
1. Przegląd
W tym ćwiczeniu z programowania poznasz kilka interfejsów API uczenia maszynowego. Użyjesz:
- Cloud Vision do analizowania treści obrazu.
- Cloud Speech-to-Text do transkrypcji dźwięku na tekst.
- Cloud Translation do tłumaczenia dowolnego ciągu znaków na dowolny obsługiwany język.
- Cloud Natural Language do wyodrębniania informacji z tekstu.
Co utworzysz
Zbudujesz potok, który porównuje nagranie audio z obrazem i określa ich wzajemną trafność. Oto krótki opis tego, jak to zrobić:
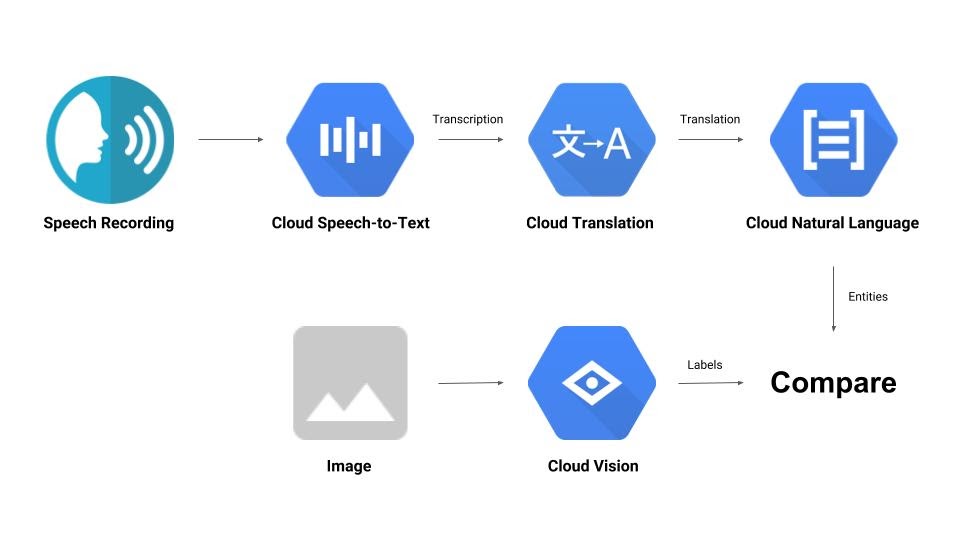
Czego się nauczysz
- Jak korzystać z interfejsów Vision API, Speech-to-Text API, Translation API i Natural Language API
- Gdzie znaleźć przykładowe fragmenty kodu
Czego potrzebujesz
2. Konfiguracja i wymagania
Samodzielne konfigurowanie środowiska
- Zaloguj się w konsoli Google Cloud i utwórz nowy projekt lub użyj istniejącego. Jeśli nie masz jeszcze konta Gmail lub Google Workspace, musisz je utworzyć.

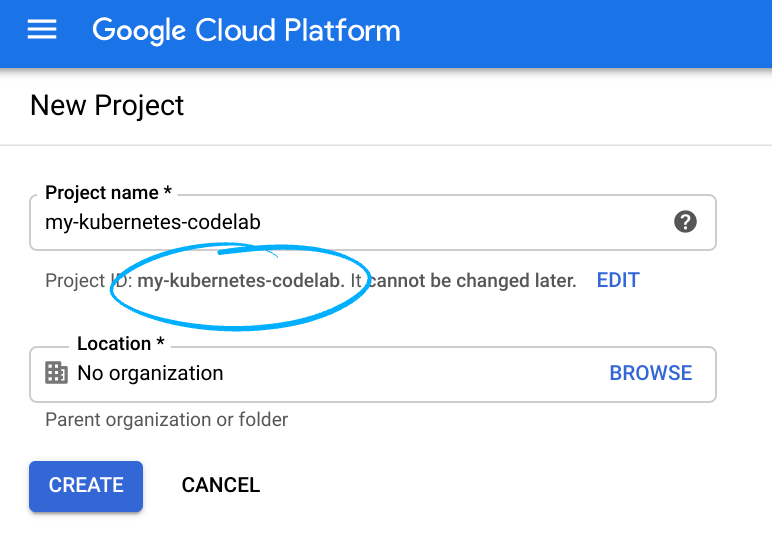
Zapamiętaj identyfikator projektu, czyli unikalną nazwę we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
- Następnie musisz włączyć płatności w Cloud Console, aby móc korzystać z zasobów Google Cloud.
