
1. Visão geral
Este codelab vai mostrar algumas APIs de machine learning. Você vai usar:
- Cloud Vision para entender o conteúdo de uma imagem
- Cloud Speech-to-Text para transcrever áudio em texto
- Cloud Translation para traduzir uma string arbitrária para qualquer idioma compatível
- Cloud Natural Language para extrair informações de texto
O que você vai criar
Você vai criar um pipeline que compara uma gravação de áudio com uma imagem e determina a relevância entre elas. Confira uma prévia de como fazer isso:
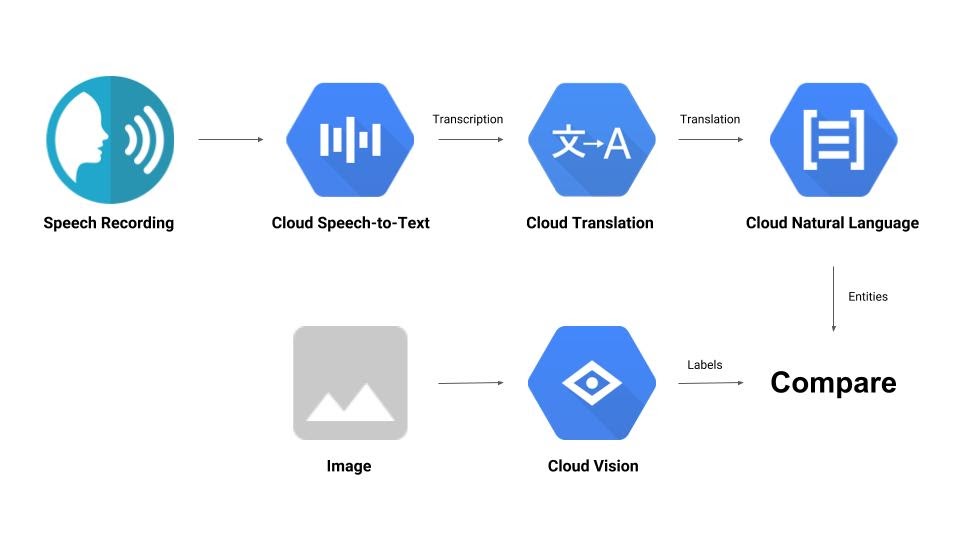
O que você vai aprender
- Como usar as APIs Vision, Speech-to-Text, Translation e Natural Language
- Onde encontrar exemplos de código
O que é necessário
2. Configuração e requisitos
Configuração de ambiente autoguiada
- Faça login no console do Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

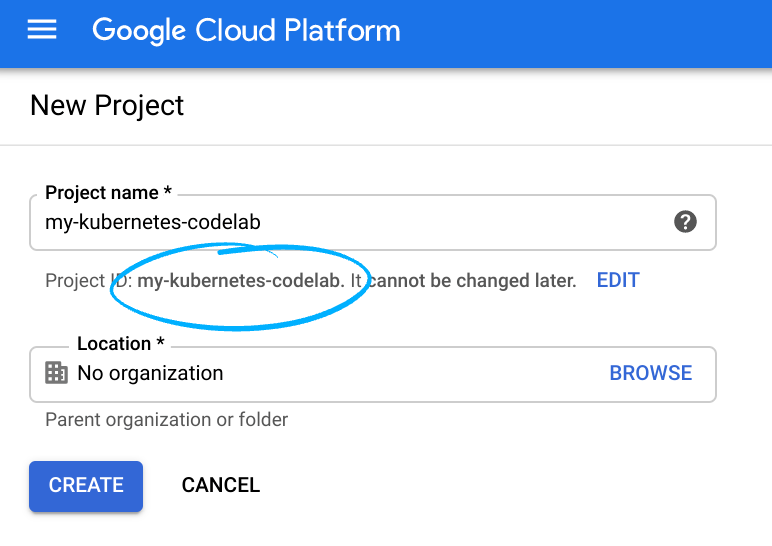
Lembre-se do código do projeto, um nome exclusivo em todos os projetos do Google Cloud. O nome acima já foi escolhido e não servirá para você. Faremos referência a ele mais adiante neste codelab como PROJECT_ID.
