
1. Übersicht
In diesem Codelab erhalten Sie einen kurzen Überblick über einige APIs für maschinelles Lernen. Sie benötigen Folgendes:
- Cloud Vision, um den Inhalt eines Bildes zu verstehen
- Cloud Speech-to-Text zum Transkribieren von Audio in Text
- Cloud Translation zum Übersetzen eines beliebigen Strings in eine unterstützte Sprache
- Cloud Natural Language zum Extrahieren von Informationen aus Text
Umfang
Sie erstellen eine Pipeline, in der eine Audioaufzeichnung mit einem Bild verglichen wird, um ihre Relevanz für einander zu ermitteln. Hier ist ein kleiner Vorgeschmack darauf, wie Sie das erreichen:
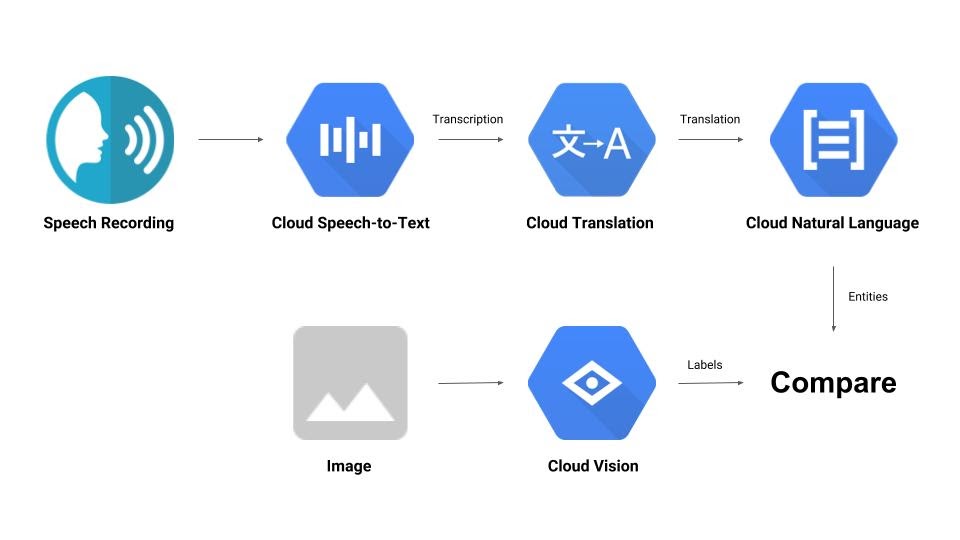
Lerninhalte
- Vision, Speech-to-Text, Translation und Natural Language APIs verwenden
- Wo finde ich Codebeispiele?
Voraussetzungen
- Ein Browser wie Google Chrome oder Mozilla Firefox
- Grundlegende Python-Kenntnisse
2. Einrichtung und Anforderungen
Einrichtung der Umgebung im eigenen Tempo
- Melden Sie sich in der Cloud Console an und erstellen Sie ein neues Projekt oder verwenden Sie ein vorhandenes Projekt. Wenn Sie noch kein Gmail- oder Google Workspace-Konto haben, müssen Sie eins erstellen.

