
Las siguientes prácticas recomendadas te proporcionarán técnicas para desarrollar consultas centradas en la privacidad y con buen rendimiento. Para conocer las prácticas recomendadas específicas para ejecutar consultas en el modo de ruido, consulta las secciones sobre patrones de consulta admitidos y no admitidos en Inyección de ruido.
Privacidad y precisión de los datos
Desarrolla consultas sobre datos de sandbox
Práctica recomendada: Solo consulta los datos de producción cuando estés en producción.
Siempre que sea posible, utiliza datos de sandbox durante el desarrollo de tus consultas. Los trabajos que usan datos de sandbox no introducen oportunidades adicionales para que las verificaciones de diferencias filtren los resultados de tus consultas. Además, debido a la falta de verificaciones de privacidad, las consultas de sandbox se ejecutan más rápido, lo que permite una iteración más rápida durante el desarrollo de las consultas.
Si tienes que desarrollar consultas sobre tus datos reales (por ejemplo, cuando usas tablas de coincidencias), para que sea menos probable que se superpongan las filas, elige períodos y otros parámetros que no se superpongan en cada iteración de tu consulta. Por último, ejecuta la consulta en el rango de datos deseado.
Considera cuidadosamente los resultados históricos
Práctica recomendada: Disminuye la probabilidad de superposición del conjunto de resultados entre las consultas ejecutadas recientemente.
Ten en cuenta que la tasa de cambio entre los resultados de las consultas afectará la probabilidad de que se omitan los resultados más adelante debido a las verificaciones de privacidad. Es probable que se quite un segundo conjunto de resultados que se parezca mucho a un conjunto de resultados que se mostró recientemente.
En su lugar, modifica los parámetros clave de tu consulta, como los períodos o los IDs de campaña, para disminuir la probabilidad de superposición significativa.
No consultes los datos de hoy
Práctica recomendada: No ejecutes varias consultas en las que la fecha de finalización sea hoy.
Ejecutar varias consultas con fechas de finalización iguales a hoy suele provocar que se filtren las filas. Esta guía también se aplica a la ejecución de consultas poco después de la medianoche sobre los datos de ayer.
No consultes los mismos datos más de lo necesario
Prácticas recomendadas:
- Selecciona fechas de inicio y finalización bien definidas.
- En lugar de consultar ventanas superpuestas, ejecuta tus consultas en conjuntos de datos disjuntos y, luego, agrega los resultados en BigQuery.
- Usa los resultados guardados en lugar de volver a ejecutar la consulta.
- Crea tablas temporales para cada período que consultes.
El Centro de Datos de Anuncios restringe la cantidad total de veces que puedes consultar los mismos datos. Por lo tanto, debes intentar limitar la cantidad de veces que accedes a un dato determinado.
No uses más agregaciones de las necesarias en la misma consulta
Prácticas recomendadas:
- Minimiza la cantidad de agregaciones en una consulta.
- Vuelve a escribir las consultas para combinar agregaciones cuando sea posible.
El Centro de Datos de Anuncios limita a 100 la cantidad de agregaciones entre usuarios que se pueden usar en una subconsulta. Por lo tanto, en general, recomendamos escribir consultas que generen más filas con claves de agrupación enfocadas y agregaciones simples, en lugar de más columnas con claves de agrupación amplias y agregaciones complejas. Se debe evitar el siguiente patrón:
SELECT
COUNTIF(field_1 = a_1 AND field_2 = b_1) AS cnt_1,
COUNTIF(field_1 = a_2 AND field_2 = b_2) AS cnt_2
FROM
table
Las consultas que cuentan eventos según el mismo conjunto de campos se deben volver a escribir con la instrucción GROUP BY.
SELECT
field_1,
field_2,
COUNT(1) AS cnt
FROM
table
GROUP BY
1, 2
El resultado se puede agregar de la misma manera en BigQuery.
Las consultas que crean columnas a partir de un array y, luego, las agregan, se deben volver a escribir para combinar estos pasos.
