
1. ก่อนเริ่มต้น
การพิมพ์โค้ดเป็นวิธีที่ยอดเยี่ยมในการสร้างความจำของกล้ามเนื้อและเพิ่มความเข้าใจในเนื้อหา แม้ว่าการคัดลอกและวางจะช่วยประหยัดเวลาได้ แต่การลงทุนในแนวทางปฏิบัตินี้จะช่วยเพิ่มประสิทธิภาพและทักษะการเขียนโค้ดในระยะยาว
ในโค้ดแล็บนี้ คุณจะได้เรียนรู้วิธีสร้างแอปพลิเคชัน Android ที่ทำการแบ่งกลุ่มรูปภาพแบบเรียลไทม์ในฟีดกล้องสดโดยใช้รันไทม์ใหม่ของ TensorFlow Lite ของ Google ซึ่งก็คือ LiteRT คุณจะใช้แอปพลิเคชัน Android เริ่มต้นและเพิ่มความสามารถในการแบ่งกลุ่มรูปภาพลงในแอป นอกจากนี้ เราจะดูขั้นตอนการประมวลผลเบื้องต้น การอนุมาน และการประมวลผลภายหลังด้วย คุณจะได้รับสิ่งต่อไปนี้
- สร้างแอป Android ที่แบ่งกลุ่มรูปภาพแบบเรียลไทม์
- ผสานรวมโมเดลการแบ่งกลุ่มรูปภาพ LiteRT ที่ฝึกไว้ล่วงหน้า
- ประมวลผลล่วงหน้าของรูปภาพอินพุตสำหรับโมเดล
- ใช้รันไทม์ LiteRT เพื่อการเร่งความเร็ว CPU และ GPU
- ทำความเข้าใจวิธีประมวลผลเอาต์พุตของโมเดลเพื่อแสดงมาสก์การแบ่งกลุ่ม
- ดูวิธีปรับสำหรับกล้องหน้า
สุดท้ายแล้ว คุณจะสร้างผลงานที่คล้ายกับรูปภาพด้านล่าง

ข้อกำหนดเบื้องต้น
Codelab นี้ออกแบบมาสำหรับนักพัฒนาแอปบนอุปกรณ์เคลื่อนที่ที่มีประสบการณ์ซึ่งต้องการได้รับประสบการณ์ด้านแมชชีนเลิร์นนิง คุณควรคุ้นเคยกับสิ่งต่อไปนี้
- การพัฒนาแอป Android โดยใช้ Kotlin และ Android Studio
- แนวคิดพื้นฐานของการประมวลผลรูปภาพ
สิ่งที่คุณจะได้เรียนรู้
- วิธีผสานรวมและใช้รันไทม์ LiteRT ในแอปพลิเคชัน Android
- วิธีทำการแบ่งกลุ่มรูปภาพโดยใช้โมเดล LiteRT ที่ฝึกไว้ล่วงหน้า
- วิธีประมวลผลล่วงหน้าของรูปภาพอินพุตสำหรับโมเดล
- วิธีเรียกใช้การอนุมานสำหรับโมเดล
- วิธีประมวลผลเอาต์พุตของโมเดลการแบ่งกลุ่มเพื่อแสดงผลลัพธ์เป็นภาพ
- วิธีใช้ CameraX เพื่อประมวลผลฟีดกล้องแบบเรียลไทม์
สิ่งที่คุณต้องมี
- Android Studio เวอร์ชันล่าสุด (ทดสอบใน v2025.1.1)
- อุปกรณ์ Android จริง โดยเราได้ทดสอบฟีเจอร์นี้ในอุปกรณ์ Galaxy และ Pixel แล้ว
- โค้ดตัวอย่าง (จาก GitHub)
- มีความรู้พื้นฐานเกี่ยวกับการพัฒนาแอป Android ใน Kotlin
2. การแบ่งกลุ่มรูปภาพ
การแบ่งกลุ่มรูปภาพเป็นงานด้านคอมพิวเตอร์วิทัศน์ที่เกี่ยวข้องกับการแบ่งรูปภาพออกเป็นหลายส่วนหรือหลายภูมิภาค การแบ่งกลุ่มรูปภาพจะกำหนดคลาสหรือป้ายกำกับที่เฉพาะเจาะจงให้กับทุกพิกเซลในรูปภาพ ซึ่งแตกต่างจากการตรวจหาออบเจ็กต์ที่วาดกรอบล้อมรอบออบเจ็กต์ ซึ่งจะช่วยให้คุณเข้าใจเนื้อหาของรูปภาพได้อย่างละเอียดและเฉพาะเจาะจงมากขึ้น ทำให้ทราบรูปร่างและขอบเขตที่แน่นอนของแต่ละออบเจ็กต์
เช่น แทนที่จะรู้แค่ว่ามี "คน" อยู่ในกรอบ คุณจะรู้ได้ว่าพิกเซลใดเป็นของบุคคลนั้น บทแนะนำนี้แสดงวิธีทำการแบ่งกลุ่มรูปภาพแบบเรียลไทม์ในอุปกรณ์ Android โดยใช้โมเดลแมชชีนเลิร์นนิงที่ฝึกไว้ล่วงหน้า

LiteRT: การผลักดันขีดจำกัดของ ML บนอุปกรณ์
เทคโนโลยีสำคัญที่ช่วยให้การแบ่งกลุ่มแบบเรียลไทม์ที่มีความเที่ยงตรงสูงในอุปกรณ์เคลื่อนที่คือ LiteRT LiteRT เป็นรันไทม์ประสิทธิภาพสูงรุ่นถัดไปของ Google สำหรับ TensorFlow Lite ซึ่งได้รับการออกแบบมาเพื่อให้ได้ประสิทธิภาพที่ดีที่สุดจากฮาร์ดแวร์พื้นฐาน
