
1. खास जानकारी
इस कोडलैब में, आपको मशीन लर्निंग के कुछ एपीआई के बारे में खास जानकारी मिलेगी. इनका इस्तेमाल किया जाएगा:
- इमेज के कॉन्टेंट को समझने के लिए Cloud Vision
- ऑडियो को टेक्स्ट में बदलने के लिए, Cloud Speech-to-Text
- Cloud Translation की मदद से, किसी भी स्ट्रिंग का अनुवाद, सुविधा के साथ काम करने वाली किसी भी भाषा में किया जा सकता है
- टेक्स्ट से जानकारी निकालने के लिए, Cloud Natural Language का इस्तेमाल किया जाता है
आपको क्या बनाने को मिलेगा
आपको एक ऐसी पाइपलाइन बनानी होगी जो ऑडियो रिकॉर्डिंग की तुलना इमेज से करे और यह तय करे कि दोनों एक-दूसरे से कितने मिलते-जुलते हैं. यहां बताया गया है कि आपको यह काम कैसे करना है:
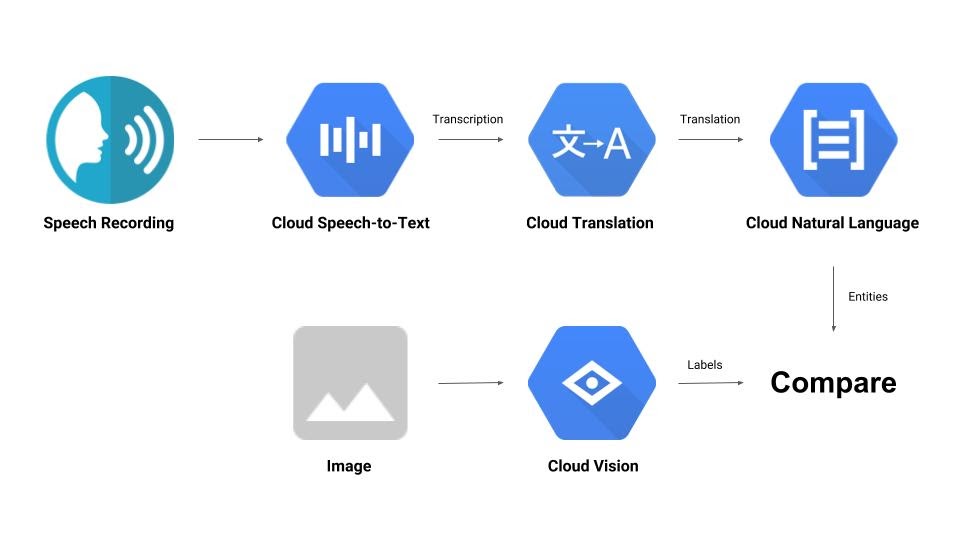
आपको क्या सीखने को मिलेगा
- Vision, Speech-to-Text, Translation, और Natural Language API का इस्तेमाल करने का तरीका
- कोड के सैंपल कहां मिलेंगे
आपको किन चीज़ों की ज़रूरत होगी
2. सेटअप और ज़रूरी शर्तें
अपने हिसाब से एनवायरमेंट सेट अप करना
- Cloud Console में साइन इन करें. इसके बाद, नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें. अगर आपके पास पहले से Gmail या Google Workspace खाता नहीं है, तो आपको एक खाता बनाना होगा.

