Wyjaśnienie techniczne, przeznaczone do wdrożenia projektu Android Open Source Project (AOSP), przedstawia motywację stojącą za personalizacją na urządzeniu (ODP), zasady projektowania, na których opiera się jej rozwój, zasady ochrony prywatności przez model poufności oraz sposoby, w jakie pomaga ona zapewnić wiarygodną prywatność.
Planujemy osiągnąć ten cel, upraszczając model dostępu do danych i dbając o to, aby wszystkie dane użytkownika, które opuszczają granicę zabezpieczeń, były zróżnicowane i prywatne na poziomie poszczególnych użytkowników (użytkownik, użytkownik, użytkownik wysyłający dane, model_instance) (czasami skracane do poziomu użytkownika w tekście poniżej).
Cały kod związany z potencjalnym ruchem wychodzącym z urządzeń użytkowników będzie dostępny na licencji open source i będzie możliwy do zweryfikowania przez podmioty zewnętrzne. Na początkowych etapach tworzenia oferty staramy się wzbudzać zainteresowanie i zbierać opinie na temat platformy, która umożliwia personalizację na urządzeniu. Zapraszamy do kontaktu z nami zainteresowane osoby, takie jak eksperci ds. prywatności, analitycy danych i specjaliści ds. bezpieczeństwa.
Przetwarzanie obrazu
Personalizacja na urządzeniu ma na celu ochronę informacji użytkowników przed firmami, z którymi nie wchodzili oni w interakcje. Firmy mogą nadal dostosowywać swoje produkty i usługi pod kątem użytkowników (np. za pomocą odpowiednio zanonimizowanych i różnorodnie prywatnych modeli systemów uczących się), ale nie będą mieć wglądu w dokładne dane dotyczące użytkownika (które zależą nie tylko od reguły dostosowywania wygenerowanej przez właściciela firmy, ale także od indywidualnych preferencji użytkownika), chyba że zachodzą bezpośrednie interakcje między firmą a użytkownikiem. Jeśli firma tworzy modele systemów uczących się lub analizy statystyczne, ODP dba o to, aby zostały odpowiednio anonimizowane za pomocą odpowiednich mechanizmów prywatności różnicowej.
W bieżącym planie planujemy wdrożenie ODP w kilku etapach, uwzględniając następujące funkcje. Zachęcamy również zainteresowane strony do konstruktywnego zaproponowania wszelkich dodatkowych funkcji lub przepływów pracy, które pomogą nam w uzupełnieniu tej analizy:
- Środowisko piaskownicy, w którym cała logika biznesowa jest zawarta i realizowana, co umożliwia dostęp do niej wielu sygnałów użytkownika, ograniczając jednocześnie dane wyjściowe.
W pełni szyfrowane magazyny danych dla:
- Kontrola użytkowników i inne dane związane z użytkownikiem. Dane te mogą być przekazywane przez użytkowników lub zbierane i wywnioskowane przez firmy, wraz z ustawieniami czasu życia danych (TTL), zasadami usuwania danych, polityką prywatności itp.
- Konfiguracje firmy. ODP udostępnia algorytmy do kompresji i zaciemnienia tych danych.
- Wyniki dotyczące przetwarzania danych biznesowych. Mogą to być:
- Wykorzystywane jako dane wejściowe w późniejszych rundach przetwarzania,
- Zaszumione przez odpowiednie mechanizmy ochrony prywatności różnicowej i przesłane do kwalifikujących się punktów końcowych.
- Przesłane za pomocą zaufanego procesu przesyłania do zaufanych środowisk wykonawczych (TEE) obsługujących zadania open source z odpowiednimi centralnymi mechanizmami prywatności różnicowej
- Wyświetlane użytkownikom.
Interfejsy API zaprojektowane do:
- Zaktualizuj 2(a), wsadową lub przyrostowo.
- Zaktualizuj 2(b) okresowo, zbiorczo lub stopniowo.
