHardwareAccelerators(litert::HwAccelerators::kGpu |
litert::HwAccelerators::kCpu);
return options;
}
الاستنتاج غير المتزامن
يستخدم مسار وحدة معالجة الرسومات RunAsync() بدلاً من Run(). يؤدي ذلك إلى إرسال العمل إلى قائمة انتظار أوامر وحدة معالجة رسومات والعودة على الفور. بعد ذلك، يمكنك إجراء المزامنة قبل قراءة النتائج:
bool async = false;
LITERT_ABORT_IF_ERROR(
compiled_model.RunAsync(0, input_buffers, output_buffers, async));
if (output_buffers[0].HasEvent()) {
LITERT_ASSIGN_OR_ABORT(auto event, output_buffers[0].GetEvent());
event.Wait();
}
يتيح لك هذا التصميم غير المحظور تداخل عمل وحدة المعالجة المركزية مع تنفيذ وحدة معالجة الرسومات في مسار في الوقت الفعلي.
استخدام البيانات الثنائية:
cpp_segmentation_gpu <model_path> <input_image> <output_image>
11. المعالجة اللاحقة — إزالة التداخل والمزج
بعد اكتمال Run() أو RunAsync()، يحتوي output_buffers[0] على مصفوفة عائمة ثابتة الشكل [256 × 256 × 6] بترتيب متداخل. تتوفّر نتائج الفئات الست للبكسل (row, col) في الفهارس من (row * 256 + col) * 6 إلى (row * 256 + col) * 6 + 5.
تقسيم البيانات إلى 6 مخازن مؤقتة للكائنات المخزّنة (SSBO)
يقسّم برنامج مساعد وحدة المعالجة المركزية الصفيفة المتداخلة إلى 6 صفائف عائمة أحادية القناة ويحمّل كل صفيفة إلى مخزن بيانات منظَّم (SSBO) خاص بها في وحدة معالجة الرسومات:
std::vector<float> data(256 * 256 * 6);
output_buffers[0].Read(absl::MakeSpan(data));
std::vector<GLuint> mask_ids(6);
for (int i = 0; i < 6; ++i)
mask_ids[i] = processor.CreateOpenGLBuffer(nullptr, 256 * 256 * sizeof(float));
processor.DeinterleaveMasksCpu(data.data(), 256, 256, mask_ids);
دمج الألوان مع الصورة الأصلية
تنفِّذ processor.ApplyColoredMasks() برنامج التظليل mask_blend_compute.glsl. بالنسبة إلى كل بكسل ناتج، يتم العثور على الفئة التي حصلت على أعلى نتيجة (argmax على مستوى 6 أقنعة SSBO)، ويتم دمج اللون المقابل مع بكسل الصورة الأصلية. يتم تحديد الألوان الستة في كل نقطة دخول:
std::vector<RGBAColor> mask_colors = {
{1.0f, 0.0f, 0.0f, 0.1f}, // red - background
{0.0f, 1.0f, 0.0f, 0.1f}, // green - hair
{0.0f, 0.0f, 1.0f, 0.1f}, // blue - body skin
{1.0f, 1.0f, 0.0f, 0.1f}, // yellow - face skin
{1.0f, 0.0f, 1.0f, 0.1f}, // magenta - clothes
{0.0f, 1.0f, 1.0f, 0.1f}, // cyan - accessories
};
تحافظ قيمة ألفا في 0.1f على التلوين بشكل خفيف حتى تظل الصورة الأصلية مرئية.
حفظ الناتج
تتم إعادة قراءة SSBO النهائي المدمج بتنسيق RGBA float، ويتم حصر قيمته في [0, 1]، وتحويله إلى unsigned char، وحفظه بتنسيق PNG:
for (size_t i = 0; i < float_data.size(); ++i)
uchar_data[i] = static_cast<unsigned char>(
std::max(0.0f, std::min(1.0f, float_data[i])) * 255.0f);
ImageUtils::SaveImage(output_file, width, height, 4, uchar_data.data());
12. النشر والتشغيل على الجهاز
وصِّل جهاز Android باستخدام USB وتأكَّد من إمكانية الاتصال بأداة ADB:
adb devices

استخدام deploy_and_run_on_android.sh
يحتوي كل خيار من المنتج على نص برمجي خاص بالنشر. يشير خيار CMake إلى الدليل build/، بينما يشير خيار Bazel إلى bazel-bin/. كلا النصّين البرمجيَّين:
- أنشئ
/data/local/tmp/cpp_segmentation_android/على الجهاز. - ادفع الملفات الثنائية وتظليلات GLSL والتصميم وصورة الاختبار ووقت التشغيل
.so. - تشغيل الاستدلال باستخدام
adb shell - اسحب
output_segmented.pngإلى جهازك.
