DSPL signifie Dataset Publishing Language. Ensembles de données décrits dans DSPL peuvent être importées dans le dossier Google Public Data Explorer, un outil qui permet une exploration visuelle enrichie données.
Remarque:Pour importer des données dans Google Public Data à l'aide de l'outil d'importation de données publiques ; vous devez disposer d'un compte Google.
Ce tutoriel fournit un exemple étape par étape de la préparation d'un ensemble de données DSPL.
Un ensemble de données DSPL est un groupe qui contient un fichier XML et un ensemble de CSV. Les fichiers CSV sont de simples tables contenant les données des le jeu de données. Le fichier XML décrit les métadonnées de l'ensemble de données. y compris des métadonnées informatives telles que des descriptions de mesures, ainsi que des métadonnées structurelles comme des références entre les tableaux. Les métadonnées permettent les utilisateurs non experts explorent et visualisent vos données.
La seule condition préalable à la compréhension de ce tutoriel est un bon niveau de mieux comprendre le langage XML. Maîtriser des concepts simples liés aux bases de données (par exemple, les tables, les clés primaires) peut vous aider, mais ce n'est pas obligatoire. Pour référence, le fichier XML complet et ensemble de données complet bundle associé à ce tutoriel sont également disponibles pour examen.
Présentation
Avant de commencer à créer notre ensemble de données, voici une vue d'ensemble ce que contient un ensemble de données DSPL:
- Informations générales:à propos de l'ensemble de données
- Concepts:définition du terme "choses" que apparaissent dans l'ensemble de données (par exemple, pays, taux de chômage, genre, etc.)
- Slices (Segments d'application) : combinaisons de concepts pour lesquelles il existe données
- Tables:données pour les concepts et les tranches. Tableaux de concepts stocker les énumérations et les tables de tranches de données contiennent des données statistiques
- Topics (Sujets) : permet d'organiser les concepts de l'ensemble de données. dans une hiérarchie significative grâce à l'étiquetage
Pour illustrer ces notions plutôt abstraites, prenons l'ensemble de données (avec données factices) utilisées tout au long de ce tutoriel: séries temporelles statistiques pour la population et le chômage, agrégés par différentes combinaisons de pays, l'État américain et le genre.
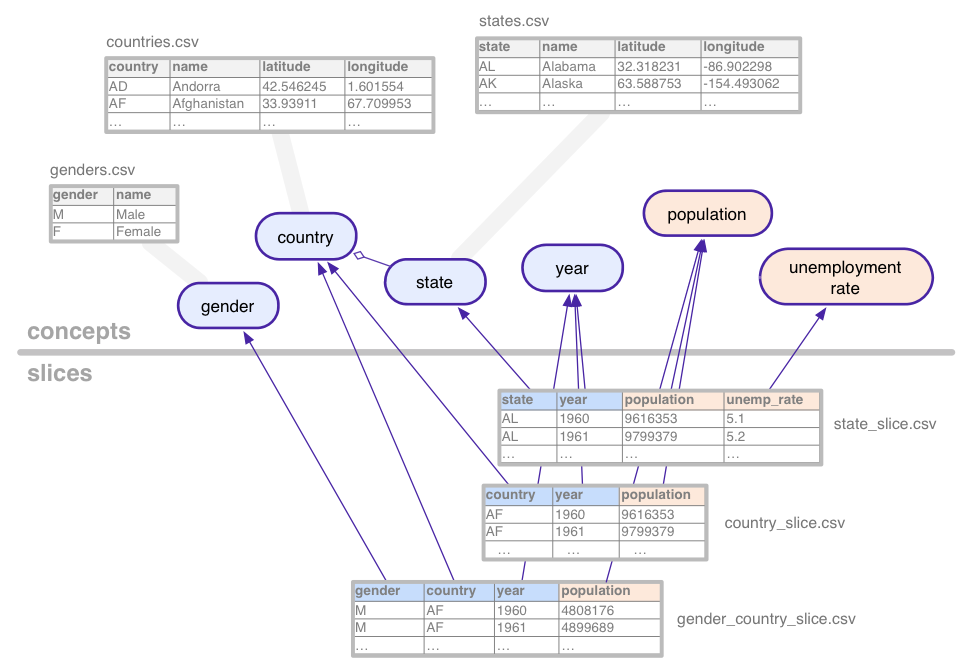
Cet exemple d'ensemble de données définit les concepts suivants:
- country
- gender (genre)
- population
- state
- taux de chômage
- année
Les concepts catégoriels, tels que l'état, sont associés au concept Les tables, qui énumèrent toutes leurs valeurs possibles (Californie, Arizona, etc.). Les concepts peuvent comporter des colonnes supplémentaires pour les propriétés telles que le nom ou le pays d’un État.
