En esta explicación técnica, que se pensó para implementarse en el proyecto de código abierto de Android (AOSP), se analiza la motivación detrás de la personalización integrada en el dispositivo (ODP), los principios de diseño que guían su desarrollo, su privacidad a través de un modelo de confidencialidad y la manera para garantizar una experiencia de privacidad verificable.
Para lograrlo, planeamos simplificar el modelo de acceso a los datos y asegurarnos de que todos los datos del usuario que superen el límite de seguridad tengan una privacidad diferencial por nivel (usuario, usuario pionero, instancia de modelo) (con frecuencia, en el siguiente texto se abrevia a "nivel de usuario").
Todo el código relacionado con la posible salida de datos del usuario final desde sus dispositivos será de código abierto y podrá ser verificado por las entidades externas. En las primeras etapas de nuestra propuesta, buscamos generar interés y recopilar comentarios para una plataforma que facilite las oportunidades de personalización integrada en el dispositivo. Invitamos a las partes interesadas, como expertos en privacidad, analistas de datos y profesionales de la seguridad, a que interactúen con nosotros.
Vision
La personalización integrada en el dispositivo está diseñada para proteger la información de los usuarios finales de las empresas con las que no interactuaron. Las empresas pueden seguir personalizando sus productos y servicios para los usuarios finales (por ejemplo, con modelos de aprendizaje automático con privacidad diferencial y anonimización correctas), pero no podrán ver las personalizaciones exactas que se realicen para un usuario final (que depende no solo de la regla de personalización que genera el propietario de la empresa, sino también de la preferencia del usuario final individual), a menos que haya interacciones directas entre la empresa y el usuario final. Si una empresa produce modelos de aprendizaje automático o análisis estadísticos, la ODP intentará asegurarse de que se anonimicen, de forma correcta, con los mecanismos correctos de privacidad diferencial.
Nuestro plan actual es explorar la ODP en varios hitos y abarcar las siguientes características y funcionalidades. También invitamos a las partes interesadas a que sugieran, de manera constructiva, cualquier función o flujo de trabajo adicional para profundizar esta exploración:
- Un entorno de zona de pruebas en el que se contiene y ejecuta toda la lógica empresarial, lo que permite que una gran cantidad de indicadores de los usuarios finales ingresen a la zona de pruebas, a la vez que se limitan los resultados.
Almacenes de datos encriptados de extremo a extremo para lo siguiente:
- Controles y otros datos relacionados con el usuario, lo que podría ser proporcionado por el usuario final o ser recopilado e inferido por las empresas, junto con controles de tiempo de actividad (TTL), políticas de eliminación y de privacidad, y mucho más
- Configuraciones empresariales. La ODP proporciona algoritmos para comprimir u ofuscar esos datos
- Resultados de procesamiento empresarial. Con estos resultados, puede suceder lo siguiente:
- Pueden ser consumidos como entradas en las rondas posteriores de procesamiento.
- Pueden contaminarse según los mecanismos de privacidad diferencial adecuados y subirse a los extremos aptos.
- Pueden subirse con el flujo de carga de confianza a entornos de ejecución confiables (TEE) que ejecutan cargas de trabajo de código abierto con mecanismos centrales de privacidad diferencial correctos.
- Pueden mostrarse a los usuarios finales.
APIs diseñadas para lo siguiente:
- Actualizar 2(a), por lotes o de forma incremental.
- Actualizar 2(b) de forma periódica, ya sea por lotes o de forma incremental.
- Subir 2(c), con los mecanismos de contaminación correctos en entornos de agregación confiables. Esos resultados pueden convertirse en 2(b) en las próximas rondas de procesamiento.
Principios de diseño
Existen tres pilares de la ODP que buscan equilibrar la privacidad, la equidad y la utilidad.
Modelo de datos en torres para una mejor protección de la privacidad
La ODP sigue la privacidad desde el diseño y se diseñó con la protección de la privacidad del usuario final como la forma predeterminada.