โดยทำได้ด้วยการใช้ตัวเร่งฮาร์ดแวร์อย่างชาญฉลาดและได้รับการเพิ่มประสิทธิภาพ เช่น GPU (หน่วยประมวลผลกราฟิก) และ NPU (หน่วยประมวลผลนิวรอน) การลดปริมาณงานด้านการคำนวณที่ซับซ้อนของโมเดลการแบ่งกลุ่มจาก CPU แบบอเนกประสงค์ไปยังโปรเซสเซอร์เฉพาะทางเหล่านี้ทำให้ LiteRT ลดเวลาการอนุมานได้อย่างมาก การเร่งความเร็วนี้ช่วยให้เราสามารถเรียกใช้โมเดลที่ซับซ้อนได้อย่างราบรื่นในฟีดกล้องสด ซึ่งเป็นการขยายขีดจำกัดของสิ่งที่เราทำได้ด้วยแมชชีนเลิร์นนิงบนโทรศัพท์โดยตรง หากไม่มีประสิทธิภาพระดับนี้ การแบ่งกลุ่มแบบเรียลไทม์จะช้าและไม่ราบรื่นเกินไปจนทำให้ผู้ใช้ได้รับประสบการณ์ที่ไม่ดี
3. ตั้งค่า
โคลนที่เก็บ
ก่อนอื่น ให้โคลนที่เก็บสำหรับ LiteRT
git clone https://github.com/google-ai-edge/litert-samples.git
litert-samples/compiled_model_api/image_segmentation คือไดเรกทอรีที่มีทรัพยากรทั้งหมดที่คุณจะต้องใช้ สำหรับโค้ดแล็บนี้ คุณจะต้องใช้โปรเจ็กต์ kotlin_cpu_gpu/android_starter เท่านั้น คุณอาจต้องตรวจสอบโปรเจ็กต์ที่เสร็จสมบูรณ์แล้วหากติดขัด โดยทำดังนี้ kotlin_cpu_gpu/android
หมายเหตุเกี่ยวกับเส้นทางของไฟล์
บทแนะนำนี้จะระบุเส้นทางของไฟล์ในรูปแบบ Linux/macOS หากใช้ Windows คุณจะต้องปรับเส้นทางให้เหมาะสม
นอกจากนี้ คุณควรทราบความแตกต่างระหว่างมุมมองโปรเจ็กต์ของ Android Studio กับมุมมองระบบไฟล์มาตรฐานด้วย มุมมองโปรเจ็กต์ Android Studio คือการแสดงไฟล์ของโปรเจ็กต์อย่างเป็นระบบ ซึ่งจัดระเบียบไว้สำหรับการพัฒนา Android เส้นทางไฟล์ในบทแนะนำนี้หมายถึงเส้นทางระบบไฟล์ ไม่ใช่เส้นทางในมุมมองโปรเจ็กต์ Android Studio
นำเข้าแอปเริ่มต้น
มาเริ่มกันด้วยการนำเข้าแอปเริ่มต้นไปยัง Android Studio
- เปิด Android Studio แล้วเลือกเปิด
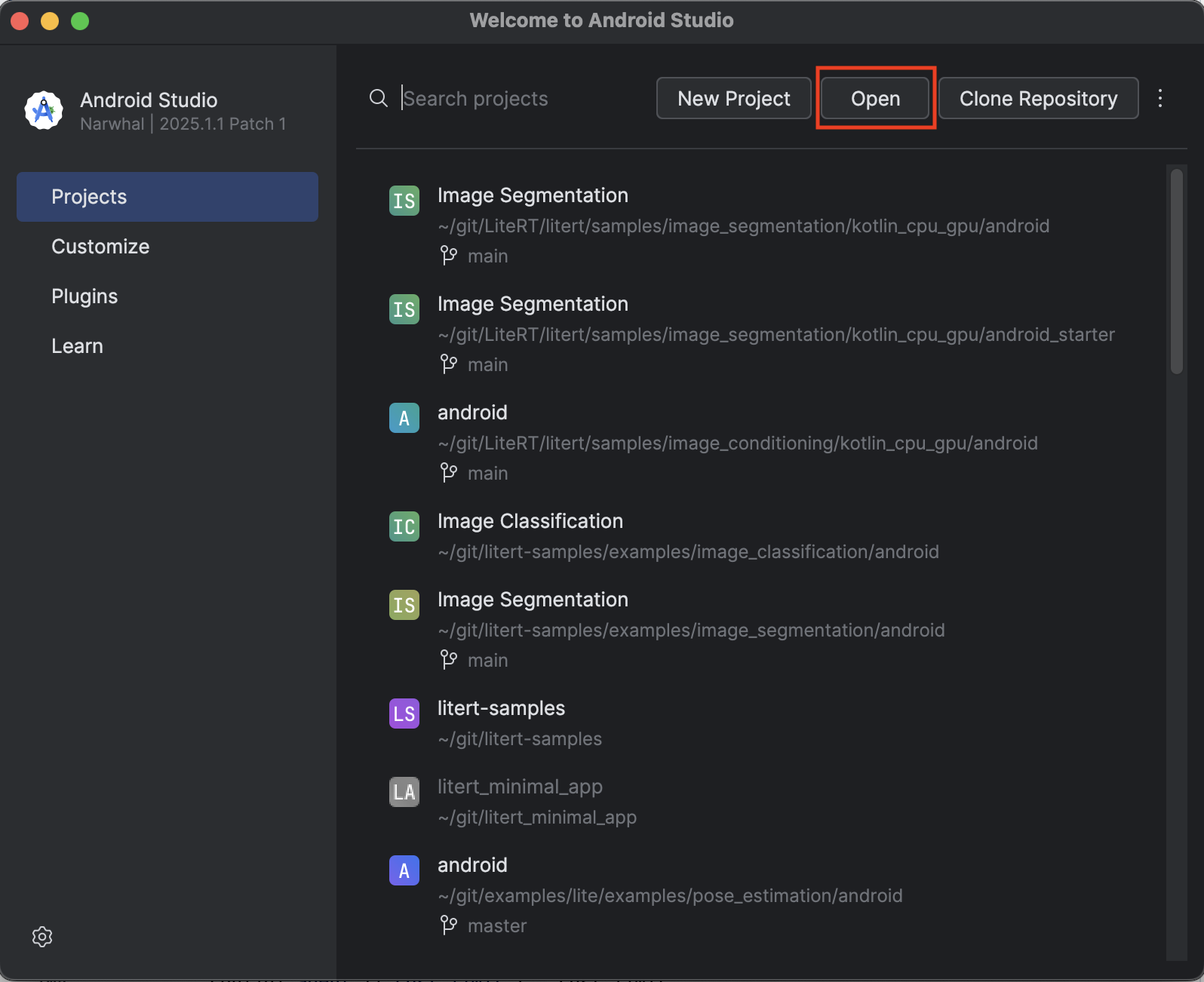
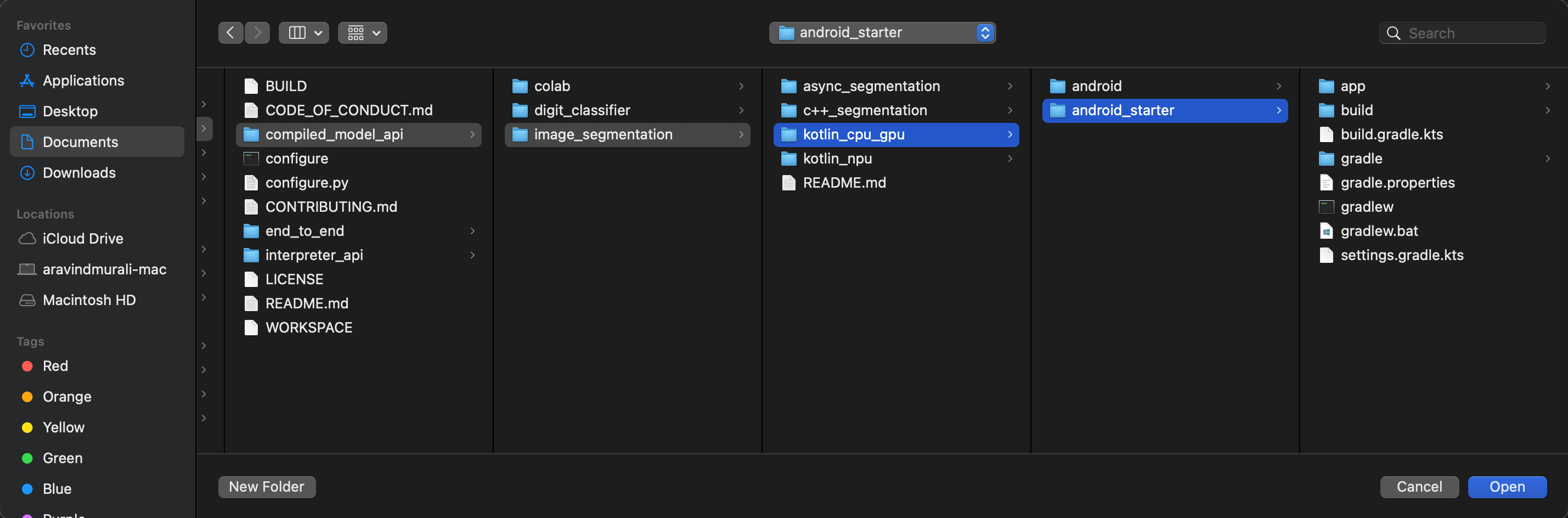
- ไปที่ไดเรกทอรี
kotlin_cpu_gpu/android_starterแล้วเปิด
หากต้องการให้แน่ใจว่าแอปของคุณมีทรัพยากร Dependency ทั้งหมด คุณควรซิงค์โปรเจ็กต์กับไฟล์ Gradle เมื่อกระบวนการนำเข้าเสร็จสิ้น
- เลือกซิงค์โปรเจ็กต์กับไฟล์ Gradle จากแถบเครื่องมือของ Android Studio
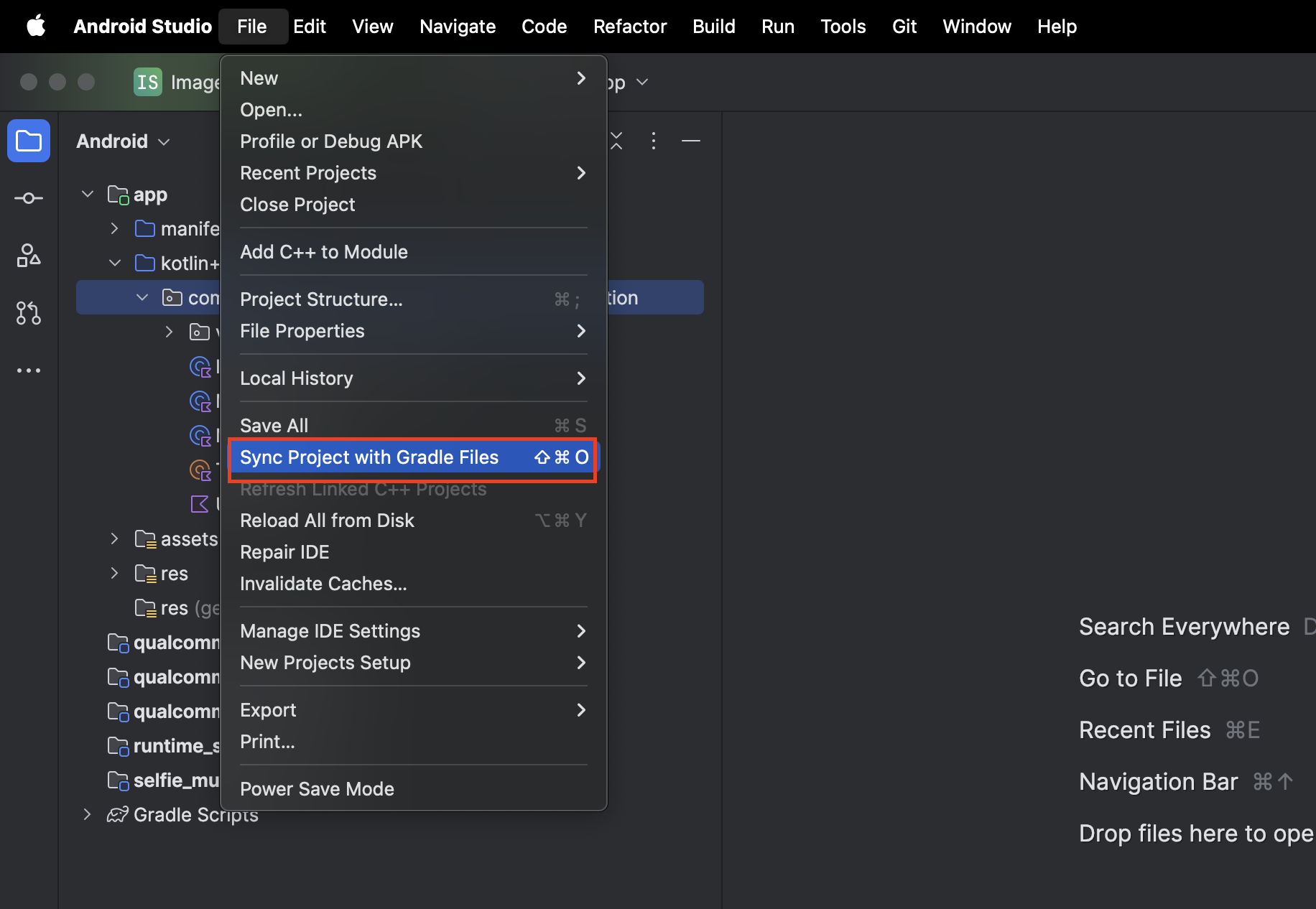
- โปรดอย่าข้ามขั้นตอนนี้ หากไม่ได้ผล บทแนะนำที่เหลือจะไม่มีประโยชน์
เรียกใช้แอปเริ่มต้น
ตอนนี้คุณได้นำเข้าโปรเจ็กต์ไปยัง Android Studio แล้ว และพร้อมที่จะเรียกใช้แอปเป็นครั้งแรก
เชื่อมต่ออุปกรณ์ Android กับคอมพิวเตอร์ผ่าน USB แล้วคลิกเรียกใช้ในแถบเครื่องมือของ Android Studio
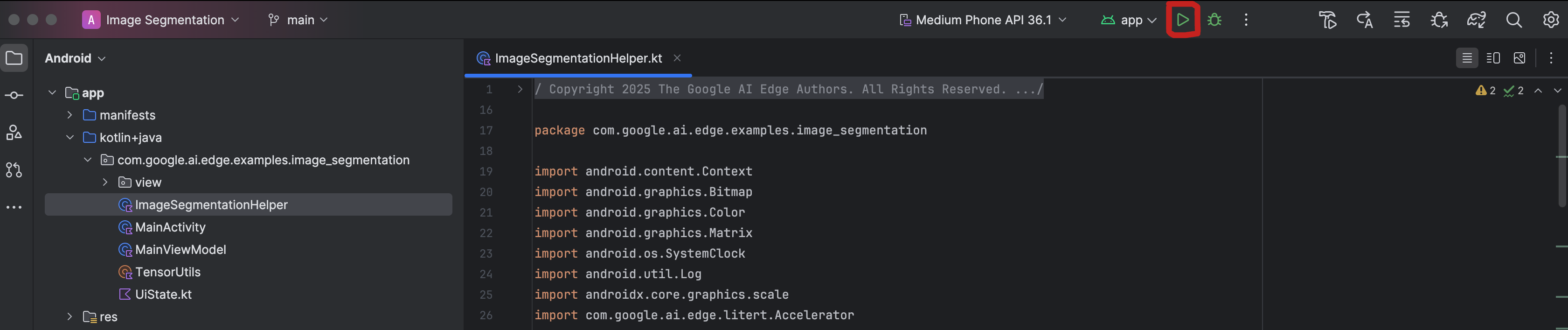
แอปควรเปิดขึ้นในอุปกรณ์ คุณจะเห็นฟีดกล้องแบบเรียลไทม์ แต่จะยังไม่มีการแบ่งกลุ่ม การแก้ไขไฟล์ทั้งหมดที่คุณจะทำในบทแนะนำนี้จะอยู่ในไดเรกทอรี litert-samples/compiled_model_api/image_segmentation/kotlin_cpu_gpu/android_starter/app/src/main/java/com/google/ai/edge/examples/image_segmentation (ตอนนี้คุณคงทราบแล้วว่าเหตุใด Android Studio จึงปรับโครงสร้างนี้ 😃)
