
1. Présentation
Cet atelier de programmation vous présentera rapidement quelques API de machine learning. Vous utiliserez :
- Cloud Vision pour comprendre le contenu d'une image
- Cloud Speech-to-Text pour transcrire des pistes audio en texte
- Cloud Translation pour traduire une chaîne arbitraire dans n'importe quelle langue compatible
- Cloud Natural Language pour extraire des informations à partir de texte
Objectifs de l'atelier
Vous allez créer un pipeline qui compare un enregistrement audio à une image et détermine leur pertinence mutuelle. Voici un aperçu de la façon dont vous allez procéder :
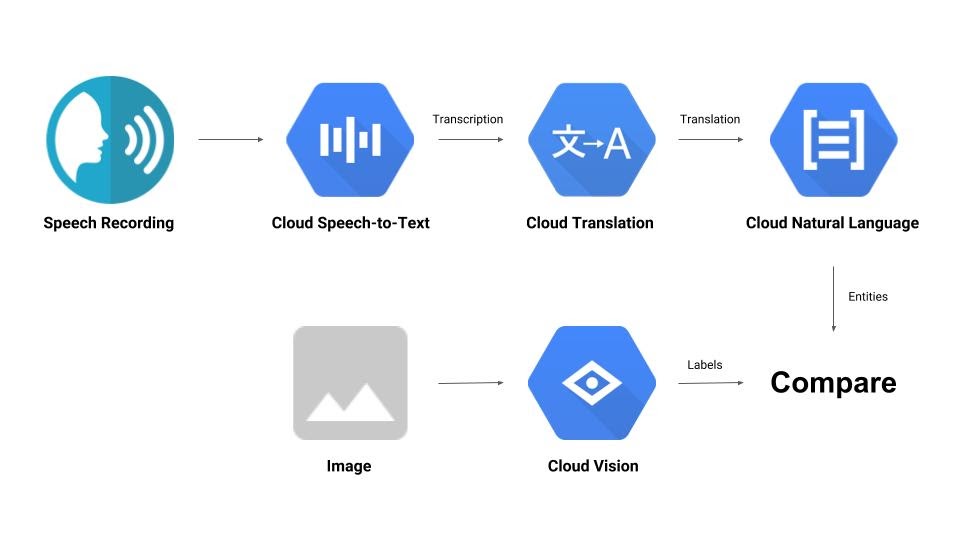
Points abordés
- Utiliser les API Vision, Speech-to-Text, Translation et Natural Language
- Où trouver des exemples de code ?
Prérequis
2. Préparation
Configuration de l'environnement d'auto-formation
- Connectez-vous à la console Cloud, puis créez un projet ou réutilisez un projet existant. (Si vous ne possédez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.)

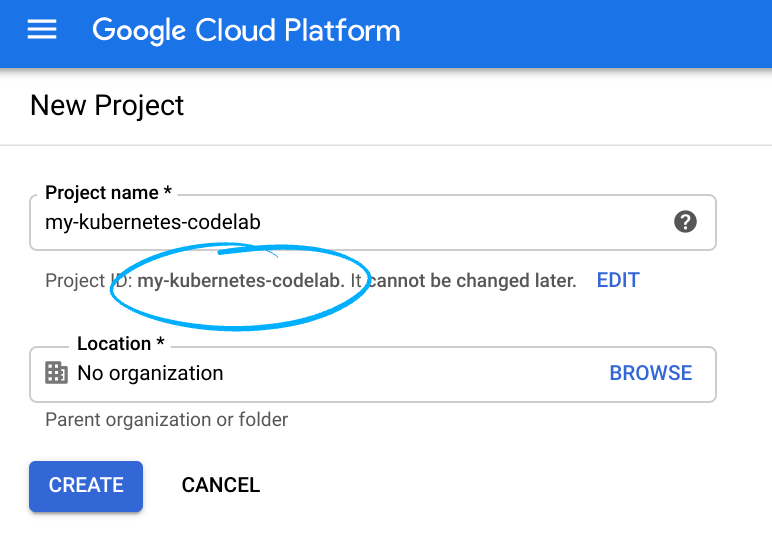
Mémorisez l'ID du projet. Il s'agit d'un nom unique permettant de différencier chaque projet Google Cloud (le nom ci-dessus est déjà pris ; vous devez en trouver un autre). Il sera désigné par le nom PROJECT_ID tout au long de cet atelier de programmation.
