
1. Descripción general
En este codelab, se te guiará por algunas APIs de aprendizaje automático. Usarás lo siguiente:
- Cloud Vision para comprender el contenido de una imagen
- Cloud Speech-to-Text para transcribir audio a texto
- Cloud Translation para traducir una cadena arbitraria a cualquier idioma admitido
- Cloud Natural Language para extraer información del texto
Qué compilarás
Construirás una canalización que comparará una grabación de audio con una imagen y determinará su relevancia mutua. Aquí tienes un avance de cómo lo lograrás:
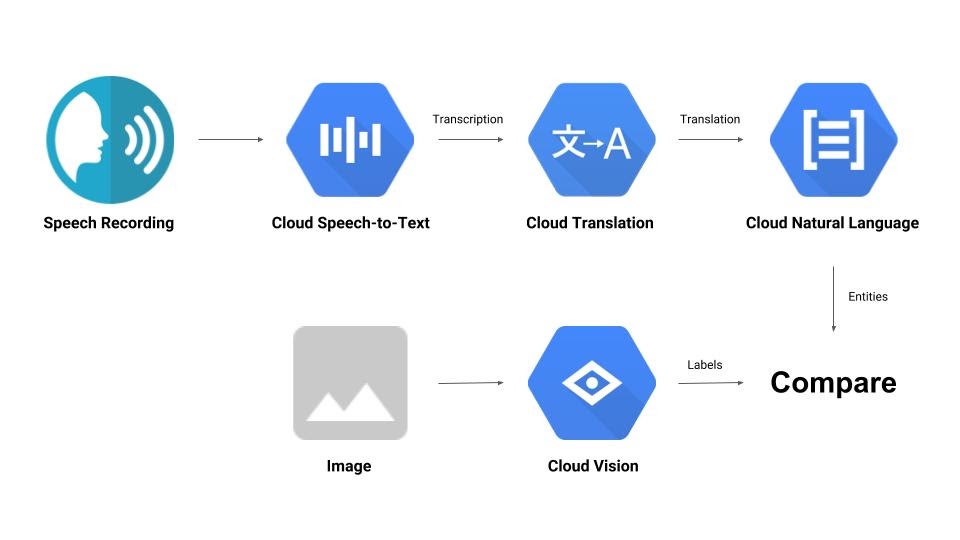
Qué aprenderás
- Cómo usar las APIs de Vision, Speech-to-Text, Translation y Natural Language
- Dónde encontrar muestras de código
Requisitos
2. Configuración y requisitos
Configuración del entorno de autoaprendizaje
- Accede a la consola de Cloud y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

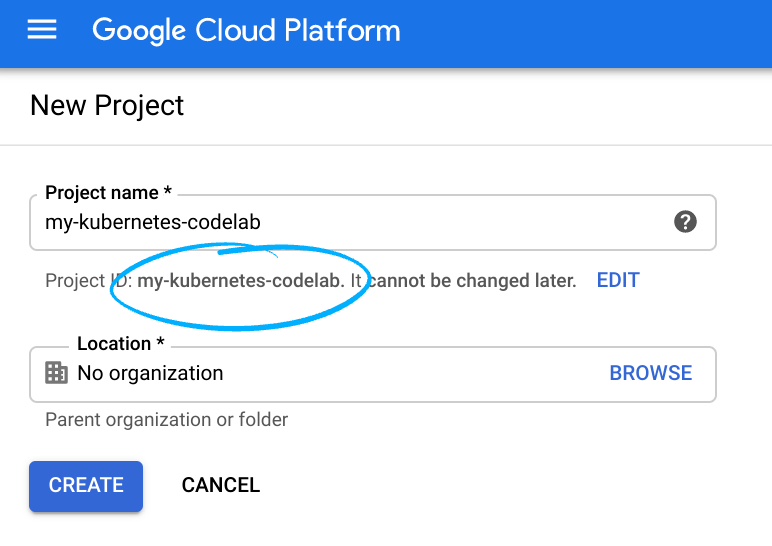
Recuerde el ID de proyecto, un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar los recursos de Google Cloud recursos.
Ejecutar este codelab no debería costar mucho, tal vez nada. Asegúrate de seguir las instrucciones de la sección “Realiza una limpieza”, en la que se indica cómo cerrar los recursos para no incurrir en facturaciones más allá de este instructivo. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de USD 300.
