تتوفّر الآن واجهة برمجة التطبيقات Checks Guardrails في إصدار ألفا ضمن البرنامج التجريبي الخاص . يمكنك طلب الوصول إلى البرنامج التجريبي الخاص باستخدام نموذج الاهتمام.
واجهة برمجة التطبيقات Guardrails هي واجهة تتيح لك التحقّق مما إذا كان النص قد يكون ضارًا أو غير آمن. يمكنك استخدام واجهة برمجة التطبيقات هذه في تطبيق الذكاء الاصطناعي التوليدي لمنع المستخدمين من التعرّض لمحتوى ضارّ.
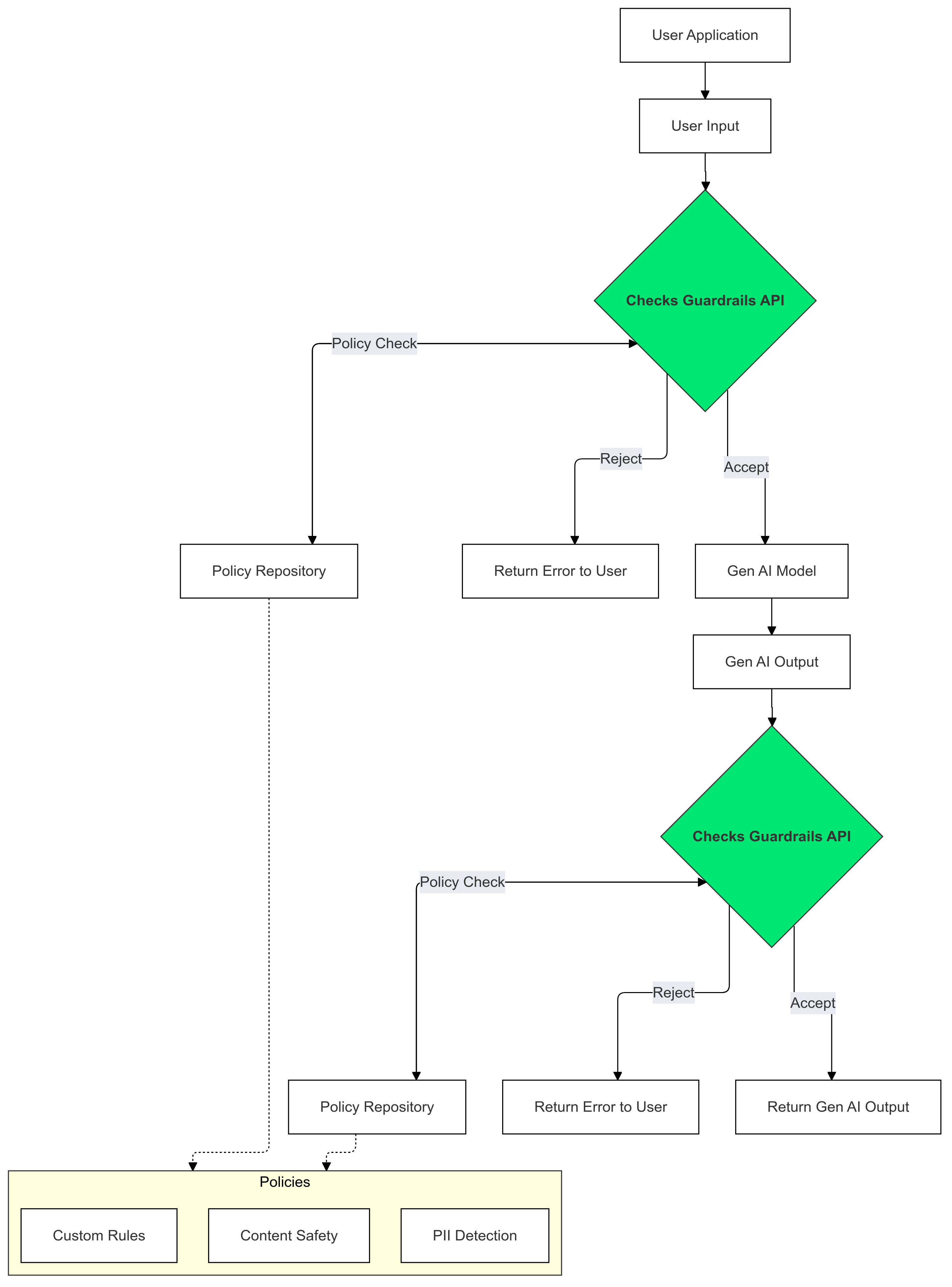
كيفية استخدام ضوابط الحماية
يمكنك استخدام ميزة "ضوابط الحماية في Checks" على مدخلات ومخرجات الذكاء الاصطناعي التوليدي لرصد النص الذي يخالف سياساتك والتخفيف من تأثيره.