- Prześlij punkt 2(c) z odpowiednimi mechanizmami szumującymi w zaufanych środowiskach agregacji. Takie wyniki mogą zostać oznaczone jako 2(b) w kolejnych rundach przetwarzania.
Zasady dotyczące projektowania
ODP niesie ze sobą 3 filary: prywatność, uczciwość i użyteczność.
Model danych z wysokim poziomem ochrony prywatności
ODP jest zgodny z zasadą prywatności w fazie projektowania i zaprojektowano ją z myślą o ochronie prywatności użytkowników.
ODP bada przeniesienie przetwarzania personalizacji na urządzenie użytkownika. Takie podejście zapewnia równowagę między prywatnością i przydatnością, ponieważ umożliwia przechowywanie danych na urządzeniu w maksymalnym zakresie i przetwarzanie ich poza urządzeniem tylko wtedy, gdy jest to konieczne. ODP koncentruje się na:
- Kontrola nad danymi użytkownika, nawet gdy opuści urządzenie. Miejsca docelowe muszą być poświadczone zaufanych środowisk wykonawczych oferowanych przez dostawców chmury, którzy korzystają z kodu ODP.
- Weryfikowanie przez urządzenie tego, co dzieje się z danymi użytkownika, gdy opuści urządzenie. ODP udostępnia zadania open source (sfederowane) Compute do koordynowania systemów uczących się działających na różnych urządzeniach oraz analizy statystycznej. Urządzenie użytkownika będzie sprawdzać, czy takie zadania są wykonywane w niezmodyfikowanych zaufanych środowiskach wykonawczych.
- Gwarantowana techniczna prywatność (np. agregacja, szum, prywatność różnicowa) danych wyjściowych, które wykraczają poza granicę kontrolowanych lub weryfikowanych przez urządzenie.
W konsekwencji personalizacja będzie zależeć od urządzenia.
Co więcej, firmy wymagają również środków ochrony prywatności, na które platforma powinna się skupić. Wiąże się to z utrzymywaniem nieprzetworzonych danych biznesowych na odpowiednich serwerach. W tym celu ODP wykorzystuje ten model danych:
- Każde nieprzetworzone źródło danych będzie przechowywane na urządzeniu lub po stronie serwera, co umożliwi lokalne uczenie się i wnioskowanie.
- Udostępniamy algorytmy ułatwiające podejmowanie decyzji związanych z wieloma źródłami danych, np. przez filtrowanie danych między 2 odmiennymi lokalizacjami danych lub trenowanie bądź wnioskowanie z różnych źródeł.
W tym kontekście może to być zarówno Business Tower, jak i grupa użytkowników końcowych:
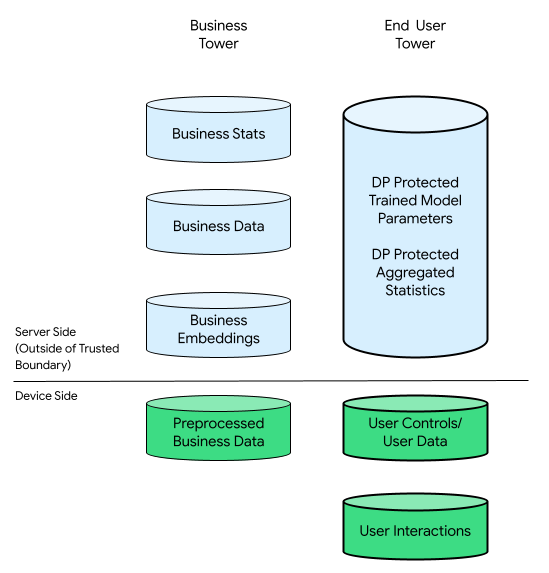
W grupie użytkowników znajdują się dane dostarczone przez użytkownika (np. informacje o koncie i elementy sterujące), dane o interakcjach użytkownika z jego urządzeniem oraz dane pochodne (np. dotyczące zainteresowań i preferencji) ustalone przez firmę. Dane wywnioskowane nie zastępują bezpośrednich deklaracji użytkownika.