Habilitar las API
Puedes hacer clic en este vínculo para habilitar todas las APIs necesarias. Después de hacerlo, puedes ignorar las instrucciones para configurar la autenticación. Lo haremos en un momento. Como alternativa, puedes habilitar cada API de forma individual. Para ello, haz clic en el ícono de menú ubicado en la parte superior izquierda de la pantalla.

Selecciona APIs & services en el menú desplegable y haz clic en Panel.
Haz clic en Habilitar APIs y servicios.
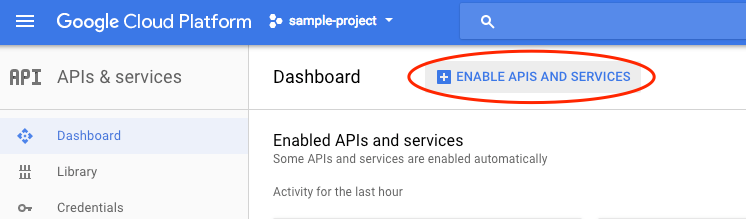
Luego, busca "visión" en el cuadro de búsqueda. Haz clic en Google Cloud Vision API:

Haz clic en Habilitar para habilitar la API de Cloud Vision:

Espera unos segundos para que se habilite. Verás este mensaje cuando se habilite:
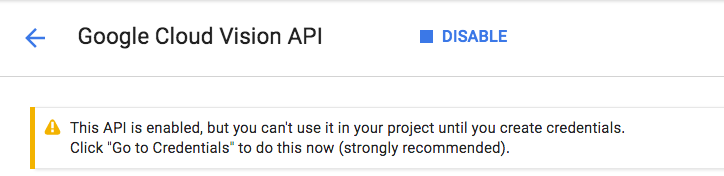
Repite el mismo proceso para habilitar las APIs de Cloud Speech, Cloud Translation y Cloud Natural Language.
Cloud Shell
Google Cloud Shell es un entorno de línea de comandos que se ejecuta en la nube. Esta máquina virtual basada en Debian está cargada con todas las herramientas de desarrollo que necesitarás (gcloud, bq, git y otras) y ofrece un directorio principal persistente de 5 GB. Usaremos Cloud Shell para crear nuestra solicitud a las APIs de aprendizaje automático.
Para comenzar a usar Cloud Shell, haz clic en el ícono "Activar Google Cloud Shell"  en la esquina superior derecha de la barra de encabezado.
en la esquina superior derecha de la barra de encabezado.

Se abrirá una sesión de Cloud Shell en un marco nuevo en la parte inferior de la consola, que mostrará una línea de comandos. Espera hasta que aparezca el mensaje user@project:~$
Opcional: Editor de código
Según tu nivel de comodidad con la línea de comandos, es posible que desees hacer clic en el ícono  "Iniciar editor de código" en la esquina superior derecha de la barra de Cloud Shell.
"Iniciar editor de código" en la esquina superior derecha de la barra de Cloud Shell.

Cuenta de servicio
Necesitarás una cuenta de servicio para autenticarte. Para crear una, reemplaza [NAME] por el nombre deseado de la cuenta de servicio y ejecuta el siguiente comando en Cloud Shell:
gcloud iam service-accounts create [NAME]
Ahora, deberás generar una clave para usar esa cuenta de servicio. Reemplaza [FILE_NAME] por el nombre deseado de la clave, [NAME] por el nombre de la cuenta de servicio anterior y [PROJECT_ID] por el ID de tu proyecto. El siguiente comando creará y descargará la clave como [FILE_NAME].json:
gcloud iam service-accounts keys create [FILE_NAME].json --iam-account [NAME]@[PROJECT_ID].iam.gserviceaccount.com
Para usar la cuenta de servicio, deberás configurar la variable GOOGLE_APPLICATION_CREDENTIALS en la ruta de acceso de la clave. Para ello, ejecuta el siguiente comando después de reemplazar [PATH_TO_FILE] y [FILE_NAME]:
export GOOGLE_APPLICATION_CREDENTIALS=[PATH_TO_FILE]/[FILE_NAME].json
3. Cloud Vision
Cliente de Python
Necesitarás el cliente de Python para Cloud Vision. Para instalarlo, escribe lo siguiente en Cloud Shell:
pip install --upgrade google-cloud-vision --user
Probar
Veamos las muestras de código de la API de Cloud Vision. Nos interesa saber qué hay en una imagen específica. detect.py parece ser útil para esto, así que lo tomaremos. Una forma es copiar el contenido de detect.py, crear un archivo nuevo en Cloud Shell llamado vision.py y pegar todo el código en vision.py. Puedes hacerlo de forma manual en el editor de código de Cloud Shell o ejecutar este comando curl en Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/vision/cloud-client/detect/detect.py -o vision.py
Después de hacerlo, ejecuta lo siguiente en Cloud Shell para usar la API:
python vision.py labels-uri gs://cloud-samples-data/ml-api-codelab/birds.jpg
Deberías ver un resultado sobre aves y avestruces, ya que esta fue la imagen analizada: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/birds.jpg
¿Qué sucede?