Ukończenie tego laboratorium nie powinno wiązać się z dużymi kosztami, a nawet z żadnymi. Postępuj zgodnie z instrukcjami w sekcji „Czyszczenie”, która zawiera wskazówki dotyczące zamykania zasobów, aby uniknąć opłat po zakończeniu tego samouczka. Nowi użytkownicy Google Cloud mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Włączanie interfejsów API
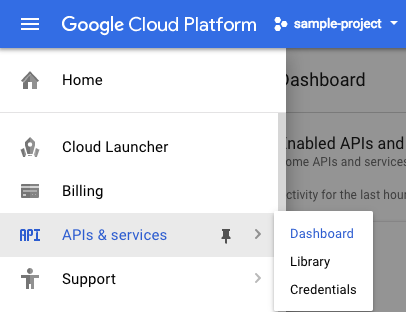
Możesz kliknąć ten link, aby włączyć wszystkie niezbędne interfejsy API. Po wykonaniu tych czynności możesz zignorować instrukcje konfigurowania uwierzytelniania. Zrobimy to za chwilę. Możesz też włączyć każdy interfejs API osobno. Aby to zrobić, kliknij ikonę menu w lewym górnym rogu ekranu.

Wybierz Interfejsy API i usługi z menu i kliknij Panel.
Kliknij Włącz interfejsy API i usługi.
Następnie w polu wyszukiwania wpisz „wzrok”. Kliknij Google Cloud Vision API:

Aby włączyć interfejs Cloud Vision API, kliknij Włącz:

Odczekaj kilka sekund, aż się włączy. Gdy ta funkcja będzie włączona, zobaczysz:
Powtórz ten sam proces, aby włączyć interfejsy Cloud Speech, Cloud Translation i Cloud Natural Language API.
Cloud Shell
Google Cloud Shell to środowisko wiersza poleceń działające w chmurze. Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów (gcloud, bq, git i inne) i oferuje trwały katalog domowy o pojemności 5 GB. Do utworzenia żądania do interfejsów API uczenia maszynowego użyjemy Cloud Shell.
Aby rozpocząć korzystanie z Cloud Shell, kliknij ikonę „Aktywuj Google Cloud Shell”  w prawym górnym rogu paska nagłówka.
w prawym górnym rogu paska nagłówka.

Sesja Cloud Shell otworzy się w nowej ramce u dołu konsoli, zostanie również wyświetlony monit wiersza poleceń. Poczekaj, aż pojawi się prompt user@project:~$ (użytkownik@projekt:~$).
Opcjonalnie: edytor kodu
Jeśli wolisz korzystać z wiersza poleceń, możesz kliknąć ikonę „Uruchom edytor kodu”  w prawym górnym rogu paska Cloud Shell.
w prawym górnym rogu paska Cloud Shell.

Konto usługi
Do uwierzytelnienia będziesz potrzebować konta usługi. Aby utworzyć konto usługi, zastąp [NAME] wybraną nazwą konta usługi i uruchom to polecenie w Cloud Shell:
gcloud iam service-accounts create [NAME]
Teraz musisz wygenerować klucz, aby używać tego konta usługi. Zastąp [FILE_NAME] wybraną nazwą klucza, [NAME] nazwą konta usługi z powyższego przykładu, a [PROJECT_ID] identyfikatorem projektu. Poniższe polecenie utworzy i pobierze klucz w postaci pliku [FILE_NAME].json:
gcloud iam service-accounts keys create [FILE_NAME].json --iam-account [NAME]@[PROJECT_ID].iam.gserviceaccount.com
Aby używać konta usługi, musisz ustawić zmienną GOOGLE_APPLICATION_CREDENTIALS na ścieżkę do klucza. Aby to zrobić, uruchom to polecenie po zastąpieniu wartości [PATH_TO_FILE] i [FILE_NAME]:
export GOOGLE_APPLICATION_CREDENTIALS=[PATH_TO_FILE]/[FILE_NAME].json
3. Cloud Vision
Klient Python
Potrzebujesz klienta Pythona dla Cloud Vision. Aby zainstalować narzędzie, wpisz w Cloud Shell:
pip install --upgrade google-cloud-vision --user
Wypróbuj
Przyjrzyjmy się przykładowym fragmentom kodu interfejsu Cloud Vision API. Chcemy dowiedzieć się, co znajduje się na określonym obrazie. detect.py wydaje się przydatne w tym przypadku, więc użyjemy tego narzędzia. Jednym ze sposobów jest skopiowanie zawartości pliku detect.py, utworzenie w Cloud Shell nowego pliku o nazwie vision.py i wklejenie do niego całego kodu.vision.py Możesz to zrobić ręcznie w edytorze kodu Cloud Shell lub uruchomić to polecenie curl w Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/vision/cloud-client/detect/detect.py -o vision.py
Gdy to zrobisz, użyj interfejsu API, uruchamiając w Cloud Shell to polecenie:
python vision.py labels-uri gs://cloud-samples-data/ml-api-codelab/birds.jpg
Powinny się wyświetlić informacje o ptakach i strusiach, ponieważ to to zdjęcie zostało przeanalizowane: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/birds.jpg
Co się dzieje?
