
1. Panoramica
Questo codelab ti offrirà un rapido tour di alcune API di machine learning. Utilizzerai:
- Cloud Vision per comprendere i contenuti di un'immagine
- Cloud Speech-to-Text per trascrivere l'audio in testo
- Cloud Translation per tradurre una stringa arbitraria in qualsiasi lingua supportata
- Cloud Natural Language per estrarre informazioni dal testo
Cosa creerai
Costruirai una pipeline che confronta una registrazione audio con un'immagine e ne determina la pertinenza reciproca. Ecco un'anteprima di come fare:
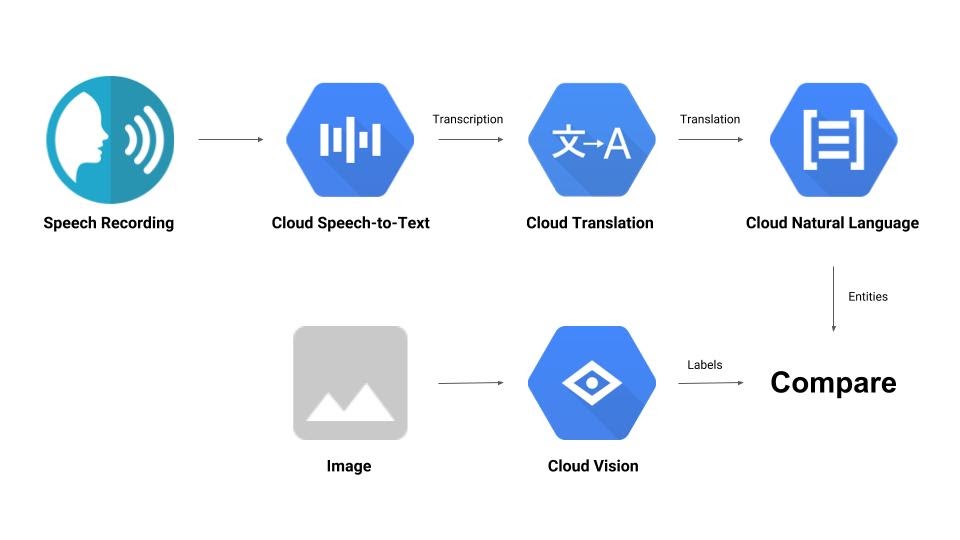
Obiettivi didattici
- Come utilizzare le API Vision, Speech-to-Text, Translation e Natural Language
- Dove trovare esempi di codice
Che cosa ti serve
2. Configurazione e requisiti
Configurazione dell'ambiente autonoma
- Accedi alla console Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai già un account Gmail o Google Workspace, devi crearne uno.

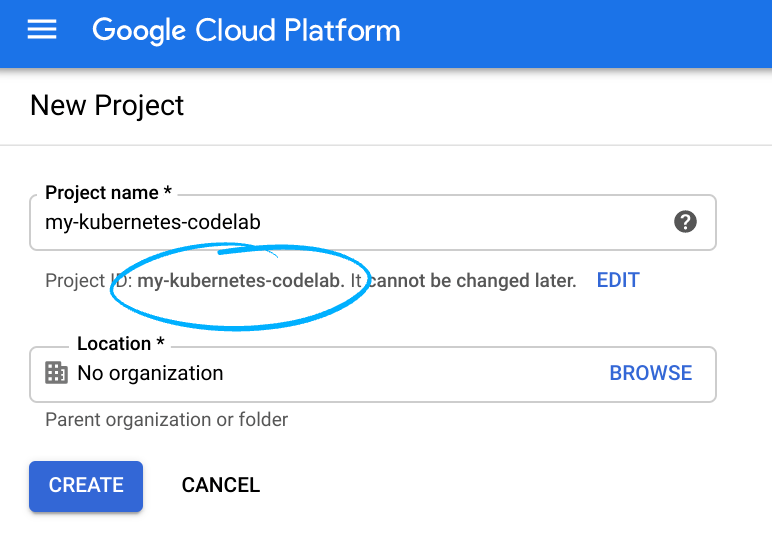
Ricorda l'ID progetto, un nome univoco per tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, mi dispiace). In questo codelab verrà chiamato PROJECT_ID.
