DSPL significa linguagem de publicação de conjunto de dados. Conjuntos de dados descritos em DSPL podem ser importadas para o aplicativo Google Public Data Explorer, uma ferramenta que permite uma exploração visual e rica dos dados.
Observação: para fazer o upload de dados para o Google Public Data usando a ferramenta de upload de dados públicos, você precisa ter uma Conta do Google.
Este tutorial fornece um exemplo passo a passo de como preparar um conjunto de dados DSPL.
Um conjunto de dados DSPL é um pacote que contém um arquivo XML e um conjunto de CSV. Os arquivos CSV são tabelas simples que contêm os dados de conjunto de dados. O arquivo XML descreve os metadados do conjunto de dados, incluindo metadados informativos como descrições de medidas, bem como metadados estruturais, como referências entre tabelas. Com os metadados, os usuários não especialistas exploram e visualizam seus dados.
O único pré-requisito para entender este tutorial é ter um bom nível de sobre XML. Alguma compreensão de conceitos simples de bancos de dados (por exemplo, tabelas, chaves primárias) pode ajudar, mas não é obrigatório. Para referência, a arquivo XML concluído e conjunto de dados completo pacote associado a este tutorial também estão disponíveis para análise.
Visão geral
Antes de começar a criar nosso conjunto de dados, aqui está uma visão geral de alto nível o que um conjunto de dados DSPL contém:
- Informações gerais:sobre o conjunto de dados
- Conceitos:definições de "coisas" que aparecem no conjunto de dados (por exemplo, países, taxa de desemprego, gênero, etc.)
- Slices:combinações de conceitos para as quais há dados
- Tabelas:dados de conceitos e frações. Tabelas de conceito as enumerações e as tabelas de fração contêm dados estatísticos
- Tópicos:usados para organizar os conceitos do conjunto de dados em uma hierarquia significativa por meio da rotulagem
Para ilustrar essas noções bastante abstratas, considere o conjunto de dados (com dados fictícios) usados em todo este tutorial: séries temporais estatísticas para população e desemprego, agregados por várias combinações de país, Estado dos EUA e gênero.
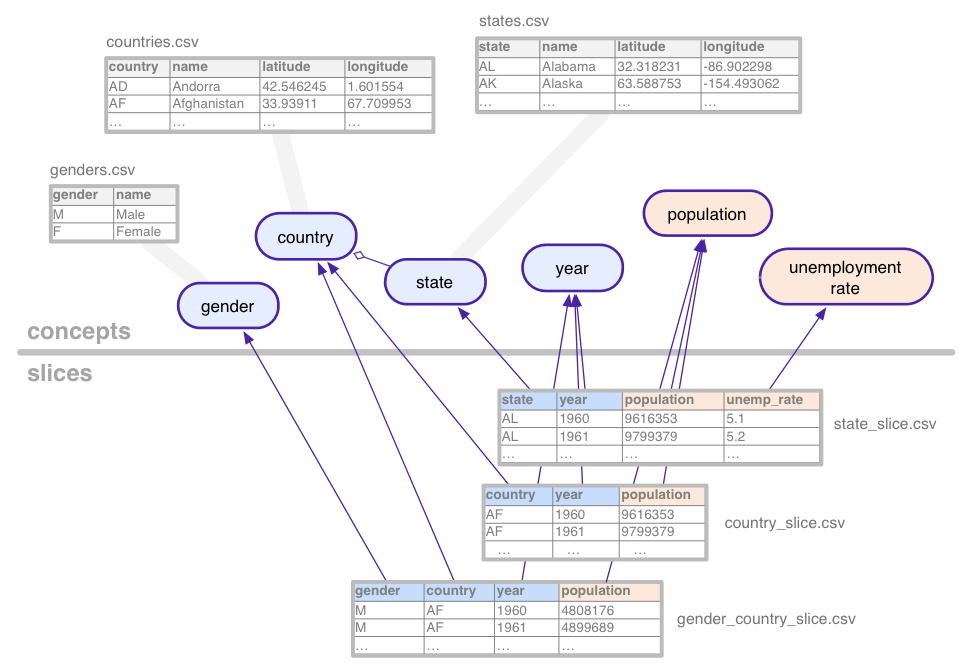
Este conjunto de dados de exemplo define os seguintes conceitos:
- país
- gênero
- population
- estado
- taxa de desemprego
- ano
Conceitos categóricos, como estado, são associados a eles tabelas, que enumeram todos os valores possíveis (Califórnia, Arizona etc.). Os conceitos podem ter colunas adicionais para propriedades como o nome ou o país de um estado.
