Checks Guardrails API, अब निजी झलकमें अल्फ़ा वर्शन में उपलब्ध है. हमारी दिलचस्पी दिखाने वाले फ़ॉर्म का इस्तेमाल करके, निजी झलक का ऐक्सेस पाने का अनुरोध करें.
Guardrails API एक ऐसा एपीआई है जिसकी मदद से यह पता लगाया जा सकता है कि टेक्स्ट, संभावित तौर पर नुकसान पहुंचाने वाला या असुरक्षित है या नहीं. अपने GenAI ऐप्लिकेशन में इस एपीआई का इस्तेमाल करके, अपने उपयोगकर्ताओं को संभावित तौर पर नुकसान पहुंचाने वाले कॉन्टेंट से बचाया जा सकता है.
Guardrails का इस्तेमाल कैसे करें?
Gen AI के इनपुट और आउटपुट पर Checks Guardrails का इस्तेमाल करके, अपनी नीतियों का उल्लंघन करने वाले टेक्स्ट की पहचान करें और उसे कम करें.
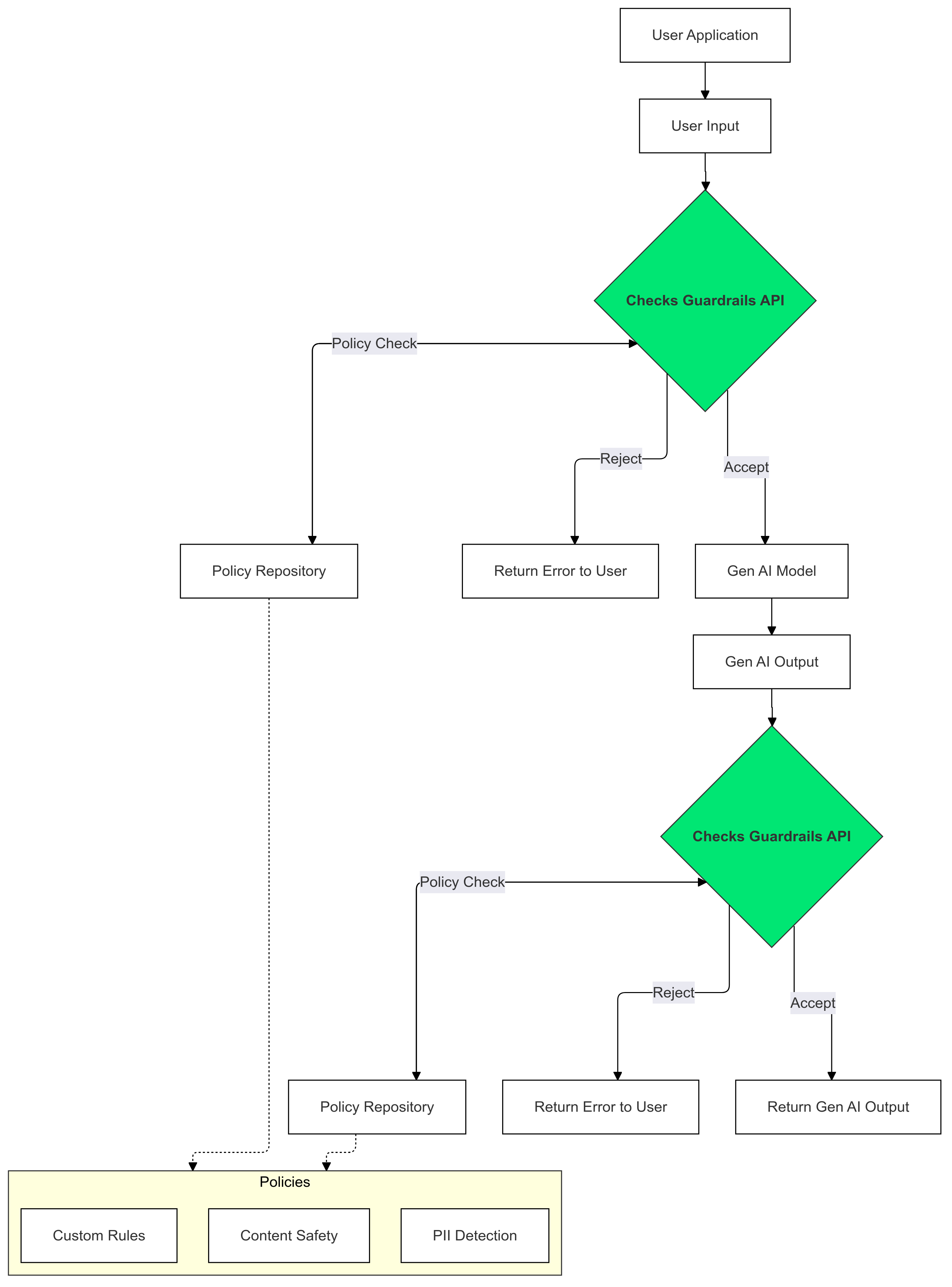
Guardrails का इस्तेमाल क्यों करें?