Les segments d'application définissent chaque combinaison de concepts pour laquelle il existe
des données statistiques
dans l'ensemble de données. Un secteur contient des dimensions et
métriques. Sur l'image ci-dessus, les dimensions sont bleues et
les métriques sont orange. Dans cet exemple, la tranche
gender_country_slice contient des données pour la métrique
population et les dimensions country,
year et gender. Une autre tranche, appelée
country_slice, donne la population totale annuelle (métrique) pour
pays.
Outre les dimensions et les métriques, les segments font également référence Les tables, qui contiennent les données réelles.
Voyons maintenant, étape par étape, la création d'un tel jeu de données dans DSPL
Informations sur l'ensemble de données
Pour commencer, nous devons créer un fichier XML pour notre ensemble de données. Voici les début d'une description DSPL pour notre exemple de jeu de données:
<?xml version="1.0" encoding="UTF-8"?> <dspl targetNamespace="http://www.stats-bureau.com/mystats" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://schemas.google.com/dspl/2010" xmlns:time="http://www.google.com/publicdata/dataset/google/time" xmlns:geo="http://www.google.com/publicdata/dataset/google/geo" xmlns:entity="http://www.google.com/publicdata/dataset/google/entity" xmlns:quantity="http://www.google.com/publicdata/dataset/google/quantity"> <import namespace="http://www.google.com/publicdata/dataset/google/time"/> <import namespace="http://www.google.com/publicdata/dataset/google/entity"/> <import namespace="http://www.google.com/publicdata/dataset/google/geo"/> <import namespace="http://www.google.com/publicdata/dataset/google/quantity"/> <info> <name> <value>My statistics</value> </name> <description> <value>Some very interesting statistics about countries</value> </description> <url> <value>http://www.stats-bureau.com/mystats/info.html</value> </url> </info> <provider> <name> <value>Bureau of Statistics</value> </name> <url> <value>http://www.stats-bureau.com</value> </url> </provider> ... </dspl>
La description de l'ensemble de données commence par un élément <dspl> de niveau supérieur.
. L'attribut targetNamespace contient un URI qui
identifie de manière unique
cet ensemble de données. L'espace de noms du jeu de données est particulièrement
important lors de la publication de l'ensemble de données, car il s'agit de l'identifiant global
votre jeu de données et les moyens
pour d'autres de s'y référer.
Notez que l'attribut targetNamespace peut être omis. Dans
Dans ce cas, un espace de noms unique est automatiquement généré lorsque l'ensemble de données
importés.
Utiliser des informations provenant d'autres jeux de données
Les ensembles de données peuvent réutiliser les définitions et les données d'autres ensembles de données en important
ces jeux de données. Chaque élément <import> spécifie
espace de noms d'un autre ensemble de données auquel cet ensemble de données fera référence.
Dans notre exemple d'ensemble de données, nous avons besoin de certaines définitions figurant dans http://www.google.com/publicdata/dataset/google/quantity. (un ensemble de données créé par Google qui contient des concepts utiles pour définir quantités numériques), ainsi qu'à partir des ensembles de données heures, entités et géographiques, qui fournissent des définitions liées au temps, aux entités et à la géographie, respectivement.
L'élément <dspl> supérieur fournit un préfixe d'espace de noms
(par exemple, xmlns:time="http://...") pour chaque
des ensembles de données importés. Des déclarations de préfixe sont nécessaires pour référencer
des éléments d'autres jeux
de données de manière concise. Par exemple,
time:year fait référence à la définition de year dans le
ensemble de données importé dont l'espace de noms est associé au préfixe
time
Informations sur l'ensemble de données et le fournisseur
L'élément <info> contient des informations générales sur
le jeu de données: nom, description et URL où des informations supplémentaires peuvent être
trouvé.