- Successivamente, dovrai abilitare la fatturazione in Cloud Console per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costare molto, se non nulla. Assicurati di seguire le istruzioni nella sezione "Pulizia", che ti consiglia come arrestare le risorse in modo da non incorrere in addebiti oltre questo tutorial. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Abilita le API
Puoi fare clic su questo link per abilitare tutte le API necessarie. Dopo averlo fatto, puoi ignorare le istruzioni per la configurazione dell'autenticazione, che eseguiremo tra poco. In alternativa, puoi abilitare ogni API singolarmente. Per farlo, fai clic sull'icona del menu in alto a sinistra dello schermo.

Seleziona API e servizi dal menu a discesa e fai clic su Dashboard.
Fai clic su Abilita API e servizi.
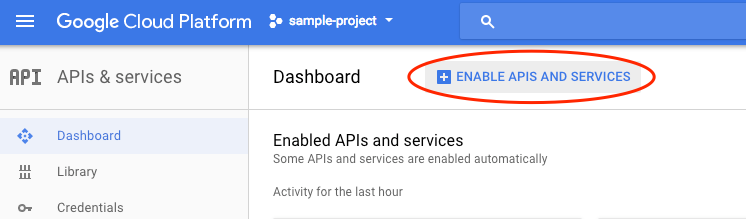
Cerca "visione" nella casella di ricerca. Fai clic su API Google Cloud Vision:

Fai clic su Abilita per abilitare l'API Cloud Vision:

Attendi qualche secondo affinché venga attivato. Una volta attivata, vedrai questo:
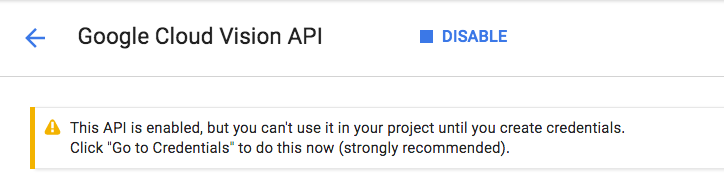
Ripeti la stessa procedura per attivare le API Cloud Speech, Cloud Translation e Cloud Natural Language.
Cloud Shell
Google Cloud Shell è un ambiente a riga di comando in esecuzione nel cloud. Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui avrai bisogno (gcloud, bq, git e altri) e mette a tua disposizione una home directory permanente di 5 GB. Utilizzeremo Cloud Shell per creare la nostra richiesta alle API di machine learning.
Per iniziare a utilizzare Cloud Shell, fai clic sull'icona "Attiva Google Cloud Shell"  nell'angolo in alto a destra della barra dell'intestazione.
nell'angolo in alto a destra della barra dell'intestazione.

All'interno di un nuovo frame nella parte inferiore della console si apre una sessione di Cloud Shell e viene visualizzato un prompt della riga di comando. Attendi che venga visualizzato il prompt user@project:~$
(Facoltativo) Editor di codice
A seconda della tua familiarità con la riga di comando, potresti voler fare clic sull'icona "Avvia editor di codice"  nell'angolo in alto a destra della barra di Cloud Shell.
nell'angolo in alto a destra della barra di Cloud Shell.

Account di servizio
Per l'autenticazione, devi avere un service account. Per crearne uno, sostituisci [NAME] con il nome desiderato del service account ed esegui il seguente comando in Cloud Shell:
gcloud iam service-accounts create [NAME]
Ora devi generare una chiave per utilizzare l'account di servizio. Sostituisci [FILE_NAME] con il nome che vuoi assegnare alla chiave, [NAME] con il nome del service account riportato sopra e [PROJECT_ID] con l'ID del tuo progetto. Il seguente comando creerà e scaricherà la chiave come [FILE_NAME].json:
gcloud iam service-accounts keys create [FILE_NAME].json --iam-account [NAME]@[PROJECT_ID].iam.gserviceaccount.com
Per utilizzare il service account, devi impostare la variabile GOOGLE_APPLICATION_CREDENTIALS sul percorso della chiave. Per farlo, esegui questo comando dopo aver sostituito [PATH_TO_FILE] e [FILE_NAME]:
export GOOGLE_APPLICATION_CREDENTIALS=[PATH_TO_FILE]/[FILE_NAME].json
3. Cloud Vision
Client Python
Avrai bisogno del client Python per Cloud Vision. Per installare, digita quanto segue in Cloud Shell:
pip install --upgrade google-cloud-vision --user
Proviamo
Diamo un'occhiata agli esempi di codice per l'API Cloud Vision. Ci interessa scoprire cosa contiene un'immagine specifica. detect.py sembra essere utile per questo, quindi prendiamolo. Un modo è copiare i contenuti di detect.py, creare un nuovo file in Cloud Shell chiamato vision.py e incollare tutto il codice in vision.py. Puoi farlo manualmente nell'editor di Cloud Shell o eseguire questo comando curl in Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/vision/cloud-client/detect/detect.py -o vision.py
Una volta fatto, utilizza l'API eseguendo il comando seguente in Cloud Shell:
python vision.py labels-uri gs://cloud-samples-data/ml-api-codelab/birds.jpg
Dovresti visualizzare un output relativo a uccelli e struzzi, poiché questa era l'immagine analizzata: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/birds.jpg
Che cosa succede?