Do funkcji vision.py przekazano 2 argumenty:
- labels-uri wybiera funkcję
detect_labels_uri()do uruchomienia. - gs://cloud-samples-data/ml-api-codelab/birds.jpg to lokalizacja obrazu w Google Cloud Storage, która jest przekazywana jako uri do
detect_labels_uri()
Przyjrzyjmy się bliżej detect_labels_uri(). Zwróć uwagę na wstawione dodatkowe komentarze.
def detect_labels_uri(uri):
"""Detects labels in the file located in Google Cloud Storage or on the
Web."""
# relevant import from above
# from google.cloud import vision
# create ImageAnnotatorClient object
client = vision.ImageAnnotatorClient()
# create Image object
image = vision.types.Image()
# specify location of image
image.source.image_uri = uri
# get label_detection response by passing image to client
response = client.label_detection(image=image)
# get label_annotations portion of response
labels = response.label_annotations
print('Labels:')
for label in labels:
# print the label descriptions
print(label.description)
4. Cloud Speech-to-Text
Klient Pythona
Potrzebujesz klienta Pythona dla Cloud Speech-to-Text. Aby zainstalować narzędzie, wpisz w Cloud Shell:
sudo pip install --upgrade google-cloud-speech
Wypróbuj
Przejdźmy do przykładowego kodu Cloud Speech-to-Text. Chcemy transkrybować dźwięk mowy. transcribe.py wydaje się dobrym miejscem na początek, więc użyjemy tej opcji. Skopiuj zawartość pliku transcribe.py, utwórz w Cloud Shell nowy plik o nazwie speech2text.py i wklej do niego cały kod.speech2text.py Możesz to zrobić ręcznie w edytorze kodu Cloud Shell lub uruchomić to polecenie curl w Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/speech/cloud-client/transcribe.py -o speech2text.py
Gdy to zrobisz, użyj interfejsu API, uruchamiając w Cloud Shell to polecenie:
python speech2text.py gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Powinny pojawić się błędy dotyczące nieprawidłowego kodowania i częstotliwości próbkowania w hercach. Nie martw się, przejdź do transcribe_gcs() w kodzie i usuń ustawienia encoding i sampe_hertz_rate z RecognitionConfig(). Przy okazji zmień kod języka na „tr-TR”, ponieważ tr-ostrich.wav to nagranie mowy w języku tureckim.
config = types.RecognitionConfig(language_code='tr-TR')
Teraz ponownie uruchom speech2text.py. Dane wyjściowe powinny zawierać tekst w języku tureckim, ponieważ analizowany był dźwięk w tym języku: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Co się dzieje?
Przekazano gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav, czyli lokalizację pliku audio w Google Cloud Storage, do speech2text.py, który jest następnie przekazywany jako gcs_uri do transcribe_uri()
Przyjrzyjmy się bliżej zmodyfikowanemu transcribe_uri().
def transcribe_gcs(gcs_uri):
"""Transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
# enums no longer used
# from google.cloud.speech import enums
from google.cloud.speech import types
# create ImageAnnotatorClient object
client = speech.SpeechClient()
# specify location of speech
audio = types.RecognitionAudio(uri=gcs_uri)
# set language to Turkish
# removed encoding and sample_rate_hertz
config = types.RecognitionConfig(language_code='tr-TR')
# get response by passing config and audio settings to client
response = client.recognize(config, audio)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
# get the transcript of the first alternative
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
5. Cloud Translation
Klient Pythona
Potrzebujesz klienta Pythona dla Cloud Translation. Aby zainstalować narzędzie, wpisz w Cloud Shell:
sudo pip install --upgrade google-cloud-translate
Wypróbuj
Teraz zapoznaj się z przykładami kodu Cloud Translation. W tym ćwiczeniu chcemy przetłumaczyć tekst na język angielski. snippets.py wygląda na to, czego szukamy. Skopiuj zawartość pliku snippets.py, utwórz w Cloud Shell nowy plik o nazwie translate.py i wklej do niego cały kod.translate.py Możesz to zrobić ręcznie w edytorze kodu Cloud Shell lub uruchomić to polecenie curl w Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/translate/cloud-client/snippets.py -o translate.py
Gdy to zrobisz, użyj interfejsu API, uruchamiając w Cloud Shell to polecenie:
python translate.py translate-text en '你有沒有帶外套'
Tłumaczenie powinno brzmieć „Do you have a jacket?”.
