
নিম্নলিখিত সেরা অনুশীলনগুলি আপনাকে গোপনীয়তা-কেন্দ্রিক এবং উচ্চ কার্যক্ষমতাসম্পন্ন কোয়েরি তৈরি করার কৌশল প্রদান করবে। নয়েজ মোডে কোয়েরি চালানোর নির্দিষ্ট সেরা অনুশীলনের জন্য, 'নয়েজ ইনজেকশন'- এর সমর্থিত এবং অসমর্থিত কোয়েরি প্যাটার্ন সম্পর্কিত বিভাগগুলি দেখুন।
গোপনীয়তা এবং ডেটার নির্ভুলতা
স্যান্ডবক্স ডেটার উপর কোয়েরি তৈরি করুন
সর্বোত্তম পন্থা : শুধুমাত্র প্রোডাকশনে থাকাকালীনই প্রোডাকশন ডেটা কোয়েরি করুন।
আপনার কোয়েরি তৈরির সময় যখনই সম্ভব স্যান্ডবক্স ডেটা ব্যবহার করুন। স্যান্ডবক্স ডেটা ব্যবহারকারী জবগুলো আপনার কোয়েরির ফলাফল ফিল্টার করার জন্য পার্থক্য যাচাইয়ের অতিরিক্ত সুযোগ তৈরি করে না। এছাড়াও, গোপনীয়তা যাচাইয়ের অনুপস্থিতির কারণে স্যান্ডবক্স কোয়েরিগুলো দ্রুত চলে, যা কোয়েরি তৈরির সময় আরও দ্রুত পুনরাবৃত্তির সুযোগ করে দেয়।
যদি আপনাকে আপনার আসল ডেটার উপর কোয়েরি তৈরি করতে হয় (যেমন ম্যাচ টেবিল ব্যবহার করার সময়), তাহলে সারি ওভারল্যাপ হওয়ার সম্ভাবনা কমাতে, আপনার কোয়েরির প্রতিটি পুনরাবৃত্তির জন্য এমন তারিখের পরিসর এবং অন্যান্য প্যারামিটার বেছে নিন যেগুলো ওভারল্যাপ হওয়ার সম্ভাবনা কম। সবশেষে, ডেটার কাঙ্ক্ষিত পরিসরের উপর আপনার কোয়েরিটি চালান।
ঐতিহাসিক ফলাফলগুলো সাবধানে বিবেচনা করুন।
সর্বোত্তম পন্থা : সম্প্রতি চালানো কোয়েরিগুলোর ফলাফল সেটের মধ্যে ওভারল্যাপের সম্ভাবনা হ্রাস করুন।
মনে রাখবেন যে, কোয়েরির ফলাফলের পরিবর্তনের হারের ওপর নির্ভর করে পরবর্তীতে গোপনীয়তা যাচাইয়ের কারণে কোনো ফলাফল বাদ পড়ার সম্ভাবনা থাকে। সম্প্রতি প্রাপ্ত কোনো ফলাফলের সেটের সাথে ঘনিষ্ঠভাবে সাদৃশ্যপূর্ণ দ্বিতীয় কোনো ফলাফল সেট বাদ পড়ে যাওয়ার সম্ভাবনা থাকে।
এর পরিবর্তে, উল্লেখযোগ্য ওভারল্যাপের সম্ভাবনা কমাতে আপনার কোয়েরির মূল প্যারামিটারগুলো, যেমন তারিখের পরিসীমা বা ক্যাম্পেইন আইডি, পরিবর্তন করুন।
আজকের ডেটা কোয়েরি করবেন না।
সর্বোত্তম পন্থা : একাধিক কোয়েরি চালাবেন না যেখানে শেষ তারিখটি আজকের দিন।
আজকের দিনকে শেষ তারিখ ধরে একাধিক কোয়েরি চালালে প্রায়শই সারিগুলো ফিল্টার হয়ে যায়। এই নির্দেশনাটি গতকালের ডেটার ওপর মধ্যরাতের কিছুক্ষণ পরে কোয়েরি চালানোর ক্ষেত্রেও প্রযোজ্য।
প্রয়োজনের চেয়ে বেশিবার একই ডেটা কোয়েরি করবেন না।