La ODP explora el traslado del procesamiento de personalización al dispositivo de un usuario final. Este enfoque equilibra la privacidad y la utilidad manteniendo los datos en el dispositivo tanto como sea posible y procesándolos fuera del dispositivo solo cuando es necesario. La ODP se centra en lo siguiente:
- El control de los datos del usuario final del dispositivo, incluso cuando salen de este. Los destinos deben estar certificados como entornos de ejecución confiables que ofrecen los proveedores de servicios en la nube pública que ejecutan el código creado por la ODP.
- La verificabilidad del dispositivo de lo que sucede con los datos del usuario final si salen del dispositivo. La ODP proporciona cargas de trabajo del procesamiento federado y de código abierto para coordinar el aprendizaje automático y el análisis estadístico multidispositivos para los usuarios pioneros. El dispositivo de un usuario final certificará que esas cargas de trabajo se ejecutan en entornos de ejecución confiables sin modificaciones.
- La privacidad técnica garantizada (por ejemplo, agregación, contaminación o privacidad diferencial) de las salidas que superan el límite controlado o verificable por el dispositivo.
Por lo tanto, la personalización será específica del dispositivo.
Además, las empresas también requieren medidas de privacidad, que la plataforma debe abordar, lo que implica mantener los datos de la empresa sin procesar en sus respectivos servidores. Para lograrlo, la ODP adopta el siguiente modelo de datos:
- Cada fuente de datos sin procesar se almacenará en el dispositivo o en el servidor, lo que permite el aprendizaje y la inferencia locales.
- Proporcionaremos algoritmos para facilitar la toma de decisiones en varias fuentes de datos, como el filtrado entre dos ubicaciones de datos dispares o el entrenamiento o la inferencia en varias fuentes.
En este contexto, podría haber una torre de la empresa y una torre de usuarios finales:
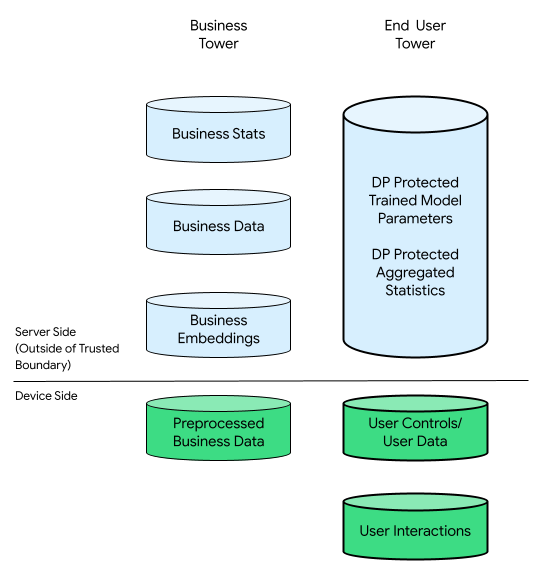
La torre de usuarios finales consta de datos proporcionados por el usuario final (por ejemplo, información y controles de la cuenta), datos recopilados relacionados con las interacciones de un usuario final con su dispositivo y datos derivados (por ejemplo, intereses y preferencias) inferidos por la empresa. Los datos inferidos no reemplazan las declaraciones directas de ningún usuario.
A modo de comparación, en una infraestructura centrada en la nube, todos los datos sin procesar de la torre de usuarios finales se transfieren a los servidores de las empresas. Por el contrario, en una infraestructura centrada en el dispositivo, todos los datos sin procesar de la torre de usuarios finales permanecen en su origen, mientras que los datos de la empresa permanecen almacenados en servidores.
La personalización integrada en el dispositivo combina lo mejor de ambos mundos, ya que solo habilita código certificado y abierto para procesar datos que tienen cualquier potencial de relacionarse con usuarios finales en TEE que usan canales de salida más privados.
Participación pública inclusiva para lograr soluciones equitativas
El objetivo de la ODP es garantizar un entorno equilibrado para todos los participantes de un ecosistema diverso. Reconocemos la complejidad de este ecosistema, que consta de varios jugadores que ofrecen servicios y productos distintos.
Para inspirar la innovación, la ODP ofrece APIs que los desarrolladores y las empresas que representan pueden implementar. La personalización integrada en el dispositivo facilita la integración perfecta de estas implementaciones, a la vez que se administran las versiones, la supervisión, las herramientas para desarrolladores y las de comentarios. La personalización integrada en el dispositivo no crea ninguna lógica empresarial concreta, sino que funciona como catalizador de la creatividad.