Pasaste 2 argumentos a vision.py:
- labels-uri selecciona la función
detect_labels_uri()para ejecutarla. - gs://cloud-samples-data/ml-api-codelab/birds.jpg es la ubicación de una imagen en Google Cloud Storage y se pasa como uri en
detect_labels_uri().
Analicemos detect_labels_uri() con más detalle. Observa los comentarios adicionales que se insertaron.
def detect_labels_uri(uri):
"""Detects labels in the file located in Google Cloud Storage or on the
Web."""
# relevant import from above
# from google.cloud import vision
# create ImageAnnotatorClient object
client = vision.ImageAnnotatorClient()
# create Image object
image = vision.types.Image()
# specify location of image
image.source.image_uri = uri
# get label_detection response by passing image to client
response = client.label_detection(image=image)
# get label_annotations portion of response
labels = response.label_annotations
print('Labels:')
for label in labels:
# print the label descriptions
print(label.description)
4. Cloud Speech-to-Text
Cliente de Python
Necesitarás el cliente de Python para Cloud Speech-to-Text. Para instalarlo, escribe lo siguiente en Cloud Shell:
sudo pip install --upgrade google-cloud-speech
Probar
Dirijámonos a las muestras de código de Cloud Speech-to-Text. Nos interesa transcribir el audio de voz. transcribe.py parece ser un buen lugar para comenzar, así que lo usaremos. Copia el contenido de transcribe.py, crea un archivo nuevo en Cloud Shell llamado speech2text.py y pega todo el código en speech2text.py. Puedes hacerlo de forma manual en el editor de código de Cloud Shell o ejecutar este comando curl en Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/speech/cloud-client/transcribe.py -o speech2text.py
Después de hacerlo, ejecuta lo siguiente en Cloud Shell para usar la API:
python speech2text.py gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Debería haber errores que indiquen que la codificación y la tasa de Hertz de la muestra son incorrectas. No te preocupes, ve a transcribe_gcs()en el código y borra la configuración de encoding y sampe_hertz_rate de RecognitionConfig(). Ya que estás, cambia el código de idioma a “tr-TR”, ya que tr-ostrich.wav es una grabación de voz en turco.
config = types.RecognitionConfig(language_code='tr-TR')
Ahora, vuelve a ejecutar speech2text.py. El resultado debería ser un texto en turco, ya que ese fue el audio analizado: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/tr-ostrich.wav
¿Qué sucede?
Pasaste gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav, la ubicación de un archivo de audio en Google Cloud Storage, a speech2text.py, que luego se pasa como gcs_uri a transcribe_uri().
Analicemos con más detalle nuestro transcribe_uri() modificado.