Slices definem cada combinação de conceitos para os quais há
dados estatísticos no conjunto de dados. Uma fração contém dimensões e
métricas. Na imagem acima, as dimensões são azuis e a
são laranja. Neste exemplo, a fração
gender_country_slice tem dados para a métrica
population e as dimensões country,
year e gender. Outra fatia, chamada
country_slice, fornece os números totais anuais da população (métrica) para
países.
Além das dimensões e métricas, as frações também fazem referência tabelas, que contêm os dados reais.
Agora, vamos analisar passo a passo a criação desse conjunto de dados em DSPL.
Informações do conjunto de dados
Para começar, precisamos criar um arquivo XML para nosso conjunto de dados. Este é o Início de uma descrição de DSPL para nosso conjunto de dados de exemplo:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
A descrição do conjunto de dados começa com uma <dspl> de nível superior
. O atributo targetNamespace contém um URI que
que identifica exclusivamente este conjunto de dados. O namespace do conjunto de dados é especialmente
importante ao publicar o conjunto de dados, pois ele será o identificador global do
conjunto de dados e os meios para que outras pessoas o consultem.
O atributo targetNamespace pode ser omitido. Em
Nesse caso, um namespace exclusivo é gerado automaticamente quando o conjunto de dados é
importadas.
Como usar informações de outros conjuntos de dados
Os conjuntos de dados podem reutilizar definições e dados de outros conjuntos de dados ao importar
nesses conjuntos de dados. Cada elemento <import> especifica
namespace de outro conjunto de dados a que este conjunto fará referência.
Em nosso conjunto de dados de exemplo, precisaremos de algumas definições de http://www.google.com/publicdata/dataset/google/quantity (um conjunto de dados criado pelo Google que contém conceitos úteis para definir quantidades numéricas) e dos conjuntos de dados de tempo, entidade e geolocalização, que fornecem definições relacionadas a tempo, entidades e geografia, respectivamente.
O elemento <dspl> superior fornece um prefixo de namespace
declaração de serviço (por exemplo, xmlns:time="http://...") para cada
dos conjuntos de dados importados. As declarações de prefixo são necessárias para referenciar
elementos de outros conjuntos de dados de forma concisa. Por exemplo:
time:year faz referência à definição de year no
conjunto de dados importado cujo namespace está associado ao prefixo
time
Informações do conjunto de dados e do provedor
O elemento <info> contém informações gerais sobre
conjunto de dados: nome, descrição e um URL em que é possível inserir mais informações
encontradas.
O elemento <provider> contém informações sobre o
provedor do conjunto de dados: seu nome e um URL onde mais informações podem ser
encontrado (geralmente, a página inicial do provedor de dados).
definir conceitos
Agora que fornecemos algumas informações gerais sobre o conjunto de dados, estamos prontos para começar a definir o conteúdo. Nossa próxima meta é adicionar estatísticas populacionais de países nos últimos 50 anos.
A primeira coisa que precisamos fazer é fornecer algumas definições das noções de população, país e ano. No DSPL, essas definições são chamadas diferentes.
Um conceito é uma definição de um tipo de dados que aparece em uma no conjunto de dados. Os valores de dados que correspondem a um determinado conceito são chamados instâncias desse conceito.
População
Vamos começar definindo o conceito de população. Em um
Documento DSPL, os conceitos são definidos em um <concepts>.
que vem logo após as informações do conjunto de dados e do provedor.
Aqui está um conceito de população com apenas o mínimo de informações necessárias
para qualquer conceito: id (um identificador exclusivo), name e
type
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Veja como esse exemplo funciona:
- Cada conceito precisa fornecer um
idque identifique exclusivamente o conceito dentro do conjunto de dados. Isso significa que não há dois conceitos definidos o mesmo conjunto de dados pode ter o mesmo ID. - Assim como para o conjunto de dados e seu provedor,
Os elementos
<info>fornecem informações textuais sobre o conceito, como nome e descrição. - O elemento
<type>especifica o tipo de dados para o instâncias do conceito (em outras palavras, seus "valores"). Neste exemplo, o tipo depopulationéinteger. O DSPL oferece suporte aos seguintes tipos de dados:stringintegerfloatbooleandate
País
Agora, vamos escrever a definição do conceito de país:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
A definição do conceito de país começa como a anterior,
com id, info e type.
