Seyrek tensör kodlaması, bilgileri kodlamaya yarayan bir özelliktir. densörlerin seyrek olma özellikleri üzerine, TACO'nun seyrek tensörlerin biçimlendirilmesiyle elde edilmiştir. Bu kodlama sonunda, bir API'den tamamen otomatik olarak seyrek kod oluşturmak için bir ayırıcı hesaplamanın seyrek biçimden bağımsız temsili, ör. örtülü seyrek açık bir seyrek temsile dönüştürülür. ortak yineleme döngüleri seyrek depolama alanında çalışır düzensiz bir tensör yerine kullanır. Bu ayırıcı geçişten önce çalışan derleyici geçişlerinin dikkat edilmesi gerekir. oluşan tensör türlerinin anlamını ortaya koydu.

Bu kodlamada, boyut ifadesini anlamsal tensörün eksenlerine bakın ve level, gerçek depolama biçiminin eksenlerini ifade eder; yani seyrek tensörün bellekteki operasyonel temsili. Kullanılan boyutları genellikle düzey sayısı (CSR depolama biçimi gibi). Ancak kodlama, aynı zamanda daha üst düzey düzeylere yükseltme (örneğin, için blok halinde ayrılmış BSR depolama biçimini) veya daha düşük düzeylere (örneğin, boyutları depolamada tek bir düzey olarak doğrusallaştırmak için).
Kodlama, aşağıdakileri sağlayan bir harita içerir:
- Her biri şunları tanımlayan sıralı bir boyut özellikleri dizisi:
- boyut-boyut (tensörün boyut şeklinden örtülü)
- bir boyut-ifadesi
- Her biri gerekli bir seviyeyi içeren sıralı bir seviye özellikleri dizisi
level-type, seviyenin nasıl depolanması gerektiğini tanımlar. Her bir seviye türü
şunları içerir:
- nelerin depolandığını tanımlayan bir seviye-ifade
- seviyeli biçimde
- düzey biçimi için geçerli olan bir level-özellik koleksiyonu
Her seviye ifadesi afin bir ifadedir kullanabilirsiniz. Dolayısıyla, seviye ifadeleri toplu olarak afin harita olarak boyut koordinatlarına seviye koordinatlarını kullanabilirsiniz. Boyut-ifadeleri ters haritayı toplu olarak tanımlayabilirsiniz. Bu karşılaştırma yalnızca, sonucun anlaşılamayacağı ayrıntılı durumlar için otomatik olarak oluşturur.
Her boyutta isteğe bağlı bir SparseTensorDimSliceAttr de olabilir.
Seyrek depolama biçiminde, açıkça depolanan dizinleri belirtiriz.
koordinat ve ofset olarak konumlar olarak depolama biçimine dönüştürülür.
Desteklenen düzey biçimleri şunlardır:
- yoğun : Bu düzeydeki tüm girişler depolanır
- sıkıştırılmış : yalnızca bu düzeydeki sıfır olmayan öğeler depolanır
- loose_compressed : sıkıştırılmış olarak, ancak bölgeler arasında boş alan sağlar
- singleton : Koordinatların eşdüzey olmadığı sıkıştırılmış biçimin bir varyantı
- block2_4 : Sıkıştırma, her 1x4 blok için 2:4 kodlamasını kullanır
Sıkıştırılmış bir seviye için her konum aralığı küçük bir değer ile gösterilir.
alt sınır pos(i) ve üst sınır pos(i+1) - 1 ile görünür. Bu da
art arda gelen aralıkların, herhangi bir "delik" olmadan sırayla görünmesi gerektiğini arasında
gerekir. Gevşek sıkıştırılmış biçim, her bir boyutu temsil ederek bu kısıtlamaları
alt sınır lo(i) ve üst sınır hi(i) olan konum aralığı
aralıkların rastgele bir sırada ve bunlar arasında dirsek mesafesi olacak şekilde görünmesine olanak tanır.