def transcribe_gcs(gcs_uri):
"""Transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
# enums no longer used
# from google.cloud.speech import enums
from google.cloud.speech import types
# create ImageAnnotatorClient object
client = speech.SpeechClient()
# specify location of speech
audio = types.RecognitionAudio(uri=gcs_uri)
# set language to Turkish
# removed encoding and sample_rate_hertz
config = types.RecognitionConfig(language_code='tr-TR')
# get response by passing config and audio settings to client
response = client.recognize(config, audio)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
# get the transcript of the first alternative
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
5. Cloud Translation
Cliente de Python
Necesitarás el cliente de Python para Cloud Translation. Para instalarlo, escribe lo siguiente en Cloud Shell:
sudo pip install --upgrade google-cloud-translate
Probar
Ahora, veamos las muestras de código de Cloud Translation. Para los fines de este codelab, queremos traducir texto al inglés. snippets.py parece ser lo que queremos. Copia el contenido de snippets.py, crea un archivo nuevo en Cloud Shell llamado translate.py y pega todo el código en translate.py. Puedes hacerlo de forma manual en el editor de código de Cloud Shell o ejecutar este comando curl en Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/translate/cloud-client/snippets.py -o translate.py
Después de hacerlo, ejecuta lo siguiente en Cloud Shell para usar la API:
python translate.py translate-text en '你有沒有帶外套'
La traducción debe ser "¿Tienes una chaqueta?".
¿Qué sucede?
Pasaste 3 argumentos a translate.py:
- translate-text selecciona la función
translate_text()para ejecutarla. - en se pasa como target a
translate_text()y sirve para especificar el idioma al que se traducirá. - “你有沒有帶外套” es la cadena que se traducirá y se pasa como texto a
translate_text().
Analicemos translate_text() con más detalle. Observa los comentarios que se agregaron.
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
# relevant imports from above
# from google.cloud import translate
# import six
# create Client object
translate_client = translate.Client()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# get translation result by passing text and target language to client
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
# print original text, translated text and detected original language
print(u'Text: {}'.format(result['input']))
print(u'Translation: {}'.format(result['translatedText']))
print(u'Detected source language: {}'.format(
result['detectedSourceLanguage']))
6. Cloud Natural Language
Cliente de Python
Necesitarás el cliente de Python para Cloud Natural Language. Para instalarlo, escribe lo siguiente en Cloud Shell:
sudo pip install --upgrade google-cloud-language
Probar
Por último, veamos las muestras de código de la API de Cloud Natural Language. Queremos detectar entidades en el texto. snippets.py parece contener código que hace eso. Copia el contenido de snippets.py, crea un archivo nuevo en Cloud Shell llamado natural_language.py y pega todo el código en natural_language.py. Puedes hacerlo de forma manual en el editor de código de Cloud Shell o ejecutar este comando curl en Cloud Shell:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/language/cloud-client/v1/snippets.py -o natural_language.py
Después de hacerlo, ejecuta lo siguiente en Cloud Shell para usar la API:
python natural_language.py entities-text 'where did you leave my bike'
La API debe identificar "bicicleta" como una entidad. Las entidades pueden ser nombres propios (figuras públicas, puntos de referencia, etc.) o nombres comunes (restaurante, estadio, etc.).
¿Qué sucede?
Pasaste 2 argumentos a natural_language.py:
- entities-text selecciona la función
entities_text()para ejecutar. - "¿Dónde dejaste mi bicicleta?" es la cadena que se analizará para detectar entidades y se pasa como texto a
entities_text().
Analicemos entities_text() con más detalle. Observa los comentarios nuevos que se insertaron.
def entities_text(text):
"""Detects entities in the text."""
# relevant imports from above
# from google.cloud import language
# from google.cloud.language import enums
# from google.cloud.language import types
# import six
# create LanguageServiceClient object
client = language.LanguageServiceClient()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# Instantiates a plain text document.
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects entities in the document. You can also analyze HTML with:
# document.type == enums.Document.Type.HTML
entities = client.analyze_entities(document).entities
# entity types from enums.Entity.Type
entity_type = ('UNKNOWN', 'PERSON', 'LOCATION', 'ORGANIZATION',
'EVENT', 'WORK_OF_ART', 'CONSUMER_GOOD', 'OTHER')
# print information for each entity found
for entity in entities:
print('=' * 20)
print(u'{:<16}: {}'.format('name', entity.name))
print(u'{:<16}: {}'.format('type', entity_type[entity.type]))
print(u'{:<16}: {}'.format('metadata', entity.metadata))
print(u'{:<16}: {}'.format('salience', entity.salience))
print(u'{:<16}: {}'.format('wikipedia_url',
entity.metadata.get('wikipedia_url', '-')))
7. Integrémoslos
Recordemos qué estás creando.