ما هي مزايا استخدام ضوابط الحماية؟
يمكن أن تنشئ النماذج اللغوية الكبيرة أحيانًا محتوًى قد يكون ضارًا أو غير ملائم. إنّ دمج واجهة برمجة التطبيقات Guardrails في تطبيق الذكاء الاصطناعي التوليدي أمر ضروري لضمان الاستخدام المسؤول والآمن للنماذج اللغوية الكبيرة. تساعدك هذه الواجهة في التخفيف من المخاطر المرتبطة بالمحتوى الذي يتم إنشاؤه من خلال استبعاد مجموعة كبيرة من المخرجات التي قد تكون ضارة، بما في ذلك اللغة غير الملائمة والملاحظات التمييزية والمحتوى الذي قد يسهّل إلحاق الضرر. لا يحمي ذلك المستخدمين فحسب، بل يحافظ أيضًا على سمعة تطبيقك ويعزّز الثقة بين جمهورك. من خلال إعطاء الأولوية للسلامة والمسؤولية، تمنحك ضوابط الحماية إمكانية إنشاء تطبيقات ذكاء اصطناعي توليدي مبتكرة وآمنة في الوقت نفسه.
الخطوات الأولى
يقدّم هذا الدليل تعليمات حول كيفية استخدام واجهة برمجة التطبيقات Guardrails لرصد المحتوى غير الملائم في تطبيقاتك واستبعاده. توفّر واجهة برمجة التطبيقات مجموعة متنوّعة من السياسات المدرَّبة مسبقًا التي يمكنها تحديد أنواع مختلفة من المحتوى الذي قد يكون ضارًا، مثل كلام يحض على الكراهية والعنف والمواد الجنسية الفاضحة. يمكنك أيضًا تخصيص سلوك واجهة برمجة التطبيقات من خلال ضبط الحدود القصوى لكل سياسة.
المتطلبات الأساسية
- يجب أن يكون مشروعك على Google Cloud معتمَدًا للبرنامج التجريبي الخاص بميزة "الأمان في الذكاء الاصطناعي في Checks". إذا لم يسبق لك ذلك، يمكنك طلب الوصول باستخدام نموذج الاهتمام.
- يجب تفعيل واجهة برمجة التطبيقات Checks API.
- يجب أن تكون قادرًا على إرسال طلبات مُرخَّصة باستخدام دليل التفويض .
السياسات المتوافقة
| اسم السياسة | وصف السياسة | قيمة تعداد واجهة برمجة التطبيقات لنوع السياسة |
|---|---|---|
| المحتوى الخطير | المحتوى الذي يسهّل الوصول إلى السلع والخدمات والأنشطة الضارة أو يروّج لها أو يتيحها | DANGEROUS_CONTENT |
| طلب معلومات تكشف الهوية الشخصية وتلاوتها | المحتوى الذي يطلب معلومات شخصية حسّاسة أو بيانات خاصة بفرد أو يكشفها | PII_SOLICITING_RECITING |
| المضايقة | المحتوى الذي يكون خبيثًا أو مخيفًا أو متسلّطًا أو مسيئًا تجاه فرد أو أفراد آخرين | HARASSMENT |
| المحتوى الجنسي الفاضح | المحتوى الذي يكون جنسيًا فاضحًا بطبيعته | SEXUALLY_EXPLICIT |
| كلام يحض على الكراهية | المحتوى الذي يُقبل عمومًا على أنّه كلام يحض على الكراهية. | HATE_SPEECH |
| المعلومات الطبية | يُحظر المحتوى الذي يسهّل الوصول إلى نصائح أو إرشادات طبية ضارة أو يروّج لها أو يتيحها. | MEDICAL_INFO |
| العنف والمحتوى الدموي | المحتوى الذي يتضمّن أوصافًا غير مبرَّرة للعنف الواقعي و/أو المحتوى الدموي | VIOLENCE_AND_GORE |
| المحتوى الفاحش واللغة النابية | يُحظر المحتوى الذي يتضمّن لغة فاحشة أو بذيئة أو مسيئة. | OBSCENITY_AND_PROFANITY |
مقتطفات الرمز البرمجي
Python
يمكنك تثبيت حزمة Google API Python client من خلال تنفيذ الأمر pip install
google-api-python-client.