Valores de conceito
Conceitos categóricos, como países, têm uma enumeração de todos os possíveis
instâncias. Em outras palavras, você pode listar todos os países possíveis que podem ser
referenciadas. Para isso, cada país precisa de um identificador exclusivo.
Este exemplo usa
o código ISO dos países (em inglês) para identificar os países; esses códigos são
do tipo string.
Neste exemplo, você não precisa usar o código ISO. você seria melhor usar o nome do país. Os nomes, no entanto, diferem conforme o idioma, podem mudar com o tempo e nem sempre são usadas de modo consistente nos conjuntos de dados. Para países e para conceitos categóricos em geral, é uma boa escolher, curtos, estáveis, comumente usados e independentes de linguagem e identificadores (se houver).
Propriedades do conceito
Além do id, o conceito de país tem um
Elemento <property> que especifica o nome do país.
Em outras palavras, o nome do país ("Irlanda") é uma propriedade
do país com o id IE. As propriedades são a forma como o DSPL fornece
informações estruturadas adicionais sobre as instâncias de um conceito.
Assim como o conceito em si, as propriedades têm um id,
info e type.
Dados conceituais
Por fim, o conceito de país tem um elemento <table>.
Esse elemento faz referência a uma tabela que enumera a lista de todos
países.
O uso de tabelas faz sentido para alguns conceitos, mas não para outros. Para exemplo, não faz sentido enumerar todos os valores possíveis para a população do conceito. No entanto, se você referenciar uma tabela a tabela deve conter todas as instâncias do conceito, por exemplo, ele deve listar todos os países, não apenas alguns.
O conjunto de dados define a tabela countries_table da seguinte maneira:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
A tabela de países especifica as colunas da tabela e seus tipos,
e faz referência a um arquivo CSV que contém os dados. Esse CSV pode ser
empacotados e carregados com o XML do conjunto de dados ou acessados remotamente via HTTP, HTTPS,
ou FTP. Nos últimos casos, substitua countries.csv por
um URL, por exemplo, http://www.myserver.com/mydata/countries.csv.
Onde quer que esteja armazenado, o arquivo CSV tem a seguinte aparência:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
A primeira linha da tabela lista os IDs de coluna, conforme especificado no DSPL
a definição de table. Cada uma das linhas a seguir corresponde a um
exemplo do conceito de país. Se o conceito tiver uma tabela, então
a tabela deve conter todas as instâncias do conceito; neste
caso, ele deve listar todos os países.
As colunas são mapeadas para o conceito de país e suas propriedades com base no
o ID. O ID da primeira coluna, country, corresponde ao conceito
ID. Isso significa que esta coluna contém o identificador de país exclusivo
definida pelo conceito de país. A próxima coluna corresponde
a propriedade name do conceito de país. Os valores
nessa coluna correspondem aos valores da propriedade name.
Há alguns requisitos para os dados CSV da tabela de conceito:
- Os títulos das colunas na primeira linha do arquivo de dados devem
corresponder exatamente ao conceito
ide à propriedadeiddo conceito a que os dados estão associados (embora a ordem pode variar). - Cada linha precisa ter exatamente o mesmo número de elementos que o número de no conceito (mesmo que o valor esteja vazio).
- Cada valor do campo
iddo conceito (aqui, o código do país) precisa ser único e não pode estar vazio (um campo vazio é um com zero ou apenas caracteres de espaço em branco). - Os valores das propriedades que fazem referência a outros conceitos precisam ser vazio ou ser um valor válido do conceito em questão.
- Os valores que contêm vírgulas, aspas duplas ou caracteres de nova linha devem ser está totalmente entre aspas duplas.
- Todas as aspas duplas literais dentro de um valor precisam ser precedido por outra aspa dupla.
Ano
O último conceito de que precisamos para os dados sobre a população do país é um conceito para
representam anos. Em vez de definir um novo conceito, usaremos o
ano de um dos conjuntos de dados que importamos:
"http://www.google.com/publicdata/dataset/google/time". Para isso,
precisamos fazer referência a ele como time:year, em que time
representa o conjunto de dados referenciado, e year identifica
o conceito.
Conceitos canônicos
time:year faz parte de um pequeno conjunto de conceitos canônicos
definidos pelo Google. Os conceitos canônicos fornecem definições básicas para tempo,
geografia, quantidades numéricas, unidades etc.