Ahora, unamos todo. Crea un archivo solution.py, y copia y pega detect_labels_uri(), transcribe_gcs(), translate_text() y entities_text() de los pasos anteriores en solution.py.
Declaraciones de importación
Quita las marcas de comentario y mueve las instrucciones de importación a la parte superior. Ten en cuenta que se importan speech.types y language.types. Esto causará un conflicto, así que quitémoslos y cambiemos cada ocurrencia individual de types en transcribe_gcs() y entities_text() a speech.types y language.types, respectivamente. Deberías obtener lo siguiente:
from google.cloud import vision
from google.cloud import speech
from google.cloud import translate
from google.cloud import language
from google.cloud.language import enums
import six
Devuelve resultados
En lugar de imprimir, haz que las funciones muestren los resultados. Deberías tener algo similar a lo siguiente:
# import statements
def detect_labels_uri(uri):
# code
# we only need the label descriptions
label_descriptions = []
for label in labels:
label_descriptions.append(label.description)
return label_descriptions
def transcribe_gcs(gcs_uri):
# code
# naive assumption that audio file is short
return response.results[0].alternatives[0].transcript
def translate_text(target, text):
# code
# only interested in translated text
return result['translatedText']
def entities_text(text):
# code
# we only need the entity names
entity_names = []
for entity in entities:
entity_names.append(entity.name)
return entity_names
Usa las funciones
Después de todo ese trabajo, puedes llamar a esas funciones. ¡Adelante, hazlo! Por ejemplo:
def compare_audio_to_image(audio, image):
"""Checks whether a speech audio is relevant to an image."""
# speech audio -> text
transcription = transcribe_gcs(audio)
# text of any language -> english text
translation = translate_text('en', transcription)
# text -> entities
entities = entities_text(translation)
# image -> labels
labels = detect_labels_uri(image)
# naive check for whether entities intersect with labels
has_match = False
for entity in entities:
if entity in labels:
# print result for each match
print('The audio and image both contain: {}'.format(entity))
has_match = True
# print if there are no matches
if not has_match:
print('The audio and image do not appear to be related.')
Compatibilidad con varios idiomas
Anteriormente, codificamos el turco en transcribe_gcs(). Cambiemos eso para que el idioma se pueda especificar desde compare_audio_to_image(). Estos son los cambios necesarios:
def transcribe_gcs(language, gcs_uri):
...
config = speech.types.RecognitionConfig(language_code=language)
def compare_audio_to_image(language, audio, image):
transcription = transcribe_gcs(language, audio)
Probar
El código final se puede encontrar en solution.py de este repositorio de GitHub. Este es un comando curl para obtenerlo:
curl https://raw.githubusercontent.com/googlecodelabs/integrating-ml-apis/master/solution.py -O
La versión de GitHub contiene argparse, que permite lo siguiente desde la línea de comandos:
python solution.py tr-TR gs://cloud-samples-data/ml-api-codelab/tr-ball.wav gs://cloud-samples-data/ml-api-codelab/football.jpg
Para cada elemento encontrado, el código debe generar el mensaje "El audio y la imagen contienen: ". En el ejemplo anterior, sería "El audio y la imagen contienen: pelota".
Adicional: Prueba más
Aquí tienes más ubicaciones de archivos de audio y de imagen que puedes probar.
8. ¡Felicitaciones!
Exploraste e integraste cuatro APIs de aprendizaje automático para determinar si una muestra de voz habla sobre la imagen proporcionada. Esto es solo el comienzo, ya que hay muchas más formas de mejorar esta canalización.
Temas abordados
- Cómo realizar solicitudes a la API de Cloud Vision
- Cómo realizar solicitudes a la API de Cloud Speech-to-Text
- Cómo realizar solicitudes a la API de Cloud Translation
- Cómo realizar solicitudes a la API de Cloud Natural Language
- Uso de todas las APIs anteriores en conjunto
Próximos pasos
- Para comparar mejor las palabras, consulta word2vec.
- Consulta los codelabs más detallados sobre la API de Vision, la API de Speech-to-Text, la API de Translation y la API de Natural Language.
- Intenta sustituir Cloud Vision por Cloud Video Intelligence
- Sintetiza audio de voz con la API de Cloud Text-to-Speech
- Aprende a subir objetos a Cloud Storage