La ODP podría ofrecer más algoritmos con el tiempo. La colaboración con el ecosistema es esencial para determinar el nivel correcto de las funciones y, potencialmente, establecer un límite de recursos de dispositivos razonable para cada empresa participante. Esperamos los comentarios del ecosistema para ayudarnos a reconocer y priorizar nuevos casos de uso.
Utilidad para que los desarrolladores mejoren la experiencia del usuario
Con la ODP, no se pierden los datos de eventos ni se producen demoras en la observación, ya que todos los eventos se registran de forma local a nivel del dispositivo. No se producen errores de unión, y todos los eventos están asociados con un dispositivo específico. Como resultado, todos los eventos observados forman, de forma intrínseca, una secuencia cronológica que refleja las interacciones del usuario.
Este proceso simplificado elimina la necesidad de unir o reorganizar los datos del usuario, lo que permite su accesibilidad casi en tiempo real y sin pérdidas. A su vez, esto puede mejorar la utilidad que los usuarios finales perciben cuando interactúan con productos y servicios basados en datos, lo que podría generar mayores niveles de satisfacción y experiencias más significativas. Con la ODP, las empresas pueden adaptarse, de manera efectiva, a las necesidades de sus usuarios.
El modelo de privacidad: la privacidad a través de la confidencialidad
En las siguientes secciones, se analiza el modelo de productor y consumidor como base de este análisis de privacidad, y la privacidad del entorno de procesamiento frente a la exactitud de las salidas.
El modelo de productor y consumidor como base de este análisis de privacidad
Emplearemos el modelo de productor y consumidor para examinar las garantías de la privacidad a través de la confidencialidad. Los procesamientos en este modelo se representan como nodos dentro de un grafo acíclico dirigido (DAG) que consta de nodos y subgrafos. Cada nodo de procesamiento tiene tres componentes: entradas consumidas, salidas producidas y entradas a las salidas de asignación de procesamientos.

En este modelo, la protección de la privacidad se aplica a los tres componentes:
- Privacidad de la entrada. Los nodos pueden tener dos tipos de entradas. Si un nodo predecesor genera una entrada, ya tiene las garantías de privacidad de la salida de ese predecesor. De lo contrario, las entradas deben borrar las políticas de entrada de los datos con el motor de políticas.
- Privacidad de la salida. Es posible que se deba privatizar la salida, como aquella que brinda la privacidad diferencial (DP).
- Confidencialidad del entorno de procesamiento. El procesamiento debe ocurrir en un entorno sellado de forma segura, lo que garantiza que nadie tenga acceso a estados intermedios dentro de un nodo. Las tecnologías que permiten esto incluyen el procesamiento federado (FC), los entornos de ejecución confiables basados en hardware (TEE), el procesamiento seguro de múltiples partes (sMPC), la encriptación homomórfica (HPE) y mucho más. Vale la pena señalar que la privacidad a través de la confidencialidad protege los estados intermedios, y todas las salidas que superan el límite de confidencialidad deben protegerse con mecanismos de privacidad diferencial. Son obligatorios los siguientes dos reclamos:
- La confidencialidad de los entornos, lo que garantiza que solo las salidas declaradas dejen el entorno
- La solidez, lo que permite deducciones precisas de los reclamos de privacidad de la salida a partir de los reclamos de privacidad de la entrada. La solidez permite la propagación de propiedades de privacidad en un DAG.
Un sistema privado mantiene la privacidad de las entradas, la confidencialidad del entorno de procesamiento y la privacidad de las salidas. Sin embargo, la cantidad de aplicaciones de los mecanismos de privacidad diferencial puede reducirse si se sella más procesamiento dentro de un entorno de procesamiento confidencial.
Este modelo ofrece dos ventajas principales. Primero, la mayoría de los sistemas, grandes y pequeños, se pueden representar como un DAG. En segundo lugar, las propiedades posprocesamiento [sección 2.1] y composición de DP y Lemma 2.4 en la complejidad de la privacidad diferencial prestan herramientas potentes para analizar (en el peor de los casos) la compensación entre privacidad y precisión en un gráfico completo:
- El procesamiento posterior garantiza que, una vez que se privatiza una cantidad, no se puede "desprivatizar" si no se vuelven a usar los datos originales. Siempre que todas las entradas de un nodo sean privadas, su salida será privada, sin importar sus cálculos.