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
SECRET_FILE_PATH = 'path/to/your/secret.json'
credentials = service_account.Credentials.from_service_account_file(
SECRET_FILE_PATH, scopes=['https://www.googleapis.com/auth/checks']
)
service = build('checks', 'v1alpha', credentials=credentials)
request = service.aisafety().classifyContent(
body={
'input': {
'textInput': {
'content': 'Mix, bake, cool, frost, and enjoy.',
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'}
], # Default Checks-defined threshold is used
}
)
response = request.execute()
for policy_result in response['policyResults']:
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
انتقال
يمكنك تثبيت حزمة Checks API Go Client من خلال تنفيذ الأمر go get google.golang.org/api/checks/v1alpha.
package main
import (
"context"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
const credsFilePath = "path/to/your/secret.json"
func main() {
ctx := context.Background()
checksService, err := checks.NewService(
ctx,
option.WithEndpoint("https://checks.googleapis.com"),
option.WithCredentialsFile(credsFilePath),
option.WithScopes("https://www.googleapis.com/auth/checks"),
)
if err != nil {
// Handle error
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: "Mix, bake, cool, frost, and enjoy.",
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"}, // Default Checks-defined threshold is used
},
}
classificationResults, err := checksService.Aisafety.ClassifyContent(req).Do()
if err != nil {
// Handle error
}
for _, policy := range classificationResults.PolicyResults {
slog.Info("Checks Guardrails violation: ", "Policy", policy.PolicyType, "Score", policy.Score, "Violation Result", policy.ViolationResult)
}
}
راحة
ملاحظة: يستخدم هذا المثال oauth2l أداة سطر الأوامر.
عليك استبدال YOUR_GCP_PROJECT_ID برقم تعريف مشروعك على Google Cloud الذي تم منح إذن الوصول إلى واجهة برمجة التطبيقات Guardrails فيه.
curl -X POST https://checks.googleapis.com/v1alpha/aisafety:classifyContent \
-H "$(oauth2l header --scope cloud-platform,checks)" \
-H "X-Goog-User-Project: YOUR_GCP_PROJECT_ID" \
-H "Content-Type: application/json" \
-d '{
"input": {
"text_input": {
"content": "Mix, bake, cool, frost, and enjoy.",
"language_code": "en"
}
},
"policies": [
{
"policy_type": "HARASSMENT",
"threshold": "0.5"
},
{
"policy_type": "DANGEROUS_CONTENT",
},
]
}'
نموذج إجابة
{
"policyResults": [
{
"policyType": "HARASSMENT",
"score": 0.430,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "DANGEROUS_CONTENT",
"score": 0.764,
"violationResult": "VIOLATIVE"
},
{
"policyType": "OBSCENITY_AND_PROFANITY",
"score": 0.876,
"violationResult": "VIOLATIVE"
},
{
"policyType": "SEXUALLY_EXPLICIT",
"score": 0.197,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "HATE_SPEECH",
"score": 0.45,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "MEDICAL_INFO",
"score": 0.05,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "VIOLENCE_AND_GORE",
"score": 0.964,
"violationResult": "VIOLATIVE"
},
{
"policyType": "PII_SOLICITING_RECITING",
"score": 0.0009,
"violationResult": "NON_VIOLATIVE"
}
]
}
حالات الاستخدام
يمكن دمج واجهة برمجة التطبيقات Guardrails في تطبيق النموذج اللغوي الكبير بطرق متنوّعة، وذلك حسب احتياجاتك المحدّدة ومستوى تحمّلك للمخاطر. في ما يلي بعض الأمثلة على حالات الاستخدام الشائعة:
عدم تدخّل ضوابط الحماية - التسجيل
في هذا السيناريو، يتم استخدام واجهة برمجة التطبيقات Guardrails بدون إجراء أي تغييرات على سلوك التطبيق. ومع ذلك، يتم تسجيل الانتهاكات المحتمَلة للسياسة لأغراض المراقبة والتدقيق. يمكن استخدام هذه المعلومات أيضًا لرصد المخاطر المحتمَلة على سلامة النموذج اللغوي الكبير.