- Em seguida, será necessário ativar o faturamento no Console do Cloud para usar os recursos do Google Cloud.
A execução deste codelab não será muito cara, se for o caso. Siga todas as instruções na seção "Limpeza", que orienta você sobre como encerrar recursos para não incorrer em cobranças além deste tutorial. Novos usuários do Google Cloud estão qualificados para o programa de US$300 de avaliação sem custos.
Ativar as APIs
Clique neste link para ativar todas as APIs necessárias. Depois disso, ignore as instruções para configurar a autenticação. Vamos fazer isso em breve. Você também pode ativar cada API individualmente. Para fazer isso, clique no ícone de menu no canto superior esquerdo da tela.

Selecione APIs e serviços no menu suspenso e clique em Painel.
Clique em Ativar APIs e serviços.
Em seguida, digite "vision" na caixa de pesquisa. Clique em API Google Cloud Vision:

Clique em Ativar para ativar a API Cloud Vision:

Aguarde alguns segundos para que ele seja ativado. Quando ele estiver ativado, você verá isto:
Repita o mesmo processo para ativar as APIs Cloud Speech, Cloud Translation e Cloud Natural Language.
Cloud Shell
O Google Cloud Shell é um ambiente de linha de comando executado na nuvem. Essa máquina virtual baseada em Debian contém todas as ferramentas de desenvolvimento necessárias (gcloud, bq, git e outras) e oferece um diretório principal permanente de 5 GB. Vamos usar o Cloud Shell para criar nossa solicitação às APIs de machine learning.
Para começar a usar o Cloud Shell, clique no ícone  "Ativar o Google Cloud Shell" no canto superior direito da barra de cabeçalho.
"Ativar o Google Cloud Shell" no canto superior direito da barra de cabeçalho.

Uma sessão do Cloud Shell é aberta em um novo frame na parte inferior do console e um prompt de linha de comando é exibido. Aguarde até que o prompt user@project:~$ apareça.
Opcional: Editor de código
Dependendo do seu nível de conhecimento da linha de comando, clique no ícone "Iniciar editor de código"  no canto superior direito da barra do Cloud Shell.
no canto superior direito da barra do Cloud Shell.

Conta de serviço
Você vai precisar de uma conta de serviço para autenticar. Para criar uma, substitua [NAME] pelo nome desejado da conta de serviço e execute o seguinte comando no Cloud Shell:
gcloud iam service-accounts create [NAME]
Agora você precisa gerar uma chave para usar essa conta de serviço. Substitua [FILE_NAME] pelo nome desejado da chave, [NAME] pelo nome da conta de serviço acima e [PROJECT_ID] pelo ID do seu projeto. O comando a seguir vai criar e baixar a chave como [FILE_NAME].json:
gcloud iam service-accounts keys create [FILE_NAME].json --iam-account [NAME]@[PROJECT_ID].iam.gserviceaccount.com
Para usar a conta de serviço, defina a variável GOOGLE_APPLICATION_CREDENTIALS como o caminho da chave. Para isso, execute o comando a seguir depois de substituir [PATH_TO_FILE] e [FILE_NAME]:
export GOOGLE_APPLICATION_CREDENTIALS=[PATH_TO_FILE]/[FILE_NAME].json
3. Cloud Vision
Cliente Python
Você vai precisar do cliente Python para o Cloud Vision. Para instalar, digite o seguinte no Cloud Shell:
pip install --upgrade google-cloud-vision --user
Vamos tentar
Vamos conferir as amostras de código da API Cloud Vision. Queremos saber o que há em uma imagem específica. O detect.py parece ser útil para isso, então vamos usá-lo. Uma maneira é copiar o conteúdo de detect.py, criar um novo arquivo no Cloud Shell chamado vision.py e colar todo o código em vision.py. É possível fazer isso manualmente no editor de código do Cloud Shell ou executar este comando curl no Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/vision/cloud-client/detect/detect.py -o vision.py
Depois disso, use a API executando o seguinte no Cloud Shell:
python vision.py labels-uri gs://cloud-samples-data/ml-api-codelab/birds.jpg
Você vai ver uma saída sobre pássaros e avestruzes, já que esta foi a imagem analisada: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/birds.jpg
O que está acontecendo?