صيغة CMake (use_prebuilt_litert/)
# CPU
./deploy_and_run_on_android.sh --accelerator=cpu --phone=s25 build/
# GPU
./deploy_and_run_on_android.sh --accelerator=gpu --phone=s25 build/
صيغة Bazel (build_from_source/)
نفِّذ الأوامر التالية من جذر مستودع نماذج LiteRT:
# CPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=cpu --phone=s25 bazel-bin/
# GPU
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=gpu --phone=s25 bazel-bin/
يتحكّم الخيار --phone في مكتبات الطُرز والمورّدين الخاصة بالجهاز التي يتم استخدامها. القيم المتاحة: s24 (Snapdragon 8 Gen 3) وs25 (Snapdragon 8 Elite) وdim9400 (MediaTek Dimensity 9400) وpixel8 (Tensor G3) وpixel9 (شريحة Tensor G4) وpixel10 (Tensor G5) وpixel11 (Tensor G6).
توقيت الاستنتاج
بعد الاستنتاج، تطبع PrintTiming() تفصيلاً كاملاً لعملية إنشاء الملف الشخصي:
Load image: X ms
Preprocess: X ms
Inference: X ms
Postprocess: X ms
E2E: X ms
Save image: X ms
الأداء المرجعي على هاتف Samsung S25 Ultra (معالج Snapdragon 8 Elite):
مسرِّعة أعمال | نوع التنفيذ | الاستنتاج | E2E |
وحدة معالجة مركزية (CPU) | مزامنة | ~116–128 ملي ثانية | ~157 ملي ثانية |
وحدة معالجة الرسومات (OpenCL) | غير متزامنة | ~0.95 مللي ثانية | ~35–43 ملي ثانية |
13. الإعدادات المتقدّمة (اختياري): استنتاج وحدة المعالجة العصبية
لتحقيق أفضل أداء، تتيح LiteRT تسريع وحدة المعالجة العصبية باستخدام مكتبات المكوّنات الإضافية الخاصة بالمورّد. يمكن أن يحقّق مسار وحدة المعالجة العصبية وقت استجابة من البداية إلى النهاية يبلغ 9 ملي ثانية فقط.
الأجهزة والأوضاع المتوافقة
شريحة | مثال على الجهاز | الوضع | E2E |
Qualcomm SM8650 | Galaxy S24 | AOT | ~17 ملي ثانية |
Qualcomm SM8750 | Galaxy S25 | AOT | ~17 ملي ثانية |
Qualcomm (أي) | — | JIT | 28 ملي ثانية تقريبًا |
MediaTek Dimensity 9400 | — | JIT | 9 ملي ثانية تقريبًا |
Google Tensor G3-G6 | Pixel 8-11 | AOT/JIT | يختلف |
تستخدم الترجمة المسبقة (AOT) نموذجًا مجمّعًا مسبقًا خاصًا بالجهاز (مثل selfie_multiclass_256x256_SM8650.tflite). هذه هي أسرع طريقة، ولكنّها خاصة بشريحة معيّنة.
تستخدم التجميع أثناء التنفيذ (JIT) selfie_multiclass_256x256.tflite العادي ويتم التجميع إلى وحدة المعالجة العصبية في وقت التشغيل، ما يؤدي إلى إبطاء عملية التشغيل الأولى، ولكنها مستقلة عن الشريحة.
متطلبات أساسية إضافية
برنامج Qualcomm HTP:
- الإصدار 2.41 أو إصدار أحدث من حزمة تطوير البرامج (SDK) الخاصة بأداة QAIRT (توفّر ملفات
libQnnHtp.soأو ملفات.so). libLiteRtDispatch_Qualcomm.soمن إصدار مكتبات وقت التشغيل NPU في LiteRT على GitHub.
وحدة المعالجة المسرّعة (APU) من MediaTek:
libLiteRtDispatch_MediaTek.soمن إصدار مكتبات وقت التشغيل لوحدة المعالجة العصبية (NPU) في LiteRT.- وقت تشغيل NeuroPilot (وهو عبارة عن مكتبة نظام متوفّرة حاليًا على أجهزة Dimensity 9400، ولا يلزم إجراء أي تعديل).
Google Tensor:
libLiteRtDispatch_GoogleTensor.soمن إصدار مكتبات وقت التشغيل لوحدة المعالجة العصبية (NPU) في LiteRT.