- La composición avanzada garantiza que, si cada parte del grafo es DP, el grafo general también lo es, por lo que se delimita, de manera efectiva, ε y δ de la salida final de un grafo en aproximadamente ε√κ, respectivamente, si suponemos que un grafo tiene unidades κ y la salida de cada unidad es (ε, δ)-DP.
Estas dos propiedades se traducen en dos principios de diseño para cada nodo:
- Propiedad 1 (del procesamiento posterior) si las entradas de un nodo son todas DP, su salida es DP, si se ajusta cualquier lógica empresarial ejecutada en el nodo y se admiten los "ingredientes secretos" de la empresa.
- Propiedad 2 (de la composición avanzada) si las entradas de un nodo no son todas DP, su salida debe cumplir con la DP. Si un nodo de procesamiento es uno que ejecuta, en entornos de ejecución confiables, cargas de trabajo y configuraciones que proporcione la personalización integrada en el dispositivo de código abierto, es posible establecer límites más estrictos de la DP. De lo contrario, es posible que la personalización integrada en el dispositivo necesite usar los límites de la DP para el peor de los casos. Debido a restricciones de recursos, los entornos de ejecución confiables que ofrece un proveedor de servicios en la nube pública tendrán prioridad en un principio.
La privacidad del entorno de procesamiento frente a la precisión de las salidas
En adelante, la personalización integrada en el dispositivo se centrará en mejorar la seguridad de los entornos de procesamiento confidenciales y en garantizar que los estados intermedios permanezcan inaccesibles. Este proceso de seguridad, conocido como "sellado", se aplicará al nivel del subgrafo, lo que permite que varios nodos juntos cumplan con la DP. Es decir, la propiedad 1 y la propiedad 2 mencionadas anteriormente se aplican al nivel del subgrafo.

Por supuesto, la salida final del grafo, la salida 7, se DP por composición. Esto significa que habrá 2 DP en total para este gráfico, en comparación con 3 DP totales (locales) si no se usó ningún sellado.
En esencia, cuando se protege el entorno de procesamiento y se eliminan las oportunidades para que los adversarios accedan a las entradas y los estados intermedios de un gráfico o subgrafo, se habilita la implementación de Central DP (es decir, la salida de un entorno sellado cumple con el DP), lo que puede mejorar la exactitud en comparación con la DP local (es decir, las entradas individuales cumplen con el DP). Este principio sustenta la consideración de los FC, los TEE, los sMPC y las HPEs como tecnologías de privacidad. Consulta el capítulo 10 en The Complexity of Differential Privacy (La complejidad de la privacidad diferencial).
Un buen ejemplo práctico es el entrenamiento y la inferencia de modelos. En los análisis a continuación, se supone que (1) la población de entrenamiento y la de inferencia se superponen y que (2) ambas funciones y etiquetas constituyen datos privados del usuario. Podemos aplicar la DP a todas las entradas:

La personalización integrada en el dispositivo puede aplicar la DP local a las etiquetas y los atributos del usuario antes de enviarlos a los servidores. Este enfoque no impone ningún requisito en el entorno de ejecución del servidor ni en su lógica empresarial.



Este es el diseño actual de personalización integrada en el dispositivo.
Privacidad verificable
El objetivo de la personalización integrada en el dispositivo es que se pueda verificar la privacidad. Se enfoca en verificar lo que sucede fuera de los dispositivos del usuario. La ODP creará el código que procesa los datos que salen de los dispositivos de los usuarios finales y usará la arquitectura de los procedimientos de certificación remota (RATS) de RFC 9334 de NIST para certificar que ese código se esté ejecutando sin modificaciones en un servidor sin privilegios del administrador de instancias que cumpla con Confidential Computing Consortium. Estos códigos serán de código abierto, y se podrá acceder a ellos para realizar una verificación transparente y generar confianza. Estas medidas pueden darles a las personas la confianza de que sus datos están protegidos, y las empresas pueden ganar reputación en función de una base sólida de garantías de privacidad.