Você transmitiu dois argumentos para vision.py:
- labels-uri seleciona a função
detect_labels_uri()para execução - gs://cloud-samples-data/ml-api-codelab/birds.jpg é o local de uma imagem no Google Cloud Storage e é transmitido como uri para
detect_labels_uri()
Vamos analisar melhor detect_labels_uri(). Observe os comentários adicionais que foram inseridos.
def detect_labels_uri(uri):
"""Detects labels in the file located in Google Cloud Storage or on the
Web."""
# relevant import from above
# from google.cloud import vision
# create ImageAnnotatorClient object
client = vision.ImageAnnotatorClient()
# create Image object
image = vision.types.Image()
# specify location of image
image.source.image_uri = uri
# get label_detection response by passing image to client
response = client.label_detection(image=image)
# get label_annotations portion of response
labels = response.label_annotations
print('Labels:')
for label in labels:
# print the label descriptions
print(label.description)
4. Cloud Speech-to-Text
Cliente Python
Você vai precisar do cliente Python para o Cloud Speech-to-Text. Para instalar, digite o seguinte no Cloud Shell:
sudo pip install --upgrade google-cloud-speech
Vamos tentar
Vamos acessar os exemplos de código do Cloud Speech-to-Text. Queremos transcrever áudio de fala. transcribe.py parece ser um bom lugar para começar, então vamos usar isso. Copie o conteúdo de transcribe.py, crie um arquivo no Cloud Shell chamado speech2text.py e cole todo o código nele.speech2text.py É possível fazer isso manualmente no editor de código do Cloud Shell ou executar este comando curl no Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/speech/cloud-client/transcribe.py -o speech2text.py
Depois disso, use a API executando o seguinte no Cloud Shell:
python speech2text.py gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Deve haver erros informando sobre a codificação e a taxa de hertz de amostragem incorretas. Não se preocupe, acesse transcribe_gcs() no código e exclua as configurações encoding e sampe_hertz_rate de RecognitionConfig(). Aproveite e mude o código de idioma para "tr-TR", já que tr-ostrich.wav é uma gravação de voz em turco.
config = types.RecognitionConfig(language_code='tr-TR')
Agora, execute speech2text.py novamente. A saída será um texto em turco, já que esse foi o áudio analisado: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/tr-ostrich.wav
O que está acontecendo?
Você transmitiu gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav, o local de um arquivo de áudio no Google Cloud Storage para speech2text.py, que é transmitido como gcs_uri para transcribe_uri().
Vamos analisar mais de perto nosso transcribe_uri() modificado.
def transcribe_gcs(gcs_uri):
"""Transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
# enums no longer used
# from google.cloud.speech import enums
from google.cloud.speech import types
# create ImageAnnotatorClient object
client = speech.SpeechClient()
# specify location of speech
audio = types.RecognitionAudio(uri=gcs_uri)
# set language to Turkish
# removed encoding and sample_rate_hertz
config = types.RecognitionConfig(language_code='tr-TR')
# get response by passing config and audio settings to client
response = client.recognize(config, audio)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
# get the transcript of the first alternative
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
5. Cloud Translation
Cliente Python
Você vai precisar do cliente Python para a Cloud Translation. Para instalar, digite o seguinte no Cloud Shell:
sudo pip install --upgrade google-cloud-translate
Vamos tentar
Agora, vamos conferir as amostras de código do Cloud Translation. Para os fins deste codelab, queremos traduzir o texto para o inglês. snippets.py parece ser o que queremos. Copie o conteúdo de snippets.py, crie um arquivo no Cloud Shell chamado translate.py e cole todo o código em translate.py. É possível fazer isso manualmente no editor de código do Cloud Shell ou executar este comando curl no Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/translate/cloud-client/snippets.py -o translate.py
Depois disso, use a API executando o seguinte no Cloud Shell:
python translate.py translate-text en '你有沒有帶外套'
A tradução precisa ser "Você tem um casaco?".
