
1. Prima di iniziare
In questo codelab, imparerai ad aggiornare il modello di classificazione del testo creato dal set di dati originale di commenti di spam sui blog, ma migliorato con i tuoi commenti in modo da avere un modello che funzioni con i tuoi dati.
Prerequisiti
Questo codelab fa parte del percorso Inizia a utilizzare la classificazione del testo nelle app Flutter. I codelab di questo percorso sono sequenziali. L'app e il modello su cui lavorerai devono essere stati creati in precedenza, mentre seguivi i codelab. Se non hai ancora completato le attività precedenti, interrompi la procedura e completale ora:
- Addestra un modello di rilevamento dello spam nei commenti con il codelab TensorFlow Lite Model Maker
- Codelab Crea un'app Flutter per rilevare i commenti spam
Obiettivi didattici
- Come aggiornare il modello di classificazione del testo che hai creato nel codelab Addestra un modello di rilevamento dello spam nei commenti con TensorFlow Lite Model Maker.
- Come personalizzare il modello in modo che blocchi lo spam più diffuso nella tua app.
Che cosa ti serve
- L'app Flutter e il modello di filtro antispam che hai osservato e creato nelle attività precedenti.
2. Migliorare la classificazione del testo
- Puoi ottenere il codice per questo codice clonando questo repository e caricando l'app dalla cartella
tfserving-flutter/codelab2/finished. - Dopo aver avviato l'immagine Docker di TensorFlow Serving, nell'app che hai creato, inserisci
buy my book to learn online tradinge poi fai clic su gRPC > Classifica.
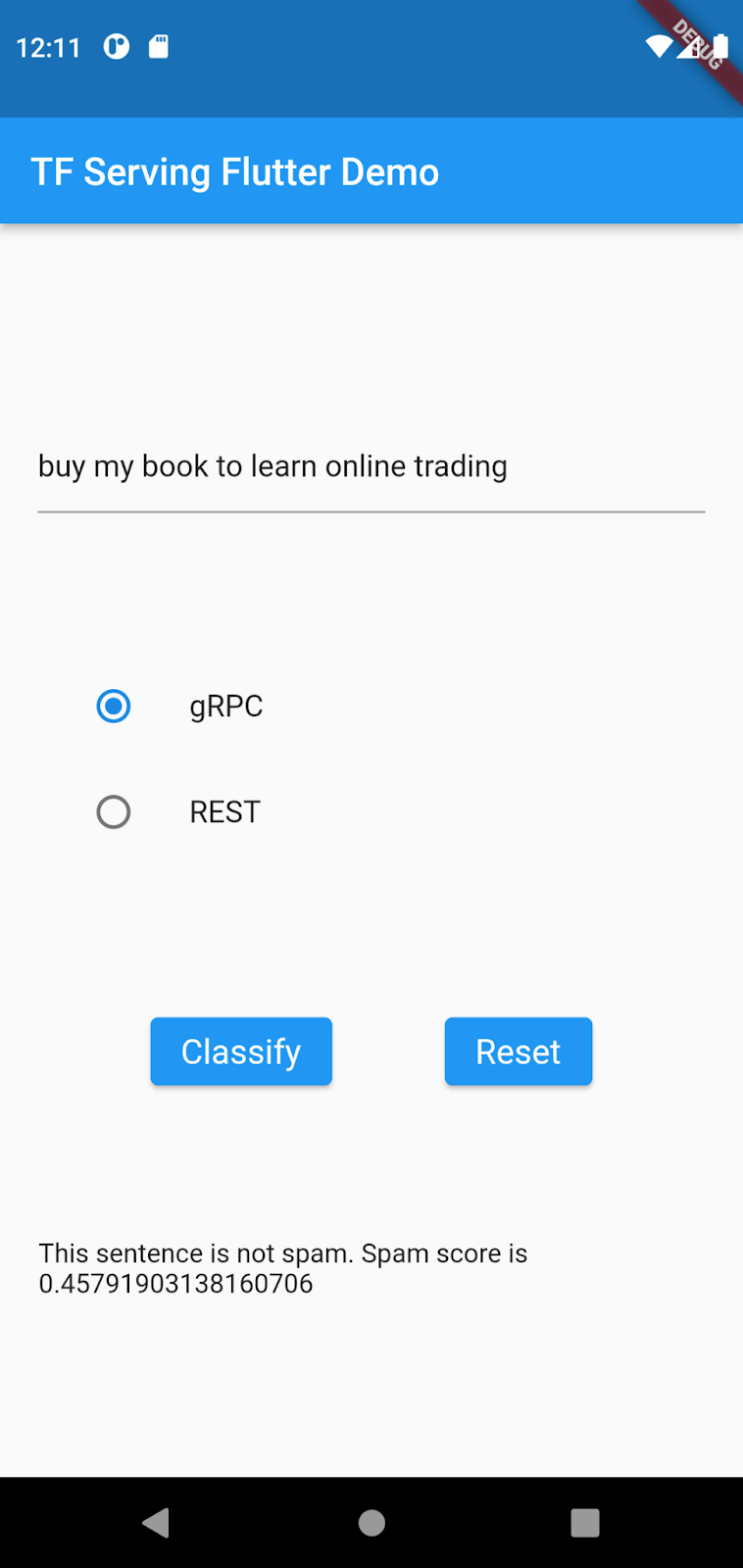
L'app genera un punteggio di spam basso perché non ci sono molte occorrenze di trading online nel set di dati originale e il modello non ha appreso che si tratta di spam. In questo codelab, aggiorni il modello con nuovi dati in modo che identifichi la stessa frase come spam.