- Vous devez ensuite activer la facturation dans Cloud Console pour pouvoir utiliser les ressources Google Cloud.
L'exécution de cet atelier de programmation est très peu coûteuse, voire gratuite. Veillez à suivre les instructions de la section "Nettoyer" qui indique comment désactiver les ressources afin d'éviter les frais une fois ce tutoriel terminé. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300$.
Activer les API
Vous pouvez cliquer sur ce lien pour activer toutes les API nécessaires. Une fois que vous l'aurez fait, n'hésitez pas à ignorer les instructions de configuration de l'authentification. Nous le ferons dans un instant. Vous pouvez également activer chaque API individuellement. Pour ce faire, cliquez sur l'icône de menu en haut à gauche de l'écran.

Sélectionnez API et services dans le menu déroulant, puis cliquez sur "Tableau de bord".
Cliquez sur Activer les API et les services.
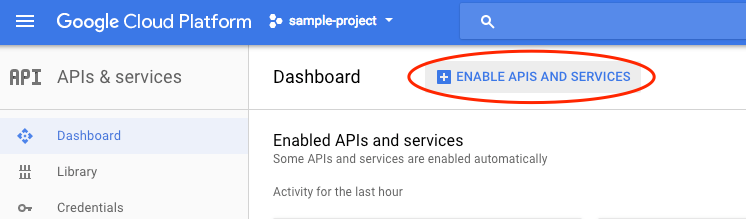
Ensuite, recherchez "vision" dans le champ de recherche. Cliquez sur API Google Cloud Vision :

Cliquez sur Activer pour activer l'API Cloud Vision :

Patientez quelques secondes jusqu'à ce qu'il soit activé. Une fois la fonctionnalité activée, vous verrez ceci :
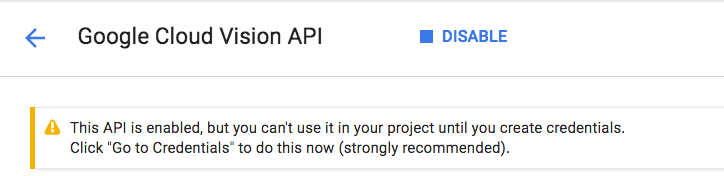
Répétez la même procédure pour activer les API Cloud Speech, Cloud Translation et Cloud Natural Language.
Cloud Shell
Google Cloud Shell est un environnement de ligne de commande exécuté dans le cloud. Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin (gcloud, bq, git, etc.) et offre un répertoire de base persistant de 5 Go. Nous allons utiliser Cloud Shell pour créer notre requête pour les API de machine learning.
Pour commencer à utiliser Cloud Shell, cliquez sur l'icône "Activer Google Cloud Shell"  en haut à droite de la barre d'en-tête.
en haut à droite de la barre d'en-tête.

Une session Cloud Shell s'ouvre dans un nouveau cadre en bas de la console et affiche une invite de ligne de commande. Attendez que l'invite user@project:~$ s'affiche.
Facultatif : Éditeur de code
Selon votre niveau de confort avec la ligne de commande, vous pouvez cliquer sur l'icône "Lancer l'éditeur de code"  en haut à droite de la barre Cloud Shell.
en haut à droite de la barre Cloud Shell.

Compte de service
Vous aurez besoin d'un compte de service pour vous authentifier. Pour en créer un, remplacez [NAME] par le nom de compte de service souhaité et exécutez la commande suivante dans Cloud Shell :
gcloud iam service-accounts create [NAME]
Vous devez maintenant générer une clé pour utiliser ce compte de service. Remplacez [FILE_NAME] par le nom de clé souhaité, [NAME] par le nom du compte de service indiqué ci-dessus et [PROJECT_ID] par l'ID de votre projet. La commande suivante permet de créer et de télécharger la clé sous le nom [FILE_NAME].json :
gcloud iam service-accounts keys create [FILE_NAME].json --iam-account [NAME]@[PROJECT_ID].iam.gserviceaccount.com
Pour utiliser le compte de service, vous devez définir la variable GOOGLE_APPLICATION_CREDENTIALS sur le chemin d'accès de la clé. Pour ce faire, exécutez la commande suivante après avoir remplacé [PATH_TO_FILE] et [FILE_NAME]:
export GOOGLE_APPLICATION_CREDENTIALS=[PATH_TO_FILE]/[FILE_NAME].json
3. Cloud Vision
Client Python
Vous aurez besoin du client Python pour Cloud Vision. Pour l'installer, saisissez la commande suivante dans Cloud Shell :
pip install --upgrade google-cloud-vision --user
Essayons
Examinons les exemples de code de l'API Cloud Vision. Nous souhaitons savoir ce que contient une image spécifique. detect.py semble utile pour cela, alors récupérons-le. Pour ce faire, vous pouvez copier le contenu de detect.py, créer un fichier dans Cloud Shell appelé vision.py et y coller tout le code.vision.py Vous pouvez le faire manuellement dans l'éditeur de code Cloud Shell ou exécuter cette commande curl dans Cloud Shell :
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/vision/cloud-client/detect/detect.py -o vision.py
Une fois cette opération effectuée, utilisez l'API en exécutant la commande suivante dans Cloud Shell :
python vision.py labels-uri gs://cloud-samples-data/ml-api-codelab/birds.jpg
Vous devriez voir un résultat concernant des oiseaux et des autruches, car il s'agit de l'image analysée : https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/birds.jpg.