L'élément <provider> contient des informations sur la
fournisseur de l'ensemble de données: son nom et une URL où des informations supplémentaires peuvent être
(en général, la page d'accueil du fournisseur de données).
Définir des concepts
Maintenant que nous avons fourni des informations générales sur le jeu de données, nous sommes prêts à commencer à définir son contenu. Notre prochain objectif est d'ajouter les statistiques démographiques des pays sur les 50 dernières années.
La première chose à faire est de fournir quelques définitions des notions de population, de pays et d'année. Dans DSPL, ces définitions sont appelées concepts.
Un concept est une définition d'un type de données qui apparaît dans ensemble de données. Les valeurs de données qui correspondent à un concept donné sont appelées instances de ce concept.
Population
Commençons par définir le concept de population. Dans un
DSPL (les concepts sont définis dans un <concepts>)
juste après l'ensemble de données
et les informations sur le fournisseur.
Voici un concept de population avec très peu d'informations
pour n'importe quel concept: id (identifiant unique), name et
type
<dspl ...> ... <concepts> <concept id="population"> <info> <name> <value>Population</value> </name> </info> <type ref="integer"/> </concept> ... </concepts>
Description de l'exemple
- Chaque concept doit fournir un
idqui identifie de manière unique le concept dans le jeu de données. Cela signifie qu'aucun concept défini dans d'un même ensemble de données peuvent avoir le même identifiant. - Tout comme pour l'ensemble de données et son fournisseur,
Les éléments
<info>fournissent des informations textuelles sur les comme son nom et sa description. - L'élément
<type>spécifie le type de données de la instances du concept (en d'autres termes, ses "valeurs"). Dans cet exemple, le type depopulationestintegerDSPL accepte les types de données suivants: <ph type="x-smartling-placeholder">- </ph>
stringintegerfloatbooleandate
Pays
Écrivons maintenant la définition du concept de pays:
<concept id="country"> <info> <name><value>Country</value></name> <description> <value>My list of countries.</value> </description> </info> <type ref="string"/> <property id="name"> <info> <name><value>Name</value></name> <description> <value>The official name of the country</value> </description> </info> <type ref="string" /> </property> <table ref="countries_table" /> </concept>
La définition du concept de pays commence
comme la précédente,
avec id, info et type.
Valeurs de concept
Les concepts catégoriels, comme les pays, ont une énumération de tous les
Compute Engine. En d'autres termes, vous pouvez lister
tous les pays possibles pour lesquels
référencées. Toutefois, pour ce faire, chaque pays a besoin d'un identifiant unique.
Cet exemple utilise
Codes pays ISO pour identifier les pays ces codes sont
de type string.
Dans cet exemple, vous n'avez pas besoin d'utiliser le code ISO. vous pourrait tout aussi bien utiliser le nom du pays. Toutefois, les noms diffèrent selon les langues, peuvent changer au fil du temps et ne sont pas toujours utilisées de manière cohérente dans les ensembles de données. Pour les pays, et pour les concepts catégoriels en général, s'entraîner à choisir, court, stable, couramment utilisé et indépendant du langage identifiants (s'ils existent).
Propriétés du concept
En plus de id, le concept de pays
Élément <property> spécifiant le nom du pays.
En d'autres termes, le nom du pays ("Irlande") est une propriété
du pays avec l'Irlande id. DSPL fournit les propriétés
des informations structurées supplémentaires
sur les instances d'un concept.
Tout comme le concept, les propriétés ont une id,
info et type.
Données de concept
Enfin, le concept de pays comporte un élément <table>.
Cet élément fait référence à une table qui énumère la liste de tous
pays.
L'utilisation de tableaux a du sens pour certains concepts, mais pas pour d'autres. Pour il n'est pas judicieux d'énumérer toutes les valeurs possibles pour la population du concept. Toutefois, si vous faites référence à un tableau pour un concept, cette table doit contenir toutes les instances de ce concept, par exemple il doit lister tous les pays, pas seulement quelques exemples.