Varsayılan olarak, her düzey türü benzersiz olma özelliğine sahiptir (yinelenen veya koordinatlarını içerir) ve düzenlenir (koordinatlar düzeyinde). Aşağıdaki özellikler, değiştirmek için düzey biçimine eklenebilir şu varsayılan davranışı uygulayın:
- benzersiz olmayan : Aynı düzeyde yinelenen koordinatlar görünebilir
- sırasız : koordinatlar arşiv sırasında görünebilir
Haritaya ek olarak, aşağıdaki iki alan da isteğe bağlıdır:
Konum depolama için gerekli bit genişliği (integral ofsetler) seyrek depolama şemasına dahil edilir). Genişliğin dar olması belleği azaltır kadar, baş üstü depolama alanının kapladığı yer, toplam gerekli aralığı tanımlayın (ör. depolanan maksimum tüm dolaylı düzeylerdeki girişler). Seçenekler şunlardır:
8,16,32,64veya varsayılan olarak, yerel bit genişliğini belirtmek için0.Koordinat depolama alanı için gerekli bit genişliği ( kullanılabilir). Dar genişlik bellek ayak izini azaltır bir depolama alanı; toplam gerekli aralık (ör. her tensörün maksimum değeri) koordinasyonu sağlamalısınız. Seçenekler şunlardır:
8,16,32,64veya yerel bit genişliğini belirtmek için varsayılan olarak0.
Örnekler
CSR(Compressed Sparse Row) biçiminde
aşağıda gösterildiği gibi, seyrek tensör kodlaması
şöyle olur:
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
first dimension (satır) değerinin first level,
Bu, 4 boyutla belirtilen bir dense düzeyidir. Ayrıca second dimension
(sütun), konum dizisi ve konum dizisi ile belirtilen second level ile eşlenir.
koordinat dizisi. 3 değeri (orijinal matriste [1, 1])
pozisyonlardan uzaklık dizisiyle (3 değerinin satır numarası) temsil edilir
ikinci ofset çifti olduğundan ve orijinal matriste 1
sütun numarası, koordinat dizisindeki [2 : 4) dizininde yer alır. Ayrıca
koordinatlar dizisinde, 3 sütun numarasının 1
oluşturmaktır.

BSR(Block Sparse Row) biçimi için seyrek tensör türü şu şekildedir:
#BSR = #sparse_tensor.encoding<{
map = (i, j) ->
( i floordiv 2 : dense
, j floordiv 2 : compressed
, i mod 2 : dense
, j mod 2 : dense
)
2x2 bloklardan oluşan aşağıdaki seyrek matrisi göz önünde bulundurun:
Example 2x2 block storage:
+-----+-----+-----+ +-----+-----+-----+
| 1 2 | . . | 4 . | | 1 2 | | 4 0 |
| . 3 | . . | . 5 | | 0 3 | | 0 5 |
+-----+-----+-----+ => +-----+-----+-----+
| . . | 6 7 | . . | | | 6 7 | |
| . . | 8 . | . . | | | 8 0 | |
+-----+-----+-----+ +-----+-----+-----+
Bu, nihai olarak TACO aromalı biçimde
Stored as:
positions[1] : 0 2 3
coordinates[1] : 0 2 1
values : 1.000000 2.000000 0.000000 3.000000
4.000000 0.000000 0.000000 5.000000
6.000000 7.000000 8.000000 0.000000
İşte tesadüfen, cuSparse dokümanlarında sunulan NVidia blok biçimi.