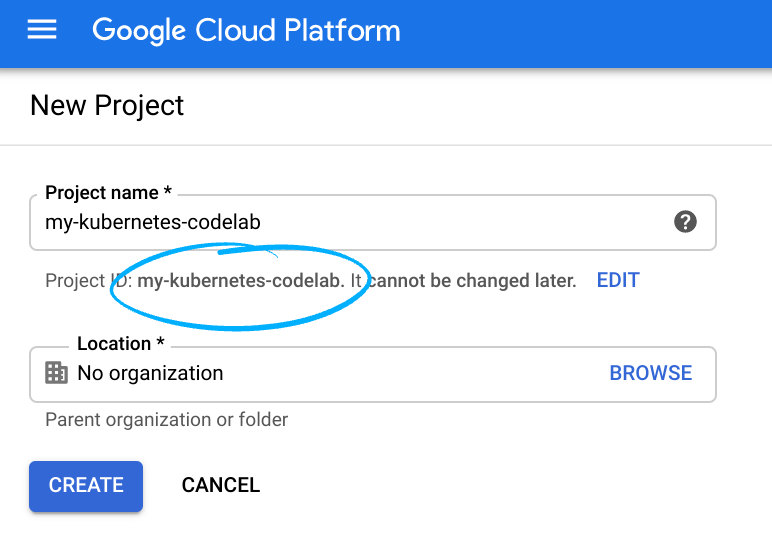
Notieren Sie sich die Projekt-ID, also den projektübergreifend nur einmal vorkommenden Namen eines Google Cloud-Projekts. Der oben angegebene Name ist bereits vergeben und kann leider nicht mehr verwendet werden. Sie wird in diesem Codelab später als PROJECT_ID bezeichnet.
- Als Nächstes müssen Sie die Abrechnung in der Cloud Console aktivieren, um Google Cloud-Ressourcen verwenden zu können.
Die Durchführung dieses Codelabs sollte keine oder nur geringe Kosten verursachen. Folgen Sie unbedingt den Anweisungen im Abschnitt „Bereinigen“, in dem beschrieben wird, wie Sie Ressourcen herunterfahren, damit nach dieser Anleitung keine weiteren Kosten anfallen. Neuen Nutzern von Google Cloud steht das Programm Kostenlose Testversion mit einem Guthaben von 300$ zur Verfügung.
APIs aktivieren
Klicken Sie auf diesen Link, um alle erforderlichen APIs zu aktivieren. Danach können Sie die Anleitung zum Einrichten der Authentifizierung ignorieren. Wir werden das gleich tun. Alternativ können Sie jede API einzeln aktivieren. Klicken Sie dazu links oben auf dem Bildschirm auf das Menüsymbol.

Wählen Sie im Drop-down-Menü APIs & Services (APIs & Dienste) aus und klicken Sie auf „Dashboard“.
Klicken Sie auf APIs und Dienste aktivieren.
Geben Sie dann in das Suchfeld „vision“ ein. Klicken Sie auf Google Cloud Vision API:

Klicken Sie auf Aktivieren, um die Cloud Vision API zu aktivieren:

Es dauert einige Sekunden, bis die Funktion aktiviert ist. So sieht es aus, wenn die Funktion aktiviert ist:
Wiederholen Sie den Vorgang, um die Cloud Speech API, Cloud Translation API und Cloud Natural Language API zu aktivieren.
Cloud Shell
Google Cloud Shell ist eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird. Auf dieser Debian-basierten virtuellen Maschine sind alle erforderlichen Entwicklungstools (gcloud, bq, git usw.) installiert und sie stellt ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher zur Verfügung. Wir verwenden Cloud Shell, um unsere Anfrage an die Machine-Learning-APIs zu erstellen.
Klicken Sie zum Starten von Cloud Shell rechts oben in der Kopfzeile auf das Symbol „Google Cloud Shell aktivieren“  .
.

Im unteren Bereich der Konsole wird ein neuer Frame für die Cloud Shell-Sitzung geöffnet, in dem eine Befehlszeilen-Eingabeaufforderung angezeigt wird. Warten Sie, bis die Eingabeaufforderung user@project:~$ angezeigt wird.
Optional: Code-Editor
Je nachdem, wie vertraut Sie mit der Befehlszeile sind, können Sie oben rechts in der Cloud Shell-Leiste auf das Symbol  Code-Editor starten klicken.
Code-Editor starten klicken.

