Чтобы предотвратить определенные типы межсайтового отслеживания по побочным каналам, Chrome разделил большинство API-интерфейсов хранилища и связи на сторонние контексты.
Статус реализации
Эта функция включена для всех пользователей Chrome 115 и более поздних версий. Предложение по разделению хранилища открыто для дальнейшего обсуждения.
Сайты, у которых еще не было времени реализовать поддержку стороннего разделения хранилища, могут принять участие в пробной версии устаревания , чтобы временно отменить разделение (продолжить изоляцию с помощью политики того же источника, но удалить изоляцию с помощью сайта верхнего уровня) и восстановить прежнее поведение хранилища. сервисные работники и коммуникационные API в контенте, встроенном в их сайт.
Что такое разделение хранилища?
Чтобы предотвратить определенные типы межсайтового отслеживания по побочным каналам, Chrome распределяет API-интерфейсы хранилища и связи в сторонние контексты.
Без разделения хранилища сайт может объединять данные с разных сайтов, чтобы отслеживать пользователя в сети. Кроме того, это позволяет встроенному сайту делать выводы о конкретных состояниях пользователя на сайте верхнего уровня, используя методы побочных каналов, такие как Timing Attacks , XS-Leaks и COSI .
Исторически хранилище определялось только по происхождению. Это означает, что если iframe из example.com встроен в a.com и b.com , он может узнать о ваших привычках просмотра этих двух сайтов, сохранив и успешно извлекая идентификатор из хранилища. Если включено стороннее разделение хранилища, хранилище для example.com существует в двух разных разделах: один для a.com , а другой для b.com .
Секционирование обычно означает, что данные, хранящиеся в API хранилища, таких как локальное хранилище и IndexedDB, с помощью iframe, больше не доступны для всех контекстов в одном и том же источнике. Вместо этого данные доступны только для контекстов с тем же источником и одним и тем же сайтом верхнего уровня.
До

После

Разделение хранилища на связанных iframe
Когда iframe содержит iframe, все становится сложнее. Это особенно верно, когда один и тот же источник находится более чем в одном месте цепочки.
Например, A1 содержит iframe для B, который содержит iframe для A2, и оба A1 и A2 находятся на одном сайте. Если при секционировании мы учитываем только контексты верхнего уровня и текущего уровня, то iframe A2 можно считать основным, поскольку он находится на том же сайте, что и контекст верхнего уровня (A1), несмотря на промежуточный сторонний iframe (B). . Это могло бы открыть A2 для угроз безопасности, таких как кликджекинг, если бы A2 по умолчанию имел доступ к неразделенному хранилищу.
Чтобы решить эту проблему, Chrome включает дополнительный «бит предка» как часть ключа раздела хранилища, который устанавливается, если какой-либо документ между текущим контекстом и контекстом верхнего уровня является межсайтовым по отношению к текущему контексту. В этом случае сайт B является межсайтовым, поэтому бит будет установлен для A2, а его хранилище будет отделено от A1.
Если в цепочке нет межсайтового контекста, хранилище не секционируется. Например, сайт A1, содержащий iframe для A2, который содержит iframe для A3, не будет разделен для A1, A2 или A3, поскольку все они находятся на одном сайте.
Для сайтов, которым требуется неразделенный доступ через связанные iframe, Chrome экспериментирует с расширением API доступа к хранилищу, чтобы включить этот вариант использования . Поскольку API доступа к хранилищу требует, чтобы созданный сайт явно вызывал API, это снижает риск кликджекинга.
Обновленные API
API, на которые влияет секционирование, можно разделить на следующие группы:
API хранилища
- Система квот
- Система квот используется для определения того, сколько дискового пространства выделяется для хранения. Система квот управляет каждым разделом как отдельным сегментом, чтобы определить, сколько места разрешено и когда оно очищается.
-
navigator.storage.estimate()возвращает информацию о разделе. API-интерфейсы только для Chrome, такие какwindow.webkitStorageInfoиnavigator.webkitTemporaryStorageстанут устаревшими. - В хранилище IndexedDB и Cache используется новая система секционированных квот.
- API веб-хранилища
- API веб-хранилища предоставляет механизмы, с помощью которых браузеры могут хранить пары ключ/значение. Существует два механизма: локальное хранилище и сеансовое хранилище . В настоящее время они не управляются квотами, но все еще разделены.