সর্বোত্তম অনুশীলন :
- সুনির্দিষ্ট শুরু এবং শেষের তারিখ নির্বাচন করুন।
- ওভারল্যাপিং উইন্ডোতে কোয়েরি করার পরিবর্তে, আপনার কোয়েরিগুলো বিচ্ছিন্ন ডেটা সেটের উপর চালান, তারপর BigQuery-তে ফলাফলগুলো অ্যাগ্রিগেট করুন।
- আপনার কোয়েরিটি পুনরায় চালানোর পরিবর্তে সংরক্ষিত ফলাফল ব্যবহার করুন।
- আপনি যে প্রতিটি তারিখের পরিসরের উপর কোয়েরি করছেন, তার জন্য অস্থায়ী টেবিল তৈরি করুন।
অ্যাডস ডেটা হাব একই ডেটা কতবার কোয়েরি করা যাবে তার উপর সীমাবদ্ধতা আরোপ করে। তাই, আপনার উচিত কোনো নির্দিষ্ট ডেটা কতবার অ্যাক্সেস করবেন তা সীমিত রাখার চেষ্টা করা।
একই কোয়েরিতে প্রয়োজনের চেয়ে বেশি অ্যাগ্রিগেশন ব্যবহার করবেন না।
সর্বোত্তম অনুশীলন:
- একটি কোয়েরিতে অ্যাগ্রিগেশনের সংখ্যা সর্বনিম্ন করুন।
- সম্ভব হলে অ্যাগ্রিগেশন একত্রিত করতে কোয়েরিগুলো পুনর্লিখন করুন।
অ্যাডস ডেটা হাব একটি সাবকোয়েরিতে ব্যবহারের জন্য ক্রস-ইউজার অ্যাগ্রিগেশনের সংখ্যা ১০০-তে সীমাবদ্ধ করে। তাই, আমরা সাধারণত এমন কোয়েরি লেখার পরামর্শ দিই যা বিস্তৃত গ্রুপিং কী এবং জটিল অ্যাগ্রিগেশনযুক্ত বেশি কলামের পরিবর্তে, সুনির্দিষ্ট গ্রুপিং কী এবং সাধারণ অ্যাগ্রিগেশনযুক্ত বেশি সারি আউটপুট করে। নিম্নলিখিত প্যাটার্নটি পরিহার করা উচিত:
SELECT
COUNTIF(field_1 = a_1 AND field_2 = b_1) AS cnt_1,
COUNTIF(field_1 = a_2 AND field_2 = b_2) AS cnt_2
FROM
table
যেসব কোয়েরি একই ফিল্ডের ওপর ভিত্তি করে ইভেন্ট গণনা করে, সেগুলোকে GROUP BY স্টেটমেন্ট ব্যবহার করে নতুন করে লেখা উচিত।
SELECT
field_1,
field_2,
COUNT(1) AS cnt
FROM
table
GROUP BY
1, 2
BigQuery-তেও ফলাফলটি একইভাবে একত্রিত করা যায়।
যেসব কোয়েরি একটি অ্যারে থেকে কলাম তৈরি করে এবং পরে সেগুলোকে একত্রিত করে, সেগুলোকে এই ধাপগুলো একীভূত করার জন্য নতুন করে লেখা উচিত।
SELECT
COUNTIF(a_1) AS cnt_1,
COUNTIF(a_2) AS cnt_2
FROM
(SELECT
1 IN UNNEST(field) AS a_1,
2 IN UNNEST(field) AS a_2,
FROM
table)
পূর্ববর্তী কোয়েরিটি নিম্নরূপে পুনরায় লেখা যেতে পারে:
SELECT f, COUNT(1) FROM table, UNNEST(field) AS f GROUP BY 1
যেসব কোয়েরিতে বিভিন্ন অ্যাগ্রিগেশনে ফিল্ডের নানা সংমিশ্রণ ব্যবহৃত হয়, সেগুলোকে কয়েকটি আরও সুনির্দিষ্ট কোয়েরিতে পুনর্লিখন করা যেতে পারে।