कभी-कभी एलएलएम, संभावित तौर पर नुकसान पहुंचाने वाला या आपत्तिजनक कॉन्टेंट जनरेट कर सकते हैं. अपने GenAI ऐप्लिकेशन में Guardrails API को इंटिग्रेट करना ज़रूरी है, ताकि लार्ज लैंग्वेज मॉडल (एलएलएम) का इस्तेमाल ज़िम्मेदारी और सुरक्षित तरीके से किया जा सके. यह जनरेट किए गए कॉन्टेंट से जुड़े जोखिमों को कम करने में आपकी मदद करता है. इसके लिए, यह संभावित तौर पर नुकसान पहुंचाने वाले कई तरह के आउटपुट को फ़िल्टर करता है. इनमें आपत्तिजनक भाषा, भेदभाव करने वाली टिप्पणियां, और ऐसा कॉन्टेंट शामिल है जिससे नुकसान हो सकता है. इससे न सिर्फ़ आपके उपयोगकर्ताओं को सुरक्षित रखा जा सकता है, बल्कि आपके ऐप्लिकेशन की प्रतिष्ठा भी बनी रहती है और आपके दर्शकों का भरोसा भी बढ़ता है. सुरक्षा और ज़िम्मेदारी को प्राथमिकता देकर, Guardrails आपको ऐसे GenAI ऐप्लिकेशन बनाने में मदद करता है जो इनोवेटिव होने के साथ-साथ सुरक्षित भी हों.
शुरू करना
इस गाइड में, आपके ऐप्लिकेशन में आपत्तिजनक कॉन्टेंट की पहचान करने और उसे फ़िल्टर करने के लिए, Guardrails API का इस्तेमाल करने के निर्देश दिए गए हैं. यह एपीआई, पहले से ट्रेन की गई कई नीतियां उपलब्ध कराता है. इनकी मदद से, संभावित तौर पर नुकसान पहुंचाने वाले अलग-अलग तरह के कॉन्टेंट की पहचान की जा सकती है. जैसे, नफ़रत फैलाने वाली भाषा, हिंसा, और साफ़ तौर पर सेक्शुअल ऐक्ट दिखाने वाला कॉन्टेंट. हर नीति के लिए थ्रेशोल्ड सेट करके, एपीआई के व्यवहार को भी पसंद के मुताबिक बनाया जा सकता है.
ज़रूरी शर्तें
- Checks AI Safety की निजी झलक के लिए, अपने Google Cloud प्रोजेक्ट को मंज़ूरी दिलाएं. अगर आपने पहले से ऐसा नहीं किया है, तो हमारी दिलचस्पी दिखाने वाले फ़ॉर्म का इस्तेमाल करके, ऐक्सेस का अनुरोध करें.
- Checks API को चालू करें.
- पक्का करें कि अनुमति देने से जुड़ी हमारी गाइड का इस्तेमाल करके, अनुमति वाले अनुरोध भेजे जा सकें.