Na verdade, o conceito de país definido acima existe como um
do conceito canônico. Ele foi criado aqui apenas para fins ilustrativos.
Sempre que possível, use conceitos canônicos nos seus conjuntos de dados, seja
diretamente ou estendendo-as (veja mais sobre a extensão abaixo). Conceitos canônicos
tornar seus dados comparáveis a outros conjuntos de dados e ativar recursos para sua
conjuntos de dados no Explorador de Dados Públicos. Por exemplo, animar dados ao longo do tempo
ou mostrar dados geográficos em um mapa dependem do uso das time e
conceitos canônicos geo, respectivamente.
Primeira fração
Agora que temos conceitos para população, país e ano, é hora de para montá-las.
Para isso, precisamos criar uma fatia que os combine. No DSPL, uma fração é uma combinação de conceitos para os quais há dados.
Por que não criar uma tabela com as colunas certas? Como as frações capturam as informações do conjunto de dados em termos de conceitos. Isso vai se tornar mais claras à medida que criamos mais partes do conjunto de dados.
Os Slices aparecem no arquivo DSPL em um <slices>.
que precisa aparecer logo após a seção concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Assim como os conceitos, cada fração tem um id
(countries_slice) que identifica exclusivamente a fração dentro da
no conjunto de dados.
Uma fração contém dois tipos de referências de conceito: Dimensões e
métricas. Os valores das métricas variam com os valores de
dimensões. Aqui, o valor de population (a métrica) varia
as dimensões country e year.
Assim como os conceitos, as frações incluem uma referência a uma tabela que contém os dados da fração. A tabela referenciada deve ter uma coluna para cada dimensão e métrica da fração. Assim como para os conceitos, a parte as dimensões e métricas são mapeadas para as colunas da tabela com os mesmos IDs.
Tabela de fração
A tabela da nossa fração populacional aparece no tables
do arquivo DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
A coluna year vem com format.
que especifica como os anos são formatados. Os formatos de data compatíveis são
aqueles definidos pelo formato Joda DateTime.
A tabela countries_slice especifica as colunas da tabela e
os tipos e aponta para um arquivo CSV que contém os dados. O arquivo CSV
é assim:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Cada linha da tabela de dados contém uma combinação exclusiva das dimensões
country e year, com o valor correspondente
da métrica population (por exemplo, a população -
metric: do Afeganistão em 1960, dimensions).
Os valores na coluna country correspondem ao
valor/identificador do conceito country, que é a norma ISO 3166
Código de duas letras do país.
Os dados CSV de uma fração precisam atender às seguintes restrições:
- Cada valor de um campo de dimensão (como
countryeyear) não pode estar em branco. Valores de campos de métricas (comopopulation) podem estar vazias. Um valor vazio é representado por caracteres. - Cada valor de um campo de dimensão que faz referência a um conceito precisa ser
presentes nos dados desse conceito. Por exemplo, o valor
AFprecisa estar presente na tabela de dados conceituaiscountry. - Cada combinação exclusiva de valores de dimensão, por exemplo,
AF, 2000, pode ocorrer apenas uma vez. - Os dados devem ser classificados pelas colunas de dimensão que não são de tempo (em qualquer ordem),
e, opcionalmente, por qualquer uma das outras colunas. Por exemplo,
em uma tabela com as colunas
[date, dimension1, dimension2, metric1, metric2], é possível classificar pordimension1, depoisdimension2, depoisdate, mas não pordatee as dimensões.
Resumo
Neste ponto, temos o suficiente em nossa DSPL para descrever o país dados populacionais. Para recapitular, o que tínhamos que fazer foi:
- Crie o cabeçalho DSPL e a descrição do conjunto de dados e seus fornecedor
- Crie um conceito para população e outro para país, com um arquivo csv enumerando todos os países e seus nomes.
- Criar uma fração com os números populacionais dos países ao longo do tempo. fazendo referência ao conceito de ano já definido no conjunto de dados de tempo importado do Google.
No restante deste tutorial, enriqueceremos nosso conjunto de dados adicionando mais dimensões em mais frações, bem como mais métricas agrupadas por tópico.
Adição de uma dimensão: estados dos EUA
Agora, vamos enriquecer nosso conjunto de dados adicionando dados populacionais para os estados da nos EUA. Primeiro precisamos definir um conceito para os estados. Isso parece muito como o conceito de país que definimos antes.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Extensões e propriedade de conceito referências
O conceito de estado introduz vários novos recursos de DSPL.