Dla porównania – w infrastrukturze skoncentrowanej na chmurze wszystkie nieprzetworzone dane z maszyn wirtualnych są przenoszone na serwery firmy. Natomiast w infrastrukturze zorientowanej na urządzenia wszystkie nieprzetworzone dane z maszyn wirtualnych użytkowników pozostają u źródła, a dane firmy są przechowywane na serwerach.
Personalizacja na urządzeniu łączy to, co najlepsze w obu tych rozwiązaniach, ponieważ do przetwarzania danych, które mogą być powiązane z użytkownikami TEE, wykorzystując więcej prywatnych kanałów wyjściowych, musi używać tylko atestowanego kodu open source.
Zaangażowanie opinii publicznej na rzecz sprawiedliwych rozwiązań.
ODP ma na celu zapewnienie zrównoważonego środowiska dla wszystkich użytkowników w zróżnicowanym ekosystemie. Zdajemy sobie sprawę z złożoności tego ekosystemu obejmującego różnych graczy oferujących różne usługi i produkty.
Aby inspirować do innowacji, ODP udostępnia interfejsy API, które mogą być wdrażane przez deweloperów i firmy, które reprezentują. Personalizacja na urządzeniu ułatwia płynną integrację tych implementacji oraz zarządzanie wersjami, monitorowaniem, narzędziami dla programistów i narzędziami do przekazywania opinii. Personalizacja na urządzeniu nie tworzy konkretnej logiki biznesowej, ale służy jako katalizator kreatywności.
Z czasem ODP może oferować więcej algorytmów. Współpraca z ekosystemem jest niezbędna do określenia odpowiedniego poziomu funkcji i potencjalnie ustanowienia rozsądnych limitów zasobów dotyczących urządzeń dla każdej firmy biorącej udział w programie. Przewidujemy opinie od ekosystemu, które pomogą nam rozpoznać nowe przypadki użycia i nadać im priorytet.
Narzędzia dla programistów zwiększające wygodę użytkowników
Dzięki ODP nie tracisz danych zdarzeń ani opóźnień obserwacji, ponieważ wszystkie zdarzenia są rejestrowane lokalnie na poziomie urządzenia. Nie występują błędy dołączania, a wszystkie zdarzenia są powiązane z konkretnym urządzeniem. W rezultacie wszystkie obserwowane zdarzenia w naturalny sposób tworzą sekwencję chronologiczną, która odzwierciedla interakcje użytkownika.
Ten uproszczony proces eliminuje konieczność złączania i zmieniania kolejności danych. Umożliwia to dostęp do danych użytkownika w czasie zbliżonym do rzeczywistego i nie wymaga utraty dostępu. To z kolei może zwiększyć użyteczność postrzeganą przez użytkowników podczas korzystania z produktów i usług opartych na danych, co może skutkować wyższym poziomem zadowolenia i wartościowymi doświadczeniami. Dzięki ODP firmy mogą skutecznie dostosowywać się do potrzeb użytkowników.
Model prywatności: prywatność przez poufność
W kolejnych sekcjach omówiono model producenta konsumenta jako podstawę tej analizy prywatności oraz porównanie prywatności środowiska obliczeniowego z dokładnością danych wyjściowych.
Model producenta konsumenta jako podstawa tej analizy prywatności
Do sprawdzania gwarancji prywatności dotyczących prywatności poprzez poufność będziemy stosować model producenta konsumenckiego. Obliczenia w tym modelu są przedstawiane jako węzły w kierowanym grafie acyklicznym (DAG), który składa się z węzłów i podgrafów. Każdy węzeł obliczeniowy składa się z 3 komponentów: zużywanych danych wejściowych, uzyskanych danych wyjściowych i danych wejściowych do mapowania na dane wyjściowe.

W tym modelu ochrona prywatności obejmuje wszystkie 3 komponenty:
- Prywatność danych wejściowych. Węzły mogą mieć 2 rodzaje danych wejściowych. Jeśli dane wejściowe są generowane przez poprzedni węzeł, mają już takie same wyjściowe zabezpieczenia prywatności. W przeciwnym razie dane wejściowe muszą wyczyścić zasady ruchu przychodzącego danych za pomocą mechanizmu zasad.