Co się dzieje?
Do funkcji translate.py przekazano 3 argumenty:
- translate-text wybiera funkcję
translate_text()do uruchomienia. - en jest przekazywany jako target do
translate_text()i określa język, na który ma zostać przetłumaczony tekst. - ‘你有沒有帶外套' to ciąg znaków do przetłumaczenia, który jest przekazywany jako text do
translate_text()
Przyjrzyjmy się bliżej translate_text(). Zwróć uwagę na dodane komentarze.
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
# relevant imports from above
# from google.cloud import translate
# import six
# create Client object
translate_client = translate.Client()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# get translation result by passing text and target language to client
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
# print original text, translated text and detected original language
print(u'Text: {}'.format(result['input']))
print(u'Translation: {}'.format(result['translatedText']))
print(u'Detected source language: {}'.format(
result['detectedSourceLanguage']))
6. Cloud Natural Language
Klient Pythona
Potrzebujesz klienta Pythona dla Cloud Natural Language. Aby zainstalować narzędzie, wpisz w Cloud Shell:
sudo pip install --upgrade google-cloud-language
Wypróbuj
Na koniec przyjrzyjmy się przykładowym kodom interfejsu Cloud Natural Language API. Chcemy wykryć w tekście fragmenty. snippets.py zawiera kod, który to umożliwia. Skopiuj zawartość pliku snippets.py, utwórz w Cloud Shell nowy plik o nazwie natural_language.py i wklej do niego cały kod.natural_language.py Możesz to zrobić ręcznie w edytorze kodu Cloud Shell lub uruchomić to polecenie curl w Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/language/cloud-client/v1/snippets.py -o natural_language.py
Gdy to zrobisz, użyj interfejsu API, uruchamiając w Cloud Shell to polecenie:
python natural_language.py entities-text 'where did you leave my bike'
Interfejs API powinien identyfikować „rower” jako jednostkę. Elementy mogą być rzeczownikami własnymi (osoby publiczne, punkty orientacyjne itp.) lub rzeczownikami pospolitymi (restauracja, stadion itp.).
Co się dzieje?
Do funkcji natural_language.py przekazano 2 argumenty:
- entities-text wybiera funkcję
entities_text()do uruchomienia. - „gdzie zostawiłeś mój rower” to ciąg znaków, który ma zostać przeanalizowany pod kątem encji. Jest on przekazywany jako tekst do
entities_text().
Przyjrzyjmy się bliżej entities_text(). Zwróć uwagę na nowe wstawione komentarze.
def entities_text(text):
"""Detects entities in the text."""
# relevant imports from above
# from google.cloud import language
# from google.cloud.language import enums
# from google.cloud.language import types
# import six
# create LanguageServiceClient object
client = language.LanguageServiceClient()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# Instantiates a plain text document.
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects entities in the document. You can also analyze HTML with:
# document.type == enums.Document.Type.HTML
entities = client.analyze_entities(document).entities
# entity types from enums.Entity.Type
entity_type = ('UNKNOWN', 'PERSON', 'LOCATION', 'ORGANIZATION',
'EVENT', 'WORK_OF_ART', 'CONSUMER_GOOD', 'OTHER')
# print information for each entity found
for entity in entities:
print('=' * 20)
print(u'{:<16}: {}'.format('name', entity.name))
print(u'{:<16}: {}'.format('type', entity_type[entity.type]))
print(u'{:<16}: {}'.format('metadata', entity.metadata))
print(u'{:<16}: {}'.format('salience', entity.salience))
print(u'{:<16}: {}'.format('wikipedia_url',
entity.metadata.get('wikipedia_url', '-')))
7. Zintegrujmy je
Przypomnijmy sobie, co tworzysz.