SELECT
COUNTIF(field_1 = a_1) AS cnt_a_1,
COUNTIF(field_1 = b_1) AS cnt_b_1,
COUNTIF(field_2 = a_2) AS cnt_a_2,
COUNTIF(field_2 = b_2) AS cnt_b_2,
FROM table
পূর্ববর্তী কোয়েরিটিকে নিম্নলিখিতভাবে বিভক্ত করা যেতে পারে:
SELECT
field_1, COUNT(*) AS cnt
FROM table
GROUP BY 1
এবং
SELECT
field_2, COUNT(*) AS cnt
FROM table
GROUP BY 1
আপনি এই ফলাফলগুলিকে আলাদা কোয়েরিতে ভাগ করতে পারেন, একটি একক কোয়েরিতে টেবিলগুলি তৈরি ও যুক্ত করতে পারেন, অথবা স্কিমা সামঞ্জস্যপূর্ণ হলে সেগুলিকে UNION দিয়ে একত্রিত করতে পারেন।
সংযোগগুলি অপ্টিমাইজ করুন এবং বুঝুন
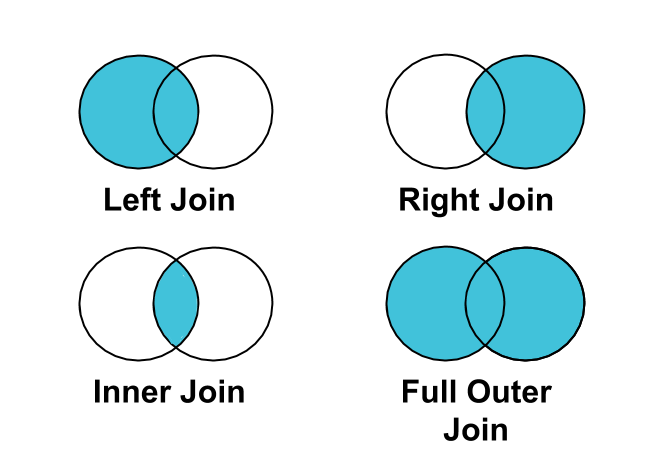
সর্বোত্তম পদ্ধতি : ক্লিক বা কনভার্সনকে ইম্প্রেশনের সাথে যুক্ত করতে INNER JOIN এর পরিবর্তে LEFT JOIN ব্যবহার করুন।
সব ইম্প্রেশনই ক্লিক বা কনভার্সনের সাথে যুক্ত থাকে না। তাই, আপনি যদি ইম্প্রেশনের উপর ভিত্তি করে ক্লিক বা কনভার্সনকে INNER JOIN , তাহলে যে ইম্প্রেশনগুলো ক্লিক বা কনভার্সনের সাথে যুক্ত নয়, সেগুলো আপনার ফলাফল থেকে ফিল্টার হয়ে যাবে।
BigQuery-তে কিছু চূড়ান্ত ফলাফল একত্রিত করুন
সর্বোত্তম পন্থা : অ্যাডস ডেটা হাব (Ads Data Hub) কোয়েরি ব্যবহার করা থেকে বিরত থাকুন যা একত্রিত ফলাফল (aggregated results) যুক্ত করে। এর পরিবর্তে, দুটি পৃথক কোয়েরি লিখুন এবং বিগকোয়েরি (BigQuery)-তে ফলাফলগুলো যুক্ত করুন।
যে সারিগুলো অ্যাগ্রিগেশন শর্ত পূরণ করে না, সেগুলো আপনার ফলাফল থেকে ফিল্টার করে বাদ দেওয়া হয়। সুতরাং, যদি আপনার কোয়েরি একটি অপর্যাপ্তভাবে অ্যাগ্রিগেটেড সারির সাথে একটি পর্যাপ্তভাবে অ্যাগ্রিগেটেড সারিকে যুক্ত করে, তাহলে ফলাফলস্বরূপ প্রাপ্ত সারিটি ফিল্টার হয়ে যাবে। এছাড়াও, অ্যাডস ডেটা হাব-এ একাধিক অ্যাগ্রিগেশনযুক্ত কোয়েরিগুলোর পারফরম্যান্স কম হয়।
আপনি Ads Data Hub থেকে একাধিক অ্যাগ্রিগেশন কোয়েরির ফলাফল BigQuery-তে যুক্ত করতে পারেন। একই কোয়েরি ব্যবহার করে গণনা করা ফলাফলগুলোর চূড়ান্ত স্কিমা একই থাকবে।
নিম্নলিখিত কোয়েরিটি Ads Data Hub-এর স্বতন্ত্র ফলাফল ( campaign_data_123 এবং campaign_data_456 ) গ্রহণ করে এবং BigQuery-তে সেগুলোকে যুক্ত করে:
SELECT t1.campaign_id, t1.city, t1.X, t2.Y