काम करने वाली नीतियां
| नीति का नाम | नीति का ब्यौरा | नीति के टाइप के लिए एपीआई की एनम वैल्यू |
|---|---|---|
| खतरनाक कॉन्टेंट | ऐसा कॉन्टेंट जो नुकसान पहुंचाने वाले सामान, सेवाओं, और गतिविधियों को बढ़ावा देता है, उन्हें आसान बनाता है या उनका ऐक्सेस देता है. | DANGEROUS_CONTENT |
| पीआईआई के लिए अनुरोध करना और उसे सार्वजनिक करना | ऐसा कॉन्टेंट जो किसी व्यक्ति की संवेदनशील निजी जानकारी या डेटा के लिए अनुरोध करता है या उसे सार्वजनिक करता है. | PII_SOLICITING_RECITING |
| उत्पीड़न | ऐसा कॉन्टेंट जो किसी दूसरे व्यक्ति या लोगों के ग्रुप के लिए नुकसान पहुंचाने वाला, डराने वाला, धमकाने वाला या आपत्तिजनक हो. | HARASSMENT |
| साफ़ तौर पर सेक्शुअल ऐक्ट दिखाने वाला कॉन्टेंट | ऐसा कॉन्टेंट जो साफ़ तौर पर सेक्शुअल ऐक्ट दिखाता है. | SEXUALLY_EXPLICIT |
| नफ़रत फैलाने वाली भाषा | ऐसा कॉन्टेंट जिसे आम तौर पर नफ़रत फैलाने वाली भाषा माना जाता है. | HATE_SPEECH |
| स्वास्थ्य से जुड़ी जानकारी | ऐसे कॉन्टेंट का प्रमोशन करने की अनुमति नहीं है जो नुकसान पहुंचाने वाली स्वास्थ्य सलाह या दिशा-निर्देशों को बढ़ावा देता है, उन्हें आसान बनाता है या उनका ऐक्सेस देता है. | MEDICAL_INFO |
| हिंसा और खून-खराबे वाला कॉन्टेंट | ऐसा कॉन्टेंट जिसमें हिंसा और/या खून-खराबे को बिना किसी वजह के दिखाया गया हो. | VIOLENCE_AND_GORE |
| अश्लीलता और अपशब्दों का इस्तेमाल | ऐसे कॉन्टेंट का प्रमोशन करने की अनुमति नहीं है जिसमें अश्लील, गंदी या आपत्तिजनक भाषा का इस्तेमाल किया गया हो. | OBSCENITY_AND_PROFANITY |
कोड स्निपेट
Python
pip install
google-api-python-client चलाकर, Google API Python क्लाइंट इंस्टॉल करें.
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
SECRET_FILE_PATH = 'path/to/your/secret.json'
credentials = service_account.Credentials.from_service_account_file(
SECRET_FILE_PATH, scopes=['https://www.googleapis.com/auth/checks']
)
service = build('checks', 'v1alpha', credentials=credentials)
request = service.aisafety().classifyContent(
body={
'input': {
'textInput': {
'content': 'Mix, bake, cool, frost, and enjoy.',
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'}
], # Default Checks-defined threshold is used
}
)
response = request.execute()
for policy_result in response['policyResults']:
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
Go
go get google.golang.org/api/checks/v1alpha चलाकर, Checks API Go क्लाइंट इंस्टॉल करें.
package main
import (
"context"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
const credsFilePath = "path/to/your/secret.json"
func main() {
ctx := context.Background()
checksService, err := checks.NewService(
ctx,
option.WithEndpoint("https://checks.googleapis.com"),
option.WithCredentialsFile(credsFilePath),
option.WithScopes("https://www.googleapis.com/auth/checks"),
)
if err != nil {
// Handle error
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: "Mix, bake, cool, frost, and enjoy.",
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"}, // Default Checks-defined threshold is used
},
}
classificationResults, err := checksService.Aisafety.ClassifyContent(req).Do()
if err != nil {
// Handle error
}
for _, policy := range classificationResults.PolicyResults {
slog.Info("Checks Guardrails violation: ", "Policy", policy.PolicyType, "Score", policy.Score, "Violation Result", policy.ViolationResult)
}
}
REST
ध्यान दें: इस उदाहरण में, oauth2l सीएलआई टूल का इस्तेमाल किया गया है.