L'ensemble de données définit la table countries_table comme suit:
... <tables> <table id="countries_table"> <column id="country" type="string"/> <column id="name" type="string"/> <data> <file format="csv" encoding="utf-8">countries.csv</file> </data> </table> ... </tables>
Le tableau des pays spécifie les colonnes
du tableau et leur type,
et référence un fichier CSV
contenant les données. Ce fichier CSV peut être
groupé et téléchargé avec le jeu de données XML ou
accessible à distance via HTTP, HTTPS,
ou FTP. Dans les derniers cas, vous devez remplacer countries.csv par
une URL, par exemple http://www.myserver.com/mydata/countries.csv.
Quel que soit l'emplacement de stockage, le fichier CSV se présente comme suit:
country, name AD, Andorra AF, Afghanistan AI, Anguilla AL, Albania US, United States
La première ligne du tableau répertorie les identifiants des colonnes, tels qu'ils sont spécifiés dans la DSPL.
Définition de table. Chacune des lignes suivantes correspond à un
du concept de pays. Si le concept comporte un tableau, alors
La table doit contenir toutes les instances du concept. Dans ce
il doit répertorier tous les pays.
Les colonnes sont mises en correspondance avec le concept du pays et ses propriétés en fonction
son identifiant. L'ID de la première colonne, country, correspond au concept
ID. Cela signifie que cette colonne contient
l'identifiant unique du pays
défini par le concept du pays. La colonne suivante
correspond à
la propriété name du concept de pays. Les valeurs
de cette colonne correspondent aux valeurs de la propriété name.
Les données CSV de la table de concepts doivent respecter certaines exigences:
- Les en-têtes de colonne de la première ligne du fichier de données
correspondent exactement au concept
idet à la propriétéiddu concept auquel les données sont associées (bien que peut varier). - Chaque ligne doit contenir exactement le même nombre d'éléments que le nombre de sur le concept (même si la valeur est vide).
- Chaque valeur du champ
iddu concept (ici, le code pays) doit être unique et non vide (un champ vide correspond à un champ vide ou uniquement des espaces blancs). - Les valeurs des propriétés qui font référence à d'autres concepts doivent être vide ou être une valeur valide du concept référencé.
- Les valeurs contenant des virgules, des guillemets doubles ou des sauts de ligne doivent être entièrement délimitée par des guillemets doubles.
- Tout caractère littéral de "guillemet double" dans une valeur doit être immédiatement précédé d'un autre guillemet double.
Année
Le dernier concept dont nous avons besoin pour
nos données de population d’un pays est un concept pour
représentent des années. Au lieu de définir un nouveau concept, nous utiliserons
de l'un des ensembles de données que nous avons importés:
"http://www.google.com/publicdata/dataset/google/time". Pour ce faire,
nous devons la référencer comme time:year, où time
représente l'ensemble de données référencé, et year identifie
le concept.
Concepts canoniques
time:year fait partie d'un petit ensemble de concepts canoniques.
défini par Google. Les concepts canoniques fournissent
des définitions de base pour le temps,
la zone géographique, les quantités numériques, les unités, etc.
En fait, le concept de pays défini ci-dessus s'applique
concept canonique. Nous ne l'avons créé ici qu'à titre d'illustration.
Dans la mesure du possible, utilisez des concepts canoniques dans vos jeux de données :
directement ou en les étendant (plus d'informations sur l'extension ci-dessous). Concepts canoniques
de rendre vos données comparables à d'autres ensembles de données, et d'activer des fonctionnalités pour vos
ensembles de données dans Public Data Explorer. Par exemple, l'animation de données au fil du temps
ou l'affichage de données géographiques sur une carte, utilisez time et
geo, respectivement.
Première tranche
Maintenant que nous avons les concepts de population, de pays et d'année, il est temps pour les assembler !
Pour cela, nous devons créer une tranche qui les combine. Dans DSPL, une tranche est une combinaison de concepts pour lesquels des données existent.
Pourquoi ne pas simplement créer un tableau avec les bonnes colonnes ? Comme les tranches capturent les informations du jeu de données en termes de concepts. Ce sera plus claire à mesure que nous créons davantage d'éléments de notre jeu de données.
Les segments d'application apparaissent dans le fichier DSPL sous un <slices>
, qui doit apparaître juste après la section concepts.
<slices>
<slice id="countries_slice">
<dimension concept="country"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="countries_slice_table"/>
</slice>
</slices>Tout comme les concepts, chaque segment possède une id
(countries_slice) qui identifie de manière unique le segment dans
ensemble de données.