- Частная файловая система Origin
- API доступа к файловой системе позволяет сайту читать или сохранять изменения непосредственно в файлах и папках на устройстве после того, как пользователь предоставит доступ. Частная файловая система Origin позволяет источнику хранить личный контент на диске, к которому пользователь может легко получить доступ и который разбит на разделы.
- API сегмента хранилища
- API Storage Bucket разрабатывается для Storage Standard , который объединяет различные API хранилища, такие как IndexedDB и localStorage, с помощью новой концепции, называемой сегментами. Данные, хранящиеся в сегментах, и метаданные, связанные с сегментами, секционируются.
- Заголовок Clear-Site-Data
- Включение заголовка
Clear-Site-Dataв ответ позволяет серверу запросить очистку данных, хранящихся в браузере пользователя. Кэш, файлы cookie и хранилище DOM можно очистить. Использование заголовка очищает хранилище только в одном разделе.
- Хранилище URL-адресов BLOB- объектов
- Большой двоичный объект — это объект, который содержит необработанные данные для обработки, и для доступа к ресурсу можно создать URL-адрес большого двоичного объекта. Хранилища URL-адресов BLOB-объектов не секционированы. Чтобы поддержать вариант использования для перехода в контексте верхнего уровня к любому URL-адресу BLOB-объекта ( обсуждение ), хранилище URL-адресов BLOB-объектов может быть разделено кластером агентов, а не сайтом верхнего уровня. Эта функция пока недоступна для тестирования, и механизм разделения может измениться в будущем.
Коммуникационные API
Наряду с API-интерфейсами хранения секционированы также API-интерфейсы связи, которые позволяют одному контексту взаимодействовать через границы источника. Изменения в основном затрагивают API, которые позволяют обнаруживать другие контексты посредством широковещательной рассылки или рандеву того же источника.
Для следующих коммуникационных API сторонний iframe больше не может взаимодействовать с контекстом того же источника:
- Трансляционный канал
- API широковещательного канала обеспечивает связь между контекстами просмотра (окнами, вкладками или iframe) и рабочими процессами одного и того же происхождения.
- Межсайтовый iframe
postMessage(), где связь между контекстами четко определена, менять не предлагается.
- Общий рабочий
- API SharedWorker предоставляет работника, к которому можно получить доступ в контекстах просмотра одного и того же источника.
- Веб-замки
- API веб-блокировок позволяет коду, выполняющемуся на одной вкладке или в рабочем потоке одного и того же происхождения, получить блокировку общего ресурса во время выполнения некоторой работы.
API сервисного работника
API Service Worker предоставляет интерфейс для выполнения задач в фоновом режиме. Сайты создают постоянные регистрации, которые создают новый рабочий контекст для реагирования на события, и этот рабочий процесс может взаимодействовать с любым контекстом того же источника. Кроме того, API Service Worker может изменять время выполнения навигационных запросов, что приводит к потенциальной утечке информации между сайтами, например при перехвате истории .
Таким образом, Service Workers, зарегистрированные из стороннего контекста, секционируются.
API расширений
Расширения — это программы, которые позволяют пользователям настраивать свой опыт просмотра.
Страницы расширений (страницы со схемой chrome-extension:// ) могут быть встроены в сайты в Интернете, и в этих случаях они сохранят доступ к своему разделу верхнего уровня. Эти страницы также могут встраивать другие сайты, и в этом случае эти сайты будут иметь доступ к своему разделу верхнего уровня, если у расширения есть разрешения хоста для этого сайта.
Для получения дополнительной информации см. документацию по расширению .