Teraz połączmy wszystkie elementy. Utwórz plik solution.py, a następnie skopiuj i wklej do niego wartości detect_labels_uri(), transcribe_gcs(), translate_text() i entities_text() z poprzednich kroków.solution.py
Importowanie wyciągów
Odkomentuj instrukcje importu i przenieś je na początek. Pamiętaj, że importowane są zarówno plik speech.types, jak i plik language.types. Spowoduje to konflikt, więc usuńmy je i zmieńmy każde wystąpienie znaku types w transcribe_gcs() i entities_text() na odpowiednio speech.types i language.types. Powinny pozostać:
from google.cloud import vision
from google.cloud import speech
from google.cloud import translate
from google.cloud import language
from google.cloud.language import enums
import six
Wyniki zwrotu
Zamiast drukowania niech funkcje zwracają wyniki. Powinien pojawić się tekst podobny do tego:
# import statements
def detect_labels_uri(uri):
# code
# we only need the label descriptions
label_descriptions = []
for label in labels:
label_descriptions.append(label.description)
return label_descriptions
def transcribe_gcs(gcs_uri):
# code
# naive assumption that audio file is short
return response.results[0].alternatives[0].transcript
def translate_text(target, text):
# code
# only interested in translated text
return result['translatedText']
def entities_text(text):
# code
# we only need the entity names
entity_names = []
for entity in entities:
entity_names.append(entity.name)
return entity_names
Korzystanie z funkcji
Po wykonaniu tych wszystkich czynności możesz wywołać te funkcje. Śmiało, zrób to! Oto przykład:
def compare_audio_to_image(audio, image):
"""Checks whether a speech audio is relevant to an image."""
# speech audio -> text
transcription = transcribe_gcs(audio)
# text of any language -> english text
translation = translate_text('en', transcription)
# text -> entities
entities = entities_text(translation)
# image -> labels
labels = detect_labels_uri(image)
# naive check for whether entities intersect with labels
has_match = False
for entity in entities:
if entity in labels:
# print result for each match
print('The audio and image both contain: {}'.format(entity))
has_match = True
# print if there are no matches
if not has_match:
print('The audio and image do not appear to be related.')
Obsługa wielu języków
Wcześniej na stałe zakodowaliśmy język turecki w transcribe_gcs(). Zmieńmy to, aby język można było określać w compare_audio_to_image(). Wymagane zmiany:
def transcribe_gcs(language, gcs_uri):
...
config = speech.types.RecognitionConfig(language_code=language)
def compare_audio_to_image(language, audio, image):
transcription = transcribe_gcs(language, audio)
Wypróbuj
Ostateczny kod znajdziesz w pliku solution.py w tym repozytorium GitHub. Oto polecenie curl, które umożliwia pobranie tych informacji:
curl https://raw.githubusercontent.com/googlecodelabs/integrating-ml-apis/master/solution.py -O
Wersja w GitHubie zawiera moduł argparse, który umożliwia wykonanie w wierszu poleceń tych czynności:
python solution.py tr-TR gs://cloud-samples-data/ml-api-codelab/tr-ball.wav gs://cloud-samples-data/ml-api-codelab/football.jpg
W przypadku każdego znalezionego elementu kod powinien wyświetlać komunikat „The audio and image both contain: ” (Dźwięk i obraz zawierają:). W przykładzie powyżej będzie to „The audio and image both contain: ball” (Dźwięk i obraz zawierają: piłka).
Bonus: wypróbuj więcej
Oto więcej lokalizacji plików audio i obrazów, które możesz wypróbować.
8. Gratulacje!
Poznaliśmy i zintegrowaliśmy 4 interfejsy API systemów uczących się, aby określić, czy próbka mowy dotyczy podanego obrazu. To dopiero początek, ponieważ ten proces można jeszcze ulepszyć na wiele sposobów.
Omówione zagadnienia
- Wysyłanie żądań do interfejsu Cloud Vision API
- Wysyłanie żądań do interfejsu Cloud Speech-to-Text API
- Wysyłanie żądań do interfejsu Cloud Translation API
- Wysyłanie żądań do interfejsu Cloud Natural Language API
- Korzystanie ze wszystkich powyższych interfejsów API
Następne kroki
- Aby lepiej porównać słowa, zapoznaj się z word2vec.
- Zapoznaj się z bardziej szczegółowymi ćwiczeniami z programowania dotyczącymi Vision API, Speech-to-Text API, Translation API i Natural Language API.
- Spróbuj zastąpić Cloud Vision usługą Cloud Video Intelligence
- Syntezowanie dźwięku mowy za pomocą interfejsu Cloud Text-to-Speech API
- Dowiedz się, jak przesyłać obiekty do Cloud Storage