Dienstkonto
Zur Authentifizierung benötigen Sie ein Dienstkonto. Ersetzen Sie [NAME] durch den gewünschten Namen des Dienstkontos und führen Sie den folgenden Befehl in Cloud Shell aus:
gcloud iam service-accounts create [NAME]
Jetzt müssen Sie einen Schlüssel generieren, um dieses Dienstkonto zu verwenden. Ersetzen Sie [FILE_NAME] durch den gewünschten Namen des Schlüssels, [NAME] durch den Namen des Dienstkontos von oben und [PROJECT_ID] durch die ID Ihres Projekts. Mit dem folgenden Befehl wird der Schlüssel als [FILE_NAME].json erstellt und heruntergeladen:
gcloud iam service-accounts keys create [FILE_NAME].json --iam-account [NAME]@[PROJECT_ID].iam.gserviceaccount.com
Wenn Sie das Dienstkonto verwenden möchten, müssen Sie die Variable GOOGLE_APPLICATION_CREDENTIALS auf den Pfad des Schlüssels festlegen. Führen Sie dazu den folgenden Befehl aus, nachdem Sie [PATH_TO_FILE] und [FILE_NAME] ersetzt haben:
export GOOGLE_APPLICATION_CREDENTIALS=[PATH_TO_FILE]/[FILE_NAME].json
3. Cloud Vision
Python-Client
Sie benötigen den Python-Client für Cloud Vision. Geben Sie zum Installieren Folgendes in Cloud Shell ein:
pip install --upgrade google-cloud-vision --user
Ausprobieren
Sehen wir uns die Codebeispiele für die Cloud Vision API an. Wir möchten wissen, was auf einem bestimmten Bild zu sehen ist. detect.py scheint dafür nützlich zu sein. Eine Möglichkeit besteht darin, den Inhalt von detect.py zu kopieren, eine neue Datei in Cloud Shell mit dem Namen vision.py zu erstellen und den gesamten Code in vision.py einzufügen. Sie können dies manuell im Cloud Shell-Code-Editor tun oder den folgenden curl-Befehl in Cloud Shell ausführen:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/vision/cloud-client/detect/detect.py -o vision.py
Führen Sie dann in Cloud Shell den folgenden Befehl aus, um die API zu verwenden:
python vision.py labels-uri gs://cloud-samples-data/ml-api-codelab/birds.jpg
Sie sollten eine Ausgabe über Vögel und Strauße sehen, da dies das analysierte Bild war: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/birds.jpg
Was ist da los?
Sie haben zwei Argumente an vision.py übergeben:
- Mit labels-uri wird die auszuführende
detect_labels_uri()-Funktion ausgewählt. - gs://cloud-samples-data/ml-api-codelab/birds.jpg ist der Speicherort eines Bildes in Google Cloud Storage und wird als uri an
detect_labels_uri()übergeben.
Sehen wir uns detect_labels_uri() genauer an. Beachten Sie die zusätzlichen Kommentare, die eingefügt wurden.
def detect_labels_uri(uri):
"""Detects labels in the file located in Google Cloud Storage or on the
Web."""
# relevant import from above
# from google.cloud import vision
# create ImageAnnotatorClient object
client = vision.ImageAnnotatorClient()
# create Image object
image = vision.types.Image()
# specify location of image
image.source.image_uri = uri
# get label_detection response by passing image to client
response = client.label_detection(image=image)
# get label_annotations portion of response
labels = response.label_annotations
print('Labels:')
for label in labels:
# print the label descriptions
print(label.description)
4. Cloud Speech-to-Text
Python-Client
Sie benötigen den Python-Client für Cloud Speech-to-Text. Geben Sie zum Installieren Folgendes in Cloud Shell ein:
sudo pip install --upgrade google-cloud-speech
Ausprobieren
Codebeispiele für Cloud Speech-to-Text Wir möchten Audioinhalte mit gesprochenem Text transkribieren. transcribe.py scheint ein guter Ausgangspunkt zu sein. Kopieren Sie den Inhalt von „transcribe.py“, erstellen Sie in Cloud Shell eine neue Datei namens speech2text.py und fügen Sie den gesamten Code in speech2text.py ein. Sie können dies manuell im Cloud Shell-Code-Editor tun oder den folgenden curl-Befehl in Cloud Shell ausführen:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/speech/cloud-client/transcribe.py -o speech2text.py
Führen Sie dann in Cloud Shell den folgenden Befehl aus, um die API zu verwenden:
python speech2text.py gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Es sollten Fehlermeldungen zur falschen Codierung und Abtastrate angezeigt werden. Keine Sorge. Gehe im Code zu transcribe_gcs() und lösche die Einstellungen für encoding und sampe_hertz_rate aus RecognitionConfig(). Ändern Sie dabei den Sprachcode in „tr-TR“, da tr-ostrich.wav eine Sprachaufzeichnung auf Türkisch ist.