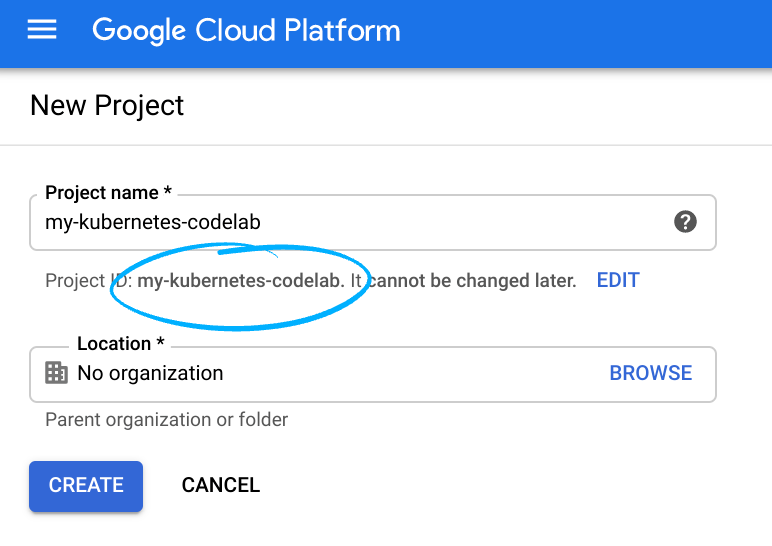
प्रोजेक्ट आईडी याद रखें. यह सभी Google Cloud प्रोजेक्ट के लिए एक यूनीक नाम होता है. ऊपर दिया गया नाम पहले ही इस्तेमाल किया जा चुका है. इसलिए, यह आपके लिए काम नहीं करेगा. माफ़ करें! इस कोड लैब में इसे बाद में PROJECT_ID के तौर पर दिखाया जाएगा.
- इसके बाद, Google Cloud के संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में ज़्यादा खर्च नहीं आएगा. "साफ़ करना" सेक्शन में दिए गए निर्देशों का पालन करना न भूलें. इसमें आपको संसाधनों को बंद करने का तरीका बताया गया है, ताकि इस ट्यूटोरियल के बाद आपको बिलिंग से जुड़ी कोई समस्या न हो. Google Cloud के नए उपयोगकर्ता, 300 डॉलर के मुफ़्त में आज़माने वाले प्रोग्राम में शामिल हो सकते हैं.
एपीआई चालू करना
सभी ज़रूरी एपीआई चालू करने के लिए, इस लिंक पर क्लिक करें. ऐसा करने के बाद, पुष्टि करने की प्रोसेस सेट अप करने के निर्देशों को अनदेखा करें. हम इसे कुछ ही समय में सेट अप कर देंगे. इसके अलावा, हर एपीआई को अलग-अलग भी चालू किया जा सकता है. इसके लिए, स्क्रीन पर सबसे ऊपर बाईं ओर मौजूद मेन्यू आइकॉन पर क्लिक करें.

ड्रॉप-डाउन मेन्यू से एपीआई और सेवाएं चुनें. इसके बाद, डैशबोर्ड पर क्लिक करें
एपीआई और सेवाएं चालू करें पर क्लिक करें.
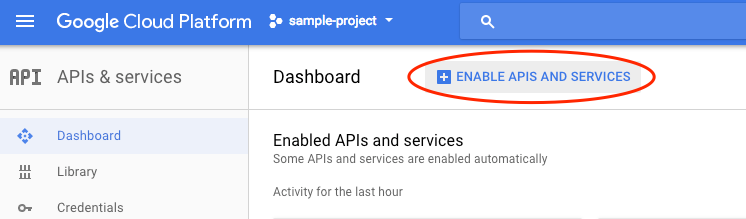
इसके बाद, खोज बॉक्स में "vision" खोजें. Google Cloud Vision API पर क्लिक करें:

Cloud Vision API को चालू करने के लिए, चालू करें पर क्लिक करें:

इसे चालू होने में कुछ सेकंड लगेंगे. इस सुविधा के चालू होने पर, आपको यह दिखेगा:
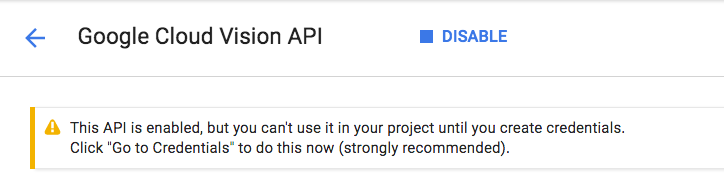
Cloud Speech, Cloud Translation, और Cloud Natural Language API चालू करने के लिए, यही प्रोसेस दोहराएं.