นอกจากนี้ คุณจะเห็นTODOความคิดเห็นในไฟล์ ImageSegmentationHelper.kt, MainViewModel.kt และ view/SegmentationOverlay.kt ด้วย ในขั้นตอนต่อไปนี้ คุณจะใช้ฟังก์ชันการแบ่งกลุ่มรูปภาพโดยการกรอกข้อมูลใน TODOs เหล่านี้
4. ทำความเข้าใจแอปเริ่มต้น
แอปเริ่มต้นมี UI พื้นฐานและตรรกะการจัดการกล้องอยู่แล้ว ภาพรวมโดยสรุปของไฟล์สำคัญมีดังนี้
app/src/main/java/com/google/ai/edge/examples/image_segmentation/MainActivity.kt: นี่คือจุดแรกเข้าหลักของแอปพลิเคชัน โดยจะตั้งค่า UI โดยใช้ Jetpack Compose และจัดการสิทธิ์เข้าถึงกล้องapp/src/main/java/com/google/ai/edge/examples/image_segmentation/MainViewModel.kt: ViewModel นี้จัดการสถานะ UI และประสานกระบวนการแบ่งกลุ่มรูปภาพapp/src/main/java/com/google/ai/edge/examples/image_segmentation/ImageSegmentationHelper.kt: ส่วนนี้คือที่ที่เราจะเพิ่มตรรกะหลักสำหรับการแบ่งกลุ่มรูปภาพ โดยจะจัดการการโหลดโมเดล การประมวลผลเฟรมกล้อง และการเรียกใช้การอนุมานapp/src/main/java/com/google/ai/edge/examples/image_segmentation/view/CameraScreen.kt: ฟังก์ชันที่ประกอบกันได้นี้จะแสดงตัวอย่างกล้องและการซ้อนทับการแบ่งกลุ่มapp/download_model.gradle: สคริปต์นี้จะดาวน์โหลดselfie_multiclass.tfliteนี่คือโมเดลการแบ่งกลุ่มรูปภาพ TensorFlow Lite ที่ได้รับการฝึกมาก่อนซึ่งเราจะใช้
5. ทำความเข้าใจ LiteRT และการเพิ่มทรัพยากร Dependency
ตอนนี้มาเพิ่มฟังก์ชันการทำงานของการแบ่งกลุ่มรูปภาพลงในแอปเริ่มต้นกัน
1. เพิ่มการอ้างอิง LiteRT
ก่อนอื่น คุณต้องเพิ่มไลบรารี LiteRT ลงในโปรเจ็กต์ นี่คือก้าวแรกที่สำคัญในการเปิดใช้แมชชีนเลิร์นนิงในอุปกรณ์ด้วยรันไทม์ที่เพิ่มประสิทธิภาพของ Google
เปิดไฟล์ app/build.gradle.kts แล้วเพิ่มบรรทัดต่อไปนี้ลงในบล็อก dependencies
// LiteRT for on-device ML
implementation(libs.litert)
หลังจากเพิ่มทรัพยากร Dependency แล้ว ให้ซิงค์โปรเจ็กต์กับไฟล์ Gradle โดยคลิกปุ่มซิงค์เลยที่ปรากฏที่มุมขวาบนของ Android Studio

2. ทำความเข้าใจ API หลักของ LiteRT
เปิด ImageSegmentationHelper.kt
ก่อนที่จะเขียนโค้ดการติดตั้งใช้งาน คุณควรทำความเข้าใจคอมโพเนนต์หลักของ LiteRT API ที่คุณจะใช้ ตรวจสอบว่าคุณนำเข้าจากแพ็กเกจ com.google.ai.edge.litert แล้วเพิ่มการนำเข้าต่อไปนี้ที่ด้านบนของ ImageSegmentationHelper.kt
import com.google.ai.edge.litert.Accelerator
import com.google.ai.edge.litert.CompiledModel