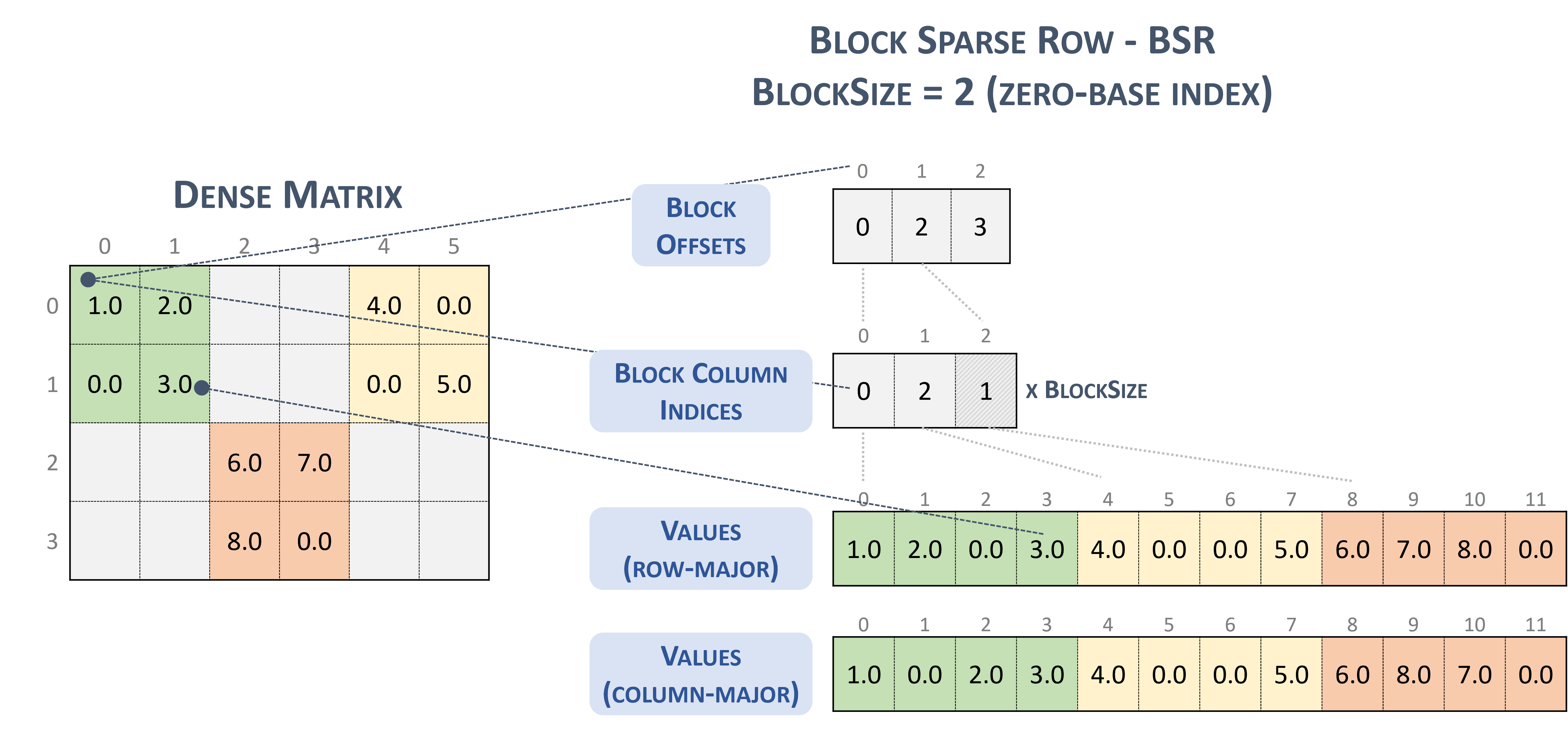
Seyrek satırı engelle. (t.d.-b). Nvidia'ya dokunun. https://docs.nvidia.com/cuda/cusparse/_images/bsr.png
Nvidia's 2:4 structured sparsity desteği de sunulmaktadır.