Демо: тестирование разделения хранилища
Демо-сайт: https://storage-partitioning-demo-site-a.glitch.me/
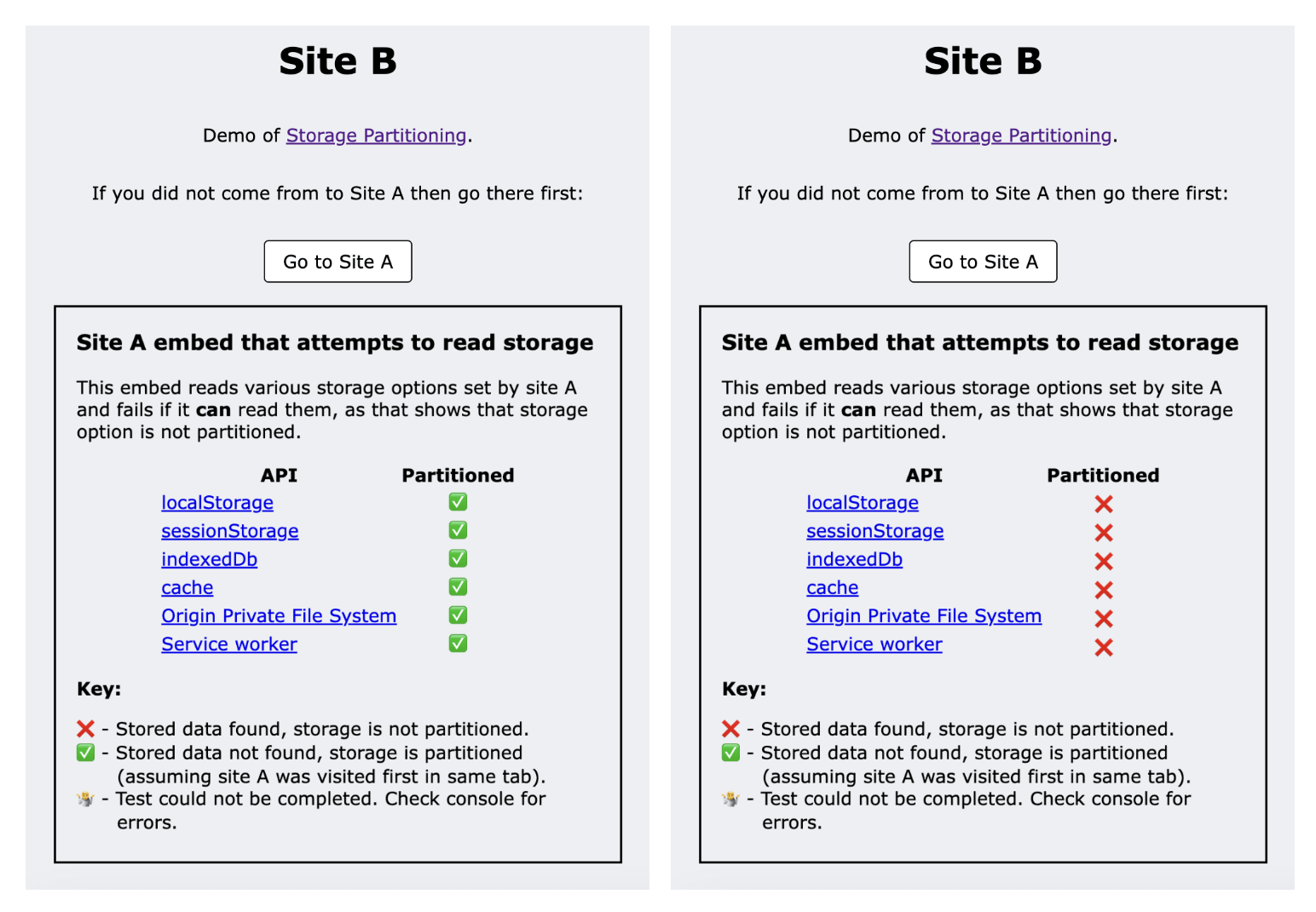
В демо-версии используются два сайта: сайт A и сайт B.
- Когда вы посещаете сайт A в контексте верхнего уровня, он устанавливает данные, используя различные методы хранения.
- Сайт Б встраивает страницу с сайта А и пытается прочитать ранее установленные параметры хранения.
- Когда сайт A встроен в сайт B, он не имеет доступа к этим данным, когда хранилище разделено, и поэтому чтение не выполняется.
- Демо использует успех или неудачу каждого чтения, чтобы показать, секционированы ли данные.
На данный момент вы можете отключить разделение хранилища в Chrome, установив для флага Chrome chrome://flags/#third-party-storage-partitioning значение disabled , чтобы подтвердить, что тест на разделение не прошел.
Вы также можете протестировать другие браузеры таким же образом, чтобы увидеть статус их разделов.
Привлекайте и делитесь отзывами
- GitHub : читайте исходное предложение , задавайте вопросы и участвуйте в обсуждении .
- Поддержка разработчиков : задавайте вопросы и присоединяйтесь к обсуждениям в репозитории поддержки разработчиков Privacy Sandbox .
- Ошибки в файлах . Сообщите об ошибке в трекере Chromium , если вы считаете, что что-то работает не так, как ожидалось.