Hai passato due argomenti a vision.py:
- labels-uri seleziona la funzione
detect_labels_uri()da eseguire - gs://cloud-samples-data/ml-api-codelab/birds.jpg è la posizione di un'immagine su Google Cloud Storage e viene passata come uri in
detect_labels_uri()
Diamo un'occhiata più da vicino a detect_labels_uri(). Prendi nota dei commenti aggiuntivi inseriti.
def detect_labels_uri(uri):
"""Detects labels in the file located in Google Cloud Storage or on the
Web."""
# relevant import from above
# from google.cloud import vision
# create ImageAnnotatorClient object
client = vision.ImageAnnotatorClient()
# create Image object
image = vision.types.Image()
# specify location of image
image.source.image_uri = uri
# get label_detection response by passing image to client
response = client.label_detection(image=image)
# get label_annotations portion of response
labels = response.label_annotations
print('Labels:')
for label in labels:
# print the label descriptions
print(label.description)
4. Cloud Speech-to-Text
Client Python
Avrai bisogno del client Python per Cloud Speech-to-Text. Per installare, digita quanto segue in Cloud Shell:
sudo pip install --upgrade google-cloud-speech
Proviamo
Passiamo agli esempi di codice per Cloud Speech-to-Text. Siamo interessati alla trascrizione dell'audio del parlato. transcribe.py sembra un buon punto di partenza, quindi usiamolo. Copia i contenuti di transcribe.py, crea un nuovo file in Cloud Shell chiamato speech2text.py e incolla tutto il codice in speech2text.py. Puoi farlo manualmente nell'editor di Cloud Shell o eseguire questo comando curl in Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/speech/cloud-client/transcribe.py -o speech2text.py
Una volta fatto, utilizza l'API eseguendo il comando seguente in Cloud Shell:
python speech2text.py gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Dovrebbero essere presenti errori che segnalano la codifica e la frequenza di campionamento errate. Non preoccuparti, vai su transcribe_gcs()nel codice ed elimina le impostazioni encoding e sampe_hertz_rate da RecognitionConfig(). Già che ci sei, modifica il codice della lingua in "tr-TR", poiché tr-ostrich.wav è una registrazione vocale in turco.
config = types.RecognitionConfig(language_code='tr-TR')
Ora esegui di nuovo speech2text.py. L'output dovrebbe essere un testo in turco, poiché questo era l'audio analizzato: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Che cosa sta succedendo?
Hai superato gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav, la posizione di un file audio su Google Cloud Storage, a speech2text.py, che viene poi passato come gcs_uri in transcribe_uri()
Diamo un'occhiata più da vicino al nostro transcribe_uri() modificato.
