PageSpeed Insights (PSI) genera report sull'esperienza utente di una pagina su dispositivi mobili e desktop e fornisce suggerimenti su come migliorarla.
PSI fornisce dati di prova controllati e reali relativi a una pagina. I dati dei lab sono utili per il debug dei problemi, poiché vengono raccolti in un ambiente controllato. Tuttavia, potrebbero non inquadrare i colli di bottiglia reali. I dati sul campo sono utili per acquisire un'esperienza utente reale ma hanno un insieme più limitato di metriche. Consulta Come pensare agli strumenti di velocità per ulteriori informazioni sui due tipi di dati.
Dati sull'esperienza utente reale
I dati sull'esperienza utente reale in PSI si basano sul set di dati Chrome User Experience Report (CrUX). PSI riporta le esperienze First Contentful Paint (FCP), First Input Delay (FID), Largest Contentful Paint (LCP), Cumulative Layout Shift (CLS) e Interaction to Next Paint (INP) nel periodo di raccolta dei 28 giorni precedenti. PSI segnala anche le esperienze per la metrica sperimentale Time to First Byte (TTFB).
Per mostrare i dati relativi all'esperienza utente per una determinata pagina, devono essere disponibili dati sufficienti per l'inclusione nel set di dati di CrUX. Una pagina potrebbe non avere dati sufficienti se è stata pubblicata di recente o se ha un numero insufficiente di campioni di utenti reali. In questo caso, PSI tornerà alla granularità a livello di origine, che include tutte le esperienze utente su tutte le pagine del sito web. A volte l'origine potrebbe anche avere dati insufficienti, nel qual caso PSI non sarà in grado di mostrare dati reali sull'esperienza utente.
Valutazione della qualità delle esperienze
PSI classifica la qualità delle esperienze utente in tre bucket: Buona, Richiede miglioramenti o Scadente. PSI imposta le seguenti soglie in conformità con l'iniziativa Web Vitals:
| Buoni | Richiede miglioramenti | Scadente | |
|---|---|---|---|
| FCP | [0, 1800ms] | (1800ms, 3000ms] | oltre 3000 ms |
| FID | [0, 100ms] | (100ms, 300ms] | oltre 300 ms |
| LCP | [0, 2500ms] | (2500ms, 4000ms] | oltre 4000 ms |
| CLS | [0, 0,1] | (0,1; 0,25] | più di 0,25 |
| INP | [0, 200ms] | (200ms, 500ms] | oltre 500 ms |
| TTFB (sperimentale) | [0, 800ms] | (800ms, 1800ms] | oltre 1800 ms |
Distribuzione e valori delle metriche selezionati
PSI presenta una distribuzione di queste metriche in modo che gli sviluppatori possano comprendere la gamma di esperienze per quella pagina o origine. Questa distribuzione è suddivisa in tre categorie: Buona, Richiede miglioramenti e Scadente, rappresentate da barre verdi, ambra e rosse. Ad esempio, se l'11% nella barra ambra di LCP indica che l'11% di tutti i valori LCP osservati rientra tra 2500 ms e 4000 ms.
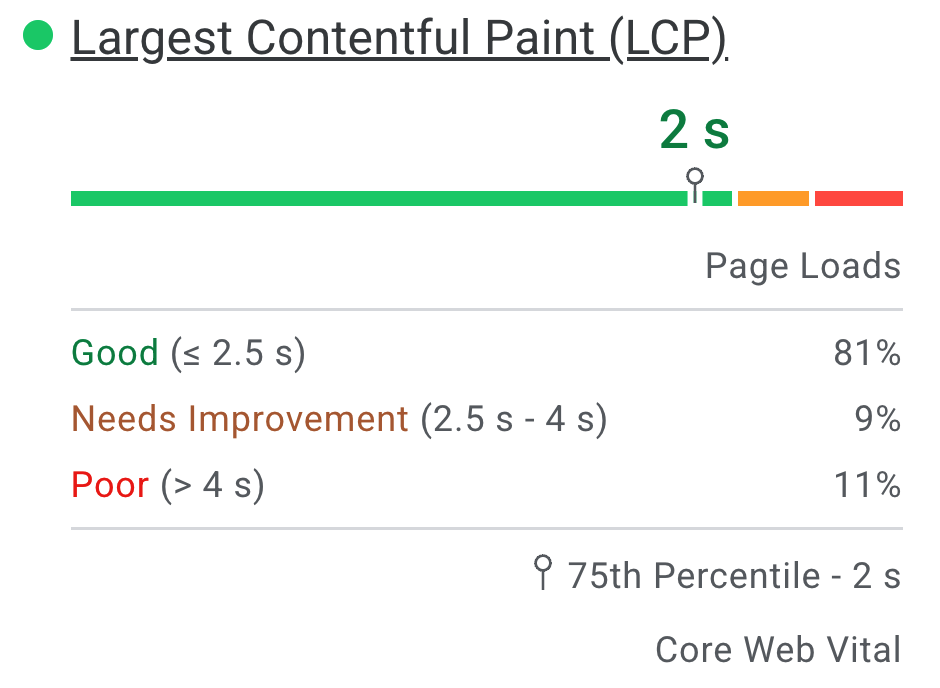
Sopra le barre di distribuzione, PSI riporta il 75° percentile per tutte le metriche. Il 75° percentile è selezionato per consentire agli sviluppatori di comprendere le esperienze utente più frustranti sul loro sito. I valori di queste metriche dei campi vengono classificati come buono/da migliorare/scarso applicando le stesse soglie mostrate sopra.