SELECT
COUNTIF(a_1) AS cnt_1,
COUNTIF(a_2) AS cnt_2
FROM
(SELECT
1 IN UNNEST(field) AS a_1,
2 IN UNNEST(field) AS a_2,
FROM
table)
La consulta anterior se puede volver a escribir de la siguiente manera:
SELECT f, COUNT(1) FROM table, UNNEST(field) AS f GROUP BY 1
Las consultas que usan diferentes combinaciones de campos en diferentes agregaciones se pueden volver a escribir en varias consultas más enfocadas.
SELECT
COUNTIF(field_1 = a_1) AS cnt_a_1,
COUNTIF(field_1 = b_1) AS cnt_b_1,
COUNTIF(field_2 = a_2) AS cnt_a_2,
COUNTIF(field_2 = b_2) AS cnt_b_2,
FROM table
La consulta anterior se puede dividir de la siguiente manera:
SELECT
field_1, COUNT(*) AS cnt
FROM table
GROUP BY 1
y
SELECT
field_2, COUNT(*) AS cnt
FROM table
GROUP BY 1
Puedes dividir estos resultados en consultas separadas, crear y unir las tablas en una sola consulta o combinarlas con una instrucción UNION si los esquemas son compatibles.
Optimiza y comprende las uniones
Práctica recomendada: Usa una LEFT JOIN en lugar de una INNER JOIN para unir clics o conversiones a impresiones.
No todas las impresiones se asocian con clics o conversiones. Por lo tanto, si realizas una INNER JOIN de clics o conversiones en impresiones, las impresiones que no estén vinculadas a clics o conversiones se filtrarán de tus resultados.
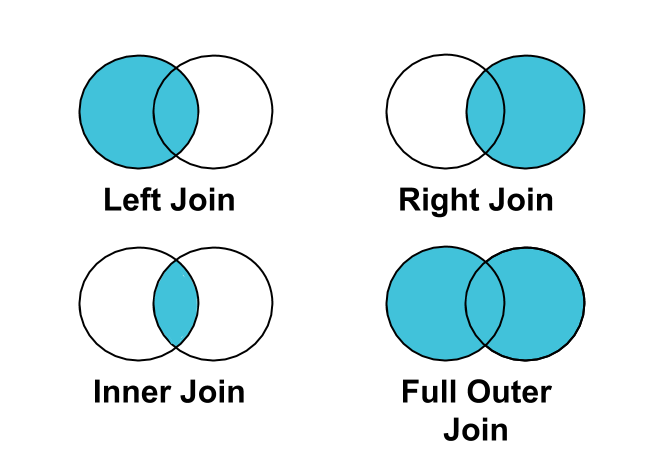
Une algunos resultados finales en BigQuery
Práctica recomendada: Evita las consultas del Centro de Datos de Anuncios que unen resultados agregados. En su lugar, escribe 2 consultas separadas y une los resultados en BigQuery.
Las filas que no cumplen con los requisitos de agregación se filtran de tus resultados. Por lo tanto, si tu consulta une una fila agregada de forma insuficiente con una fila agregada de forma suficiente, la fila resultante se filtrará. Además, las consultas con varias agregaciones tienen un rendimiento inferior en el Centro de Datos de Anuncios.
Puedes unir resultados (en BigQuery) de varias consultas de agregación (del Centro de Datos de Anuncios). Los resultados calculados con consultas comunes compartirán esquemas finales.
La siguiente consulta toma resultados individuales del Centro de Datos de Anuncios (campaign_data_123 y campaign_data_456) y los une en BigQuery:
SELECT t1.campaign_id, t1.city, t1.X, t2.Y
FROM `campaign_data_123` AS t1
FULL JOIN `campaign_data_456` AS t2
USING (campaign_id, city)
Usa resúmenes de filas filtradas
Práctica recomendada: Agrega resúmenes de filas filtradas a tus consultas.
Los resúmenes de filas filtradas registran los datos que se filtraron debido a las verificaciones de privacidad. Los datos de las filas filtradas se suman y se agregan a una fila de captura general. Si bien los datos filtrados no se pueden analizar más, proporcionan un resumen de la cantidad de datos que se filtraron de los resultados.