- Prywatność wyjściowa. Wyniki mogą wymagać prywatności, na przykład w ramach ochrony prywatności różnicowej.
- Poufność środowiska obliczeniowego. Obliczenia muszą odbywać się w zabezpieczonym środowisku, tak aby nikt nie miał dostępu do stanów pośrednich w węźle. Umożliwiają to technologie sfederowane (FC), sprzętowe Trusted Execution Environments (TEE), bezpieczne systemy obliczeniowe wielostronne (sMPC), szyfrowanie homomorficzne (HPE) i inne. Warto zauważyć, że prywatność w ramach środków ochrony poufności
Państwa pośredników i wszystkie dane wyjściowe wychodzące poza granicę poufności nadal muszą być chronione przez mechanizmy prywatności różnicowej. Oto 2 wymagane roszczenia:
- poufność środowisk, co oznacza, że tylko zadeklarowane dane wyjściowe opuszczają
- dźwiękowość, która umożliwia dokładne odliczenie ogłoszeń dotyczących prywatności w wynikach z danych wejściowych. Dźwiękowość umożliwia propagację właściwości prywatności w obrębie DAG-a.
System prywatny zachowuje prywatność danych wejściowych, poufność środowiska obliczeniowego i prywatność danych wyjściowych. Można jednak ograniczyć liczbę zastosowań mechanizmów ochrony prywatności różnicowej, zabezpieczając więcej procesów przetwarzania w poufnym środowisku obliczeniowym.
Ten model ma dwie główne zalety. Po pierwsze, większość systemów, dużych i małych, można przedstawić jako DAG-i. Po drugie, właściwości przetwarzania danych [section 2.1] i kompozycji Lemma 2.4 w złożoności prywatności różnicowej umożliwiają skuteczne narzędzia do analizowania równowagi (najgorszego przypadku) z prywatnością i dokładnością na całym wykresie:
- Przetwarzanie końcowe daje gwarancję, że po prywatyzacji ilość nie może zostać „nieprywatna”, jeśli oryginalne dane nie zostaną ponownie użyte. Dopóki wszystkie dane wejściowe węzła są prywatne, dane wyjściowe pozostaną prywatne niezależnie od obliczeń.
- Zaawansowana kompozycja gwarantuje, że jeśli każda część wykresu jest DP, również całkowity wykres będzie skutecznie ograniczał wartości i delta ostatecznego wyniku wykresu odpowiednio o około Play⋮, przy założeniu, że wykres ma jednostki Akceptuj, a wynik każdej z nich to (żeby , obecny)-DP.
W każdym węźle te 2 właściwości tworzą 2 zasady projektowania:
- Usługa 1 (z przetwarzania po przetworzeniu), jeśli dane wejściowe węzła to DP, dane wyjściowe to DP, uwzględniające dowolną logikę biznesową wykonywaną w węźle i obsługują „tajne źródła” firm.
- Usługa 2 (z kompozycji zaawansowanej), jeśli dane wejściowe węzła nie są zgodne ze wszystkimi DP, jego dane wyjściowe muszą być zgodne z DP. Jeśli węzeł obliczeniowy to taki, który działa w zaufanych środowiskach wykonawczych i wykonuje zadania i konfiguracje udostępniane na licencji open source, możliwe są węższe granice DP. W przeciwnym razie personalizacja na urządzeniu może wymagać użycia progów DPFP. Ze względu na ograniczenia zasobów początkowo priorytetowo będą traktowane zaufane środowiska wykonawcze oferowane przez dostawców chmury publicznej.
Prywatność środowiska obliczeniowego a dokładność danych wyjściowych
Od tej pory personalizacja na urządzeniu będzie skupiać się na zwiększaniu bezpieczeństwa poufnych środowisk obliczeniowych i zapewnianiu niedostępności stanów pośrednich. Ten proces zabezpieczeń, znany jako uszczelnianie, będzie stosowany na poziomie podpunktu, dzięki czemu wiele węzłów może być jednocześnie zgodnych z DP. Oznacza to, że wspomniana wcześniej usługa 1 i usługa 2 są stosowane na poziomie podtytułu.