Bunun için seyrek tensör türü aşağıdaki gibidir:
#NV_24 = #sparse_tensor.encoding<{
map = ( i, j ) -> ( i : dense,
j floordiv 4 : dense,
j mod 4 : block2_4),
crdWidth = 2 // 2-bits for each coordinate
}>
NVidia dokümanlarında verilen örnek matrise göre:
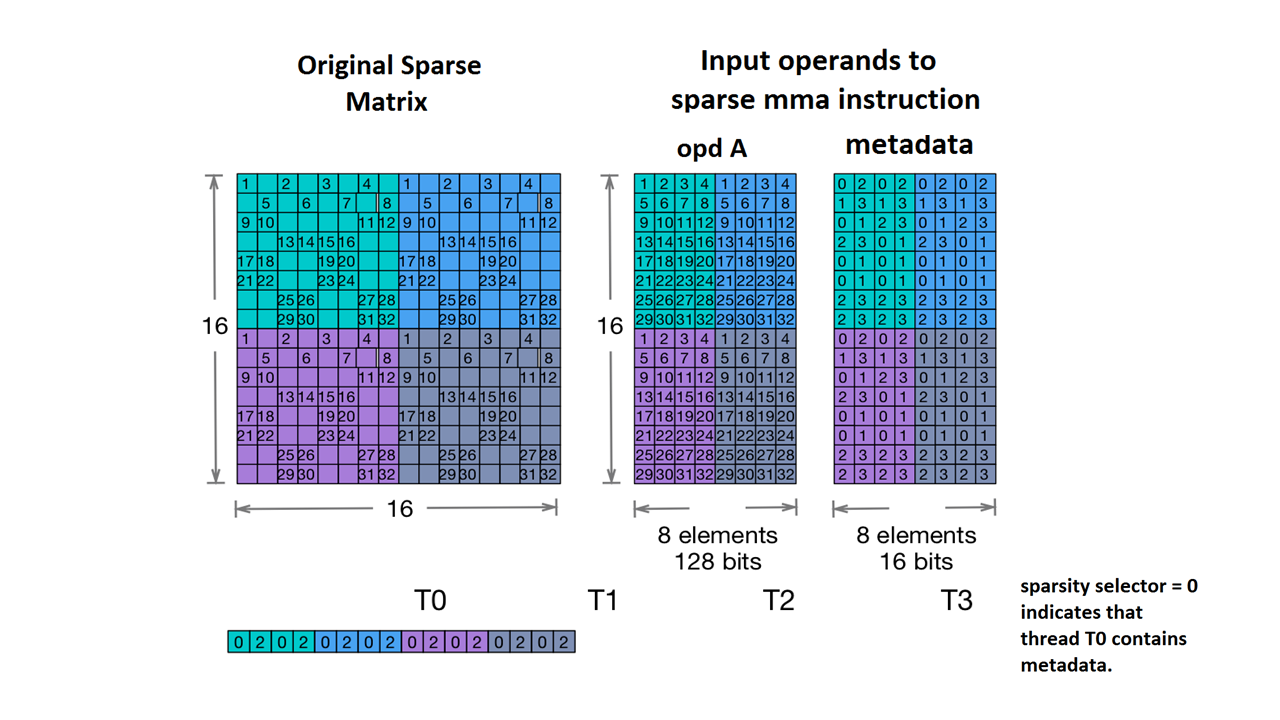
Ayrı MMA depolama alanı örneği. (n.d.). Nvidia'ya dokunun. https://docs.nvidia.com/cuda/parallel-thread-execution/index.html#warp-level-matrix-instructions-for-sparse-mma
MLIR artık bu matrisi özdeş bir düzene eşliyor:
coordinates[2] :
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
0 2 0 2 0 2 0 2
1 3 1 3 1 3 1 3
0 1 2 3 0 1 2 3
2 3 0 1 2 3 0 1
0 1 0 1 0 1 0 1
0 1 0 1 0 1 0 1
2 3 2 3 2 3 2 3
2 3 2 3 2 3 2 3
values :
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
1.000000 2.000000 3.000000 4.000000 1.000000 2.000000 3.000000 4.000000
5.000000 6.000000 7.000000 8.000000 5.000000 6.000000 7.000000 8.000000
9.000000 10.000000 11.000000 12.000000 9.000000 10.000000 11.000000 12.000000
13.000000 14.000000 15.000000 16.000000 13.000000 14.000000 15.000000 16.000000
17.000000 18.000000 19.000000 20.000000 17.000000 18.000000 19.000000 20.000000
21.000000 22.000000 23.000000 24.000000 21.000000 22.000000 23.000000 24.000000
25.000000 26.000000 27.000000 28.000000 25.000000 26.000000 27.000000 28.000000
29.000000 30.000000 31.000000 32.000000 29.000000 30.000000 31.000000 32.000000
Diğer örnekler:
// Sparse vector.