Cloud Shell
Google Cloud Shell, क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है. Debian पर आधारित इस वर्चुअल मशीन में, आपको ज़रूरी सभी डेवलपमेंट टूल (gcloud, bq, git वगैरह) मिलेंगे. साथ ही, इसमें 5 जीबी की होम डायरेक्ट्री भी मिलती है. हम मशीन लर्निंग एपीआई के लिए अनुरोध बनाने के लिए, Cloud Shell का इस्तेमाल करेंगे.
Cloud Shell का इस्तेमाल शुरू करने के लिए, हेडर बार में सबसे ऊपर दाएं कोने में मौजूद, "Google Cloud Shell चालू करें"  आइकॉन पर क्लिक करें
आइकॉन पर क्लिक करें

Cloud Shell सेशन, कंसोल में सबसे नीचे मौजूद नए फ़्रेम में खुलता है. इसमें कमांड-लाइन प्रॉम्प्ट दिखता है. जब तक user@project:~$ प्रॉम्प्ट न दिखे, तब तक इंतज़ार करें.
ज़रूरी नहीं: कोड एडिटर
अगर आपको कमांड लाइन का इस्तेमाल करना आसान लगता है, तो Cloud Shell बार के सबसे ऊपर दाएं कोने में मौजूद "कोड एडिटर लॉन्च करें"  आइकॉन पर क्लिक करें
आइकॉन पर क्लिक करें

सेवा खाता
पुष्टि करने के लिए, आपको सेवा खाते की ज़रूरत होगी. सेवा खाता बनाने के लिए, [NAME] को सेवा खाते के नाम से बदलें. इसके बाद, Cloud Shell में यह कमांड चलाएं:
gcloud iam service-accounts create [NAME]
अब आपको उस सेवा खाते का इस्तेमाल करने के लिए, एक कुंजी जनरेट करनी होगी. [FILE_NAME] की जगह कुंजी का मनचाहा नाम, [NAME] की जगह ऊपर दिया गया सेवा खाते का नाम, और [PROJECT_ID] की जगह अपने प्रोजेक्ट का आईडी डालें. नीचे दिए गए निर्देश से, [FILE_NAME].json के तौर पर कुंजी बनाई और डाउनलोड की जाएगी:
gcloud iam service-accounts keys create [FILE_NAME].json --iam-account [NAME]@[PROJECT_ID].iam.gserviceaccount.com
सेवा खाते का इस्तेमाल करने के लिए, आपको GOOGLE_APPLICATION_CREDENTIALS वैरिएबल को कुंजी के पाथ पर सेट करना होगा. इसके लिए, [PATH_TO_FILE] और [FILE_NAME] को बदलने के बाद, यह कमांड चलाएं:
export GOOGLE_APPLICATION_CREDENTIALS=[PATH_TO_FILE]/[FILE_NAME].json
3. Cloud विज़न
Python क्लाइंट
आपको Cloud Vision के लिए Python क्लाइंट की ज़रूरत होगी. इसे इंस्टॉल करने के लिए, Cloud Shell में यह टाइप करें:
pip install --upgrade google-cloud-vision --user
इसे आज़माएं
आइए, Cloud Vision API के लिए कोड सैंपल देखें. हमें यह जानना है कि दी गई इमेज में क्या है. detect.py इस काम के लिए मददगार हो सकता है. इसलिए, इसे इस्तेमाल करते हैं. इसके लिए, detect.py के कॉन्टेंट को कॉपी करें. इसके बाद, Cloud Shell में vision.py नाम की एक नई फ़ाइल बनाएं और पूरे कोड को vision.py में चिपकाएं. Cloud Shell कोड एडिटर में जाकर, इसे मैन्युअल तरीके से किया जा सकता है. इसके अलावा, Cloud Shell में यह कर्ल कमांड चलाकर भी इसे किया जा सकता है:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/vision/cloud-client/detect/detect.py -o vision.py
इसके बाद, Cloud Shell में यह कमांड चलाकर एपीआई का इस्तेमाल करें:
python vision.py labels-uri gs://cloud-samples-data/ml-api-codelab/birds.jpg
आपको पक्षियों और शुतुरमुर्गों के बारे में आउटपुट दिखेगा, क्योंकि इस इमेज का विश्लेषण किया गया था: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/birds.jpg
आपको कम्यूनिटी दिशा-निर्देशों और नीतियों का उल्लंघन करने वाला किस तरह का कॉन्टेंट मिला?