config = types.RecognitionConfig(language_code='tr-TR')
Führen Sie speech2text.py jetzt noch einmal aus. Die Ausgabe sollte türkischer Text sein, da dies die analysierte Audioquelle war: https://storage.googleapis.com/cloud-samples-data/ml-api-codelab/tr-ostrich.wav
Worum geht es?
Sie haben gs://cloud-samples-data/ml-api-codelab/tr-ostrich.wav, den Speicherort einer Audiodatei in Google Cloud Storage, an speech2text.py übergeben, die dann als gcs_uri an transcribe_uri() übergeben wird.
Sehen wir uns die modifizierte transcribe_uri() genauer an.
def transcribe_gcs(gcs_uri):
"""Transcribes the audio file specified by the gcs_uri."""
from google.cloud import speech
# enums no longer used
# from google.cloud.speech import enums
from google.cloud.speech import types
# create ImageAnnotatorClient object
client = speech.SpeechClient()
# specify location of speech
audio = types.RecognitionAudio(uri=gcs_uri)
# set language to Turkish
# removed encoding and sample_rate_hertz
config = types.RecognitionConfig(language_code='tr-TR')
# get response by passing config and audio settings to client
response = client.recognize(config, audio)
# Each result is for a consecutive portion of the audio. Iterate through
# them to get the transcripts for the entire audio file.
for result in response.results:
# The first alternative is the most likely one for this portion.
# get the transcript of the first alternative
print(u'Transcript: {}'.format(result.alternatives[0].transcript))
5. Cloud Translation
Python-Client
Sie benötigen den Python-Client für Cloud Translation. Geben Sie zum Installieren Folgendes in Cloud Shell ein:
sudo pip install --upgrade google-cloud-translate
Ausprobieren
Sehen wir uns nun die Codebeispiele für Cloud Translation an. In diesem Codelab möchten wir Text ins Englische übersetzen. snippets.py sieht so aus, wie wir es uns vorstellen. Kopieren Sie den Inhalt von snippets.py, erstellen Sie in Cloud Shell eine neue Datei mit dem Namen translate.py und fügen Sie den gesamten Code in translate.py ein. Sie können dies manuell im Cloud Shell-Code-Editor tun oder den folgenden curl-Befehl in Cloud Shell ausführen:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/translate/cloud-client/snippets.py -o translate.py
Führen Sie dann in Cloud Shell den folgenden Befehl aus, um die API zu verwenden:
python translate.py translate-text en '你有沒有帶外套'
Die Übersetzung sollte „Hast du eine Jacke?“ lauten.
Worum geht es?
Sie haben drei Argumente an translate.py übergeben:
- Mit translate-text wird die auszuführende Funktion
translate_text()ausgewählt. - en wird als target an
translate_text()übergeben und dient zur Angabe der Sprache, in die übersetzt werden soll. - ‘你有沒有帶外套' ist der zu übersetzende String, der als text an
translate_text()übergeben wird.
Sehen wir uns translate_text() genauer an. Beachten Sie die hinzugefügten Kommentare.
def translate_text(target, text):
"""Translates text into the target language.
Target must be an ISO 639-1 language code.