Ten en cuenta los IDs de usuario en cero
Práctica recomendada: Ten en cuenta los IDs de usuario en cero en tus resultados.
El ID de un usuario final se puede establecer en 0 por varios motivos, como la inhabilitación de la personalización de anuncios, motivos reglamentarios, etc. Por lo tanto, los datos que provienen de varios usuarios se asignarán a un user_id de 0.
Si deseas comprender los totales de datos, como las impresiones totales o los clics, debes incluir estos eventos. Sin embargo, estos datos no serán útiles para obtener estadísticas sobre los clientes y se deben filtrar si realizas ese tipo de análisis.
Para excluir estos datos de tus resultados, agrega WHERE user_id != "0" a tus consultas.
Rendimiento
Evita la reagregación
Práctica recomendada: Evita varias capas de agregación entre usuarios.
Las consultas que combinan resultados que ya se agregaron, como en el caso de una consulta con varias instrucciones GROUP BY o agregación anidada, requieren más recursos para procesarse.
A menudo, las consultas con varias capas de agregación se pueden dividir, lo que mejora el rendimiento. Debes intentar mantener las filas en el nivel de evento o de usuario durante el procesamiento y, luego, combinarlas con una sola agregación.
Se deben evitar los siguientes patrones:
SELECT SUM(count)
FROM
(SELECT campaign_id, COUNT(0) AS count FROM ... GROUP BY 1)
Las consultas que usan varias capas de agregación se deben volver a escribir para usar una sola capa de agregación.
(SELECT ... GROUP BY ... )
JOIN USING (...)
(SELECT ... GROUP BY ... )
Las consultas que se pueden dividir fácilmente se deben dividir. Puedes unir resultados en BigQuery.
Optimiza para BigQuery
En general, las consultas que hacen menos cosas tienen un mejor rendimiento. Cuando se evalúa el rendimiento de las consultas, la cantidad de trabajo requerido depende de los siguientes factores:
- Datos de entrada y fuentes de datos (E/S): ¿cuántos bytes lee tu consulta?
- Comunicación entre nodos (redistribución): ¿cuántos bytes pasa tu consulta a la siguiente etapa?
- Procesamiento: ¿cuánto trabajo de CPU requiere tu consulta?
- Salidas (materialización): ¿cuántos bytes escribe tu consulta?
- Antipatrones de consulta: tus consultas ¿siguen las recomendaciones de SQL?
Si la ejecución de la consulta no cumple con tus acuerdos de nivel de servicio o si encuentras errores debido al agotamiento de recursos o al tiempo de espera agotado, considera lo siguiente:
- Usar los resultados de consultas anteriores en lugar de volver a calcular. Por ejemplo, tu total semanal podría ser la suma calculada en BigQuery de 7 consultas agregadas de un solo día.
- Descomponer las consultas en subconsultas lógicas (como dividir varias uniones en varias consultas) o restringir el conjunto de datos que se procesan. Puedes combinar los resultados de trabajos individuales en un solo conjunto de datos en BigQuery. Si bien esto puede ayudar con el agotamiento de recursos, puede ralentizar tu consulta.
- Si tienes errores de recursos excedidos en BigQuery, intenta usar tablas temporales para dividir tu consulta en varias consultas de BigQuery.
- Hacer referencia a menos tablas en una sola consulta, ya que esto usa grandes cantidades de memoria y puede hacer que falle la consulta.
- Volver a escribir tus consultas de modo que unan menos tablas de usuarios.
- Volver a escribir tus consultas para evitar unir la misma tabla consigo misma.
Asesor de consultas
Si tu SQL es válido, pero podría generar problemas de privacidad, el asesor de consultas muestra sugerencias prácticas durante el proceso de desarrollo de la consulta para ayudarte a evitar resultados no deseados.
Para usar el asesor de consultas, haz lo siguiente:
- IU : Las recomendaciones aparecerán en el editor de consultas, sobre el texto de la consulta.
- API : Usa el
customers.analysisQueries.validatemétodo.