Un secteur contient deux types de références conceptuelles: Dimensions et
métriques. Les valeurs des métriques varient en fonction des valeurs
. Ici, la valeur de population (la métrique) varie de
les dimensions country et year.
Tout comme les concepts, les tranches incluent une référence à une table qui contient les données de la tranche. Le tableau référencé doit avoir une colonne pour chaque dimension et métrique du secteur. Comme pour les concepts, les dimensions et les métriques sont associées aux colonnes du tableau ayant les mêmes ID.
Table des secteurs
Le tableau correspondant à notre tranche de population apparaît dans le tables
du fichier DSPL:
<tables> ... <table id="countries_slice_table"> <column id="country" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">country_slice.csv</file> </data> </table> ... </tables>
Notez que la colonne year contient un attribut format
qui spécifie le format des années. Les formats de date acceptés sont les suivants :
celles définies par le format Joda DateTime.
La table countries_slice spécifie les colonnes de la table et
leurs types et pointe vers un fichier CSV contenant les données. Fichier CSV
se présente comme suit:
country, year, population AF, 1960, 9616353 AF, 1961, 9799379 AF, 1962, 9989846 AF, 1963, 10188299 ...
Chaque ligne du tableau de données contient une combinaison unique de dimensions.
country et year, ainsi que la valeur correspondante
de la métrique population (par exemple, la population
metric - de l'Afghanistan en 1960 - dimensions).
Notez que les valeurs de la colonne country correspondent aux
valeur/identifiant du concept country, qui est la norme ISO 3166
Code à deux lettres du pays.
Les données CSV d'une tranche doivent respecter les contraintes suivantes:
- Chaque valeur d'un champ de dimension (
countryetyear) ne doit pas être vide. Les valeurs des champs de métriques (commepopulation) peut être vide. Une valeur vide est représentée par caractères. - Chaque valeur d'un champ de dimension faisant référence à un concept doit être
présentes dans les données de ce concept. Par exemple, la valeur
AFdoit figurer dans la table de données conceptuellecountry. - Chaque combinaison unique de valeurs de dimension (ex. :
AF, 2000, ne peuvent survenir qu'une seule fois. - Les données doivent être triées en fonction des colonnes de dimensions non temporelles (dans n'importe quel ordre).
et éventuellement par l'une des autres colonnes. Par exemple,
dans un tableau comportant les colonnes
[date, dimension1, dimension2, metric1, metric2], vous pouvez trier pardimension1, puisdimension2, puisdate, mais pasdate, puis les dimensions.
Résumé
À ce stade, notre DSPL dispose de suffisamment d'informations pour décrire le pays sur la population. Pour récapituler, ce que nous avons dû faire:
- Créez l'en-tête DSPL et la description du jeu de données et de ses fournisseur
- Créez un concept pour la population et un autre pour le pays, avec une csv énumérant tous les pays et leur nom.
- Créer une tranche avec nos chiffres de population pour les pays au fil du temps, en référençant le concept d'année déjà défini dans l'ensemble de données temporelle importé de Google.
Dans la suite de ce tutoriel, nous allons enrichir notre ensemble de données en en ajoutant plus de dimensions dans plus de secteurs, ainsi que d'autres métriques regroupées par sur ce sujet.
Ajout d'une dimension: États des États-Unis
Enrichissons maintenant notre ensemble de données en ajoutant des données de population pour les États de aux États-Unis. Nous devons d'abord définir un concept pour les états. Cela semble beaucoup comme le concept de pays que nous avons défini précédemment.
<concept id="state" extends="geo:location">
<info>
<name>
<value>state</value>
</name>
<description>
<value>US states, identified by their two-letter code.</value>
</description>
</info>
<property concept="country" isParent="true" />
<table ref="states_table"/>
</concept>Propriété et extensions de concept références
Le concept d'état introduit plusieurs nouvelles fonctionnalités de DSPL.
Premièrement, l'état étend un autre concept,
geo:location (défini dans l'ensemble de données géographiques externe que nous
importés au début de notre ensemble de données). D'un point de vue sémantique, cela signifie
state est un type de geo:location. Une conséquence est
qu'elle hérite de tous les attributs et propriétés
geo:location En particulier, l'emplacement définit les propriétés
latitude et longitude ; en prolongeant l'ancienne
ces propriétés s'appliquent également à l'état. De plus, puisque
l'emplacement hérite de entity:entity, l'état obtient également
toutes les propriétés de ce dernier, y compris name,
description et info_url.