आपने vision.py में दो आर्ग्युमेंट पास किए हैं:
- labels-uri,
detect_labels_uri()फ़ंक्शन को चलाने के लिए चुनता है - gs://cloud-samples-data/ml-api-codelab/birds.jpg, Google Cloud Storage पर मौजूद किसी इमेज की जगह है. इसे
detect_labels_uri()में uri के तौर पर पास किया जाता है
आइए, detect_labels_uri() के बारे में ज़्यादा जानें. जोड़ी गई अन्य टिप्पणियों पर ध्यान दें.
def detect_labels_uri(uri):
"""Detects labels in the file located in Google Cloud Storage or on the
Web."""
# relevant import from above
# from google.cloud import vision
# create ImageAnnotatorClient object
client = vision.ImageAnnotatorClient()
# create Image object
image = vision.types.Image()
# specify location of image
image.source.image_uri = uri
# get label_detection response by passing image to client
response = client.label_detection(image=image)
# get label_annotations portion of response
labels = response.label_annotations
print('Labels:')
for label in labels:
# print the label descriptions
print(label.description)
4. क्लाउड स्पीच-टू-टेक्स्ट
Python क्लाइंट
आपको Cloud Speech-to-Text के लिए Python क्लाइंट की ज़रूरत होगी. इसे इंस्टॉल करने के लिए, Cloud Shell में यह टाइप करें:
sudo pip install --upgrade google-cloud-speech
इसे आज़माएं
आइए, Cloud Speech-to-Text के लिए कोड के सैंपल पर जाएं. हमें ऑडियो में मौजूद आवाज़ को टेक्स्ट में बदलने में दिलचस्पी है. transcribe.py से शुरुआत करना सही रहेगा. इसलिए, इसका इस्तेमाल करते हैं. transcribe.py के कॉन्टेंट को कॉपी करें. Cloud Shell में speech2text.py नाम की एक नई फ़ाइल बनाएं और पूरे कोड को speech2text.py में चिपकाएं. Cloud Shell कोड एडिटर में जाकर, इसे मैन्युअल तरीके से किया जा सकता है. इसके अलावा, Cloud Shell में यह कर्ल कमांड चलाकर भी इसे किया जा सकता है:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/speech/cloud-client/transcribe.py -o speech2text.py
इसके बाद, Cloud Shell में यह कमांड चलाकर एपीआई का इस्तेमाल करें:
python speech2text.py gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav
इसमें गलत एन्कोडिंग और सैंपल हर्ट्ज़ रेट के बारे में गड़बड़ियां होनी चाहिए. चिंता न करें, कोड में transcribe_gcs() पर जाएं और RecognitionConfig() से encoding और sampe_hertz_rate सेटिंग मिटाएं. इसके साथ ही, भाषा कोड को ‘tr-TR' में बदलें, क्योंकि tr-ostrich.wav तुर्क भाषा में रिकॉर्ड की गई स्पीच है.
config = types.RecognitionConfig(language_code='tr-TR')
अब speech2text.py को फिर से चलाएं. आउटपुट में कुछ तुर्की टेक्स्ट होना चाहिए, क्योंकि यह ऑडियो विश्लेषण किया गया था: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/tr-ostrich.wav
क्या हो रहा है?