Que se passe-t-il ?
Vous avez transmis deux arguments à vision.py :
- labels-uri sélectionne la fonction
detect_labels_uri()à exécuter. - gs://cloud-samples-data/ml-api-codelab/birds.jpg correspond à l'emplacement d'une image sur Google Cloud Storage et est transmis en tant que uri dans
detect_labels_uri().
Examinons de plus près detect_labels_uri(). Notez les commentaires supplémentaires qui ont été insérés.
def detect_labels_uri(uri):
"""Detects labels in the file located in Google Cloud Storage or on the
Web."""
# relevant import from above
# from google.cloud import vision
# create ImageAnnotatorClient object
client = vision.ImageAnnotatorClient()
# create Image object
image = vision.types.Image()
# specify location of image
image.source.image_uri = uri
# get label_detection response by passing image to client
response = client.label_detection(image=image)
# get label_annotations portion of response
labels = response.label_annotations
print('Labels:')
for label in labels:
# print the label descriptions
print(label.description)
4. Cloud Speech-to-Text
Client Python
Vous aurez besoin du client Python pour Cloud Speech-to-Text. Pour l'installer, saisissez la commande suivante dans Cloud Shell :
sudo pip install --upgrade google-cloud-speech
Essayons
Accédez aux exemples de code pour Cloud Speech-to-Text. Nous souhaitons transcrire des contenus audio vocaux. transcribe.py semble être un bon point de départ. Utilisons-le. Copiez le contenu de transcribe.py, créez un fichier dans Cloud Shell appelé speech2text.py et collez-y tout le code.speech2text.py Vous pouvez le faire manuellement dans l'éditeur de code Cloud Shell ou exécuter cette commande curl dans Cloud Shell :
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/speech/cloud-client/transcribe.py -o speech2text.py
Une fois cette opération effectuée, utilisez l'API en exécutant la commande suivante dans Cloud Shell :
python speech2text.py gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Des erreurs devraient s'afficher pour signaler un encodage et une fréquence d'échantillonnage hertzienne incorrects. Ne vous inquiétez pas, accédez à transcribe_gcs() dans le code et supprimez les paramètres encoding et sampe_hertz_rate de RecognitionConfig(). Pendant que vous y êtes, remplacez le code de langue par "tr-TR", car tr-ostrich.wav est un enregistrement vocal en turc.
config = types.RecognitionConfig(language_code='tr-TR')
Exécutez à nouveau speech2text.py. Le résultat doit être un texte en turc, car il s'agit de la langue de l'extrait audio analysé : https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/tr-ostrich.wav.
Que se passe-t-il ?
Vous avez transmis gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav, l'emplacement d'un fichier audio sur Google Cloud Storage, à speech2text.py, qui est ensuite transmis en tant que gcs_uri dans transcribe_uri().