Remarque:Le concept de pays défini précédemment
Techniquement, devrait être également étendue à partir de geo:location.
Ce point a été omis auparavant pour plus de simplicité ; nous avons inclus les
l'héritage du lieu en fonction du pays.
fichier XML final.
Remarque:Vous pouvez utiliser la extends
construire dans vos propres jeux de données pour réutiliser
les informations définies par d'autres jeux de données.
L'utilisation de extends nécessite que toutes les instances de votre concept soient
des instances valides du
concept que vous étendez. Les extensions vous permettent d'ajouter
des propriétés et attributs supplémentaires, et de limiter l'ensemble d'instances
sous-ensemble des instances du concept étendu.
En plus de l'héritage, la propriété d'état introduit également
idée de références conceptuelles.
En particulier, le concept d'état inclut une propriété appelée country,
qui fait référence au concept de pays
que nous avons créé ci-dessus. Cela se fait en
à l'aide d'un attribut concept. Notez que cette propriété
fournissez un identifiant, mais uniquement une référence conceptuelle. Cela revient à créer un identifiant
ayant la même valeur que l'identifiant du concept référencé (par exemple,
country dans cet exemple). La relation hiérarchique entre
l'état et le comté sont capturés à l'aide d'un attribut
isParent="true" sur la référence. En général,
associées à des relations hiérarchiques, telles que les zones géographiques,
de cette façon, le concept enfant ayant une propriété
référence le concept parent à l'aide de l'attribut isParent.
La définition de la table pour les états se présente comme suit:
<tables> ... <table id="states_table"> <column id="state" type="string"/> <column id="name" type="string"/> <column id="country" type="string"> <value>US</value> </column> <column id="latitude" type="float"/> <column id="longitude" type="float"/> <data> <file format="csv" encoding="utf-8">states.csv</file> </data> </table> ... </tables>
La colonne "country" contient une valeur constante pour tous les États. Le spécifier dans
le DSPL évite de répéter cette
valeur pour chaque état dans les données. Notez également
que nous avons inclus les colonnes name, latitude et
longitude, car l'État a hérité de ces propriétés
geo:location D'autre part, certaines propriétés héritées
(par exemple, description) n'ont pas de colonnes. Tout va bien...
Si une propriété est omise d'un tableau de définition de concept, sa valeur est
est supposé être non défini pour chaque instance du concept.
Le fichier CSV se présente comme suit:
state, name, latitude, longitude AL, Alabama, 32.318231, -86.902298 AK, Alaska, 63.588753, -154.493062 AR, Arkansas, 35.20105, -91.831833 AZ, Arizona, 34.048928, -111.093731 CA, California, 36.778261, -119.417932 CO, Colorado, 39.550051, -105.782067 CT, Connecticut, 41.603221, -73.087749 ...
Comme nous avons déjà des concepts de population et d'année, nous pouvons les réutiliser pour définir une nouvelle tranche pour la population des États.
<slices>
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<table ref="states_slice_table"/>
</slice>
</slices>La définition de la table de données se présente comme suit:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <file format="csv" encoding="utf-8">state_slice.csv</file> </table> ... </tables>
Le fichier CSV se présente comme suit:
state, year, population AL, 1960, 9616353 AL, 1961, 9799379 AL, 1962, 9989846 AL, 1963, 10188299
Pourquoi avons-nous créé un segment, au lieu d'en ajouter un autre ? à la dimension précédente ?
Une tranche avec des dimensions pour l'État et le pays ne serait pas correcte. car certaines lignes concernent les données de pays et d'autres les données données. Le tableau aurait des « trous » pour certaines dimensions, ce qui non autorisé (n'oubliez pas que les valeurs manquantes ne sont autorisées que pour les métriques et et non des dimensions).
Les dimensions servent de "clé primaire" pour le segment. Cela signifie que Chaque ligne de données doit contenir des valeurs pour toutes les dimensions, mais pas deux lignes de données. peuvent avoir les mêmes valeurs pour toutes les dimensions.