आपने speech2text.py को Google Cloud Storage पर मौजूद ऑडियो फ़ाइल की जगह gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav पास की है. इसके बाद, इसे transcribe_uri() में gcs_uri के तौर पर पास किया जाता है
आइए, हम अपने बदले गए transcribe_uri() पर एक नज़र डालें.
def transcribe_gcs(gcs_uri):
"""Transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
# enums no longer used
# from google.cloud.speech import enums
from google.cloud.speech import types
# create ImageAnnotatorClient object
client = speech.SpeechClient()
# specify location of speech
audio = types.RecognitionAudio(uri=gcs_uri)
# set language to Turkish
# removed encoding and sample_rate_hertz
config = types.RecognitionConfig(language_code='tr-TR')
# get response by passing config and audio settings to client
response = client.recognize(config, audio)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
# get the transcript of the first alternative
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
5. Cloud Translation
Python क्लाइंट
आपको Cloud Translation के लिए Python क्लाइंट की ज़रूरत होगी. इसे इंस्टॉल करने के लिए, Cloud Shell में यह टाइप करें:
sudo pip install --upgrade google-cloud-translate
इसे आज़माएं
अब Cloud Translation के लिए कोड के सैंपल देखें. इस कोडलैब के लिए, हमें टेक्स्ट का अंग्रेज़ी में अनुवाद करना है. snippets.py, हमारी ज़रूरत के हिसाब से है. snippets.py के कॉन्टेंट को कॉपी करें. Cloud Shell में translate.py नाम की एक नई फ़ाइल बनाएं और पूरे कोड को translate.py में चिपकाएं. Cloud Shell कोड एडिटर में जाकर, इसे मैन्युअल तरीके से किया जा सकता है. इसके अलावा, Cloud Shell में यह कर्ल कमांड चलाकर भी इसे किया जा सकता है:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/translate/cloud-client/snippets.py -o translate.py
इसके बाद, Cloud Shell में यह कमांड चलाकर एपीआई का इस्तेमाल करें:
python translate.py translate-text en '你有沒有帶外套'
अनुवाद "क्या आपके पास जैकेट है?" होना चाहिए.
क्या हो रहा है?
आपने translate.py में तीन आर्ग्युमेंट पास किए हैं:
- translate-text,
translate_text()फ़ंक्शन को चलाने के लिए चुनता है - en को
translate_text()में target के तौर पर पास किया जाता है. इससे यह तय किया जाता है कि किस भाषा में अनुवाद करना है - ‘你有沒有帶外套' वह स्ट्रिंग है जिसका अनुवाद करना है. इसे
translate_text()में text के तौर पर पास किया जाता है
आइए, translate_text() के बारे में ज़्यादा जानें. जोड़ी गई टिप्पणियों को नोट करें.
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
# relevant imports from above
# from google.cloud import translate
# import six
# create Client object
translate_client = translate.Client()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# get translation result by passing text and target language to client
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
# print original text, translated text and detected original language
print(u'Text: {}'.format(result['input']))
print(u'Translation: {}'.format(result['translatedText']))
print(u'Detected source language: {}'.format(
result['detectedSourceLanguage']))
6. Cloud Natural Language
Python क्लाइंट
आपको Cloud Natural Language के लिए Python क्लाइंट की ज़रूरत होगी. इसे इंस्टॉल करने के लिए, Cloud Shell में यह टाइप करें:
sudo pip install --upgrade google-cloud-language
इसे आज़माएं
आखिर में, आइए Cloud Natural Language API के लिए कोड सैंपल देखते हैं. हमें टेक्स्ट में मौजूद इकाइयों का पता लगाना है. snippets.py में ऐसा कोड मौजूद है. snippets.py के कॉन्टेंट को कॉपी करें. Cloud Shell में natural_language.py नाम की एक नई फ़ाइल बनाएं और पूरे कोड को natural_language.py में चिपकाएं. Cloud Shell कोड एडिटर में जाकर, इसे मैन्युअल तरीके से किया जा सकता है. इसके अलावा, Cloud Shell में यह कर्ल कमांड चलाकर भी इसे किया जा सकता है:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/language/cloud-client/v1/snippets.py -o natural_language.py
इसके बाद, Cloud Shell में यह कमांड चलाकर एपीआई का इस्तेमाल करें:
python natural_language.py entities-text 'where did you leave my bike'
एपीआई को "बाइक" को एक इकाई के तौर पर पहचानना चाहिए. इकाइयां, प्रॉपर नाउन (मशहूर हस्तियां, लैंडमार्क वगैरह) या कॉमन नाउन (रेस्टोरेंट, स्टेडियम वगैरह) हो सकती हैं.