def transcribe_gcs(gcs_uri):
"""Transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
# enums no longer used
# from google.cloud.speech import enums
from google.cloud.speech import types
# create ImageAnnotatorClient object
client = speech.SpeechClient()
# specify location of speech
audio = types.RecognitionAudio(uri=gcs_uri)
# set language to Turkish
# removed encoding and sample_rate_hertz
config = types.RecognitionConfig(language_code='tr-TR')
# get response by passing config and audio settings to client
response = client.recognize(config, audio)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
# get the transcript of the first alternative
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
5. Cloud Translation
Client Python
Avrai bisogno del client Python per Cloud Translation. Per installare, digita quanto segue in Cloud Shell:
sudo pip install --upgrade google-cloud-translate
Proviamo
Ora diamo un'occhiata agli esempi di codice per Cloud Translation. Ai fini di questo codelab, vogliamo tradurre il testo in inglese. snippets.py sembra quello che vogliamo. Copia i contenuti di snippets.py, crea un nuovo file in Cloud Shell denominato translate.py e incolla tutto il codice in translate.py. Puoi farlo manualmente nell'editor di Cloud Shell o eseguire questo comando curl in Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/translate/cloud-client/snippets.py -o translate.py
Una volta fatto, utilizza l'API eseguendo il comando seguente in Cloud Shell:
python translate.py translate-text en '你有沒有帶外套'
La traduzione dovrebbe essere "Hai una giacca?".
Che cosa sta succedendo?
Hai passato tre argomenti a translate.py:
- translate-text seleziona la funzione
translate_text()da eseguire - en viene passato come target in
translate_text()e serve a specificare la lingua in cui eseguire la traduzione - '你有沒有帶外套' è la stringa da tradurre e viene passata come text in
translate_text()
Diamo un'occhiata più da vicino a translate_text(). Prendi nota dei commenti aggiunti.
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
# relevant imports from above
# from google.cloud import translate
# import six
# create Client object
translate_client = translate.Client()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# get translation result by passing text and target language to client
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
# print original text, translated text and detected original language
print(u'Text: {}'.format(result['input']))
print(u'Translation: {}'.format(result['translatedText']))
print(u'Detected source language: {}'.format(
result['detectedSourceLanguage']))
6. Cloud Natural Language
Client Python
Avrai bisogno del client Python per Cloud Natural Language. Per installare, digita quanto segue in Cloud Shell:
sudo pip install --upgrade google-cloud-language
Proviamo
Infine, esaminiamo gli esempi di codice per l'API Cloud Natural Language. Vogliamo rilevare le entità nel testo. snippets.py sembra contenere codice che lo fa. Copia i contenuti di snippets.py, crea un nuovo file in Cloud Shell denominato natural_language.py e incolla tutto il codice in natural_language.py. Puoi farlo manualmente nell'editor di Cloud Shell o eseguire questo comando curl in Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/language/cloud-client/v1/snippets.py -o natural_language.py
Una volta fatto, utilizza l'API eseguendo il comando seguente in Cloud Shell:
python natural_language.py entities-text 'where did you leave my bike'
L'API deve identificare "bicicletta" come entità. Le entità possono essere nomi propri (personaggi pubblici, punti di riferimento e così via) o nomi comuni (ristorante, stadio e così via).
Che cosa sta succedendo?
Hai passato due argomenti a natural_language.py:
- entities-text seleziona la funzione
entities_text()da eseguire - "where did you leave my bike" è la stringa da analizzare per le entità e viene passata come text in
entities_text()
Diamo un'occhiata più da vicino a entities_text(). Prendi nota dei nuovi commenti inseriti.
def entities_text(text):
"""Detects entities in the text."""
# relevant imports from above
# from google.cloud import language
# from google.cloud.language import enums
# from google.cloud.language import types
# import six
# create LanguageServiceClient object
client = language.LanguageServiceClient()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# Instantiates a plain text document.
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects entities in the document. You can also analyze HTML with:
# document.type == enums.Document.Type.HTML
entities = client.analyze_entities(document).entities
# entity types from enums.Entity.Type
entity_type = ('UNKNOWN', 'PERSON', 'LOCATION', 'ORGANIZATION',
'EVENT', 'WORK_OF_ART', 'CONSUMER_GOOD', 'OTHER')
# print information for each entity found
for entity in entities:
print('=' * 20)
print(u'{:<16}: {}'.format('name', entity.name))
print(u'{:<16}: {}'.format('type', entity_type[entity.type]))
print(u'{:<16}: {}'.format('metadata', entity.metadata))
print(u'{:<16}: {}'.format('salience', entity.salience))
print(u'{:<16}: {}'.format('wikipedia_url',
entity.metadata.get('wikipedia_url', '-')))
7. Integriamoli
Ricordiamo cosa stai creando.