CompiledModel: นี่คือคลาสส่วนกลางสำหรับการโต้ตอบกับโมเดล TFLite ซึ่งแสดงถึงโมเดลที่คอมไพล์ล่วงหน้าและเพิ่มประสิทธิภาพสำหรับตัวเร่งฮาร์ดแวร์ที่เฉพาะเจาะจง (เช่น CPU หรือ GPU) การคอมไพล์ล่วงหน้านี้เป็นฟีเจอร์หลักของ LiteRT ที่ช่วยให้การอนุมานเร็วขึ้นและมีประสิทธิภาพมากขึ้นCompiledModel.Options: คุณใช้คลาส Builder นี้เพื่อกำหนดค่าCompiledModelการตั้งค่าที่สำคัญที่สุดคือการระบุตัวเร่งฮาร์ดแวร์ที่คุณต้องการใช้ในการเรียกใช้โมเดลAccelerator: การแจงนับนี้ช่วยให้คุณเลือกฮาร์ดแวร์สำหรับการอนุมานได้ โปรเจ็กต์เริ่มต้นได้รับการกำหนดค่าให้รองรับตัวเลือกต่อไปนี้แล้วAccelerator.CPU: สำหรับการเรียกใช้โมเดลใน CPU ของอุปกรณ์ ตัวเลือกนี้เข้ากันได้กับทุกอุปกรณ์มากที่สุดAccelerator.GPU: สำหรับการเรียกใช้โมเดลใน GPU ของอุปกรณ์ ซึ่งมักจะเร็วกว่า CPU สำหรับโมเดลที่อิงตามรูปภาพอย่างมาก
- บัฟเฟอร์อินพุตและเอาต์พุต (
TensorBuffer): LiteRT ใช้TensorBufferสำหรับอินพุตและเอาต์พุตของโมเดล ซึ่งช่วยให้คุณควบคุมหน่วยความจำได้อย่างละเอียดและหลีกเลี่ยงการคัดลอกข้อมูลที่ไม่จำเป็น คุณจะได้รับบัฟเฟอร์เหล่านี้โดยตรงจากอินสแตนซ์CompiledModelโดยใช้model.createInputBuffers()และmodel.createOutputBuffers()จากนั้นเขียนข้อมูลอินพุตลงในบัฟเฟอร์เหล่านั้นและอ่านผลลัพธ์จากบัฟเฟอร์ model.run(): ฟังก์ชันนี้จะดำเนินการอนุมาน คุณส่งบัฟเฟอร์อินพุตและเอาต์พุตไปยัง LiteRT และ LiteRT จะจัดการงานที่ซับซ้อนในการเรียกใช้โมเดลในฮาร์ดแวร์ Accelerator ที่เลือก
6. การติดตั้งใช้งาน ImageSegmentationHelper เริ่มต้นให้เสร็จสมบูรณ์
ตอนนี้ถึงเวลาเขียนโค้ดแล้ว คุณจะติดตั้งใช้งาน ImageSegmentationHelper.kt ในช่วงแรกให้เสร็จสมบูรณ์ ซึ่งเกี่ยวข้องกับการตั้งค่าSegmenterคลาสส่วนตัวเพื่อเก็บโมเดล LiteRT และการใช้ฟังก์ชัน cleanup() เพื่อเผยแพร่โมเดลอย่างถูกต้อง
- ทำให้คลาส
Segmenterและฟังก์ชันcleanup()เสร็จสมบูรณ์: ในไฟล์ImageSegmentationHelper.ktคุณจะเห็นโครงสร้างของคลาสส่วนตัวชื่อSegmenterและฟังก์ชันชื่อcleanup()ก่อนอื่น ให้ทําSegmenterคลาสclose()ให้เสร็จสมบูรณ์โดยกําหนดตัวสร้างเพื่อเก็บโมเดล สร้างพร็อพเพอร์ตี้สําหรับบัฟเฟอร์อินพุต/เอาต์พุต และเพิ่มเมธอดclose()เพื่อเผยแพร่โมเดล จากนั้นใช้ฟังก์ชันcleanup()เพื่อเรียกใช้เมธอดclose()ใหม่นี้ แทนที่คลาสSegmenterและฟังก์ชันcleanup()ที่มีอยู่ด้วยรายการต่อไปนี้ (~บรรทัดที่ 83)private class Segmenter( // Add this argument private val model: CompiledModel, private val coloredLabels: List<ColoredLabel>, ) { // Add these private vals private val inputBuffers = model.createInputBuffers() private val outputBuffers = model.createOutputBuffers() fun cleanup() { // cleanup buffers inputBuffers.forEach { it.close() } outputBuffers.forEach { it.close() } // cleanup model model.close() } } - กำหนดเมธอด toAccelerator: เมธอดนี้จะแมปการแจงนับตัวเร่งที่กำหนดจากเมนูตัวเร่งไปยังการแจงนับตัวเร่งที่เฉพาะเจาะจงสำหรับโมดูล LiteRT ที่นำเข้า (~บรรทัดที่ 225)
fun toAccelerator(acceleratorEnum: AcceleratorEnum): Accelerator { return when (acceleratorEnum) { AcceleratorEnum.CPU -> Accelerator.CPU AcceleratorEnum.GPU -> Accelerator.GPU } } - เริ่มต้น