YOUR_GCP_PROJECT_ID की जगह, अपने Google Cloud प्रोजेक्ट का वह आईडी डालें जिसे Guardrails API का ऐक्सेस मिला है.
curl -X POST https://checks.googleapis.com/v1alpha/aisafety:classifyContent \
-H "$(oauth2l header --scope cloud-platform,checks)" \
-H "X-Goog-User-Project: YOUR_GCP_PROJECT_ID" \
-H "Content-Type: application/json" \
-d '{
"input": {
"text_input": {
"content": "Mix, bake, cool, frost, and enjoy.",
"language_code": "en"
}
},
"policies": [
{
"policy_type": "HARASSMENT",
"threshold": "0.5"
},
{
"policy_type": "DANGEROUS_CONTENT",
},
]
}'
रिस्पॉन्स का उदाहरण
{
"policyResults": [
{
"policyType": "HARASSMENT",
"score": 0.430,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "DANGEROUS_CONTENT",
"score": 0.764,
"violationResult": "VIOLATIVE"
},
{
"policyType": "OBSCENITY_AND_PROFANITY",
"score": 0.876,
"violationResult": "VIOLATIVE"
},
{
"policyType": "SEXUALLY_EXPLICIT",
"score": 0.197,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "HATE_SPEECH",
"score": 0.45,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "MEDICAL_INFO",
"score": 0.05,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "VIOLENCE_AND_GORE",
"score": 0.964,
"violationResult": "VIOLATIVE"
},
{
"policyType": "PII_SOLICITING_RECITING",
"score": 0.0009,
"violationResult": "NON_VIOLATIVE"
}
]
}
इस्तेमाल के उदाहरण
Guardrails API को अपने एलएलएम ऐप्लिकेशन में कई तरीकों से इंटिग्रेट किया जा सकता है. यह आपकी ज़रूरतों और जोखिम को बर्दाश्त करने की क्षमता पर निर्भर करता है. यहां कुछ सामान्य इस्तेमाल से जुड़े उदाहरण दिए गए हैं:
Guardrail का इस्तेमाल न करना - लॉगिंग
इस उदाहरण में, Guardrails API का इस्तेमाल, ऐप्लिकेशन के व्यवहार में कोई बदलाव किए बिना किया जाता है. हालांकि, निगरानी और ऑडिट के मकसद से, नीति के संभावित उल्लंघनों को लॉग किया जा रहा है. इस जानकारी का इस्तेमाल, एलएलएम की सुरक्षा से जुड़े संभावित जोखिमों की पहचान करने के लिए भी किया जा सकता है.
Python
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path):
self.scope = scope
self.creds_file_path = creds_file_path
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def log_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
log_violations(user_prompt)
llm_response = fetch_llm_response(user_prompt)
log_violations(llm_response, user_prompt)
print(llm_response)
Go
package main
import (
"context"
"fmt"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"},
{PolicyType: "HATE_SPEECH"},
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func logViolations(ctx context.Context, content string, context string) error {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return err
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
slog.Warn("Checks Guardrails violation: ", "Policy", policyResult.PolicyType, "Score", policyResult.Score, "Violation Result", policyResult.ViolationResult)
}
}
return nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
err := logViolations(ctx, userPrompt, "")
if err != nil {
// Handle error
}
llmResponse := fetchLLMResponse(userPrompt)
err = logViolations(ctx, llmResponse, userPrompt)
if err != nil {
// Handle error
}
fmt.Println(llmResponse)
}
किसी नीति के आधार पर Guardrail को ब्लॉक करना
इस उदाहरण में, Guardrails API, उपयोगकर्ता के असुरक्षित इनपुट और मॉडल के जवाबों को ब्लॉक करता है. यह पहले से तय की गई सुरक्षा नीतियों (जैसे, नफ़रत फैलाने वाली भाषा, खतरनाक कॉन्टेंट) के हिसाब से, दोनों की जांच करता है. इससे एआई को संभावित तौर पर नुकसान पहुंचाने वाले आउटपुट जनरेट करने से रोका जा सकता है. साथ ही, उपयोगकर्ताओं को आपत्तिजनक कॉन्टेंट से बचाया जा सकता है.