Oczywiście dane wyjściowe 7 są podzielone zgodnie z poszczególnymi kompozycjami. Oznacza to, że na tym wykresie widoczne są łącznie 2 DP. Dla porównania, jeśli nie zastosowano uszczelnienia, łączna wartość DP będzie równa 3.
Zasadniczo, zabezpieczając środowisko obliczeniowe i eliminując możliwości dostępu przeciwników do danych wejściowych wykresu lub podgrafu i stanów przejściowych, umożliwia to wdrożenie Central DP (czyli danych wyjściowych zamkniętego środowiska zgodnego z DP), co może zwiększyć dokładność w porównaniu z lokalnymi danymi wejściowymi (tzn. dane wyjściowe są zgodne z poszczególnymi danymi). Na tej zasadzie FC, TEE, sMPC i HPE są uznawane za technologie ochrony prywatności. zapoznaj się z rozdziałem 10 artykułu Złożoność prywatności różnicowej.
Dobrym i praktycznym przykładem jest trenowanie i wnioskowanie modelu. W dyskusjach poniżej przyjęto założenie, że: (1), populacja na potrzeby trenowania i populacja wnioskowania pokrywają się oraz (2) zarówno funkcje, jak i etykiety stanowią prywatne dane użytkownika. Możemy zastosować DP do wszystkich danych wejściowych:

Personalizacja na urządzeniu może stosować lokalne DP do etykiet i funkcji użytkowników przed wysłaniem ich na serwery. Takie podejście nie narzuca żadnych wymagań na środowisko wykonawcze serwera ani jego logikę biznesową.



To jest bieżący projekt personalizacji na urządzeniu.
Potwierdzono prywatny
Personalizacja na urządzeniu powinna być weryfikowalna i prywatna. Skupia się na weryfikacji tego, co dzieje się poza urządzeniami użytkowników. ODP utworzy kod, który przetwarza dane opuszczające urządzenia użytkowników, i użyje architektury RATS procedur zdalnego uwierzytelniania w standardzie RFC 9334 w celu potwierdzenia, że taki kod działa bez zmian na zgodnym z Confidential Computing Consortium serwerze z wyłączonym dostępem administratora instancji. Kody te będą udostępniane na licencji open source i będziesz mieć dostęp do ich w ramach przejrzystej weryfikacji w celu budowania zaufania. Takie środki dają pewność, że ich dane są chronione, a firmy mogą budować reputację na podstawie solidnych podstaw zapewnienia prywatności.
Kolejnym ważnym aspektem personalizacji na urządzeniu jest ograniczenie ilości gromadzonych i przechowywanych danych prywatnych. Jest ona zgodna z tą zasadą i wdraża technologie takie jak sfederowane oblicze obliczeniowe i prywatność różnicową, które umożliwiają odkrywanie cennych wzorców danych bez ujawniania poufnych szczegółów dotyczących poszczególnych osób lub informacji umożliwiających ich identyfikację.
Kolejnym kluczowym aspektem możliwej do zweryfikowania prywatności jest utrzymywanie rejestru kontrolnego, w którym rejestrowane są działania związane z przetwarzaniem i udostępnianiem danych. Umożliwia to tworzenie raportów z kontroli i identyfikację luk w zabezpieczeniach, co pokazuje nasze zobowiązanie do ochrony prywatności.
Prosimy o konstruktywną współpracę ze strony ekspertów, władz, firm z branży i indywidualnych specjalistów ds. ochrony prywatności, aby stale ulepszać projekty i wdrożenia.
Wykres poniżej przedstawia ścieżkę kodu do agregacji danych na różnych urządzeniach i szumu w zależności od prywatności różnicowej.