CompiledModel: ตอนนี้ให้ค้นหาฟังก์ชันinitSegmenterนี่คือส่วนที่คุณจะสร้างอินสแตนซ์CompiledModelและใช้เพื่อสร้างอินสแตนซ์ของคลาสSegmenterที่กำหนดไว้ โค้ดนี้จะตั้งค่าโมเดลด้วยตัวเร่งที่ระบุ (CPU หรือ GPU) และเตรียมโมเดลสำหรับการอนุมาน แทนที่TODOในinitSegmenterด้วยการติดตั้งใช้งานต่อไปนี้ (Cmd/Ctrl+f ‘initSegmenter` หรือ ~บรรทัดที่ 62)cleanup() try { withContext(singleThreadDispatcher) { val model = CompiledModel.create( context.assets, "selfie_multiclass.tflite", CompiledModel.Options(toAccelerator(acceleratorEnum)), null, ) segmenter = Segmenter(model, coloredLabels) Log.d(TAG, "Created an image segmenter") } } catch (e: Exception) { Log.i(TAG, "Create LiteRT from selfie_multiclass is failed: ${e.message}") _error.emit(e) }
7. เริ่มการแบ่งกลุ่มและการประมวลผลล่วงหน้า
ตอนนี้เรามีโมเดลแล้ว จึงต้องทริกเกอร์กระบวนการแบ่งกลุ่มและเตรียมข้อมูลอินพุตสำหรับโมเดล
การแบ่งกลุ่มทริกเกอร์
กระบวนการแบ่งกลุ่มจะเริ่มใน MainViewModel.kt ซึ่งรับเฟรมจากกล้อง
เปิด MainViewModel.kt
- ทริกเกอร์การแบ่งกลุ่มจากเฟรมกล้อง: ฟังก์ชัน
segmentในMainViewModelคือจุดแรกเข้าสำหรับงานการแบ่งกลุ่มของเรา ระบบจะเรียกใช้ฟังก์ชันเหล่านี้ทุกครั้งที่มีรูปภาพใหม่จากกล้องหรือเลือกจากแกลเลอรี จากนั้นฟังก์ชันเหล่านี้จะเรียกใช้เมธอดsegmentในImageSegmentationHelperแทนที่TODOในฟังก์ชันsegmentทั้ง 2 ฟังก์ชันด้วยข้อความต่อไปนี้ (บรรทัดที่ ~107)// For ImageProxy (from CameraX) fun segment(imageProxy: ImageProxy) { segmentJob = viewModelScope.launch { imageSegmentationHelper.segment(imageProxy.toBitmap(), imageProxy.imageInfo.rotationDegrees) imageProxy.close() } } // For Bitmaps (from gallery) fun segment(bitmap: Bitmap, rotationDegrees: Int) { segmentJob = viewModelScope.launch { val argbBitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true) imageSegmentationHelper.segment(argbBitmap, rotationDegrees) } }
ประมวลผลรูปภาพล่วงหน้า
ตอนนี้เรากลับไปที่ ImageSegmentationHelper.kt เพื่อจัดการการประมวลผลล่วงหน้าของรูปภาพกัน
เปิด ImageSegmentationHelper.kt
- ใช้ฟังก์ชัน Public
segment: ฟังก์ชันนี้ทำหน้าที่เป็น Wrapper ที่เรียกใช้ฟังก์ชัน PrivatesegmentภายในคลาสSegmenterแทนที่TODOด้วย (~บรรทัดที่ 95):try { withContext(singleThreadDispatcher) { segmenter?.segment(bitmap, rotationDegrees)?.let { if (isActive) _segmentation.emit(it) } } } catch (e: Exception) { Log.i(TAG, "Image segment error occurred: ${e.message}") _error.emit(e) } - ใช้การประมวลผลล่วงหน้า:
segmentฟังก์ชันส่วนตัวภายในคลาสSegmenterคือที่ที่เราจะทำการเปลี่ยนรูปแบบที่จำเป็นกับรูปภาพอินพุตเพื่อเตรียมไว้สำหรับโมเดล ซึ่งรวมถึงการปรับขนาด การหมุน และการปรับรูปภาพให้เป็นปกติ จากนั้นฟังก์ชันนี้จะเรียกใช้ฟังก์ชันsegmentส่วนตัวอีกฟังก์ชันหนึ่งเพื่อทำการอนุมาน แทนที่TODOในฟังก์ชันsegment(bitmap: Bitmap, ...)ด้วย (~บรรทัดที่ 121)val totalStartTime = SystemClock.uptimeMillis() val rotation = -rotationDegrees / 90 val (h, w) = Pair(256, 256) // Preprocessing val preprocessStartTime = SystemClock.uptimeMillis() var image = bitmap.scale(w, h, true) image = rot90Clockwise(image, rotation) val inputFloatArray = normalize(image, 127.5f, 127.5f) Log.d(TAG, "Preprocessing time: ${SystemClock.uptimeMillis() - preprocessStartTime} ms") // Inference val inferenceStartTime = SystemClock.uptimeMillis() val segmentResult = segment(inputFloatArray) Log.d(TAG, "Inference time: ${SystemClock.uptimeMillis() - inferenceStartTime} ms") Log.d(TAG, "Total segmentation time: ${SystemClock.uptimeMillis() - totalStartTime} ms") return SegmentationResult(segmentResult, SystemClock.uptimeMillis() - inferenceStartTime)
8. การอนุมานหลักด้วย LiteRT
เมื่อประมวลผลข้อมูลอินพุตล่วงหน้าแล้ว ตอนนี้เราก็สามารถเรียกใช้การอนุมานหลักโดยใช้ LiteRT ได้
เปิด ImageSegmentationHelper.kt
- การใช้งานการดำเนินการโมเดล: ฟังก์ชัน
segment(inputFloatArray: FloatArray)ส่วนตัวคือที่ที่เราโต้ตอบกับเมธอดrun()LiteRT โดยตรง เราจะเขียนข้อมูลที่ประมวลผลล่วงหน้าไปยังบัฟเฟอร์อินพุต เรียกใช้โมเดล และอ่านผลลัพธ์จากบัฟเฟอร์เอาต์พุต แทนที่TODOในฟังก์ชันนี้ด้วย (~บรรทัดที่ 188):val (h, w, c) = Triple(256, 256, 6) // MODEL EXECUTION PHASE val modelExecStartTime = SystemClock.uptimeMillis() // Write input data - measure time val bufferWriteStartTime = SystemClock.uptimeMillis() inputBuffers[0].writeFloat(inputFloatArray) val bufferWriteTime = SystemClock.uptimeMillis() - bufferWriteStartTime Log.d(TAG, "Buffer write time: $bufferWriteTime ms") // Optional tensor inspection logTensorStats("Input tensor", inputFloatArray) // Run model inference - measure time val modelRunStartTime = SystemClock.uptimeMillis() model.run(inputBuffers, outputBuffers) val modelRunTime = SystemClock.uptimeMillis() - modelRunStartTime Log.d(TAG, "Model.run() time: $modelRunTime ms") // Read output data - measure time val bufferReadStartTime = SystemClock.uptimeMillis() val outputFloatArray = outputBuffers[0].readFloat() val outputBuffer = FloatBuffer.wrap(outputFloatArray) val bufferReadTime = SystemClock.uptimeMillis() - bufferReadStartTime Log.d(TAG, "Buffer read time: $bufferReadTime ms") val modelExecTime = SystemClock.uptimeMillis() - modelExecStartTime Log.d(TAG, "Total model execution time: $modelExecTime ms") // Optional tensor inspection logTensorStats("Output tensor", outputFloatArray) // POSTPROCESSING PHASE val postprocessStartTime = SystemClock.uptimeMillis() // Process