Examinons de plus près notre transcribe_uri() modifié.
def transcribe_gcs(gcs_uri):
"""Transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
# enums no longer used
# from google.cloud.speech import enums
from google.cloud.speech import types
# create ImageAnnotatorClient object
client = speech.SpeechClient()
# specify location of speech
audio = types.RecognitionAudio(uri=gcs_uri)
# set language to Turkish
# removed encoding and sample_rate_hertz
config = types.RecognitionConfig(language_code='tr-TR')
# get response by passing config and audio settings to client
response = client.recognize(config, audio)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
# get the transcript of the first alternative
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
5. Cloud Translation
Client Python
Vous aurez besoin du client Python pour Cloud Translation. Pour l'installer, saisissez la commande suivante dans Cloud Shell :
sudo pip install --upgrade google-cloud-translate
Essayons
Passons maintenant aux exemples de code pour Cloud Translation. Dans cet atelier de programmation, nous souhaitons traduire du texte en anglais. snippets.py ressemble à ce que nous voulons. Copiez le contenu de snippets.py, créez un fichier dans Cloud Shell appelé translate.py et collez-y tout le code.translate.py Vous pouvez le faire manuellement dans l'éditeur de code Cloud Shell ou exécuter cette commande curl dans Cloud Shell :
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/translate/cloud-client/snippets.py -o translate.py
Une fois cette opération effectuée, utilisez l'API en exécutant la commande suivante dans Cloud Shell :
python translate.py translate-text en '你有沒有帶外套'
La traduction devrait être "Avez-vous une veste ?".
Que se passe-t-il ?
Vous avez transmis trois arguments à translate.py :
- translate-text sélectionne la fonction
translate_text()à exécuter. - en est transmis en tant que target dans
translate_text()et sert à spécifier la langue dans laquelle traduire le texte. - 你有沒有帶外套 est la chaîne à traduire et est transmise en tant que text dans
translate_text()
Examinons de plus près translate_text(). Notez les commentaires qui ont été ajoutés.
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
# relevant imports from above
# from google.cloud import translate
# import six
# create Client object
translate_client = translate.Client()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# get translation result by passing text and target language to client
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
# print original text, translated text and detected original language
print(u'Text: {}'.format(result['input']))
print(u'Translation: {}'.format(result['translatedText']))
print(u'Detected source language: {}'.format(
result['detectedSourceLanguage']))
6. Cloud Natural Language
Client Python
Vous aurez besoin du client Python pour Cloud Natural Language. Pour l'installer, saisissez la commande suivante dans Cloud Shell :
sudo pip install --upgrade google-cloud-language
Essayons
Enfin, examinons les exemples de code de l'API Cloud Natural Language. Nous souhaitons détecter les entités dans le texte. snippets.py semble contenir du code qui fait cela. Copiez le contenu de snippets.py, créez un fichier dans Cloud Shell appelé natural_language.py et collez-y tout le code.natural_language.py Vous pouvez le faire manuellement dans l'éditeur de code Cloud Shell ou exécuter cette commande curl dans Cloud Shell :
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/language/cloud-client/v1/snippets.py -o natural_language.py
Une fois cette opération effectuée, utilisez l'API en exécutant la commande suivante dans Cloud Shell :
python natural_language.py entities-text 'where did you leave my bike'
L'API doit identifier "vélo" comme une entité. Les entités peuvent être des noms propres (personnalités publiques, points de repère, etc.) ou des noms communs (restaurant, stade, etc.).
Que se passe-t-il ?
Vous avez transmis deux arguments à natural_language.py :
- entities-text sélectionne la fonction
entities_text()à exécuter. - où as-tu laissé mon vélo est la chaîne à analyser pour les entités et est transmise en tant que text dans
entities_text()
Examinons de plus près entities_text(). Notez les nouveaux commentaires qui ont été insérés.
def entities_text(text):
"""Detects entities in the text."""
# relevant imports from above
# from google.cloud import language
# from google.cloud.language import enums
# from google.cloud.language import types
# import six
# create LanguageServiceClient object
client = language.LanguageServiceClient()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# Instantiates a plain text document.
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects entities in the document. You can also analyze HTML with:
# document.type == enums.Document.Type.HTML
entities = client.analyze_entities(document).entities
# entity types from enums.Entity.Type
entity_type = ('UNKNOWN', 'PERSON', 'LOCATION', 'ORGANIZATION',
'EVENT', 'WORK_OF_ART', 'CONSUMER_GOOD', 'OTHER')
# print information for each entity found
for entity in entities:
print('=' * 20)
print(u'{:<16}: {}'.format('name', entity.name))
print(u'{:<16}: {}'.format('type', entity_type[entity.type]))
print(u'{:<16}: {}'.format('metadata', entity.metadata))
print(u'{:<16}: {}'.format('salience', entity.salience))
print(u'{:<16}: {}'.format('wikipedia_url',
entity.metadata.get('wikipedia_url', '-')))
7. Intégrons-les
Rappelons ce que vous allez créer.