بيئة NPU وخياراتها
يشير main_npu.cc إلى Environment في دليل مكتبة إرسال المورّد على الجهاز، ثم يضبط خيارات الأداء الخاصة بالمورّد:
// Configure LiteRT to find the dispatch library
std::vector<litert::Environment::Option> env_opts;
env_opts.push_back({litert::Environment::OptionTag::DispatchLibraryDir,
kQualcommDispatchDir});
LITERT_ASSIGN_OR_ABORT(auto env,
litert::Environment::Create(std::move(env_opts)));
// Target NPU with CPU fallback
LITERT_ASSIGN_OR_ABORT(litert::Options options, litert::Options::Create());
options.SetHardwareAccelerators(litert::HwAccelerators::kNpu |
litert::HwAccelerators::kCpu);
// Qualcomm: burst performance mode
auto& qnn_opts = options.GetQualcommOptions();
qnn_opts.SetLogLevel(litert::qualcomm::QualcommOptions::LogLevel::kOff);
qnn_opts.SetHtpPerformanceMode(
litert::qualcomm::QualcommOptions::HtpPerformanceMode::kBurst);
LITERT_ASSIGN_OR_ABORT(auto model,
litert::CompiledModel::Create(env, model_path, options));
بالنسبة إلى MediaTek، استبدِل الحظر GetQualcommOptions() بما يلي:
// MediaTek: fast single-answer mode + low-latency hint
auto& mtk_opts = options.GetMediatekOptions();
mtk_opts.SetPerformanceMode(
kLiteRtMediatekNeuronAdapterPerformanceModeNeuronPreferFastSingleAnswer);
mtk_opts.SetOptimizationHint(
kLiteRtMediatekNeuronAdapterOptimizationHintLowLatency);
mtk_opts.SetNeronSDKVersionType(
kLiteRtMediatekOptionsNeronSDKVersionTypeVersion8);
النشر على وحدة المعالجة العصبية
متغير CMake — Qualcomm S25 (AOT)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 \
--host_npu_lib=/path/to/qairt/lib \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_Qualcomm.so \
build/
إصدار CMake: MediaTek Dimensity 9400 (التنفيذ في الوقت المناسب)
./deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit \
--host_npu_dispatch_lib=/path/to/dir/with/libLiteRtDispatch_MediaTek.so \
build/
إصدار Bazel — Qualcomm S25 (AOT)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=s25 bazel-bin/
إصدار Bazel — MediaTek Dimensity 9400 (التنفيذ في الوقت المناسب)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=dim9400 --jit bazel-bin/
صيغة Bazel — Google Tensor Pixel 9 (التنفيذ في الوقت المناسب)
./compiled_model_api/image_segmentation/c++_segmentation/build_from_source/deploy_and_run_on_android.sh \
--accelerator=npu --phone=pixel9 --jit bazel-bin/
بالنسبة إلى صيغة Bazel، يتم اختيار مكتبات QAIRT SDK تلقائيًا من شجرة ملفات التشغيل bazel-bin عند ضبط LITERT_QAIRT_SDK في مدّة التصميم. يتطلّب متغير CMake العلامة --host_npu_lib للإشارة إلى حزمة تطوير البرامج (SDK) المستخرَجة من QAIRT.
14. تهانينا!
لقد أنشأت ونفّذت بنجاح مسارًا لتقسيم الصور بلغة C++ على نظام التشغيل Android باستخدام LiteRT. لقد تعلّمت كيفية:
- يمكنك تجميع ملف C++ ثنائي متوافق مع Android
arm64-v8aباستخدام CMake وNDK أو Bazel. - استخدِم واجهة برمجة تطبيقات LiteRT C++ (
EnvironmentوCompiledModelوTensorBuffer) لإجراء استنتاج فعّال على الجهاز فقط. - يمكنك معالجة بيانات الصور مسبقًا على وحدة معالجة الرسومات باستخدام برامج تظليل الحوسبة OpenGL ES 3.1.
- تشغيل استنتاج متزامن لوحدة المعالجة المركزية (CPU) واستنتاج غير متزامن لوحدة معالجة الرسومات (OpenCL)
- ضبط تسريع وحدة المعالجة العصبية (NPU) لأجهزة Qualcomm وMediaTek وGoogle Tensor
- نشر وتشغيل ملف C++ ثنائي على Android باستخدام "جسر تصحيح أخطاء Android"
الخطوات التالية
- استبدال نموذج TFLite بآخر مختلف (مثل تقدير العمق أو رصد الوضعية)
- دمج مسار C++ في تطبيق Android NDK باستخدام JNI
- يمكنك تسجيل استخدام الذاكرة باستخدام أداة Android GPU Inspector إلى جانب إخراج التوقيت.
- استكشاف تحديد كمية النموذج لتقليل وقت استجابة الاستدلال في وحدة المعالجة العصبية بشكل أكبر