क्या हो रहा है?
आपने natural_language.py में दो आर्ग्युमेंट पास किए हैं:
- entities-text,
entities_text()फ़ंक्शन को चलाने के लिए चुनता है - ‘where did you leave my bike' वह स्ट्रिंग है जिसका विश्लेषण इकाइयों के लिए किया जाना है. इसे
entities_text()में text के तौर पर पास किया जाता है
आइए, entities_text() के बारे में ज़्यादा जानें. ध्यान दें कि नई टिप्पणियां जोड़ी गई हैं.
def entities_text(text):
"""Detects entities in the text."""
# relevant imports from above
# from google.cloud import language
# from google.cloud.language import enums
# from google.cloud.language import types
# import six
# create LanguageServiceClient object
client = language.LanguageServiceClient()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# Instantiates a plain text document.
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects entities in the document. You can also analyze HTML with:
# document.type == enums.Document.Type.HTML
entities = client.analyze_entities(document).entities
# entity types from enums.Entity.Type
entity_type = ('UNKNOWN', 'PERSON', 'LOCATION', 'ORGANIZATION',
'EVENT', 'WORK_OF_ART', 'CONSUMER_GOOD', 'OTHER')
# print information for each entity found
for entity in entities:
print('=' * 20)
print(u'{:<16}: {}'.format('name', entity.name))
print(u'{:<16}: {}'.format('type', entity_type[entity.type]))
print(u'{:<16}: {}'.format('metadata', entity.metadata))
print(u'{:<16}: {}'.format('salience', entity.salience))
print(u'{:<16}: {}'.format('wikipedia_url',
entity.metadata.get('wikipedia_url', '-')))
7. इन्हें इंटिग्रेट करना
आइए, हम याद करते हैं कि आपको क्या बनाना है.
अब हम सभी चीज़ों को एक साथ जोड़ते हैं. एक solution.py फ़ाइल बनाएं. पिछले चरणों में दिए गए detect_labels_uri(), transcribe_gcs(), translate_text(), और entities_text() को कॉपी करके solution.py में चिपकाएं.
इंपोर्ट स्टेटमेंट
इंपोर्ट स्टेटमेंट से टिप्पणी हटाएं और उन्हें सबसे ऊपर ले जाएं. ध्यान दें कि speech.types और language.types, दोनों को इंपोर्ट किया जा रहा है. इससे टकराव हो सकता है. इसलिए, इन्हें हटा देते हैं. साथ ही, types में मौजूद हर transcribe_gcs() और entities_text() को बदलकर, speech.types और language.types कर देते हैं. आपके पास ये होने चाहिए:
from google.cloud import vision
from google.cloud import speech
from google.cloud import translate
from google.cloud import language
from google.cloud.language import enums
import six
सामान लौटाने के नतीजे
प्रिंट करने के बजाय, फ़ंक्शन से नतीजे पाएं. आपके पास कुछ ऐसा होना चाहिए:
# import statements
def detect_labels_uri(uri):
# code
# we only need the label descriptions
label_descriptions = []
for label in labels:
label_descriptions.append(label.description)
return label_descriptions
def transcribe_gcs(gcs_uri):
# code
# naive assumption that audio file is short
return response.results[0].alternatives[0].transcript
def translate_text(target, text):
# code
# only interested in translated text
return result['translatedText']
def entities_text(text):
# code
# we only need the entity names
entity_names = []
for entity in entities:
entity_names.append(entity.name)
return entity_names
फ़ंक्शन इस्तेमाल करना
इतनी मेहनत करने के बाद, आपको उन फ़ंक्शन को कॉल करने का मौका मिलता है. आगे बढ़ें और इसे करें! यहां एक उदाहरण दिया गया है:
def compare_audio_to_image(audio, image):
"""Checks whether a speech audio is relevant to an image."""