Python
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path, default_threshold):
self.scope = scope
self.creds_file_path = creds_file_path
self.default_threshold = default_threshold
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
default_threshold=0.6,
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{
'policyType': 'DANGEROUS_CONTENT',
'threshold': my_checks_config.default_threshold,
},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def has_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
return True
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
if has_violations(user_prompt):
print("Sorry, I can't help you with this request.")
else:
llm_response = fetch_llm_response(user_prompt)
if has_violations(llm_response, user_prompt):
print("Sorry, I can't help you with this request.")
else:
print(llm_response)
Go
package main
import (
"context"
"fmt"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
defaultThreshold float64
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
defaultThreshold: 0.6,
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT", Threshold: myChecksConfig.defaultThreshold},
{PolicyType: "HATE_SPEECH"}, // default Checks-defined threshold is used
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func hasViolations(ctx context.Context, content string, context string) (bool, error) {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return false, fmt.Errorf("failed to classify content: %w", err)
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
return true, nil
}
}
return false, nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
hasInputViolations, err := hasViolations(ctx, userPrompt, "")
if err == nil && hasInputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
llmResponse := fetchLLMResponse(userPrompt)
hasOutputViolations, err := hasViolations(ctx, llmResponse, userPrompt)
if err == nil && hasOutputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
fmt.Println(llmResponse)
}
एलएलएम के आउटपुट को Guardrails पर स्ट्रीम करना
यहां दिए गए उदाहरणों में, हम किसी एलएलएम के आउटपुट को Guardrails API पर स्ट्रीम करते हैं. इसका इस्तेमाल, उपयोगकर्ता की नज़र में दिखने वाली लेटेन्सी को कम करने के लिए किया जा सकता है. अधूरे कॉन्टेक्स्ट की वजह से, इस तरीके से फ़ॉल्स पॉज़िटिव आ सकते हैं. इसलिए, यह ज़रूरी है कि एलएलएम के आउटपुट में इतना कॉन्टेक्स्ट हो कि एपीआई को कॉल करने से पहले, Guardrails सटीक आकलन कर सके.
Guardrails को सिंक्रोनस कॉल करना
Python
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
while not my_llm_model.finished:
chunk = my_llm_model.next_chunk()
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
Go
func main() {
ctx := context.Background()
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
var llmResponse string
for !model.finished {
chunk := model.nextChunk()
llmResponse += chunk + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
Guardrails को एसिंक्रोनस कॉल करना
Python
async def main():
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
async for chunk in my_llm_model:
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
asyncio.run(main())
Go
func main() {
var textChannel = make(chan string)
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
var llmResponse string
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
go model.streamToChannel(textChannel)
for text := range textChannel {
llmResponse += text + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
अक्सर पूछे जाने वाले सवाल
अगर मैंने Guardrails API के लिए, अपने कोटे की सीमाएं पार कर ली हैं, तो मुझे क्या करना चाहिए?
कोटा बढ़ाने का अनुरोध करने के लिए, checks-support@google.com पर ईमेल भेजें और उसमें अपना अनुरोध शामिल करें. अपने ईमेल में यह जानकारी शामिल करें:
- आपके Google Cloud प्रोजेक्ट का नंबर: इससे हमें आपके खाते की पहचान करने में मदद मिलती है.
- इस्तेमाल के उदाहरण के बारे में जानकारी: बताएं कि आपने Guardrails API का इस्तेमाल कैसे किया है.
- कोटे की ज़रूरी रकम: बताएं कि आपको कितना अतिरिक्त कोटा चाहिए.