Ajouter une métrique: chômage Noter
Ajoutons maintenant une autre métrique à notre ensemble de données:
<concept id="unemployment_rate" extends="quantity:rate"> <info> <name> <value>Unemployment rate</value> </name> <description> <value>The percent of the labor force that is unemployed.</value> </description> <url> <value>http://www.bls.gov/cps/cps_htgm.htm</value> </url> </info> <type ref="float/> <attribute id="is_percentage"> <type ref="boolean"/> <value>true</value> </attribute> </concept>
La section info de cette métrique comporte un nom, une description et une
URL (lien vers le Bureau des statistiques du travail des États-Unis).
Ce concept étend également le concept canonique quantity:rate.
La quantité
ensemble de données définit les concepts fondamentaux qui permettent de représenter des quantités numériques. Dans
votre ensemble de données, vous devez créer vos concepts numériques en étendant
le concept de quantité approprié. Ainsi, le concept population
définis ci-dessus devraient, techniquement, être étendues
quantity:amount
Attributs de concept
Ce concept introduit également la construction d'un attribut. Dans
Dans cet exemple, un attribut est utilisé pour indiquer que unemployment_rate
est un pourcentage. L'attribut is_percentage est hérité de
le concept quantity:rate que ce concept étend. Ce
sont utilisées par Public Data Explorer pour afficher des signes de pourcentage lorsque
visualiser les données.
Les attributs fournissent un mécanisme général pour associer des paires clé/valeur
(contrairement aux propriétés, qui associent des valeurs supplémentaires
instances d'un concept). Tout comme les concepts et les propriétés,
ont les attributs id, info et
type Tout comme les propriétés, elles peuvent faire référence à d'autres concepts.
Les attributs ne sont pas réservés à des éléments généraux prédéfinis, comme des valeurs numériques, propriétés. Vous pouvez définir vos propres attributs pour vos concepts.
Ajout des données sur le taux de chômage pour les États-Unis États
Nous sommes maintenant prêts à ajouter les données sur le taux de chômage pour les États américains. En effet, le taux de chômage est une mesure et nous avons déjà des données sur la population pour les États, nous pouvons simplement l'ajouter à la tranche que nous avons déjà créée pour l'état et l'année dimensions:
<slices>
...
<slice id="states_slice">
<dimension concept="state"/>
<dimension concept="time:year"/>
<metric concept="population"/>
<metric concept="unemployment_rate"/>
<table ref="states_slice_table"/>
</slice>
...
</slices>... et ajouter une colonne à la définition de la table:
<tables> ... <table id="states_slice_table"> <column id="state" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <column id="unemployment_rate" type="float"/> <data> <file format="csv" encoding="utf-8">state_slice.csv</file> </data> </table> ... </tables>
... et au fichier CSV:
state, year, population, unemployment_rate AL, 1960, 9616353, 5.1 AL, 1961, 9799379, 5.2 AL, 1962, 9989846, 4.8 AL, 1963, 10188299, 6.9
Comme nous l'avons vu précédemment, les dimensions forment, pour chaque tranche, une clé primaire pour le segment. De plus, chaque jeu de données ne peut contenir qu'une seule tranche pour une une combinaison de dimensions donnée. Toutes les métriques disponibles pour doivent appartenir au même secteur.
Autres dimensions: Répartition de la population par sexe
Enrichissons notre ensemble de données avec une répartition de la population par genre pour pays. À présent, vous commencez à connaître l'exercice... Nous devons d'abord ajoutez un concept pour le genre:
<concept id="gender" extends="entity:entity"> <info> <name> <value>Gender</value> </name> <description> <value>Gender, Male or Female</value> </description> <pluralName> <value>Genders</value> </pluralName> <totalName> <value>Both genders</value> </totalName> </info> <type ref="string"/> <table ref="genders_table"/> </concept>
La section sur le concept de genre info comporte une
pluralName, qui fournit le texte à utiliser pour désigner
plusieurs instances du concept de genre. La section info comporte également
inclut un totalName, qui fournit le texte à utiliser pour
se réfèrent à toutes les instances
du concept de genre dans son ensemble. Ces deux exemples sont
utilisé par Public Data Explorer pour afficher des informations sur le genre
concept. En général, vous devez les fournir pour des concepts qui peuvent être utilisés comme
.