FROM `campaign_data_123` AS t1
FULL JOIN `campaign_data_456` AS t2
USING (campaign_id, city)
ফিল্টার করা সারি সারাংশ ব্যবহার করুন
সর্বোত্তম পন্থা : আপনার কোয়েরিগুলোতে ফিল্টার করা সারির সারাংশ যোগ করুন।
ফিল্টার করা সারির সারাংশ গোপনীয়তা যাচাইয়ের কারণে ফিল্টার করা ডেটার হিসাব রাখে। ফিল্টার করা সারিগুলোর ডেটা যোগ করে একটি সাধারণ সারিতে যুক্ত করা হয়। যদিও ফিল্টার করা ডেটা আরও বিশ্লেষণ করা যায় না, এটি ফলাফল থেকে কী পরিমাণ ডেটা ফিল্টার করা হয়েছে তার একটি সারাংশ প্রদান করে।
শূন্য ব্যবহারকারী আইডিগুলির হিসাব রাখুন
সর্বোত্তম অনুশীলন : আপনার ফলাফলে শূন্য ব্যবহারকারী আইডিগুলোও অন্তর্ভুক্ত করুন।
বিভিন্ন কারণে একজন ব্যবহারকারীর আইডি ০ সেট করা হতে পারে, যার মধ্যে রয়েছে: বিজ্ঞাপনের ব্যক্তিগতকরণ থেকে অপ্ট-আউট করা, নিয়ন্ত্রক কারণ ইত্যাদি। সেই হিসেবে, একাধিক ব্যবহারকারীর ডেটা ০ user_id এর সাথে সংযুক্ত করা হবে।
আপনি যদি মোট ইম্প্রেশন বা ক্লিকের মতো ডেটার মোট পরিমাণ বুঝতে চান, তবে আপনার এই ইভেন্টগুলো অন্তর্ভুক্ত করা উচিত। তবে, এই ডেটা গ্রাহকদের সম্পর্কে ধারণা পেতে সহায়ক হবে না এবং এই ধরনের বিশ্লেষণ করার সময় এটি ফিল্টার করা উচিত।
আপনার কোয়েরিতে WHERE user_id != "0" যোগ করে আপনি ফলাফল থেকে এই ডেটা বাদ দিতে পারেন।
কর্মক্ষমতা
পুনঃএকত্রীকরণ এড়িয়ে চলুন
সর্বোত্তম পন্থা : ব্যবহারকারীদের মধ্যে একাধিক স্তরের একত্রীকরণ পরিহার করুন।
যেসব কোয়েরি আগে থেকেই একত্রিত করা ফলাফলকে একত্রিত করে, যেমন একাধিক GROUP BY যুক্ত কোয়েরি বা নেস্টেড অ্যাগ্রিগেশন, সেগুলো প্রসেস করতে আরও বেশি রিসোর্সের প্রয়োজন হয়।
প্রায়শই, একাধিক স্তরের অ্যাগ্রিগেশনযুক্ত কোয়েরিগুলোকে ভেঙে ফেলা যায়, যা পারফরম্যান্স উন্নত করে। প্রসেসিং করার সময় আপনার উচিত ইভেন্ট বা ইউজার লেভেলে সারিগুলো রাখা এবং তারপর একটিমাত্র অ্যাগ্রিগেশন দিয়ে সেগুলোকে একত্রিত করা।
নিম্নলিখিত ধরণগুলি পরিহার করা উচিত:
SELECT SUM(count)
FROM
(SELECT campaign_id, COUNT(0) AS count FROM ... GROUP BY 1)
যেসব কোয়েরিতে একাধিক স্তরের অ্যাগ্রিগেশন ব্যবহার করা হয়, সেগুলোকে একটিমাত্র স্তরের অ্যাগ্রিগেশন ব্যবহার করার জন্য নতুন করে লেখা উচিত।
(SELECT ... GROUP BY ... )
JOIN USING (...)