Otro aspecto fundamental de la personalización integrada en el dispositivo es reducir la cantidad de datos privados que se recopilan y almacenan. Para cumplir con este principio, se adoptan tecnologías como, el procesamiento federado y la privacidad diferencial, lo que permite la divulgación de patrones de datos valiosos sin exponer detalles individuales sensibles ni información de identificación.
Mantener un registro de auditoría con las actividades asociadas al procesamiento y a su uso compartido es otro aspecto clave de la privacidad verificable. Esto permite la creación de informes de auditoría y la identificación de vulnerabilidades, lo que demuestra nuestro compromiso con la privacidad.
Solicitamos colaboraciones constructivas de expertos en privacidad, autoridades, sectores y personas para ayudarnos a mejorar, de manera continua, el diseño y las implementaciones.
En el siguiente gráfico, se muestran instrucciones de código para la agregación y la contaminación multidispositivos, según la privacidad diferencial.
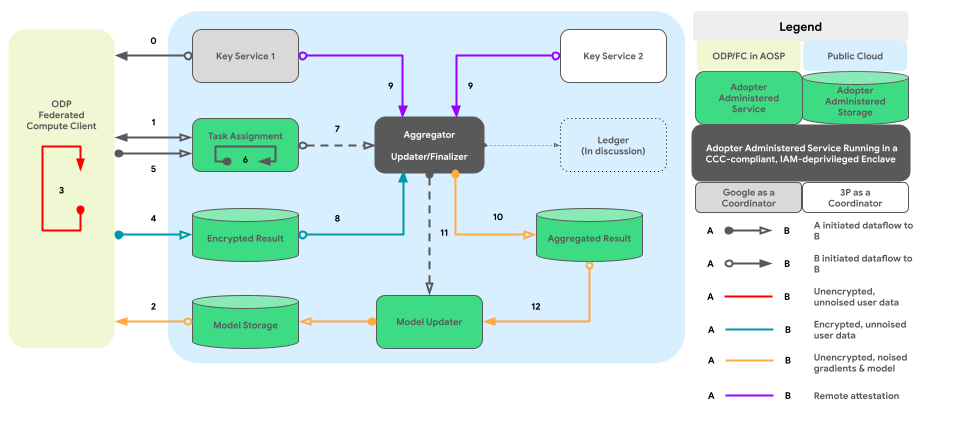
Diseño de alto nivel
¿Cómo se puede implementar la privacidad a través de la confidencialidad? En un nivel alto, un motor de políticas creado por la ODP que se ejecute en un entorno sellado funciona como el componente principal que supervisa cada nodo o subgrafo mientras se realiza un seguimiento del estado de la DP de sus entradas y salidas:
- Desde la perspectiva del motor de políticas, los dispositivos y los servidores se tratan de la misma manera. Los dispositivos y servidores que ejecutan el mismo motor de políticas se consideran lógicamente idénticos, una vez que sus motores de políticas se certifiquen de forma mutua.
- En los dispositivos, el aislamiento se logra a través de procesos aislados de AOSP (o pKVM a largo plazo una vez que aumente la disponibilidad). En los servidores, el aislamiento depende de una "fuente de confianza", que puede ser un TEE junto con otras soluciones de sellado técnico que se prefieran, un acuerdo contractual o ambos.
En otras palabras, todos los entornos sellados que instalan y ejecutan el motor de políticas de la plataforma se consideran parte de nuestra base de procesamiento confiable (TCB). Los datos se pueden propagar sin contaminación adicional con la TCB. La DP debe aplicarse cuando los datos salen de la TCB.
El diseño de alto nivel de la personalización integrada en el dispositivo integra, de forma efectiva, dos elementos esenciales:
- Una arquitectura de procesos vinculados para ejecutar la lógica empresarial
- Políticas y un motor de políticas para administrar la entrada y la salida de datos, y las operaciones permitidas
Este diseño cohesivo les ofrece a las empresas un campo de juego imparcial en el que pueden ejecutar su código de propiedad en un entorno de ejecución confiable y acceder a los datos del usuario que hayan aprobado las verificaciones correctas de políticas.