3. Modificare il file CSV
Per addestrare il modello originale, è stato creato un set di dati in formato CSV (lmblog_comments.csv) contenente quasi mille commenti etichettati come spam o non spam. Apri il file CSV in qualsiasi editor di testo se vuoi esaminarlo.
La prima riga del file CSV deve descrivere le colonne, etichettate commenttext e spam. Ogni riga successiva segue questo formato:

L'etichetta a destra ha un valore true per lo spam e un valore false per non spam. Ad esempio, la terza riga è considerata spam.
Se gli utenti inviano spam al tuo sito web con messaggi sul trading online, puoi aggiungere esempi di commenti di spam in fondo al sito web. Ad esempio:
online trading can be highly highly effective,true online trading can be highly effective,true online trading now,true online trading here,true online trading for the win,true
- Salva il file con un nuovo nome, ad esempio
lmblog_comments.csv, in modo da poterlo utilizzare per addestrare un nuovo modello.
Per il resto di questo codelab, utilizzerai l'esempio fornito, modificato e ospitato su Cloud Storage con gli aggiornamenti di trading online. Se vuoi utilizzare il tuo set di dati, puoi modificare l'URL nel codice.
4. Riaddestra il modello con i nuovi dati
Per eseguire di nuovo l'addestramento del modello, puoi semplicemente riutilizzare il codice di (SpamCommentsModelMaker.ipynb), ma indirizzarlo al nuovo set di dati CSV, denominato lmblog_comments_extras.csv. Se vuoi il blocco note completo con i contenuti aggiornati, puoi trovarlo come SpamCommentsUpdateModelMaker.ipynb.
Se hai accesso a Colaboratory, puoi avviarlo direttamente. In caso contrario, recupera il codice dal repository ed eseguilo nell'ambiente notebook che preferisci.
Il codice aggiornato ha l'aspetto seguente:
training_data = tf.keras.utils.get_file(fname='comments-spam-extras.csv',
origin='https://storage.googleapis.com/laurencemoroney-blog.appspot.com/
lmblog_comments_extras.csv',
extract=False)
Durante l'addestramento, dovresti notare che il modello viene ancora addestrato a un elevato livello di accuratezza:

Comprimi l'intera cartella di /mm_update_spam_savedmodel e scarica il file mm_update_spam_savedmodel.zip generato.
# Rename the SavedModel subfolder to a version number
!mv /mm_update_spam_savedmodel/saved_model /mm_update_spam_savedmodel/123
!zip -r mm_update_spam_savedmodel.zip /mm_update_spam_savedmodel/
5. Avvia Docker e aggiorna l'app Flutter
- Decomprimi il file
mm_update_spam_savedmodel.zipscaricato in una cartella, quindi arresta l'istanza del container Docker del codelab precedente e riavviala, ma sostituisci il segnapostoPATH/TO/UPDATE/SAVEDMODELcon il percorso assoluto della cartella che ospita i file scaricati:
docker run -it --rm -p 8500:8500 -p 8501:8501 -v "PATH/TO/UPDATE/SAVEDMODEL:/models/spam-detection" -e MODEL_NAME=spam-detection tensorflow/serving
- Apri il file
lib/main.dartcon il tuo editor di codice preferito e poi trova la parte che definisce le variabiliinputTensorNameeoutTensorName:
const inputTensorName = 'input_3';
const outputTensorName = 'dense_5';
- Riassegna la variabile
inputTensorNamea un valore "input_1'" e la variabileoutputTensorNamea un valore'dense_1':
const inputTensorName = 'input_1';
const outputTensorName = 'dense_1';
- Copia il file
vocab.txtche hai scaricato nella cartellalib/assets/per sostituire quello esistente. - Rimuovi manualmente l'app Flutter di classificazione del testo dall'emulatore Android.