(SELECT ... GROUP BY ... )
যে কোয়েরিগুলো সহজে ভাগ করা যায়, সেগুলো ভাগ করে ফেলা উচিত। আপনি BigQuery-তে ফলাফলগুলো জয়েন করতে পারেন।
BigQuery-এর জন্য অপ্টিমাইজ করুন
সাধারণত, যে কোয়েরিগুলো কম কাজ করে, সেগুলোর পারফরম্যান্স ভালো হয়। কোয়েরির পারফরম্যান্স মূল্যায়ন করার সময়, প্রয়োজনীয় কাজের পরিমাণ নিম্নলিখিত বিষয়গুলোর উপর নির্ভর করে:
- ইনপুট ডেটা এবং ডেটার উৎস (I/O) : আপনার কোয়েরিটি কত বাইট ডেটা পড়ে?
- নোডগুলির মধ্যে যোগাযোগ (শাফলিং) : আপনার কোয়েরি পরবর্তী ধাপে কত বাইট পাঠায়?
- গণনা : আপনার কোয়েরিটির জন্য কী পরিমাণ সিপিইউ কাজের প্রয়োজন হয়?
- আউটপুট (মেটেরিয়ালাইজেশন) : আপনার কোয়েরি কত বাইট লেখে?
- কোয়েরি অ্যান্টি-প্যাটার্ন : আপনার কোয়েরিগুলো কি SQL-এর সর্বোত্তম অনুশীলন অনুসরণ করছে?
যদি কোয়েরি এক্সিকিউশন আপনার সার্ভিস লেভেল এগ্রিমেন্ট অনুযায়ী না হয়, অথবা রিসোর্স শেষ হয়ে যাওয়া বা টাইমআউটের কারণে কোনো ত্রুটি দেখা দেয়, তাহলে নিম্নলিখিত বিষয়গুলো বিবেচনা করুন:
- পুনরায় গণনা করার পরিবর্তে পূর্ববর্তী কোয়েরিগুলির ফলাফল ব্যবহার করা। উদাহরণস্বরূপ, আপনার সাপ্তাহিক মোট পরিমাণটি BigQuery-তে গণনা করা ৭টি একক দিনের অ্যাগ্রিগেট কোয়েরির যোগফল হতে পারে।
- কোয়েরিগুলোকে যৌক্তিক সাবকোয়েরিতে বিভক্ত করা (যেমন একাধিক জয়েনকে একাধিক কোয়েরিতে ভাগ করা), অথবা অন্য কোনোভাবে প্রক্রিয়াকৃত ডেটার সেটকে সীমিত করা। BigQuery-তে আপনি স্বতন্ত্র জবগুলোর ফলাফলকে একটি একক ডেটাসেটে একত্রিত করতে পারেন। যদিও এটি রিসোর্সের ব্যবহার কমাতে সাহায্য করতে পারে, তবে এটি আপনার কোয়েরির গতি কমিয়ে দিতে পারে।
- BigQuery-তে যদি আপনি 'resources exceeded' ত্রুটির সম্মুখীন হন, তাহলে আপনার কোয়েরিকে একাধিক BigQuery কোয়েরিতে বিভক্ত করতে টেম্প টেবিল ব্যবহার করে দেখুন।
- একটি কোয়েরিতে কম সংখ্যক টেবিল রেফারেন্স করুন, কারণ এতে প্রচুর পরিমাণে মেমরি ব্যবহৃত হয় এবং এর ফলে আপনার কোয়েরি ব্যর্থ হতে পারে।
- আপনার কোয়েরিগুলো এমনভাবে পুনর্লিখন করুন যাতে সেগুলো কম সংখ্যক ইউজার টেবিল জয়েন করে।
- একই টেবিলকে পুনরায় জয়েন করা এড়াতে আপনার কোয়েরিগুলো পুনর্লিখন করুন।
কোয়েরি উপদেষ্টা
আপনার SQL বৈধ হওয়া সত্ত্বেও যদি তা গোপনীয়তার সমস্যা তৈরি করতে পারে, তবে কোয়েরি অ্যাডভাইজার কোয়েরি তৈরির প্রক্রিয়া চলাকালীন কার্যকরী পরামর্শ প্রদান করে, যা আপনাকে অনাকাঙ্ক্ষিত ফলাফল এড়াতে সাহায্য করে।
কোয়েরি অ্যাডভাইজার ব্যবহার করতে:
- UI . সুপারিশগুলো কোয়েরি এডিটরে, কোয়েরি টেক্সটের উপরে প্রদর্শিত হবে।
- API .
customers.analysisQueries.validateমেথডটি ব্যবহার করুন।