mask from model output val inferenceData = InferenceData(width = w, height = h, channels = c, buffer = outputBuffer) val mask = processImage(inferenceData) val postprocessTime = SystemClock.uptimeMillis() - postprocessStartTime Log.d(TAG, "Postprocessing time (mask creation): $postprocessTime ms") return Segmentation( listOf(Mask(mask, inferenceData.width, inferenceData.height)), coloredLabels, )
9. การประมวลผลภายหลังและการแสดงภาพซ้อน
หลังจากเรียกใช้การอนุมาน เราจะได้รับเอาต์พุตดิบจากโมเดล เราต้องประมวลผลเอาต์พุตนี้เพื่อสร้างมาสก์การแบ่งกลุ่มภาพ แล้วจึงแสดงบนหน้าจอ
เปิด ImageSegmentationHelper.kt
- ใช้การประมวลผลเอาต์พุต: ฟังก์ชัน
processImageจะแปลงเอาต์พุตจุดลอยตัวดิบจากโมเดลเป็นByteBufferที่แสดงถึงมาสก์การแบ่งกลุ่ม โดยจะพิจารณาจากคลาสที่มีโอกาสสูงสุดสำหรับแต่ละพิกเซล แทนที่TODOด้วย (~บรรทัดที่ 238):val mask = ByteBuffer.allocateDirect(inferenceData.width * inferenceData.height) for (i in 0 until inferenceData.height) { for (j in 0 until inferenceData.width) { val offset = inferenceData.channels * (i * inferenceData.width + j) var maxIndex = 0 var maxValue = inferenceData.buffer.get(offset) for (index in 1 until inferenceData.channels) { if (inferenceData.buffer.get(offset + index) > maxValue) { maxValue = inferenceData.buffer.get(offset + index) maxIndex = index } } mask.put(i * inferenceData.width + j, maxIndex.toByte()) } } return mask
เปิด MainViewModel.kt
- รวบรวมและประมวลผลผลลัพธ์การแบ่งกลุ่ม: ตอนนี้เรากลับไปที่
MainViewModelเพื่อประมวลผลผลลัพธ์การแบ่งกลุ่มจากImageSegmentationHelpersegmentationUiShareFlowจะรวบรวมSegmentationResultแปลงมาสก์เป็นBitmapที่มีสีสัน และแสดงใน UI แทนที่TODOในพร็อพเพอร์ตี้segmentationUiShareFlowด้วย (~บรรทัดที่ 63) อย่าแทนที่โค้ดที่มีอยู่แล้ว เพียงแค่กรอกข้อมูลในส่วนเนื้อหาviewModelScope.launch { imageSegmentationHelper.segmentation .filter { it.segmentation.masks.isNotEmpty() } .map { val segmentation = it.segmentation val mask = segmentation.masks[0] val maskArray = mask.data val width = mask.width val height = mask.height val pixelSize = width * height val pixels = IntArray(pixelSize) val colorLabels = segmentation.coloredLabels.mapIndexed { index, coloredLabel -> ColorLabel(index, coloredLabel.label, coloredLabel.argb) } // Set color for pixels for (i in 0 until pixelSize) { val colorLabel = colorLabels[maskArray[i].toInt()] val color = colorLabel.getColor() pixels[i] = color } // Get image info val overlayInfo = OverlayInfo(pixels = pixels, width = width, height = height) val inferenceTime = it.inferenceTime Pair(overlayInfo, inferenceTime) } .collect { flow.emit(it) } }