See https://g.co/cloud/translate/v2/translate-reference#supported_languages
"""
# relevant imports from above
# from google.cloud import translate
# import six
# create Client object
translate_client = translate.Client()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# get translation result by passing text and target language to client
# Text can also be a sequence of strings, in which case this method
# will return a sequence of results for each text.
result = translate_client.translate(text, target_language=target)
# print original text, translated text and detected original language
print(u'Text: {}'.format(result['input']))
print(u'Translation: {}'.format(result['translatedText']))
print(u'Detected source language: {}'.format(
result['detectedSourceLanguage']))
6. Cloud Natural Language
Python-Client
Sie benötigen den Python-Client für Cloud Natural Language. Geben Sie zum Installieren Folgendes in Cloud Shell ein:
sudo pip install --upgrade google-cloud-language
Ausprobieren
Sehen wir uns zum Schluss die Codebeispiele für die Cloud Natural Language API an. Wir möchten Entitäten im Text erkennen. snippets.py enthält anscheinend Code, der das tut. Kopieren Sie den Inhalt von snippets.py, erstellen Sie in Cloud Shell eine neue Datei mit dem Namen natural_language.py und fügen Sie den gesamten Code in natural_language.py ein. Sie können dies manuell im Cloud Shell-Code-Editor tun oder den folgenden curl-Befehl in Cloud Shell ausführen:
curl https://raw.githubusercontent.com/GoogleCloudPlatform/python-docs-samples/master/language/cloud-client/v1/snippets.py -o natural_language.py
Führen Sie dann in Cloud Shell den folgenden Befehl aus, um die API zu verwenden:
python natural_language.py entities-text 'where did you leave my bike'
Die API sollte „Fahrrad“ als Entität erkennen. Entitäten können Eigennamen (Personen des öffentlichen Lebens, Sehenswürdigkeiten usw.) oder Gattungsnamen (Restaurant, Stadion usw.) sein.
Worum geht es?
Sie haben zwei Argumente an natural_language.py übergeben:
- Mit entities-text wird die auszuführende Funktion
entities_text()ausgewählt. - where did you leave my bike ist der String, der auf Entitäten analysiert werden soll, und wird als text an
entities_text()übergeben.
Sehen wir uns entities_text() genauer an. Beachten Sie die neuen Kommentare, die eingefügt wurden.
def entities_text(text):
"""Detects entities in the text."""
# relevant imports from above
# from google.cloud import language
# from google.cloud.language import enums
# from google.cloud.language import types
# import six
# create LanguageServiceClient object
client = language.LanguageServiceClient()
# decode text if it's a binary type
# six is a python 2 and 3 compatibility library
if isinstance(text, six.binary_type):
text = text.decode('utf-8')
# Instantiates a plain text document.
document = types.Document(
content=text,
type=enums.Document.Type.PLAIN_TEXT)
# Detects entities in the document. You can also analyze HTML with:
# document.type == enums.Document.Type.HTML
entities = client.analyze_entities(document).entities
# entity types from enums.Entity.Type
entity_type = ('UNKNOWN', 'PERSON', 'LOCATION', 'ORGANIZATION',
'EVENT', 'WORK_OF_ART', 'CONSUMER_GOOD', 'OTHER')
# print information for each entity found
for entity in entities:
print('=' * 20)
print(u'{:<16}: {}'.format('name', entity.name))
print(u'{:<16}: {}'.format('type', entity_type[entity.type]))
print(u'{:<16}: {}'.format('metadata', entity.metadata))
print(u'{:<16}: {}'.format('salience', entity.salience))
print(u'{:<16}: {}'.format('wikipedia_url',
entity.metadata.get('wikipedia_url', '-')))
7. Einbinden
Sehen wir uns noch einmal an, was Sie entwickeln.
Jetzt wollen wir alles zusammenfügen. Erstellen Sie eine Datei mit dem Namen solution.py und kopieren Sie detect_labels_uri(), transcribe_gcs(), translate_text() und entities_text() aus den vorherigen Schritten in solution.py.