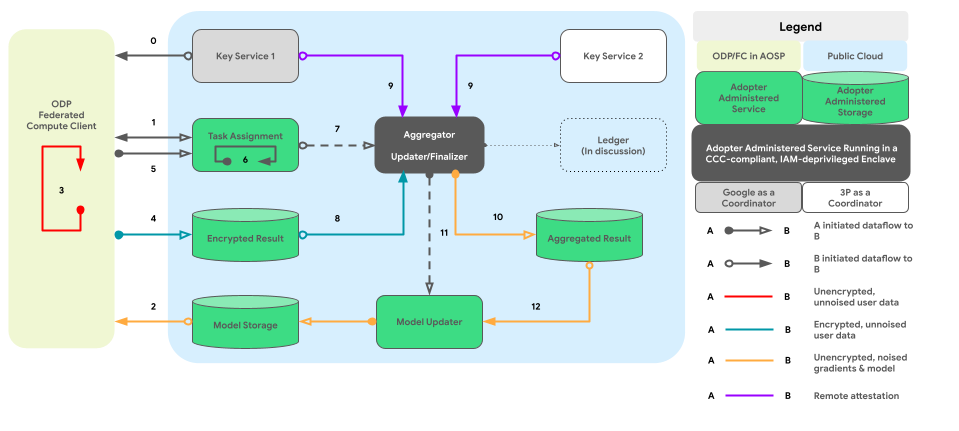
Zaawansowany projekt
Jak można wdrożyć ochronę prywatności przez poufność? Ogólnie rzecz biorąc, mechanizm zasad utworzony przez ODP, który działa w zamkniętym środowisku, służy jako główny komponent nadzorujący każdy węzeł/podrzędny, a jednocześnie śledzi stan ich danych wejściowych i wyjściowych (DP).
- Z perspektywy silnika zasad urządzenia i serwery są traktowane tak samo. Urządzenia i serwery korzystające z identycznego silnika zasad są uznawane za identyczne logicznie, gdy ich mechanizmy zasad zostaną wzajemnie poświadczone.
- Na urządzeniach izolacja jest osiągana przez procesy izolowane od AOSP (lub pKVM, jeśli w dłuższej perspektywie jest to wysoka dostępność). W przypadku serwerów izolacja bazuje na „zaufanej stronie”, którą jest TEE i inne preferowane rozwiązania techniczne, umowy umowne lub jedno i drugie.
Inaczej mówiąc, wszystkie zamknięte środowiska, w których jest zainstalowany i uruchamiany mechanizm zasad platformy, są częścią naszej zaufanej bazy obliczeniowej. Dane mogą być rozpowszechniane bez dodatkowego szumu dzięki TCB. DP musi być stosowany, gdy dane wychodzą z zasad TCB.
Ogólna koncepcja personalizacji na urządzeniu skutecznie łączy 2 podstawowe elementy:
- Architektura sparowanych procesów na potrzeby wykonywania logiki biznesowej
- Zasady i mechanizm zasad do zarządzania ruchem przychodzącym, ruchem wychodzącym i dozwolonymi operacjami na danych.
Spójny projekt umożliwia firmom uruchamianie własnego kodu w zaufanym środowisku wykonawczym i umożliwia dostęp do danych użytkowników, których zasady są w tym zakresie sprawdzone.
W kolejnych sekcjach omówimy te 2 kluczowe aspekty.