Maintenant, assemblons le tout. Créez un fichier solution.py, puis copiez et collez detect_labels_uri(), transcribe_gcs(), translate_text() et entities_text() des étapes précédentes dans solution.py.
Instructions d'importation
Décommentez et déplacez les instructions d'importation vers le haut. Notez que speech.types et language.types sont importés. Cela va créer un conflit. Nous allons donc les supprimer et remplacer chaque occurrence de types dans transcribe_gcs() et entities_text() par speech.types et language.types, respectivement. Vous devriez obtenir le résultat suivant :
from google.cloud import vision
from google.cloud import speech
from google.cloud import translate
from google.cloud import language
from google.cloud.language import enums
import six
Résultats de retour
Au lieu d'imprimer, faites en sorte que les fonctions renvoient les résultats. Vous devriez obtenir un résultat semblable à celui-ci :
# import statements
def detect_labels_uri(uri):
# code
# we only need the label descriptions
label_descriptions = []
for label in labels:
label_descriptions.append(label.description)
return label_descriptions
def transcribe_gcs(gcs_uri):
# code
# naive assumption that audio file is short
return response.results[0].alternatives[0].transcript
def translate_text(target, text):
# code
# only interested in translated text
return result['translatedText']
def entities_text(text):
# code
# we only need the entity names
entity_names = []
for entity in entities:
entity_names.append(entity.name)
return entity_names
Utiliser les fonctions
Après tout ce travail, vous pouvez appeler ces fonctions. Allez-y, faites-le ! Exemple :
def compare_audio_to_image(audio, image):
"""Checks whether a speech audio is relevant to an image."""
# speech audio -> text
transcription = transcribe_gcs(audio)
# text of any language -> english text
translation = translate_text('en', transcription)
# text -> entities
entities = entities_text(translation)
# image -> labels
labels = detect_labels_uri(image)
# naive check for whether entities intersect with labels
has_match = False
for entity in entities:
if entity in labels:
# print result for each match
print('The audio and image both contain: {}'.format(entity))
has_match = True
# print if there are no matches
if not has_match:
print('The audio and image do not appear to be related.')
Prise en charge de plusieurs langues
Auparavant, nous avions codé en dur le turc dans transcribe_gcs(). Modifions cela pour que la langue puisse être spécifiée à partir de compare_audio_to_image(). Voici les modifications requises :
def transcribe_gcs(language, gcs_uri):
...
config = speech.types.RecognitionConfig(language_code=language)
def compare_audio_to_image(language, audio, image):
transcription = transcribe_gcs(language, audio)
Essayer
Le code final se trouve dans solution.py de ce dépôt GitHub. Voici une commande curl pour récupérer ces informations :
curl https://raw.githubusercontent.com/googlecodelabs/integrating-ml-apis/master/solution.py -O
La version sur GitHub contient argparse, qui permet les opérations suivantes à partir de la ligne de commande :
python solution.py tr-TR gs://cloud-samples-data/ml-api-codelab/tr-ball.wav gs://cloud-samples-data/ml-api-codelab/football.jpg
Pour chaque élément trouvé, le code doit générer "L'audio et l'image contiennent tous les deux : ". Dans l'exemple ci-dessus, il s'agirait de "L'audio et l'image contiennent tous les deux : ballon".
Bonus : essayez d'autres fonctionnalités
Voici d'autres emplacements de fichiers audio et d'image à essayer.
8. Félicitations !
Vous avez exploré et intégré quatre API de machine learning pour déterminer si un échantillon vocal parle de l'image fournie. Ce n'est que le début, car il existe de nombreuses autres façons d'améliorer ce pipeline.
Points abordés
- Envoyer des requêtes à l'API Cloud Vision
- Envoyer des requêtes à l'API Cloud Speech-to-Text
- Envoyer des requêtes à l'API Cloud Translation
- Envoyer des requêtes à l'API Cloud Natural Language
- Utiliser toutes les API ci-dessus ensemble
Étapes suivantes
- Pour mieux comparer les mots, consultez word2vec.
- Consultez les ateliers de programmation plus détaillés sur l'API Vision, l'API Speech-to-Text, l'API Translation et l'API Natural Language.
- Essayez de remplacer Cloud Vision par Cloud Video Intelligence.
- Synthétiser des fichiers audio vocaux avec l'API Cloud Text-to-Speech
- Découvrez comment importer des objets dans Cloud Storage.