เปิด view/SegmentationOverlay.kt
ส่วนสุดท้ายคือการวางซ้อนการแบ่งกลุ่มอย่างถูกต้องเมื่อผู้ใช้เปลี่ยนไปใช้กล้องหน้า ฟีดกล้องจะปรับให้เหมือนภาพในกระจกสำหรับกล้องหน้าโดยอัตโนมัติ ดังนั้นเราจึงต้องใช้การพลิกแนวนอนแบบเดียวกันกับภาพซ้อนทับ Bitmap เพื่อให้ภาพซ้อนทับสอดคล้องกับการแสดงตัวอย่างกล้องอย่างถูกต้อง
- จัดการการวางซ้อน: ค้นหา
TODOในไฟล์SegmentationOverlay.ktแล้วแทนที่ด้วยโค้ดต่อไปนี้ โค้ดนี้จะตรวจสอบว่ากล้องหน้าทำงานอยู่หรือไม่ หากทำงานอยู่ ก็จะพลิกภาพซ้อนทับBitmapในแนวนอนก่อนที่จะวาดบนCanvas(~บรรทัดที่ 42):val orientedBitmap = if (lensFacing == CameraSelector.LENS_FACING_FRONT) { // Create a matrix for horizontal flipping val matrix = Matrix().apply { preScale(-1f, 1f) } Bitmap.createBitmap(image, 0, 0, image.width, image.height, matrix, false).also { image.recycle() } } else { image }
10. เรียกใช้และใช้แอปสุดท้าย
ตอนนี้คุณได้ทำการเปลี่ยนแปลงโค้ดที่จำเป็นทั้งหมดเสร็จสมบูรณ์แล้ว ได้เวลาเรียกใช้แอปและดูผลงานของคุณแล้ว
- เรียกใช้แอป: เชื่อมต่ออุปกรณ์ Android แล้วคลิกเรียกใช้ในแถบเครื่องมือของ Android Studio
- ทดสอบฟีเจอร์: เมื่อเปิดแอปแล้ว คุณควรเห็นฟีดกล้องสดพร้อมการซ้อนทับการแบ่งกลุ่มสีสันสดใส
- เปลี่ยนกล้อง: แตะไอคอนพลิกกล้องที่ด้านบนเพื่อสลับระหว่างกล้องหน้าและกล้องหลัง สังเกตว่าการซ้อนทับปรับทิศทางของตัวเองอย่างถูกต้องอย่างไร
- เปลี่ยนตัวเร่ง: แตะปุ่ม "CPU" หรือ "GPU" ที่ด้านล่างเพื่อเปลี่ยนตัวเร่งฮาร์ดแวร์ สังเกตการเปลี่ยนแปลงในเวลาอนุมานที่แสดงที่ด้านล่างของหน้าจอ GPU ควรจะเร็วกว่ามาก
- ใช้รูปภาพในแกลเลอรี: แตะแท็บ "แกลเลอรี" ที่ด้านบนเพื่อเลือกรูปภาพจากแกลเลอรีรูปภาพของอุปกรณ์ แอปจะเรียกใช้การแบ่งกลุ่มในรูปภาพนิ่งที่เลือก

ตอนนี้คุณมีแอปการแบ่งกลุ่มรูปภาพแบบเรียลไทม์ที่ทำงานได้อย่างเต็มรูปแบบซึ่งขับเคลื่อนโดย LiteRT แล้ว
11. ขั้นสูง (ไม่บังคับ): การใช้ NPU
นอกจากนี้ ที่เก็บนี้ยังมีแอปเวอร์ชันที่ได้รับการเพิ่มประสิทธิภาพสำหรับหน่วยประมวลผลประสาท (NPU) ด้วย เวอร์ชัน NPU จะช่วยเพิ่มประสิทธิภาพได้อย่างมากในอุปกรณ์ที่มี NPU ที่เข้ากันได้
หากต้องการลองใช้เวอร์ชัน NPU ให้เปิดkotlin_npu/androidโปรเจ็กต์ใน Android Studio โค้ดมีความคล้ายคลึงกับเวอร์ชัน CPU/GPU มาก และได้รับการกำหนดค่าให้ใช้ตัวแทน NPU
หากต้องการใช้ตัวแทน NPU คุณจะต้องลงทะเบียนในโปรแกรมทดลองใช้ก่อนเปิดตัว
12. ยินดีด้วย
คุณสร้างแอป Android ที่ทำการแบ่งกลุ่มรูปภาพแบบเรียลไทม์โดยใช้ LiteRT ได้สำเร็จแล้ว คุณได้เรียนรู้วิธีต่อไปนี้แล้ว
- ผสานรวมรันไทม์ LiteRT เข้ากับแอป Android
- โหลดและเรียกใช้โมเดลการแบ่งกลุ่มรูปภาพ TFLite
- ประมวลผลอินพุตของโมเดลล่วงหน้า
- ประมวลผลเอาต์พุตของโมเดลเพื่อสร้างมาสก์การแบ่งกลุ่ม
- ใช้ CameraX สำหรับแอปกล้องแบบเรียลไทม์
ขั้นตอนถัดไป
- ลองใช้โมเดลการแบ่งกลุ่มรูปภาพอื่น
- ทดสอบกับตัวแทน LiteRT ต่างๆ (CPU, GPU, NPU)