O que está acontecendo?
Você transmitiu três argumentos para translate.py:
- translate-text seleciona a função
translate_text()para execução - en é transmitido como target para
translate_text()e serve para especificar o idioma para o qual o texto será traduzido. - 你有沒有帶外套' é a string a ser traduzida e é transmitida como text para
translate_text()
Vamos analisar melhor translate_text(). Observe os comentários que foram adicionados.
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
# relevant imports from above
# from google.cloud import translate
# import six
# create Client object
translate_client = translate.Client()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# get translation result by passing text and target language to client
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
# print original text, translated text and detected original language
print(u'Text: {}'.format(result['input']))
print(u'Translation: {}'.format(result['translatedText']))
print(u'Detected source language: {}'.format(
result['detectedSourceLanguage']))
6. Cloud Natural Language
Cliente Python
Você vai precisar do cliente Python para o Cloud Natural Language. Para instalar, digite o seguinte no Cloud Shell:
sudo pip install --upgrade google-cloud-language
Vamos tentar
Por fim, vamos conferir as amostras de código da API Cloud Natural Language. Queremos detectar entidades no texto. snippets.py parece conter um código que faz isso. Copie o conteúdo de snippets.py, crie um arquivo no Cloud Shell chamado natural_language.py e cole todo o código em natural_language.py. É possível fazer isso manualmente no editor de código do Cloud Shell ou executar este comando curl no Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/language/cloud-client/v1/snippets.py -o natural_language.py
Depois disso, use a API executando o seguinte no Cloud Shell:
python natural_language.py entities-text 'where did you leave my bike'
A API precisa identificar "bicicleta" como uma entidade. As entidades podem ser substantivos próprios (figuras públicas, pontos de referência etc.) ou substantivos comuns (restaurante, estádio etc.).
O que está acontecendo?
Você transmitiu dois argumentos para natural_language.py:
- entities-text seleciona a função
entities_text()para execução - "onde você deixou minha bicicleta" é a string a ser analisada para entidades e é transmitida como text para
entities_text()
Vamos analisar melhor entities_text(). Observe os novos comentários inseridos.
def entities_text(text):
"""Detects entities in the text."""
# relevant imports from above
# from google.cloud import language
# from google.cloud.language import enums
# from google.cloud.language import types
# import six
# create LanguageServiceClient object
client = language.LanguageServiceClient()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# Instantiates a plain text document.
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects entities in the document. You can also analyze HTML with:
# document.type == enums.Document.Type.HTML
entities = client.analyze_entities(document).entities
# entity types from enums.Entity.Type
entity_type = ('UNKNOWN', 'PERSON', 'LOCATION', 'ORGANIZATION',
'EVENT', 'WORK_OF_ART', 'CONSUMER_GOOD', 'OTHER')
# print information for each entity found
for entity in entities:
print('=' * 20)
print(u'{:<16}: {}'.format('name', entity.name))
print(u'{:<16}: {}'.format('type', entity_type[entity.type]))
print(u'{:<16}: {}'.format('metadata', entity.metadata))
print(u'{:<16}: {}'.format('salience', entity.salience))
print(u'{:<16}: {}'.format('wikipedia_url',
entity.metadata.get('wikipedia_url', '-')))
7. Vamos integrá-los
Vamos relembrar o que você está criando.
Agora vamos juntar tudo. Crie um arquivo solution.py. Copie e cole detect_labels_uri(), transcribe_gcs(), translate_text() e entities_text() das etapas anteriores em solution.py.