Segnali web essenziali
I Segnali web essenziali sono un insieme comune di indicatori delle prestazioni fondamentali per tutte le esperienze web. Le metriche di Segnali web essenziali sono FID, LCP e CLS e possono essere aggregate a livello di pagina o di origine. Nel caso di aggregazioni con dati sufficienti in tutte e tre le metriche, l'aggregazione supera la valutazione Segnali web essenziali se il 75° percentile di tutte e tre le metriche è Buono. In caso contrario, l'aggregazione non supera la valutazione. Se l'aggregazione dispone di dati insufficienti per il FID, supererà la valutazione se entrambi il 75° percentile di LCP e CLS sono buoni. Se LCP o CLS hanno dati insufficienti, non è possibile valutare l'aggregazione a livello di pagina o di origine.
Differenze tra i dati sul campo in PSI e CrUX
La differenza tra i dati sul campo in PSI e il set di dati CrUX su BigQuery è che i dati di PSI vengono aggiornati quotidianamente, mentre il set di dati BigQuery viene aggiornato mensilmente e limitato ai dati a livello di origine. Entrambe le origini dati rappresentano periodi degli ultimi 28 giorni.
Diagnostica lab
PSI utilizza Lighthouse per analizzare l'URL specificato in un ambiente simulato per le categorie Prestazioni, Accessibilità, Best practice e SEO.
Punteggio
Nella parte superiore della sezione sono visualizzati i punteggi per ogni categoria, determinati eseguendo Lighthouse per raccogliere e analizzare le informazioni diagnostiche sulla pagina. Un punteggio pari o superiore a 90 è considerato buono. Da 50 a 89 è un punteggio che deve essere migliorato, mentre un punteggio inferiore a 50 è considerato scarso.
Metriche
La categoria Prestazioni riporta anche le prestazioni della pagina su diverse metriche, tra cui: First Contentful Paint, Largest Contentful Paint, Speed Index, Cumulative Layout Shift, Time to Interactive, e Total Block Time.
A ogni metrica è associato un punteggio ed etichettata con un'icona:
- Il prodotto è indicato con un cerchio verde
- Richiede miglioramenti è indicato con un quadrato informativo color ambra
- La dicitura "Scadente" è indicata da un triangolo rosso di pericolo
Controlli
All'interno di ogni categoria sono presenti controlli che forniscono informazioni su come migliorare l'esperienza utente della pagina. Consulta la documentazione di Lighthouse per un'analisi dettagliata degli audit di ogni categoria.
Domande frequenti
Quali condizioni del dispositivo e della rete utilizza Lighthouse per simulare un caricamento di pagina?
Attualmente Lighthouse simula le condizioni di caricamento della pagina di un dispositivo di fascia media (Moto G4) su una rete mobile per dispositivi mobili e di un desktop emulato con una connessione cablata per computer. PageSpeed viene inoltre eseguito in un data center Google che può variare in base alle condizioni della rete. Puoi verificare la posizione in cui è stato eseguito il test esaminando il blocco di ambiente del report Lighthouse:

Nota: PageSpeed riporterà la pubblicazione in Nord America, Europa o Asia.
Perché i dati sul campo e i dati di laboratorio a volte sono in contraddizione tra loro?
I dati sul campo rappresentano un report storico sul rendimento di un determinato URL e rappresentano dati anonimizzati sulle prestazioni degli utenti nel mondo reale su una varietà di dispositivi e condizioni di rete. I dati del lab sono basati su un caricamento simulato di una pagina su un singolo dispositivo e su un insieme fisso di condizioni di rete. Di conseguenza, i valori potrebbero variare. Per ulteriori informazioni, consulta Perché i dati di prova controllati e reali possono essere diversi (e cosa fare al riguardo).
Perché viene scelto il 75° percentile per tutte le metriche?
Il nostro obiettivo è assicurarci che le pagine funzionino correttamente per la maggior parte degli utenti. Concentrandoci sui valori del 75° percentile delle nostre metriche, questo garantisce che le pagine offrano una buona esperienza utente nelle condizioni più difficili del dispositivo e della rete. Per saperne di più, consulta la sezione Definizione delle soglie delle metriche di Segnali web essenziali.
Qual è un buon punteggio per i dati di prova?
Qualsiasi punteggio verde (90+) è considerato positivo, ma tieni presente che avere dati di prova controllati di buona qualità non significa necessariamente che anche l'esperienza utente reale sarà positiva.
Perché il punteggio delle prestazioni cambia dall'esecuzione all'esecuzione? Non ho modificato nulla nella mia pagina.
La variabilità nella misurazione delle prestazioni viene introdotta tramite una serie di canali con diversi livelli di impatto. Alcune fonti comuni della variabilità delle metriche sono la disponibilità della rete locale, la disponibilità dell'hardware del client e la contesa delle risorse del client.
Perché i dati CrUX dell'utente reale non sono disponibili per un URL o un'origine?
Il Report sull'esperienza utente di Chrome aggrega i dati sulla velocità reale degli utenti che hanno attivato l'attivazione e richiede che un URL sia pubblico (sottoponibile a scansione e indicizzabile) e abbia un numero sufficiente di campioni distinti che forniscano una visualizzazione anonima e rappresentativa delle prestazioni dell'URL o dell'origine.
Altri dubbi?
Se avete una domanda specifica e disponibile per l'utilizzo di PageSpeed Insights, fatela in inglese su Stack Overflow.
Se hai domande o feedback generici su PageSpeed Insights, oppure se vuoi iniziare una discussione generale, avvia un thread nella mailing list.
Se hai domande generali sulle metriche di Web Vitals, avvia un thread nel gruppo di discussione di web-vitals-feedback.
Feedback
Hai trovato utile questa pagina?