Architektura sparowanego procesu na potrzeby wykonywania logiki biznesowej
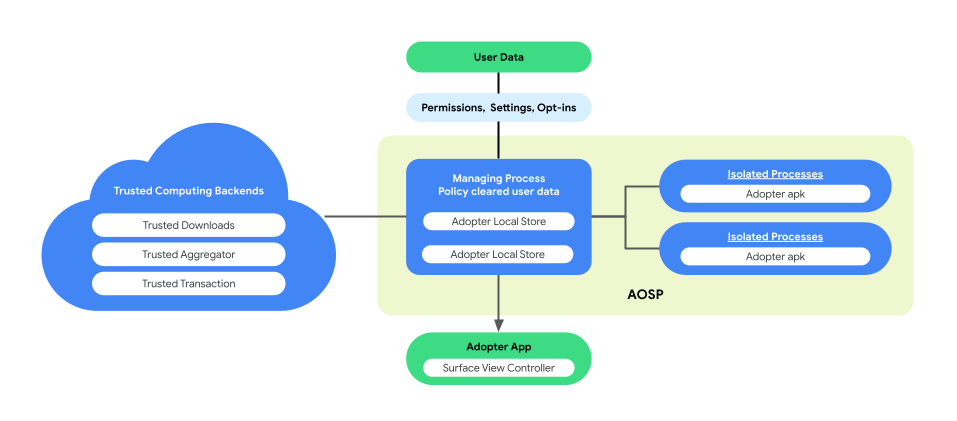
Personalizacja na urządzeniu wprowadza architekturę sparowanych procesów w AOSP, aby zwiększyć prywatność użytkowników i bezpieczeństwo danych podczas wykonywania logiki biznesowej. Taka architektura składa się z:
ManagingProcess. Ten proces tworzy procesy IsolatedProcess oraz nimi zarządza, zapewniając odizolowanie ich na poziomie procesu z dostępem ograniczonym do interfejsów API znajdujących się na liście dozwolonych i bez uprawnień sieci ani dysku. ManagingProcess zajmuje się gromadzeniem wszystkich danych biznesowych, wszystkimi danymi użytkowników i zasadami czyszczącymi je pod kątem kodu biznesowego, przenosząc je do procesu IsolatedProcess w celu wykonania. Pośredniczy też w interakcjach między procesami IsolatedProcesses i innymi procesami, takimi jak system_server.
IsolatedProcess. Ten proces, oznaczony w pliku manifestu jako izolowany (
isolatedprocess=true), otrzymuje firmowe bazy danych, dane użytkowników i dane użytkowników wyczyszczonych z zasad oraz kod biznesowy z metody ManagingProcess. Pozwalają kodowi biznesowemu działać na jego danych i danych użytkowników usuniętych z zasad. IsolatedProcess komunikuje się wyłącznie z procesem ManagingProcess zarówno w przypadku ruchu przychodzącego, jak i wychodzącego, bez dodatkowych uprawnień.
Architektura sparowanych procesów umożliwia niezależną weryfikację polityki prywatności danych użytkowników bez konieczności udostępniania przez firmy logiki biznesowej lub kodu na licencji open source. Dzięki ManagingProcess, która zachowuje niezależność procesów izolowanych, oraz efektywne wykonywanie logiki biznesowej przez IsolatedProcess, architektura ta zapewnia bezpieczniejsze i wydajniejsze rozwiązanie do zachowania prywatności użytkowników podczas personalizacji.
Poniższy rysunek przedstawia architekturę tego sparowanego procesu.
Zasady i mechanizmy zasad dla operacji na danych
Personalizacja na urządzeniu wprowadza warstwę egzekwowania zasad między platformą a logiką biznesową. Celem jest udostępnienie zestawu narzędzi, które mapują elementy sterujące dla użytkowników i firm w scentralizowane, praktyczne decyzje dotyczące zasad. Zasady te są wtedy wszechstronnie i niezawodnie egzekwowane w różnych przepływach pracy i firmach.
W architekturze ze sparowanym procesem mechanizm zasad znajduje się w ramach zarządzania procesem, nadzorując ruch przychodzący i wychodzący danych użytkowników i firm. Udostępnia też operacje umieszczone na liście dozwolonych do metody IsolatedProcess. Przykładowe obszary obejmują kontrolę użytkowników, ochronę dzieci, zapobieganie udostępnianiu danych bez zgody użytkownika i prywatność biznesową.