En las siguientes secciones, se ampliarán estos dos aspectos clave.
Arquitectura de procesos vinculados para ejecutar la lógica empresarial
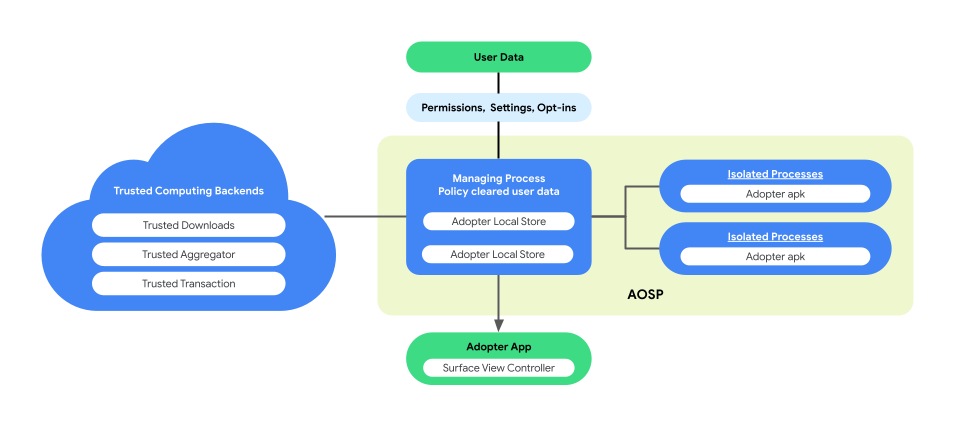
La personalización integrada en el dispositivo presenta una arquitectura de procesos vinculados en AOSP para mejorar la privacidad del usuario y la seguridad de los datos durante la ejecución de la lógica empresarial. Esta arquitectura consta de lo siguiente:
ManagingProcess. Este proceso crea y administra IsolatedProcesses, lo que garantiza que permanezca aislado en el nivel del proceso con acceso limitado a las APIs incluidas en la lista de entidades permitidas y sin permisos de red o disco. ManagingProcess controla la recopilación de todos los datos de la empresa, todos los datos del usuario final, y la política los aprueba para el código empresarial y los envía a IsolatedProcesses para su ejecución. Además, media la interacción entre IsolatedProcesses y otros procesos, como system_server.
IsolatedProcess. Este proceso, que se designa como aislado (
isolatedprocess=trueen el manifiesto), recibe datos de la empresa, datos del usuario final borrados por la política y el código empresarial desde ManagingProcess. Permiten que el código empresarial funcione en sus datos y en los datos del usuario final que cuentan con la aprobación de la política. IsolatedProcess se comunica, de forma exclusiva, con ManagingProcess para la entrada y la salida, sin permisos adicionales.
La arquitectura de procesos vinculados proporciona la oportunidad de realizar una verificación independiente de las políticas de privacidad de los datos del usuario final sin que las empresas deban utilizar código abierto para su lógica o código empresariales. Como ManagingProcess mantiene la independencia de IsolatedProcesses, y IsolatedProcesses ejecuta, de manera eficiente, la lógica empresarial, esta arquitectura garantiza una solución más segura y eficiente para preservar la privacidad del usuario durante la personalización.
En la siguiente figura, se muestra esta arquitectura de procesos vinculados.
Políticas y motores de políticas para las operaciones de datos
La personalización integrada en el dispositivo presenta una capa de aplicación de las políticas entre la plataforma y la lógica empresarial. El objetivo es proporcionar un conjunto de herramientas que asignen los controles empresariales y de usuario final a las decisiones centralizadas y prácticas relacionadas con las políticas. Luego, estas políticas se aplican, de manera integral y confiable, en todos los flujos y las empresas.
En la arquitectura de procesos vinculados, el motor de políticas reside dentro de ManagingProcess, que supervisa la entrada y salida de los datos del usuario final y de la empresa. También le proporcionará a IsolatedProcess las operaciones incluidas en la lista de entidades permitidas. Por ejemplo, entre las áreas de cobertura, se incluye el cumplimiento del control del usuario final, la protección infantil, la prevención del uso compartido de datos sin consentimiento y la privacidad empresarial.