Primeiro, o estado estende outro conceito,
geo:location (definido no conjunto de dados geográficos externo que
importado no início do nosso conjunto de dados). Semanticamente, isso significa
state é um tipo de geo:location. Uma consequência é
que ele herde todos os atributos e propriedades
geo:location: Em particular, o local define propriedades
latitude e longitude estendendo a primeira
essas propriedades também são aplicadas ao estado. Além disso, como
o local é herdado de entity:entity, o estado também recebe
todas as propriedades deste último, incluindo name,
description e info_url.
Observação:o conceito de país definido anteriormente
também precisa ter, tecnicamente, a extensão geo:location.
Este ponto foi omitido antes para simplificar; incluímos o
local para herança de país, no entanto,
arquivo XML final.
Observação:você pode usar o extends
construa nos seus próprios conjuntos de dados para reutilizar informações definidas por outros conjuntos de dados.
O uso de extends exige que todas as instâncias do conceito sejam
instâncias válidas do conceito que você está estendendo. As extensões permitem adicionar
propriedades e atributos adicionais e restringe o conjunto de instâncias a um
subconjunto de instâncias do conceito estendido.
Além da herança, a propriedade do estado também introduz o
ideia de referências de conceito.
Especificamente, o conceito de estado tem uma propriedade com o nome country,
que faz referência ao conceito de país que criamos acima. Isso é feito pela
usando um atributo concept. Essa propriedade não
forneça um ID, apenas uma referência de conceito. Isso equivale a criar um ID
com o mesmo valor que o ID do conceito referenciado (ou seja,
country neste exemplo). A relação hierárquica entre
o estado e o condado é capturado com um atributo
isParent="true" na referência. Em geral,
dimensões com relações hierárquicas, como geografias, devem ser
representada dessa forma, com o conceito filho tendo uma propriedade que
faz referência ao conceito pai usando o atributo isParent.
A definição da tabela para os estados tem esta aparência:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
A coluna País tem um valor constante para todos os estados. Especificá-lo em
o DSPL evita repetir esse valor para cada estado dos dados. Observe também
que incluímos colunas para name, latitude e
longitude, já que o estado herdou essas propriedades de
geo:location. Por outro lado, algumas propriedades herdadas
(por exemplo, description) não têm colunas; está tudo bem,
se uma propriedade é omitida de uma tabela de definição de conceito, seu valor é
considerados indefinidos para cada instância do conceito.
O arquivo CSV tem esta aparência:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Como já temos conceitos de população e ano, podemos reutilizá-los. para definir uma nova fração para a população dos estados.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>A definição da tabela de dados é semelhante a esta:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
E o arquivo CSV ficará assim:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Por que criamos uma nova fração em vez de adicionar outra em relação à anterior?
Uma fração com dimensões para estado e país não estaria correta, porque algumas linhas serviriam para dados do país e outras para estado dados. A tabela teria "buracos" para algumas dimensões, que são não é permitido (valores ausentes são permitidos somente para métricas e e não dimensões).
As dimensões atuam como uma "chave primária" para a fatia. Isso significa que cada linha de dados precisa ter valores para todas as dimensões e não pode ter duas linhas de dados podem ter exatamente os mesmos valores para todas as dimensões.
Como adicionar uma métrica: desemprego Avaliar
Agora, vamos adicionar outra métrica ao nosso conjunto de dados:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
A seção info dessa métrica tem um nome, uma descrição e um
URL (link para a Secretaria de Estatísticas Trabalhistas dos EUA).
Esse conceito também estende o conceito canônico quantity:rate.
O atributo quantity
conjunto de dados define os principais conceitos para representar quantidades numéricas. Em
conjunto de dados, você deve criar seus conceitos numéricos estendendo a
o conceito de quantidade apropriada. Assim, o conceito population
definidos acima devem ter, tecnicamente, sido estendidos do
quantity:amount.
Atributos de conceito
Esse conceito também introduz a construção de um atributo. Em
neste exemplo, um atributo é usado para dizer que unemployment_rate
é uma porcentagem. O atributo is_percentage é herdado de
o conceito quantity:rate que esse conceito estende. Isso
é utilizada pelo Explorador de Dados Públicos para mostrar sinais de porcentagem quando
visualizar os dados.