#SparseVector = #sparse_tensor.encoding<{
map = (i) -> (i : compressed)
}>
... tensor<?xf32, #SparseVector> ...
// Sorted coordinate scheme.
#SortedCOO = #sparse_tensor.encoding<{
map = (i, j) -> (i : compressed(nonunique), j : singleton)
}>
... tensor<?x?xf64, #SortedCOO> ...
// Batched sorted coordinate scheme, with high encoding.
#BCOO = #sparse_tensor.encoding<{
map = (i, j, k) -> (i : dense, j : compressed(nonunique, high), k : singleton)
}>
... tensor<10x10xf32, #BCOO> ...
// Compressed sparse row.
#CSR = #sparse_tensor.encoding<{
map = (i, j) -> (i : dense, j : compressed)
}>
... tensor<100x100xbf16, #CSR> ...
// Doubly compressed sparse column storage with specific bitwidths.
#DCSC = #sparse_tensor.encoding<{
map = (i, j) -> (j : compressed, i : compressed),
posWidth = 32,
crdWidth = 8
}>
... tensor<8x8xf64, #DCSC> ...
// Block sparse row storage (2x3 blocks).
#BSR = #sparse_tensor.encoding<{
map = ( i, j ) ->
( i floordiv 2 : dense,
j floordiv 3 : compressed,
i mod 2 : dense,
j mod 3 : dense
)
}>
... tensor<20x30xf32, #BSR> ...
// Same block sparse row storage (2x3 blocks) but this time
// also with a redundant reverse mapping, which can be inferred.
#BSR_explicit = #sparse_tensor.encoding<{
map = { ib, jb, ii, jj }
( i = ib * 2 + ii,
j = jb * 3 + jj) ->
( ib = i floordiv 2 : dense,
jb = j floordiv 3 : compressed,
ii = i mod 2 : dense,
jj = j mod 3 : dense)
}>
... tensor<20x30xf32, #BSR_explicit> ...
// ELL format.
// In the simple format for matrix, one array stores values and another
// array stores column indices. The arrays have the same number of rows
// as the original matrix, but only have as many columns as
// the maximum number of nonzeros on a row of the original matrix.
// There are many variants for ELL such as jagged diagonal scheme.
// To implement ELL, map provides a notion of "counting a
// dimension", where every stored element with the same coordinate
// is mapped to a new slice. For instance, ELL storage of a 2-d
// tensor can be defined with the mapping (i, j) -> (#i, i, j)
// using the notation of [Chou20]. Lacking the # symbol in MLIR's
// affine mapping, we use a free symbol c to define such counting,
// together with a constant that denotes the number of resulting
// slices. For example, the mapping [c](i, j) -> (c * 3 * i, i, j)
// with the level-types ["dense", "dense", "compressed"] denotes ELL
// storage with three jagged diagonals that count the dimension i.
#ELL = #sparse_tensor.encoding<{
map = [c](i, j) -> (c * 3 * i : dense, i : dense, j : compressed)
}>
... tensor<?x?xf64, #ELL> ...
// CSR slice (offset = 0, size = 4, stride = 1 on the first dimension;
// offset = 0, size = 8, and a dynamic stride on the second dimension).
#CSR_SLICE = #sparse_tensor.encoding<{
map = (i : #sparse_tensor<slice(0, 4, 1)>,
j : #sparse_tensor<slice(0, 8, ?)>) ->
(i : dense, j : compressed)
}>
... tensor<?x?xf64, #CSR_SLICE> ...