Importanweisungen
Entfernen Sie die Auskommentierung und verschieben Sie die Importanweisungen nach oben. Beachten Sie, dass sowohl speech.types als auch language.types importiert werden. Das wird zu Konflikten führen. Entfernen wir sie einfach und ändern wir jedes einzelne Vorkommen von types in transcribe_gcs() und entities_text() in speech.types bzw. language.types. Sie sollten nun Folgendes sehen:
from google.cloud import vision
from google.cloud import speech
from google.cloud import translate
from google.cloud import language
from google.cloud.language import enums
import six
Ergebnisse zurückgeben
Lassen Sie die Funktionen die Ergebnisse zurückgeben, anstatt sie auszugeben. Die Ausgabe sollte in etwa so aussehen:
# import statements
def detect_labels_uri(uri):
# code
# we only need the label descriptions
label_descriptions = []
for label in labels:
label_descriptions.append(label.description)
return label_descriptions
def transcribe_gcs(gcs_uri):
# code
# naive assumption that audio file is short
return response.results[0].alternatives[0].transcript
def translate_text(target, text):
# code
# only interested in translated text
return result['translatedText']
def entities_text(text):
# code
# we only need the entity names
entity_names = []
for entity in entities:
entity_names.append(entity.name)
return entity_names
Funktionen verwenden
Nach all der harten Arbeit können Sie diese Funktionen aufrufen. Nur zu! Beispiel:
def compare_audio_to_image(audio, image):
"""Checks whether a speech audio is relevant to an image."""
# speech audio -> text
transcription = transcribe_gcs(audio)
# text of any language -> english text
translation = translate_text('en', transcription)
# text -> entities
entities = entities_text(translation)
# image -> labels
labels = detect_labels_uri(image)
# naive check for whether entities intersect with labels
has_match = False
for entity in entities:
if entity in labels:
# print result for each match
print('The audio and image both contain: {}'.format(entity))
has_match = True
# print if there are no matches
if not has_match:
print('The audio and image do not appear to be related.')
Mehrere Sprachen unterstützen
Wir haben Türkisch zuvor in transcribe_gcs() fest codiert. Ändern wir das so, dass die Sprache über compare_audio_to_image() angegeben werden kann. Folgende Änderungen sind erforderlich:
def transcribe_gcs(language, gcs_uri):
...
config = speech.types.RecognitionConfig(language_code=language)
def compare_audio_to_image(language, audio, image):
transcription = transcribe_gcs(language, audio)
Ausprobieren
Der endgültige Code befindet sich in solution.py in diesem GitHub-Repository. Hier ist ein curl-Befehl, um das abzurufen:
curl https://raw.githubusercontent.com/googlecodelabs/integrating-ml-apis/master/solution.py -O
Die Version auf GitHub enthält „argparse“, was Folgendes über die Befehlszeile ermöglicht:
python solution.py tr-TR gs://cloud-samples-data/ml-api-codelab/tr-ball.wav gs://cloud-samples-data/ml-api-codelab/football.jpg
Für jedes gefundene Element sollte der Code „The audio and image both contain: “ ausgeben. Im Beispiel oben wäre das „The audio and image both contain: ball“.
Bonus: Mehr ausprobieren
Hier sind weitere Speicherorte für Audio- und Bilddateien, die Sie ausprobieren können.
8. Glückwunsch!
Sie haben vier APIs für maschinelles Lernen untersucht und integriert, um festzustellen, ob in einer Sprachprobe über das bereitgestellte Bild gesprochen wird. Das ist erst der Anfang, denn es gibt noch viele weitere Möglichkeiten, diese Pipeline zu verbessern.
Behandelte Themen
- Anfragen an die Cloud Vision API stellen
- Anfragen an die Cloud Speech-to-Text API stellen
- Anfragen an die Cloud Translation API stellen
- Anfragen an die Cloud Natural Language API stellen
- Alle oben genannten APIs zusammen verwenden
Nächste Schritte
- Für einen besseren Vergleich von Wörtern sollten Sie sich word2vec ansehen.
- Ausführlichere Codelabs zur Vision API, Speech-to-Text API, Translation API und Natural Language API
- Ersetzen Sie Cloud Vision durch Cloud Video Intelligence.
- Sprachaudio mit der Cloud Text-to-Speech API synthetisieren
- Objekte in Cloud Storage hochladen