Os atributos fornecem um mecanismo geral para anexar pares de chave-valor a um
(em contraste com as propriedades, que associam valores adicionais a
instâncias de um conceito). Assim como conceitos e propriedades,
atributos têm um id, um info e um
type Assim como as propriedades, elas podem fazer referência a outros conceitos.
Os atributos não servem apenas para itens gerais predefinidos, como dados propriedades. Você pode definir seus próprios atributos para os conceitos.
Como adicionar dados de taxa de desemprego para os EUA Estados
Agora estamos prontos para adicionar dados de taxa de desemprego para estados dos EUA. Devido ao A taxa de desemprego é uma métrica, e já temos dados populacionais de estados, basta adicioná-lo à fração já criada para o estado e o ano dimensões:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... e adicione outra coluna à definição da tabela:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... e ao arquivo CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Já dissemos que, para cada fatia, as dimensões formam uma chave primária para a fatia. Além disso, cada conjunto de dados pode conter apenas uma fração para um determinada combinação de dimensões. Todas as métricas disponíveis devem pertencer à mesma fatia.
Mais dimensões: detalhamento da população por gênero
Vamos enriquecer nosso conjunto de dados com um detalhamento da população por gênero para países. A essa altura, você já está começando a entender o procedimento... Primeiro, precisamos adicione um conceito para gênero:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
A seção info do conceito de gênero tem
pluralName, que fornece o texto a ser usado para se referir à
várias instâncias do conceito de gênero. A seção info também
inclui um totalName, que fornece o texto a ser usado para
referir-se a todas as instâncias do conceito de gênero como um todo. Ambos são
usados pelo Explorador de dados públicos para exibir informações relacionadas ao gênero
conceito. Em geral, você deve fornecê-los para conceitos que podem ser usados como
dimensões.
O conceito de gênero também está se estendendo
entity:entity: Essa é uma boa prática para conceitos
que são usados como dimensões, já que permite adicionar nomes personalizados,
URLs e cores para as várias instâncias de conceito.
O conceito de gênero se refere à tabela genders_table, que
contém os valores possíveis para gênero e seus nomes de exibição
(omitido aqui).
Para adicionar população por gênero ao nosso conjunto de dados, precisamos criar uma nova fatia (lembre: cada combinação disponível de dimensões corresponde a uma fração conjunto de dados).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
A definição da tabela para a fração é semelhante a:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
O arquivo CSV da tabela tem esta aparência:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
Em comparação com os países anteriores, população e fração de desemprego, mas essa tem uma dimensão adicional. cada valor da métrica de população correspondem não só a um país e ano específicos, mas também a um gênero específico.
Note que criamos uma "esparsa" no conjunto de dados. Nem todas estão disponíveis para todas as dimensões: população é disponíveis para países e estados dos EUA todos os anos, enquanto o desemprego está disponível apenas para países. O detalhamento por gênero está disponível para população apenas por país; não está disponível para a taxa de desemprego e não para a dimensão de estado. Também pode haver esparsidade nos dados com determinadas métricas não tendo valores para certos valores de dimensão, mas isso não é representado na DSPL.
Tópicos
O último recurso do DSPL que usaremos no conjunto de dados são os topics. Os tópicos são usados para classificar conceitos hierarquicamente para ajudar os usuários a navegar até os dados.
No arquivo DSPL, os tópicos aparecem logo antes dos conceitos. Aqui está um exemplo hierarquia de tópicos:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>É possível aninhar tópicos o mais profundamente necessário.
Para usar tópicos, você só precisa referenciá-los a partir do conceito da seguinte forma:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Um conceito pode fazer referência a mais de um tópico.
Como enviar seu conjunto de dados
Agora que você criou o conjunto de dados, o próximo passo é compactá-lo e fazer upload do arquivo ZIP para a ferramenta Explorador de Dados Públicos do Google. Em caso de problemas, verifique as Perguntas frequentes, que incluem uma discussão um dos problemas de envio mais comuns.
Para referência, você também pode fazer o download do arquivo XML completo e do pacote completo do conjunto de dados associadas a este tutorial.
O que fazer depois
Parabéns por criar seu primeiro conjunto de dados DSPL. Agora que você entender os princípios básicos, recomendamos a leitura do Guia para desenvolvedores, que, documentos "avançados", entre outras coisas, recursos DSPL, como suporte a várias linguagens e conceitos mapeáveis.
Você também pode ver mais alguns conjuntos de dados de exemplo.