Declarações de importação
Remova o comentário e mova as instruções de importação para a parte de cima. Observe que speech.types e language.types estão sendo importados. Isso vai causar conflito. Então, vamos remover e mudar cada ocorrência individual de types em transcribe_gcs() e entities_text() para speech.types e language.types, respectivamente. Você vai ter:
from google.cloud import vision
from google.cloud import speech
from google.cloud import translate
from google.cloud import language
from google.cloud.language import enums
import six
Retornar resultados
Em vez de imprimir, faça com que as funções retornem os resultados. Você vai encontrar algo semelhante a:
# import statements
def detect_labels_uri(uri):
# code
# we only need the label descriptions
label_descriptions = []
for label in labels:
label_descriptions.append(label.description)
return label_descriptions
def transcribe_gcs(gcs_uri):
# code
# naive assumption that audio file is short
return response.results[0].alternatives[0].transcript
def translate_text(target, text):
# code
# only interested in translated text
return result['translatedText']
def entities_text(text):
# code
# we only need the entity names
entity_names = []
for entity in entities:
entity_names.append(entity.name)
return entity_names
Usar as funções
Depois de todo esse trabalho, você pode chamar essas funções. Vá em frente! Veja um exemplo:
def compare_audio_to_image(audio, image):
"""Checks whether a speech audio is relevant to an image."""
# speech audio -> text
transcription = transcribe_gcs(audio)
# text of any language -> english text
translation = translate_text('en', transcription)
# text -> entities
entities = entities_text(translation)
# image -> labels
labels = detect_labels_uri(image)
# naive check for whether entities intersect with labels
has_match = False
for entity in entities:
if entity in labels:
# print result for each match
print('The audio and image both contain: {}'.format(entity))
has_match = True
# print if there are no matches
if not has_match:
print('The audio and image do not appear to be related.')
Compatibilidade com vários idiomas
Antes, o turco estava fixado no código em transcribe_gcs(). Vamos mudar isso para que o idioma possa ser especificado em compare_audio_to_image(). Estas são as mudanças necessárias:
def transcribe_gcs(language, gcs_uri):
...
config = speech.types.RecognitionConfig(language_code=language)
def compare_audio_to_image(language, audio, image):
transcription = transcribe_gcs(language, audio)
Testar
O código final pode ser encontrado em solution.py deste repositório do GitHub. Confira um comando curl para fazer isso:
curl https://raw.githubusercontent.com/googlecodelabs/integrating-ml-apis/master/solution.py -O
A versão no GitHub contém argparse, que permite o seguinte na linha de comando:
python solution.py tr-TR gs://cloud-samples-data/ml-api-codelab/tr-ball.wav gs://cloud-samples-data/ml-api-codelab/football.jpg
Para cada item encontrado, o código precisa gerar "O áudio e a imagem contêm: ". No exemplo acima, seria "O áudio e a imagem contêm: bola".
Bônus: tente mais
Confira mais locais de arquivos de áudio e imagem para testar.
8. Parabéns!
Você testou e integrou quatro APIs de machine learning para determinar se uma amostra de fala está falando sobre a imagem fornecida. Este é apenas o começo, já que há muitas outras maneiras de melhorar esse pipeline.
O que vimos
- Fazer solicitações para a API Cloud Vision
- Como fazer solicitações para a API Cloud Speech-to-Text
- Como fazer solicitações à API Cloud Translation
- Como fazer solicitações para a API Cloud Natural Language
- Usar todas as APIs acima juntas
Próximas etapas
- Para uma comparação melhor de palavras, confira o word2vec.
- Confira os codelabs mais detalhados sobre a API Vision, a API Speech-to-Text, a API Translation e a API Natural Language.
- Tente substituir o Cloud Vision pela Cloud Video Intelligence.
- Sintetizar áudio de voz com a API Cloud Text-to-Speech
- Saiba como fazer upload de objetos para o Cloud Storage.