Ora mettiamo tutto insieme. Crea un file solution.py; copia e incolla detect_labels_uri(), transcribe_gcs(), translate_text() e entities_text() dai passaggi precedenti in solution.py.
Importare gli estratti conto
Rimuovi il commento e sposta le istruzioni di importazione in alto. Tieni presente che vengono importati sia speech.types che language.types. Ciò causerà un conflitto, quindi rimuoviamoli e modifichiamo ogni singola occorrenza di types in transcribe_gcs() e entities_text() in speech.types e language.types rispettivamente. Dovresti avere:
from google.cloud import vision
from google.cloud import speech
from google.cloud import translate
from google.cloud import language
from google.cloud.language import enums
import six
Risultati restituiti
Anziché stampare, fai in modo che le funzioni restituiscano i risultati. Dovresti visualizzare un risultato simile a questo:
# import statements
def detect_labels_uri(uri):
# code
# we only need the label descriptions
label_descriptions = []
for label in labels:
label_descriptions.append(label.description)
return label_descriptions
def transcribe_gcs(gcs_uri):
# code
# naive assumption that audio file is short
return response.results[0].alternatives[0].transcript
def translate_text(target, text):
# code
# only interested in translated text
return result['translatedText']
def entities_text(text):
# code
# we only need the entity names
entity_names = []
for entity in entities:
entity_names.append(entity.name)
return entity_names
Utilizzare le funzioni
Dopo tutto questo duro lavoro, puoi chiamare queste funzioni. Vai avanti, fallo! Ecco un esempio:
def compare_audio_to_image(audio, image):
"""Checks whether a speech audio is relevant to an image."""
# speech audio -> text
transcription = transcribe_gcs(audio)
# text of any language -> english text
translation = translate_text('en', transcription)
# text -> entities
entities = entities_text(translation)
# image -> labels
labels = detect_labels_uri(image)
# naive check for whether entities intersect with labels
has_match = False
for entity in entities:
if entity in labels:
# print result for each match
print('The audio and image both contain: {}'.format(entity))
has_match = True
# print if there are no matches
if not has_match:
print('The audio and image do not appear to be related.')
Supportare più lingue
In precedenza abbiamo codificato in modo permanente il turco in transcribe_gcs(). Modifichiamo questa impostazione in modo che la lingua sia specificabile da compare_audio_to_image(). Ecco le modifiche necessarie:
def transcribe_gcs(language, gcs_uri):
...
config = speech.types.RecognitionConfig(language_code=language)
def compare_audio_to_image(language, audio, image):
transcription = transcribe_gcs(language, audio)
Prova
Il codice finale è disponibile in solution.py di questo repository GitHub. Ecco un comando curl per recuperare queste informazioni:
curl https://raw.githubusercontent.com/googlecodelabs/integrating-ml-apis/master/solution.py -O
La versione su GitHub contiene argparse, che consente quanto segue dalla riga di comando:
python solution.py tr-TR gs://cloud-samples-data/ml-api-codelab/tr-ball.wav gs://cloud-samples-data/ml-api-codelab/football.jpg
Per ogni elemento trovato, il codice dovrebbe restituire "The audio and image both contain: ". Nell'esempio precedente, sarebbe "The audio and image both contain: ball".
Bonus: prova altre funzionalità
Ecco altre posizioni di file audio e immagine da provare.
8. Complimenti!
Hai esplorato e integrato quattro API di machine learning per determinare se un campione vocale parla dell'immagine fornita. Questo è solo l'inizio, perché ci sono molti altri modi per migliorare questa pipeline.
Argomenti trattati
- Invio di richieste all'API Cloud Vision
- Effettuare richieste all'API Cloud Speech-to-Text
- Effettuare richieste all'API Cloud Translation
- Invio di richieste all'API Cloud Natural Language
- Utilizzo combinato di tutte le API precedenti
Passaggi successivi
- Per un confronto migliore delle parole, dai un'occhiata a word2vec.
- Consulta i codelab più approfonditi su API Vision, API Speech-to-Text, API Translation e API Natural Language.
- Prova a sostituire Cloud Vision con Cloud Video Intelligence
- Sintetizza l'audio del parlato con l'API Cloud Text-to-Speech
- Scopri come caricare oggetti in Cloud Storage.