- Esegui il comando
'flutter run'nel terminale per avviare l'app. - Nell'app, inserisci
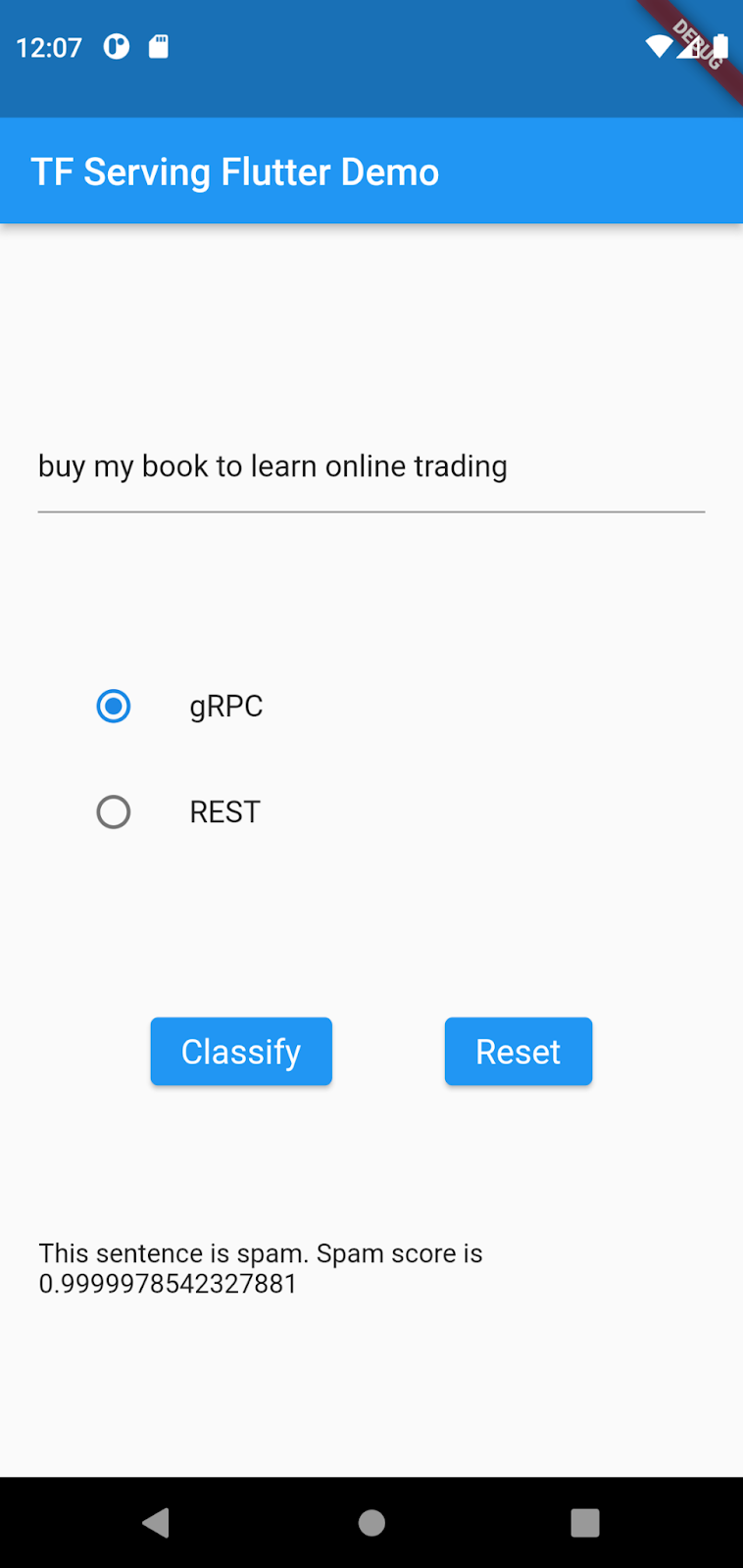
buy my book to learn online tradinge poi fai clic su gRPC > Classifica.
Ora il modello è stato migliorato per rilevare come spam i messaggi che vanno da acquista il mio libro al trading online.
6. Complimenti
Hai riaddestrato il modello con nuovi dati, lo hai integrato con l'app Flutter e hai aggiornato la funzionalità per rilevare nuove frasi di spam.