Esta arquitectura de aplicación de políticas consta de tres tipos de flujos de trabajo que se pueden aprovechar:
- Flujos de trabajo sin conexión iniciados de forma local con comunicaciones del entorno de ejecución confiable (TEE):
- Flujos de descarga de datos: descargas confiables
- Flujos de carga de datos: transacciones confiables
- Flujos de trabajo en línea iniciados de forma local:
- Flujos de publicación en tiempo real
- Flujos de inferencia
- Flujos de trabajo sin conexión iniciados de forma local:
- Flujos de optimización: entrenamiento de modelos integrados en el dispositivo que se implementan a través del aprendizaje federado (FL)
- Flujos de informes: agregación multidispositivo que se implementa a través del análisis federado (FA)
En la siguiente figura, se muestra la arquitectura desde la perspectiva de las políticas y los motores de políticas.
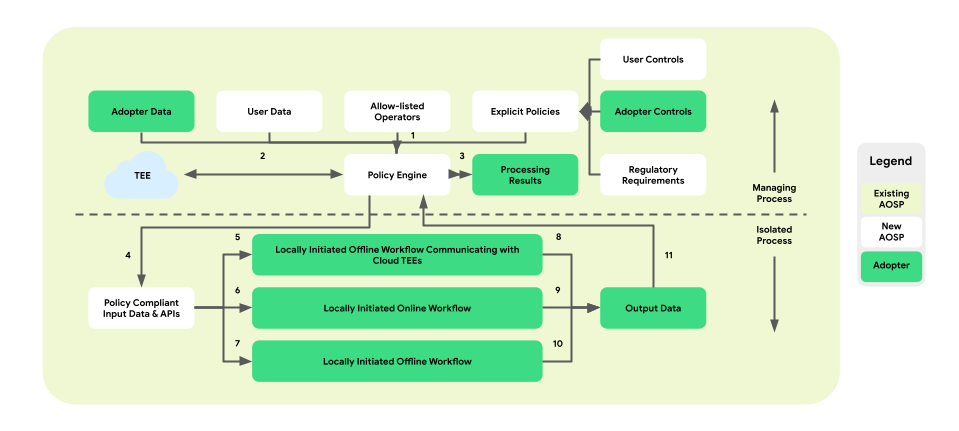
- Descarga: 1 -> 2 -> 4 -> 7 -> 10 -> 11 -> 3
- Publicación: 1 + 3 -> 4 -> 6 -> 9 -> 11 -> 3
- Optimización: 2 (proporciona un plan de entrenamiento) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
- Informes: 3 (proporciona un plan de agregación) -> 1 + 3 -> 4 -> 5 -> 8 -> 11 -> 2
En general, agregar la capa de aplicación de políticas y el motor de políticas dentro de la arquitectura de procesos vinculados de la personalización integrada en el dispositivo garantiza un entorno aislado que preserva la privacidad para ejecutar la lógica empresarial, a la vez que proporciona acceso controlado a las operaciones y los datos necesarios.
Plataformas de APIs en capas
La personalización integrada en el dispositivo proporciona una arquitectura de API en capas para las empresas interesadas. La capa superior consta de aplicaciones pensadas para casos de uso específicos. Las empresas potenciales pueden conectar sus datos a estas aplicaciones, que se conocen como APIs de la capa superior. Las APIs de la capa superior se compilan en las APIs de la capa media.
Con el tiempo, esperamos agregar más APIs de la capa superior. Cuando una API de capa superior no está disponible para un caso de uso en particular o cuando las APIs de la capa superior existentes no son lo suficientemente flexibles, las empresas pueden implementar directamente las APIs de la capa media, que brindan potencia y flexibilidad a través de primitivas de programación.
Conclusión
La personalización integrada en el dispositivo es una propuesta de investigación en etapa inicial para generar intereses y solicitar comentarios sobre una solución a largo plazo que aborda las inquietudes sobre la privacidad de los usuarios finales con las mejores y más recientes tecnologías que se espera que tengan una gran utilidad.
Nos gustaría interactuar con las partes interesadas, como expertos en privacidad, analistas de datos y posibles usuarios finales, para garantizar que la ODP satisfaga sus necesidades y aborde sus inquietudes.