# speech audio -> text
transcription = transcribe_gcs(audio)
# text of any language -> english text
translation = translate_text('en', transcription)
# text -> entities
entities = entities_text(translation)
# image -> labels
labels = detect_labels_uri(image)
# naive check for whether entities intersect with labels
has_match = False
for entity in entities:
if entity in labels:
# print result for each match
print('The audio and image both contain: {}'.format(entity))
has_match = True
# print if there are no matches
if not has_match:
print('The audio and image do not appear to be related.')
कई भाषाओं में उपलब्ध है
हमने पहले transcribe_gcs() में तुर्किये को हार्डकोड किया था. आइए, इसे बदलते हैं, ताकि भाषा को compare_audio_to_image() से तय किया जा सके. यहां ज़रूरी बदलाव दिए गए हैं:
def transcribe_gcs(language, gcs_uri):
...
config = speech.types.RecognitionConfig(language_code=language)
def compare_audio_to_image(language, audio, image):
transcription = transcribe_gcs(language, audio)
इसे आज़माएँ
फ़ाइनल कोड, इस GitHub रिपॉज़िटरी के solution.py में देखा जा सकता है. यहां उस जानकारी को पाने के लिए कर्ल कमांड दी गई है:
curl https://raw.githubusercontent.com/googlecodelabs/integrating-ml-apis/master/solution.py -O
GitHub पर मौजूद वर्शन में argparse शामिल है. इससे कमांड लाइन से ये काम किए जा सकते हैं:
python solution.py tr-TR gs://cloud-samples-data/ml-api-codelab/tr-ball.wav gs://cloud-samples-data/ml-api-codelab/football.jpg
मिली हर आइटम के लिए, कोड को "ऑडियो और इमेज, दोनों में यह मौजूद है: " आउटपुट करना चाहिए. ऊपर दिए गए उदाहरण में, यह "ऑडियो और इमेज, दोनों में यह मौजूद है: गेंद" होगा.
बोनस: और कोशिश करें
यहाँ ऑडियो और इमेज फ़ाइलों की कुछ और लोकेशन दी गई हैं.
8. बधाई हो!
आपने चार मशीन लर्निंग एपीआई का इस्तेमाल किया है और उन्हें इंटिग्रेट किया है. इससे यह पता लगाया जा सकता है कि स्पीच सैंपल में दी गई इमेज के बारे में बात की जा रही है या नहीं. यह तो बस शुरुआत है. इस पाइपलाइन को बेहतर बनाने के लिए, कई और तरीके हैं!
हमने क्या-क्या बताया
- Cloud Vision API को अनुरोध भेजना
- Cloud Speech-to-Text API को अनुरोध करना
- Cloud Translation API से अनुरोध करना
- Cloud Natural Language API से अनुरोध करना
- ऊपर दिए गए सभी एपीआई का एक साथ इस्तेमाल करना
अगले चरण
- शब्दों की बेहतर तुलना करने के लिए, word2vec देखें
- Vision API, Speech-to-Text API, Translation API और Natural Language API के बारे में ज़्यादा जानकारी देने वाले कोडलैब देखें
- Cloud Vision की जगह Cloud Video intelligence का इस्तेमाल करके देखें
- Cloud Text-to-Speech API की मदद से, टेक्स्ट को ऑडियो में बदलना
- Cloud Storage में ऑब्जेक्ट अपलोड करने का तरीका जानें