Notez que le concept de genre s'étend aussi
entity:entity C'est une bonne pratique
pour les concepts
utilisées comme dimensions, car elles vous permettent d'ajouter des noms personnalisés,
des URL et des couleurs pour les différentes instances de concept.
Le concept de genre fait référence à la table genders_table, qui
contient les valeurs possibles pour le sexe et son nom à afficher
(omis ici).
Pour ajouter la population par genre à notre ensemble de données, nous devons créer une tranche (rappelez-vous: chaque combinaison de dimensions disponible correspond à un secteur de l'ensemble de données).
<slice id="countries_gender_slice"> <dimension concept="country"/> <dimension concept="gender"/> <dimension concept="time:year"/> <metric concept="population"/> <table ref="countries_gender_slice_table"/> </slice>
La définition de la table pour la tranche se présente comme suit:
<table id="countries_gender_slice_table"> <column id="country" type="string"/> <column id="gender" type="string"/> <column id="year" type="date" format="yyyy"/> <column id="population" type="integer"/> <data> <file format="csv" encoding="utf-8">gender_country_slice.csv</file> </data> </table>
Le fichier CSV de la table se présente comme suit:
country, gender, year, population AF, M, 1960, 4808176 AF, F, 1960, 4808177 AF, M, 1961, 4899689 AF, F, 1961, 4899690...
Par rapport aux pays précédents, à la population et à la tranche de chômage, celui-ci a une dimension supplémentaire ; chaque valeur de la métrique "population" correspond non seulement à un pays et à une année spécifiques, mais aussi à un genre particulier.
Notez que nous avons créé une couche ensemble de données. Il est possible que sont disponibles pour toutes les dimensions: la population est disponibles pour les pays et les États américains, sur une base annuelle, tandis que l'assurance chômage n'est disponible que pour les pays. La répartition par genre est disponible pour la population par pays uniquement ; il n'est pas disponible pour le taux de chômage et non à la dimension "État". La parcimonie peut également exister et que certaines métriques n'ont pas de valeur pour certaines dimensions, mais cela n'est pas représenté dans DSPL.
Thèmes
La dernière fonctionnalité de DSPL que nous allons utiliser dans notre ensemble de données concerne les topics. Les thèmes sont utilisés pour classer des concepts de manière hiérarchique et sont utilisés par applications pour aider les utilisateurs à accéder à vos données.
Dans le fichier DSPL, les thèmes apparaissent juste avant les concepts. Voici un exemple hiérarchie des sujets:
<dspl ... >
...
<topics>
<topic id="geography">
<info>
<name>
<value>Geography</value>
</name>
</info>
</topic>
<topic id="social_indicators">
<info>
<name>
<value>Social indicators</value>
</name>
</info>
</topic>
<topic id="population_indicators">
<info>
<name>
<value>Population indicators</value>
</name>
</info>
</topic>
<topic id="poverty_and_income">
<info>
<name>
<value>Poverty & income</value>
</name>
</info>
</topic>
<topic id="health">
<info>
<name>
<value>Health</value>
</name>
</info>
</topic>
</topics>Vous pouvez imbriquer des sujets aussi profondément que nécessaire.
Pour utiliser des sujets, il vous suffit de les référencer dans le concept comme suit:
<concept id="population"> <info> <name> <value>Population</value> </name> <description> <value>Size of the resident population.</value> </description> </info> <topic ref="population_indicators"/> <type ref="integer"/> </concept>
Un concept peut faire référence à plusieurs sujets.
Envoyer votre ensemble de données
Maintenant que vous avez créé votre ensemble de données, l'étape suivante consiste à le compresser et à le compresser importez le fichier zip sur l'outil Google Public Data Explorer. En cas de problème, vérifiez Les questions fréquentes, qui incluent une discussion des problèmes de mise en ligne les plus courants.
Pour référence, vous pouvez également télécharger le fichier XML complet et le bundle d'ensembles de données complets. associées à ce tutoriel.
Étapes suivantes
Félicitations ! Vous avez créé votre premier ensemble de données DSPL. Maintenant que vous de comprendre les principes de base, nous vous recommandons de lire le guide du développeur, qui, entre autres, les documents « avancés » Les fonctionnalités DSPL telles que la prise en charge multilingue et les concepts mappables.
Vous pouvez également consulter d'autres exemples d'ensembles de données.