Python
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path):
self.scope = scope
self.creds_file_path = creds_file_path
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def log_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
log_violations(user_prompt)
llm_response = fetch_llm_response(user_prompt)
log_violations(llm_response, user_prompt)
print(llm_response)
انتقال
package main
import (
"context"
"fmt"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"},
{PolicyType: "HATE_SPEECH"},
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func logViolations(ctx context.Context, content string, context string) error {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return err
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
slog.Warn("Checks Guardrails violation: ", "Policy", policyResult.PolicyType, "Score", policyResult.Score, "Violation Result", policyResult.ViolationResult)
}
}
return nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
err := logViolations(ctx, userPrompt, "")
if err != nil {
// Handle error
}
llmResponse := fetchLLMResponse(userPrompt)
err = logViolations(ctx, llmResponse, userPrompt)
if err != nil {
// Handle error
}
fmt.Println(llmResponse)
}
حظر ضوابط الحماية استنادًا إلى سياسة
في هذا المثال، تحظر واجهة برمجة التطبيقات Guardrails مدخلات المستخدم غير الآمنة وردود النموذج. وتتحقّق هذه الواجهة من المدخلات والردود استنادًا إلى سياسات الأمان المحدّدة مسبقًا (مثل كلام يحض على الكراهية والمحتوى الخطير). يمنع ذلك الذكاء الاصطناعي من إنشاء مخرجات قد تكون ضارة ويحمي المستخدمين من التعرّض لمحتوى غير ملائم.
Python
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path, default_threshold):
self.scope = scope
self.creds_file_path = creds_file_path
self.default_threshold = default_threshold
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
default_threshold=0.6,
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{
'policyType': 'DANGEROUS_CONTENT',
'threshold': my_checks_config.default_threshold,
},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def has_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
return True
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
if has_violations(user_prompt):
print("Sorry, I can't help you with this request.")
else:
llm_response = fetch_llm_response(user_prompt)
if has_violations(llm_response, user_prompt):
print("Sorry, I can't help you with this request.")
else:
print(llm_response)
انتقال
package main
import (
"context"
"fmt"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
defaultThreshold float64
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
defaultThreshold: 0.6,
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT", Threshold: myChecksConfig.defaultThreshold},
{PolicyType: "HATE_SPEECH"}, // default Checks-defined threshold is used
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func hasViolations(ctx context.Context, content string, context string) (bool, error) {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return false, fmt.Errorf("failed to classify content: %w", err)
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
return true, nil
}
}
return false, nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
hasInputViolations, err := hasViolations(ctx, userPrompt, "")
if err == nil && hasInputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
llmResponse := fetchLLMResponse(userPrompt)
hasOutputViolations, err := hasViolations(ctx, llmResponse, userPrompt)
if err == nil && hasOutputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
fmt.Println(llmResponse)
}
نقل مخرجات النموذج اللغوي الكبير إلى ضوابط الحماية
في الأمثلة التالية، ننقل مخرجات من نموذج لغوي كبير إلى واجهة برمجة التطبيقات Guardrails. يمكن استخدام ذلك لتقليل فترة الانتظار التي يلاحظها المستخدم. يمكن أن يؤدي هذا النهج إلى ظهور نتائج إيجابية خاطئة بسبب السياق غير المكتمل، لذا من المهم أن تتضمّن مخرجات النموذج اللغوي الكبير سياقًا كافيًا لكي تتمكّن ضوابط الحماية من إجراء تقييم دقيق قبل طلب واجهة برمجة التطبيقات.
طلبات متزامنة إلى ضوابط الحماية
Python
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
while not my_llm_model.finished:
chunk = my_llm_model.next_chunk()
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
انتقال
func main() {
ctx := context.Background()
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
var llmResponse string
for !model.finished {
chunk := model.nextChunk()
llmResponse += chunk + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
طلبات غير متزامنة إلى ضوابط الحماية
Python
async def main():
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
async for chunk in my_llm_model:
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
asyncio.run(main())
انتقال
func main() {
var textChannel = make(chan string)
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
var llmResponse string
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
go model.streamToChannel(textChannel)
for text := range textChannel {
llmResponse += text + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
الأسئلة الشائعة
ماذا عليّ أن أفعل إذا بلغتُ حدود الحصة المخصّصة لي في واجهة برمجة التطبيقات Guardrails؟
لطلب زيادة الحصة، يُرجى إرسال رسالة إلكترونية إلى checks-support@google.com تتضمّن طلبك. يُرجى تضمين المعلومات التالية في رسالتك الإلكترونية:
- رقم مشروعك على Google Cloud: يساعدنا ذلك في تحديد حسابك بسرعة.
- تفاصيل حول حالة الاستخدام: يُرجى شرح كيفية استخدامك لواجهة برمجة التطبيقات Guardrails.
- مقدار الحصة المطلوبة: يُرجى تحديد مقدار الحصة الإضافية التي تحتاج إليها.