Ta architektura egzekwowania zasad obejmuje 3 rodzaje przepływów pracy, które można wykorzystać:
- Lokalnie inicjowane przepływy pracy offline i komunikacja w ramach zaufanego środowiska wykonawczego (TEE):
- Procesy pobierania danych: zaufane pobieranie
- Procesy przesyłania danych: zaufane transakcje
- Przepływy pracy online inicjowane lokalnie:
- Procesy wyświetlania w czasie rzeczywistym
- Przepływy wnioskowania
- Przepływy pracy inicjowane lokalnie w trybie offline:
- Procesy optymalizacji: szkolenie z modelu na urządzeniu wdrażane w ramach sfederowanego uczenia się
- Procesy raportowania: agregacja danych z różnych urządzeń wdrożona za pomocą sfederowanej analizy
Poniższy rysunek przedstawia architekturę z perspektywy zasad i ich silników.
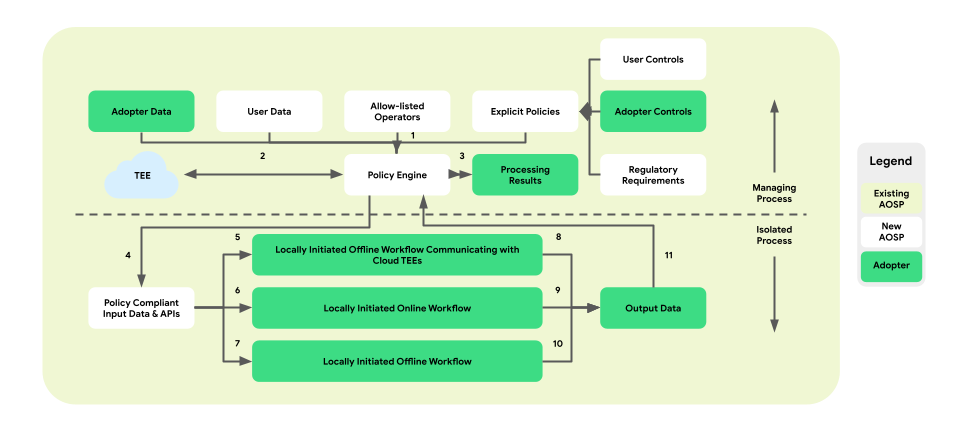
- Pobierz: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Porcja: 1+3 -> 4 -> 6 -> 9 -> 11 -> 3
- Optymalizacja: 2 (zawiera plan szkoleniowy) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Raportowanie: 3 (dostarcza plan agregacji) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
Ogólnie rzecz biorąc, wprowadzenie warstwy egzekwowania zasad i mechanizmu zasad w architekturze sparowanego procesu personalizacji na urządzeniu zapewnia odizolowane, chroniące prywatność środowisko do wykonywania logiki biznesowej przy jednoczesnym zapewnieniu kontroli dostępu do niezbędnych danych i operacji.
Warstwowe platformy API
Personalizacja na urządzeniu zapewnia warstwową architekturę interfejsów API dla zainteresowanych firm. Górna warstwa składa się z aplikacji utworzonych do konkretnych zastosowań. Potencjalne firmy mogą połączyć swoje dane z tymi aplikacjami, znanymi jako interfejsy API najwyższego poziomu. Interfejsy API najwyższego poziomu są oparte na interfejsach API pośredniej warstwy.
Z czasem planujemy dodać więcej interfejsów API najwyższego poziomu. Gdy interfejs API najwyższego poziomu jest niedostępny w konkretnym przypadku użycia lub gdy istniejące interfejsy API najwyższego poziomu nie są wystarczająco elastyczne, firmy mogą bezpośrednio wdrożyć te interfejsy API, które zapewniają zaawansowane i elastyczność za pomocą prostych interfejsów API.
Podsumowanie
Personalizacja na urządzeniu to wczesna propozycja badań mających na celu zebranie opinii i zainteresowań nad długoterminowym rozwiązaniem, które rozwiązuje kwestie związane z ochroną prywatności użytkowników za pomocą najnowszych i najlepszych technologii, które mogą być bardzo przydatne.
Chcemy współpracować z zainteresowanymi osobami, takimi jak eksperci w dziedzinie ochrony prywatności, analitycy danych i potencjalni użytkownicy, aby mieć pewność, że ODP spełnia ich potrzeby i odpowie na ich obawy.